Revolution of Knowledge Work - A Tekes Large Strategic Opening
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Revolution of Knowledge Work
A Tekes Large Strategic Opening
Second Phase 4/2015−6/2017 Final Report
31.10.2017
Patrik Floréen, Salvatore Andolina, Aristides Gionis, Andrej Gisbrecht, Dorota Głowacka, Giulio
Jacucci, Markus Koskela, Kai Kuikkaniemi, Tuukka Lehtiniemi, Matti Nelimarkka, Jaakko
Peltonen, Tuukka Ruotsalo, Miamaria Saastamoinen, Baris Serim, Mats Sjöberg, Jonathan
Strahl, Tung Vuong
Helsinki Institute for Information Technology HIIT
Benjamin Cowley, Kai Puolamäki
Finnish Institute of Occupational Health
Abstract
The aim of the Revolution of Knowledge Work (Re:Know) was to create information-seeking and
sense-making methods supporting a revolution of knowledge work. The main idea was
symbiotic human-information interfaces, supporting the combined potential of human creativity
and the capability of computers to handle data, with the human in control. Instead of having the
organisation in the centre of attention, we studied tools from the point of view of individual
knowledge workers.
The first phase Re:Know 1 was a Tekes large strategic opening project funded with 1.68
million € for the period 1.9.2013−30.4.2015 (20 months). The Revolution of Knowledge Work 2
(Re:Know 2) project run for 1.4.2015−30.6.2017 (27 months, of which one month overlapping
with Re:Know 1). Originally, the project was foreseen to continue until 2019, but this was not the
case due to ceased funding for this instrument in Tekes. The project research partners were
Helsinki Institute for Information Technology HIIT (Aalto University and University of Helsinki)
and the Finnish Institute of Occupational Health (FIOH).
This report covers the results of the Re:Know 2 project.
The project resulted in a multitude of research results, many of which were demonstrated with
prototypes. The original SciNet system ideas were commercialised already earlier as Etsimo
Oy, with further commercialisation possible. The results will also be taken up in new projects; for
instance, the Digital Me platform will be used in the Tekes project TrustNet – Trust Network for
Distributed Personal Data Management.
ii
Contents
Abstract ......................................................................................................................................................... ii
1 Introduction ............................................................................................................................................... 1
2 The Process ................................................................................................................................................ 2
3 Content Reports: Introduction ................................................................................................................... 5
4 Content Report: WP1 Open Ecosystem ..................................................................................................... 5
5 Content Report: WP2 Digital Work Me Core ............................................................................................. 7
6 Content Report: WP3 Information Seeking and Sense-making ................................................................. 9
7 Content Report: WP4 Collaboration and Collective Digital Work Me ..................................................... 17
8 Content Report: WP5 Cognitive State and Organisational Pulse............................................................. 21
9 Summary of Outcomes ............................................................................................................................ 24
10 Conclusion .............................................................................................................................................. 29
Re:Know 2 Publications............................................................................................................................... 30
iii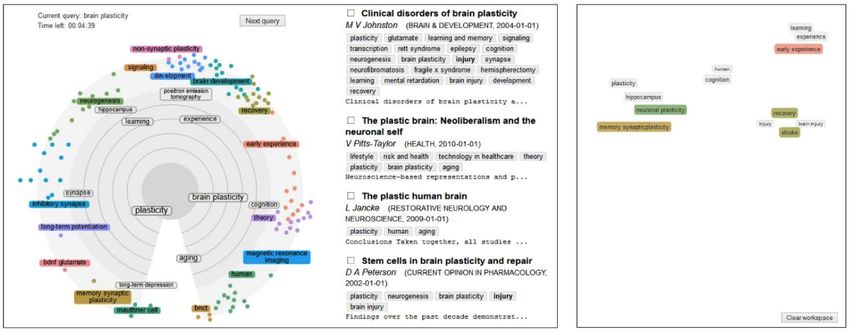
1 Introduction
A huge amount of information is spread out in various data silos. The current systems and
search engines have inflexible views to the data and they have only a limited ability to study the
large data masses, leaving knowledge workers trapped in individual information bubbles.
Current systems constrain the work instead of supporting the combined potential of human
creativity and the capability of computers to handle big or complex data.
The project combined the multidisciplinary world-class expertise in machine learning, human-
computer interaction, distributed computing, cognitive neuroergonomics and human factors at
work, available within Helsinki Institute for Information Technology HIIT and the Finnish Institute
of Occupational Health. Our objective was to develop symbiotic human-information interfaces,
which pave the way for a revolution of knowledge work.
Symbiotic human-information interfaces combine heterogeneous data sources and utilise the
context of use and user actions to jointly with the user determine what information is most likely
relevant, and provide the user with a new type of interactive and proactive interface to the data.
In the context of knowledge work, we used our know-how on both computational principles and
how humans process information to develop methods enabling humans and computers to
support each other.
The underlying idea is that by combining the potential of human creativity and the capability of
computers to handle data, we support human cognition, freeing the knowledge worker’s time to
sense-making, collaboration and creative thinking.
A central concept for our work was Digital Work Me, also called Digital Me (DiMe), a personal
data storage platform implementing a MyData vision of the user being in control of her own
data.
For information about Re:Know 1, please see the Final Report [FA15] of that project.
The Tekes decision of 20.3.2015 states the following objectives for the project:
1. A next generation of information seeking prototypes is developed. They improve sense-
making and supports well-being at work in a new way, using the human’s physiological
status, search history and other context.
2. A prototype has been developed that supports work of an ideation group both in an
intelligent meeting room and as remote participation.
3. Results of the project has been taken in use in companies.
4. An open ecosystem for promoting the commercialisation of the tools has been created
and the Digital Work Me concept has been implemented as an open source system with
at least 1000 users.
