The CERN Digital Memory Platform - Master Thesis - CERN Document Server
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Vrije Universiteit Amsterdam Universiteit van Amsterdam
Master Thesis
The CERN Digital Memory Platform
Building a CERN scale OAIS compliant Archival Service
Author: Jorik van Kemenade (2607628)
CERN-THESIS-2020-092
Supervisor: dr. Clemens Grelck
28/06/2020
2nd reader: dr. Ana Lucia Varbanescu
A thesis submitted in fulfillment of the requirements for
the joint UvA-VU Master of Science degree in Computer Science
June 28, 2020
The CERN Digital Memory Platform
Building a CERN scale OAIS compliant Archival Service
Jorik van Kemenade
Abstract
CERN produces a large variety of research data. This data plays an important role in CERN’s
heritage and is often unique. As a public institute, it is CERN’s responsibility to preserve current
and future research data. To fulfil this responsibility, CERN wants to build an “Archive as a
Service” that enables researchers to conveniently preserver their valuable research.
In this thesis we investigate a possible strategy for building a CERN wide archiving service using
an existing preservation tool, Archivematica. Building an archival service at CERN scale has at
least three challenges. 1) The amount of data: CERN currently stores more than 300PB of data.
2) Preservation of versioned data: research is often a series of small, but important changes. This
history needs to be preserved without duplicating very large datasets. 3) The variety of systems
and workflows: with more than 17,500 researchers the preservation platform needs to integrate
with many different workflows and content delivery systems.
The main objective of this research is to evaluate if Archivematica can be used as the main
component of a digital archiving service at CERN. We discuss how we created a distributed
deployment of Archivematica and increased our video processing capacity from 2.5 terabytes
per month to approximately 15 terabytes per month. We present a strategy for preserving
versioned research data without creating duplicate artefacts. Finally, we evaluate three methods
for integrating Archivematica with digital repositories and other digital workflows.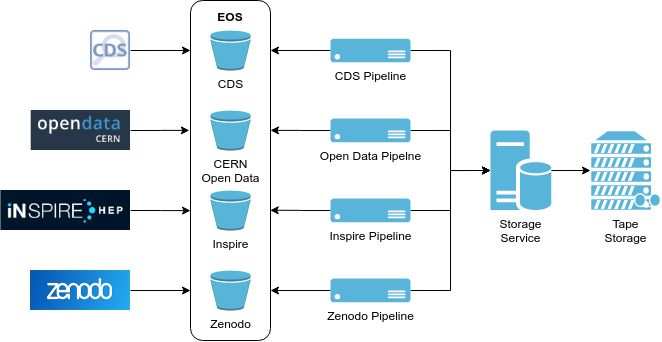
Contents
1 Introduction 7
2 Digital preservation 11
2.1 Digital preservation concepts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Open Archival Information System (OAIS) . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Digital preservation systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 CERN Digital Memory Platform 21
3.1 Digital Preservation at CERN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3 Building an OAIS compliant archive service . . . . . . . . . . . . . . . . . . . . . . 24
4 Vertical scaling 29
4.1 Archivematica Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2 Storage Scaling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5 Horizontal scaling 35
5.1 Distributing Archivematica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.2 Task management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 Distributed image processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.4 Distributed video processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
6 Versioning and deduplication 45
6.1 The AIC versioning strategy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
6.2 Case study: Using versioned AICs for Zenodo . . . . . . . . . . . . . . . . . . . . . 47
7 Automated job management 51
7.1 Automation tools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
7.2 Archivematica API client . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
7.3 Enduro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
8 Discussion and conclusion 57
5Chapter 1
Introduction
For centuries scientists have relied upon two paradigms for understanding nature, theory and
experimentation. During the final quarter of last century a third paradigm emerged, computer
simulation. Computer simulation allows scientists to explore domains that are generally inaccessi-
ble to theory or experimentation. With the ever growing production of data by experiments and
simulations a fourth paradigm emerged, data-intensive science [1].
Data-intensive science is vital to many scientific endeavours, but demands specialised skills and
analysis tools: databases, workflow management, visualisation, computing, and many more. In
almost every laboratory “born digital” data is accumulated in files, spreadsheets, databases,
notebooks, websites, blogs and wikis. Astronomy and particle physics experiments generate
petabytes of data. Currently, CERN stores almost 300 petabytes of research data. With every
upgrade of the Large Hadron Collider (LHC), or the associated experiments, the amount of acquired
data grows even faster. By the early 2020’s, the experiments are expected to generate 100 petabytes
a year. By the end of the decade this has grown to 400 petabytes a year. As a result of this the
total data volume is expected to grow to 1.3 exabytes by 2025 and 4.3 exabytes by 2030 [2].
Before building the LHC, CERN was performing experiments using the Large Electron-Positron
Collider (LEP). Between 1989 and 2000, the four LEP experiments produced about 100 terabytes
of data. In 2000, the LEP and the associated experiments were disassembled to make space for the
LHC. As a result of this the experiments cannot be repeated, making their data unique. To make
sure that this valuable data is not lost, the LEP experiments saved all their data and software to
tape. Unfortunately, due to unexpectedly high tape-wear, two tapes with data were lost.
Regrettably hardware failure is not the only threat to this data. Parts of the reconstructed data is
inaccessible because of deprecated software. In addition to this, a lot of specific knowledge about
the experiments and data is lost because user-specific documentation, analysis code, and plotting
macros never made it into the experiment’s repositories [3]. So even though the long term storage
of files and associated software was well organised, the LEP data is still at risk.
But even when carefully mitigating hardware and software failures, data is simply lost because the
value of the data was not recognised at the time. A notable example are the very first web pages
of the World Wide Web. This first website, CERN’s homepage, and later versions were deleted
during updates. In 2013, CERN started a project to rebuild and to preserve the first web page
and other artefacts that were associated with the birth of the web. During this project volunteers
rebuilt the first ever website1 , but also saved or recreated the first web browsers, web servers,
documentation and even original server names and IP-addresses [4].
