Hierarchical Critic Assignment for Multi-agent Reinforcement Learning
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Hierarchical Critic Assignment for Multi-agent Reinforcement Learning
Zehong Cao1,2 and Chin-Teng Lin1
1
Centre for Artificial Intelligence, School of Software, Faculty of Engineering and IT, University of
Technology Sydney, NSW, Australia.
2
Discipline of ICT, School of Technology, Environments and Design, College of Sciences and
Engineering, University of Tasmania, TAS, Australia
{Zehong.Cao, Chin-Teng.Lin}@uts.edu.au
arXiv:1902.03079v2 [cs.LG] 11 Feb 2019
Abstract ditionally: maximise one’s benefit under the worst-case as-
sumption that the opponent will always endeavour to min-
In this paper, we investigate the use of global in- imise that benefit. This principle suggests using opponent-
formation to speed up the learning process and in- independent algorithms. The minimax-Q algorithm [Littman,
crease the cumulative rewards of multi-agent re- 2001] employs the minimax principle to compute strategies
inforcement learning (MARL) tasks. Within the and values for the stage games, and a temporal-difference rule
actor-critic MARL, we introduce multiple coopera- similar to Q-learning is used to propagate the values across
tive critics from two levels of the hierarchy and pro- state transitions. If considering policy gradient methods, each
pose a hierarchical critic-based MARL algorithm. agent can use model-based policy optimisation to learn opti-
In our approach, the agent is allowed to receive in- mal policies via back-propagation such as the Monte-Carlo
formation from local and global critics in a compe- policy gradient and Deterministic Policy Gradient (DPG)
tition task. The agent not only receives low-level [Silver et al., 2014]. Unfortunately, traditional Q-Learning
details but also considers coordination from high and policy gradient methods are poorly suited to multi-agent
levels to obtain global information for increasing environments. Thus, [Lowe et al., 2017] presented an adapta-
operational performance. Here, we define multiple tion of actor-critic methods that considers the action policies
cooperative critics in a top-down hierarchy, called of other agents and can successfully learn policies that require
the Hierarchical Critic Assignment (HCA) frame- complex multi-agent coordination.
work. Our experiment, a two-player tennis com-
petition task performed in the Unity environment, One hint at enabling MARL algorithms to overcome these
tested the HCA multi-agent framework based on challenges may lie in the way in which multiple agents are hi-
the Asynchronous Advantage Actor-Critic (A3C) erarchically structured [Mnih et al., 2015]. Inspired by feudal
with Proximal Policy Optimization (PPO) algo- reinforcement learning [Dayan, 1993], the DeepMind group
rithm. The results showed that the HCA frame- proposed Feudal Networks (FuNs) [Vezhnevets et al., 2017],
work outperforms the non-hierarchical critic base- which employ a manager module and a worker module for hi-
line method on MARL tasks. erarchical reinforcement learning. The manager sets abstract
goals, which are conveyed to and enacted by the worker, who
generates primitive actions at every tick of the environment.
1 Introduction Furthermore, the FuNs structure has been extended to co-
The analysis of multi-agent systems is a topic of interest in operative reinforcement learning [Ahilan and Dayan, 2019],
the field of artificial intelligence (AI). Although multi-agent whereby the manager learns to communicate sub-goals to
systems have been widely studied in robotic control, decision multiple workers. Indeed, these properties of extracting sub-
support systems, and data mining, only recently have they be- goals from the manager allow FuN to dramatically outper-
gun to attract interest in AI [González-Briones et al., 2018]. form a strong baseline agent on tasks.
A significant portion of research on multi-agent learning con- However, almost all the above MARL methods ignore this
cerns reinforcement learning (RL) techniques [Busoniu et al., critical fact that an agent might have access to the multiple
2010], which can provide learning policies for achieving tar- cooperative critics to speed up the learning process and in-
get tasks by maximising rewards provided by the environ- crease the rewards on competition tasks. In particular, it is
ment. In the multi-agent reinforcement learning (MARL) frequently the case that high-level agents agree to be assigned
framework, each agent learns by interacting with its dynamic different observations that co-work with low-level agents for
environment to solve a cooperative or competitive task. At the benefit of hierarchical cooperation. For example, military
each time step, the agent perceives the state of the environ- personnel typically have different roles and responsibilities.
