Towards a Polyglot Data Access Layer for a Low-Code Application Development Platform
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Towards a Polyglot Data Access Layer for a Low-Code
Application Development Platform∗
Ana Nunes Alonso1 , João Abreu2 , David Nunes2 , André Vieira2 ,
arXiv:2004.13495v1 [cs.DB] 28 Apr 2020
Luiz Santos2 , Tércio Soares2 , and José Pereira1
1
INESC TEC and U. Minho, ana.n.alonso@inesctec.pt, jop@di.uminho.pt
2
OutSystems, first.last @outsystems.com
Abstract 1 Introduction
Low-code application development as proposed by According to Forrester Research, that defines low-
the OutSystems Platform enables fast mobile and code as “enabl[ing] rapid delivery of business applica-
desktop application development and deployment. It tions with a minimum of hand-coding and minimal
hinges on visual development of the interface and upfront investment in setup, training, and deploy-
business logic but also on easy integration with data ment,” OutSystems is a leading low-code platform for
stores and services while delivering robust applica- application development and delivery [19]. It empha-
tions that scale. sizes drag-and-drop to define the functionality for UI,
Data integration increasingly means accessing a va- business processes, logic, and data models to create
riety of NoSQL stores. Unfortunately, the diversity of full-stack, cross-platform applications.
data and processing models, that make them useful in Integrating with existing systems increasingly
the first place, is difficult to reconcile with the sim-
means connecting to a variety of NoSQL data stores,
plification of abstractions exposed to developers in deployed as businesses take advantage of Big Data.
a low-code platform. Moreover, NoSQL data stores Our goal is to enable interactive applications built
also rely on a variety of general purpose and custom with the OutSystems Platform [16] to query data in
scripting languages as their main interfaces. NoSQL stores.
In this paper we propose a polyglot data access The current standard for integrating NoSQL stores
layer for the OutSystems Platform that uses SQL with available low-code platforms is for developers
with optional embedded script snippets to bridge to manually define how the available data must be
the gap between low-code and full access to NoSQL imported and consumed by the platform, requiring
stores. In detail, we characterize the challenges for expertise in each particular NoSQL store, especially
integrating a variety of NoSQL data stores; we de- if performance is a concern.
scribe the architecture and proof-of-concept imple- Conversely, an ideal OutSystems experience for
mentation; and evaluate it with a sample applica- leveraging Big Data should be: (1) create an inte-
tion. gration with the Big Data repository, providing the
∗ This work was supported by Lisboa2020, Compete2020 connection details including credentials; (2) the plat-
and FEDER through Project RADicalize (LISBOA-01-0247- form introspects the data in the repository and cre-
FEDER-017116 | POCI-01-0247-FEDER-017116). ates a representation for it; (3) the developer trims
1down the mapping to the information that is valuable NoSQL stores to interactive applications creating us-
for the application; (4) the developer is able to query ing the OutSystems platform, preserving the low-
this information with some transformation capabili- code developer experience, i.e. without requiring spe-
ties which include filtering, sorting, grouping; (5) the cific NoSQL knowledge for a developer to success-
platform handles all the requirements for providing fully write applications that leverage this type of data
this information with enterprise-grade non-functional stores.
requirements (NFRs) such as security, performance, Enabling the seamless integration of a multitude
and scalability; and (6) the developer is able to cre- NoSQL stores with the OutSystems platform will of-
ate applications that can interact with the Big Data fer its more than 200 000 developers a considerable
repository and leverage this information in business competitive advantage over other currently available
logic and processes, and also to create visualizations. low-code offers. Moreover, Gartner predicts low code
Delivering the ideal experience for Big Data does application platforms will be used for 65% of all appli-
however raise significant challenges. First, step (2) cation development activity in 5 years time[25], am-
is challenged by NoSQL systems not having a stan- plifying the impact of our contribution.
dardized data model, a standard method to query In this paper we summarize our work on a proof-
metadata, or even in many cases by not enforcing a of-concept polyglot data access layer for the OutSys-
schema at all. In fact, even if stored data conform to tems Platform that addresses these challenges, thus
a well defined schema, it may be only implicit in the making the following contributions:
code of applications that manipulate it.
Second, the value added by NoSQL data stores • We describe in detail the challenge in integrat-
rests precisely on a diversity of query operations and ing NoSQL data stores in a low-code develop-
query composition mechanisms, that exploit specific ment platform targeted at relational data. This
data models, storage, and indexing structures. Ex- is achieved mainly by surveying how data and
posing these as visual abstractions for manipulation query models in a spectrum of NoSQL data
in step (4) risks polluting the low-code platform with stores match the abstractions that underlie the
multiple particular and overlapping concepts, instead low-code approach in OutSystems.
of general purpose abstractions. On the other hand, • We propose to use a polyglot query engine, based
if we expose the minimal common factor between all on extended relational data and query models,
NoSQL data stores, we are likely to end up with with embedded NoSQL query script fragments
minimal filtering capabilities that prevent developers as the approach that reconciles the expecta-
from fully exploiting NoSQL integration. In either tion of low-code integration with the reality of
case, some NoSQL data stores offer only very mini- NoSQL diversity.
mal query processing capabilities and thus force client
applications to code all other data manipulation op- • We describe a proof-of-concept implementation
erations, which also conflicts with the low-code ap- that leverages an off-the-shelf SQL query engine
proach. Finally, step (5) requires ensuring that per- that implements the SQL/MED standard [10] for
formance is compatible with interactive applications managing external data.
means that one cannot resort to built-in MapReduce As a result, we describe various lessons learned, that
to cope with missing query functionality, as it leads are relevant to the integration of NoSQL data stores
to high latency and resource usage. Also, coping with with low-code tools in general, to how NoSQL data
large scale data sets means full data traversals should stores can evolve to make this integration easier and
be avoided. This can be done by exposing relevant more effective, and to research and development in
indexing mechanisms and resorting to approximate polyglot query processing systems in general.
and incomplete data, for instance, when displaying a The rest of the paper is structured as follows. In
developer preview during step (3). Section 2 we briefly describe the OutSystems plat-
Our goal is to add the ability to query data in form, how it handles data access, and integrates with
2external SQL databases. Section 3 presents the main
results of an analysis of target data stores focusing
on how their characteristics impact our goal. Sec-
tion 5 describes our proposal to integrate NoSQL
data stores in the OutSystems platform, including
our current proof-of-concept implementation. This
proposal is then evaluated in Section 6 and compared
to related work in Section 7. Section 8 concludes the
paper by discussing the main lessons learned.