This are some examples of lost data, threatened data, and data that is saved by chance. For
each example there are countless others, both inside CERN and at other institutes. Fortunately,
there is a growing acknowledgement in the scientific community that digital preservation deserves
attention. Sharing of research data and artefacts is not enough, it is essential to capture the
structured information of the research data analysis workflows and processes to ensure the usability
1
This page can be found on the original url: http://info.cern.ch/
7CHAPTER 1. INTRODUCTION and longevity of results [5]. To move from a model of preservation by chance to preservation by mission, CERN started the CERN Digital Memory Project [6]. The goal of the Digital Memory project is to preserve CERN’s institutional heritage through three initiatives. The first initiative is a digitisation project. This project aims to preserve CERN’s analogue multimedia carriers and paper archives through digitisation. The multimedia archive consists of hundreds of thousands of photos, negatives, and video and audio tapes. The multimedia carriers are often fragile and damaged. The digitisation is performed by specialised partners, and the resulting digital files will be preserved by CERN. The second initiative is Memory Net. The goal of Memory Net is to make digital preservation an integral part of CERN’s culture and processes. Preservation is usually an afterthought: it is easy to postpone and does not provide immediate added-value. By introducing simple processes, leadership commitment, and long-term budgets, Memory Net changes the preservation of CERN’s institutional heritage from an ad-hoc necessity to an integral part of the data management strategy. The third initiative is creating the CERN Digital Memory Platform, a service for preserving digitised and born-digital content. The main goal of the CERN Digital Memory Platform is to serve as a true digital archive, rather than as a conventional backup facility. The idea is that all researchers at CERN can connect their systems to the archiving service and use it to effortlessly preserve their valuable research. Building a digital archive at the scale of CERN is not without challenges. The obvious challenge is the size of the archive. Currently, CERN is storing 300 petabytes of data. This is significantly larger than the median archive size of 25 terabytes [7]. The largest archive in this study is 5.5 petabytes and the total size of all archives combined is 66.8 petabytes. Assuming that CERN can archive material at a rate of the largest archive per year, processing only a quarter of the current backlog takes 14 years. Fortunately, CERN already takes great care in preserving raw experimental data. This means that the archiving effort only has to focus on preserving the surrounding research: software, multimedia, documentation, and other digital artefacts. One of the characteristics of research is that it is often the result of many incremental improvements over longer periods of time. Preserving every version of a research project, including large data sets, results in a lot of duplication. Consequently, we need to preserve all versions of a research project without duplicating large datasets. The third, and last, challenge is integrating the CERN Digital Memory Platform into existing workflows. With more than 17,500 researchers from over 600 institutes working on many different experiments there is a large variety in workflows and information systems. The CERN Digital Memory Platform will only be used if it allows users to to conveniently deposit new material into the archive. This requires that the archiving service is scalable in the number of connected systems, and in the variety of material that can be preserved. In this thesis we a investigate a possible approach for creating the CERN Digital Memory Platform. More specifically we want to investigate if it is possible to build the platform using currently existing solutions. The first step is investigating a selection of existing and past preservation initiatives, preservation standards, tools and systems. For each component we determine if they meet the requirements for the CERN Digital Memory Platform. This analysis forms the basis for selecting the standards and systems used for creating the CERN Digital Memory Platform. Based on this analysis we selected Archivematica for building the CERN Digital Memory Platform. Before committing to use Archivematica for the project, it is important to verify that Archive- matica can be used to address each of the three challenges. The first challenge is the size of the preservation backlog. To evaluate if Archivematica has the required capacity for processing the preservation backlog, we evaluate the performance of a default Archivematica deployment. During this evaluation we benchmark the performance of Archivematica for simple preservation tasks. During the initial investigation we identified two bottlenecks. The first bottleneck is the size the local storage. When processing multiple transfers simultaneously, Archivematica runs out of local storage. The storage requirements of Archivematica are too demanding for the virtual machines offered in the CERN cloud. To solve this problem we investigate various large scale external storage solutions. For each option, we benchmark the raw performance and the impact on the preservation throughput. 8
CHAPTER 1. INTRODUCTION
The second bottleneck is processing power. A single Archivematica server cannot deliver the
required preservation throughput for processing the massive preservation backlog. This means
that we need to investigate how Archivematica can scale beyond a single server. We present
a strategy for deploying a distributed Archivematica cluster. To evaluate the performance of a
distributed Archivematica cluster we benchmark the archiving throughput for both photo and video
preservation. For each workload we compare the performance of the distributed Archivematica
cluster to the performance of a regular Archivematica deployment and evaluate the scalability.
The second challenge is supporting the preservation of versioned data. One problem with archiving
every version of a digital object is duplication. Duplicate data has triple cost: the processing of
duplicate data, the storage space of the data, and the migration costs of the data. By default
Archivematica does not support deduplication or versioning of preserved data. We propose to
solve this by using a strategy that we decided to call “AIC versioning”. AIC versioning uses a
week archiving strategy to create a preservation system agnostic strategy for preserving highly
versioned data. To asses the effectiveness of AIC versioning for preserving scientific data, we
present a case-study using sample data from Zenodo, a digital repository for research data. In this
case-study we compare the expected archive size with and without AIC versioning for a sample of
Zenodo data.
The third, and final, challenge is integrating the CERN Digital Memory Platform with existing
workflows. We investigate three options for managing and automating the transfer of content into
Archivematica: the automation-tools, the Archivematica API, and Enduro. For each option we
discuss the design philosophy and goals. After this we discuss how each of the alternatives can be
used to handle the workload for many different services using multiple Archivematica pipelines.
Finally we evaluate if the combination of a distributed Archivematica deployment, the AIC ver-
sioning strategy, and one of the workflow management solutions can be used as the central building
block of the CERN Digital Memory Platform. We want to know if this combination solves the
challenges and meets the requirements set for the CERN Digital Memory Platform. We also
want to know what problems are not addressed by the proposed solution. Ultimately we want to
understand if this is a viable strategy, or if an entirely different approach might be advised.
