ParaSCI: A Large Scientific Paraphrase Dataset for Longer Paraphrase Generation
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
ParaSCI: A Large Scientific Paraphrase Dataset for Longer Paraphrase
Generation
Qingxiu Dong1,3,4 , Xiaojun Wan1,2,3 and Yue Cao1,2,3
1
Wangxuan Institute of Computer Technology, Peking University
2
Center for Data Science, Peking University
3
The MOE Key Laboratory of Computational Linguistics, Peking University
4
College of Science, Minzu University of China
qingxiudong@icloud.com,{wanxiaojun,yuecao}@pku.edu.cn
Abstract used pos tags predicted by the stanford pos tag-
ger” as an example, the generated sentences from
We propose ParaSCI, the first large-scale para- Transformer (Vaswani et al., 2017) models trained
phrase dataset in the scientific field, including
on existing paraphrase datasets1 are “level basic
arXiv:2101.08382v2 [cs.CL] 5 Feb 2021
33,981 paraphrase pairs from ACL (ParaSCI-
ACL) and 316,063 pairs from arXiv (ParaSCI- topics : what is the basic purpose of stanford tradi-
arXiv). Digging into characteristics and com- tional hmo” and “a picture of a street sign with a
mon patterns of scientific papers, we construct sign on it”, far from ground-truth paraphrases.
this dataset though intra-paper and inter-paper We have noticed that the structure of scientific
methods, such as collecting citations to the papers is nearly fixed. Paraphrase sentence pairs
same paper or aggregating definitions by sci- appear not only within a paper (intra-paper) but also
entific terms. To take advantage of sentences
across different papers (inter-paper), which makes
paraphrased partially, we put up PDBERT as a
general paraphrase discovering method. The
it possible to construct a paraphrase dataset in the
major advantages of paraphrases in ParaSCI scientific field. For example, repetitions of the
lie in the prominent length and textual diver- same crucial contribution in a paper or explanations
sity, which is complementary to existing para- of the same term in different papers are potential
phrase datasets. ParaSCI obtains satisfactory paraphrases. Based on such characteristics, we
results on human evaluation and downstream design different methods to extract paraphrase pairs
tasks, especially long paraphrase generation. (shown in Section 4).
In terms of the construction methods, existing
1 Introduction
methods merely focus on the paraphrase relation-
A paraphrase is a restatement of meaning with dif- ship between entire sentences, while hardly han-
ferent expressions (Bhagat and Hovy, 2013). Being dle sentences with partial paraphrase parts, leaving
very common in our daily language expressions, it much original corpus idle. We find that if part of a
can also be applied to multiple downstream tasks sentence paraphrases another short sentence, such
of natural language processing (NLP), such as gen- sequences will be filtered out because the overall
erating diverse text or adding richness to a chatbot. semantic similarity is not high enough. For para-
At present, paraphrase recognition or paraphrase phrase discovering in this case, we fine-tune BERT
generation are largely limited to the deficiency of to extract semantically equivalent parts of two sen-
paraphrase corpus. Especially, due to the perma- tences and name it PDBERT. In order to train
nent vacancy of paraphrase corpus in the scien- PDBERT, we construct pseudo training data by
tific field, scientific paraphrase generation advances stitching existing paraphrase sentences, and train
slowly. Scientific paraphrases can not only be help- a paraphrase extraction model using the pseudo
ful for data augmentation of challenging scientific training data. In the end, this model performs well
machine translation, but is also effective for polish- on real scientific texts.