Of the objectives, number 1 was realised through several solutions explained elsewhere in this
report: IntentStreams, SciNet with negative feedback, MemEx, SIDE, etc. Objective number 2
1
was realised through InspirationWall and Crowdboard. For objective number 3, companies have
been interested in time management with DiMe and Crowdboard and Etsimo commercialises
exploratory retrieval with extensions to other fields. However, objective number 4 was only
partially met. DiMe has been released as open source on GitHub and the ecosystem has been
developed both in the academic community and in the industry sphere (via the MyData
community and consortium companies). The goal of 1000 users has not yet been reached by
the end of the reporting period. Work is still under way to make DiMe more user friendly and the
takeup is foreseen in the TrustNet project 1.10.2017−31.3.2019.
2 The Process
A consortium agreement was signed already for Re:Know 1 between the project research
partners Aalto University, University of Helsinki and FIOH. The formal decision making body
was the General Assembly, consisting of one representative per organisation (Samuel Kaski for
Aalto, Patrik Floréen for UH, and Kai Puolamäki for FIOH). These representatives were the
respective scientists in charge for the project in their own organisation. The General Assembly
had 4 meetings, all conducted as email meetings: 18.1.2016, 21.4.2016, 25.8.2016 and
20.3.2017.
The Tekes Steering Group consisted of the members of the General Assembly and the Advisory
Board. The Tekes contact person for the project was Katja Ahola. A non-disclosure agreement
was made for the participants in the Advisory Board. The following members were the most
active taking part in Steering Group meetings:
Elisa Oyj: Markus Ahokangas
M-Brain Oy: Kimmo Valtonen
Tieto Oyj: Matti Vakkuri (Chairman)
The Steering Group convened 30.4.2015, 27.8.2015, 3.12.2015, 29.2.2016, 18.5.2016,
4.10.2016, 18.1.2017 and 13.6.2017.
Project result presentations for a wider audience were arranged in conjunction with Steering
Group meetings as follows: at Tieto premises 29.2.2016, at Elisa premises 15.12.2016, and at
Futurice premises 13.6.2017.
The daily work was organised using meetings and two email lists (all Re:Know researchers &
the Principal Researchers). The Big Meetings were bi-monthly gatherings for everybody working
in the project. The Principal Researchers meetings, held mainly as videoconferences, were
targeted to professors and WP coordinators, but also others were welcome to participate. The
meetings were used to spread information, manage the project and synchronise the work. In
addition there have been many internal research meetings in smaller groups around particular
issues or prototypes.
Big Meetings were held 25.5.2015, 19.8.2015, 15.10.2015, 16.12.2015, 18.2.2016, 4.5.2016,
14.6.2016, 13.9.2016, 1.12.2016, 27.3.2017 and 29.5.2017. Principal Researchers meetings
2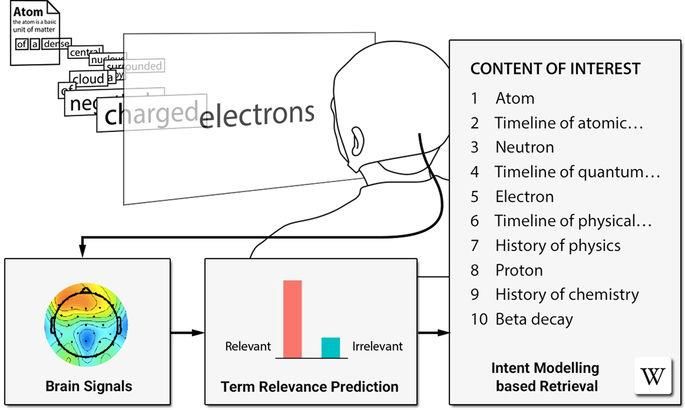
were held 2.4., 30.4., 15.5., 5.6., 10.8., 11.9., 9.10., 6.11., 20.11. and 4.12.2015; 15.1., 5.2.,
18.3., 8.4., 10.6., 12.8., 7.9., 7.10., 14.10., 4.11., 25.11. and 16.12.2016; 3.2., 24.2., 24.3., 18.5.,
and 9.6.2017.
The project material was available to the researchers in Google Drive.
The project website www.reknow.fi went operational 21.8.2013. Unigrafia designed the project
logo, visible on the front page of this document. The Final Reports will be published on the
webpage.
Personnel
Our project personnel is very international. We employed a large number of postdocs for the
project, and many were recruited from abroad.
In the following is a list of the researchers with at least 8 months of effective working time in the
Re:Know 2 project (name and effective person-months). Note that the person-months noted are
effective person-months, i.e., holidays and sick leaves are not included.
At University of Helsinki (1 person-month = 152.25 hours):
Markus Koskela 14.21
Thanh Vuong 13.18
Petri Luukkonen 10.43
Patrik Floréen 9.74
Jorma Nieminen 9.10
Khalil Klouche 8.48
In total 27 persons and 156.05 person-months. Out of these, 14 were persons of non-Finnish
origin with 72.93 person-months (46.7% of all person-months).
At Aalto University (1 person-month = 152.25 hours):
Jonathan Strahl 18.82
Marco Filetti 18.78
Tuukka Lehtiniemi 15.01
Darshan Mallenahalli Shankara Lingappa 12.14
Andrej Gisbrecht 11.03
Jesse Haapoja 9.84
Kai Kuikkaniemi 9.44
Michael Mathioudakis 9.16
Sami Remes 8.53
Mika Honkanen 8.50
Jesper Hjort 8.21
In total 29 persons and 177.86 person-months. Out of these, 13 were persons of non-Finnish
origin with 96.86 person-months (54.5% of all person-months).
3
At Finnish Institute of Occupational Health (1 person-month = 150 hours):
Benjamin Cowley 16.92
Antti Ukkonen 12.27
Andreas Henelius 12.14
Kai Puolamäki 11.10
Lauri Ahonen 10.75
In total 15 persons and 82.64 person-months. Out of these, one person was of non-Finnish
origin with 16.92 person-months (20.5% of all person-months).
The total manpower in the project was 416.55 person-months, out of which 186.71 (44.8%) was
by researchers of non-Finnish origin.
Several researchers working in the HIIT Focus Area “Augmented Research,” as well as at
FIOH, also in effect contribute to the project, without being paid from the project. For instance,
Mats Sjöberg, the lead DiMe developer, was paid by the HIIT Focus Area.