2 Background
The OutSystems Platform is used to develop, deploy
and operate a large number of custom applications .
through a model driven approach and based on a low
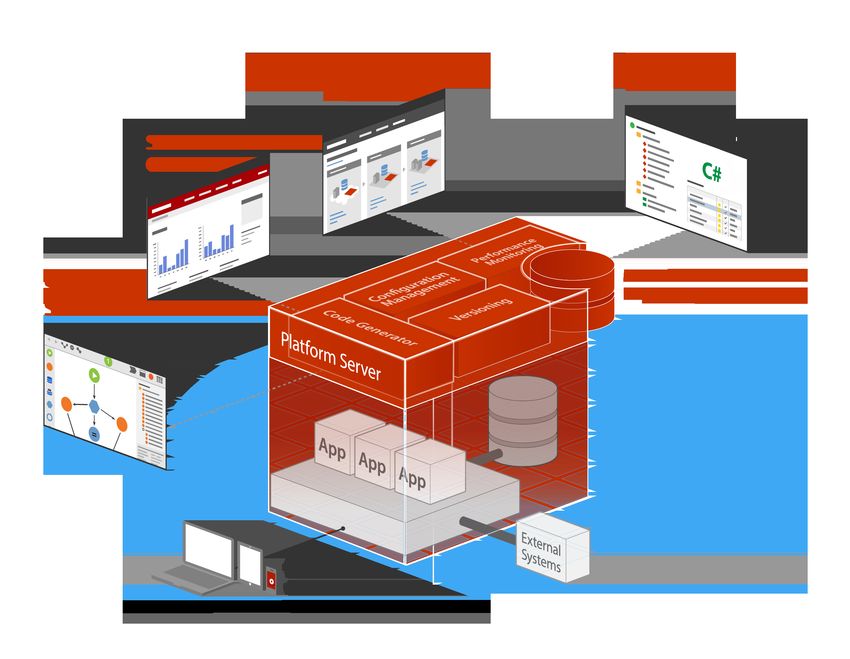
Figure 1: OutSystems Platform Architecture
code visual language [16]. A key trait of the approach
is that the most common tasks executed in the cre-
ation of an Information System are visually modeled. be ASP.Net and SQL code). The compiled applica-
This is a major contribution for providing accelera- tion is then deployed to the Application Server.
tion to customers. Visual models abstract a lot of Application Server. Runs on top of IIS. The
the complexity of low level coding, are easier to read server stores and runs the developed applications
and therefore reduce the time needed for knowledge
Service Center. Provides a web interface for
transfer. Having a common modeling language favors
sysadmins, managers and operations teams. Connec-
skill reuse either when implementing back end logic,
tions to external databases are configured here.
business processes, web UIs, or mobile UIs. A second
Integration Studio. A desktop environment,
key trait is that customers should never hit a wall,
targeted at technical developers, used to integrate ex-
in the sense that the not so common tasks can also
ternal libraries, services, and databases.
be achieved, while sometimes not as easily, but still
using visual modelling and/or extensibility to 3GL
languages. 2.2 Data Access
One of the most common operations in data-driven
2.1 Architecture applications is to fetch and display data from the
database. The OutSystems Platform models the data
The OutSystems solution architecture [13] features access through the concept of Entities, elements that
five main components, as shown in Figure 1: enable information to be persisted in the database
Service Studio. The development environment and the implementation of a database model, follow-
for all the DSLs supported by OutSystems. When ing the relational model to represent data and its re-
the developer publishes an application, Service Stu- lationships. A visual editor that allows development
dio saves a document with the application’s model teams to query and aggregate data visually is also
and sends it to the Platform Server. provided, so that developers with any skill set can
Platform Server. Takes care of all the steps re- work with the complex data needed for any applica-
quired to generate, build, package, and deploy na- tion.
tive C# web applications on top of a particular stack Using this platform, developers can create inte-
(e.g., for a Windows Server using SQL Server this will grations of local and external data sources without
3having to write custom code, significantly reducing ally offering complex declarative languages, that do
time and effort, and eliminating errors. OutSystems not extend SQL but are tailored to their data mod-
integrates natively with several of the major rela- els, as is the case with Neo4j. In all of these, the
tional database systems: SQL Server, SQL Azure, increasing complexity and expressiveness of the lan-
Oracle, MySQL, and DB2 iSeries. This allows the guage means that these have actually evolved to have
development of applications that access data in ex- query engines that, to some extent, perform query
ternal databases using the OutSystems entity model optimization and execution.
without having to worry about data migration. Inte- The selection of data stores to be analysed in the
gration with external databases involves: (1) In the context of this work was based on two criteria. First,
Service Center, defining a connection to the external variety, to include the most common NoSQL mod-
database; (2) In the Integration Studio, mapping ta- els, such as document-based, wide-column, pure key-
bles or views in the external database to entities in value and graph-based. Second, utility, targeting the
an extension module; (3) In the Service Studio, ref- most popular data stores, in each class, considering
erencing and using the extension in an application. the client base of the OutSystems platform.
The minimum requirements for NoSQL data stores
to be compatible with the OutSystems platform are:
3 Data stores (1) the ability to expose the database schema, to
enable the platform user to select the appropriate
NoSQL data stores, in general, forgo the require- databases, tables, attributes or equivalent constructs,
ment for a strict structure, sacrificing query process- explored in Section 4; (2) a compatible model (and
ing capabilities for flexibility and efficiency. While syntax) for expressing queries considering filtering
SQL became an ANSI standard, allowing queries operators such as selection and projection, ordering
to be executed in compatible RDBMS with few id- and grouping operators such as sort by and group by,
iomatic changes, NoSQL data stores offer a variety and aggregation operators for counting, summation
of data models, also supporting different data types and average; a compatible structure for consuming
and query capabilities. Additionally, most support query results, currently restricted to scalar values or
heterogeneity at each hierarchical level, allowing, for flat structures, i.e., no nested data.
example, rows of a given table to have different at- Additionally, it would be desirable to: enable visual
tributes. Values can be any type of object: For doc- construction of queries based on online partial results;
ument stores, values can be semi-structured JSON have the ability to take advantage of NoSQL-specific
documents, for example; for wide-column data stores, features; and provide client-side query simplification.
