Inferring the Reader: Guiding Automated Story Generation with Commonsense Reasoning
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Inferring the Reader: Guiding Automated Story Generation with
Commonsense Reasoning
Xiangyu Peng∗, Siyan Li∗, Sarah Wiegreffe, and Mark Riedl
Georgia Institute of Technology
Atlanta, GA 30332
{xpeng62, sli613, swiegreffe6}@gatech.edu
riedl@cc.gatech.edu
Abstract
Transformer-based language model ap-
arXiv:2105.01311v1 [cs.CL] 4 May 2021
proaches to automated story generation
currently provide state-of-the-art results.
However, they still suffer from plot incoher-
ence when generating narratives over time,
and critically lack basic commonsense reason-
ing. Furthermore, existing methods generally
focus only on single-character stories, or fail
to track characters at all. To improve the co-
herence of generated narratives and to expand
the scope of character-centric narrative gener-
ation, we introduce Commonsense-inference
Augmented neural StoryTelling (CAST), a
framework for introducing commonsense
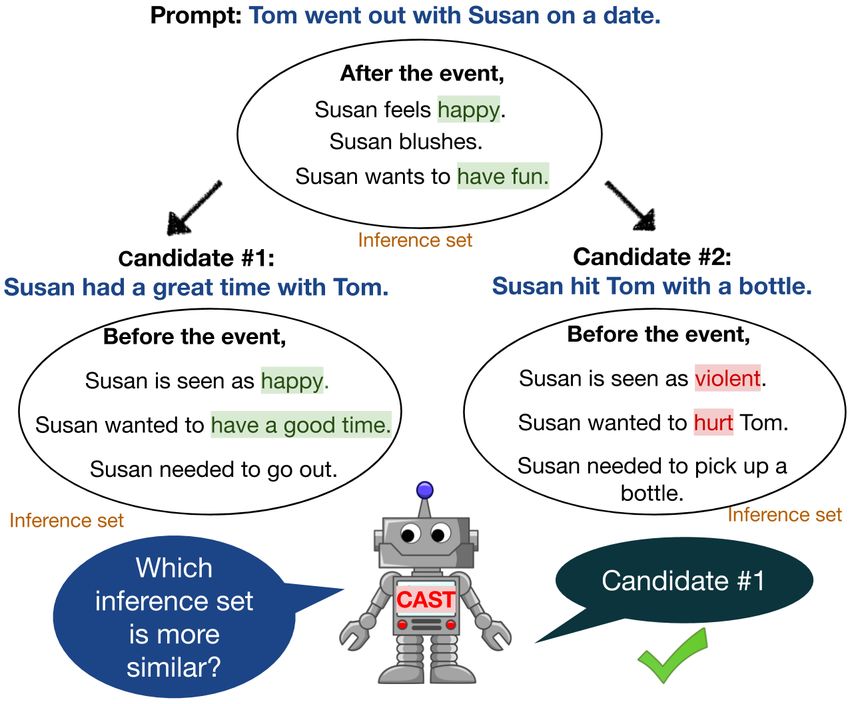
reasoning into the generation process while Figure 1: Overview of the CAST system. 1. A text
modeling the interaction between multiple prompt starts the story generation process. 2. The sys-
characters. We find that our CAST method tem infers facts about the characters’ intents. 3. A lan-
produces significantly more coherent and guage model generates candidate continuations. 4. In-
on-topic two-character stories, outperforming ferences about the candidates are matched against the
baselines in dimensions including plot plausi- previous inferences and the best candidate is added to
bility and staying on topic. We also show how the story.
the CAST method can be used to further train
language models that generate more coherent
stories and reduce computation cost. These techniques have improved with the adoption
of Transformer-based models, such as GPT-2 (Rad-
1 Introduction ford et al., 2019). While GPT-2 and similar neural
language models are considered highly fluent from
AI storytelling is a crucial component of computa- a grammatical standpoint, they are prone to gener-
tional creativity. Humans use storytelling to enter- ating repetitive or generic continuations (Holtzman
tain, share experiences, educate, and to facilitate et al., 2019). Furthermore, as the length of the story
social bonding. For an intelligent system to be un- grows, these models can lose coherence. One rea-
able to generate a story limits its ability to interact son for these phenomena is that language models
with humans in naturalistic ways. Automated Story generate continuations by sampling from a learned
Generation, in particular, has been a grand chal- distribution Pθ (tokn |tokn−k , ..., tokn−2 , tokn−1 ).
lenge in artificial intelligence, requiring a system Human readers, however, do not perceive the coher-
to construct a sequence of sentences that can be ence of a narrative as a function of the likelihood
read and understood as a story. of seeing particular words based on the occurrence
A common approach to story generation is to use of previous words.
neural language models (Roemmele, 2016; Khalifa
Previous attempts to enhance the coherence
et al., 2017; Clark et al., 2018; Martin et al., 2018).
of generated stories use conditioning on content-
∗
Equal contributions relevant features such as plot outlines (Fan et al.,2018; Peng et al., 2018; Rashkin et al., 2020), or erative model trained on triples from ATOMIC and
character emotional arcs (Brahman and Chaturvedi, infers relations about sentences broadly divided
2020). These achieve coherence through adher- into four categories: (1) Causes of a person’s ac-
ence to a manually given high-level plan. The high tions (preconditions of the event), (2) Attributes of
level plan can be generated (Yao et al., 2019; Am- a person, (3) Effects of actions on a person (post-
manabrolu et al., 2020), which only elevates the conditions of the event), and (4) Effects of actions
challenges of maintaining coherence to a higher on others (postconditions of the event). We pro-
level of abstraction. Neural language models pose to infer character intentions and effects of
can also be fine-tuned on extraneous signals such actions using COMET to inform the generation of
as commonsense knowledge or progression re- subsequent sentences by a neural language model.
