ChatBot for student service based on RASA framework
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
ChatBot for student service based on RASA framework João Fonseca Polytechnic Institute of Porto Fátima Rodrigues ( mfc@isep.ipp.pt ) Polytechnic Institute of Porto Research Article Keywords: Chatbot, RASA, Machine Learning, Natural Language Processing Posted Date: April 5th, 2023 DOI: https://doi.org/10.21203/rs.3.rs-2771200/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Additional Declarations: No competing interests reported.

ChatBot for student service based on RASA
framework
João Fonseca1 and Fátima Rodrigues1,2*
1 ISEP, Polytechnic Institute of Porto, Rua Dr. António Bernardino de
Almeida, 4249-015, Porto, Portugal.
2 ISRC, Interdisciplinary Studies Research Center.
*Corresponding author(s). E-mail(s): mfc@isep.ipp.pt;
Contributing authors: 1171166@isep.ipp.pt;
Abstract
The availability of face-to-face attendance at the School’s Administrative Services
for Students is limited to one schedule, which may prevent the timely clarification
of students’ questions, causing a decrease in their level of satisfaction. To solve
this problem, a conversational agent was designed, consisting of a Portuguese
language interpretation module using natural language processing and machine
learning techniques. To keep the system abstracted from any technical depen-
dency, a web service that manages the agent’s knowledge base was developed. In
the evaluation of the solution, the performance of several learning models was
compared, and the results emphasize the superiority of BERT language model
of Google, combined with the DIET classifier, obtaining a F1-Score of 0.965.
The system was implemented through a prototype and, for a total of 256 ques-
tions, around 70% of correct responses were obtained, with a positive average
satisfaction rating of 4.20 on a 0-5 scale.
Keywords: Chatbot, RASA, Machine Learning, Natural Language Processing
1 Introduction
In the academic context, communication between a Higher Education Institution and
its students takes place, as a rule, through virtual channels, such as the Higher Edu-
cation Institution online platform and by email, and in person through the Academic
1
Division. Although requests from students to the Academic Division occur through-
out the whole academic year, there are periods of substantially greater concentration
of requests, such as the beginning of the school year or the exams periods. More-
over, requests from students to the Academic Division are not only cyclical but also
repetitive, with the same questions being asked by several students. This scenario is
therefore ideal for the use of an intelligent agent, such a chatbot.
A chatbot is defined as an application that interacts with the user through natural
language, usually available on communication platforms, using some form of intelli-
gence [1]. In brief, chatbots aim to simulate a human assistant and, through artificial
intelligence, understand and adequately respond to customer requests.
The solution presented here is a system with question-answer interaction, consti-
tuting a simplified version of a conversational agent, where the objective is not to
build a conversation, but to respond directly to user requests. Given a natural lan-
guage entry point, its function is to search for information in a knowledge base. It is
a closed-domain agent, since its performance is reduced and limited, in this specific
case, to the Academic Division knowledge base of a Higher Education Institution.
There are already numerous works related to the creation of chatbots in several
domains. Chatbol [2] is a chatbot to answer questions related to the football league “La
Liga”. The main component of Chatbol is a natural language processing (NLP) block
trained to extract intents and entities from questions asked by users. The extracted
entities are used to query Wikidata and thus obtain information to respond to users. In
another work, a chatbot was developed to respond to various e-government initiatives
in order to provide citizens with personalized information about public services [3].
This chatbot was built using the RASA framework combined with a knowledge graph
designed to provide information to the chatbot. Another chatbot was developed to
assist insurance brokers in the daily service to their customers [4]. The authors defined
a model of an API in Python that uses libraries for NLP providing services in REST. A
prototype was developed to validate the responses, integrating the API with Facebook
Messenger.
This article describes the development process of a chatbot for the Academic
Division of an Higher Education Institution capable of automatically answering the
students’ most frequently asked questions. The chatbot not only avoids the physical
displacement of students, an asset in today’s society, but also reduces the number of
face-to-face sessions, phone calls and emails, also contributing to the reduction of Aca-
demic Division overload. Finally, in scientific terms, the present study is relevant for
the construction of conversational agents consisting of NLP techniques in conjunction
with machine learning algorithms.