values can be variable sets of columns. This flexibility While the platform also supports a hierarchical
harms predictability, as additional knowledge (meta- model currently geared towards consuming data from
data) of what is being stored is required, as well as REST endpoints, data manipulation using the rela-
the ability to handle similar data items with irregular tional model is better supported, as the current query
structures. construction interface uses a tabular representation
NoSQL data stores have initially provided only for data. Also, it is a more natural fit for the guiding
minimal query capabilities. In fact, pure key-value principles of a low-code platform as it is more likely to
stores offer only minimal get, put, and delete oper- be familiar to developers. Focusing on this route for
ations. However, query capabilities in NoSQL data integration, for each examined data store, we eval-
stores have been enriched over time: by embedding uate: (1) the available query operations, including
different subsets and extensions of SQL, as is the case traversal of data, filtering, and computing different
with Cassandra, Couchbase, Hive and Cloudera; by aggregations (Section 3.1); (2) how such operations
evolving increasingly complex native query languages can be combined (Section 3.2); and (3) how to map
out of initially simplistic query mechanisms, as is the such operators and compositions to the OutSystems
case with MongoDB and Elasticsearch; and by actu- model (Section 3.3).
4HyperLogLogs, a probabilistic data structure used to
count unique items. Selection (filtering rows/records)
3.1 Query Operators and projection (filtering columns/attributes) opera-
tors are generally supported in NoSQL data stores,
The fitness of the relational model for interfacing with even if projections require defining paths on possibly
each NoSQL data store rests on: (1) the ability to ex- nested structures.
press a given operation in the data store’s model and The commands/keywords to make use of a given
query language, even if some translation is required feature in the particular data store are presented, in
and (2) on results being either scalar values or con- Figure 4, as a command where available, or a short
vertible to a tabular form. explanation of what is available, where convenient.
In order to use a relational notation with both MongoDB is a JSON-centric database system, us-
document-based and row-based models supporting ing it both as its data model and as its query lan-
nested structures (including collections) these must guage. It has thus been highly successful for Web
be flattened. One way to do this is to promote the applications where used together with JavaScript.
fields of the nested structure to outermost attributes Objects are grouped in collections, that are stored
and unnest lists, creating a separate row for each el- in databases. Each object is identified in the con-
ement of the list. text of a collection by the _id field for direct access.
As an example, consider the MongoDB document This field can be provided by the application with
shown in Figure 2. This document can be mod- any relevant content, or is otherwise automatically
elled as a relation, where the name of each attribute generated with a unique ObjectId. MongoDB can
is prefixed with a path to reach it in the original store relational data by introducing reference fields
model. The result from converting the document to that hold the value in the_id of the referenced docu-
this model is depicted in Figure 3. Data from other ment. Nonetheless, MongoDB encourages denormal-
documents in the same collection could be added as ization and storing related entities as a hierarchical
rows. If the schema is partial (or probabilistic), some structure in a single document. The native API for
rows will likely be missing some attributes. Natu- MongoDB is a JavaScript library, where queries are
rally, this step requires the schema to be retrievable, expressed as JSON documents. Similar APIs exist
whether explicit or inferred, a concern addressed in however for a variety of programming languages and
Section 4. platforms. First, this interface allows the application
This method can be extended to graph databases, to insert, retrieve, and delete documents directly ref-
for acyclic schemas. Using Neo4j as an example, con- erenced by their _id. Second, it allows searching for
sidering the information that can be retrieved regard- documents providing a document for matching. At
ing node and edge properties, a relational schema its simplest, this includes key-value pairs that need to
could be exposed with a relation per node type, with exist in the target documents. It allows also several
properties as attributes and a relation per edge type relational and boolean operators to be specified with
(relationship type in Neo4j). However, taking full keywords prefixed by the $ symbol, allowing com-
advantage of the capabilities of the graph model may plex expressions to be composed. In update opera-
not be as straightforward, such as, for example, using tions, the new value can also be computed by using a
the length of the path in a query. set of functions accessed also with $ keywords. The
Consider, instead, a key-value data model with col- db.collection.find() method retrieves all docu-
lections, such as Redis. While extracting a high-level ments that match a set of criteria defined over the
schema for the stored data from Redis is not gen- fields of the document. While, by default, all fields
erally feasible, it can be done on a per key basis, of matching documents are retrieved, the set of fields
first by listing the keys and querying the type of the to be projected can be defined in a projection doc-
associated value. Each value type can be straight- ument. Projection of elements in nested arrays can
forwardly converted to a tabular format, except for also be controlled. Couchbase is, like MongoDB, a
5{
_id: (hidden)
id: "store::1",
location: "Braga",
sells: [
{ widget: { id: "Widget1", color: "red" }, qty: 5 },
{ widget: { id: "Widget2", color: "blue" }, qty: 2 },
]
}
Figure 2: Example MongoDB document for a widget store.
id location sells.widget.id sells.widget.color sells.widget.qty Redis is used primarily for caching, with optional per-
store::1 Braga Widget1 red 5 sistence. Another usage pattern is to use Redis for
write-intensive data items, using a backing data store
store::1 Braga Widget2 blue 2
for other data.
store::2 Braga Widget1 blue 2
Apache Cassandra is a wide-column store inspired
by BigTable. Cassandra, however, supports super
Figure 3: Representation of a MongoDB document column families as an additional aggregate. It sup-
in a relational model. ports CQL, a SQL-like query language. Queries that
use relation traversal, i.e. the equivalent to JOINs in
the relational model, require either custom indices or
document store that uses JSON as its data model. secondary indices on would-be JOIN attributes to be
It provides a simple key-value interface and N1QL, available. Index creation is asynchronous.
a rich SQL-like query language. The outermost data Apache HBase is also a wide-column store, mod-
organization units are buckets, which group key-value elled on Google BigTable and implemented on the
pairs (items). Keys are immutable unique identi- Hadoop stack. HBase does not constrain data stored
fiers, mapped to either binary or JSON values. Like in keys, qualifiers (attributes), and values. Data
MongoDB, relations between documents can be cre- items have therefore to be serialized to byte arrays
ated either by referencing other documents by key before storage and deserialized back upon retrieval.
