Improved Mask Wearing Detection Algorithm for SSD
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Journal of Physics: Conference Series
PAPER • OPEN ACCESS
Improved Mask Wearing Detection Algorithm for SSD
To cite this article: Houkang Deng et al 2021 J. Phys.: Conf. Ser. 1757 012140
View the article online for updates and enhancements.
This content was downloaded from IP address 46.4.80.155 on 15/07/2021 at 23:02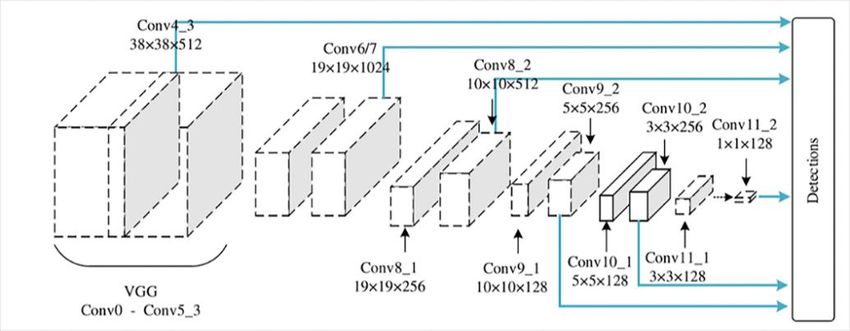
ICCBDAI 2020 IOP Publishing
Journal of Physics: Conference Series 1757 (2021) 012140 doi:10.1088/1742-6596/1757/1/012140
Improved Mask Wearing Detection Algorithm for SSD
Houkang Deng, Jin Zhang, Lingyu Chen, Meiling Cai*
College of Information Science and Engineering, Hunan Normal University, No.36,
Lushan Road, Changsha 410081, China
*Cai.Meiling@hunnu.edu.cn
Abstract. Coronavirus disease is seriously affecting the world in 2019. Wearing a mask in
public places is a major way to protect people. However, there are few studies on mask
detection based on image analysis. In this paper, an improved mask wearing inspection
algorithm based on the SSD algorithm is proposed. The SSD algorithm is improved to add a
face mask wearing detection task. Based on the original SSD model, the algorithm improves
the mask wearing detection capability by introducing inverse convolution and feature fusion in
combination with an attention mechanism to filter out the information to be retained. A dataset
containing 3656 tensor images was created and manually labeled for network training.
Experiments on this dataset show that the algorithm has good accuracy for mask wearing
inspection.
Keywords: Coronavirus, mask wearing, face detection, SSD algorithm, feature fusion,
Attention mechanisms
1. Introduction
Since the end of 2019, there has been an outbreak of a novel coronavirus (COVID-19) in China, and
the World Health Organization's (WHO) Situation Report 96 [1] states that coronavirus disease
(COVID-19) has infected more than 2.7 million people worldwide and caused more than 180,000
deaths in 2019. Currently, the WHO recommends that people wear face masks if they have respiratory
symptoms or if they are caring for someone with symptoms [2]. In addition, many public service
providers require customers to use this service only if they are wearing a mask [3]. Therefore, mask
wearing detection has become an important computer vision task to help the global society, and it has
great positive significance. The research on face detection technology originated in the 1960s and
1970s. N.J.Neethu et al. comprehensively summarized the types of traditional face detection
algorithms, and divided face detection methods into knowledge-based, template-based matching,
appearance-based, and feature-based invariance methods[4]. PalA proposed a hybrid algorithm for
face detection in color images [5], the algorithm uses the skin tone histogram in HSV color space, as
well as facial shape information to quickly locate faces in a given image, but the detection algorithm
based on skin tone features is susceptible to the effects of illumination. Singh A et al. proposed a face
detection based on Sobel edge detection and morphological operations and human eye extraction
algorithm [6], which achieves 97.5% accuracy on a test set of 40 faces in the IMM face database, a
limitation of this algorithm is its slow computational speed. The VJ detection algorithm [7] proposed
by Paul Viola et al. utilizes Haar features and Adaboost cascade strategy to achieve real-time detection
Content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution
of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
Published under licence by IOP Publishing Ltd 1
ICCBDAI 2020 IOP Publishing
Journal of Physics: Conference Series 1757 (2021) 012140 doi:10.1088/1742-6596/1757/1/012140
rate and the highest detection accuracy at that time, however, the accuracy of the cascade weak
classifier is easily degraded by the unsmoothness of the data.
In recent years, deep learning-based target detectors have shown excellent performance and
dominated the development of modern target detectors. Without using a priori knowledge to form
feature extractors, deep learning allows neural networks to learn features in an end-to-end manner [8].
