A Proposal for An Agent that Plays 7 Wonders
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
A Proposal for An Agent that Plays 7 Wonders
Ben Gardiner
Willamette University
November 27, 2012
Abstract
In the ever-growing field of artificial intelligence and machine learn-
ing, we utilize simplified models for complex sets of decisions as forums
to measure the efficiency and overall ’intelligence’ of the program.
One such set of modeling systems is board games, for which there
are clearly a series of complex decisions that interact with each other
to form a strategy. Furthermore, the outcome of the game provides
a decisive metric for determining the performance of the agent play-
ing it. In this literature review, we examine the research performed
on strategic games that are inaccessible and non-deterministic, or in-
volve imperfect information about game state and include elements of
chance. We propose an agent that plays the game 7 Wonders based
upon the techniques used here.
Keywords: Artificial intelligence, board games, Imperfect information,
Game Theory
1 Introduction
Artificial intelligence is a constantly growing area of interest because increases
in computing power lead to more questions that can be answered. We will
explore the applications of artificial intelligence with regard to board games,
specifically the game 7 Wonders. This will further the field of artificial intelli-
gence because 7 Wonders is a complex game with multiple strategies relevant
to any given scenario. Thus, it provides a model for complex decisions that
1occur in real-world applications of artificial intelligence, such as programming
of robots that need to perform intricate tasks unsafe for humans.
In this paper, we propose a project to develop an agent to play 7 Wonders
in a way that defeats most human opponents. We will begin by implementing
a heavily abridged version of the rules of the game, then creating an agent
for it. Once the agent has achieved a reasonable level of proficiency with
the abridged rules, we will add elements back into the game, and observe
how the agent adapts, potentially with additional programmatic help. This
is detailed to a greater extent in section 4. In section 2, we define necessary
terms and review existing research done on board games, then, in section 3
we summarize the rules of 7 Wonders. We finish the paper in section 5 with
rough timeline for anticipated progress.
2 Existing Work
In the field of artificial intelligence, we utilize an agent-environment model
to simulate the complex decisions that a program needs to make. One set of
models is board games, because there are many varieties of games that can
create composite decision trees. We will begin by defining the terms needed
to discuss artificial intelligence, then examine existing research that has been
done in board games, starting with games simple enough to be solved, and
finishing with a newly emerging “uro-style” of board games, with many more
rules and components than traditional, more popular varieties.
2.1 Background
Following the example set by [6], we will define an artificial intelligence to
be a rational agent acting in a suitable environment.
An agent is an entity, such as a board game player, that perceives infor-
mation, and acts based upon that information. A rational agent is one whose
actions logically follow from the information that it has perceived, and acts
in a manner deemed correct [6]. So in the case of our agent being a game
player, a rational agent is one whose actions, or plays, are always performed
to help win the game.
To measure the rationality of an agent, or the correctness of its actions,
we define a performance measure as a means of determining the efficacy of
a given agent for a specific task [6]. Our performance measure is simple,
2whether or not the agent wins the game. For games with more than two
players, we can measure relative performance to the other players, so an
agent does adequately if it consistently gets second place out of a total of
four players.
Then, we must define a series of properties an environment can have, to
specify the problem that the agent is attempting to solve. An environment
can be:
• Fully or partially observable: Can the state of the environment be com-
pletely determined by observation, or is there hidden information?
Games such as checkers or chess are fully observable, because there is
no information, but games like poker are imperfect information games,
or partially observable, in that there is information that a player’s op-
ponents have that the player does not.
• Single agent or multi-agent: Is the state of the environment determined
by other agents in addition to the one we are programming? In game
terms, is it a solitaire or multiplayer game?
• If an environment is multi-agent, is it Competitive or Cooperative: Al-
ternately, are the agents working towards a common goal, or do they
have individual agendas?
• Deterministic or Stochastic: An environment is deterministic if the eval-
uation of its next state can be fully ascertained based upon its current
state and the agent’s action. It is stochastic if otherwise.
[6]
It is clear that board games provide a very easy model for which to
emulate environments, because there many complex board games fill each of
these categories.
We see that we can formally classify an artificial intelligence problem
based upon the type environment. Furthermore, it is clear that we can use
games to model these systems. In our next section, we discuss existing work
that has been done in the field of artificial intelligence with board games.
