Year of optimizations on the first scalar
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
1 year of optimizations
on the first scalar
Cliquez pour modifier le style du titre
supercomputer
of Meteo-France
Cliquez pour modifier le style des
P. Marguinaud & R. El Khatib (Météo-France)
sous-titres du masque
24th Aladin Workshop – Hirlam All Staff Meeting 2014
1
Bucharest 07-10/04/2014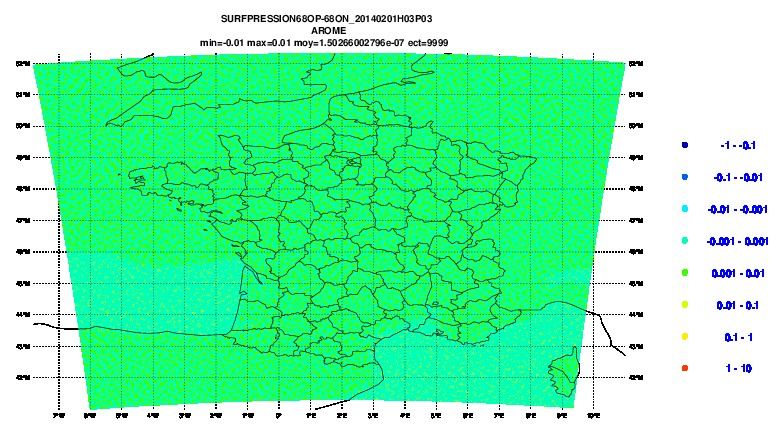
Plan
Main changes in the software configurations
Specific optimizations for ARPEGE
Parallelization of FESTAT
FULLPOS-2
– Optimizations
– The Boyd biperiodicization
Other enhancements
– post-processing server
– FA-LFI
– IO server
2
Main changes in the software configurations
Feature On NEC at M-F On Bull at M-F
NPROMA Large value (~3582) Small value (~50)
MPI gridpoint North-South only North-South
distribution and East-West
MPI spectral On waves only On waves
distribution and on vertical levels
LEQ_REGIONS .FALSE. .TRUE. (except for
(ARPEGE) AROME couplers)
MPI « I/O » Maximum values
distribution Small values unless
(NSTRIN,NSTROUT) I/O server
LOPT_SCALAR .FALSE. .TRUE. (to be revisited)
Open-MP Not used Used
(but not yet in 3DVar)
3
Specific optimizations for ARPEGE
Computation of Gaussian reduced grids :
– Merged with ECMWF program
– Optimized even more for Open-MP
Computation of filtering matrixes for the post-processing :
– Calculation of dilatation/contraction matrixes :
• fully recoded to use the algorithm of Strassauber for Legendre
polynomial computation
• Distributed/parallelized
• Modular
– Calculation of filtering matrixes themselves
• Distributed/parallelized
• Interfaced with the modular calculation of dilatation/contraction matrixes
=> On-line recomputation of filtering matrixes is fast.
No need anymore for huge matrixes on files.
4Parallelization of FESTAT (1)
FESTAT : Forecast Error STATistics :
a mono-task program developped during the years 1993-1997
which reads a lot of files and makes a lot of summations
Substantial re-write and cleaning, DrHook instrumentation
Optimizations by inverting loops and re-organization of calculations
in order to limit repeated computations
Memory savings
Development of an « in-core » option to read the files only once
MPI distribution on the files => needs to re-order the summation
independently of the members for bitwise reproducibility
MPI distribution + Open-MP parallelization on the k* wave numbers
MPI distribution on the m waves is possible but not coded yet
5Parallelization of FESTAT (2)
6000
Efficiency
Real time (s) 5000
4000
3000
2000
1000
0
4
8
16
22
8
12
27
36
54
Number of nodes
10
Scalability
30
25
20
Speed Up
15
10 Festat
5 Ideal
0
16
54
4
8
12
22
27
36
8
10
Number of nodes
108 members, 90 levels, truncation 719 x 767
72 nodes (54 tasks x 12 threads) => 11 min.
