STYLER: Style Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
STYLER: Style Modeling with Rapidity and Robustness via Speech
Decomposition for Expressive and Controllable Neural Text to Speech
Keon Lee, Kyumin Park, Daeyoung Kim
Data Engineering & Analytics Laboratory, KAIST
{keon.lee, pkm9403, kimd}@kaist.ac.kr
Abstract only after careful investigation on each style token or latent di-
mension.
Previous works on expressive text-to-speech (TTS) have a lim- Meanwhile, speech synthesis frameworks without autore-
itation on robustness and speed when training and inferring. gressive decoding have been proposed recently [12, 16, 17]. In-
Such drawbacks mostly come from autoregressive decoding, spired from Transformer [18], some of non-autoregressive TTS
which makes the succeeding step vulnerable to preceding er- models use self-attention block for parallel decoding [12, 17].
arXiv:2103.09474v1 [eess.AS] 17 Mar 2021
ror. To overcome this weakness, we propose STYLER, a novel In these models, the substitution of autoregressive decoder into
expressive text-to-speech model with parallelized architecture. duration-based self-attention block showed faster speed and sta-
Expelling autoregressive decoding and introducing speech de- bility enhancement. Furthermore, auxiliary modules such as
composition for encoding enables speech synthesis more robust variance adaptor in FastSpeech2 [17] enabled more robust and
even with high style transfer performance. Moreover, our novel controllable TTS, even though such modules needed extra su-
noise modeling approach from audio using domain adversarial pervision.
training and Residual Decodingenabled style transfer without Another recent study includes speech decomposition via in-
transferring noise. Our experiments prove the naturalness and formation bottleneck in voice conversion systems [19, 20]. For
expressiveness of our model from comparison with other paral- example, SpeechSplit [20] successfully decomposes style fac-
lel TTS models. Together we investigate our model’s robustness tors such as duration (rhythm), pitch, speaker (timbre), and con-
and speed by comparison with the expressive TTS model with tent from reference audio and convert them into target speech in
autoregressive decoding. an unsupervised way. This approach showed the possibility of
Index Terms: speech synthesis, neural text-to-speech, expres- split modeling of style factors by utilization of source audio.
sive and controllable text-to-speech, style modeling and trans- In this paper, we propose STYLER, a fast and robust
fer style modeling TTS framework without autoregression for
the expressive and controllable speech synthesis. Upon non-
1. Introduction autoregression, we construct speech decomposition modules to
construct and control style factors with reference speech that
Despite remarkable improvement in neural text-to-speech we need to represent a style of it. We also propose an additional
(TTS) towards human-level reading performance [1, 2, 3, 4], pipeline to decompose noise from reference speech without any
it was criticized that most of those models can represent only label to eliminate the noise while successfully transferring the
a single reading style. Since this style is determined from the speech style from noisy input. This is the first study of mod-
average style of speech in the training dataset [5, 6], TTS mod- eling style factors, including noise in a non-autoregressive TTS
els were limited to represent expressive voice. In order to re- framework to the best of our knowledge.
solve such a problem, several approaches [7, 8, 9, 10, 11] has Our model enhances expressive and controllable speech
been explored upon TTS models so that they can synthesize synthesis in two aspects: increasing robustness which enables
speech with various style. Such expressive TTS suggestions style factor control from unseen reference audio and increasing
extract style factors from source audio, specifically via train- model speed with high fidelity. We suggest our contributions as
able style embedding called Global Style Token [7], or latent follows:
variable [8, 9, 11].
• We prove the robustness and rapidity of expressive TTS
These expressive TTS models, however, have weaknesses with autoregressive architecture removed.
in speed and robustness due to autoregressive architecture [12].