ing scientific papers. However, existing paraphrase After filtering, we obtain 350,044 paraphrase
datasets are mainly from news, novels, or social pairs and name this dataset ParaSCI. It consists
media platforms. Most of them remain short sen- of two parts: ParaSCI-ACL (33,981 pairs) and
tences and interrogative or oral style. As a result, ParaSCI-arXiv (316,063 pairs). Compared with
none of such training data can train out a scien- 1
Here we use Quora Question Pairs and MSCOCO, they
tific paraphrase generator. Taking the sentence “we are introduced in Section 2other paraphrase datasets, sentences in ParaSCI are Paraphrase Generation Datasets MSCOCO
longer and more sententially divergent. ParaSCI (Lin et al., 2014) was originally described as a
can be used for training paraphrase generation mod- large-scale object detection dataset. It contains
els. Furthermore, we hope that it can be applied human-annotated captions of over 120K images,
to enlarge training data for other NLP tasks in the and each image is associated with five captions
scientific domain. from five different annotators. In most cases, an-
Our main contributions include: notators describe the most prominent object/action
in an image, which makes this dataset suitable for
1. We propose the first large-scale paraphrase paraphrase-related tasks. Consequently, MSCOCO
dataset in the scientific field (ParaSCI), includ- makes great contribution to paraphrase genera-
ing 33,981 pairs in ParaSCI-ACL and 316,063 tion. Quora released a new dataset3 in January
pairs in ParaSCI-arXiv. Our dataset has been 2017, which consists of over 400K lines of poten-
released to the public2 . tial question duplicate pairs. Wieting and Gimpel
(2018) constructed ParaNMT-50M, a dataset of
2. We propose a general method for paraphrase
more than 50 million paraphrase pairs. The pairs
discovering. By fine-tuning BERT innova-
were generated automatically by translating the
tively, our PDBERT can extract paraphrase
non-English side of a large parallel corpus. Nowa-
pairs from partially paraphrased sentences.
days, MSCOCO and Quora are mainly used for
3. The model trained on ParaSCI can gener- paraphrase generation (Fu et al., 2019; Gupta et al.,
ate longer paraphrases, and sentences are 2018). Nevertheless, their sentence lengths or re-
enriched with scientific knowledge, such as lated domains are restricted.
terms and abbreviations.
3 Dataset
2 Related Work 3.1 Source Materials
Paraphrases capture the essence of language diver- Our ParaSCI dataset is constructed based on the
sity (Pavlick et al., 2015) and play significant roles following source materials:
in many challenging NLP tasks, such as question ACL Anthology Sentence Corpus (AASC)
answering (Dong et al., 2017), semantic parsing AASC (Aizawa et al., 2018) is a corpus of nat-
(Su and Yan, 2017) and machine translation (Cho ural language text extracted from scientific papers.
et al., 2014). Development in paraphrases relies It contains 2,339,195 sentences from 44,481 PDF-
heavily on the construction of paraphrase datasets. format papers from the ACL Anthology, a com-
Paraphrase Identification Datasets Dolan and prehensive scientific paper repository on computa-
Brockett (2005) proposed MSR Paraphrase Corpus tional linguistics and NLP.
[MSRP], a paraphrase dataset of 5,801 sentence ArXiv Bulk Data ArXiv4 is an open-access
pairs, by clustering news articles with an SVM repository of electronic preprints. It consists of sci-
classifier and human annotations. As is discovered, entific papers in the fields of mathematics, physics,
platforms such as Twitter also contain many para- astronomy, etc.. As the complete set is too large
phrase pairs. Twitter Paraphrase Corpus [PIT-2015] to process, we randomly select 202,125 PDF files
(Xu et al., 2015) contains 14,035 paraphrase pairs as our original data and convert them to TXT files,
on more than 400 distinct topics. Two years later, arranged by sentence.
Twitter Url Corpus [TUC] (Lan et al., 2017) was
proposed as a development of PIT-2015. TUC con- Semantic Scholar Open Research Corpus
tains 51,524 sentence pairs, collected from Twitter (S2ORC) S2ORC (Lo et al., 2020) is a large
by linking tweets through shared URLs and do contextual citation graph of scientific papers from
not leverage any classifier or human intervention. multiple scientific domains, consisting of 81.1M
Datasets such as MSRP or PIT-2015 encourage a papers, 380.5M citation edges. We select all the
series of work in paraphrase identification (Das and citation edges of ACL and arXiv from S2ORC for
Smith, 2009; Mallinson et al., 2017) but the size subsequent processing.