Visits (min. 1 month per visitor)
● 13.3.−13.6.2015 Arto Klami, Amazon Development Center, Berlin
● 1.5.2015−31.12.2016 Marko Turpeinen, Silicon Valley Hub activities of EIT Digital in San
Francisco
● 28.09.2015−1.12.2015 Andreas Henelius, University of Stockholm, Sweden
● 12.10.−23.12.2015 Samuel Kaski, Kyoto, Japan
● 2.1.−31.3.2016 Samuel Kaski, London, UK
● 28.12.2015−30.6.2016 Tuukka Ruotsalo, Harvard University, USA
● 31.03.2016−29.04.2016 Andreas Henelius, University of Stockholm, Sweden
● 17.4.-4.7.2016 Evimaria Terzi, Boston University, USA. Host: Aristides Gionis.
● 23.5.−17.6.2016 Samuel Kaski, Melbourne, Australia
● 1.6.2016−5.12.2016 Yash Kasture, Birla Institute of Technology and Science, Pilani, India.
Host: Patrik Floréen
● 16.10.−2.12.2016 Aris Gionis, University of Rome “Sapienza”, Italy
● 4.12.2016−5.1.2017 Mohammad Hoque, Sueol National University, Korea
Additionally, several shorter research visits were undertaken, e.g. Kai Puolamäki visited both
Ghent University in Belgium and University of Stockholm in Sweden.
Subcontracting
The plan for Re:Know 2 included two cases of subcontracting, of which one was realised.
Danube Tech Gmbh in Vienna worked on designing and developing how the DiMe personal
data storage manage self-sovereign identities and exchange data (profile attributes) securely
between DiMe and different services. The cost for this work was 24 000 € (incl. VAT), allocated
to the costs of University of Helsinki. The other, not realised case of subcontracting, related to
4programming the user interface for DiMe and this was in the end done by our own researchers
(Hung-Han Chen and Max Vilkki).
3 Content Reports: Introduction
The project was organised into five work packages:
WP1 Open Ecosystem: Coordination between WPs and main links to the external world,
including ecosystem building (led by Marko Turpeinen and coordinated by Kai Kuikkaniemi)
WP2 Digital Work Me Core: Basic building blocks of the DiMe (led by Patrik Floréen and
coordinated by Mats Sjöberg)
WP3 Information Seeking and Sense-making: Symbiotic human-computer information
seeking from the point of view of individual DiMes (led by Petri Myllymäki and Samuel Kaski
and coordinated by Markus Koskela until 31.8.2016 and thereafter by Patrik Floréen)
WP4 Collaboration and Collective Digital Work Me: Information processing and collaboration
between several knowledge workers, i.e., several DiMes (led by Giulio Jacucci and
coordinated by Salvatore Andolina)
WP5 Cognitive State and Organisational Pulse: Cognitive state and well-being of knowledge
workers; status of a group of knowledge workers (led by Kai Puolamäki and coordinated by
Ben Cowley)
Drivers for the practical work were several software prototypes. Some prototypes are joint
between WPs, but will be addressed below in the reporting of only one WP.
4 Content Report: WP1 Open Ecosystem
WP1 was the work package focusing on coordination and ecosystem development for the
Re:Know project. The work package was divided into trends and needs of knowledge work,
benchmarking of personal data systems, concept development, ecosystem design and building,
and management tasks.
Trends and needs of knowledge work
On the topic of knowledge work trends and needs, our aim was to understand what knowledge
work is “like” now and in the near future. The reason was that we wanted better to take into
account the ongoing trends in the development work done in the project. As an outcome of this
work, there is a published Trends and Needs report [LK15], where the trend work is described in
detail. We also organised an event on ”Future of Work” on 4.8.2015.
One conclusion drawn from the trends and needs work was related to the significance of data in
the knowledge work context: data is increasingly important both as a resource to be worked on,
and as a resource to be collected and stored about work. This leads to important divisions in the
workplace regarding what and how data is used, and who gets to decide about this. The second
conclusion was that as the work organisations, projects, work contexts and affiliations change, it
5makes sense to focus on the worker instead of, for example, organisational entities. Based on
these observations, the main outcome of the trends and need work was to take the individual
worker as a focal point for the development of knowledge work tools. We started to focus the
development efforts of the project around DiMe, a core platform technology, the purpose of
which is to enable workers to gather data, make use of these data, and share data. See WP2
for more details about DiMe.
Benchmarking of personal data systems
One purpose of the benchmarking study was to feed the development of the DiMe concept, as
described later in this report. One outcome of the benchmarking work was the publication
[LK17].
Through our involvement in the European Commission Roundtable on Personal Data
Management we have had close interactions with around 30 major European actors in the field,
and we also gained access into the results of a questionnaire sent by the European
Commission to these actors. We also did case study analyses and interviews with selected
personal data system developers. The involved actors included, for example, various research
projects and startup companies. The involved actors in the domain fall into two main kinds of
approaches. Personal data stores (PDSs) gather data in a private space, for example a device,
server, account or an application. The users can collect, create, store, look at, remove, and
share data contained in the PDS, and there can be a possibility to perform third-party data
analytics within the PDS. Though not in all cases, PDSs aim to be a platform technology that
attempts to become a shared resource of an ecosystem. The other approaches are broadly
interoperability frameworks. Unlike PDSs that focus on data storage, the interoperability
frameworks focus on data flows, with the purpose of determining what data is located where,
and who can access them. These include consent management services and personal data
operators with either accounts or personal devices as the access points for users. These
models are not mutually exclusive: while some attempt to become the key technology for an
ecosystem, others aim at filling a niche within an ecosystem of other services.
Concept design
The core development concept of the Re:Know project is the Digital Me (DiMe) personal data
storage for knowledge work. The concept for DiMe has been developed by acknowledging the
results of PDS benchmarking and other industry analysis, as well as trends and needs of
knowledge work. Core characteristics of the DiMe concept is modular design (local data
storage, identity and connectivity management, logger extensions and APIs), self-collected data
and symbiotic interaction. Concept design has helped to guide the DiMe development, as well
as identify collaborators for DiMe and acquire follow-up project frameworks for DiMe
development. The DiMe development work was undertaken in WP2.