Deep learning-based face detection can be broadly divided into two categories: first, multi-stage
detection algorithms based on the recommendation region (proposal region). For example, Ren S et al.
proposed the Faster RCNN model [9], which innovatively proposes an edge-extracting neural network
RPN (Region Proposal Network) to replace the original Selective Search method to obtain candidate
region information in training, and the resulting candidate boxes and targets are used to detect the face.
The detection network shares the convolutional network, which greatly reduces the number of
candidate boxes and improves the accuracy of the candidate region. The second is a single-stage
detection algorithm based on the anchor box (anchor box). For example, Liu W [10] proposed SSD
(Single Shot MultiBox Detector), which uses all grids to predict targets based on the regression
method and draws on the anchor mechanism using Faster R-CNN, and has reached the effect of multi-
layer feature multilayer scales. The algorithm has improved the speed and accuracy of detection.
However, little attention has been paid to mask wearing detection.
In this paper, we propose an improved face mask detection model based on the SSD algorithm.
Based on a single face area, the solution uses attentional learning and feature fusion to further analyze
the face attributes and determine whether the face is wearing a mask or not. The test results show that
the above technical solution effectively solves the mask wearing recognition problem in the natural
environment. The average accuracy of the mask wearing recognition task is 91.7%. In the network
structure, a channel domain attention mechanism is introduced to enhance the semantic information of
the high-level feature map. The inverse convolution and special fusion methods are used to improve
the accuracy of mask blocking detection. The experiments show that this algorithm achieves good
accuracy in mask blocking detection.
The rest of the paper is organized as follows: in Part II, work on target detection and neural
networks is presented. The third part describes my proposed methodology. The fourth part describes
the dataset, experimental environment, evaluation metrics, and results. The fifth part summarizes the
full text and looks forward to future work.
2. Related work
2.1. SSD model structure
The basic network of SSD uses the VGG16 network. The two fully connected layers of VGG16 are
replaced with convolutional layers, and the depth of the convolutional layer is increased. Four
convolutional layers of Conv8_2, Conv9_2, Conv10_2, Conv11_2 are added later. The network
structure diagram is shown in Figure 1:
Fig.1 SSD network structure diagram
2
ICCBDAI 2020 IOP Publishing
Journal of Physics: Conference Series 1757 (2021) 012140 doi:10.1088/1742-6596/1757/1/012140
SSD discretizes the output space of the bounding box into a series of default boxes, a bit similar to
the anchor in faster r-cnn. Different layers will output different default boxes, which are finally
aggregated together for non-maximum suppression. In this way, boxes that combine feature maps of
different scales can effectively handle multi-scale problems. In the process of SSD prediction, a
classifier is an output on each extracted feature layer.
2.2. Attention mechanism
In recent years, the use of masks to form attention mechanisms has become a research method
combining deep learning and attention mechanisms. The working principle of the mask is to identify
and mark the key features in the data set picture through another layer of new weights, and then
through continuous learning and slow training, let the network learn what is needed in each data set
picture. More attention to the area, increase the weight of this area, which also forms the so-called
attention.
2.2.1. Spatial Domain
In 2015, Max[11] and others proposed a module called a spatial converter, which extracts the key
information from the picture and performs a corresponding spatial transformation on the information
in the spatial domain. The model structure is shown in Figure 2:
Localisation net
G rid
G enerator
U X V
S am ple
Fig. 2 Spatial Transformer model structure
To put it plainly, the spatial transformer is an implementation of the attention mechanism, because
the trained spatial transformer can find the area that needs to be paid attention to in the picture
information, and this transformer also has the function of making the picture larger and smaller and
changing the direction. The area that needs attention in the picture information can be extracted with a
box. This module can be added as a new layer to other network structures to identify the key
information of the upper layer signal.
2.2.2. Channel domain.
In 2017, Hujie et al. proposed a very important SENet model [12], and won the championship of
ImageNet in one fell swoop. The network structure is shown in Figure 3.
3
ICCBDAI 2020 IOP Publishing
Journal of Physics: Conference Series 1757 (2021) 012140 doi:10.1088/1742-6596/1757/1/012140
X U
H
H’ H
W’ W C W
C’ C
Fig. 3 A Squeeze-and-Excitation block
As we can see from the above figure, X on the left is the original input image feature. After the
convolution transformation Ftr, a new feature map U is generated. The feature map U includes C
channels, and the weight of each channel can be learned by the attention module to generate the
attention of the channel domain. The attention mechanism module in the middle is the innovative part
of SENet.
The attention mechanism in SENet can be divided into three parts: squeeze, excitation, and
attention.