wards (Guan et al., 2020; Tambwekar et al., 2019), To address the challenge of maintaining coher-
which improves the distribution but still relies ence in language-model-based story generation,
solely on sampling. we propose a novel two-character story genera-
The latent state of neural language models used tion method, Commonsense inference Augmented
to generate subsequent story continuations are un- neural StoryTelling (CAST), that infers the causal
likely to relate to a human reader’s mental model of relations between events as well as the intents and
the state of a story world. Studies of human reader motivations of characters in the story context so
comprehension (Trabasso and Van Den Broek, far in order to generate story continuations that are
1985; Graesser et al., 1991, 1994) show that read- more coherent to readers. CAST uses these inferred
ers comprehend stories by tracking the relations causal relations and character intentions to make
between events. Reader comprehension relies on more informed choices about potential story con-
the tracking of at least four types of relations be- tinuations generated by a neural language model
tween events: (1) causal consequence, (2) goal (GPT-2). We hypothesize that stricter, more explicit
hierarchies, (3) goal initiation, and (4) character constraints during generation should result in more
intentions. The perceived coherence of a story is coherent narratives than generating via sampling
thus a function of the reader being able to compre- from a distribution alone, even if the distribution is
hend how events correlate to each other causally fine-tuned.
or how they follow characters’ pursuits of implicit To evaluate the efficacy of our proposed method,
goals. Cognitive studies of human reading com- we conduct a series of human-participant experi-
prehension (Trabasso and Van Den Broek, 1985; ments specifically measuring perceptions of logical
Graesser et al., 1991, 1994) suggest that readers coherence of CAST against a number of fine-tuned
track the goals and motivations of story world char- variants of GPT-2. Results indicate that the CAST
acters as well as causal consequences of actions. method significantly increases the perception of
We hypothesize that a story generation system that generated stories over baselines.
makes decisions on how to continue a story based
on tracking and reasoning about character inten- 2 Related Work
tions and action consequences will generate more
Neural networks—recurrent and transformer-
coherent stories.
based—have been used to produce stories (Roem-
However, stories don’t always explicitly declare mele, 2016; Khalifa et al., 2017; Martin et al., 2018;
the goals and motivations of characters; sentences Clark et al., 2018). In these systems a neural lan-
describing character actions are not explicitly an- guage model learns to approximate the distribu-
notated with the characters’ motivations and goals. tion Pθ (tokn |tokn−k , ..., tokn−2 , tokn−1 ). Stories
Readers must infer the characters’ goals and the are generated by providing a context sequence and
relationship between their actions and those goals. sampling from the distribution. When the language
The ability to use basic knowledge about goals model is trained on a corpus of stories, the gen-
about what is happening in the world falls within erated text tends to also be a story. Sometimes
the study of commonsense inference. ATOMIC generation is done hierarchically (Yao et al., 2019;
(Sap et al., 2019) is a commonsense knowledge Ammanabrolu et al., 2020). However, coherence is
base that contains logical relationships concern- not guaranteed; statistical sampling from a distribu-
ing mental states, attributes, and events. COMET tion is not constrained to making logical transitions
(Bosselut et al., 2019) is a transformer-based gen- because the rich relationships that readers make toperceive coherence are not modeled. Other artifacts language model and obtain a set of common-
of the sampling process include new characters be- sense inferences.
ing arbitrarily introduced at any time, characters
being forgotten, and repetitions. 3. We match commonsense inference sets be-
To control the generation, sometimes a high- tween si−1 and c using a matching criteria
level plot outline is given and a language model is grounded in theory, and produce a score for c.
conditioned or otherwise guided by the high-level
plot outline (Fan et al., 2018; Peng et al., 2018; 4. If the score is above a user-specified thresh-
Rashkin et al., 2020; Brahman and Chaturvedi, old, c is selected to be si and is appended
2020). These high-level guidance specifications to the generation history. Otherwise, steps 2
turn the story generation problem into a supervised through 4 are repeated until a viable candidate
learning problem. We do not consider these ap- is found.
proaches further in this paper because we do not
assume the existence of any guidance specification. 5. Repeat steps 1 through 4 until k − 1 sentences
The story generation system by Guan et have been generated.
al. (2020) first fine-tunes GPT-2 on the ATOMIC
An overview of the pipeline is given in Figure 2.
dataset and then fine-tunes a second time on the
The system is simple but effective—CAST reasons
ROCStories corpus (Mostafazadeh et al., 2016) to
about whether there are sufficient relations between
induce GPT-2 to generate short stories. The au-
the candidate sentence and the previous sentence
thors use multi-task learning during the second
to support reader comprehension. Unlike models
fine-tuning stage with an auxiliary objective to dis-
trained or fine-tuned on commonsense knowledge,
tinguish true and engineered false stories. Even
the filtering technique provides a hard constraint
with such specialized learning, the resulting model
that is likely to persist throughout a generated story
still fails to avoid logical errors, repeats pieces of
of arbitrary length without degeneration, nor is it
narratives, and introduces unrelated entities. This
limited in application to the maximum story length
demonstrates the need for a stronger inductive bias
seen during training.
on how commonsense knowledge is used in story
generation. Brahman and Chaturvedi (2020) gen-
3.1 Language Model
erate stories that follow a given emotional arc for
a protagonist, using COMET to infer the protago- We fine-tune GPT-2 on a pre-processed version of
nist’s emotions. The C2PO system (Ammanabrolu the ROCStories corpus (Mostafazadeh et al., 2016)
et al., 2021) uses COMET to generate successor to encourage story generation. Following Guan
and predecessor events instead of a language model, et al. (2020), we pre-process the corpus to remove
performing a bi-directional search from a given character names, replacing them with [MALE] or
start event and a given end event. However, C2PO [FEMALE]. In our pipeline, we enforce the telling
generates plots made up of short statements of char- of a two-character narrative in an interleaving fash-
acter intentions. ion wherein characters take turns being the subject
of each sentence. This is a simplifying assump-
3 The CAST Method tion, but fits the pattern that occurs in many stories
in which one character acts and another character
The conventional set up for neural k-sentence story
reacts. We achieve the turn-taking by condition-
generation is: given the first sentence s1 of a story—
ing the language model generation with both the
a prompt—generate the subsequent k − 1 sen-
previous story context and the tag denoting the
tences, s2 , s3 , ..., sk . The Commonsense inference
character who is to take a turn. For example if
Augmented neural StoryTelling (CAST) method is
the last sentence in the story is “[MALE] was upset
as follows. To generate sentence si with 2 ≤ i ≤ k:
with [FEMALE].”, we append the tag of the oppo-
1. We condition a fine-tuned language model site character to the context, i.e., [FEMALE]. Since
on the story up to the current sentence the next sentence now starts with the tag associ-
[s1 , . . . , si−1 ] followed by a token signifying ated with the opposite character of the one who
the subject of sentence i. acted in the previous sentence, the language model
will be biased toward describing the action for that
2. We sample a sentence candidate c from the character.previous
COMET
inferences
"[MALE] had a big
s1 ... si-1 si
crush on [FEMALE]."