To summarise, the specific contributions of this thesis are:
• A literature study describing the evolution of the digital preservation field.
• A method for creating a scalable distributed Archivematica cluster.
• A strategy for handling the preservation and deduplication of versioned data.
• A comparison of existing Archivematica workload management systems.
The rest of this thesis has the following structure. Chapter 2 introduces digital preservation
concepts, the OAIS reference model, and existing digital preservation standards, tools, and systems.
Chapter 3 discusses some of CERN’s earlier preservation efforts and the requirements and high-level
architecture of the CERN Digital Memory Platform. Chapter 4 evaluates the base-line performance
of Archivematica and the performance of different storage platforms. Chapter 5 introduces the
distributed Archivematica deployment, discusses the required changes for efficiently using this
extra capacity, and evaluates the image and video processing capacity of Archivematica. Chapter
6 introduces the AIC versioning strategy and evaluates the influence of AIC versioning on the
required storage capacity in a case-study. Chapter 7 discusses several options for managing the
workload on one or multiple Archivematica pipelines and discusses possible solutions for integrating
Archivematica in the existing workflows. Finally, Chapter 8 evaluates the entire study.
9CHAPTER 1. INTRODUCTION 10
Chapter 2
Digital preservation
Putting a book on a shelve is not the same as preserving or archiving a book. Similarly, digital
preservation is not the same as ordinary data storage. Digital preservation requires a more elaborate
process than just saving a file to a hard disk and creating a backup. Digital preservation, just like
traditional preservation, can be described as a series of actions taken to ensure that a digital object
remains accessible and retains its value.
Within the digital preservation community, the Open Archival Information System (OAIS) refer-
ence model is the accepted standard for describing a digital preservation system. The reference
model clearly defines the roles, responsibilities, and functional units within an OAIS. The OAIS
reference model only defines actions, functionality, interfaces, and responsibilities. The model does
not supply an actual system architecture or implementation.
To create a better understanding of the digital preservation field and the existing literature, we
start with discussing some of the important digital preservation concepts and challenges. Next,
we discuss the goals of the OAIS model, provide an overview of the most important concepts and
terminology and discuss some common problems of the OAIS reference model. Finally, we provide
an overview of earlier work in OAIS compliant archives and discusses some of the past and present
digital preservation initiatives and projects.
2.1 Digital preservation concepts
There is not a single definition for digital preservation. Digital preservation is rather seen as a
continuous process of retaining the value of a collection of digital objects [8]. Digital preservation
protects the value of digital products, regardless of whether the original source is a tangible artefact
or data that was born and lives digitally [9]. This immediately raises the question of what is the
value of a digital collection and when is this value retained? The answer to these questions is: it
depends. Digital preservation is not one thing: it is a collection of many practices, policies and
structures [10]. The practices help to protect individual items against degradation. The policies
ensure the longevity of the archive in general. All practices, policies and structures combined is
what we call a digital preservation system: a system where the information it contains remains
accessible over a long period of time. This period of time being much longer than the lifetime of
formats, storage media, hardware and software components [11].
Digital preservation is a game of probabilities. All activities are undertaken to reduce the likelihood
that an artefact is lost or gets corrupted. There is a whole range of available measures that can
be taken to ensure the preservation of digital material. Figure 2.1 shows some measures in the
style of Maslow’s hierarchy of needs [12]. Each of these measures have a different impact, both in
robustness and required commitment. The measures can be divided into tow categories: bit-level
preservation and object metadata collection.
A vital part of preserving digital information is to make sure that the actual bitstreams of the
objects are preserved. Keeping archived information safe is not very different from keeping
“regular” information safe. Redundancy, back-ups and distribution are all tactics to make sure
11CHAPTER 2. DIGITAL PRESERVATION
Figure 2.1: Wilson’s hierarchy of preservation needs [12]. Each additional layer
improves the preservation system at the expense of more commitment of the
organisation. Depending on the layer, this commitment is primarily technical or
organisational.
that the bitstream is safe. One vital difference between bit-preservation and ordinary data storage
is that an archive needs to prove that the stored information is unchanged. This is done using
fixity checks. During a fixity check, the system verifies that a digital object has not been changed
between two events or between points in times. Technologies such as checksums, message digests
and digital signatures are used to verify a digital object’s fixity [13]. By performing regular fixity
checks the archive can prove the authenticity of the preserved digital material.
Another part of maintaining the integrity of the archive is to monitor file formats. Like any other
digital technology, file formats come and go. This means that a file format that is popular today,
might be obsolete in the future. If a digital object is preserved using today’s popular standard,
it might be impossible to open in the future. There are two mechanisms that can prevent a file
from turning into a random stream of bits: normalisation and migration. Normalisation is the
process of converting all files that need to be preserved to a limited set of file formats. These file
formats are selected because they are safe. This means that they are (often) non-proprietary, well
documented, well supported and broadly used within the digital preservation community.
Migration is the transfer of digital materials from one hardware or software configuration to
another. The purpose of migration is to preserve the integrity of digital objects, allowing clients
to retrieve, display, and otherwise use them in the face of constantly changing technology [14].
An example of migration is to convert all files in a certain obsolete file format to a different file
format. A common strategy for preserving the accessibility of files in a digital archive is to combine
normalisation and migration. Normalisation ensures that only a limited set of file formats need to
be monitored for obsolescence. Migration is used to ensure access in the inevitable case that a file
format is threatened with obsolescence.
The second category of measures in digital preservation is metadata collection and management.
It has been widely assumed that for (digital) information to remain understandable over time there
is a need to preserve information on the technological and intellectual context of a digital artefact
[11, 15, 16]. This information is preserved in the form of metadata. The Library of Congress
defines three types of metadata [17]:
12CHAPTER 2. DIGITAL PRESERVATION
Descriptive metadata Metadata used for resource discovery, e.g. title, author, or institute.