3
limitation hinders complex generation models. website:https://data.quora.com/First-Quora-Dataset-
Release-Question-Pairs
2 4
https://github.com/dqxiu/ParaSCI website:https://arxiv.org/help/bulk data3.2 Basic Information cancy of large-scale long paraphrase pairs.
According to the source materials, ParaSCI in- The degree of alteration is another important as-
cludes two subsets, ParaSCI-ACL and ParaSCI- pect of paraphrases. To compare our ParaSCI with
arXiv. Paraphrase pairs in ParaSCI-ACL focus on other existing paraphrase datasets in this aspect,
the NLP field, while paraphrase pairs in ParaSCI- we propose to calculate the BLEU4 score (Pap-
arXiv are more general. Some cases are shown ineni et al., 2002) between the source and target
in Table 1. ParaSCI show three main highlights: sentences of each paraphrase pair and name it Self-
1) Sentences included are long, nearly 19 words BLEU. In Table 2, ParaSCI, especially ParaSCI-
per sentence; 2) Sentences are more sententially ACL, shows a relatively low Self-BLEU, which
divergent; 3) It provides rich scientific knowledge. means sentences are significantly changed.
4 Method
Name Sentence A Sentence B
The process of identi- 4.1 Extracting Paraphrase Candidates
Word sense disam-
fying the correct mean-
biguation (wsd) is the Based on the unique characteristics of scientific
ParaSCI- ing, or sense of a word
task of identifying the
ACL
correct meaning of a
in context, is known papers, we extract the paraphrase sentences from
as word sense disam- a same paper (intra-paper) and across different pa-
word in context.
biguation (wsd).
pers (inter-paper). In most cases, we develop a sim-
In this paper, we study
In this work, we show ple but practical model to discover paraphrases in
how simple continu- different sections effectively. For a more challeng-
the use of standard
ous representations of
ParaSCI- continuous representa- ing case, when sentences are paraphrased partially
phrases can be suc-
ACL tions for words to gen-
cessfully used to in- rather than entirely, we propose PDBERT to collect
erate translation rules
duce translation rules
for infrequent phrases.
for infrequent phrases.
more paraphrase candidates.
Simon and Ronder 4.1.1 Intra-paper Extraction of Paraphrase
propose a constella- Simon et al. propose a Candidates
tion model to localize neural activation con-
ParaSCI-
parts of objects, which stellations part model Authors usually write down the same information
arXiv with transformed expressions repeatedly in differ-
utilizes cnn to find the to localize parts with
constellations of neu- constellation model. ent parts of the paper to emphasize critical informa-
ral activation patterns.
tion or echo back and forth. This kind of feature is
Here we will concen- We will put some em- the premise of our intra-paper extraction methods.
trate only on those as- phasis on those as-
ParaSCI-
arXiv
pects that are directly pects that are imme- Sentence BERT for Paraphrase Extraction
relevant to the odd- diately relevant to the
eron. odderon.
across Different Sections Noting that sentences
with shared semantics appear in different parts of
Table 1: Example paraphrase pairs in ParaSCI. Sen- one paper. For instance, the following sentences
tence A and corresponding Sentence B are paraphrase are from different parts of a same paper, and they
pairs. are paraphrases:
S1 : we propose a simple yet robust stochastic
answer network (SAN) that simulates multi-step
3.3 Statistic Characteristic reasoning in machine reading comprehension. (ab-
To assess the characteristics of ParaSCI, we com- stract, Liu et al. (2018))
pare its statistic characteristics with five main sen- S2 : we introduce Stochastic Answer Networks
tential paraphrase datasets in Table 2. The source (SAN), a simple yet robust model for machine
genre of ParaSCI is scientific papers. Therefore, reading comprehension. (introduction, Liu et al.