During the autoregressive decoding step, the speech output is • By utilizing supervision of style factor in FastSpeech2,
highly dependent on prior output, which makes speech synthe- we enable delicate style control without tricky training.
sis vulnerable in that collapse in one step may fall into the fail- • We prove that our noise decomposition pipeline enables
ure of total synthesis [13, 14]. Moreover, this autoregressive noise-robust speech synthesis with no additional label.
decoding consumes large training and inference overhead since
each decoding needs iteration along with all-time steps, making
it hard to parallelize. 2. Method
Another drawback of existing expressive TTS originates There are two primary considerations to achieve our goal, non-
from an unsupervised training manner. Regarding the claim autoregressive TTS with style factor modeling. First, some non-
that unsupervised training has a fundamental limitation on dis- autoregressive TTS frameworks benefit from supervision, while
entangling independent features [15], current expressive TTS speech decomposition using bottleneck was studied in an unsu-
with unsupervised style modeling [7, 8] could result in imper- pervised condition. Second, as the voice conversion task, the
fect style extraction from source audio. In addition, training content of audio may not be matched to the text. Prior works
in such way is usually tricky and style control can be achieved [10, 11] hired an attention mechanism, which claimed to be un-text encoding, pitch embedding (embedding of pitch predictor
output), energy embedding (embedding of energy predictor out-
put), and speaker encoding. Speaker encoding is included be-
cause information between input and target should be matched
for the desired mapping.
2.1.2. Speech Decomposition
We utilize the encoder of SpeechSplit [20] to decompose the
style factor from source audio. Applying bottleneck onto in-
put, we constrain information fit to target: duration, pitch, or
energy. Each predictor of style factor predicts real value rather
than latent code, however, input to each predictor needs to con-
tain all necessary information. Unlike the unsupervised con-
dition, forced feature selection is not needed by virtue of pre-
obtained features from incoming audio, and any excessive bot-
tleneck will lead to performance degradation [19]. Therefore,
we mitigate the bottleneck to avoid scarcity of information for
predictors and relish the supervision.
Basically, we have raw audio as input and extract mel-
spectrogram in 80 channels, pitch contour, and energy from
it for style factor decomposition. Duration and noise encoder
Figure 1: An architecture of the proposed model. Zt , Zt’ , Zd , takes mel-spectrogram. Pitch encoder takes a speaker normal-
Zp , Zs , Ze and Zn refer to text, downsampled text, duration, ized pitch contour (mean = 0.5, standarddeviation = 0.25)
pitch, speaker, energy, and noise encoding, respectively. DAT so that speaker-independent pitch contour is modeled. The en-
stands for Domain Adversarial Training, and details are in ergy encoder takes scaled energy from 0 to 1 to ease the model
Section 2.2.1. The detach function prevents the gradient flow- training. After extracted from audio, both pitch, and energy in-
ing from noisy decoding to noise-independent encoders during put is quantized in 256 bins one-hot vector, and then processed
Residual Decoding, and details are in Section 2.2.2 by encoders.
Each encoder has three 5x1 convolution layers followed by
a group normalization [23] of size 16 and channel-wise bottle-
stable. In this section, we describe the proposed model in detail neck by two layers bidirectional-LSTM size 64 except the du-
along with our solution to the aforementioned problems. ration encoder where the size is 96. The dimension of the con-
volution layer is 256 for duration and noise, 320 for pitch and
2.1. Model Architecture energy. By linear layer with ReLU activation, encoder outputs
are upsampled channel-wise before being sent to each predictor.
An overview architecture is shown in Figure 1. STYLER ex- The content of the audio is removed through the bottleneck in
tends FastSpeech21 [17] and encoders of SpeechSplit2 [20] are audio-related encoders since the content of the final output of
adapted to take a reference audio as a model input. STYLER our model should be encoded solely by the text encoder.
models total six style factors: text, duration, pitch, speaker, en-
The structure of predictors is the same as FastSpeech2.
ergy, and noise. Note that the text is regarded as a style factor
Each predictor takes the sum of the corresponding encoding
equal to audio related ones.
with text encoding. To balance the dependency, however,
the text encoding is projected to four-dimensional space as a
2.1.1. FastSpeech2 Extension
channel-wise bottleneck. The pitch predictor receives speaker
For architecture for text encoder and mel-spectrogram decoder, encoding as an additional input to predict the target speaker’s
we modified FastSpeech2 [17] to achieve our intent. Text voice with disentangled pitch contour. We project and add
encoder has two 256 dimensional Feed-Forward Transformer speaker encoding to both downsampled and upsampled pitch
(FFT) blocks [12] with four heads and takes phoneme sequence encoding, finding out empirically that this improves the decom-
as input text. We adjust model specifications in order to align position of speaker identity.