no Match? yes si+1
Generate candidate
"[FEMALE]" context candidate COMET
candidate inferences
oWant → xIntent
"[MALE] had a big crush "[FEMALE] wanted to oReact → xAttr
PREFIX
on [FEMALE]. [FEMALE]" go to prom with him."
Figure 2: The overall procedure of generating two-character narratives with the CAST pipeline.
Type Description relations:
xIntent The reason why PersonX would cause the event
xNeed What PersonX might need to do before the event • The event in si−1 affects the wants of a char-
xAttr How PersonX might be described given the event acter, which manifests as an intention of the
oReact The reaction of Others to the event primary character in c (oWant→xIntent).
oEffect The effect the event has on Others
oWant What Others may want to do after the event • An effect of the event in si−1 manifests itself
as something the primary character needs in c
Table 1: Definitions of the six types of ATOMIC rela-
(oEffect→xNeed).
tions that CAST uses. See Sap et al. (2019) for the full
set. The top set describes preconditions of the current
• A reaction to the event in si−1 is expected
sentence and the bottom set describes postconditions
of the previous sentence. Dotted lines show how we and matches some property of the primary
match postconditions to preconditions during the filter- character in c (oReact→xAttr).
ing phase.
In this way, we create hard constraints via a
form of chaining that allows us to filter a set
3.2 Commonsense Inferences of potential sentence generations to find one
that adequately matches the expected inferences.
To produce commonsense inferences for each sen- The oWant→xIntent pattern corresponds to how
tence, we use the COMET model (Bosselut et al., readers track how characters form and carry
2019) to infer a set of ATOMIC (Sap et al., 2019) out intentions in reader comprehension models
relations for each generated sentence. COMET (Graesser et al., 1991). The oEffect→xNeed and
generates commonsense inferences for a single sen- oReact→xAttr correspond to how readers track
tence, referring to PersonX as the sentence’s sub- causal consequences in reader comprehension mod-
ject, and Others as other characters in the story. els (Trabasso and Van Den Broek, 1985).
Due to our two-character closed-world assumption, To filter out “unqualified” sentence candidates
we assume Others to refer to the second character. generated by the language model, we match the
We identify six of ATOMIC’s nine relation inference types described in Table 1 and their ar-
types that are useful for creating coherent relations guments. For example, suppose sentence si−1 is
between story events: xIntent, xNeed, xAttr, “[MALE] gives [FEMALE] a burger”. Its oEffect
oReact, oEffect, and oWant. Table 1 provides is “have a burger”. If sentence si is “[FEMALE]
the definitions. We treat the first three relation eats the burger”, it will have an xNeed that is also
types as preconditions of an event because they “have a burger”, which represents the prerequisite
infer facts that might need to be true for an event to of “having a burger” in order to “eat a burger”.
be enacted, such as a character having an intention, In practice, we find that simple string match-
a goal, or a property. We categorize the final three ing does not adequately capture when two inferred
as postconditions of an event because they infer relations’ arguments have slightly different phras-
things that might change once an event is enacted, ing (e.g., “to sleep” versus “sleeping”). We define
such as a character reaction, an effect of the action, a match as the semantic similarity between two
or a character forming an intention. inferences exceeding a certain threshold. We en-
Once we have inferred relations for the previous code each relation argument into a fixed-length
sentence si−1 and current candidate sentence c, vector representation, and then compute the cosine
we look for specific patterns between the sets of similarity. We use Sentence-BERT (Reimers andGurevych, 2019) for encoding, as it is designed Sentence Pair Inferences
for semantic similarity tasks and performs better [MALE] had a big crush on [FEMALE].
None
than the traditional BERT on sentence similarity [FEMALE] was constantly yelling at him.
benchmarks. [MALE] had a big crush on [FEMALE]. oReact→xAttr
We use 80% semantic similarity as our lower- [FEMALE] wanted to go to prom with him. oWant→xIntent
bound. We find this value correctly considers the in- [MALE] took [FEMALE] fishing in summer.
None
[FEMALE] got very sick.
ferences listed above as matches, but excludes less-
related inferences. This value can also be tuned to [MALE] took [FEMALE] fishing in summer.oReact→xAttr
[FEMALE] was loving it. oWant→xIntent
increase or decrease the strength of the matching
constraint at the cost of runtime computation—a Table 2: Examples of generated labeled sentence pairs.
higher threshold requires more candidate sentences Sentence pairs with no matching inferences are labeled
generated by the language model to be evaluated. with 0, while those with over 2 matching inference
In order to balance computation time and quality pairs are labeled with 1.
of the match, we only require two of three inference
type pairs to match between a seed and a candidate
without matches incur more loss. The first sentence
sentence. In practice, we find this results in higher
of the pair is masked so that loss is only calculated
quality sentences than if we only require one out
on the logits that produce the successor sentence.
of three pairs to match, but is significantly more
efficient than three out of three. For maximal fil- 4 Experiments
tering strength and best coherence, all three pairs
would be required to match. However, in our pilot We conducted three experiments to evaluate the
experiments, the model is rarely able to generate CAST technique. The first experiment assesses
any “qualified” sentence within 100 sentence can- whether fine-tuning neural language models on
didates, when required to match all three pairs. commonsense knowledge alone can significantly
address the challenge of generating coherent nar-
3.3 Fine-tuning on Commonense Inferences ratives. The second experiment compares CAST
CAST generates candidate sentences until one to two unconstrained neural language models story
passes the inference matching process. Each candi- generators: GPT-2 and the work by Guan et al.