sentences are more formal and scholastic, and they (2018))
differ from oral TUC or newsy MSRP. The average However, sentences in Method, Data and Re-
sentence length of ParaSCI is almost twice as long sult sections are semantically different even when
as that of ParaNMT-50M, MSCOCO and Quora, they only have minor changes. For example, the
and also much longer than that of TUC. Its average strings other than numbers may be very similar
length is only a little shorter than that of MSRP. when presenting the two experimental results, but
As MSRP only contains 3,900 gold-standard para- the semantics are completely different. There-
phrases, our ParaSCI is complementary to the va- fore, we mainly focus on six sections (Abstract,Name Genre Size (pairs) Gold Size5 (pairs) Len Char Len Self-BLEU
MSRP news 5,801 3,900 22.48 119.62 47.98
TUC Twitter 56,787 21,287 15.55 85.10 12.53
ParaNMT-50M Novels, laws 51,409,585 51,409,585 12.94 59.18 28.60
MSCOCO Description 493,186 493,186 10.48 51.56 31.97
Quora Question 404,289 149,263 11.14 52.89 29.46
ParaSCI-ACL Scientific Papers 59,402 33,981 19.10 113.76 26.52
ParaSCI-arXiv Scientific Papers 479,526 316,063 18.84 114.46 29.90
Table 2: Statistic characteristics of main existing paraphrase datasets and our ParaSCI. As ParaNMT-50M is too
large, we sample 500,000 pairs as representatives. Len means the average number of words per sentence and Char
Len represents the average number of characters per sentence. We calculate Len, Char Len and Self-BLEU of the
gold-standard paraphrases rather than the whole size of sentences.
Introduction, Background, Discussion, Preamble Then we randomly pick out two sentences from the
and Conclusion). We directly obtain embeddings whole sentence set, as Sentence C and Sentence
of sentences through BERT (Devlin et al., 2018). D. We use Sentence A as input 1, and concate-
Then, we calculate the cosine similarity pair by pair nate Sentence C, Sentence B and Sentence D, with
and retain sentence pairs with a similarity score the 80%, 50%, and 80% appearance probabilities
higher than 0.931 as favorable paraphrase candi- respectively, as input 2. Input 1 and input 2 are
dates. 16,563 paraphrase candidates from ACL further concatenated by adding a token [CLS] at
and 158,227 paraphrase candidates from arXiv are the beginning of input 1, and inserting a [SEP] to-
obtained efficiently in this way. ken between input 1 and input 2. The start and
It is noteworthy that as information is hardly end positions of Sentence B in the concatenated
repeated in the same section, we exclude the com- string are recorded as the ground-truth. It is worth
parison between sentences in the same section. mentioning that while concatenating, the ending
punctuations of Sentence C and Sentence B are re-
PDBERT for Paraphrase Discovering In fact, moved. Besides, the random selection of sentences
two sentences, even if they are not semantically in input 2 guarantees our model to cover various
equivalent, may share some parts with common situations, for example, the first part of input 2 is
semantics. For example: the ground-truth paraphrase of input 1, or input 2
S1 : rationales are never given during training. is just Sentence B.
S2 : in other words, target rationales are never In this way, we generate a great number of train-
provided during training; the intermediate step ing pairs. Input 1 represents a short sentence and
of rationale generation is guided only by the two input 2 represents a long sentence, which includes
desiderata discussed above. the paraphrase of the short one. We fine-tune the
S1 and the bold part of S2 constitute a para- model to predict the start and end positions of Sen-
phrase. However, since the similarity between tence B using a softmax function.