or through embedding, creating a hierarchical struc- HBase natively offers a simple Java client API and
ture. Selection and projection are similar to SQL’s no query language. Selection is implemented by ei-
but dealing with nested structures such as arrays, re- ther retrieving a single or multiple rows, given the
quires explicitly unnesting these, using the UNNEST keys and an optional upper bound on the timestamp,
clause. or by scanning a range of rows, given (optional) start
Redis is an in-memory key-value store using strings and stop keys, optionally providing a filter expression
as keys and where values can be strings or data struc- comparing a value to a provided constant. Projec-
tures such as lists, sorted or unsorted sets, hash tion is supported through the definition of a subset
maps, bit arrays and HyperLogLogs, probabilistic of qualifiers to be retrieved.
data structures used to count unique items, trading Amazon DynamoDB is a large scale distributed
in precision for space savings. Querying over values data store offered as part of Amazon Web Services.
is not supported, only queries by key. The alterna- Data is stored in tables, where rows are identified by
tive is costly: a full scan, returning key-value pairs simple or composite primary keys. If using a simple
that match a specified condition. In terms of projec- primary key, it serves as the partition key. Composite
tion, either a single attribute is retrieved or all are. primary keys are limited to two attributes, where the
6first attribute is also used as a partition key and the Cypher, a declarative graph query and manipulation
second is used for sorting the rows. Selection and pro- language. It natively supports graph concepts such as
jection capabilities are similar to those described for paths and matching on graph structure. Along with
HBase. Answering queries that use relation traversal SQL-like selection and projection capabilities on the
efficiently requires creating secondary indexes. How- data attached to nodes and edges, attributes such as
ever, the number of indices that can be created is the length of a path can also be specified.
limited. The costly alternative is to use table scans
and combine data client-side. Apache Hive and Cloudera Impala are analytic
Elasticsearch is a document store focusing on text query engines for a SQL-like query language using,
indexing and retrieval, primarily developed as a dis- preferably, data stored in HDFS files. Hive is built
tributed version of the well known Lucene text in- on top of Hadoop and translates queries to MapRe-
dexing library. It uses the well known JSON format duce jobs. Impala translates queries to a traditional
as its base data model and groups JSON objects in Volcano-style parallel execution plan. They share the
collections called “indexes". Each object in an index same client API, most of the language, and some of
has a unique identifier used for direct access. It is the infrastructure, namely, for storage and metadata.
expected that each of these indexes contains a fairly Data can be organized in rich hierarchical structures,
homogeneous set of objects, with mostly the same at- that are however strongly typed. Nevertheless, pro-
tributes and being used for the same purpose. Elas- cessing is done in terms of flat rows.
ticsearch allows a very limited form of relational data
by introducing document parent-child relationships. Figure 4 also presents the output format for query
This allows splitting very large documents that con- results. While some of the analysed data stores
tain many sub-elements and would be inefficiently present results in document or row-based data models
managed, while maintaining the ability to traverse with nested structures, these can be easily converted
them together in some operations. This possibility to a tabular format using the already discussed tech-
has however many restrictions and the documenta- niques, fulfilling requirement (2).
tion emphatically discourages its generalized use. Se-
lection and projection are supported either in the na- Regarding sorting, grouping and aggregation op-
tive API or an experimental SQL-like API. erators, Figure 5 shows the commands/keywords to
Neo4j is a graph data management system based make use of the given feature in the particular data
on the Java platform. The graph data model and op- store, presented as a command where available, or
erations make it a very different alternative to most a short explanation of known limitations where con-
other well known NoSQL systems. Information is venient. Redis only sorts elements in a data struc-
represented as a directed graph defined as a set of ture (list, set, sorted set) stored for a specific key.
named nodes and a set of edges, each connecting a Again, support for SQL-like commands in Elastic-
source node to a target node. Additional informa- search is experimental. Cassandra supports sorting
tion can then be attached to nodes and edges in one only on one of a table’s attributes, the first cluster-
of two ways: as a single tag, that is a symbolic iden- ing column, while grouping can only be done using
tifier with particular significance as metadata and for the partition key. DynamoDB has similar restric-
indexing; or as a set of named properties, that can tions on ordering. Aggregates require creating in-
have various types and hold arbitrary data. Values dexes/materialized views, precluding ad-hoc queries.
of types attached to properties, that can be manipu- Results in HBase are sorted in a fixed order, using the
lated in queries, can be both primitive types such as row key for the outermost comparison. Aggregates
numbers or strings, but also composite values such as can be implemented in HBase using coprocessors.
lists and maps. This means that the data attached to Remaining data stores implement sorting, grouping
nodes and edges can be nested in structures as typical and aggregation operators that are compatible with
of JSON documents. The main interface to Neo4j is SQL’s, indicated in the column header.
73.2 Query Construction
Elementary operators such as projection and selec-
Selection Projection Output tion can be combined into complete query expres-
MongoDB db.collection.find() projection document JSON sions. On one extreme, data stores with limited query
$, $elemMatch
capabilities allow only simple fixed combinations of
Couchbase WHERE clause SELECT JSON
supported operators. For instance, HBase allows pro-
Redis by key or
SCAN with MATCH
single attribute or all scalar or
flattened array
jection and selection to be optionally specified for
Cassandra WHERE clause (partial) SELECT tabular
each query. On the other extreme, data stores allow
arbitrary combinations of operators to be submitted
HBase by key or addFamily() flattened map
SCAN with filter addColumn() and often perform an optimization step, reordering
DynamoDB by key or SCAN with ProjectionExpression JSON and transforming the proposed expression for efficient
FilterExpression
Selection Projection Output execution. This section focuses on the latter, namely
ElasticSearch
MongoDB
match clause
db.collection.find()
WHERE
_source
projection document
SELECT
JSON
JSON
tabular on the MapReduce, pipeline and tree query construc-
$, $elemMatch
Neo4j MATCH … WHERE RETURNING tabular or JSON
tion paradigms.
