GPU Computing with CUDA (and beyond) Part 6: beyond CUDA - Johannes Langguth Simula Research Laboratory - Sintef
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

GPU Computing with CUDA (and beyond)
Part 6: beyond CUDA
Johannes Langguth
Simula Research Laboratory
AMD GPUs
AMD Radeon VII NVIDIA Volta V100
Cores 64 80
Base frequency (Ghz) 1.8 1.6
TFLOPS 3.46 7.5
Memory Bandwidth (GB/s) 1000 900
Cache (last level in MB) 4 6
Memory 16 32
Price (USD) 700 10000
2
Johannes Langguth, Geilo Winter School 2020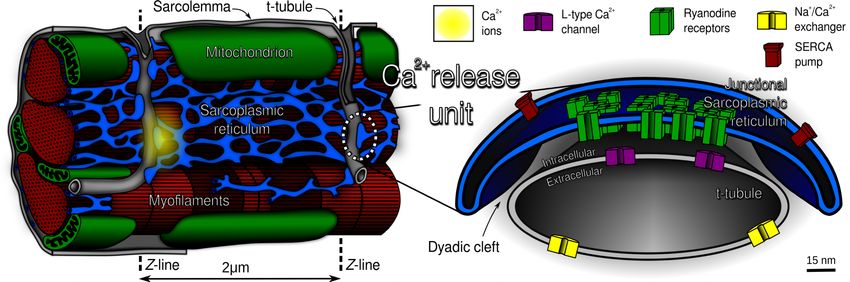
How to Program AMD GPUs
• AMD provides the Radeon Open Compute (ROC)
• Alternative to CUDA
• Currently not very mature
• OpenCL may be preferable
3
Johannes Langguth, Geilo Winter School 2020
Intel: Alternatives to GPUs
Intel MIC / Manycore / Xeon Phi
2013 2016 2018
KNC: Knight’s Corner KNL: Knight’s Landing The End
• Combined advantages of CPU and GPU
• Product line was terminated
• Xeon Phi failure shows why GPUs work
4
Johannes Langguth, Geilo Winter School 2020
Intel: Alternatives to GPUs
Intel MIC / Manycore / Xeon Phi
2013
KNC: Knight’s Corner
• 57 – 61 Pentium cores
• Ring bus
• Xeon Phi followed CPU model, but in order execution
• Cache coherency and parallel threads
• Cache traffic overwhelmed the ring bus
5
Johannes Langguth, Geilo Winter School 2020
Intel: Alternatives to GPUs
Intel MIC / Manycore / Xeon Phi
2016
KNL: Knight’s Landing
• 64 – 72 Atom cores@1.4 GHz
• 2D Lattice
• 16 GB MCDRAM@500 GB/s
• No major design flaws but
• Too similar to CPUs
• 64 Core CPUs are now available 6
Johannes Langguth, Geilo Winter School 2020
Simulating Calcium Handling in the Heart
Extremely expensive simulation.
Requires all the performance we
can get.
7
Johannes Langguth, Geilo Winter School 2020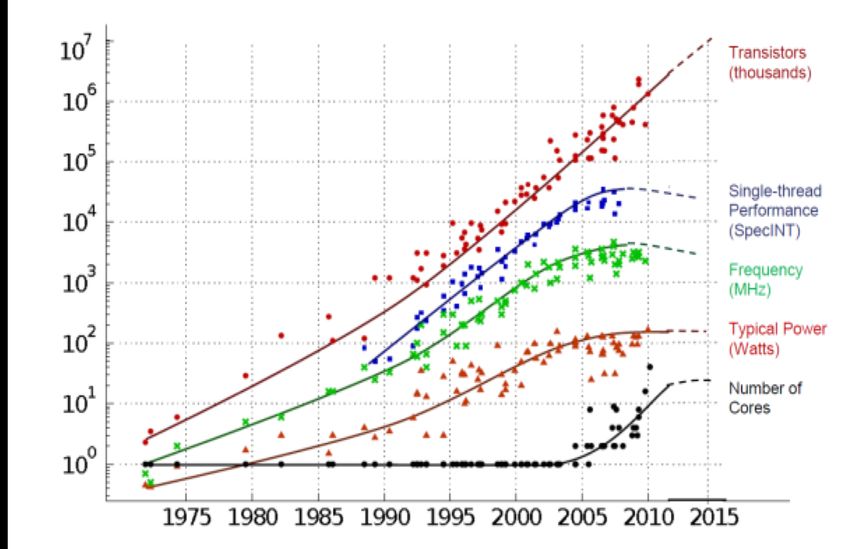
Computational Scope
Computational Scope
Tissue (3D grid of cells) One cell
(100x10x10 grid of dyads)
One dyad
5 Ca+ compartments
100 RyRs
15 L-type channels
2 * 10 9 Cells in the heart
•• 2 *410 Cells in the heart
9
• 104 Dyads per cell
• 10 2 Dyads per cell
• 10 Ryanodine Receptors (RyRs) per dyad
•• 10
10
24 Ryanodine Receptors (RyRs) per dyad
Time steps per heartbeat
• 104 Time10steps per heartbeat
19 possible state transitions
8
1019 possible state transitions
Johannes Langguth, Geilo Winter School 2020
Work Distribution: one Dyad per Thread
Cell Assignment
Relevant metric: Cell computations/s (CC/s)
Relevant metric: Cell computations/s (CC/s)
Best performance at 128 threads/block
Best performance at 128 threads/block
9
Johannes Langguth, Geilo Winter School 2020
Amortizing