the entire S1 and S2 is only 0.88, this pair of sen- Although our training data are pseudo, the fine-
tences will be filtered out. This phenomenon fre- tuned model performs well on the real data. For a
quently occurs when a sentence is much longer given real sentence pair, we take the shorter sen-
than the other, so that part of the long sentence tence as input 1 and the longer one as input 2, and
paraphrases the short sentence. To resolve this extract from the long sentence according to the
problem, we propose a new paraphrase discovering predicted positions. Actually, there is a tiny proba-
model, PDBERT. bility that the entire long sentence is the paraphrase
Our model architecture is shown in Figure 1. We of the short sentence. We exclude such a result
use the paraphrase sentence pairs recognized based because we have already obtained it via sentence
on sentence similarity (our first method mentioned BERT. Here we obtain 9,915 paraphrase candidates
above) to construct pseudo-labeled data for model from ACL and 45,397 pairs from arXiv.
training. For each genuine paraphrase pairs, we We compare our PDBERT model with a best-
take one as Sentence A and the other as Sentence B. clause baseline. The latter is simply splitting theFigure 1: A general paraphrase discovering model, PDBERT. We fine-tune a 12-layer BERT model for predicting
the start and end positions of the paraphrase part. The bottom of the figure shows the construction of labeled data.
long sentence into several clauses by punctuation concept in different papers and citations to the same
and selecting the combination of clauses that have paper.
a maximum similarity with the short sentence. We
Explanations of the Same Concept In scientific
Method Speed Size BERTScore
papers, in order to introduce the definition of a task
Best-clause 7.16 341 74.06 or a scientific terminology, the authors often ex-
PDBERT 32.34 387 88.23 plain it in one sentence. Therefore, various defini-
tions of the same term in different papers become
Table 3: Comparison of paraphrase discovering meth- paraphrase candidates naturally, just as the follow-
ods. We divide the number of all the processed sen-
ing case:
tence pairs by time (720 minutes) as processing speed.
Filtering out what can be obtained via sentence BERT, S1 : Sentence compression is the task of produc-
we take the number of remaining pairs as size of valu- ing a shorter form of a single given sentence, so
able extractions and use BERTScore (scibert-scivocab- that the new form is grammatical and retains the
uncased) to evaluate their quality. most important information of the original one.
implement PDBERT and the baseline method on S2 : Sentence compression is a task of creating
the same corpus and compare the processing speed, a short grammatical sentence by removing extra-
size of valuable extractions and BERTScore(Zhang neous words or phrases from an original sentence
et al., 2019). Table 3 demonstrates the comparison. while preserving its meaning.
PDBERT has a higher extraction speed because, in In order to extract the definition sentences from
the baseline method, we have to embed each pos- different papers, we design a series of possible pat-
sible combination of clauses. For valuable extrac- terns (regular expressions) of definition sentences
tions, PDBERT extracts a larger size of candidate and tag the terms in them. In the same subject or
paraphrase pairs. Moreover, the BERTScore of area (provided by meta-data of source materials),
PDBERT’s results is higher, indicating its semantic the extracted sentences are aggregated according
advantage in paraphrase discovering. to terms, so we obtain multiple explanations of
the same concept. In order to ensure the same se-
4.1.2 Inter-paper Extraction of Paraphrase
mantics, we combine them into pairs and adopt the
Candidates
method in Section 4.1.1 to filter out the sentence
Paraphrases also exist across different papers in pairs that are semantically different. Here we get
the same field, including explanations of the same 5,912 paraphrase candidates from ACL and 63,258
5
gold-standard paraphrase paraphrase candidates from arXiv.Citations to the Same Paper Scientific papers crete setting of scibert-scivocab-uncased L8 no-
often need to cite previous works. Besides, au- idf version=0.3.3.
thors tend to give a brief introduction (i.e., citation We design paraphrase length rate (PLR) as an-
text) to the cited paper. If different papers cite the other filter because the numbers of words in two
same one, the introductory sentences to this cited paraphrase sentences usually do not vary too much.
paper in different papers also naturally constitute a PLR is simply calculated as:
sentence set with possible paraphrase relationships.