The remainder of this article includes, in Section 2, the presentation of the main
components of a chatbot. Section 3 presents a comparative review of chatbot devel-
opment frameworks. The following section describes the architecture of the chatbot
developed using the RASA framework. In Section 5 the implementation of the con-
versational agent is described and in Section 6 several configurations of learning
algorithms and their parameters are tested, as well as NLP techniques to be included
in the core of the chatbot. The main conclusions about the work presented here are
drawn in the final section.
2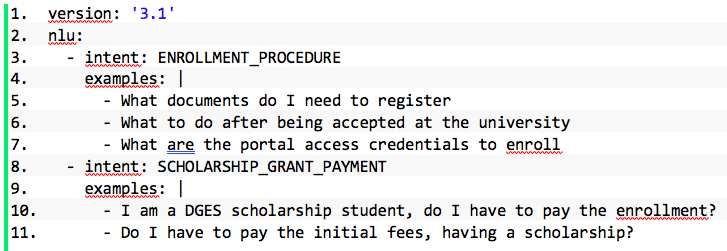
2 Chatbot operating model
Currently, most chatbots classify text into entities and intentions [5]. However, there
may also be a need to classify the act of dialogue. Intent refers to the purpose or mean-
ing of the user’s speech. It is the classification that the input component assigns to
the phrase that is later used to perform an action or generate a final response. Intents
are the pillars that determine the responsiveness of the chatbot, and are usually intro-
duced manually by developers. An entity is considered to influence the final context
of the sentence. These are keywords that are always associated with the same value,
such as personal names, locations, etc.
A chatbot is divided into three main components, namely the natural language
processor, the dialog manager and the response generator [6]. The main objective of the
natural language processor is to discover the user intention by interpreting the received
message and converting it into a predefined lexical structure. Once the message is
interpreted, the dialog manager is responsible for reacting to its intent, comparing it
with a knowledge base filled with information from the business domain. The response
generator, in line with the determined action, builds the output information through
machine learning models or through the use of standard responses. In case of failure,
the chatbot can decide to respond with a request for more information or, as a last
resort, with an error message.
3 Chatbot development tools
Essentially, there are two classes of chatbot development tools. The first class com-
prises fast building platforms that provide a set of simple rules that define the flow of
decisions for building high-level dialogue, without any machine learning techniques.
The second class includes development platforms or frameworks that provide functions
and algorithms suited to customization. A benchmark study of chatbot development
tools [7], which considered as assessment criteria the ease of implementation, the inte-
gration with communication channels, the collection of user information and the types
of response, Wotnot [8] and Intercom [9] were identified as the most popular rapid
construction platforms.
Due to the lack of a comparative review of chatbot services, Braun et al. [5]
evaluated conversational interface systems taking into account their understanding of
natural language, having highlighted the five most popular services, namely four based
on cloud implementations — LUIS, IBM Watson, Wit.ai, Dialogflow, and Amazon
LEX — and one local solution —– RASA. Additionally, Thorat and Jadhav [10] com-
pared existing technologies within a context similar to the present work, a Q&A agent.
He evaluated IBM Watson and Dialogflow through its integration with communica-
tion channels, the ability to collect user data and, finally, natural language support.
Table 1 shows the most important features of the IBM Watson, Dialogflow and RASA
frameworks, as these were also referred to as the most prominent by other authors [11].
In the context of deployment, commercial solutions provide superior support com-
pared to RASA, since, in addition to allowing agent configuration via the web, they
provide integration with their publishing platforms. Its objective is to reach a balance
between a technical and an easy way to build a solution. In contrast, the open-source
3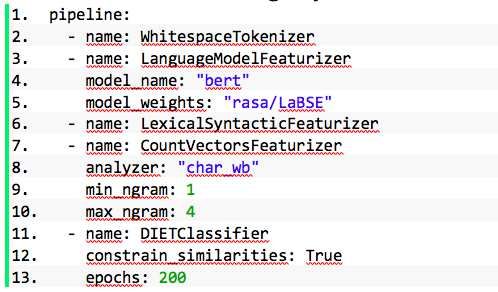
Table 1: Features comparison of three frameworks
Solution Dialogflow IBM Watson RASA
Open-source X
NLP support X X X
NLP pipeline customization X
Portuguese language support X X X
Cloud based X X
Visual interface X X
Programming language SDK for SDK for Python
14 languages 10 languages
RASA solution offers a higher level of customization. Unlike Dialogflow and IBM Wat-
son, which use their own NLP methodology, RASA transfers this responsibility to the
developer.