ment and takes an action, which causes the environment to The commander is required to monitor multiple information
transit into a new state. sources, assess changing operational conditions and recom-
In a competitive game of multiple players (for two agents, mend courses of action to soldiers. The advanced hierarchi-
when p1 = −p2 ), the mini-max principle can be applied tra- cal MARL technologies can evaluate the relative importance
of new and changing data and make recommendations that update performed by the algorithm can be written as
will both improve decision-making capabilities and empower
5θ0 logπ(at | st ; θ0 )A(st , at ; θ, θv )
commanders to make practical judgements as quickly as pos-
sible. where A(st , at ; θ, θv ) is an estimate of the advantage func-
Our proposed framework in this paper differs from existing tion.
approaches, namely, the use of global information to speed up The advantage function is given by
and increase the cumulative rewards of MARL tasks. Within k−1
the actor-critic MARL, we introduce multiple cooperative X
γ i rt+i + γ k V (st+k ; θ) − V (st ; θv )
critics from two levels of the hierarchy and propose a hierar-
i=0
chical critic-based multi-agent reinforcement learning algo-
rithm. The main contributions of our proposed approach are where k can vary from state to state and is upper bounded by
the following: (1) The agent is allowed to receive the infor- tmax .
mation from local and global critics in a competition task. (2) As with value-based methods, this method relies on actor-
The agent not only receives low-level details but also consid- learners and accumulate updates for improving the training
ers coordination from high levels receiving global informa- stability. The parameters of θ of the policy and θv of the value
tion to increase operational performance. (3) We define mul- function are shared, even if they are shown to be separate for
tiple cooperative critics in the top-bottom hierarchy, called generality. For example, a convolutional neural network has
the Hierarchical Critic Assignment (HCA) framework. We one softmax output for the policy π(at | st ; θ) and one linear
assume that HCA is a generalised RL framework and thus output for the value function V (st ; θv ), with all non-output
more applicable to multi-agent learning. These benefits can layers shared.
potentially be obtained when using any type of hierarchical
MARL algorithm. 2.3 Proximal Policy Optimization (PPO)
The remainder of this paper is organised as follows. In Algorithm
Section 2, we introduce the RL background for developing PPO [Schulman et al., 2017] is a new family of policy gra-
the multiple cooperative critic framework in multi-agent do- dient methods for reinforcement learning, which alternate
mains. Section 3 describes the baseline and proposes the between sampling data through interactions with the envi-
HCA framework for hierarchical MARL. Section 4 presents ronment and optimising a surrogate objective function using
an experimental design in a simple Unity tennis task with four stochastic gradient ascent. Whereas standard policy gradient
types of settings. Section 5 demonstrates the training perfor- methods perform one gradient update per data sample, the
mance results of the baseline and proposed HCA framework. objective function enables multiple epochs of minibatch up-
Finally, we summarise the paper and discuss some directions dates, which is simpler to implement, more general, and has
for future work in Section 6. better sample complexity.
PPO can be investigated in the A3C framework. Specif-
2 Background ically, if using a neural network architecture that shares pa-
rameters between the policy and value function, a loss func-
2.1 Theory tion must be used to combine the policy surrogate and a value
In a standard RL framework [Kaelbling et al., 1996], an agent function error term. This objective can further be augmented
interacts with the external environment over a number of time by adding an entropy bonus to ensure sufficient exploration.
steps. Here, s is the set of all possible states, and a is all To approximately maximise each iteration, the “surrogate”
possible actions. At each time step t, the agent in state st , objective function is as follows:
by perceiving the observation information Ot from the envi-
ronment, receives feedback from the reward source, say, Rt , LCLIP
t
+V F +S
(θ) = εt [LCLIP
t (θ)−c1 LVt F (θ)+c2 S[πθ ](st )]
by taking action at . Then, the agent moves to a new state where c1 and c2 are coefficients, S denotes an entropy bonus,
s( t + 1), and the reward R( t + 1) associated with the transi- LCLIP
t is a surrogate objective, and LVt F is a squared-error
tion (st , at , s( t+1)) is determined. The agent can choose any loss.