Main Problem: Amortize Kernel LaunchOverhead
Kernel Launch Overheads
10
Johannes Langguth, Geilo Winter School 2020Simulating Calcium Handling in the Heart
80000
70000
60000
50000
CC/s
40000
30000
20000
10000
0
KNC V100
l
L
00
0
0
0X
l
KN
we
K2
K4
P1
K2
ad
o
Br
al
Du
• Irregularities in the code
• GPUs still better
11
Johannes Langguth, Geilo Winter School 2020CC/sec.
Simulating Calcium Handling in the Heart
Figure
P100 a
a small
cells pe
of the G
For K
grids of
cells in
which c
the num
as a bas
cells pe
GPU code is close to STREAM bandwidth 12 the sam
Figure 6: Individual
Johannes Langguth, Geilo Winter School 2020 kernel bandwidth measurements on
the samIntel: Making GPUs since 2020
• Xeon Phi is discontinued
• Intel under contract for Exascale
• Solution: make a GPU
• Not many details yet
• Aimed at HPC
• Programing: One API
13
Johannes Langguth, Geilo Winter School 2020Intel: oneAPI
• Data Parallel C++
• Khronos Group SYCL:
Single-source Heterogeneous
Programming for OpenCL
14
Johannes Langguth, Geilo Winter School 2020Technological Trends of Scalable Systems
• Performance growth primarily at the node level
u Growing number of cores, hybrid processors
u Peak FLOPS/socket growing at 50% - 60% / year
• Communication/computation cost is growing
u Memory bandwidth increasing at ~23%/yr
u Interconnect bandwidth
at ~20%/yr
u Memory/core is shrinking
15
Johannes Langguth, Geilo Winter School 2020Technological Trends of Scalable Systems
Supercomputer performance growth: 103/decade
240 Mflops 1TFlop 1 Pflop 148 PFlops
1976 1996 2008 2018 1018
1 core 4510 122K 2.28 M 2021
115KW 850KW 2.35 MW 8.8 MW ≤ 30MW
2KF/W 1MF/W 0.4GF/W 13.8 GF/W
Cray-1 ASCI Red Roadrunner Summit
Cray-2
1985-90, 1.9 GFlops
195 KW (10 KF/W)
Ipad-Pro today:
1.6 Gflops
16
Johannes Langguth, Geilo Winter School 2020What comes after Exascale ?
Transistors
Thread
Performance
Performance
Clock Frequency
Power (watts)
# Cores
2020 2025 2030
Year 17
Johannes Langguth, Geilo Winter School 2020The End of Moore’s Law ?
18
Johannes Langguth, Geilo Winter School 2020The End of Moore’s Law ?
Name Transistors per mm2 Year Process Maker
Intel 10 nm 100,760,000 2018 10 nm Intel
5LPE 126,530,000 2018 5 nm Samsung
N7FF+ 113,900,000 2019 7 nm TSMC
CLN5FF 171,300,000 2019 5 nm TSMC
Number of Transistors is increasing for now.
Not clear how to best use them though.
19
Johannes Langguth, Geilo Winter School 2020turing lecture
On the Horizon: More and More Architectures DOI:10.1145/3282307
Innovations like domain-specific hardware,
enhanced security, open instruction sets, and
agile chip development will lead the way.