All solutions are based on the same principles: the definition of entities, intentions
and the training process for a response-generating classification model. The biggest
differentiating factor among all frameworks is the AI scheme that defines the learning
process.
3.1 RASA Stack
RASA [12] was the solution adopted for creating the chatbot with a focus on NLP.
This framework works by identifying the intents contained in user messages, classifying
them according to the intents defined by the developer, and returning a response
based on the intent. This response can be an already defined text or a custom action,
such as a database entry. RASA is segmented into two modules, the RASA Core and
the RASA NLU (Natural Language Understanding). The first is intended for dialogue
management, enabling context analysis and the choice of actions, while the second is
responsible for extracting entities and intentions.
RASA NLU is the component that provides the methods of the NLP phase with
algorithms native to the framework or through integration with other Python libraries.
The developer’s responsibility is limited to listing which methods to use and their
parameterization. The text interpretation flow normally follows these phases:
• Word Vector Sources: selection of pre-defined semantic models based on the
proximity relationship between words.
• Text Featurizer: conversion of text to suitable structures for machine learning
functions.
• Intent Classifier: extraction of intent through machine learning models.
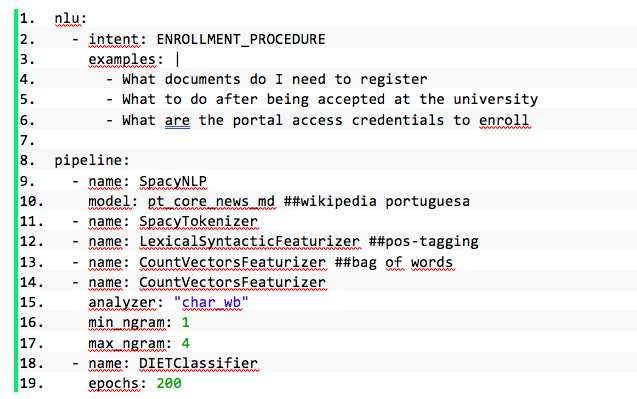
Both the training data and the NLP phase configuration are defined through the
external files presented as “nlu” and “pipeline” in Code block 1, respectively.
4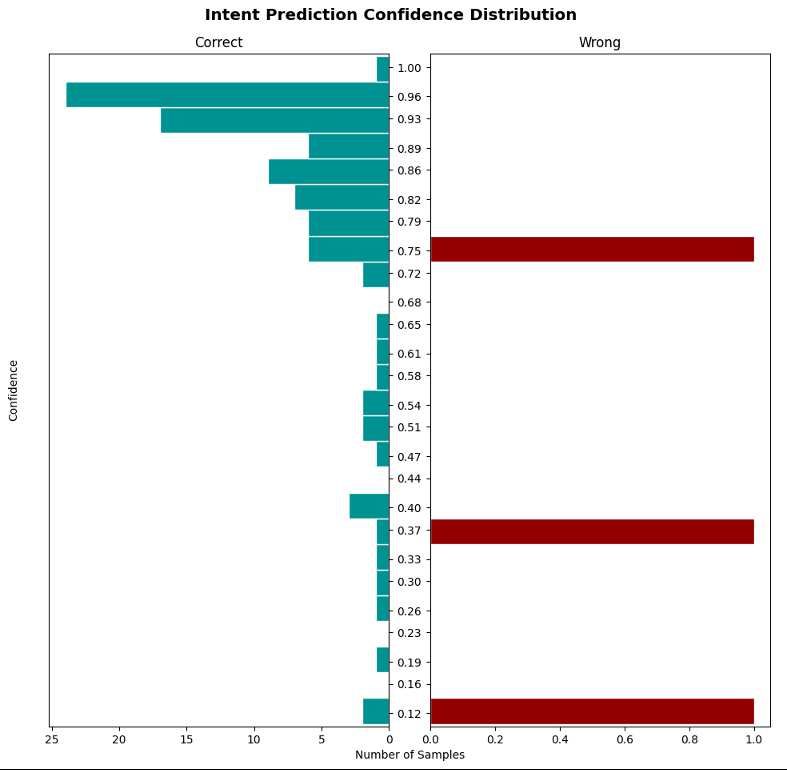
Code block 1 – Segment of RASA configuration file, with functionalities from the
SpaCy library and a pre-defined Portuguese dictionary based on Wikipedia
Finally, it supports other features such as defining regular expressions, entities and
converting words to predefined synonyms.