action as a function of the history, and the goal of a reinforce-
ment learning agent is to collect as much reward as possible 2.4 Hierarchies
with minimal delay. Hierarchical reinforcement learning (HRL) is a promising ap-
proach to extending traditional RL methods to solve more
2.2 Asynchronous Advantage Actor-Critic (A3C) complex tasks [Kulkarni et al., 2016]. In its most straight-
The A3C structure [Mnih et al., 2016] can master a variety forward setting, the hierarchy corresponds to a rooted di-
of continuous motor control tasks as well as learned general rected tree, with the highest-level manager as the root node
strategies for exploring games purely from sensor and visual and each worker reporting to only a single manager. A pop-
inputs. A3C maintains a policy π(at | st ; θ) and an estimate ular scheme is meta-learning shared hierarchies [Frans et al.,
of the value function V (st ; θv ). This variant of actor-critic 2017], which learn a hierarchical policy whereby a master
can operate in the forward view and uses the same mix of policy switches between a set of sub-policies. The master
n-step returns to update both the policy and the value func- selects an action every n time steps, and a sub-policy exe-
tion. The policy and the value function are updated after ev- cuted for n time steps constitutes a high-level action. An-
ery tmax actions or when a terminal state is reached. The other scheme [Nachum et al., 2018] is learning goal-directed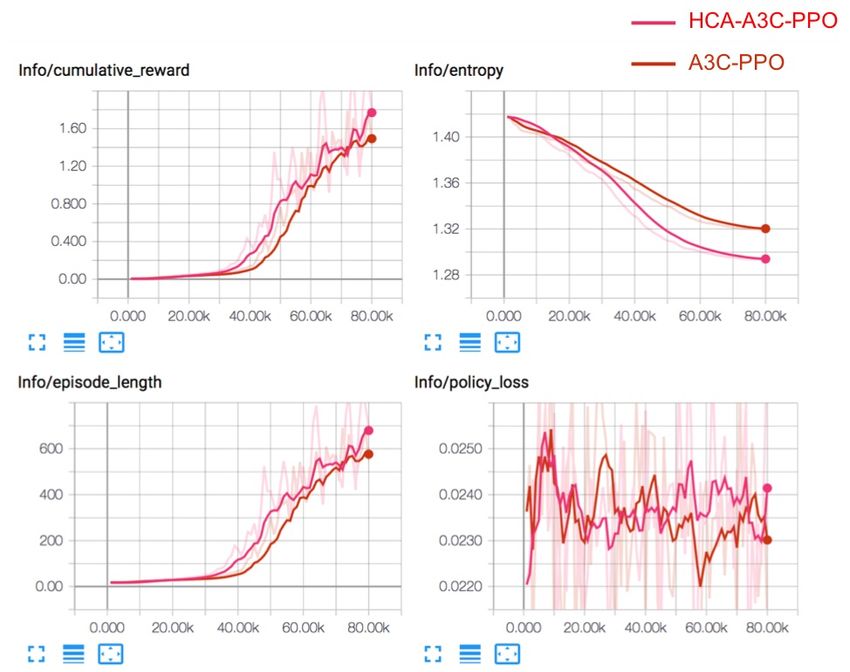
behaviours in environments, where lower level controllers are hierarchies, we are the first to develop an HCA framework
supervised with goals that are learned and proposed automat- allowing a worker to receive multiple critics computed lo-
ically by the higher level controllers. cally and globally. The manager is responsible for collecting
broader observations and estimating the corresponding global
3 Methods critic. As shown in Fig. 1, the HCA framework is constructed
by the two-level hierarchies with one manager agent and two
Toward the propagation of the critics in the hierarchies, we
worker agents. The local and global critics are implemented
propose HCA, a framework for MARL that considers multi-
by the softmax function illustrated in the ‘multiple-critic as-
ple cooperative critics from two levels of the hierarchy. To
signment’ subsection.
speed up the learning process and increase the cumulative re-
wards, the agent is allowed to receive information from local
and global critics in a competition task.