Structural metadata Metadata used describing objects, e.g. number of volumes or pages.
Administrative metadata Metadata used for managing a collection, e.g. migration history.
Metadata plays an important role in ensuring and maintaining the usability and the authenticity
of an archive. For example, when an archive uses a migration strategy metadata is used to record
the migration history. This migration history is used for proving the authenticity of the objects.
Each time a record is changed, e.g. through migration, the preservation action is recorded and
a new persistent identifier is created. These identifiers can be used by users to verify that they
are viewing a certain version of a record. This metadata is also helpful for future users of the
content, it provides details needed for understanding the original environment in which the object
was created and used.
To make sure that metadata is semantically well defined, transferable, and can be indexed it
is structured using metadata standards. Different metadata elements can often be represented
in several of the existing metadata schemas. When implementing a digital preservation system,
it is helpful to consider that the purpose of each of the competing metadata schemas is different.
Usually, a combination of different schemas is the best solution. Common combinations are; METS
and PREMIS with MODS, as used by the British Library [18]; or METS and PREMIS with Dublin
Core, as used by Archivematica [19].
METS is an XML document format for encoding complex objects within libraries. A METS file
is created using a standardised schema that contains separate sections for: descriptive metadata,
administrative metadata, inventory of content files for the object including linking information,
and a behavioural metadata section [20]. PREMIS is a data dictionary that has definitions for
preservation metadata. The PREMIS Data Dictionary defines “preservation metadata” as the
information a repository uses to support the digital preservation process. Specifically, the metadata
supporting the functions of maintaining viability, renderability, understandability, authenticity,
and identity in a preservation context. Particular attention is paid to the documentation of digital
provenance of the history of an object. [21]. Dublin Core [22] and MODS [23] are both standards
for descriptive metadata.
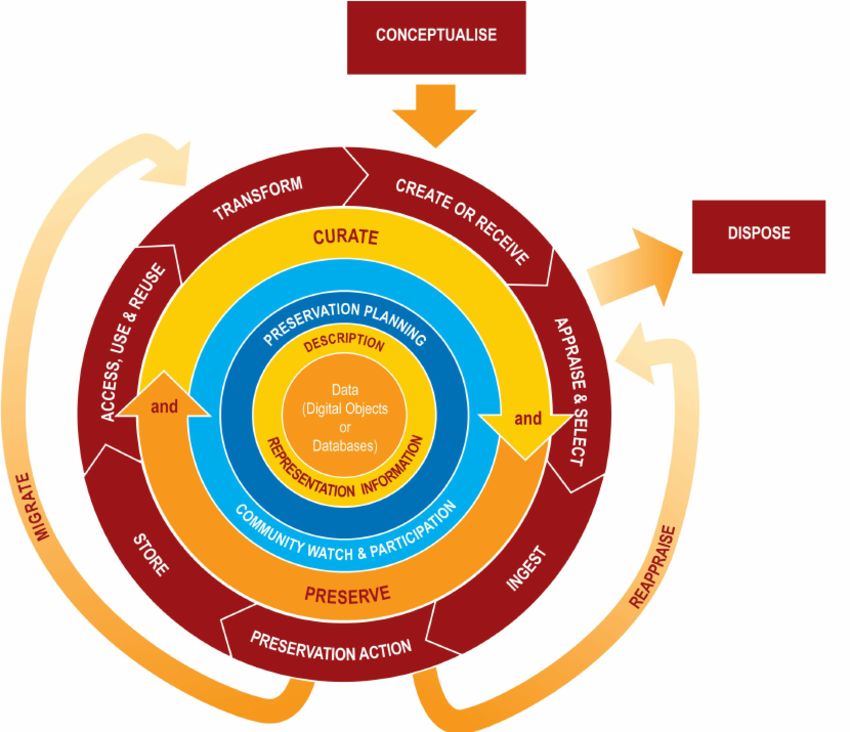
Figure 2.2: The DCC Curation Lifecycle Model [24]. High-level overview of the
lifecycle stages required for successful digital preservation. The centre of the model
contains the fundamental building blocks of a digital preservation system, the outer
layers display the curation and preservation activities.
13CHAPTER 2. DIGITAL PRESERVATION Both the British Library and Archivematica use METS as the basis for creating structured archival objects. The METS file contains all the different elements of the object and their relationships. The descriptive metadata is added to the METS file using a standard for descriptive metadata, in this case MODS or Dublin Core. All the other metadata like file formats, preservation actions, and rights data is added using PREMIS objects. Extending METS with PREMIS and other popular metadata standards is accepted practice within the digital archiving community. Other digital preservation systems use similar solutions, or slight variations, to structure their metadata. This combination of selection, enhancement, ingestion, and transformation are essential stages for the preservation of data. Figure 2.2 shows how all of these stages fit together in the DCC (Digital Curation Centre) Curation Lifecycle Model [24]. The model can be used to plan activities within an organisation or consortium to ensure that all necessary stages are undertaken. While the model provides a high-level view, it should be used in conjunction with relevant reference models, frameworks, and standards to help plan activities at more granular levels. 2.2 Open Archival Information System (OAIS) In 2005, the Consultative Committee for Space Data Systems (CCSDS), a collaboration of gov- ernmental and quasi-governmental space agencies, published the first version of a reference model for an Open Archival Information System (OAIS). The CCSDS recognised that a tremendous growth in computational power as well as in networking bandwidth and connectivity, resulted in an explosion in the number of organisations making digital information available. Along with the many advantages in the spread of digital technology in every field, this brings certain disadvantages. The rapid obsolescence of digital technologies creates considerable technical dangers. The CCSDS feels that it would be unwise to solely consider the problem from a technical standpoint. There are organisational, legal, industrial, scientific, and cultural issues to be considered as well. To ignore the problems raised by preserving digital information would inevitably lead to the loss of this information. The model establishes minimum requirements for an OAIS, along with a set of archival concepts and a common framework from which to view archival challenges. This framework can be used by organisations to understand the issues and take the proper steps to ensure long- term information preservation. The framework also provides a basis for more standardisation and, therefore, a larger market that vendors can support in meeting archival requirements. The reference model defines an OAIS as: “An archive, consisting of an organisation, which may be part of a larger organisation, of people and systems that has accepted the responsibility to preserve information and make it available for a designated community.” The information in an OAIS is meant for long-term preservation, even if the OAIS itself is not permanent. Long-term is defined as being long enough to be concerned with changing technologies, and may even be indefinite. Open in OAIS refers to the standard being open, not to open access to the archive and its information. The reference model provides a full description of all roles, responsibilities and entities within an OAIS. This section provides a quick introduction to the OAIS concepts and discusses some of the related literature required for understanding this research. It is not meant as a complete introduction to the OAIS reference model. Figure 2.3 shows the functional entities and interfaces in an OAIS. Outside of the OAIS there are producers, consumers and management. A producer can be a person or system that offers information that needs to be preserved. A consumer is a person or system that uses the OAIS to acquire information. Management is the role played by those who set the overall OAIS policy. All transactions with the OAIS by producers and consumers, but also within some functional units of the OAIS, are done by discrete transmissions. Every transmission is performed by means of moving an Information Package. Each Information Package is a container that contains both Content Information and Preservation Description Information (PDI). The Content Information is the original target of preservation. This is a combination of the original objects and the information needed to understand the context. The PDI is the information that is specifically used for preservation of the Content Information. There are five different categories of PDI data: references, provenance data, context of the submission, fixity of the content information, and access rights. 14