BY JOHN L. HENNESSY AND DAVID A. PATTERSON
A New Golden
Age for
Computer
Architecture
• Clock Frequency has stopped increasing
• Moores Law isWEcoming to anLecture
BEGAN OUR Turing endJune 4, 2018 with a review 11
of computer architecture since the 1960s. In addition
• More cores means higher
to that review, here,power consumption
we highlight current challenges
and identify future opportunities, projecting another
• The way out: adapt
golden agearchitecture to architecture
for the field of computer workload. in
the next decade, much like the 1980s when we did the
20
research that led to our award, delivering gains in cost, engineers, including ACM A.M. Tur-
Johannes Langguth, Geilo Winter
energy,School
and2020security, as well as performance. ing Award laureate Fred Brooks, Jr.,
thought they could create a single ISAOn the Horizon: More and More Architectures
• Lots of startups are working on new processors right now.
• Mostly aimed at AI, but they might still be useful.
21
Johannes Langguth, Geilo Winter School 2020Cerebras: Supercomputer on a (big) Chip (not yet available) 22 Johannes Langguth, Geilo Winter School 2020
Graphcore IPUs. Getting away from SIMD
• 1216 Cores per chip / 6 Threads per core
• True MIMD
• Uses SRAM as memory, no DRAM
23
Johannes Langguth, Geilo Winter School 2020COLOSSUS GC2
Graphcore IPUs. Getting away from SIMD
The world's most complex processor chip with 23.6 billion transistors
10x IPU-LINKSTM
320GB/s chip-to-chip bandwidth 1,216 independent IPU-CORESTM
each with IN-PROCESSOR-MEMORYTM tile
> 100GFLOPS per IPU-CORETM
> 7,000 programs executing in parallel
300MB IN-PROCESSOR-MEMORYTM
45TB/s memory bandwidth per chip
the whole model held inside the processor
8TB/s all to all IPU-EXCHANGETM
non-blocking, any communication pattern
PCIe Gen4 x16
64GB/s bi-directional host
communication bandwidth
10
24
Johannes Langguth, Geilo Winter School 2020LLEL HARDWARE
IPU uses BulkTO SOFTWARE
Synchronous Processing on chip
ocessor
1. Compute
BSP)
exchange
2. Sync
3. Exchange
cks
4. Repeat…
sters:
11 25
Johannes Langguth, Geilo Winter School 2020Graphcore IPUs. What Changes ?
• “Flops are cheap” - still true (at least single precision)
• “Bandwidth is expensive” - no longer true (if program fits)
• “Latency is physics” - no longer relevant
• But: memory is small.
Need to use a large number of IPUs for large problems
26
Johannes Langguth, Geilo Winter School 2020Lots of IPUs
27
Johannes Langguth, Geilo Winter School 2020Graphcore IPU Characteristics
• 6 Threads per core
• 6 Cycles memory latency
• 31.1 Single precision FLOPS
• No double units
• Memory Bandwidth: 7.5 - 30 TB/s
• Tensor core type units
• 1.6 Ghz Clock frequency
• 6.3 GB/s between cores
• Multi-IPU transparent to programmer
28
Johannes Langguth, Geilo Winter School 2020But will it work for Scientific Computing ?
• Need double precision units
• Memory is low, but 64 * 300 MB = 19.2 GB
• Codes will need to use a large number of IPUs
• Connection between them and partitioning of data will be crucial
29
Johannes Langguth, Geilo Winter School 2020Summary
• GPU programing with CUDA offers a lot of performance
• Acceptable extra effort, but requires understanding new concepts
• Lots of mature software for free
• Multi GPU gets progressively harder – use as needed
• We may see more novel architectures in the future
30
Johannes Langguth, Geilo Winter School 2020References
Altanaite, N., & Langguth, J. (2018, February). Gpu-based acceleration of detailed tissue-scale cardiac
simulations. In Proceedings of the 11th Workshop on General Purpose GPUs (pp. 31-38).
Langguth, J., Lan, Q., Gaur, N., & Cai, X. (2017). Accelerating detailed tissue-scale 3D cardiac
simulations using heterogeneous CPU-Xeon Phi computing. International Journal of Parallel
Programming, 45(5), 1236-1258.
Langguth, J., Lan, Q., Gaur, N., Cai, X., Wen, M., & Zhang, C. Y. (2016, December). Enabling tissue-
scale cardiac simulations using heterogeneous computing on Tianhe-2. In 2016 IEEE 22nd
International Conference on Parallel and Distributed Systems (ICPADS) (pp. 843-852). IEEE.
Credit: Lecture contains NVIDIA material available at https://developer.nvidia.com/cuda-zone
Image source: wikipedia.org, anandtech.com
Contains material from ACACES 2018 summer school, originally designed by Scott Baden
IPU material provided by Graphcore Norway.
31
Johannes Langguth, Geilo Winter School 2020You can also read

















