Couchbase WHERE clause SELECT JSON
Hive/Cloudera WHERE clause SELECT tabular MapReduce is a particular query construction ap-
Redis by key or single attribute or all scalar or
SCAN with MATCH flattened array proach as it always assumes an intermediate grouping
Cassandra
Figure WHERE clause (partial)
4: Sorting
Selection
(ORDER BY) and Projection
Grouping
SELECT
(GROUP BY) operators
Aggr.
tabular
(COUNT, SUM,in
operation. Briefly, it works as follows: The first step,
NoSQL dataSCAN
HBase
stores.
by key or addFamily()
…)
flattened map Map, allows an arbitrary function to translate each
with filter
MongoDB $orderby
addColumn()
$group yes data item in an input collection to zero or more out-
by key or SCAN with
DynamoDB
Couchbase FilterExpression
ORDER BY
ProjectionExpression
GROUP BY yes
JSON
put keys and values, usually, to filter and transform
ElasticSearch match clause _source JSON
data. In a second step, data items are grouped by
Redis SORT (partial) no no
WHERE SELECT tabular key and Reduced, allowing an arbitrary function to
Cassandra
Neo4j ORDER MATCHBY …(partial)
WHERE (partial)
GROUP BYRETURNING yes or JSON
tabular process the set of values associated with each key,
Hive/Cloudera
HBase not clause
ad-hoc
WHERE not ad-hoc
SELECT tabular
not ad-hoc usually to aggregate them. Often, multiple map and
DynamoDB partial/fixed not ad-hoc not ad-hoc reduce stages can be used, thus allowing more com-
Elasticsearch
Sorting (ORDER BY)
sort/terms.order
Grouping (GROUP BY)
terms
Aggr. (COUNT, SUM,
sort.mode
plex queries that group by different criteria in differ-
…)
ORDER BY GROUP BY yes ent stages. MapReduce jobs are mostly used to asyn-
MongoDB
Neo4j
$orderby
ORDER BY
$group
RETURN
yes
yes
chronously perform table scans and build secondary
Couchbase ORDER BY GROUP BY yes indexes, that enable these stores to offer querying ca-
Hive/Cloudera yes
Redis
ORDER BY
SORT (partial)
GROUP BY
no no
pabilities that are expected of the relational model:
materialised views, aggregations, etc. MapReduce
Cassandra ORDER BY (partial) GROUP BY (partial) yes
can be used to execute relational equi-JOINs by using
HBase not ad-hoc not ad-hoc not ad-hoc
the join key for grouping, as generating all possible
DynamoDB partial/fixed not ad-hoc not ad-hoc matches with a reducer. In this perspective, con-
Elasticsearch sort/terms.order terms sort.mode suming MapReduce results can be done within the
ORDER BY GROUP BY yes relational model, as long as these come in (or are
Neo4j ORDER BY RETURN yes easily translatable to) tabular form, possibly with an
Hive/Cloudera ORDER BY GROUP BY yes
inferred schema. First, MapReduce focuses on ana-
. lytical workloads, that read most of or all input data,
resulting in poor interactive performance. Moreover,
Figure 5: Sorting, Grouping and Aggregation opera- limiting the specification of MapReduce tasks to SQL
tors in NoSQL data stores. may be undesirable. An argument can be made for
considering that the specification of MapReduce jobs
requires sufficient expertise to fall outside of the typ-
ical utilization of the platform, making it available
8through a low-level extension. Figure 7 summarizes the supported query con-
A more general query construction approach is to struction paradigms per data store, presenting either
allow arbitrary operators to be chained in a linear the method or concept that provides the capability.
pipeline. The first operator reads data, often with Redis supports only a key-value interface, there-
an implicit selection and projection. Each operator fore, having no query construction capabilities. Ama-
does some transformation, such as grouping and ag- zon’s DynamoDB supports only simple queries by pri-
gregation, and sends data to the next. An example of mary key (or a range thereof) with optional filtering
this approach is provided by MongoDB’s aggregation applied just before the data is returned.
pipeline. Figure 6 demonstrates how this approach
can be used over a denormalized schema, in which all
3.3 Discussion
data for a store is kept in a single document:
While this is not the most natural way to express The main conclusion of the analysis is that the rela-
this query in MongoDB, it is however a simple ex- tional model is to a large extent able to map enough of
ample of an aggregation pipeline. The query first NoSQL data stores to fit the OutSystems’ low code
filters stores located in “Braga" and projects only the platform. This means that the current aggregation
required fields. Then it unwinds the “sells" array, model, designed primarily for relational data, can be
producing a document for each item sold. It then adequately used to describe most query operators and
projects the required fields and filters widgets with construction schemas found in NoSQL data stores.
color “red". This approach has several advantages. This is a consequence of two aspects. First, of the
First, it can express a large subset of all queries pos- completeness of the relational model, that can map
sible with SQL. In fact, the linear chain of operators most operators and query construction approaches
precludes only JOIN operations where more than one found in NoSQL data stores, requiring only an ex-
data source would be required, and some sub-queries, tension to support nested data. Second, of the trend
i.e., mainly those that are equivalent to JOIN oper- for NoSQL data stores to increasingly provide SQL
ations. Second, the pipeline transformation of data support, in particular, by using unwind/unnest oper-
is intuitive, as the same paradigm is used in various ations to deal with denormalized and nested data.
forms in computer interfaces. Finally, data stores An exception to this is the ability to directly de-
supporting this paradigm also tend to include query scribe a MapReduce operation (MongoDB, Couch-
optimizers, that reorder operators to produce an effi- base, HBase). The MapReduce paradigm fits in this
cient execution plan. This means that a query can be vision as a background workhorse to pre-process data,
incrementally built without being overly concerned e.g. creating secondary indexes or materialized views,
with its efficiency. to endow NoSQL data stores with sorting, grouping
The most general approach is to allow arbitrary or aggregation operations required for approximating
data query expressions that translate to operator SQL support. Some data stores provide this func-
trees. This allows expressing relational JOIN op- tionality automatically, which others require user in-
erations between data resulting from any two sub- tervention. In any case, as long as the results of a
queries. It also allows a general use of sub-queries MapReduce job can be converted to a nested tabular
whose results are used as inputs to other operators. format, these can be consumed in the context of the
The main advantage of this approach is that it is what relational model. When not supported by the data
has traditionally been done with SQL databases. store, some SQL features can be implemented with
Ironically, NoSQL data stores therefore increasingly client-side processing or a middleware solution. For
provide SQL-like dialects and query optimizers. This example, projection can be fully supported in Redis
allows existing low-code query builders designed for with client-side filtering before returning data to the
SQL databases to be reused with minor modifica- platform user. A second exception is needed to take
tions, mainly, to what functions and operators are advantage of specific NoSQL features. For example,
available. to take advantage of features such as the added query-
9{ aggregate: "stores", pipeline: [
{ $match: { location: { $eq: "Braga" } } },
{ $project: { id: 1, location: 1, sells: 1 } },
{ $project: { expr000: "$sells", expr001: "$id" } },
{ $unwind: "$expr000" },
{ $project: { sid: "$expr001", ITEM: "$expr000.widget.color" } },
{ $match: { ITEM: { $eq: "red" } } },
{ $project: { sid: 1 } }
], cursor: { batchSize: 4095
}, allowDiskUse: true, $readPreference: { mode: "secondaryPreferred"
}, $db: "storesdb"
}
Figure 6: Pipeline query construction.