date considered requires a set of commonsense in- (2020). The third experiment assesses whether
ferences and semantic matching—computationally CAST can be used to fine-tune a neural language
expensive processes. To increase the probability model. Story examples can be found in Table 3 and
that the neural language model generates candidate Appendix B.
sentences that will pass the filter, we fine-tune GPT-
Metrics. Purdy et al. (2018) proposed a set of
2 using a policy gradient reinforcement learning
questions for evaluating story generation systems
technique inspired by Peng et al. (2020).
that includes dimensions such a logical coherence,
As CAST generates sentences, it stores sentence
loyalty to plot, and enjoyability. A variation of
pairs along with a label, 0 for no relation matches,
these questions have been used in evaluations of
or 1 for two or more relation matches. Some ex-
other story generation systems (Tambwekar et al.,
amples are given in Table 2. After generating a
2019; Ammanabrolu et al., 2020, 2021). We mod-
full story of k sentences, GPT-2 is fine-tuned on
ify a subset of these questions to simplify the lan-
the labeled sentence pairs using the reinforcement
guage and focus more on participants’ overall im-
learning technique. To punish the generation of
pressions of the narrative coherence:
“unqualified” sentences, we use the following loss
function: • The story FOLLOWS A SINGLE TOPIC
• The story AVOIDS REPETITION
losss (s) if label = 1 • The story uses INTERESTING LANGUAGE
lossRL (s) =
losss (s) × ρ if label = 0 • Which story makes better LOGICAL SENSE?
(1) We conduct our studies on a crowdworking plat-
form. Only those who pass a screening question
where losss (s) is the cross-entropy loss given by are qualified for the study. Participants must also
Radford et al. (2018) and ρ is a constant (ρ ≥ 1) explain their preferences with more than 50 char-
controlling the strength of punishment—sentences acters of writing. This helps filter out low-qualitySeed Prompt: erated by GPT-ROC and GPT-ATOMIC-ROC and
Bob invited Alice to hang out. answered the set of questions introduced earlier for
CAST: each story, providing ratings for each question on a
Alice planned a nice dinner for Bob.
Bob and Alice spent all evening cooking dinner together.
scale from 1-5. At least five crowd workers rated
Alice was happy to see her dinner cooked. each story.
Bob was impressed with how delicious her dinner was. The results, summarized in Table 4, show that
GPT-ROC: GPT-ROC-ATOMIC performs slightly better than
Alice thought Bob was funny.
Bob got mad and threatened Alice with punches. GPT-ROC on some questions, but slightly worse
Alice ended up running away from Bob. on plausible order. However, none of these dif-
Bob was awarded the fun they had together.
:::::::::::::::::::::::::::::::: ferences are statistically significant as deterimined
CAST-RL: by a Mann-Whitney U-test. This result indicates
Alice invited Bob to hang out. that fine-tuning on a static commonsense knowl-
Bob agreed, and was happy to meet her.
Alice was very happy and liked Bob. edge base alone is not sufficient to improve story
Bob and Alice still hang out after that. coherence. For this reason, we use GPT-ROC as
Guan et al. (2020) the base language model for CAST in subsequent
Alice thought she would like it. experiments.
Bob only wanted to show her the interest of a nerdy rlist.
Alice seemed to:::
like::::
Bob ::::
asked::::
Bob ::::::
because :::
she :::
likes::::
him.
Bob ended up meeting Alice after
::::::::::::::::::::::::::::::
school. 4.2 Experiment 2: CAST
Table 3: Story examples generated by CAST, CAST- In this set of experiments we assess whether the
RL, GOT-ROC and Guan et al. (2020). Story gener- CAST constraint method improves story coherence
ated by CAST follows a single topic (bolded) – cook- over the GPT-ROC and Guan et al. (2020) baselines.
ing dinner, and shows a good plot coherence. However, We recruited 116 participants. Each participant
story generated by GPT-ROC fails to maintain plot co- read a randomly selected subset of 6 stories—one
herence (:::::::::
underlined) during generation. CAST-RL gen- from CAST and one from one of the baselines,
erates relatively more repetitive, boring but logical co-
GPT-ROC or Guan et al.. For each of the four ques-
herent narrative (in italic). Guan et al. (2020) also suf-
fers in plot coherence. tions described in Section 4, participants answered
which story best met the criteria. Participants read
either 5-sentence or 10-sentence stories. To gen-
responses and ensures the validity of the study. erate the stories, we again randomly selected 30
2-character prompts from the ROCStories corpus
Baselines. We evaluate CAST against three base- to seed the systems. The 10-sentence stories allow
lines. The first is GPT-2-small fine-tuned on ROC- us to look at the effect of story length on coherence
Stories (GPT-ROC), following prior work (Guan for CAST and the baseline GPT-ROC. They were
et al., 2020). The second baseline is GPT-2- generated on the same 30 prompts described above.
small fine-tuned on the ATOMIC dataset and then The results are shown in Table 5 (top). The re-
fine-tuned a second time on ROCStories (GPT- sults indicate that our model performs significantly
ATOMIC-ROC). The third baseline is the system better than baseline, GPT-ROC, on the “Logical
by Guan et al. (2020), which also fine-tunes GPT- Sense” and “Single Topic” dimensions. We con-
2-small on ATOMIC and ROCStories, but uses a clude that CAST improves the coherence of gener-
multi-objective training procedure. ated narratives and stays more on topic, while re-
taining comparably interesting language and avoid-
4.1 Experiment 1: Commonsense ance of repetition (neither of which are statisti-
Fine-Tuning cally significantly different). When we increase
The first human-participant study assesses whether the lengths of stories to 10 sentences from 5, a
fine-tuning on the ATOMIC commonsense greater proportion of participants prefer CAST to
database alone is sufficient to improve 2-character the baseline in the dimensions of “Logical Sense”
story generation coherence. 20 two-character first and “Single Topic” (∼ 10% increase). This shows
sentences were randomly sampled from ROCSto- that stories generated by CAST retain coherence
ries as seed sentences to produce 20 stories per longer relative to the baseline language model op-
baseline system. We recruited 34 participants. erating without constraints.