6Ecosystem design and ecosystem building
We have been active facilitating the national MyData Alliance and presenting MyData in several
national and international events as well as to media. Re:Know participated in arranging the
MyData 2016 conference in Helsinki 31.8.−2.9.2016 (www.mydata2016.org) with over 700
participants from over 20 countries. MyData2017 took place in Helsinki and Tallinn
30.8.−1.9.2017 (http://mydata2017.org) after the termination of Re:Know. The new TrustNet
Tekes project emerged from the MyData Alliance work, and continues the development of DiMe.
We have been actively participating in the EU Commission Roundtable on Personal Data. A
MyData global network has been established. See more information at www.mydata.org about
this global industrial and local ecosystem network for human-centric personal data
management. All these actions promote the DiMe ecosystem building and linking DiMe to
existing personal data management applications and services.
Management
Most managerial issues were covered already in Section 2 above.
As part of the management work, we undertook an internal review during the course of the
project. A questionnaire was open to Re:Know researchers 25.1.−6.2.2016 for anonymous
replies. We got 28 answers (6 UH, 9 Aalto, 8 FIOH and 5 did not answer their affiliation). The
internal project review reached the following conclusions: The overall project objectives were
unclear to some researchers (as a result, the objectives were reminded about in the Big Meeting
4.5.2016), some Tekes objectives were deemed difficult to achieve, in particular the 1000 DiMe
users, many researchers felt there are too many things going on simultaneously, and DiMe was
seen to be of central importance and also an important theme for further projects. As a
summary, we concluded that there was not a need to make substantial revisions to the project
plan.
5 Content Report: WP2 Digital Work Me Core
At the start of the project, WP2 conducted a preliminary review of existing personal data storage
(PDS) platforms and technologies together with WP1. None of the then existing software
solutions were considered directly suitable for our needs. Thus the decision was made to
develop our own PDS system, Digital Me (DiMe), incorporating existing technologies along the
way as appropriate. The basic data storage system was quickly produced with a rudimentary
API to kick-start the development work. After this, the WP2 work continued on two fronts:
immediate-term software development with an emphasis on integration, and together with WP1
assessing the long-term directions for personal data management and analysis.
On the software development side, the focus was on integration with the work being done in the
other WPs. In particular, the MemEx and PeyeDF applications, being built in WP3 and WP5
respectively, worked very closely with the WP2 team to add new features and APIs needed by
those applications. A set of DiMe loggers were also developed for collecting computer desktop
7usage, PDF document reading (including gaze tracking), web browsing and support for health
trackers such as Fitbit. Effort was also spent on producing good API and developer
documentation and easier installation. The first public and open source release of DiMe version
0.1 was on 25 January 2016.
The next stage in the core DiMe development was the introduction of tags and profiles to better
model the users’ data. Tags can be manually added by the user or automatically extracted from
textual data by various natural language processing (NLP) techniques. Profiles, in turn, are
user-defined categorisations of the collected data, which improve over time by integrating user
interaction and automatically learning from the collected data. A paper describing the DiMe
system was published and presented at the Workshop on Symbiotic Interaction 2016 in Padova,
Italy [SC17]. The DiMe platform was presented at a talk in the MyData 2016 conference, and
several contacts to companies and other MyData community members were initiated.
Together with WP1, a new user interface for DiMe using the JavaScript-based React framework
was planned and developed. DiMe version 0.2 with the new user interface was released on 30
November 2016.
Data sharing between DiMe instances was enabled by incorporating the XDI semantic data
interchange protocol (http://xdi.org/) and Sovrin (https://sovrin.org/) technologies. XDI is used for
communicating between DiMe instances, and it enables an access control mechanism, where a
DiMe user can allow or deny any external data access through the DiMe user interface. The
Sovrin component enables a digital identity for each DiMe user, which is in the user’s own
control (self-sovereign identity). The Sovrin ledger also stores connection information enabling
direct DiMe-to-DiMe communication. These technologies were demonstrated with a simple
"People finder" application where knowledge workers can upload their professional profiles built
in their DiMe, and employers can find potential hires and request access to further data from
their DiMe instances. Part of the XDI and Sovrin work was done with an external contractor,
Markus Sabadello of Danube Tech Gmbh, see the section on subcontracting above.
WP2 also investigated the use of the AWARE framework to enable a mobile phone version of
DiMe. This was deemed possible, but was not implemented as part of the project. Another
option is to integrate with SenSe [HT16], an IoT data analytics and sensing framework being
developed by researchers in our project. Recently, we also developed a Spark-based efficient
look-up method with indexed Bloom multi-filters [CH17].
DiMe version 0.3 was released on 31 October 31 2017. It included several important bug fixes
and minor improvements, such as language detection and initial support for detecting longer
term activities in the input. DiMe version 1.0 will be released in December 2017. It will be a
major release as it will incorporate all the Sovrin and XDI-related work done as part of Re:Know.
This will enable data sharing between several DiMe instances, or between DiMe and external
services. The license for DiMe version 1.0 will change from MIT to the GNU Affero General
Public License (AGPL), due to the AGPL license of the included XDI2 library. The DiMe work
related to Sovrin will continue in the TrustNet TEKES project.
86 Content Report: WP3 Information Seeking and Sense-making
WP3 had several tracks related to search and sense-making of information. Most of the
application prototypes had integration with DiMe as a major common theme.
Understanding user behaviour in naturalistic information search tasks
Understanding users' information search behaviour has largely relied on information available
from search engine logs. These studies provide limited information about the contextual factors
that affect users' search behaviour. As a consequence, the questions such as why and how we
search for information, and what triggers our information needs remain largely unanswered.
We reported [VJ17a, VJ17b] an experiment in which naturalistic information search behaviour
was captured by analysing a 24/7 continuous recordings of information on participants'
computer screens. Tasks and the associated search epochs comprising of pre-search context,
queries, and post-search context were extracted and classified under different task categories
according to individual intention, task goal, and subject matter of the task.