CHAPTER 2. DIGITAL PRESERVATION
Within the OAIS there are three different specialisations of the Information Package: the Submis-
sion Information Package (SIP), the Archival Information Package (AIP), and the Dissemination
Information Package (DIP). Producers use a SIP to submit information for archival in the OAIS.
Typically, the majority of a SIP is Content Information, i.e. the actual submitted material, and
some PDI like the identifiers of the submitted material. Within the OAIS one or more SIPs are
converted into one or more AIPs. The AIP contains a complete set of PDI for the submitted
Content Information. Upon request of a consumer the OAIS provides all or a part of an AIP in
the form of a DIP for using the archived information.
For performing all preservation related tasks, the OAIS has six functional entities. Since this is
just a reference model it is important to note that actual OAIS-compliant implementations may
have a different division of responsibilities. They may decide to combine or split some entities
and functionality of the OAIS, or the OAIS may be distributed across different applications. The
functional entities, as per Figure 2.3, are:
Ingest Provides the services and functions to accept SIPs and prepares the contents for storage
and management within the archive. The two most important functions are the extraction
of descriptive metadata from the SIP and converting a SIP into an AIP.
Archival Storage Provides the services and functions for the storage, maintenance, and re-
trieval of AIPs. Important functions are managing storage hierarchy, refreshing media, and
error checking.
Data Management Provides the services and functions for populating, maintaining, and ac-
cessing descriptive information and administrative data. The most important function is to
manage and query the database of the archive.
Administration Provides services and functions for overall operation. Important functions
include the auditing of archived material, functions to monitor the archive, and establishing
and maintaining of archive standards and policies.
Preservation Planning Provides services and functions for monitoring the archive. The main
function is to ensure accessibility of the information in the archive.
Access Provides the services and functions that support consumers in requesting and receiving
information. The most important function is to create DIPs upon consumer requests.
Even though the OAIS reference model has been regarded as the standard for building a digital
archive, it has received criticism. In 2006 the CCSDS conducted a 5-year review of the OAIS
reference model [26]. This review covers most of the shortcomings that are also identified in
independent literature, but so far the CCSDS has not been able to successfully mitigate these.
Figure 2.3: Functional entities in an OAIS [25]. The diagram shows the three users
of the OAIS and how they interact with the system. The lines connecting entities
(both dashed and solid) identify bi-directional communication.
15CHAPTER 2. DIGITAL PRESERVATION One of the points in the CCSDS’ review is the definition of the designated community. The user base of an OAIS is often broader than just the designated community. For example, at CERN the designated community for physics data would be the scientists at the experiments. But the data is also of interest for non-affiliated researchers and students across the globe. A second problem are the responsibilities of the designated community. The reference model forces digital preservation repositories to be selective in the material they archive. For institutions with ethical or legal mandates to serve broad populations, like national libraries, there is a fundamental mismatch between the mission of the institutes to preserve all cultural heritage and the model [27]. During the review, the CCSDS investigators found that the OAIS model has a clashing terminology mapping between PREMIS and other relevant standards that needs to be reviewed. Nicholson and Dobreva even suggest a complete cross-mapping between the reference model and other preservation standards [28]. The main reason for this is that because of the conceptual nature of OAIS there are many ways of implementing the standard. For example, during the review of OAIS as a model for archiving digital repositories, Allinson concluded that the OAIS reference model simply demands that a repository accepts the responsibility to provide sufficient information [29]. The model does not ask that repositories structure their systems and metadata in any particular way. As a response to this shortcoming Lavoie et al. developed an OAIS compatible metadata standard [30] and Kearney et al. propose the development of special standards and interfaces for different designated communities [31]. The OAIS standard does not specify a design or an implementation. However, the CCSDS reviewers found that the model is sometimes too prescriptive and might constrain implementation. They conclude that: “there needs to be some re-iteration that it is not necessary to implement everything.” and that “the OAIS seems to imply an ‘insular’ stand-alone archive”. In his seminal article, Rethinking Digital Preservation, Wilson arrives at a similar conclusion and calls for a revision of the OAIS model. According to Wilson the revised OAIS reference should include explicit language that clearly reflects an understanding that a multi-system architecture is acceptable and that a dark archive model can be compliant [12]. According to Wilson several challenges arise when the reference model is taken too literally. It is easy to conclude that an OAIS is a single system. If this was true for the OAIS reference model, it would violate a foundational principle of digital preservation: avoid single points of failure. To avoid misinterpretations like this, a digital preservation framework would be needed. This framework could provide an interpretation of the OAIS standard and can provide fundamental building blocks for building an OAIS [12, 28]. In their 5-year review the CCSDS recognises this problem. They argue that the standard should provide supplementary documentation for full understanding. Examples include detailed checklists of the steps required for an implementation and best practice guides. Extending the standard with a stricter implementation should prevent a proliferation of supplementary standards, frameworks, and implementations – providing much needed clarity for both system designers and users. 