3.1 Baseline: A3C-PPO
A3C and PPO-based RL algorithms have performed compa-
rably to or better than state-of-the-art approaches while being
much simpler to implement and tune. In particular, PPO has
become the default reinforcement learning algorithm at Ope-
nAI because of its ease of use and good performance. Here,
we provide the A3C algorithm with PPO, called A3C-PPO,
which is a state-of-the-art deep RL algorithm. It can be used
as the baseline to validate experiment environments as well
as starting points for the development of novel algorithms.
3.2 Multiple-Critic Assignment
To apply existing RL methods to the problem of agents with
variable attention to more than one critic, we consider a soft-
max approach for resolving the multiple-critic learning prob-
lem. In terms of advantage actor-critic methods, the actor is a
policy function π(at | st ; θ) that controls how our agent acts,
and the critic is a value function V (st ; θv ) that measures how
good these actions are. For multiple critics, the update ad-
vantage function performed by the softmax function can be
written as
[m
A(st , at ) = sof tmax {π(at | st ; θ) − V (s(i)t ; θ(i)v )}
i=1
Figure 1. The HCA framework. The multi-agent hierarchy
, where m is the total number of critics.
with one manager agent and two worker agents. The worker
The advantage function calculates the extra reward if tak-
receives multiple critics computed locally and globally, and
ing this action, which tell us the improvement compared to
the manager provides the global critic.
the average action taken at that state. In other words, the max-
imised A(st , at ) indicates that the gradient is pushed in that
direction. Based on the A3C structure, the policy function
Pk−1 Here, we applied the HCA framework in the A3C-PPO,
{π(at | st ; θ) would estimate i=0 γ i rt+i + γ k V (st+k ; θ). called HCA-A3C-PPO, or simply HCA. The successfully
Furthermore, we consider the n time step intervals of mul- trained HCA-A3C-PPO model requires tuning of the trained
tiple critics, and the update advantage function can be written hyperparameters, which is beneficial to the output of the
as training process containing the optimised policy.
ht
[
A(st , at ) = sof tmax {π(at | st ; θ) − V (s(i)t ; θ(i)v )} 4 Experiment
i=1
We apply our proposed HCA framework to scenarios in
, where ht is the total number of critics. which two agents compete with each other. We empirically
If ht = ht+kT , ht = m, where k = 2, 3, 4, ... and T is a show the success of our framework compared to the existing
time period with n time steps; otherwise, ht = 1. method in competitive scenarios. We have released codes for
both the model and the environments on GitHub.
3.3 HCA-A3C-PPO
For simplicity, the experiments generally used two-level hi- 4.1 Unity Platform for MARL
erarchies such as a multi-agent hierarchy with one manager Since many existing platforms, such as OpenAI Gym, lack
agent and two worker agents. To propagate the critics in the the ability to flexibly configure the simulation, the simulation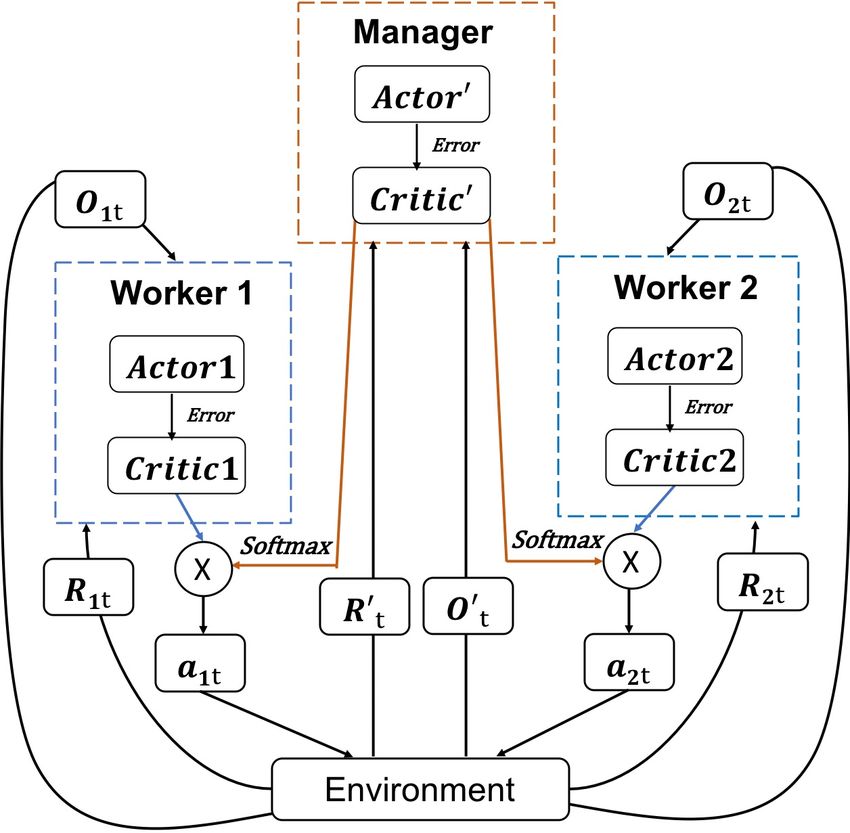
Types Agents Observation Spaces Input Variables
Type 1 worker 1&2 ball (positiont , velocityt ) 8 variables
racket (positiont , velocityt )