We investigated the effect of different task categories on three behavioural factors: content
trigger, application context, search effort. We reported dependencies between search effort and
individual intentions and task goals. We also showed dependencies between knowledge
intensive tasks and content triggers, and intellectual and creative tasks and application context.
Brain interfaces for information search
Finding relevant information from large document collections such as the World Wide Web is a
common task in our daily lives. Estimation of a user’s interest or search intention is necessary to
recommend and retrieve relevant information from these collections. During the Re:Know
project, we developed – as the first in the world – a brain-information interface used for
recommending information by relevance inferred directly from brain signals [ER16] as illustrated
in Figure 6.1. In experiments, participants were asked to read Wikipedia documents about a
selection of topics while their EEG was recorded. Based on the prediction of word relevance,
the individual’s search intent was modelled and successfully used for retrieving new relevant
documents from the whole English Wikipedia corpus. The results show that the users’ interests
toward digital content can be modelled from the brain signals evoked by reading. The
introduced brain-relevance paradigm enables the recommendation of information without any
explicit user interaction and may be applied across diverse information-intensive applications.
The fundamental brain responses to relevance signals were also studied and neural correlates
of relevance were detected [ER14].
The work got much public attention, for instance, in Helsingin Sanomat
(http://www.hs.fi/tiede/art-2000005004448.html) and TechCrunch
(https://techcrunch.com/2016/12/14/researchers-use-machine-learning-to-pull-interest-signals-
9from-readers-brain-waves/). A video illustration is available at
https://www.youtube.com/watch?v=3XIJgiLJwbI.
Figure 6.1: Overview of the brain-relevance paradigm.
Interactive interfaces for exploratory search and comprehension of search results
For information search, the starting point for the work has been the SciNet search engine with
keywords displayed on a radar interface [RJ15], see also the Re:Know 1 final report [FA15].
Efficient exploration of information in big data relies on two key abilities: the ability to
comprehend information in search results, and the ability to efficiently directly search in the
information space, based on the user’s understanding of their intent and the available
information. We have addressed both aspects.
Comprehension of search results requires help from advanced interfaces. In difficult information
seeking tasks, the majority of top-ranked documents for an initial query may be non-relevant,
and negative relevance feedback may then help find relevant documents. Presenting results as
a ranked list forces the user to scan through the ranked list and pick sufficiently relevant
documents from the top of the ranking. Often, however, users are not looking for a single
highest-ranked document, but the initial query is issued to broadly comprehend the information
space. This requires proficiency in information literacy based on the result list and confronts
users with problems detecting topical subspaces within the initial ranked list. We have
introduced the topic-relevance map [PB17a, PB17b], a novel overview visualisation approach
considering two dimensions essential for search results: topical similarity and relevance. Topic-
10relevance maps organise keywords representing the search results onto a radial layout (see
Figure 6.2 below): non-linear dimensionality reduction is used to embed high-dimensional
keyword representations into angles on the radial layout, and relevance of keywords is
estimated by a ranking method and visualised as radiuses on the radial layout. We have studied
the effectiveness and user behaviour of topic-relevance map in a search result comprehension
task; skimming and understanding the structure and conceptualisation of search results by
creating a conceptual structure using either the topic-relevance map or a comparison system
together with a workspace for organizing found keywords. Results suggest that the topic-
relevance map yields a more comprehensive understanding of search results than the
comparison system.
Figure 6.2: A screenshot of the user interface that was used by the participants in search result
comprehension tests. Left: The topic-relevance map visualization component and the ranked
list of search results in response to a search query "Brain Plasticity". The inner area (light grey
background) shows the top ten keywords related to the search query. The outer ring (very light
grey background) shows a set of other keywords clustered and the most important in each
cluster highlighted. Right: The workspace for arranging found relevant keywords; users could
drag keywords from the topic-relevance map to desired positions on the workspace. In both the
system with the topic-relevance map and in the baseline system, users could also drag
keywords appearing under the search result documents onto the workspace.
Directing search with interactive interfaces can make use of both positive and negative
feedback. In difficult information seeking tasks, the majority of top-ranked documents for an
initial query may be non-relevant, and negative relevance feedback may then help find relevant
documents. Traditional negative relevance feedback has been studied on document results; we
have introduced a system and interface for negative feedback in a novel exploratory search
setting, where continuous-valued feedback is directly given to keyword features of an inferred
probabilistic user intent model, see the Figure 6.3 below [PS17]. We carried out task-based
information seeking experiments with real users on difficult real tasks; we compared the system
to the nearest state of the art baseline allowing positive feedback only. The proposed system
11outperformed the previous state of the art system on performance, evolution of the performance
over time, and in user experience. In ongoing work, we are extending the system for exploring
and operating on multiple interrelated search interests.
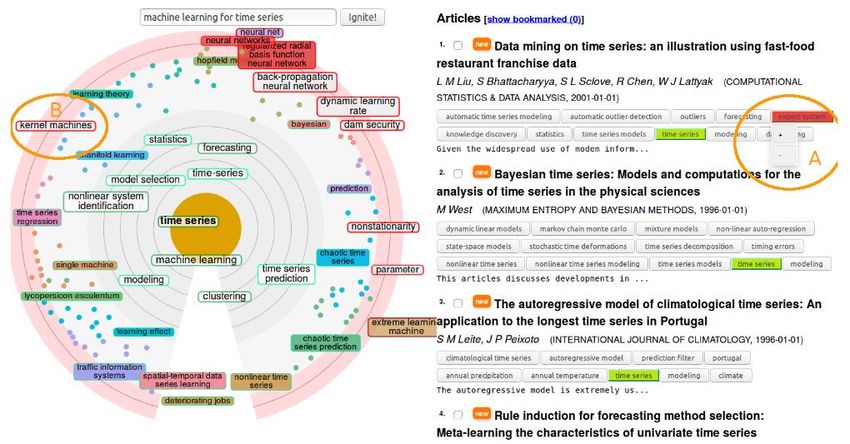
Figure 6.3: Exploratory search interface with negative feedback: The search intent radar
comprises of three ring-shaped areas: the inner circle (grey background) shows keywords
positively associated with the search intent, the future-predictions ring (lighter grey background)
uncertain keywords that have the potential to be relevant are presented, and the negative-
feedback ring (light red background) keywords predicted to have negative relevance (example
in B: “kernel machines” is predicted to be negatively associated with the search intent). In all
areas, the angle of keywords relates to the similarity of neighbouring keywords; keywords on the
same angle in the inner circle and outer rings are similar, and distance to the centre represents
estimated relevance of the keyword (closer to the centre is more relevant). A user can give
feedback by dragging keywords to the rings or directly by clicking on keywords in the article list
(A). Keywords that have received negative feedback this round are shown with red background.