2.3 Digital preservation systems The late nineties saw a rapid increase in the creation and adoption of digital content. Archivists and librarians warned that we were in the midst of a digital dark age [32, 33, 34]. This initiated a debate on how to preserve our digital heritage. In 1995, the CCSDS started a digital preservation working group and began the development of a reference model for an OAIS. At the same time Stanford created LOCKS: Lots of Copies Keep Stuff Safe. The main idea behind LOCKS was that the key to keeping a file safe is to have lots of copies. LOCKS uses a peer-to-peer network for sharing copies of digital material. Libraries keep the digital materials safe in exchange for access. LOCKS was initially designed for preserving e-journals, but is used for preserving web content around the world [35]. A LOCKS network is built using LOCKSS boxes, a LOCKSS box is a server running the LOCKS daemon. Each box crawls targeted web pages and creates a preservation copy. Other LOCKSS boxes subscribe to this content and download copies. The copies are checked for defects by comparing hashes via a consensus protocol. LOCKS is an effective system for the cost effective bit preservation of web pages. However, LOCKS is very limited in the types of materials it can preserve and has no active preservation policies. 16
CHAPTER 2. DIGITAL PRESERVATION
In 2003, the Florida Center For Library Automation (FCLA) began development on DAITSS,
the Dark Archive In The Sunshine State [36]. In contrast to LOCKS, DAITSS uses an active
preservation policy. The archive is made of two parts: DAITSS and the FCLA Digital Archive
(FDA). DAITSS is a toolkit that supports the digital archiving workflow. It provides functions
for ingest, data management, archival storage, and access. The FDA is the storage back end: a
tape-based dark archive with a selective forward migration preservation policy [37]. Building a
dark-archive saves costs on both storage and the development and maintenance of access systems.
The FDA offers two levels of preservation. For any file format the FDA ensures bit-level preserva-
tion. For a selection of popular file formats the FDA offers full digital preservation. This is ensured
by creating a preservation plan for each of the supported file formats. These preservation plans
describe the migration strategy for the file format and ensure long time access to the content. The
FCLA has been using DAITSS in high volume production since late 2006. From late 2006 to June
2011, the FDA has held 87 TB of data consisting of 290,000 packages containing 39.1 million files
with an average ingestion rate of 4-5 TB per month. In 2010, DAITSS was released to the public,
but as of 2020 the repositories and website are offline. This is a result of FCLA decommissioning
DAITSS and the FDA in December 2018.
Another preservation effort is SPAR, the Scalable Preservation and Archiving Repository [38].
SPAR was developed by the Bibliothèque Nationale de France and taken into production in 2006.
The archive is designed to preserve a digital collection of 1.5 PB. The central concept in SPAR is
a preservation track. A track is a collection of objects that require the same set of preservation
policies. Each track consists of multiple channels. A channel is a collection of objects require
similar treatment. Every track has a Service Level Agreement, a machine actionable document
that describes the process for preserving transmissions for that track.
SPAR only guarantees bit-level preservation. The added benefit of SPAR is in the metadata
management, it uses a global graph that contains all metadata of all ingested objects. This graph
is modelled using a Resource Description Framework (RDF). Each ingested object has an XML-
based METS file, this file is deconstructed in triplets that are added to the RDF. The resulting
graph can be queried, for example: which packages have invalid HTML tables; or which packages
are flagged as having a table of contents, but do not have a table of contents entry in the METS?
The main problem with the metadata graph is scalability. During testing the researchers found that
the RDF could handle approximately 2 billion triples, but only a single channel of the collection
already contains 1 billion triples.
Around this time, more and more archives started looking into digital preservation. Out of
necessity, the Burritt Library of the Central Connecticut State University, started investigating
a digital preservation system. “We realised the need for a digital preservation system after disc
space on our network share ran out due to an abundance of uncompressed TIFF files” [39]. The
main goal of the preservation project was to store 5 TB of data in a reliable and cost-effective
way. Burritt compared the costs of using an off-the-shelf digital preservation, with running their
own Windows Home Server with backups to Amazons S3 file service. They found that running
their own custom service was about 3 times less expensive as using the off-the-shelf preservation
solution. Storing 5 TB a year using their solution costs roughly 10,000 dollars a year instead of
30,000 dollars. The final solution is quite simple: a Windows Home Server with a MySQL database
and some custom scripts.
The 2000’s showed an increased interest in solving the problems of digital preservation. Many
institutes started to develop tools and systems to help preserve our digital heritage. A problem with
this approach was that the individual initiatives were not coordinated and people often reinvented
the wheel. In 2006, a consortium of national libraries and archives, leading research universities and
technology companies, co-funded by the European Union under the Sixth Framework Programme,
started a project called Planets: Preservation and Long-term Access through Networked Services.
The goal of the project was to create a sustainable framework that enables long-term preservation
of digital objects [40]. Planets most important deliveries are: an interoperability framework for
combing preservation tools and an environment for testing [41], migration tools and emulators [42],
and a method for evaluating and creating a preservation strategy [43].