the number of parameters with audio encoders. Variance adap-
tor, including duration predictor, pitch predictor, and energy 2.1.3. Mel Calibrator
predictor, is placed on top of the encoders. To become a mul-
tispeaker system, speaker encoding is transferred from pre- Not using attention alignment, we need to resolve length in-
trained speaker embedding as presented in [21]. In this work, compatibility between the content of source audio and input
Deep Speaker [22] is employed since it is faithful to embed text. Therefore, we apply Mel Calibrator between convolution
speaker identities without extra features such as noise robust- stack and upsampling layer in each style factor encoder. As-
ness. serting length aligning as a frame-wise bottleneck, we design
Decoder has four 256 dimensional FFT blocks with four Mel Calibrator as a linear compression or expansion of audio
multi heads. We increase the number of heads since the com- to the length of the input text. It simply averages frames or re-
plexity of decoding would increase to represent variants of style peats a frame of audio to assign them to a single phone. There
factor combination. The decoder’s input is a combination of are two advantages over the attention mechanism in terms of
our objective: it does not bring any robustness issue against the
1 https://github.com/ming024/FastSpeech2 non-autoregression, and it does not being exposed to the text so
2 https://github.com/auspicious3000/SpeechSplit that audio-related style factors only come from the audio.2.2. Noise modeling inal dataset by mixing each utterance with a randomly selected
piece of background noise from WHAM! dataset [28], at a ran-
Noise is one of the remaining factors that have been explicitly
dom signal-to-noise ratio (SNR) in a range from 5 to 25. Raw
encoded in model encoders. Therefore, it can be defined based
audio is resampled at 22050Hz sampling rate and preprocessed
on its residual property, excluding other style factors. In order
to 1024 filter lengths, 1024 window sizes, and 256 hops lengths.
to model noise by the definition, however, other encoders must
be constrained to exclude noise information even from noisy We divide the dataset into train, validation, and test set. In
input. the first two sets, 44 speakers of each gender are randomly se-
lected to balance speaker statistics. The remaining speakers are
2.2.1. Domain Adversarial Training in the test set. The processed dataset is about 26 hours in total,
containing 35805, 89, and 8345 utterances for the train, valida-
Not including noise information means extracting noise- tion, and test set, respectively.
independent features. In the TTS domain, this has been tack- For the baseline, we use the following models to compare
led by applying Domain Adversarial Training (DAT) [24, 25]. with STYLER in two aspects.
Similarly, in our model, the augmentation label is used to re-
place the unavailable acoustic condition label (e.g., noise la- • Mellotron [29]: Tacotron2 based GST model, which en-
bel), and a gradient reversal layer (GRL) is injected to be jointly ables conditioning pitch and duration. We use Mellotron
trainable. The label of each predictor acts as a class label. As as an expressive TTS baseline with autoregressive de-
shown in Figure 1, DAT is applied to every audio-related en- coding and unsupervised prosody extraction.
coding except noise encoder. After passing through GRL, each
• FastSpeech2 [17]: TTS model with non-autoregressive
encoding is consumed by the augmentation classifier to predict
decoding and supervision in pitch, duration, energy con-
the augmentation posterior (original/augmented). The augmen-
trol. We extend the original model to multispeaker by
tation classifier consists of two fully connected layers of 256
adding utterance level speaker embedding. This baseline
hidden size, followed by layer normalization [26] and ReLU
is used to compare the expressiveness of parallel TTS.
activation. Note that each encoder except the noise encoder is
now noise-independent, so each predictor’s output is compared STYLER is optimized by the same optimizer and sched-
to clean labels rather than noisy ones. uler in FastSpeech2. We train all models using a batch size of
16 with a single Titan RTX each until the validation loss no
2.2.2. Residual Decoding longer drops. For the fair comparison, we apply the pretrained
According to the definition of noise and the fact that explicit ResCNN Softmax+Triplet model3 for speaker embedding iden-
label is not given, the decoder needs to perform Residual De- tically to STYLER and both baselines. For mel-spectrogram
coding: clean decoding and noisy decoding. In clean decoding, to wave conversion, we use pretrained multispeaker UNIVER-
all noise-independent encodings are taken to synthesize a clean SAL V1 model4 of HiFi-GAN [4].