Interactive personalisation of the search engine
We apply user search behaviour to inform the system whether the user is performing lookup or
exploratory search, which, in turn will allow the system to balance between exploration and
exploitation. Previous work has treated lookup and exploratory search tasks as belonging to
homogeneous categories, ignoring the specific information needs between users and even
between search sessions for the same user. We avoid this dichotomy by considering each
search task to exist on a spectrum between lookup and exploratory. In doing so, our approach
aims to adapt dynamically exploration and exploitation in a manner commensurate with the
user's individual requirements for each search session. We present a novel study design
12together with a regression model for predicting the optimal exploration rate based on simple
metrics from the first iteration, such as clicks and reading time, which can be collected without
special hardware. We perform model selection based on the data collected from a user study
and show that predictions are consistent with user feedback [AM15, AM16, MP17].
Additionally we performed a short experiment on using topic models to assess the relevance of
displayed documents in exploratory search studies. Evaluation is crucial in assessing the
effectiveness of new information retrieval and human computer interaction techniques and
systems. Relevance judgements are often performed by humans, which makes obtaining them
expensive and time consuming. Consequently, relevance judgements are usually performed
only on a subset of a given collection of data or experimental results with a focus on the top
ranked documents. However, when assessing the performance of exploratory search systems,
the diversity or subjective relevance of documents that the user was presented with over a
search session are often of more importance than the relative ranking of top documents. In
order to perform these types of assessment, all the documents in a given collection need to be
judged for relevance. We proposed an approach based on topic modelling that can greatly
accelerate document relevance judgment of an entire document collection with an expert
assessor needing to mark only a small subset of documents from a given collection. The test
collection is divided into topic model clusters and the assessor only marks a small number of
documents associated with each cluster. This assessment is then propagated through the entire
collection based on the similarity of the remaining documents to the ones marked by the
assessor. Experimental results show a substantial overlap between relevance judgments
compared to a human assessor [MG17].
Proactive search, text recommendation and text generation
A significant fraction of information searches are motivated by the knowledge workers primary
task, such as documents that the user is reading or writing that trigger the information need and
search activity. We have investigated how the implicit task context can be used to model the
user's search intent and to proactively retrieve relevant and useful information. A small study
using simulation experiments and recurrent neural networks was published in the Neu-IR'16
SIGIR Workshop [LK16]. A larger study using the LinRel algorithm, and real user experiments
will be published as a journal paper (currently in review). Both studies demonstrate that users'
search intents can be inferred from the task and relevant and useful information can be
proactively retrieved.
A related area is text recommendation or generation, i.e., to predict the next words as the user
has typed a sentence. This can be used both as a way of helping to write faster, but also to
predict the likely context then used as a basis for proactive recommendations. The work on text
recommendation used recurrent neural networks, in particular long short-term memory networks
(LSTM).
13Intelligent meeting room
As the basis of the work on the Intelligent meeting room, some internal Re:Know meetings were
recorded. This included video recording both with video cameras and with the participants'
laptops, and in some cases psychophysical measurements (ECG, EDA) of the participants. A
dedicated software program (see “Meeting Recorder” in the list of software produced) was
developed to enable unobtrusive recording on laptops.
The aim of the work was twofold. First, the inclusion of meetings in the DiMe ecosystem was
studied in some preliminary experiments. Second, the recorded meetings were analysed to
discover useful patterns of behaviour to facilitate the generation of meeting summaries. The
results from including psychophysiological measurements were not conclusive. We also
analysed gaze directions based on the recorded video and obtained promising results to
capture the meeting dynamics based on gaze information.
Exploratory image retrieval
In exploratory image retrieval, we worked with neural network architectures. Recent advances in
deep neural networks have given rise to new approaches to content-based image retrieval
(CBIR). Their ability to learn universal visual features for any target query makes them a good
choice for systems dealing with large and diverse image datasets. However, employing deep
neural networks in interactive CBIR systems still poses challenges: either the search target has
to be predetermined, such as with hashing, or the computational cost becomes prohibitive for an
online setting. We developed a framework for conducting interactive CBIR that learns a deep,
dynamic metric between images. The proposed methodology is not limited to pre-calculated
categories, hashes or clusters of the search space, but rather is formed instantly and
interactively based on the user feedback. We use a deep learning framework that utilises pre-
extracted features from convolutional neural networks and learns a new distance representation
based on the user’s relevance feedback.
Our method uses deep similarity-based learning to find a new representation of the image
space. With this metric, it finds the central point of interest and clusters its local region to
present the user with representative images within the vicinity of their target search. This
clustering provides a more varied training set for the next iteration, allowing the detection of
relevant features faster. Additionally, relearning a representation of the user’s search interest in
each round enables the system to find other non-local regions of interest in the search space,
thus preventing the user from getting stuck in a context trap. We test our method in a simulated
online setting, taking into consideration the accuracy, coverage and flexibility of adapting to
changes in the user’s interest. The experimental results show the potential of applying our
framework in an interactive CBIR setting as well as symbiotic interaction, where the system
automatically detects what image features might best satisfy the user’s needs [PG16, PG17].
14Encoding multimodal histories on interactive visualisations
We rely on different forms of history encoding to orient ourselves when interacting with digital
information. Different visual encodings that help us distinguish hyperlinks we have visited or
emails we have read from others are common examples. Although the general usefulness of
history encoding is well acknowledged, previous work exclusively focused on interactive
operations that can be captured through manual input devices.