4 Chatbot architecture
The system comprises the agent core, Chatbot Core, and the topic management web
service, Topic WebService. Chatbot Core provides an external communication inter-
face through a REST API. However, the component that receives the user’s request
is the topics service, through the Higher Education Institution’s online platform. The
reception of the request triggers the Chatbot Core, which identifies the most likely
intents and the associated discussion topics. If the confidence level is greater than a
predefined value, the service returns the response to the user. This process is schemati-
cally shown in Figure 1, excluding, for the sake of simplicity, the return of a response to
the user. It is important to mention that the communication between the components
is carried out using authentication with tokens.
5Fig. 1: Integration of the two components of the chatbot architecture
In addition to promoting modularization by decoupling the implementation of the
conversational agent from the communication platform, this scheme also allows for full
control over the information management process. Furthermore, it is specifically useful
for auditing, tracking conversation context and evaluating interactions. A more tech-
nical view of containers is presented in the following sections, showing their internal
components.
4.1 Agent Core
Figure 2 shows the agent’s core architecture — Chatbot Core. The internal structure
of the agent follows the RASA functional scheme, but, since the response selection
logic resides in the topic service, only components related to NLP will be used. The
NLU dataset refers to training data.
6Fig. 2: Internal architecture of the chatbot core
The text interpreter works through the configuration of NLP methods, manually
indicated by the developer. Each scheme is divided into three components, namely
tokenizers, which represent the data pre-processing step, featurizers, functions respon-
sible for preparing the tokens before the learning phase and, finally, intent classifiers,
the deep learning algorithms. The training phase is shown in Figure 3 taking into
account the described components.
Fig. 3: Illustration of the agent training phase implemented in RASA
4.2 Topics Management Service
To build an intuitive system for the Academic Division members, namely one that
allows to reconfigure the text comprehension functionalities in a high-level way, an
abstraction layer, referred to as the topic service, was built.
The topic is a concept composed of a set of examples, one or more associated
answers, the name of the intent, the description, and the category. Topic manage-
ment constitutes the main range of service functionalities, being the agent’s knowledge
base. The annotation of the knowledge base was performed manually. An example is
provided in Table 2.
7Table 2: Extract of the intention to update the payment of tuition fees
Examples Response Intent Description Category
How long will it take “The information PERIOD PAYMENT Duration for FEES
for fees to be updated? on the payment updating
Are fees going to of fees can take tuition fees
be updated? between 24 and
An error message popped up 48 hours to update.”
regarding my tuition fees...
This service provides features for creating, editing and deleting topics that were
developed with the aim of serving as an API. In addition to these functionalities, the
import of existing information was also made available. Two sources of information
were uploaded, namely the Academic Division’s frequently asked questions page, with
subjects such as enrollment, student card, enrollment in exams and course completion,
and a set of emails with questions sent by students.
5 Implementation
The key element of the chatbot is the conversational agent core, specifically the ability
to understand natural language. The knowledge base contains the intentions that the
agent will understand and the respective training examples, such as students questions
and respective Academic Division’s answers.
5.1 Knowledge base
Topics are stored separately in order to have a dynamic information support. Although
it has advantages at the level of the end customer, it results in greater development
complexity, particularly due to the need to transform the stored topics to the format
required by the RASA specific YAML framework. It was therefore necessary to trans-
form the topics into an object that contains the intention and various text examples.