output, and in noisy decoding, noise encoder output is added
to noise-independent encodings to synthesize a noisy output. 3.2. Result
Since only the noise encoder has to be updated at noisy decod- Using Amazon Mechanical Turk, we evaluate each model’s
ing, the gradient does not flow through the other encoders. It speech synthesis quality using mean opinion score (MOS) and
can be seen as implicit supervision where the noise is directly comparative MOS (CMOS) [30, 31]. For each scoring, we test
compelled to focus on the audio’s leftover part without any ex- in two different speaker settings: seen speakers in training time
plicit label. and unseen speakers. We evaluate two different synthesis en-
vironments for each speaker: parallel (-P) denotes input audio
2.3. Loss Calculation speaks input text, where nonparallel (-NP) denotes input audio
The total loss of the model without noise modeling is: speaks different text from the input.
Lossclean = lmel + lduration + lpitch + lenergy (1)
3.2.1. Naturalness and Efficiency
where lmel is mean square error between predicted mel-
spectrogram and target, and predictor losses (lduration , lpitch , For naturalness evaluation, we evaluate MOS of audio from four
and lenergy ) are calculated by mean absolute error. Note that different sources: Ground Truth, two baselines, and our model.
it is the same as FastSpeech2 which means that the proposed In order to remove the vocoder artifact, we use HiFi-GAN [4]
model can disentangle style factors with no additional label. for all models, including ground truth. Ground truth audio is
The loss, including noise modeling, then becomes as fol- translated into mel-spectrogram and synthesized to speech con-
lows: secutively so that vocoder quality does not affect the experi-
ment. Besides, we report training time to assess model speed.
Losstotal = Lossclean + lnoisy + laug (2)
where Lossclean refers to Equation 1, lnoisy is from noisy de- Table 1: Naturalness MOS & Training Time Results
coding calculated by the same way of lmel in Equation 1, and
laug is the sum of each augmentation classifier loss in Sec- Seen Unseen
Model Training Time
tion 2.2.1. MOS-P MOS-NP MOS-P MOS-NP
GT 4.35 4.35 4.35 4.35 -
Mellotron 3.22 3.10 2.77 2.45 20m
3. Experiment FastSpeech2 3.76 3.68 3.14 3.04 4m
STYLER 3.64 3.60 3.22 3.17 4m
3.1. Experiment Setup
Throughout the experiment, we train and evaluate models on 3 https://github.com/philipperemy/deep-speaker
VCTK corpus [27]. For the noisy dataset, we augment the orig- 4 https://github.com/jik876/hifi-ganTable 1 shows experiment results in aspect of both audio
quality and model speed. The proposed model outperforms
Mellotron in the aspect of naturalness and outperforms Fast-
Speech2 in the aspect of expressiveness. Also, training time
measurement indicates that our model runs about 4 to 5 times
faster than Mellotron, the autoregressive TTS model, even with
a similar number of the model parameters.
3.2.2. Style Transfer
Table 2: Style Transfer CMOS Results
Seen Unseen
Model
CMOS-P CMOS-NP CMOS-P CMOS-NP
STYLER 0 0 0 0
FastSpeech2 -1.24 -1.55 -1.35 -1.44
Mellotron -0.20 -0.16 -0.52 -0.75
Next, we conduct CMOS between the proposed model and
each baseline to evaluate style transfer performance. Testers
are asked to select audio that represents a closer style to refer-
ence audio. Table 2 reports CMOS of style transfer performance
where score of STYLER is fixed to 0. Comparison between
FastSpeech2 and STYLER denotes that our method repre-
sents better expressiveness than the normal non-autoregressive
model. Another comparison with Mellotron indicates that our
model preserves style transfer performance proposed by exist-
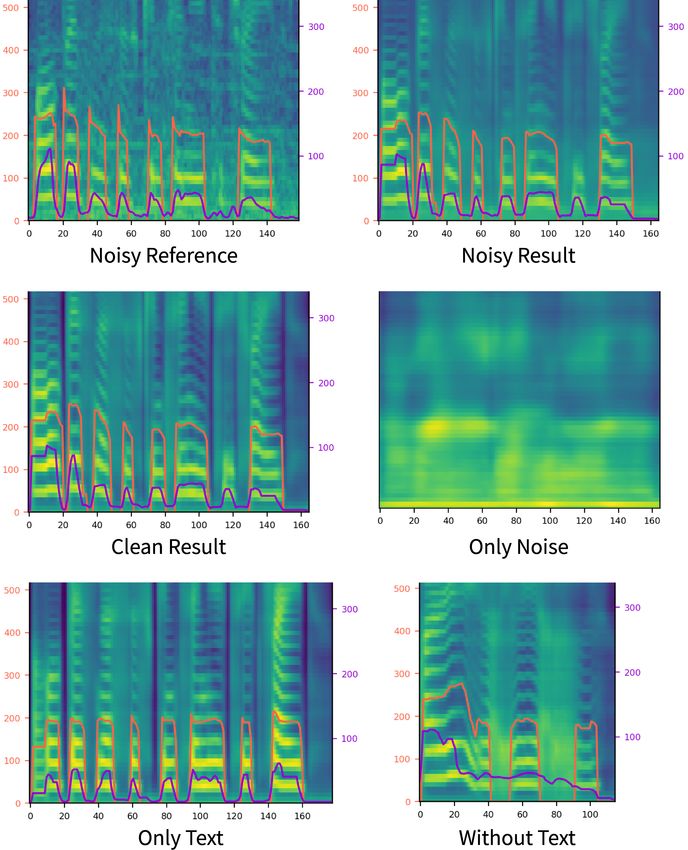
ing style transfer models. Figure 2: Results of style factor decomposition. The orange line