In Re:Know, we evaluated the potential of using eye movements and interactive operations for
encoding multimodal histories of users’ engagement. Engaging with interactive visualisations
involves visually attending to different regions through eye movements, as well as interactive
operations, such as filtering or highlighting, that alter the visual scene. Eye tracking allows
sensing visual attention with greater resolution and confidence than what can be assumed from
manual input. To evaluate the potential of multimodal histories we prototyped three interactive
visualisations. One of the visualisations, a node-link diagram, see Figure 6.4 below, has been
evaluated with 18 participants in a controlled setting, while we also invited five experts to give
open ended comments on applications in focused interview sessions. The feedback we
collected from the evaluations demonstrates a good acceptance of multimodal interaction
histories, although no improvements in task performance were seen. Additionally, we identified
a number of potential communicative problems, such as uncertainty regarding what counts as
visually attending, confusions between what is visited by mouse and what is attended by gaze
and the effect of unintentional eye movements. Overall, the user evaluations illustrate the
potential challenges and benefits of multimodal interaction histories and provide direction for
future research.
Figure 6.4: Schematic depiction of a multimodal sequence with a node-link diagram and
subsequent history encoding. After selecting a node, the selected and neighbouring nodes are
highlighted by the system and become temporary areas of interest (AOIs). After deselecting the
node, the items that are visually attended are augmented as a part of the history.
15MemEx
The idea behind MemEx (Memory expander) is to create a tool that would help users to
organise and to access their DiMe data, while working on several projects simultaneously. This
is achieved with an algorithm that models the user's intents from interactions and estimates the
relevancies of historical documents to the current user's actions. Additionally, the user interface
is designed in such a way that it shows the history based on the learned relevancies and allows
to interact with the model. It is thus possible, based on the current context in the user's
workflow, to determine the user's intent and thereby retrieve the needed information
automatically.
We are currently analysing results from a user study about how people organise their data while
multi-tasking and whether MemEx can be helpful in this scenario. The participants are asked to
find information on different topics in short succession. After working on some task, they have to
revisit previous tasks again and again. This requires changing mindsets between the tasks and
working on the different sets of documents associated to each topic respectively. By utilising
MemEx the users can adapt quickly to the current task and conveniently retrieve the desired
information. Preliminary results indicate that users can benefit from assistance when the amount
of accessed documents exceeds their working memory.
Figure 6.5: A screenshot from the MemEx interface during the user study.
Tool for subjective and interactive visual data exploration (SIDE)
We developed a theoretically justified model and a tool for information exploration SIDE [KP16,
KP17, PK16, PO17]. The idea is to model what the user knows and then provide visual
representations that show maximal difference between the assumed knowledge of the user and
the real data.
We demonstrated the concept by visualizing real valued data sets, both real and artificially
created [KP16]. We visualised the data with scatterplots, which were here projections to the
16directions of maximal difference between the assumed knowledge of the user and the real data.
In the tool, the user can interact with the data and mark features that he or she has absorbed
from the data, after which the model of user’s knowledge is updated and a new projection is
shown in the next iteration. This is in contrast to more traditional dimensionality reduction
methods, in which the criteria of interestingness are fixed in advance and cannot be easily
changed by the user. In our approach, we can adapt to the user’s knowledge and provide the
most informative visualisations to the user.
7 Content Report: WP4 Collaboration and Collective Digital Work Me
Social coordination (Task 4.1)
The goal was to analyse personal communication data, and social data, in order to infer
expertise of employees, find experts and authorities for a given skill, build teams able to work
successfully towards a given task, and infer structure of collaboration networks.
First, we mined personal communication data with the goal of generating skill endorsements of
the type “person A endorses person B on skill X” [DD16]. To address privacy concerns, we
considered that each person had access only to their own data (i.e., conversations with their
peers). By using our method, they can generate endorsements for their peers, which they can
inspect and opt to publish. To identify meaningful skills we used a knowledge base created from
the StackExchange Q&A forum. We studied two different approaches, one based on building a
skill graph and one based on information retrieval techniques. We found that the latter approach
outperformed the graph-based algorithms when tested on a dataset of user profiles from
StackOverflow.
Aggregating over all available pairs of users, the result of the method above [DD16] is an
endorsement graph, which is an edge-labelled social network, where links between two users
represent endorsements from one user to another. An endorsement graph captures topical
expertise as perceived by users. Our next research problem was to utilise endorsement graphs
and find topical experts. We proposed a new approach that combined traditional link analysis
with text mining [LD17]. We validated our method on twitter, where the task was to find experts
for a given query topic. To build an endorsement graph on twitter, we used crowd-sourced data
from Twitter lists. Extensive evaluation on a number of different topics demonstrated that the
proposed approach significantly improved on query-dependent PageRank, outperformed the
current publicly known state-of-the-art methods, and was competitive with twitter’s own search
system, while using less than 0.05% of all Twitter accounts.
Next we considered the problem of team formation with preference constraints [Ga16]. Given a
set of employees, a set of skills for each employee, a set of tasks, a set of required skills for
each task, and a preference ranking from employees to tasks, the goal was to find an
assignment of employees to tasks, so that all tasks are covered, and the total employee
satisfaction is maximised. This problem is encountered in big companies, or markets of
freelance workers, who are interested in forming teams to work in projects of interest.
17Finally, we considered problems where we observe how teams of employees perform and the
goal was to infer the social structure. We consider problem formulations where we infer the
most likely social connections [GR17a], or the strength of social ties [GR17b].
All the results in this task make a useful suite of methods for analysing, supporting, and
improving social coordination among employees.
Collaboration in creative activities (Task 4.2)
In this task we investigated how to support two main creative activities that benefit from
collaboration: exploratory search and idea generation. As part of our investigation we designed
and evaluated three systems: QueryTogether, InspirationWall, and Crowdboard.