In 2010, after evaluating the digital preservation market, the Planets project published a white
paper [44]. The authors concluded that the market was still in its infancy, but that the engagement
17CHAPTER 2. DIGITAL PRESERVATION of both the public and private sector was growing rapidly. Many organisations did not have a comprehensive digital preservation plan, or none at all. Budgets for digital preservation were often short-term or on a project basis. Furthermore, institutes said that standards were vital but that there were too many. Ruusalepp and Dobreva [45] came to similar conclusions after reviewing 191 digital preservation tools. A vast majority of these tools were a result of short-term research projects, often published as an open-source project without any support and incomplete documentation. However, together with an increased interest in cloud-computing and Software As A Service (SaaS), they saw a shift towards a more service-oriented model for digital preservation. Over the last couple of years the digital preservation community has been moving towards a more holistic approach on digital preservation. One of the common criticisms on the OAIS reference model is that it is too conceptual. Practitioners have been asking for a reference architecture for preservation services. In 2013, the European commission started the 4 year E-ARK project. The goal of this project was to provide a reference implementation that integrated non-interoperable tools into a replicable and scalable common seamless workflow [46]. The project mainly focused on the transfer, dissemination and exchange of digital objects. For each of these stages of the preservation cycle, the project analysed and described use-cases and created standards, tools and recommended practices. Preservation planning and long-term preservation processes were outside the scope of the E-ARK project. The E-ARK project developed a custom SIP, AIP and DIP specification and tools to create, convert and inspect these packages. The E-ARK project also delivered three reference implementations for integrated digital preservation solutions: RODA [47], EARK-Web [48], and ESSARch [49]. During the evaluation of the E-ARK project, participants said that the project has made a significant impact on their institutions [50]. Highlights of the project include: major savings in costs, benefits of using the EARK-Web tool, and robust common standards that can be used across Europe. The participants feel that to maintain these benefits the project needs long-term sustainability. This is achieved by publishing the E-ARK results as part of the CEF eArchiving building block. The aim of eArchiving is to provide the core specifications, software, training and knowledge to help data creators, software developers and digital archives tackle the challenge of short, medium and long-term data management [51]. In early 2010 there was another initiative to create a fully integrated, OAIS-compliant, open source archiving solution: Archivematica. Archivematica was originally developed to reduce the cost and technical complexity of deploying a comprehensive, interoperable digital curation solution that is compliant with standards and best practices [19]. Later, Archivematica was extended to support scalability, customisation, digital repository interfaces and included a format policy implementation [52]. Over the years Archivematica has extended their functionality and user-base considerably. In 2015, the Council of Prairie and Pacific University Libraries (COPPUL) created a cloud-based preservation service based on Archivematica [53]. Users can choose between three different levels of service. All levels include hosting and training, the main difference is in the available preservation options and the size of the virtual machine used for hosting the service. The results of the pilot were mixed. Most of the participating institutes did not have a comprehensive digital preservation policy. The lack of a framework for preservation policies required the institutes to allocate more staff to the project than expected, but this was not necessarily bad. The project did allow the participants to experiment with digital preservation, without having to invest a lot upfront. To this date, COPPUL still offers the Archivematica service indicating adoption by the participating institutes. Five collaborating university libraries in Massachusetts started a similar project. The libraries felt that digital preservation was not well understood by single institutes and that they lacked the resources to do it individually. In 2011, they formed a task force to collaboratively investigate digital preservation. By 2014, they had decided to run a pilot using Archivematica [54]. During the pilot period of 6 months, each institute used a shared Archivematica instance to focus on their own research goals, sharing their findings as they went along. The pilot did not result in a concrete preservation system: it provided the institutes an insight into how “ready” they were for digital preservation. A similar pilot in Texas resulted in the founding of the Texas Archivematica Users Group (A-Tex), a group of Texas universities that are either evaluating Archivematica or already using it. In 2018, 4 members were using Archivematica with archives ranging in size between 1 and 12 terabytes [55]. 18
CHAPTER 2. DIGITAL PRESERVATION
Figure 2.4: Timeline of digital preservation standards, projects, tools and systems.
The ? indicates the publication of a standard. Every bar corresponds with a longer
running project that is discussed in this study. The dotted lines indicate a shift of
focus in the research activities.
In 2014, the Bentley Historical Society and the University of Michigan received to create a fully
integrated digital preservation workflow [56]. They selected Archivematica to be the core of the
workflow. During the pilot they used Archivematica to automatically deposit 209 transfers. The
archived content had a total size of 3.6 terabytes and contained 5.2 million files. The average
transfer size was 7.2 gigabytes, and 6.7% of the transfers made up 99% of the total archive. Their
Archivematica instance was a single virtual machine with 4 cores and 16 GB of RAM. The project
was very successful, and the Bentley Historical Society is using Archivematica to the present day.
Between 2015 and 2018 Artefactual, the maintainers of Archivematica, and Scholars Portal, the
information technology service provider for the 21 members of the Ontario Council of University
Libraries, collaborated on integrating Dataverse and Archivematica [57]. Scholars Portal offers
research data management services via Dataverse, and digital preservation services via Archive-
matica to their members. The Dataverse-Archivematica integration project was undertaken as a
research initiative to explore how research data preservation aims might functionally be achieved
using Dataverse and Archivematica together. In 2019 the integration was finished and a pilot phase
started. During the pilot phase user feedback is gathered, this feedback is used to improve the
integration and to contribute to the ongoing discussion surrounding best practices for preserving
research data.
Looking at the development of the digital preservation field in Figure 2.4, we can clearly identify
three different periods. Initially, the field was focused on understanding the problem and escaping
the digital dark age. In this phase the focus was primarily directed at developing standards. After
this, the focus gradually moved towards solving the identified problems. In this phase a lot of
individual initiatives were started and many preservation tools and projects were developed. The
third, and last, phase was less focused on solving individual problems and more on creating systems.
In every step the field was gaining collective experience and the maturity of the solutions increased.
One theme that is apparent in all phases is that the research is mainly focused on the what, and
less on the how. More often than not, only the higher level architecture of systems is described.
Performance and scalability are mentioned as important factors, but they are only mentioned and
almost never qualified. This makes it hard to identify at what scale the preservation systems are
evaluated and if they are suitable for large-scale digital preservation.