represents pitch contour and the purple line represents energy.
3.2.3. Style Factor Decomposition The content of the noisy reference is ”All businesses continue to
Validating the functionality of each module in our model, we trade.” The figure is best shown in color.
synthesize speech excluding the encoding module one-by-one.
Figure 2 shows our ablation study result as mel-spectrogram.
The noisy result, which is the model output, imitates the in-
put noisy reference audio, meaning that all the style factors are
transferred well from the source audio. 4. Discussion
In order to validate noise modeling, we conduct several
experiments with the noise module. With noisy reference au- We argue that our model’s strength over FastSpeech2 is the ex-
dio (top-left), we synthesize speech with and without the noise plicit decomposition of style factor and balanced contribution of
module each. When the noise module is introduced, the result- style factors, including text content toward synthesized speech.
ing speech contains background noise (noisy result at top-right), In FastSpeech2, the duration, pitch, and energy were already
while noise is excluded when noise module is not introduced controllable. However, values were only predicted from the
(clean result at middle-left). Our model can produce completely text, and the encoders of our model can be seen as distribut-
clean audio even only the noisy input is given. Moreover, the ing the dependence equally among the necessary elements of
only noise is synthesized when only the noise module is acti- speech. Therefore, there is a difference between controlling the
vated during inference (only noise at middle-right). These ex- value of predictors (decoder input) and the encoding (predictor
periments conclude that the noise module successfully decom- input). For example, if the pitch predictor’s value is set to 0,
poses noise from reference audio. the pitch value of the final mel-spectrogram becomes 0 for each
When we infer speech without each style factor, excluded frame. However, if only text encoding is added to the pitch
style is fixed to average style in synthesized speech (only text at predictor, the dependency of audio is removed, and the output
bottom-left). Excluding pitch prediction, for instance, synthe- speech contains almost the same pitch for each phoneme which
sizes speech with average pitch flow, and excluding energy pre- is not 0. This constant value is the averaged pitch of the training
dictor makes speech containing constant volume. Also, given dataset.
another speaker, only the speaker’s identity is changed while
the rest are fixed. On the other hand, there was a trade-off between the natu-
In another experiment, we exclude text encoder in speech ralness and style transfer performance according to the model
synthesis to investigate whether an only content factor is en- input’s dependence. For example, if the text dependency is in-
coded from text input and whether the audio-related style creased, the naturalness increases too, but the reference style
factors are modeled correctly (without text at bottom-right). is less reflected. On the contrary, if the audio dependency is
Speech inferred without text encoder expresses the style of ref- increased, the reference style is well transferred, but the nat-
erence audio, but it does not speak any intelligible word. From uralness of the synthesized voice decreases. In particular, this
this result, we can conclude that content factor is extracted from phenomenon is severe in duration, so that the duration modeling
text, and encoders successfully capture expected style factors. could be less precise than other style factors.5. Conclusion speech synthesis,” in ICASSP 2020-2020 IEEE International Con-
ference on Acoustics, Speech and Signal Processing (ICASSP).