QueryTogether
Search is often considered a solo activity. However, many complex and creative tasks that
require exploration and gathering a larger body of information call for people working together
for search. In particular co-located information access is becoming increasingly common.
However, fairly little attention has been devoted to the design of ubiquitous computing
approaches for spontaneous exploration of large information spaces enabling co-located
collaboration.
Figure 7.1: QueryTogether schematic picture.
We designed QueryTogether [AK17], see Figure 7.1, a multi-device collaborative search tool
through which entities such as people, documents, and keywords can be used to compose
queries that can be shared to a public screen or specific users with easy touch-enabled
interaction. We conducted mixed-methods user experiments with 27 participants (nine groups of
three people) to compare the collaborative search with QueryTogether to a baseline of
established search and collaboration interfaces. Results show that QueryTogether led to more
balanced contribution and search engagement. While the overall subtopic recall in search was
similar, in the QueryTogether condition participants found most of the relevant results earlier in
the tasks, and for more than half of the queries avoided text entry by manipulating
18recommended entities. The video analysis demonstrated a more consistent common ground
through increased attention to the common screen, and more transitions between collaboration
styles.
InspirationWall
An important phase of the idea generation process is retrieving concepts from the associative
memory. In collaborative idea generation activities, this process is supported by leveraging
social interactions and knowledge sharing. We investigated if we could facilitate the process by
leveraging information exploration techniques that expand the current context of topics and
suggest candidate topics that are novel but related to the current context.
We designed InspirationWall [AK15], an unobtrusive display that leverages speech recognition
and information exploration to enhance an ongoing idea generation session with automatically
retrieved concepts that relate to the conversation. We evaluated the system in six idea
generation sessions of 20 minutes with small groups of two people. Preliminary results suggest
that InspirationWall contrasts the decay of idea productivity over time and can thus represent an
effective way to enhance idea generation activities.
Figure 7.2: The InspirationWall concept.
Crowdboard
While automatic approaches, such as InspirationWall, attempt to intelligently provide
inspirations based on the topic currently being discussed, automated methods have limited
intelligence. Thus, we also investigated how to support ongoing idea generation sessions by
leveraging the collective intelligence of real people, such as online crowds.
19Figure 7.3: The Crowdboard in action.
We designed Crowdboard [AS17], a system that allows online crowds to provide real-time
creative input during early-stage design activities, such as brainstorming or concept mapping.
The system enables in-person ideators to develop ideas on a physical or digital whiteboard,
which is augmented with real-time creative input from online participants who see and hear a
live broadcast of the meeting. We run a user study to test the effects of real-time crowds on
ideation. Results showed that Crowdboard helped participants generate ideas that increased in
creativity over time at a higher rate than they did when using the whiteboard without a crowd.
While there are still many open challenges regarding real-time interactions among in-person
and crowd ideators, our work suggests that this approach could be a fast and effective way to
boost early-stage ideation.
Live participation (Task 4.3)
In live participation research we have examined how mediated technology can be used to
support collaboration while people are collocated. During Re:Know 2 we have further examined
the system design and practices for meaningful presenter-audience interaction. We have
characterized live participation as participatory episodes with an aim to support the event
[NK16b]. The episode should be supported via integration work, where the presenter bridges
the digital channel to the physical channel. Through properly conducted integration work and the
ability to manage and manipulate the digital channel, the digital channel is not a separated
communication tool, but rather an extended part of the performance.
After understanding the importance of social support, our work focused on the significant roles
of the organisation of a live participation event. Kai Kuikkaniemi’s PhD work [Ku17] focused on
system design to support the creation of an extended performance. His LAIX-framework
separates the role-based interface channels (e.g., public display, participant, presenter) and
activities (e.g., poll episode, chat episode). One or more activities can be shown to one or more
channels. The LAIX-framework was implemented in the Presemo system.
20Similarly, Nelimarkka [Ne17] focused on examining the social structures during live participation.
He argued that live participation can change the social rules from traditional (single channel)
interaction. The change can be both positive and negative. Positive aspects include increased
willingness to express oneself, while negative aspects include antisocial behaviour.
Furthermore, he examined the role of the presenter to define the social rules and even the
values for system use. He therefore argued that supporting the definition and maintenance of
these social rules is a critical aspect during live participation events.
Beyond the academic results, the research continued to extend the capabilities of the open
sourced system Presemo and develop the business practices for the live participation company
screen.io.
8 Content Report: WP5 Cognitive State and Organisational Pulse
The purpose of WP5 was to use contextualised data sources, measuring physiology and
behaviour in single-person and collaborative settings, and to supply inferences on the worker’s
cognitive and motivational state. The end goal was to improve self-management for knowledge
workers, and supporting sustainable knowledge work in organisations.
The content of WP5 focused on the following main areas:
The foundational methodology of the measurement and use of biosignals
The social physiological synchrony of collaborating workers
The interaction of information seeking and cognitive state
Methods to fuse, analyse, and explore high-dimensional noisy data
Tools to support psychophysiology research and translation to application
Foundational methodology (The Psyhophysiology Primer)
Involving all researchers in WP5, a major paper [CF16] on methods of psychophysiology was
published. Entitled “The Psychophysiology Primer: a guide to methods and a broad review with
a focus on human computer interaction,” this work provides a useful introduction for novices or
reference work for experts, specifically aimed at taking biosignal measurement methods out of
the lab into application in field studies. As such, it covers all the important biosignals that can be
applied in a mobile, wearable context, with one chapter each. The work is available from Now
Publishers as a journal paper, book, or e-book. The authors have also made the content freely
available online from the arXiv preprint server.
Social physiological synchrony
WP5 studied collaboration between pairs of programmers as a specific case of knowledge
worker. WP5 cooperated with the Agile Education research group (RAGE) at University of
Helsinki to record physiology during programming classes. Two studies were conducted. The
first study, published in PloS ONE [AC16], examined how heart rate variability could be used to
detect that pairs were indeed collaborating (physiology was synchronising) in an uncontrolled
21You can also read

















