ing features the graph model brings Neo4j, more ex- is a formal description that exposes the underlying
pertise than intended for using a low-code platform structure of data.
may be required. Still, this can be supported by en- Currently, for integration with a data source, the
abling advanced users to edit the query itself. On a platform must be able to list available databases, list
different note, Redis exposes its data as simple data tables per database and to retrieve a schema for the
structures. It might make sense to allow the user to data. Providing a schema to the platform is key to
compose several of these structures into a material- the low-code approach for data integration, as pre-
ized view, providing, in fact, an external schema for senting the schema to the user, along with data sam-
the stored data. ples, is required for queries to be defined visually.
To summarize the expected development effort: For relational databases, the schema consists of re-
lations or entities (typically represented as tables),
1. There is no need to modify (any of these) NoSQL their attributes (including data types) and, poten-
data stores for integration with the OutSystems tially, the cardinality associated to the referential
platform. relationships between them. For NoSQL databases
based on a document model, using MongoDB as an
2. Client-side or in-middleware computation should
example, the schema for a database should include
be limited to: (a) when needed, converting re-
existing collections, document fields for each collec-
sults to a tabular format (b) when needed, filling
tion, including data types and, potentially, referential
in for operators that are either missing from the
relationships. However, while relational schemas are
data store or cannot be used ad-hoc; and (c) con-
flat, strict and deterministic, the flexibility of adding
vert SQL to native query languages or SQL-like
documents with different fields to the same collection,
dialects.
having fields with the same name holding values of
3. Add support for nesting and unnesting opera- different types and the ability to define nested struc-
tions to the OutSystems platform (see Figure 4). tures, make it harder to elicit a complete and accurate
schema of the data.
4 Schema Discovery 4.1 Third-party tools
Offering a uniform view of unstructured data requires Figure 8 summarizes the schema-related metadata
data types to be well defined and the definition of a that can be retrieved or inferred from each of the
schema to which the data must conform. A schema analysed data stores, using currently available tools.
10Cells marked N/A indicate there is no comparable
concept in the store’s data model. Partial schema
inference refers to cases where nested structures are
opaque.
MapReduce Pipeline Tree A wide range of NoSQL data stores explicitly store
MongoDB db.collection.mapReduce() db.collection.aggregate() no and provide metadata, a confirmation of the JSON
Couchbase "views" no N1QL
data model, that allows nested data collections, as a
common trend for data structuring and representa-
Redis no no no
tion. There are however minor differences in what
Cassandra no no CQL data types can be attached to values and even how
HBase co-processors(no grouping) no no much nesting is allowed.
DynamoDB no execute, then filter no Second, NoSQL data stores vary widely in which
metadata can be obtained. On one end, systems
Elasticsearch no “aggregations” no
such as Cassandra, Hive, and Cloudera Impala store
MapReduce Pipeline TreeQL
Neo4j no no Cypher
and enforce a user-defined schema that unambigu-
MongoDB
Hive/Cloudera db.collection.mapReduce()
no db.collection.aggregate()
no no
SQL ously describes data. On the other end, systems
.
Couchbase "views" no N1QL such as HBase do not provide any support for setting
Figure
Redis 7: Query noconstruction paradigms no in NoSQL
no or enforcing a schema. As they store just arbitrary
data stores.
Cassandra list databases
no list tables/collections
no retrievable schema
CQL
byte sequences, the schema cannot also be easily in-
MongoDB yes yes inferred, probabilistic
ferred. They are however frequently used with third-
HBase co-processors(no grouping) no no
Couchbase yes yes inferred, probabilistic
party query mechanisms, that provide the missing
DynamoDB
Redis
no
yes
execute, then filter
yes (keys)
no
generally N/A
metadata. HBase, for example, is often used in the
Elasticsearch no “aggregations” no Hadoop stack with Hive. In between, systems such as
DynamoDB N/A yes explicit, partial
Neo4j no
MongoDB, Couchbase, Elasticsearch and Neo4j allow
Cassandra yes yes no Cypher QL
explicit
the schema to be inferred from currently stored data
HBase
Hive/Cloudera N/A
no yes no noSQL
and even provide optional mechanisms to enforce it.
Hive/Cloudera yes yes explicit
For example, using MongoDB it is possible to define
ElasticSearch N/A yes (indexes) inferred, partial
a set of rules over the attributes of documents be-
Neo4J N/A yes (nodes/rels.) inferred, partial
list databases list tables/collections retrievable schema longing to a given collection. Validation is defined
MongoDB yes yes inferred, probabilistic at the collection level and conditions can require a
Couchbase yes yes inferred, probabilistic document to contain a given set of attributes, with
Redis yes yes (keys) generally N/A a given type, set attribute-level boundary conditions,
DynamoDB N/A yes explicit, partial or require values to match a given regular expression.
Cassandra yes yes explicit In effect, introducing validation limits the variability
HBase N/A yes no of the structure of JSON documents.
Hive/Cloudera yes yes explicit Mechanisms used to infer schema from MongoDB
ElasticSearch N/A yes (indexes) inferred, partial and Couchbase can, in principle, be applied to other
Neo4J N/A yes (nodes/rels.) inferred, partial
schema-less data stores, by adapting existing tools or
. by implementing similar ones. In short, tools such
as mongodb-schema1 analyze a sample of documents
Figure 8: Retrievable schema-related metadata from
stored in a given collection and provide, as outcome,
each NoSQL data store.
a probabilistic schema. Fields are annotated with a
probability according to how frequently these occur
in that collection’s sampled documents. Fields are
1 https://github.com/mongodb-js/mongodb-schema
11also annotated with a set of data types: each data port for nested data structures, integrating schema
type is itself annotated with a probability according inference/extraction techniques, as proposed and de-
the mapping’s occurrence in the sampled documents. scribed in Section 5.1.