In this paper, we propose STYLER, a fast and robust TTS IEEE, 2020, pp. 6264–6268.
framework with expressive and controllable style factor decom-
[12] Y. Ren, Y. Ruan, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y. Liu,
position. Our model enables style transfer in non-autoregressive
“Fastspeech: Fast, robust and controllable text to speech,” arXiv
TTS via speech decomposition, which outperforms existing preprint arXiv:1905.09263, 2019.
models in robustness and rapidity while preserving naturalness
and expressiveness. As discussed, however, our model has a [13] S. Bengio, O. Vinyals, N. Jaitly, and N. Shazeer, “Scheduled sam-
pling for sequence prediction with recurrent neural networks,”
trade-off between style decomposition performance and speech arXiv preprint arXiv:1506.03099, 2015.
synthesis performance. Therefore, our future work would be-
come a resolution of the trade-off to enhance performance and [14] M. Ranzato, S. Chopra, M. Auli, and W. Zaremba, “Sequence
an improvement in duration modeling. level training with recurrent neural networks,” arXiv preprint
arXiv:1511.06732, 2015.
6. Acknowledgements [15] F. Locatello, S. Bauer, M. Lucic, G. Raetsch, S. Gelly,
B. Schölkopf, and O. Bachem, “Challenging common assump-
Note to authors. This is the acknowledgments section. You can tions in the unsupervised learning of disentangled representa-
note any acknowledgment regarding the present work. tions,” in international conference on machine learning. PMLR,
2019, pp. 4114–4124.
7. References [16] K. Peng, W. Ping, Z. Song, and K. Zhao, “Non-autoregressive
neural text-to-speech,” in International Conference on Machine
[1] Y. Wang, R. Skerry-Ryan, D. Stanton, Y. Wu, R. J. Weiss, Learning. PMLR, 2020, pp. 7586–7598.
N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio et al.,
“Tacotron: Towards end-to-end speech synthesis,” arXiv preprint [17] Y. Ren, C. Hu, T. Qin, S. Zhao, Z. Zhao, and T.-Y. Liu, “Fast-
arXiv:1703.10135, 2017. speech 2: Fast and high-quality end-to-end text-to-speech,” arXiv
preprint arXiv:2006.04558, 2020.
[2] J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang,
Z. Chen, Y. Zhang, Y. Wang, R. Skerrv-Ryan et al., “Natural [18] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N.
tts synthesis by conditioning wavenet on mel spectrogram pre- Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,”
dictions,” in 2018 IEEE International Conference on Acoustics, arXiv preprint arXiv:1706.03762, 2017.
Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4779– [19] K. Qian, Y. Zhang, S. Chang, X. Yang, and M. Hasegawa-
4783. Johnson, “Autovc: Zero-shot voice style transfer with only au-
[3] R. Prenger, R. Valle, and B. Catanzaro, “Waveglow: A flow-based toencoder loss,” in International Conference on Machine Learn-
generative network for speech synthesis,” in ICASSP 2019-2019 ing. PMLR, 2019, pp. 5210–5219.
IEEE International Conference on Acoustics, Speech and Signal
Processing (ICASSP). IEEE, 2019, pp. 3617–3621. [20] K. Qian, Y. Zhang, S. Chang, M. Hasegawa-Johnson, and D. Cox,
“Unsupervised speech decomposition via triple information bot-
[4] J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial tleneck,” in International Conference on Machine Learning.
networks for efficient and high fidelity speech synthesis,” arXiv PMLR, 2020, pp. 7836–7846.
preprint arXiv:2010.05646, 2020.
[21] Y. Jia, Y. Zhang, R. J. Weiss, Q. Wang, J. Shen, F. Ren, Z. Chen,
[5] Z. Hodari, O. Watts, and S. King, “Using generative modelling P. Nguyen, R. Pang, I. L. Moreno et al., “Transfer learning
to produce varied intonation for speech synthesis,” arXiv preprint from speaker verification to multispeaker text-to-speech synthe-
arXiv:1906.04233, 2019. sis,” arXiv preprint arXiv:1806.04558, 2018.