Figure 2 provides an example. |LA − LB |
min(LA , LB )
LA and LB stand for lengths of the correspond-
ing sentences.
For paraphrase candidates extracted from expla-
nations of the same concept, they consist of more
abstract knowledge so we set a loose restriction.
We select those with a BERTScore higher than 0.6
and PLR lower than 2. Therefore, we get 4,566
definition paraphrase pairs from ACL candidates
and 49,052 pairs from arXiv candidates. For para-
phrase candidates extracted from other methods,
we change the threshold of BERTScore to be 0.7
and PLR to be 1.0. In this way, we get another
Figure 2: Example of extracting paraphrase pairs from 29,415 pairs from ACL candidates and 267,106
papers sharing a same cited paper. pairs from arXiv candidates.
We locate the citations in the paper through 5 Manual Evaluation
S2ORC data and extract the citation sentence and
the cited article. All the extracted results are ag- We conduct a manual analysis of our dataset in or-
gregated according to the same cited paper. Then der to quantify its semantic consistency and literal
we match sentences in the same group. Similarly, variation lexically, phrasally and sententially. We
in order to ensure the same semantics, we use the employ 12 volunteers who are proficient in English
method in Section 4.1.1 to filter out semantically to rate the instances. Three human judgements are
inconsistent sentence pairs. In this way, we obtain obtained for every sample and the final scores are
27,016 pairs of candidates for ACL and 212,644 averaged across different judges.
pairs for arXiv. Consistency Evaluation Criterion For seman-
4.2 Selecting High-quality Paraphrases tic consistency of paraphrase pairs, we design 5
degrees to distinguish. For a sentence pair to have
Due to insufficient computing resources, we have a rating of 5, the sentences must have exactly the
used a rough but fast filtering method to construct same meaning with all the same details. To have
paraphrase candidate set as mentioned above. It a rating of 4, the sentences are mostly equivalent,
includes 59,406 pairs from ACL and 479,526 pairs but some unimportant details can differ. To have
from arXiv. To obtain the high-quality paraphrase a rating of 3, the sentences are roughly equivalent,
corpus, we implement domain-related BERTScore with some important information missing or that
and paraphrase length rates to determine if a can- differs slightly. For a rating of 2, the sentences
didate pair is really paraphrase. Our two-stage are not equivalent, even if they share minor details.
construction process works in a coarse-to-fine way. For a rating of 1, the sentences are totally different.
BERTScore leverages the pre-trained contextual (Examples are shown in the appendix)
embeddings from BERT and matches words in can-
didate and reference sentences by cosine similar- Variation Evaluation Criterion For literal vari-
ity. It has been shown to correlate with human ation of paraphrase pairs lexically, phrasally and
judgment on sentence-level and system-level evalu- sententially, we use the following criterion respec-