A subset of the final result is given in Code block 2.
Code block 2 – Partial extract of final nlu.yml file
8Another important aspect of data set configuration is the selection of synonyms,
allowed by RASA through the same file. Although the NLP process already uses
text dictionaries, there are domain-level parallels that are not interpreted correctly. A
segment of the list of the synonyms defined for the agent is presented in Code block 3.
Code block 3 – List of some synonyms present in the data file
In order for the model to learn to classify synonyms more accurately, it is important
that the training data retain examples of each occurrence. The semantic mapping
phase is only performed after the meaning extraction. As mentioned above, two sources
of information were uploaded, the Academic Division’s FAQs and student’s email
extracts, provided by the Academic Division itself. The annotation of the data was
manual, by assigning a category to each intention, facilitating the qualitative analysis
within each theme.
After an initial test, new topics crucial to the proper functioning of the agent were
identified. In addition to the capacity for natural dialogue, namely greetings, references
were added regarding the functioning of the Academic Division. The final version of
the agent knowledge base includes 38 topics. No entity recognition was configured, as
it was not necessary for any intention.
5.2 Natural Language Understanding
Once the training data is prepared, it is possible to proceed with the creation of the
classification model. For RASA, the NLP process is divided into three components,
tokenizers, featurizers and intent classifiers.
The processing flow works sequentially according to the configuration order, with
each component receiving input values, processing them, and returning output values.
The final configuration is presented in Code block 4.
9Code block 4 – Partial extract of final config.yml file
Each component has different functions, outlined in Table 3.
Table 3: Responsibility of each component in the chosen configuration
Component Functionality
Tokenizer WhitespaceTokenizer Segments the sentence by spaces
Featurizer LanguageModelFeaturizer Interprets the meaning of the token
according to a pre-trained language model
LexicalSyntacticFeaturizer Adds the phrasing function of the token
CountVectorsFeaturizer Add token frequency in training examples
Classifier DIET Classifier Performs intent prediction through the
use of transformers and neural networks
The DIET classifier, or Dual Intent Entity Transformer, is a transformer architec-
ture capable of interpreting entities and intents simultaneously [13]. A transformer is
a sequence-to-sequence model, whose initial purpose was to serve as a translator, so its
architecture is divided into two components, the encoder, which receives the message,
and the decoder, which does the translation [14]. However, transformers were quickly
adapted to perform other NLP tasks, with positive results, including natural language
inference. The pre-trained transformers available in the RASA framework are BERT
[15], and RoBERTa [16] that will be tested within the knowledge base of this agent.
5.3 Message Sending
Once the text comprehension phase is finished, the intent is ready to be issued to the
user. The midpoint between the online platform and the agent is the topic service.
The latter receives the text of the request and forwards it to the chatbot, obtaining
the content of the agent’s analysis (see Code block 5).
10Code block 5 – JSON content of the agent response
The final topic is obtained through the intent block, in conjunction with the asso-
ciated confidence percentage. If it exists in the database, the information allows to
connect the intention with a response and confirm whether the confidence is above
the outlined minimum.
5.4 Prototype
A prototype was built to demonstrate the capacity of the developed system expos-
ing all the functionalities through a visual interface implemented in React [17]. The
objective of this prototype was to structure a simple interface that could integrate the
produced ecosystem. The prototype is subdivided into three main sections, namely
the conversation page, the topic management panel and, finally, the list of observed
messages.
The start page or main page consists of a conversation block where a line represents
the agent or, if a question is introduced, the user. For simplification purposes, and
to ease the visualization, the message from the chatbot and the user have different
colors. If a topic is directly answered, the system allows the user to rate the quality
of the answer to the question, on a scale of 0-5 (with 0 being the worst rating and 5
the best), as illustrated in Figure 4. For topics such as initial greetings, farewells and
clarification requests, there is no possibility of evaluation.
The topics panel made available to the Academic Division aims to allow their
staff to add and modify topics from the agent’s knowledge base and trigger a new
training process. For quality analysis processes, a web page that allows to view the
11Fig. 4: Example of interaction appearing in the chatbot interface
list of messages exchanged with the chatbot, the evaluation given and the identified
intention was also developed.