6Parallelization of FESTAT (3)
&NAMFESTAT
Getting started with parallel FESTAT : NFLEV=60,
NCASES=72,
OMP_NUM_THREADS=$(number of threads) LSTABAL=.true.,
LANAFBAL=.true.,
Namelist file NAMFESTAT in fort.4 OUTBAL='stabbal',
OUTCVT='stabcvt',
mpirun -np $(number of mpi tasks) FESTAT OUTCVU='stabcv',
ELON1=351.613266296832,
ELAT1=37.33305050,
100 % in memory Partly on disk
ELON2=15.74536410,
40000 ELAT2=53.02364987,
35000
ELON0=2.00000000,
30000
ELAT0=45.80000000,
Billing units
25000
NMSMAX=374,
20000
NSMAX=359,
15000
10000 NDGL=720,
5000 NDLON=750,
0 NDGUX=709,
1 2 3 4 5 6 7 8 9 10 NDLUX=739,
Number of member files per node EDELY=2500.00000000,
EDELX=2500.00000000,
LELAM=.TRUE.,
=> read festat_guidelines.pdf for more /
7Optimization of Fullpos-2
Efficiency Cost of FULLPOS-927 vs FULLPOS-2
Cycle 40 Cycle 40t1 Coupling ARPEGE T1198 to AROME 1.3 km
100 140
90 120
80 100
Real time (s)
Real time (s)
80
70
60
60
40
50
20
40
3 4 5 6 0
=9 =9 =3
Number of nodes D ES D ES D ES
7 NO NO NO
92 -2 -2
P- FP FP
F
8The Boyd biperiodicization in Fullpos-2 (1)
In New developments have been added :
– The interpolation grid and the target grid can be different
– => Needs to move the biperiodicization
immediately after the horizontal interpolation
– => Makes less MPI communications
– => Biperiodicization code is easier to maintain
– => Switching from splines to Boyd biperiodicization
becomes easy :
just set in namelist NAMFPC:
NFPBOYD=1
9The Boyd biperiodicization in Fullpos-2 (2)
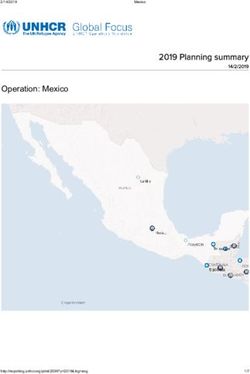
Difference Splines/Boyd on the U-wind at the lowest level
10The Boyd biperiodicization in Fullpos-2 (3)
Difference of the biperiodicization Before/After the vertical
interpolations on the U-wind at the lowest level
11Fullpos-927 will no longer be supported
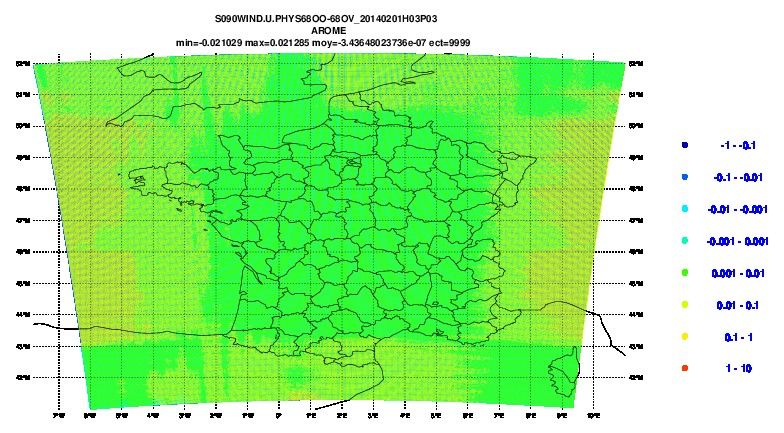
in cycle 41
Difference between NFPOS=927 and NFPOS=2
on surface pressure
12Post-processing server
Start the model once, post-process multiple files (same geometry)
→ save the setup time
Simple design (loop in cnt2)
Simple to use (test case available – ask P. Marguinaud)
Savings ~ 20 %
FA - LFI
FA and LFI have a thread safe interface
→ possible to read/write multiple files using OpenMP
– OK with GRIB Edition 0
– Not yet with GRIB Edition 1 (aka Gribex)
13IO server
Field transposition is now performed by the IO server tasks (no more
GATH_GRID/GATH_SPEC in the model)
Synchronization tools (retrieve model data as soon as produced) ; test
case available – ask P. Marguinaud
The IO server creates several files for each forecast term
→ make the LFI library handle this transparently, no need to
concatenate files (an index is created over multiple LFI files)
Read coupling files with the IO server ; saves 2.5 % of time on AROME
1.3 km
14Summary / Conclusion
Ready for higher resolutions :
– Arome 1.3 km L90
– Arpege T1198L105
Among next plans :
– Toward higher scalability
• Fullpos-2 in a single 4DVar binary for OOPS
• ...
– Continuing porting
• Parallelization of FESTAT-Arpege
• Conf. 903 including the « PP-server » facility to replace
the monotask conf. 901 (« IFS-to-FA » file transformation)
• ...
15Cliquez pour modifier le style du titre
Thank you for your attention !
Cliquez pour modifier le style des
sous-titres du masque
16You can also read