3. Improve the SSD algorithm for mask wearing detection
In order to achieve the detection of face mask wearing, this paper improves on the SSD algorithm, and
the improvement is shown in the following figure, the whole framework is divided into two parts the
attention mechanism is added to the backbone network to enhance the expression of the feature map.
The feature layer conv4_3 uses inverse convolution to get richer feature layers, and finally, these
feature layers are fused with unified features. The efficiency and accuracy of the algorithm for mask
occlusion detection are improved.
C onv11_
2
C onv10_2 Feature
D etect
A ttention fusion ion
C onv9_2
C onv4_3
C onv8_2
C onv7
Feature
m apping
D econv4_ N ew conv4_3
P ooling
3
Fig.4 Improved SSD detection model diagram
3.1. Improved Attention Mechanisms
The attention mechanism module is implemented in three steps: squeeze, excitation, and attention. The
formula for squeeze is shown in equation (1):
1
Y = H∗W Hi=1 W
j=1
X(i,j) (1)
where H, W, and C represent the length, width, and the number of channels of the input dimension
of low resolution high semantic information graph X. After squeezing the information graph X, an
4
ICCBDAI 2020 IOP Publishing
Journal of Physics: Conference Series 1757 (2021) 012140 doi:10.1088/1742-6596/1757/1/012140
array of length C is obtained. The (i,j) in Equation (1) represents the (i,j) points on the feature map of
size H*W, and the output Y is a one-dimensional array of length C. We can see that the (i,j) in
Equation (1) represents the (i,j) points on the feature map of size H*W. We can see that Eq. (1) is
actually a global average pooling operation, where all the eigenvalues in each channel are averaged
and added together. The next step in the excitation process is to model the correlation between the
channels, as follows:
S = Sigmiod(W2 ∙ ReLU W1 Y ) (2)
W1 has the dimension C*C and W 2 has the dimension C*C, where C is C*1/4. The ReLU
activation function and the Sigmoid function are used to train and learn these two weights, and a one-
dimensional excitation weight is obtained to activate each channel. The final dimension of S is C*1*1.
attention Operation:
X● = X ∙ S (3)
Replace the original input X with the feature map obtained through the attention mechanism
module X● . It is sent to the improved SSD network in this article for detection. In other words, this
process is actually a process of scaling. The values of different channels are multiplied by different
weights, which can enhance the attention to key channels. The algorithm flow chart is shown in Figure
5:
Fig.5 An algorithmic flowchart introducing channel attention mechanism
3.2. Inverse Convolution and Feature Fusion
To address the problem that SSD is not capable of detecting mask label occlusion, this paper uses
inverse convolution to enlarge the feature map of the feature layer conv4_3 to obtain a richer semantic
feature layer and then pooling and the inherent multi-scale feature layer of the SSD model to perform
pixel direct weighting and feature fusion with different weighting coefficients.
The inverse convolution feature region amplification module in Figure 4 is used to amplify the
conv4_3 feature map resolution by inverse convolution, resulting in a new feature layer, Newconv4_3.
The other feature layers in the SSD model are conv7, conv8_2, conv9_2, and conv10_2. conv11_2 is
the same as the conv4_3 feature map resolution. Newconv4_3 performs feature fusion with different
weighting coefficients and finally performs face-mask wearing location detection and outputs.
4. Experimental results
4.1. Experimental data set
Since there is no publicly available data set for wearing face masks in natural scenes, this paper has
diversified training samples through the collection and enhancement processing of different types of
data. Source of experimental data: public data collected online, data collected by individuals. The
number of original data images collected is shown in the following table:
Kind WIDER Face MAFA Homemade data Total
Mask 756 837 513 2106
No mask 558 342 650 1550
Tab.1 Test data
5ICCBDAI 2020 IOP Publishing
Journal of Physics: Conference Series 1757 (2021) 012140 doi:10.1088/1742-6596/1757/1/012140
In the data set, there were 2,106 masks and 1,550 unmasked faces, including a total of images of
multiple people. After the original images have been collected, then they need to be formatted into
VOC datasets. First, all the pictures were marked. The face wearing the mask was marked with a
rectangular box, and the position information of the rectangle box, labels, and other information was
written into the XML file, as shown in Figure 6:
Fig.6 Data set annotation
4.2. Experimental Environment
The algorithm in this experiment is implemented in the Ubuntu operating system, the programming
language uses python3.7.3, the deep learning framework uses Caffe, and the GPU acceleration tool
uses CUDA 8.0. The hardware configuration mainly includes Intel (R) Core (TM) i7-7700K@4.2GHz
CPU and NVDIA GTX 1070Ti GPU.