6 Solution Modelling and Evaluation
The interaction quality with the chatbot will be analysed through the evaluation of
intention learning models. It is expected that the user’s experience will vary depending
on the preparation of the system, and this implies not only the learning aspect, but
also text comprehension. To this end, a comparative analysis of the learning models is
established, varying not only the learning algorithms and their parameters, but also
the data pre-processing stage.
Another reliable metric of the system is the direct evaluation of the user, which
will be done by analyzing the scores assigned to the chatbot’s responses.
6.1 Training and selection of classification models
The selection of the most appropriate classification model was carried out by com-
bining the learning algorithm that produces the best results, taking into account the
same information base. Due to the modularity of RASA, it is possible to create and
test configurations simultaneously, defining the desired components, as presented in
section 5.2.
The information base used is small, consisting of 38 intentions and only 456 text
examples divided into 80% for training and 20% for testing. It is expected that models
that use pre-defined language repositories have better results, but all options were
tested. Although the framework is based on its intent classifier, DIET, linear regression
methods and support vector machines were also tested, but their results were inferior
and, therefore, excluded from the analysis.
The first verification phase was carried out with the base DIET classifier, testing
only tokenizers and featurizers with 200 training iterations (epochs), 1 feed-forward
layer and 2 transformers. The test was performed with the 5 different configurations,
described in Table 4.
Configurations 1, 2 and 3 represent the implementation of Google’s language mod-
els, BERT and RoBERTa which support any language. To confirm that the parsing
and word frequency counting algorithms help the prediction capability, the first con-
figuration does not include them. Configuration 4 supports the NLP pipeline from the
SpaCy library, which has a complete flow already configured. In addition to an initial
data dictionary, based on Portuguese news articles [18], configuration 4 also contains
tokenizers, a morphological generalizer and a lemmatizer. Finally, to verify whether
12Table 4: Learning scheme for the various test configurations
ID Configuration Tokenizer Featurizer
1 config_bert_base.yml Whitespace Language Model: BERT
2 config_bert_sparse_features.yml Whitespace Language Model: BERT
Lexical Syntatic
Count Vectors: n-gram: 1..n-gram: 4
3 config_roberta.yml Whitespace Language Model: RoBERTa
Lexical Syntatic
Count Vectors: n-gram: 1..n-gram: 4
4 config_spacy_portuguese.yml SpaCy SpaCyNLP – Medium
Portuguese Dictionary
Lexical Syntatic
Count Vectors: n-gram: 1..n-gram: 4
5 config_domain.yml Whitespace Lexical Syntatic
Count Vectors: n-gram: 1..n-gram: 4
the learning process without a pre-defined knowledge base is effective, configuration 5
was created. It builds the learning labels exclusively through the examples provided.
Table 5 illustrates the results obtained, where the superiority of BERT is observed.
Not only did it achieve the highest F1-score across all iterations, it also evolved with
more training data. Additionally, it is understood that the use of syntactic functions
and word count helped in text interpretation, with configuration 1 classified below
configuration 2. The remaining configurations obtained a similar F1-score value. The
fact that, with the exception of the SpaCy model, all configurations evolved throughout
the tests reveals that the agent will benefit from a greater number of training examples.
Although all models have shown positive results, BERT (configuration 2) achieves the
best performance, followed by RoBERTa (configuration 3).
Table 5: Metrics of the best execution of each configuration
ID Setting accuracy precision recall F1-score
1 config_bert_base.yml 0.891 0.936 0.918 0.901
2 config_bert_sparse_features.yml 0.949 0.951 0.956 0.951
3 config_roberta.yml 0.929 0.946 0.929 0.924
4 config_spacy_portuguese.yml 0.898 0.928 0.898 0.894
5 config_domain.yml 0.888 0.917 0.888 0.889
The next verification phase focused on the parameterization of the DIET classi-
fication algorithm, using the best combinations of data preparation outlined in the
previous step. The objective is to increase the predictive capacity of the models, try-
ing to obtain superior results in relation to the default parameters. The configurations
observed in Table 6 were applied to both BERT and RoBERTa algorithms.