manager ball (positiont , velocityt ) 10 variables
racket (positiont , velocityt )
distance (ballt , rackett )
Type 2 worker 1&2 ball (positiont , velocityt ) 8 variables
racket (positiont , velocityt )
manager ball (position(t−1,t) , velocity(t−1,t)) ) 16 variables
racket (position(t−1,t) , velocity(t−1,t)) )
Type 3 worker 1&2 ball (positiont , velocityt ) 8 variables
racket (positiont , velocityt )
manager ball (position(t−1,t) ,velocity(t−1,t) ) 20 variables
racket (position(t−1,t) , velocity(t−1,t) )
distance (ball(t−1,t) , racket(t−1,t) )
Type 4 worker 1&2 ball (positiont , velocityt ) 8 variables
racket (positiont , velocityt )
manager ball (positionht =ht+kT , velocityht =ht+kT ) 10 variables
racket (positionht =ht+kT , velocityht =ht+kT )
distance (ballht =ht+kT , racketht =ht+kT )
Table 1: Four types of multi-agent observations
environment becomes a black box from the perspective of vector action space is continuous, with a size of 3, corre-
the learning system. The Unity platform, a new open-source sponding to movement toward the net or away from the net,
toolkit, has been developed for creating and interacting with and jumping.
simulation environments. Specifically, the Unity Machine
Learning Agents Toolkit (ML-Agents Toolkit) [Juliani et al.,
2018] is an open-source Unity plugin that enables games and
simulations to serve as environments for training intelligent
agents. The toolkit supports dynamic multi-agent interaction,
and agents can be trained using RL through a simple-to-use
Python API.
4.2 Unity Scenario: Tennis Competition
We set up a tennis competition scenario in Unity including
a two-player game whereby agents control rackets to bounce
the ball over a net. The goal of this task is that the agents
must bounce the ball between one another while not dropping Figure 2 Tennis competition in Unity
or sending the ball out of bounds. Furthermore, as shown in
Fig. 2, we construct a new learning environment involving
the two-layer hierarchy by introducing a manager to look at
The hyperparameters for the RL used for training are spec-
broader observation spaces. The information that the low-
ified in Table 2, which provides the initialisation settings that
level agents (racket workers 1 and 2) collect includes the posi-
we used in the tennis competition learning environment. In
tion of the target and the position of the agent itself, as well as
PPO, the batch size and buffer size represent the number
the velocity of the agent. The stat observation of the manager
of experiences in each iteration of gradient descent and the
contains additional variables, such as the distance between
number of experiences to collect before updating the policy
the ball and the racket and information about the previous
model, respectively. Beta controls the strength of entropy
time steps. These observation state spaces are continuous,
regularisation, and epsilon influences how rapidly the policy
and we need them for initialisation. Here, we provide four
can evolve during training. Gamma and lambda indicate the
types of observation spaces in Table 1 to test our proposed
reward discount rate for the generalised advantage estimator
HCA framework and baseline A3C-PPO.
and the regularisation parameter, respectively.