There is also mongodrdl2 , a tool for inferring a rela-
tional schema from a MongoDB database or collec- 4.2 Improving current tools
tion, which, however, in our experiments, fell short of
accurately representing some relationships between Here, we briefly consider research results, for which
unnested array elements and top-most attributes. runnable systems are not generally available, but
A similar concern holds for using data sources with which nonetheless can contribute relevant ideas and
polyglot query engines, as these enable expressing techniques. Generic schema inference/discovery fo-
data processing operations over systems that expose cuses on discovering, for a set of semi-structured
multiple native data models and query languages. data, how these can be generically represented as
Dremio OSS performs schema inference, but treats sets of attributes (entities) of a given type (or set
nested structures as opaque and, therefore, does not thereof), optionally identifying relationships between
completely support low-code construction of unnest- entities (e.g., references) and constraints (e.g. that a
ing operations, in the sense that the user still needs given attribute is required to be non-null). Proposals
to explicitly handle these. Still, it provides the abil- are typically motivated by the necessity of designing
ity to impose a table schema ad-hoc or flexibly adapt client applications that can take advantage of a semi-
data types which is a desirable feature for overriding structured data source for which a schema is unknown
incorrect schema inference. with earlier work focused mainly on XML data. One
With PostgreSQL FDW, it is possible to declare approach, is to involve the user in schema discovery
tables for which query and manipulation operations by exposing generated relational views of the JSON
are delegated on adapters. The wrapper interface in- data to users so that these can help clusters records
cludes the ability to either impose or import a schema as collections and mark or validate relationships be-
for the foreign tables. Imposing a schema requires the tween entities [22]. While the goal of this partic-
user to declare data types and structure and it is up ular work is to ultimately provide a flat relational
to the wrapper to make it fit by using automatic type schema of the JSON data, concerns such as minimis-
conversions as possible. If this automatic process is ing the number of collections in the final schema and
not successful the user will need to change the spec- introducing relationships between entities might have
ified data type to provide a closer type match. The a significant impact in the effectiveness of querying
wrapper can also (optionally) advertise the possibil- JSON data, an aspect that is not assessed by the
ity of importing a schema. In this case, the user sim- authors. This type of approach seems to be better
ply instructs PostgreSQL to import meta-data from suited for data exploration than for integrating data
the wrapper and use it for further operations. This sources with applications in a low code setting.
capability is provided by the wrapper and currently, It has also been proposed that machine learning
this is only supported for SQL databases, for which can be used to generate a relational schemas from
the schema can be easily queried. Furthermore, Post- semi-structured data [6]. However, while the au-
greSQL FDW can export the schema of the created thors did perform a preliminary assessment of the
foreign tables. Both for Dremio and PostgreSQL, query performance on the generated schemas, queries
limitations in schema imposition/inference do not im- were performed on the data loaded onto a relational
pact querying capabilities, only the required talent database. Results from this assessment do not nec-
to use the system. For PostgreSQL FDW, this can essarily hold when queries (operations) are pushed
be mitigated by extending adapters to improve sup- down to a NoSQL store.
A commonly identified pattern is that the same
2 https://docs.mongodb.com/bi-connector/current/ conceptual object can be represented by documents
reference/mongodrdl/ that differ in a subset of fields, or have fields with
12different types, as a consequence of the schema-less of abstractions that have to be learned by the devel-
nature of semi-structured data. This effect can be opers to fully use it. Moreover, these abstractions
captured as coalescing these slightly different effective change with support for additional NoSQL systems
schemas as different versions of the same document and are not universally applicable. In fact, support
schema. In [18], the authors propose a method based for different NoSQL systems would be very different,
on model-driven engineering to do just that. making it difficult to use the same know-how to de-
A significantly different approach for schema dis- velop applications on them all. Finally, building and
covery is to analyse application source code to dis- maintaining the platform itself would require a lot
cover the schema implicitly imposed by the applica- of talent and effort in the long term, as support for
tion on schema-less data sources. In [4], the authors additional systems could not be neatly separated in
propose such a method for applications that use re- plugins with simple, abstract interfaces.
lational and NoSQL data sources. While currently On the other hand, we can map all data in different
out-of-scope, it might be interesting to offer this type NoSQL systems to a relational schema with standard
of capability to ease the migration of applications to types and allow queries to be expressed in SQL. This
the OutSystems platform. results in a mediator/wrapper architecture that al-
lows the same queries to be executed over all data
regardless of its source, even if by the query engine
5 Architecture at the mediator layers.
This approach also has drawbacks. First, mapping
Considering the conclusions from surveying a vari- NoSQL data models to a relational schema requires
ety of NoSQL systems, in particular, regarding their developer intervention to extract the view that is ade-
supported data and query models, we describe the quate to the queries that are foreseen. This will most
architecture for a polyglot data access layer for a low- likely require NoSQL-specific talent to write target
code application platform, and then discuss a proof- queries and conversion scripts. Moreover, query ca-
of-concept implementation based on existing open pabilities in NoSQL systems will remain largely un-
source components. used, as only simple filters and projections are pushed
Our proposal is based on two main criteria. First, down, meaning the bulk of data processing would
how it contributes to the vision of NoSQL data inte- need to be performed client-side.
gration in the low-code platform outlined in Section 1 Our proposal is a compromise between these two
and how it fits the low-code approach in general. extreme approaches, that can be summed up as: sup-
Second, the talent and effort needed for developing port for nested data and its manipulation in the ab-
such integrations and then, later, for each additional stractions shown to the low-code developer, along
NoSQL system that needs to be supported. with the ability to push aggregation operations down
We can consider two extreme views. On the one to NoSQL stores from a mediator query engine, will
hand, we can enrich the abstractions that are ex- account for the vast majority of use cases. In addi-
posed to the developer to encompass the data and tion, the ability to embed native query fragments in
query processing models. This includes: data types queries will allow fully using the NoSQL store when
and structures, such as nested tuples, arrays, and talent is available, without disrupting the overall inte-
maps; query operations, ranging from general pur- gration. The result is a polyglot query engine, where
pose data manipulation (e.g., flattening a nested SQL statements are combined with multiple foreign
structure) to domain-specific operations (e.g., regard- languages for different NoSQL systems.
ing search terms in a text index); and finally, where The proposed architecture is summarized in Fig-
applicable, query composition (e.g., with MapReduce ure 9, highlighting the proposed NoSQL data ac-
or a pipeline). cess layer. To the existing OutSystems platform, en-
This approach has however several drawbacks. compassing development tools and runtime compo-
First, it pollutes the low-code platform with a variety nents, we add a new Polyglot connector, using the
13times. The Job Scheduler enables periodically re-
freshing materialized views by re-executing their cor-
responding queries.