2.2 Literature Review
We begin this section by examining known solved games, such as checkers,
and what they have in common. We will then look at other families of games,
3such as poker, or the recently emerging euro-games genre.
2.2.1 Solved Games
Some games have been studied to the point that artificial players can con-
sistently beat human opponents, even at the level of grand master or world
champion. While these games are no longer interesting for study, they are
useful as points of reference for the development of the field. We will utilize
the game-theoretic definitions for the term “solved game,” where a game has
been solved if its game-theoretic value can be computed for the initial po-
sition and a strategy can be devised for that game-theoretic value [10]. If
a game is solved, the idea of developing an intelligent player is trivialized,
because there are known rules for devising a strategy.
According to [10], there is a family of games known as convergent games,
“where the size of the state space decreases as the game progresses.” This
leads to the set of end moves being small enough that it can be categorized
in a database. These games have been solved to the extent that the solu-
tion space is searchable via brute force methods, using a technique known
as retrograde analysis. This method, also known as the mini-max algorithm,
consists of beginning at a desired end state, and working backwards to gener-
ate the sequence of moves, acting under the assumption that opponents will
make the best move for them [6, 11]. This list includes Nine Men’s Morris,
mancala games, checkers, all of which are fully detailed in [10].
The other family of games examined in [10] is divergent games, ones that
do have a finite set of endgame states, so databases cannot be generated. The
methods for solving these games are either search-based or knowledge-based.
A common theme among these solved games is that all of them are fully
observable, two-agent, and deterministic, and therefore, according to [7],
are “easy” to program. This gives us several specific fields to expand the re-
search; we can examine non-deterministic, n-agent (n greater than 2), and/or
partially observable games, which is our task in the next section.
2.2.2 Stochastic Games
Fully Observable Games We briefly mention backgammon, which is fully
observable but stochastic because of the nature of the dice rolls that generate
moves. However, in 1979, a backgammon player defeated the then world
champion [2]. The backgammon agent, known as TD-gammon, simply plays
4against itself and learns from results, and was still considered to be a top tier
player in 1994, after several years where human players improved their play
[?]. It is clear that backgammon and other observable, stochastic games like
it could be programmed simply. It is clear that observable, two-agent games
are no longer interesting for artificial intelligence results.
Partially Observable Games One of the early attempts in partially ob-
servable games was a partner-Dominoes player, first published in 1973 [8].
The authors of the article detail the challenges of imperfect information, re-
sulting from the way that at any time, there is a set of unknown dominoes
in opponents’ and partner’s hands, and they begin defining a strategy based
upon probabilistic analyses. While this work is rather rudimentary, it lays a
foundation for the later works we will discuss.
Poker is an interesting game to model with artificial intelligence, because
of the stochastic and unobservable nature of the game and deception of oppo-
nents being a necessary component of skilled play. This requires algorithms
to model and understand opponents, as a part of formulating a strategy,
because there are many approaches to playing to win, that depend largely
on the person playing [3]. Billings et. al, examine the opponent modeling,
and selective sampling needed to create a skilled automated poker player. In
[3], once a poker player has been described, the authors proceed to explain
why this approach cannot be easily generalized to other non-deterministic
games. They observe that there are a variety of important factors, so the
initial goals of the intelligent agent and its performance measure could vary,
depending upon what the designer wishes to accomplish [3]. This is largely
what makes most games interesting to human players, because there are
many useful strategies to attempt, so any game is an intellectual exercise.
Euro-Games Finally, we will examine more recent research in a genre of
games known as euro-games, where there is a complex set of rules and playing
components, often including pieces or different types of cards. In 2009, Szita
et al. created an agent for the game Settlers of Catan, using Monte Carlo
tree search [9]. While their agent was not as successful as they hoped, the
authors noted that success was more probable with a well-defined heuristic
function, and concluded that Monte Carlo Tree search is viable for other
multiplayer games of similar complexity [9].
A similar Monte Carlo method was used in [5], to create an agent just for
5the initial part of determining territories (drafting) in the game Risk. Gibson
et al. use the UCT Monte Carlo method combined with a “machine-learned
evaluation function” to make quick draft picks, and conclude that the two
combined form an effective computational approach.