[6] D. Stanton, Y. Wang, and R. Skerry-Ryan, “Predicting expressive
[22] C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y. Cao, A. Kan-
speaking style from text in end-to-end speech synthesis,” in 2018
nan, and Z. Zhu, “Deep speaker: an end-to-end neural speaker
IEEE Spoken Language Technology Workshop (SLT). IEEE,
embedding system,” arXiv preprint arXiv:1705.02304, vol. 650,
2018, pp. 595–602.
2017.
[7] Y. Wang, D. Stanton, Y. Zhang, R.-S. Ryan, E. Battenberg,
J. Shor, Y. Xiao, Y. Jia, F. Ren, and R. A. Saurous, [23] Y. Wu and K. He, “Group normalization,” in Proceedings of the
“Style tokens: Unsupervised style modeling, control and European conference on computer vision (ECCV), 2018, pp. 3–
transfer in end-to-end speech synthesis,” in Proceedings of 19.
the 35th International Conference on Machine Learning, [24] Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle,
ser. Proceedings of Machine Learning Research, J. Dy and F. Laviolette, M. Marchand, and V. Lempitsky, “Domain-
A. Krause, Eds., vol. 80. Stockholmsmässan, Stockholm adversarial training of neural networks,” The journal of machine
Sweden: PMLR, 10–15 Jul 2018, pp. 5180–5189. [Online]. learning research, vol. 17, no. 1, pp. 2096–2030, 2016.
Available: http://proceedings.mlr.press/v80/wang18h.html
[25] W.-N. Hsu, Y. Zhang, R. J. Weiss, Y.-A. Chung, Y. Wang, Y. Wu,
[8] Y. Zhang, S. Pan, L. He, and Z. Ling, “Learning latent represen-
and J. Glass, “Disentangling correlated speaker and noise for
tations for style control and transfer in end-to-end speech syn-
speech synthesis via data augmentation and adversarial factoriza-
thesis,” in ICASSP 2019 - 2019 IEEE International Conference
tion,” in ICASSP 2019-2019 IEEE International Conference on
on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp.
Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019,
6945–6949.
pp. 5901–5905.
[9] W.-N. Hsu, Y. Zhang, R. J. Weiss, H. Zen, Y. Wu, Y. Wang,
Y. Cao, Y. Jia, Z. Chen, J. Shen et al., “Hierarchical genera- [26] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”
tive modeling for controllable speech synthesis,” arXiv preprint arXiv preprint arXiv:1607.06450, 2016.
arXiv:1810.07217, 2018. [27] J. Yamagishi, C. Veaux, K. MacDonald et al., “Cstr vctk corpus:
[10] Y. Lee and T. Kim, “Robust and fine-grained prosody control of English multi-speaker corpus for cstr voice cloning toolkit (ver-
end-to-end speech synthesis,” in ICASSP 2019-2019 IEEE Inter- sion 0.92),” https://datashare.ed.ac.uk/handle/10283/3443, 2019.
national Conference on Acoustics, Speech and Signal Processing [28] G. Wichern, J. Antognini, M. Flynn, L. R. Zhu, E. McQuinn,
(ICASSP). IEEE, 2019, pp. 5911–5915. D. Crow, E. Manilow, and J. Le Roux, “Wham!: Extending
[11] G. Sun, Y. Zhang, R. J. Weiss, Y. Cao, H. Zen, and Y. Wu, “Fully- speech separation to noisy environments,” in Proc. Interspeech,
hierarchical fine-grained prosody modeling for interpretable Sep. 2019.[29] R. Valle, J. Li, R. Prenger, and B. Catanzaro, “Mellotron: Mul-
tispeaker expressive voice synthesis by conditioning on rhythm,
pitch and global style tokens,” in ICASSP 2020-2020 IEEE Inter-
national Conference on Acoustics, Speech and Signal Processing
(ICASSP). IEEE, 2020, pp. 6189–6193.
[30] M. Chu and H. Peng, “Objective measure for estimating mean
opinion score of synthesized speech,” Apr. 4 2006, uS Patent
7,024,362.
[31] F. Ribeiro, D. Florêncio, C. Zhang, and M. Seltzer, “Crowdmos:
An approach for crowdsourcing mean opinion score studies,” in
2011 IEEE international conference on acoustics, speech and sig-
nal processing (ICASSP). IEEE, 2011, pp. 2416–2419.You can also read

















