The variation focused on increasing the number of transformers, the number of
feed-forward layers and the number of training iterations. Again, the superiority of the
BERT language model (1, 3, 5) was verified, which showed superior results in all iter-
ations. Nevertheless, the parameterization of DIET did not generate large variations
13Table 6: Parameterization of the various DIET classifiers
ID Configuration Parameterization
1 config_bert_diet0 Training iterations (Epochs): 200
2 config_roberta_diet0 Number of feed-forward layers: 1
Number of Transformers: 2
3 config_bert_diet1 Training iterations (Epochs): 300
4 config_roberta_diet1 Number of feed-forward layers: 2
Number of Transformers: 2
5 config_bert_diet2 Training iterations (Epochs): 300
Number of feed-forward layers: 3
Number of Transformers: 3
in the capacity of the models, since the models continued to yield F1-scores similar to
those of the first phase. Regarding the maximum F1-score, increasing the number of
feed-forward layers and transformers produced a better result. However, it should be
noted that the only configuration that continued to improve its performance as more
iterations were carried out was configuration 1. The results of the best performing
iteration for each configuration are shown in Table 7.
Table 7: Metrics taken from the best execution of each configura-
tion
ID Setting accuracy precision recall F1-score
1 config_bert_diet0.yml 0.952 0.972 0.969 0.967
3 config_bert_diet1.yml 0.939 0.943 0.939 0.938
5 config_bert_diet2.yml 0.959 0.96 0.959 0.965
2 config_roberta_diet0.yml 0.929 0.951 0.939 0.94
4 config_roberta_diet1.yml 0.919 0.944 0.911 0.914
6 config_roberta_diet2.yml 0.914 0.937 0.919 0.914
Taking into account the analysis carried out, the configuration chosen for the pro-
totype was config bert diet0.yml. Not only does it already produce the best results in
these experiments, but it also allows for a scalable implementation for larger knowledge
bases.
The RASA framework also provides statistical analysis tools, including the confi-
dence distribution of predictions. Figure 5 shows two histograms with the correct (left
histogram) and the wrong (right histogram) predictions, taking into account the con-
fidence (vertical axis) and the number of samples (horizontal axis). The chosen model
made most of the correct predictions with confidence greater than 70%, obtaining only
three wrong predictions.
The graph is important to understand which threshold to use to decide whether
the associated response should be sent or not. Although there is one question with an
error above 70%, most success predictions were higher than this value, which was the
threshold chosen for publication in the prototype. In short, the metrics related to the
classification models were positive, especially the use of the BERT language model.
14Fig. 5: Confidence distribution of predictions of chosen model
6.2 User satisfaction level
With regard to direct user evaluation, the prototype was made available to members
of the Academic Division and students of a master’s course to carry out early tests of
its implementation for 12 days, with a total of 256 interactions obtained. It should be
noted that the test does not assess the real purpose of the chatbot as users did not
exactly have doubts, but the intention was to find out the usefulness of the chatbot. In
any case, the publication of the prototype was positive, since 70% of the 256 questions
asked were adequately answered and positively evaluated not only by the Academic
Division but also directly by the students. The mean overall rating was 4.20 with
a standard deviation of 1.23. However, even though the chatbot’s performance may
improve with its continued use, the reduced size of its knowledge base is considerable,
which is why 30% of the questions were not understood correctly.
7 Conclusion
In this paper we aimed to build a fully configurable chatbot to aid the Academic
Division of a Higher Education Institution. A comparison was made between several
tools and the RASA framework was the most suitable solution because it allows for
15the highest level of customization, both for the intent classification model and in the
preparation of training data.
The present paper exposed the development process from the design stage to the
implementation of the chatbot, which included the configuration of the chatbot core,
with the NLP module and intent learning model, the topic management service and
a web service for the storage of exchanged messages and respective evaluation. The
use of AI and NLP was essential to enhance the chatbot with the ability to interpret
questions and respond appropriately to users.
As future work, the addition of more topics and examples in the knowledge base
will improve the understanding of the chatbot, thus increasing its accuracy rate.