5.1 Implementation
We base our proof-of-concept implementation on
open source components. In this section we start
by describing how we selected those components and
then describe the additional development needed to
make it fit the proposed architecture. We base
our proof-of-concept implementation on open source
components.
5.1.1 Component selection
The main component to select is the SQL query
engine used as the mediator. Besides its features
as a query engine, we focus on: the availability of
wrappers for different NoSQL systems and the talent
needed to implement additional features; the com-
Figure 9: Architecture overview patibility of the open source license with commer-
cial distribution; the maturity of the code-base and
supporting open source community; and finally, on
its compatibility with the OutSystems low-code plat-
Database Integration API to connect to the Polyglot
form. We consider two options.
Query Engine (QE) through standard platform APIs.
PostgreSQL with FDW[17]. It is an option as
The Polyglot QE acts as a mediator. It exposes an
it supports foreign data wrappers according to the
extended relational database schema for connected
SQL/MED standard (ISO/IEC 9075-9:2008). The
NoSQL stores and is able to handle SQL and poly-
main attractive for PostgreSQL is that it is a very
glot queries.
mature open source product, with a business friendly
For each NoSQL Store, there is a Wrapper, com- license, a long history of deployment in production,
posed of three sub-components: metadata extraction, and an unparalleled developer and user community.
responsible for determining the structure of data in There is also support for .NET and Java client appli-
the corresponding store using an appropriate method cation platforms. In terms of features, PostgreSQL
and mapping it to the extended SQL data model of provides a robust optimizer and an efficient query
the Polyglot QE; a query push-down component, able engine, that has recently added parallel execution,
to translate a subset of SQL query expressions, to with excellent support for SQL standards and mul-
relay native query fragments, or produce a combina- tiple useful extensions. It supports nested data
tion of both in a store-specific way; and finally, the structures both with the json/jsonb data types, as
cursor, able to iterate on result data and to translate well as by natively supporting arrays and composite
and convert it as required to fit the common extended types. It has extensive support for traversing and
SQL data model. unnesting them. Regarding support for foreign data
The Polyglot QE makes use of Local storage for the sources, besides simple filters and projections, the
configuration of NoSQL store adapters and for hold- PostgreSQL Foreign Data Wrapper (FDW) interface
ing materialized views of data to improve response can interact with the optimizer to push down joins
14and post-join operations such as aggregations. With but treats nested structures as opaque and, therefore,
PostgreSQL FDW, it is possible to declare tables for does not completely support low-code construction of
which query and manipulation operations are dele- unnesting operations, in the sense that the user still
gated on adapters. The wrapper interface includes needs to explicitly handle these. Still, it provides the
the ability to either impose or import a schema for ability to impose a table schema ad-hoc or flexibly
the foreign tables. Imposing a schema requires the adapt data types which is a desirable feature for over-
user to declare data types and structure and it is up riding incorrect schema inference. Also, Dremio OSS
to the wrapper to make it fit by using automatic type adds a distributed parallel execution engine, based on
conversions as possible. If this automatic process is the Arrow columnar format, and a convenient way to
not successful the user will need to change the spec- manage materialized views (a.k.a., “reflections”), that
ified data type to provide a closer type match. The are automatically used in queries. Unfortunately, one
wrapper can also (optionally) advertise the possibil- cannot define or use indexes on theses views, which
ity of importing a schema. In this case, the user sim- reduces their usefulness in our target application sce-
ply instructs PostgreSQL to import meta-data from narios.
the wrapper and use it for further operations. This Although Calcite has a growing user and devel-
capability is provided by the wrapper and currently, oper community, its maturity is still far behind Post-
this is only supported for SQL databases, for which greSQL. The variety of adapters for different NoSQL
the schema can be easily queried. Furthermore, Post- systems is also lagging behind PostgreSQL FDW, al-
greSQL FDW can export the schema of the created though some are highly developed. For instance, the
foreign tables. In addition to already existing wrap- MongoDB adapter in Dremio OSS is able to exten-
pers for many NoSQL data sources, with variable fea- sively translate SQL queries to MongoDB’s aggrega-
tures and maturity, the Multicorn3 framework allows tion pipeline syntax, thus being able to push down
exposing the Python scripting language to the devel- much of the computation and reduce data transfer.
oper, to complement SQL and express NoSQL data The talent and effort needed for exploiting this in ad-
manipulation operations. ditional data wrappers is, however, substantial. Both
In terms of our goals, PostgreSQL falls short on for Dremio and PostgreSQL, limitations in schema
automatically using existing materialized views in imposition/inference do not impact querying capa-
queries. The common workaround is to design queries bilities, only the required talent to use the system.
based on views and later decide whether to materi- For PostgreSQL FDW, this can be mitigated by ex-
alize them, which is usable in our scenario. Another tending adapters to improve support for nested data
issue is that schema inference is currently offered for structures, integrating schema inference/extraction
relational data sources only. The workaround is for techniques. Finally, the main drawback of this option
the developer to explicitly provide the foreign table is that, as we observed in preliminary tests, resource
definition. usage and response time for simple queries is much
Calcite[1] (in Dremio OSS[7]). The Calcite higher than for PostgreSQL.
SQL compiler, featuring an extensible optimizer, is Choosing PostgreSQL with FDW. In the end,
used in a variety of modern data processing systems. we found that our focus on interactive operational
We focus on Dremio OSS as its feature list most applications and the maturity of the PostgreSQL op-
closely matches our goal. Calcite is designed from tion, outweigh, for now, the potential advantages
scratch for data integration and focuses on the abil- from Calcite’s extensibility.
ity to use the optimizer itself to translate parts of the Additional development Completing a proof-of-
query plan to different back end languages and APIs. concept implementation based on PostgreSQL as a
It also supports nested data types and corresponding mediator requires additional development in the low-
operators. Dremio OSS performs schema inference, code platform itself, an external database connector,
and in the wrappers. As examples, we describe sup-
3 https://github.com/Kozea/Multicorn port for two NoSQL systems. The first is Cassandra,
15You can also read

















