One of the quintessential complex age in the modern board game era is
Dominion. Fynbo et al. provide a first documented and published imple-
mentation of an agent that plays Dominion in [4]. They conclude that the
game is complex enough that it requires several different rational agents for
various aspects of the game including one for measuring the overall progress
of the game. While their agent is largely unsuccessful in the playing of cards,
they observe that their artificial neural network using back-propagation is
very skilled at determining the state of the game, which, for human players,
is a more intangible form of the strategy. Finally they demonstrate that two
techniques previously not attempted for complex games work with a high
success rate [4].
2.3 Conclusion
We note that programming board games is a useful field in artificial intelli-
gence research, because there are games for each possible environment. Then,
we examine games that have been researched exhaustively, all of which are
fully observable. The problem of examining partially observable games has
been investigated in a variety of ways, including cooperative dominoes, poker,
and the recently emerging Euro-games. While there has been a great deal
of research into traditional or more popular games such as chess, checkers,
or even poker, the Euro-games have seen much less formal exposure, largely
because they are a recent development in the gaming community. We have
found that a small number of Euro-games have been formally examined, with
no unifying ideas or approaches with regards to complex, multi-agent, par-
tially observable stochastic games, but much more research remains to be
done. We propose an implementation of an agent that plays a game not yet
documented, with new approaches examined.
3 Game Rules
The game 7 Wonders is structured in the form of 3 drafts. A draft is a
process where a pool of cards is distributed evenly among each player, seven
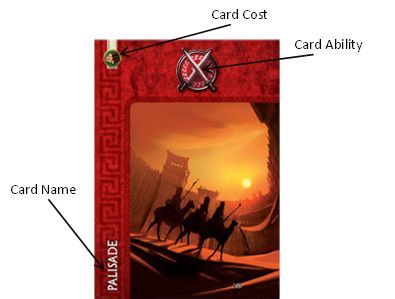
6(b) Victory Points
(a) Sample card from 7 Wonders
cards per player to start, and each player selects a card and then passes the
remainder of their cards to the player on their left. Then, once everybody
has selected a card, they play it in one of three ways, fully detailed in [1].
Each card has a cost, a name, and an ability, see figure 1a.
In order to play the card, the player must be able to produce the resources
depicted in the cost, that is have enough cards that generate each resource
as their ’ability’ so that each resource in the cost is generated. An alternate
means of obtaining resources is purchasing them, for two coins, from the 2
players on either side of the current player, known as the neighbors. For
example, in figure 1a, a player needs to be able to produce at least one
resource of the “wood” type, shown in the upper left-hand corner of the
card.
Alternately, if one does not want or is unable to play the card, they may
build a stage of the “wonder,” which is similar to playing a card, in that a cost
must be paid. However, the stages of the wonder are unique to each player,
and also are public information. One builds the next stage of the wonder by
paying the cost shown, and then sliding the card face-down underneath the
corresponding wonder stage.
The final option for playing a card is to sell it, face down, for three coins,
which can be used to purchase resources from one’s neighbors.
Thus, when selecting a card, there are factors of how useful it will be
in the future, and what its immediate impact are. When every player has
selected and played a card, they pick up the set of cards passed by the
player to their right, and the process repeats. Therefore, the game follows
a simultaneous play paradigm. When the game finishes, the players count
7their victory points, denoted with the symbol in 1b.
The player with the most victory points wins the game. An agent for
the game will need to be able to select cards based upon what it has already
played, and what potential cards are coming in the future. It must be able
to evaluate its current points, its potential points given its progress, and
speculate on expected values of cards at the end of the game.
There are several types of cards. At an abstract level, these can be de-
scribed as cards that provide resources, cards that produce victory points,
and cards that offer economic benefit in terms of commerce with other play-
ers.
4 Proposal
We propose to develop an agent to play 7 Wonders. We will begin by im-
plementing the rules of the game using an object-oriented language such as
Java. For example, there will be a ’card’ abstract class holding basic infor-
mation, with each type of card extending it. Also, there will have to be a
player class, and classes for several other pieces of information. Then, the
agent will interact with the rest of the game through an extension of the
player class.
The agent for 7 Wonders will largely build upon skills acquired in the Ma-
chine Learning course. Techniques that we used in this course can be easily
extended to implementing the game rules, and then developing a framework
of interaction between the agent and player. Furthermore, the course pro-
vided an introduction to the types of machine learning algorithms necessary
for developing an intelligent, game-playing, agent.