Each participant read 10 5-sentence stories gen- CAST also significantly outperforms Guan et al.Model Single Plot Plausible Order Avoids Repetition Enjoyable
GPT-ROC 3.025 ± 1.180 2.825 ± 1.188 3.525 ± 1.031 2.575 ± 1.041
GPT-ATOMIC-ROC 3.213 ± 1.122 2.750 ± 1.153 3.713 ± 0.814 2.600 ± 1.165
Table 4: Human participant evaluation results for experiment 1. Each system was conditioned on the same 20
test-set prompts. 34 participants rated each story on a Likert scale (1-5). A confidence level of 95% over the scores
is presented. None of the models’ score differences are statistically significant at p < 0.10 by the Mann-Whitney
U test.
Story Logical Sense Single Topic Avoid Repetition Interesting LanguageNum
Models
lengthWin %Lose %Tie %Win %Lose %Tie %Win %Lose %Tie %Win %Lose % Tie % resp.
5 53.7**17.0 29.3 52.4**14.3 33.3 18.5 25.3 56.2 30.6 23.8 45.6 147
CAST vs GPT-ROC
10 63.3**19.3 17.4 55.0**14.7 30.3 33.9 48.6 17.5 34.9 34.9 30.2 109
5 64.8**19.4 15.8 62.5**18.5 19.0 26.9 31.9 41.2 27.4 34.4 38.2 216
CAST vs Guan et al.
10 73.9**11.3 14.8 86.7**7.6 5.7 27.6 50.5** 21.9 29.5 48.6* 21.9 115
GPT-ROC-RL vs GPT-ROC 5 68.1**21.3 10.6 63.8**20.2 16.0 33.0 39.4 27.6 41.5 29.8 28.7 94
CAST-RL vs GPT-ROC-RL 5 42.7 42.7 14.6 31.1 25.6 43.3 26.7 35.6 37.7 24.4 25.6 50.0 89
CAST-RL vs CAST 5 45.2 38.1 16.7 36.5 31.0 32.5 27.2 39.2 33.6 23.2 40.8* 36.0 126
Table 5: Human-participant evaluation results for experiments 2 and 3, showing the percentage of participants that
preferred the first system, second system, or thought the systems were equal. Each system was conditioned on the
same 30 test-set prompts. * indicates results are significant at p < 0.05 confidence level; ** at p < 0.01 using a
Wilcoxan sign test on win-lose pairs.
Model Train Set Test Set the neural language model and (b) reducing overall
CAST 20.43 ± 3.40* 28.31 ± 3.39* computation time by foregoing the inference and se-
CAST-RL 8.72 ± 1.95* 11.06 ± 1.81* mantic matching steps. We hypothesize fine-tuning
on CAST labels can increase robustness by generat-
Table 6: The average number of sentence candidates ing continuations that will pass the filtering process
generated before finding a match. A confidence level
with higher likelihood. This in turn decreases in
of 95% over 5 random-seed runs for each model is pre-
sented. Each system was conditioned on the same 30 the average number of sentence candidates needed
(training) and 10 (test) 2-character prompts from ROC- to be generated to find a match.
Stories. * indicates the difference between CAST and After generating 30 5-sentence stories with
CAST-RL is statistically significant at p < 0.01 using CAST using 40 different random seeds, we train
the Mann-Whitney U test. GPT-ROC with the 2 × 4 × 30 × 40 generated la-
beled sentence pairs as described in Section 3.3.1
in the “Logical Sense” and “Single Topic” dimen- This results in a new fine-tuned language model,
sions. When increasing story length to 10 sen- which we refer to as GPT-ROC-RL. 40 different
tences, the coherence of stories generated by the seeds for the language model are used to gener-
Guan et al. system drops substantially compared to ate sentence pairs in order to simulate fine-tuning
our model. Our model is worse at avoiding repeti- on very small datasets. Consistent with previous
tion and using interesting language, though these experiments, we use GPT-ROC as our baseline.
differences are only statisically significant on the To evaluate whether fine-tuning on CAST labels
10-sentence stories. We consider this a valuable improves story coherence, we recruited 59 partic-
tradeoff for logical coherence. ipants and replicated the protocol in Section 4.2,
except participants read pairs of stories from GPT-
4.3 Experiment 3: RL-Based Fine-Tuning ROC, GPT-ROC-RL, CAST, or CAST-RL (GPT-
Having established that CAST improves coherence, ROC-RL with CAST filtering on top).
we ask whether reinforcement-based fine-tuning Table 5 (bottom half) shows the percentage of
(Section 3.3) can be used to teach a language model 1
We generate 2 “matched” sentence pairs during each sen-
to model the CAST filtering method directly. In tence generation, one pair of each label. When k = 5, 4
doing so we hope to (a) increase the robustness of sentences are generated to form a 5-sentence story.times stories from each system are preferred for CAST method can be applied to any neural lan-
each metric. GPT-ROC-RL improves coherence guage model or be used to create a labeled fine-
over GPT-ROC to approximately the same degree tuning dataset. The approach presents a first at-
as CAST does over GPT-ROC, indicating that RL tempt at building text generation systems that rea-
fine-tuning can be an alternative to constraint-based son about their reader along multiple dimensions.
filtering on short (5-sentence) stories. CAST-RL
does not significantly improve the logical sense of
stories over GPT-ROC-RL, indicating that the re- References
inforcement learning process has generalized the Prithviraj Ammanabrolu, Wesley Cheung, William
CAST inferential constraints into the language Broniec, and Mark O Riedl. 2021. Automated sto-
model. GPT-ROC-RL performs better on avoid- rytelling via causal, commonsense plot ordering. In
Proceedings of AAAI, volume 35.
ing repetition and interesting language than CAST-
RL, implying more robust language generation. Fi- Prithviraj Ammanabrolu, Ethan Tien, Wesley Cheung,
nally, CAST-RL does improve the logical sense Zhaochen Luo, William Ma, Lara J Martin, and
and single topic a small amount over CAST, but Mark O Riedl. 2020. Story realization: Expanding
plot events into sentences. In Proceedings of AAAI,
not at a statisically significant level. Despite being
volume 34.
trained on CAST labels, the filtering process can
still improve coherence. However, it does so at the Antoine Bosselut, Hannah Rashkin, Maarten Sap, Chai-
expense of repetition and interesting language. tanya Malaviya, Asli Celikyilmaz, and Yejin Choi.