Acknowledgements
The authors would like to thank the deputy President of School of Engineering of Poly-
technic Institute of Porto (ISEP/IPP), Antonio Vega, for the approval of the adoption
of the chatbot, and the Head of the Academic Division of ISEP/IPP, José Luı́s Nunes,
for providing all the necessary information to construct the chatbot knowledge base,
which was crucial to the development of this project.
References
[1] Mayo, J. (2017) Programming the Microsoft Bot Framework: A Multiplatform
Approach to Building Chatbots. Microsoft Press
[2] Segura, C., Palau, À., Luque, J., Costa-Jussà, M. R., Banchs, R. E. (2019) Chatbol,
a chatbot for the Spanish “La Liga”. In 9th International Workshop on Spoken
Dialogue System Technology, pp 319-330 Springer, Singapore.
[3] Patsoulis, G., Promikyridis, R., Tambouris, E. (2021) Integration of chatbots with
Knowledge Graphs in eGovernment: The case of Getting a Passport. In 25th Pan-
Hellenic Conference on Informatics, pp 425-429. https://doi.org/10.1145/3503823.
3503901
[4] Valmorbida, W., Hart, L. M. (2019) Desenvolvimento de uma API para Chatbots
de Vendas e Gestão de Seguros. Revista Destaques Academicos, 11(4). http://dx.
doi.org/10.22410/issn.2176-3070.v11i4a2019.2361
[5] Braun, D., Mendez, A. H., Matthes, F., Langen, M. (2017) Evaluating natural
language understanding services for conversational question answering systems. In
Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pp
174-185. http://dx.doi.org/10.18653/v1/W17-5522
[6] Mohammed, M., Aref, M. M. (2022) Chatbot system architecture. https://doi.org/
10.48550/arXiv.2201.06348
[7] Maruti Techlabs (2023) 14 Most Powerful Platforms to Build a Chatbot
[2023 Update] https://marutitech.com/14-powerful-chatbot-platforms/ (accessed
1624 March 2023)
[8] WOTNOT (2023) Automate interactions with your current and future customers
today! https://wotnot.io/. (accessed 27 March 2023)
[9] INTERCOM (2011) The only AI costumer service solution you need
https://www.intercom.com. (accessed 27 March 2023)
[10] Thorat, S. A., Jadhav, V. (2020) A review on implementation issues of rule-
based chatbot systems. In Proceedings of the International Conf. on Innovative
Computing Communications http://dx.doi.org/10.2139/ssrn.3567047
[11] Canonico, M., De Russis, L (2018) A comparison and critique of natural language
understanding tools. Cloud Computing, 120.
[12] Rasa Technologies GmbH (2020) Introduction to Rasa Open Source & Rasa Pro
https://rasa.com/docs/rasa/ (accessed 27 March 2023)
[13] Bunk, T., Varshneya, D., Vlasov, V., Nichol, A. (2020) Diet: Lightweight language
understanding for dialogue systems. https://doi.org/10.48550/arXiv.2004.09936
[14] Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones, L., Gomez A. N.,
Kaiser L., Polosukhin I. (2017) Attention is all you need. In Advances in neural
information processing systems pp 5998–6008.
[15] Devlin, J., Chang, M. W., Lee, K., Toutanova, K. (2018) Bert: Pre-training of
deep bidirectional transformers for language understanding. https://doi.org/10.
48550/arXiv.1810.04805
[16] Liu Y., Ott M., Goyal N., Du J., Joshi M., Chen D., Stoyanov V. (2019) Roberta:
A robustly optimized bert pretraining approach. https://doi.org/10.48550/arXiv.
1907.11692
[17] Jordan Walke (2022) React, The library for web and native user interfaces
https://legacy.reactjs.org. (accessed 27 March 2023)
[18] Rademaker A., Chalub F., Real L., Freitas C., Bick E., De Paiva V. (2017) Uni-
versal dependencies for Portuguese. In Proceedings of the Fourth International
Conference on Dependency Linguistics, Depling pp 197-206.
17You can also read

















