Of note, the agent reward function is +0.1 when hitting the
ball over the net and -0.1 when letting the ball hit the ground
or when the ball is hit out of bounds. The observation space 5 Results
includes 8-20 variable vectors corresponding to the position We provide the training performance of the HCA framework
and velocity of the ball and racket, as well as the distance be- (HCA-A3C-PPO) and baseline algorithm (A3C-PPO). The
tween the ball and the racket in continuous time steps. The HCA framework has been shown to be efficient and more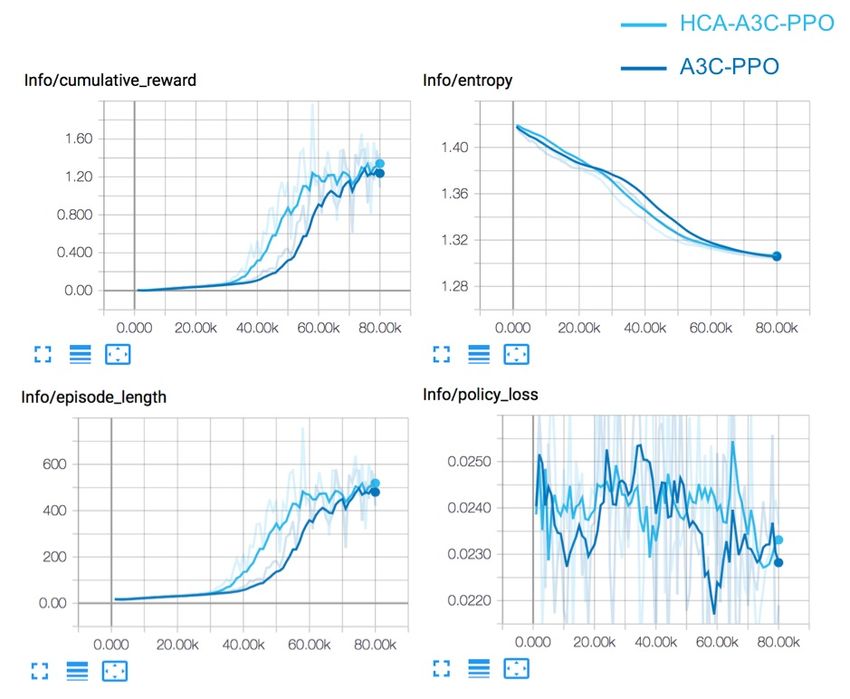
Parameters Values Parameters Values A3C-PPO, orange line) and baseline (A3C-PPO, blue line)
batch size 1024 beta 5 ∗ 10−3 performance. As shown in Fig. 4, the HCA framework results
buffer size 10240 epsilon 0.2 show higher cumulative reward and longer episode length
gamma 0.99 hidden units 128 with short training steps. Both methods experience a success-
lambda 0.95 learning rate 3 ∗ 10−4 ful training process, as they both presented a slowly decreased
max steps 8 ∗ 104 memory size 256 entropy and ultimate decreased magnitude of the policy loss.
normalise true num. epoch 3
num. layers 2 time horizon 64
sequence length 64 summary freq. 1000
Table 2: Parameters in the learning environment
general than the baseline algorithm; as such, we chose an
example scenario for use with the two-player tennis compe-
tition. To study the training process in more detail, we used
TensorBoard (smoothing =0.7) to demonstrate the dynamic
rewards, episodes, and policies with four types (type 1, type
2, type 3 and type 4) of observation spaces. In particular, we
focus on two indices, cumulative reward and episode length,
which represent the mean cumulative episode reward and the
mean length of each episode in the environment for all agents,
respectively.