2019. Comet: Commonsense transformers for au-
Importantly, Table 6 shows that fine-tuning on tomatic knowledge graph construction. In Proceed-
CAST labels reduces the average number of can- ings of the 57th ACL, pages 4762–4779.
didates that need to be generated for a “match”
to 11 from 28. The RL fine-tuning procedure re- Faeze Brahman and Snigdha Chaturvedi. 2020. Mod-
eling protagonist emotions for emotion-aware sto-
duces CAST’s computation by 60.93%. Further
rytelling. In Proceedings of EMNLP, pages 5277–
fine-tuning results in an overfit language model 5294.
but this model is sufficient to tie models explicitly
using constraints (e.g., CAST-RL) on the issue of Elizabeth Clark, Yangfeng Ji, and Noah A. Smith. 2018.
coherence. Tables 5 and 6 taken together show the Neural text generation in stories using entity repre-
sentations as context. In Proceedings of NAACL-
benefit of CAST-RL for efficiency at no cost to HTL, pages 2250–2260.
desired model characteristics.
Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hi-
5 Conclusions erarchical neural story generation. In Proceedings of
the 56th ACL, pages 889–898.
Neural language models generate content based on Art Graesser, Kathy L. Lang, and Richard M. Roberts.
the likelihood of tokens given a historical context. 1991. Question answering in the context of sto-
Human readers, on the other hand, use complex ries. Journal of Experimental Psychology: General,
inferential processes to connect the relationships 120(3):254–277.
between events. This mismatch between genera- Art Graesser, Murray Singer, and Tom Trabasso. 1994.
tive models and reader comprehension is one of the Constructing inferences during narrative text com-
reasons why stories generated by neural language prehension. Psychological Review, 101(3):371–
models lose coherence over time. We present a 395.
new approach to neural story generation that at- Jian Guan, Fei Huang, Zhihao Zhao, Xiaoyan Zhu, and
tempts to model the inferred event relations and Minlie Huang. 2020. A knowledge-enhanced pre-
character intentions of human readers in order to training model for commonsense story generation.
generate more coherent stories. The CAST method Transactions of the ACL, 8:93–108.
provides hard constraints to neural language model
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and
generation that results in greater story coherence, Yejin Choi. 2019. The curious case of neural text de-
which crucially does not degenerate as the story generation. In International Conference on Learn-
gets longer. We further show that we can train ing Representations.
neural language models to emulate the logic of the
Ahmed Khalifa, Gabriella AB Barros, and Julian
CAST constraints using reinforcement learning. Togelius. 2017. Deeptingle. arXiv preprint
Our approach is relatively straightforward; the arXiv:1705.03557.Lara Martin, Prithviraj Ammanabrolu, Xinyu Wang, Tom Trabasso and Paul Van Den Broek. 1985. Causal
William Hancock, Shruti Singh, Brent Harrison, and thinking and the representation of narrative events.
Mark Riedl. 2018. Event representations for auto- Journal of memory and language, 24(5):612–630.
mated story generation with deep neural nets. In
Proceedings of AAAI, volume 32. Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin
Knight, Dongyan Zhao, and Rui Yan. 2019. Plan-
Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong and-write: Towards better automatic storytelling. In
He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Proceedings of AAAI, volume 33, pages 7378–7385.
Pushmeet Kohli, and James Allen. 2016. A corpus
and evaluation framework for deeper understanding
of commonsense stories. In Proceedings of NAACL-
HLT, pages 839–849.
Nanyun Peng, Marjan Ghazvininejad, Jonathan May,
and Kevin Knight. 2018. Towards controllable story
generation. In Proceedings of the First Workshop on
Storytelling, pages 43–49.
Xiangyu Peng, Siyan Li, Spencer Frazier, and Mark
Riedl. 2020. Reducing non-normative text genera-
tion from language models. In Proceedings of the
13th INLG, pages 374–383.
Christopher Purdy, Xinyu Wang, Larry He, and Mark
Riedl. 2018. Predicting generated story quality with
quantitative measures. In Proceedings of the AAAI
Conference on Artificial Intelligence and Interactive
Digital Entertainment, volume 14.
Alec Radford, Karthik Narasimhan, Tim Salimans, and
Ilya Sutskever. 2018. Improving language under-
standing by generative pre-training.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan,
Dario Amodei, and Ilya Sutskever. 2019. Language
models are unsupervised multitask learners.
Hannah Rashkin, Asli Celikyilmaz, Yejin Choi, and
Jianfeng Gao. 2020. Plotmachines: Outline-
conditioned generation with dynamic plot state
tracking. In Proceedings of EMNLP, pages 4274–
4295.
Nils Reimers and Iryna Gurevych. 2019. Sentence-
bert: Sentence embeddings using siamese bert-
networks. In Proceedings of EMNLP-IJCNLP,
pages 3982–3992.
Melissa Roemmele. 2016. Writing stories with help
from recurrent neural networks. In Proceedings of
AAAI, volume 30.
Maarten Sap, Ronan Le Bras, Emily Allaway, Chan-
dra Bhagavatula, Nicholas Lourie, Hannah Rashkin,
Brendan Roof, Noah A Smith, and Yejin Choi. 2019.
Atomic: An atlas of machine commonsense for if-
then reasoning. In Proceedings of AAAI, volume 33,
pages 3027–3035.