Our current plan is to use the Monte-Carlo tree search method, which
constructs a ranked tree of potential future game states based upon the cur-
rent one, and then ranks them according to a judged value. There are several
steps involved, fully detailed in [cite sources here]. However, we need to learn
more details of this approach, and several others, before making a final de-
cision in implementation. This is the current largest roadblock, the bulk
of the technical topics still needed to learn, because the Monte-Carlo tree
search method was selected from brief survey of artificial intelligence tech-
niques. Once we have fully familiarized ourselves with the details necessary,
then we will be able to fully exploit them to the advantage of the project. We
will begin by designing an abridged version of the rules, with a small subset
8of types of cards. Once we have implemented this condensed version of the
game, we will begin designing and implementing an agent for it. An initial
goal, or milestone, would be a competent agent with the smallest version of
the game. Then, we would select 1 rule to add, to minimalize complexity,
and redesign the artificial intelligence. Depending upon how simplified the
rules are, there are several sets of potential deliverables, each corresponding
to a different iteration of the game rules and the agent that can play with it.
Our final, stretch goal is to have the agent developed with the full rules con-
sistently win eighty percent of its games with human opponents. However,
we are not anticipating this much success. We anticipate sacrifices either on
the win rate, or on how much of the game that we develop.
In our first version of the rules of the game, we propose to ignore the
stages of the wonder, and the ability to purchase resources from opponents.
Cards can still be sold for coins, simply as an alternative if one is unable to
play the card. In our second stage of the rules, we will add the ability to
purchase resources from the neighbors. In the third version of the rules, we
propose to add the ability to build the wonder, in addition to an ability to
play certain cards for free.
If the full rules of the game are developed, and we have an agent that
plays to our satisfaction, then we will have gone far above what we expected.
In this case, we will develop a visual and interactive user interface that makes
it very easy to play against.
5 Timetable
Date Deliverable
14-Jan First Day of Classes
31-Jan Initial game rules implemented
14-Feb Agent for initial rules completed
28-Feb Second iteration of rules implemented
14-Mar Second Agent Implemented
28-Mar Third Rules Version
11-Apr Third Agent Implemented
17-Apr SSRD
5-May Final Deadline
9References
[1] Antoine Bauza. 7 wonders game rules, 2010.
[2] H.J. Berliner. Backgammon computer program beats world champion.
Artificial Intelligence, 14(2):205–220, 1980.
[3] Darse Billings, Aaron Davidson, Jonathan Schaeffer, and Duane Szafron.
The challenge of poker. Artificial Intelligence, 134(1-2):201–240, Jan-
uary 2002.
[4] Rasmus Fynbo and Christian Nelleman. Developing an agent for do-
minion using modern ai-approaches. Master’s thesis, IT- University of
Copenhagen, 2010.
[5] Richard Gibson, Neesha Desai, and Richard Zhao. An automated tech-
nique for drafting territories in the board game risk, 2010.
[6] Stuart J. Russell and Peter Norvig. Artificial intelligence: A Modern
Approach. Prentice Hall, third edition, 2010.
[7] Jonathan Schaeffer and H. Jaap van den Herik. Games, computers, and
artificial intelligence. Artif. Intell., 134(1-2):1–7, 2002.
[8] Michael H. Smith. A learning program which plays partnership domi-
noes. Commun. ACM, 16(8):462–467, August 1973.
[9] Istvan Szita, Guillaume Chaslot, and Pieter Spronck. Monte-carlo tree
search in settlers of catan. In H. Jaap van den Herik and Pieter Spronck,
editors, ACG, volume 6048 of Lecture Notes in Computer Science, pages
21–32. Springer, 2009.
[10] H.Jaap van den Herik, Jos W.H.M. Uiterwijk, and Jack van Rijswijck.
Games solved: Now and in the future. Artificial Intelligence, 134(12):277
– 311, 2002.
[11] Brandon Wilson. Improving game-tree search by incorporating error
propagation and social orientations. In The 10th International Con-
ference on Autonomous Agents and Multiagent Systems, volume 3 of
AAMAS ’11, pages 1355–1356, Richland, SC, 2011. International Foun-
dation for Autonomous Agents and Multiagent Systems.
10You can also read

















