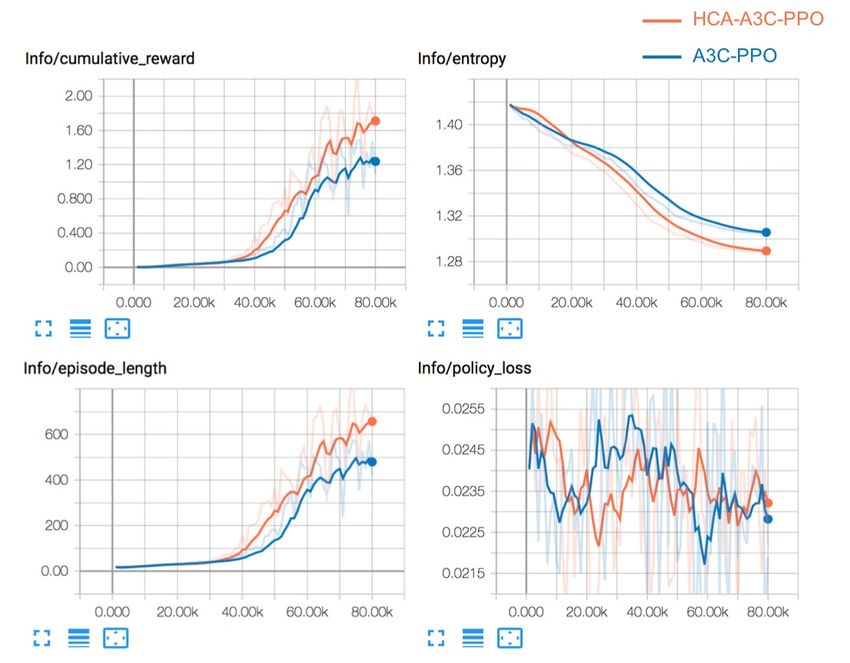
5.1 Type 1: HCA vs. Baseline Figure 4. Graphs depicting mean cumulative episodic re-
ward, mean episode length, mean entropy and policy loss (y-
Considering the 10 variable vectors of the observation spaces axis) with respect to the time steps of the simulation (in thou-
of the manager, we compare our HCA framework (HCA- sands, x-axis) during the training process.
A3C-PPO, pink-red line) and baseline (A3C-PPO, dark-red
line) performance. As shown in Fig. 3, the HCA framework 5.3 Type 3: HCA vs. Baseline
results showed higher cumulative reward and longer episode Considering the 16 variable vectors of the observation spaces
length with short training steps. Both methods experience a of the manager, we compare our HCA framework (HCA-
successful training process, as they both presented a slowly A3C-PPO, light-blue line) and baseline (A3C-PPO, dark-blue
decreased entropy and ultimately decreased magnitude of the line) performance. As shown in Fig. 5, the HCA framework
policy loss. results show higher cumulative reward and longer episode
length with short training steps. Both methods experience
a successful training process, as they both presented slowly
decreased entropy and ultimately decreased magnitude of the
policy loss.
Figure 3. Graphs depicting the mean cumulative episodic
reward, mean episode length, mean entropy and policy loss
(y-axis) with respect to the time steps of the simulation (in
thousands, x-axis) during the training process.
Figure 5. Graphs depicting the mean cumulative episodic
5.2 Type 2: HCA vs. Baseline reward, mean episode length, mean entropy and policy loss
Considering the 16 variable vectors of the observation spaces (y-axis) with respect to the time steps of the simulation (in
in the manager, we compare our HCA framework (HCA- thousands, x-axis) during the training process.
5.4 Type 4: HCA vs. Baseline References
Considering the 10 variable vectors (with 5-time-step inter- [Ahilan and Dayan, 2019] Sanjeevan Ahilan and Peter
vals) of the observation spaces of the manager, we compare Dayan. Feudal multi-agent hierarchies for cooperative
our HCA framework (HCA-A3C-PPO, green line) and base- reinforcement learning. arXiv preprint arXiv:1901.08492,
line (A3C-PPO, blue line) performance. As shown in Fig. 6, 2019.
the HCA framework results showed higher cumulative reward
and longer episode length with short training steps. Both [Busoniu et al., 2010] Lucian Busoniu, Robert Babuška, and
methods experience successful training processes, as they Bart De Schutter. Multi-agent reinforcement learning:
both presented slowly decreased entropy and ultimately de- An overview. Innovations in multi-agent systems and
creased magnitude of the policy loss. applications-1, 310:183–221, 2010.
[Dayan, 1993] Peter Dayan. Improving generalization for
temporal difference learning: The successor representa-
tion. Neural Computation, 5(4):613–624, 1993.
[Frans et al., 2017] Kevin Frans, Jonathan Ho, Xi Chen,
Pieter Abbeel, and John Schulman. Meta learning shared
hierarchies. arXiv preprint arXiv:1710.09767, 2017.