Pradyumna Tambwekar, Murtaza Dhuliawala, Lara J
Martin, Animesh Mehta, Brent Harrison, and
Mark O Riedl. 2019. Controllable neural story plot
generation via reinforcement learning. In Proceed-
ings of the 28th IJCAI.A Implementation Details inferences for each inference type, which results
in a higher percent of matched inferences in our
A.1 Data
preliminary experiments. We also qualitatively ob-
We use the preprocessed ROCStories corpus of serve that matching on a larger set of inferences
5-sentence stories (588,966 stories) and joint (as shown in the demo5 ) more often results in at
ATOMIC and ConceptNet dataset converted to tem- least one or a few high-quality inferences, due to
plate sentences (1,174,267 train/66,856 dev/73,083 COMET having some error.
test), both provided by Guan et al.2 We shuffle As mentioned in the body of the text, we use a
and split the ROCStories dataset into 80% (78,528) semantic similarity threshold of 80% and require 2
train and 20% (19,633) test sets. of 3 inferences to match. Runtime is feasible due
Following Guan et al. (2020), character names in to matching on two out of three inference filters
the ROCStories corpus are replaced with [MALE] and using the 5-beam COMET output. However, in
or [FEMALE] tags. This prevents skewed predic- some rare cases, no matching next-sentence candi-
tions due to the presence of certain names in a date can be found. If no qualified sentence is found
small dataset such as ROCStories and also allows after 50 generated candidates, in order to avoid
us to focus on 2-character stories without having potentially infinite search we loosen the filtering
to perform NER on generated sentences to remove strength to match only one pair of inferences.
extraneously generated names outside of the two
main characters. It also allows a direct comparison A.4 Preliminary Study Questions
to prior work. After a story is generated, we replace • The story FOLLOWS A SINGLE PLOT.
the [MALE] and [FEMALE] tags with user-inputted • The story’s events OCCUR IN A PLAUSI-
names, assuming the subject and object of the first BLE ORDER.
sentence are the subsequently-generated tags. • The story AVOIDS REPETITION.
• The story IS ENJOYABLE.
A.2 Models
Following Guan et al., we use the small version A.5 RL Fine-Tuning
of GPT-2 with 124M parameters as the base for We generate 30 5-sentence stories with CAST, us-
all fine-tuned models. When fine-tuning GPT-2 on ing 40 different seeds. 2 sentence pairs are gen-
either ROCStories and the commonsense knowl- erated when generating each following sentence
edge resources (done separately), we train with a and each 5-sentence story is composed of 4 follow-
batch-size of 16, a learning rate of 0.00005, and ing sentence. Hence, 2 × 4 × 30 × 40 sentence
using the Adam optimizer with gradient clipping at pairs are generated to fine-tune GPT-ROC with re-
a max norm of 1. All models were trained on sin- inforcement learning technique for 1 iteration. We
gle GeForce RTX 2080 GPUs in Pytorch using the use ρ = 0.001 in Section 3.3 to punish the ”un-
Huggingface Transformers library.3 We replicate match” sentence pairs.
the multi-task baseline of Guan et al. in Tensorflow
using their provided code.4 We train with early B Additional Story Outputs
stopping on the dev set (80% train,10% dev,10%
Additional 5-sentence story examples are as fol-
test split) loss with a patience of 10 epochs. Both
lows,
models converge within 1-2 epochs. All other train-
ing details are kept the same.
We use top-p sampling (Holtzman et al., 2019) Seed Prompt:
with a value of 0.9, a temperature of 1, and a max Bob and Alice went hiking together.
length of 20 tokens per sentence to sample from all
models. CAST:
Alice was excited because she planned a picnic.
A.3 CAST Bob was excited because he was staying up late at
When producing commonsense inferences from night.
COMET, we use “beam-5” setting to generate 5 Alice felt much better about her camping trip.
Bob spent the night playing in the woods.
2
https://cloud.tsinghua.edu.cn/d/670f7787b6554f308226/
3
https://huggingface.co/transformers/
4 5
https://github.com/thu-coai/CommonsenseStoryGen https://mosaickg.apps.allenai.org/comet atomicGPT-ROC:
Alice was being very loud.
Bob told Alice they did not agree. Seed Prompt:
Alice ordered pizza to be delivered. Bob took Alice fishing in the summer.
Bob showed up later and Alice was pleased.
CAST:
CAST-RL: Alice waited at the lake for hours.
Alice decided to take a group photo. Bob got another boat and brought it back home.
Bob shared the picture with Alice. Alice and Bob fished the next day.
Alice came over and smiled at Bob. Bob enjoyed the fishing and had a great time.
Bob was so happy that he took the picture.
GPT-ROC:
Guan et al. (2020): Alice took his friend’s boat.
Alice thought that the hike was cool. Bob brought with him to the water.
Bob was pretty cool. Alice stuck her hand out a river but the fishing got
Alice reminded him of the great fall, especially in stuck.
the forest. Bob snapped his fishing line and the boat stopped
in the middle.
Bob was cute, but Alice was lost.
CAST-RL:
Alice caught ten fish.
Seed Prompt:
Bob was pleased that he caught ten fish.
Bob asked Alice to come over for dinner.
Alice was very pleased to have a good fish.
Bob is glad that he caught ten fish.
CAST:
Alice wanted to go to a party.
Guan et al. (2020):
Bob agreed to go with her.
Alice got seasick.
Alice and Bob went to the concert.
Bob asked Alice to help him.
Bob bought a bottle of wine, and they enjoyed their
Alice went to Bob ’s house to tow Bob ’s boat.
time.
Bob got a surfboard for a big fishing trip.
GPT-ROC:
Alice said yes. Seed Prompt:
Bob put on his clothing. Bob was engaged to Alice.
Alice walked out of the restaurant.
Bob didn’t give Alice her favorite shirt. CAST:
Alice wanted a diamond ring.
CAST-RL: Bob thought that ring was the perfect diamond.
Alice said yes, so he brought her food. Alice loved the diamond ring and decided to buy it.
Bob had dinner with Alice that night. Bob went to the store and bought the ring.
Alice said yes to the dinner.
Bob was happy that he invited her to dinner with GPT-ROC:
him. Alice invited him to her wedding.
Bob refused and immediately broke down.
Guan et al. (2020): Alice stormed out of the door.