4.3. Evaluation Index
In order to evaluate the performance of the model, the average precision and mean average precision
commonly used in the field of target detection was used to evaluate the effectiveness of the proposed
algorithm in the face and mask wearing detection. The value of AP reflects the detection effect of a
single target, which is calculated as follows:
1
AP = 0 (R) (4)
Where p (r) represents the mapping relationship between true positive rate and recall rate, and p
and r are calculated as follows:
P= + (5)
r= +
(6)
Where TP (True Positive) represents the number of positive samples predicted to be positive, FP
(False Positive) represents the number of negative samples predicted to be positive, and FN (False
6ICCBDAI 2020 IOP Publishing
Journal of Physics: Conference Series 1757 (2021) 012140 doi:10.1088/1742-6596/1757/1/012140
Negative) represents the number of positive samples predicted to be negative. In this paper, mask
wearing samples were correctly classified into the mask wearing category, which was denoted as TP.
The category of non-wearing masks was wrongly classified into the category of wearing masks,
denoted as FP; The sample of wearing masks was wrongly classified into the category of not wearing
masks, which was denoted as FN. The sample without a mask was correctly classified into the
category without a mask, which was recorded as TN.
MAP represents the mean of the average precision of all categories and reflects the target detection
effect on the total volume. Its calculation method is as follows:
mAP = =1
(7)
Where n represents the number of categories and I represent a category.
4.4. Experimental results and comparison
The experimental results are shown in Table 2. It can be seen that the AP values in face detection are
90.6% and 87.3% respectively, and 92.7% and 83.5% respectively in face mask wearing detection. It
can be seen that compared with the SSD algorithm, the improved algorithm model in this paper has a
limited improvement in AP value, but has a significant improvement in facial mask wearing inspection.
Methods mask/% no mask/% mAP%
SSD 83.5 87.3 85.4
Ours 92.7 90.6 91.7
Tab.2 Test results comparison
The algorithm in this paper improves to a certain extent compared with the SSD algorithm in the
aspect of face detection mask wearing detection through improvement.
5. Conclusion
This paper proposes a face mask wearing inspection algorithm for real scenarios by improving the
SSD algorithm, which ultimately improves the detection by adding an attention mechanism to the
backbone network and using an inverse convolution operation on the conv4_3 feature layer of the SSD
algorithm, and finally fusing these feature layers with unified features. The training results on a dataset
of 3656 images constructed by ourselves indicate that the improved method in this paper can
effectively detect whether a person is wearing a mask or not in a real environment, with an average
accuracy of 91.7%. It proves the reasonable usability of this algorithm. In the next work, I will
improve and optimize the model and add more datasets to further improve the performance of the
algorithm.
Acknowledgments
This work was supported by the research projects: the Hunan Provincial Department of Education
Innovation Platform Open Fund Project(15K082), the Hunan Provincial Department of Transportation
Scientific and Technological Progress and Innovation Program Project(201927), the Central Military
Commission Department of Equipment Development Pre-research Project(31511010105), the
National Defense Science and Technology Bureau of National Defense Basic
Research(WDZC20205500119), the Hunan Provincial Department of Education Project (JG2018A012,
[2019]No.291, [2019]No.248, [2019]No.370; [2020]No.9, [2020]No.90, [2020]No.172), the Ministry
of Education's Industry-University Cooperation and Collaborative Education Project (201901051021).
References
[1] World Health Organization 2020 Coronavirus disease situation report
[2] Feng S, Shen C, Xia N, Song W, Fan M and Cowling B 2020 The Lancet Respiratory Medicine
7ICCBDAI 2020 IOP Publishing
Journal of Physics: Conference Series 1757 (2021) 012140 doi:10.1088/1742-6596/1757/1/012140
8 p 434
[3] Fang Y, Nie Y and Penny M 2020 Journal of medical virology 92 p 645
[4] Bk A 2014 International conference on advanced trends in engineering and technology
[5] Pal A 2008 In 2008 International Machine Vision and Image Processing Conference
(Piscataway: IEEE) p 57
[6] Singh A, Singh M and Singh B 2016 In 2016 Conference on Advances in Signal Processing
(Piscataway: IEEE) p 295
[7] Viola P and Jones M J 2004 International Journal of Computer Vision 57 p 137
[8] Liu L, Ouyang W, Wang X, Fieguth P, Chen J, Liu X and Pietikäinen M 2020 International
journal of computer vision 128 p26
[9] Ren S, He K, Girshick R and Sun J 2015 In Advances in neural information processing systems
[10] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y and Berg A C 2016 In European
conference on computer vision (Berlin: Springer Cham) p 21
[11] Jaderberg M, Simonyan K and Zisserman A 2015 Advances in neural information processing
systems
[12] Hu J, Shen L and Sun G 2018 Proceedings of the IEEE conference on computer vision and
pattern recognition (Piscataway: IEEE) p 7132
8You can also read