[González-Briones et al., 2018] Alfonso González-Briones,
Fernando De La Prieta, Mohd Mohamad, Sigeru Omatu,
and Juan Corchado. Multi-agent systems applications in
energy optimization problems: A state-of-the-art review.
Energies, 11(8):1928, 2018.
[Juliani et al., 2018] Arthur Juliani, Vincent-Pierre Berges,
Esh Vckay, Yuan Gao, Hunter Henry, Marwan Mattar, and
Danny Lange. Unity: A general platform for intelligent
agents. arXiv preprint arXiv:1809.02627, 2018.
Figure 6. Graphs depicting the mean cumulative episodic [Kaelbling et al., 1996] Leslie Pack Kaelbling, Michael L
reward, mean episode length, mean entropy and policy loss Littman, and Andrew W Moore. Reinforcement learn-
(y-axis) with respect to the time steps of the simulation (in ing: A survey. Journal of artificial intelligence research,
thousands, x-axis) during the training process. 4:237–285, 1996.
[Kulkarni et al., 2016] Tejas D Kulkarni, Karthik
6 Conclusion Narasimhan, Ardavan Saeedi, and Josh Tenenbaum.
In this study, we developed the HCA framework using global Hierarchical deep reinforcement learning: Integrating
information to speed up the learning process and increase the temporal abstraction and intrinsic motivation. In Ad-
cumulative rewards. Within this framework, the agent is al- vances in neural information processing systems, pages
lowed to receive information from local and global critics in 3675–3683, 2016.
a competition task. We tested the proposed framework in a [Littman, 2001] Michael L Littman. Value-function rein-
two-player tennis competition task in the Unity environment forcement learning in markov games. Cognitive Systems
by comparing with a baseline algorithm: A3C-PPO. The re- Research, 2(1):55–66, 2001.
sults showed that the HCA framework outperforms the non-
[Lowe et al., 2017] Ryan Lowe, Yi Wu, Aviv Tamar, Jean
hierarchical critic baseline method on MARL tasks.
In future work, we will explore weighted approaches to Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-
fuse critics from different layers and consider optimising the agent actor-critic for mixed cooperative-competitive envi-
temporal scaling in different layers. Furthermore, we will ex- ronments. In Advances in Neural Information Processing
tend the number of agents and the number of layers, and even Systems, pages 6379–6390, 2017.
allow for more than one manager at the highest level of the [Mnih et al., 2015] Volodymyr Mnih, Koray Kavukcuoglu,
hierarchy. We expect the possibility, in more exotic circum- David Silver, Andrei A Rusu, Joel Veness, Marc G Belle-
stances, of considering more general multi-agent reinforce- mare, Alex Graves, Martin Riedmiller, Andreas K Fidje-
ment loops in which each agent can potentially achieve the land, Georg Ostrovski, et al. Human-level control through
maximum reward hierarchically. deep reinforcement learning. Nature, 518(7540):529,
2015.
Acknowledgments [Mnih et al., 2016] Volodymyr Mnih, Adria Puigdomenech
This work was partially supported by grants from the Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim
Australian Research Council under Discovery Projects Harley, David Silver, and Koray Kavukcuoglu. Asyn-
[DP180100670 and DP180100656], US Army Research Lab- chronous methods for deep reinforcement learning. In In-
oratory [W911NF-10-2-0022 and W911NF-10-D-0002/TO ternational conference on machine learning, pages 1928–
0023], and Australia Defence Science Technology Group. 1937, 2016.[Nachum et al., 2018] Ofir Nachum, Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical re- inforcement learning. arXiv preprint arXiv:1805.08296, 2018. [Schulman et al., 2017] John Schulman, Filip Wolski, Pra- fulla Dhariwal, Alec Radford, and Oleg Klimov. Prox- imal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017. [Silver et al., 2014] David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic policy gradient algorithms. In ICML, 2014. [Vezhnevets et al., 2017] Alexander Sasha Vezhnevets, Si- mon Osindero, Tom Schaul, Nicolas Heess, Max Jader- berg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. arXiv preprint arXiv:1703.01161, 2017.
You can also read

















