19CHAPTER 2. DIGITAL PRESERVATION 20
Chapter 3
CERN Digital Memory Platform
From the very beginning, CERN was aware of the importance of their research. During the third
session of the CERN Council in 1955, Albert Picot, a Swiss politician involved in the founding of
CERN, said:
“CERN is not just another laboratory. It is an institution that has been entrusted with
a noble mission which it must fulfil not just for tomorrow but for the eternal history of
human thought.”
The fundamental research that is performed at CERN, is to be preserved and shared with a large
audience. This is one of the reasons CERN has been maintaining an extensive paper archive since
the 1970s. However, with the ever growing production of digital content a new archive is needed,
a digital archive.
Building a shared digital archive at CERN scale is not without challenges. CERN is a collaboration
consisting of more than 17,500 researchers from 600 collaborating institutes. The research at
CERN covers many aspects of physics: computing, engineering, material science, and more. A
collaboration at this scale requires a diverse set of information systems to create, use, and store
vast amounts of digital content. Preserving CERN’s digital heritage means that each of these
systems should be able to deposit their material in the digital archive.
To provide the historical context for the CERN Digital Memory, we start with discussing the past
digital preservation initiatives at CERN and the need for creating the CERN Digital Memory
Platform. Next, we examine the system requirements and discuss the goals and non-goals of the
platform. Finally, we introduce the high-level architecture of the CERN Digital Memory platform.
We explain why we decided to use Archivematica as the core of the platform, we discuss what kind
of functionality is provided by Archivematica, what functionality is not provided, and what are
some of the concerns that need to be addressed.
3.1 Digital Preservation at CERN
As early as the late nineties CERN started to investigate digital preservation. In 1997 CERN
started the LTEA Working Group [58]. This group was to: “explore the size and the typology of
the electronic documents at CERN [and] their current status, and prepare recommendations for an
archiving policy to preserve their historical and economical value in the future.”
The main recommendations of the working group included: selective archiving of e-mail, archiving
of the CERN Web, defining a document management plan, and prevent the loss of information
due to format migration or otherwise. The working group decided to postpone the creation of a
digital archive. At the time the operational costs were too high, but it was expected that the costs
would rapidly decrease in the near future.
In 2009, CERN and other laboratories instituted the Data Preservation in High Energy Physics
(DPHEP) collaboration. The main goal of this collaboration was to coordinate the effort of the
laboratories to ensure data preservation according to the FAIR principle [59]. The FAIR data
21CHAPTER 3. CERN DIGITAL MEMORY PLATFORM principles state that data should be: Findable, Accessible, Interoperable and Reproducible. This collaboration let to several initiatives to preserve high energy physics data. Examples include: CERN Open Data for publishing datasets [60], CERN Analysis Preservation for preserving physics data and analysis [61], and REANA for creating reusable research data analysis workflows [62]. CERN’s most recent project is the Digital Memory Project [6]. This project contains an effort to digitise and index all of CERN’s analogue multimedia carriers. The main goal of this effort is to save the material from deterioration and to create open access to a large audience by uploading all digitised material to the CERN Document Server (CDS). CDS is a digital repository used for providing open access to articles, reports and multimedia in High Energy Physics. Together with CERN Open Data, CERN Analysis Preservation, REANA and, Zenodo CDS is one of many efforts of CERN to build digital repositories to facilitate open science. The original CERN convention already stated that: “the results of [CERN’s] experimental and theoretical work shall be published or otherwise made generally available” [63]. But in the spirit of Picot’s words: sharing the material today is not enough, it needs to be available for the eternal history of human thought. Previous preservation efforts have mainly been focused on identifying valuable digital material and bit prevention. The LTEA and DPHEP projects recommended bit preservation for high energy physics data. In the case of widely used, well documented physics datasets this might be sufficient. But bit preservation only ensures that the actual data stays intact, it does not preserve the meaning of the data. Each of these preservation efforts have helped to identify a large amount of digital artefacts that need to be preserved for future generations, but with no clear plans to achieve this. One fundamental question which remains unanswered is how to preserve digital artefacts for future generations? The longer CERN waits to answer this question, the longer the preservation backlog gets. This increases the initial costs and effort of creating a digital archive, and more importantly, increases the risk of losing content forever. To solve the problem for all preservation efforts and the numerous information systems within CERN a catch-all digital archiving solution is needed. Building an institutional archive, will allow each information system to preserve relevant content with minimum effort. 3.2 Requirements It is CERN’s public duty to share the results of their experimental and theoretical work, this requires trustworthy digital repositories. A trustworthy repository has “a mission to provide reliable, long-term access to managed digital resources to its designated community, now and into the future” [64]. Part of a trustworthy digital repository is an OAIS compliant preservation system. Part of the trust and confidence in these systems is provided by using accepted standards and practices. To provide a similar level of trust and confidence for CERN’s digital repositories, the Digital Memory Platform should, wherever possible, be based on accepted standards and practices. The key to the design of any digital preservation system is that the information it contains must remain accessible over a long period of time. No manufacturer for hardware or software can be reasonably expected to design a system that can offer eternal preservation. This means that any digital preservation platform must anticipate failure and obsolescence of hardware and software. As a result, the Digital Memory Platform as a whole should not have a single point of failure, should support rolling upgrades of hardware and software, and should monitor and verify the viability of the preserved material. The main focus of the Digital Memory Platform is on reducing the long-term fragility of preserved material. Central to this is an active migration policy. This means that the platform should monitor all file-formats in the archive for obsolescence and apply preservation actions where necessary. The dissemination activities, as described in the OAIS reference model, are outside the immediate scope of the platform. The material is primarily made available to the designated community via the original information systems. CERN has to preserve the contents of an extensive digitisation project – comprising of photos, videos and audio tapes – as well as born digital content from different information systems such as the CERN Document Server, CERN Open Data, Inspire, and Zenodo [65]. This large variety in information systems and possible types of material, requires the archiving platform to have no 22
You can also read

















