Alice drove and came over Bob ’s house in time. Bob was very upset that he would never see her
Bob decided to let Alice choose the foods. again.
Alice ate some dog food and then she met her hus-
band. CAST-RL:
Bob offered Alice a side of anything he had for Alice was going on a date with Bob.
dinner. Bob agreed to the date and married her.Alice now has two kids and needs the baby. Alice informed Bob she was very excited for him.
Bob is very happy he finally realized she was un- Bob was very appreciative.
happy. Alice said it was a perfect time.
Bob and Alice had a wonderful first date.
Guan et al. (2020): Alice was surprised she was invited to his birthday.
Alice just got a new husband. Bob was thrilled.
Bob wondered what to expect. Alice was happy to have a new boyfriend.
Alice bought the nice wedding ring from a daycare.
Bob wore it to the wedding. GPT-ROC:
Alice asked him to meet her at the restaurant.
Bob refused to get her out of the car.
Seed Prompt: Alice began to panic and began to argue with Bob.
Bob took Alice to school today. Bob ended up never talking to Alice.
Alice began to return the phone and she called the
CAST: restaurant.
Alice was a freshman. Bob got a new date with Alice.
Bob took her to the library. Alice left Bob with a very happy reunion.
Alice was excited to take the long bus ride to the Bob is so happy he is now dating Alice.
library. Alice is so happy she loves her new boyfriend.
Bob continued the long walk through the library.
Guan et al. (2020):
GPT-ROC: Alice and Bob didn’t realize that Bob loved movies.
Alice really needed Bob to come with her. Bob’s friend, Alice, saw the movie with Alice.
Bob knew he couldn’t get her to come with him. Alice and Bob were good friends.
Alice saw Bob grow up and change his attitude. Bob’s friend, Alice, screamed for Alice.
Bob is grounded because Bob is getting away with Alice was their eyes met her eyes.
everything. Bob and Alice’s grandparents were never match.
Alice because they had ever though, they thought
CAST-RL: the end the words said, she passed with Alice.
Alice had been waiting for hours at school. Bob and they agreed that they went out the eyes.
Bob was relieved to see her take the bus to school. Alice felt they got puppies and they do the thought
Alice was excited to see the bus arrive. she was their eyes Alice had.
Bob was proud of her for taking the bus to school.
Guan et al. (2020): Seed Prompt:
Alice was nervous because Bob didn’t know how Bob broke up with Alice.
to tap dance.
Bob was excited for his first attempt at tap dancing. CAST:
Alice was impressed and wanted to learn. Alice was very hurt and very angry.
Bob started his first dance at the dance school. Bob knew he would have to live with his pain.
Alice said she could give him a relief.
Additional 10-sentence story examples are as fol- Bob felt much better after that.
lows: Alice felt even better in peace.
Bob is now happy with himself.
Seed Prompt: Alice felt much better.
Bob went on her very first date with Alice. Bob will make himself a happy man.
Alice feels much better after having peace.
CAST:
Alice was very excited about having a date with GPT-ROC:
Bob. Alice had a fake boyfriend.
Bob was excited and eager. Bob found out Alice was missing.Alice promised to find her. Bob had a great time.
Bob found her in an alley. Alice had some great food and wine.
Alice never broke up with Bob again. Bob couldn’t wait to see Alice again.
Bob never broke up with Alice. Alice let him take a bath.
Alice was so happy to see him again. Bob felt smarter and had a good time again.
Bob is very happy being close to her. Alice also got his great seeing Alice tattoo.
Alice is happy that he’s okay now. Bob had a good time.
Alice tattooy from his favorite j tomorrow too.
Guan et al. (2020):
Alice didn’t want to get it.
Bob thought that he was too thin. Seed Prompt:
Alice said he could give back inside a horse. Bob went over to play at Alice’s house.
Bob could bring along for a ride and to return to
the river. CAST:
Alice had to drive for three days and she realized Alice liked to watch movies.
she was cheating. Bob was always there watching movies.
Bob and Alice got into a fight. Alice saw a movie she wanted to see.
Alice ran away with Alice and grounded. Bob was very glad to buy that movie.
Bob and sent Alice. Alice was so happy with the movie he bought.
Alice and a girl kicked each other. Bob was excited to be watching the movie with
Alice.
Alice could not wait to see the movie with Bob.
Seed Prompt: Bob and Alice had so many fun.
Bob went to see Alice today. Alice laughed and thanked Bob for the great movie.
CAST: GPT-ROC:
Alice told him about the movie she loved to watch. Alice and Bob played soccer.
Bob grabbed a movie poster from the library. Bob’s mom told him to throw a kick.
Alice shared her own reaction to the movie. Alice kicked him in the leg.
Bob watched the movie that night. Bob was glad that he never played there again. Al-
Alice felt very satisfied after the movie was over. ice’s mom apologized for the incident.
Bob went home happy that he watched the movie. Bob’s mom never learned to kick in the leg again.
Alice has been a huge fan of the movie ever since. Alice was very glad he never stopped playing soc-
Bob looks forward to a nice vacation at the movies. cer with her.
Alice is glad that she shared her own comments to Bob was happy that he was never kicked again.
the movie. Alice still still plays soccer every now and loves
hertime.
GPT-ROC:
Alice wanted to buy her a necklace. Guan et al. (2020):
Bob felt bad for her. Alice was a baby dolls.
Alice got the necklace. Bob told Alice he could save a doll.
Bob made it. Alice went to the video game section to change the
Alice was very happy with the necklace. game.
Bob was glad that she got to see Alice. Bob was amazed to see who did the laundry to the
Alice will never forget her great necklace. last minute.
Bob will never forget the necklace that Alice Alice waved and proposed the doll girls.
bought. Bob wished her that she was getting a doll.
Alice is glad that she bought her necklace. Alice helped him with the $40 and she gave her
$100, but by buttering buttering a doll.
Guan et al. (2020): Bob’s doll broke.
Alice was nice and gregarious. Alice had an ruined doll and they would buy her.You can also read

















