ation. We calculate domain-related BERTScore tively: 5 means there are more than five variations
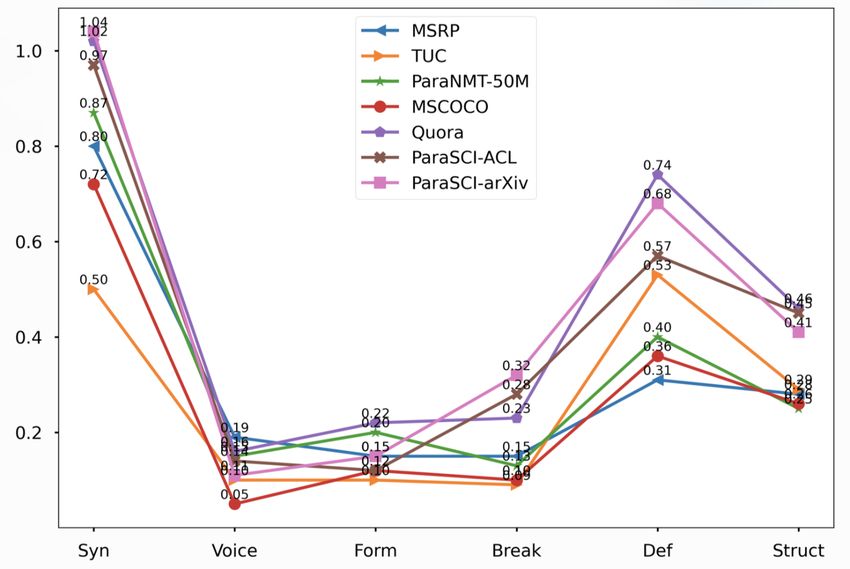
for each paraphrase candidate, with the con- of this level, 4 means four or five, 3 means two orName Lexical Phrasal Sentential Name Syn Voice Form Break Def Struct
MSRP 0.80 0.19 0.15 0.15 0.31 0.28
ParaSCI-ACL 3.82 2.73 2.01 TUC 0.50 0.10 0.10 0.09 0.53 0.29
ParaSCI-arXiv 3.67 2.68 1.48 ParaNMT-50M 0.87 0.15 0.20 0.13 0.40 0.25
MSCOCO 0.72 0.05 0.12 0.10 0.36 0.26
Quora 1.02 0.16 0.22 0.23 0.74 0.46
Table 4: Overall variation of ParaSCI from manual
ParaSCI-ACL 0.97 0.14 0.12 0.28 0.57 0.45
evaluation. ParaSCI-arXiv 1.04 0.11 0.15 0.32 0.68 0.41
Table 5: Example of extracting paraphrase pairs from
three, 2 means it has only one change and 1 means papers sharing a same cited paper.
no change.
Quality Control We evaluate the annotation a word with its definition or meaning), Structure
quality of each worker using Cohen’s kappa agree- (use different sentence structures to express the
ment (Artstein and Poesio, 2008) against the ma- same thing). We report the average number of oc-
jority vote of other workers. We asked the best currences of each paraphrase type per sentence pair
worker to label more data by republishing the ques- for each corpus in Table 5 and visualize that in
tions done by workers with low reliability (Co- Figure 3.
hen’s kappaTraining Test BLEU Len As we use domain-related terms and correspond-
ing abbreviations in scientific texts frequently, this
Quora ParaSCI-ACL 6.31 14.23
advantage can add conciseness, technicality and
Quora ParaSCI-arXiv 8.06 13.92
naturality to the generated sentences.
ParaSCI-ACL ParaSCI-ACL 15.70 18.45
Another thing to mention is that some common
ParaSCI-arXiv ParaSCI-arXiv 27.18 18.82
sense or scientific knowledge is also taken into
paraphrase generation. For example, we input “the
Table 6: BLEU scores and average lengths of scientific penn discourse treebank is the largest corpus richly
paraphrase generation by Transformer models trained annotated with explicit and implicit discourse re-
on Quora and ParaSCI. Since the performance of the
lations and their senses.” as the original sentence.
model trained on MSCOCO is rather poor (BLEU4phrase dataset in the scientific field. It shows fa- Dipanjan Das and Noah A Smith. 2009. Paraphrase
vorable results in the either automatic or manual identification as probabilistic quasi-synchronous
recognition. In Proceedings of the Joint Confer-
evaluation.
ence of the 47th Annual Meeting of the ACL and the
For future work, although we filter out more than 4th International Joint Conference on Natural Lan-
200 thousand paraphrase candidates to promise guage Processing of the AFNLP: Volume 1-Volume
the quality of ParaSCI, most candidates include 1, pages 468–476. Association for Computational
Linguistics.
valuable paraphrase patterns lexically or phrasally.
Therefore, more paraphrase patterns are remaining Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
to be discovered. Similarly, compared to the bulk Kristina Toutanova. 2018. Bert: Pre-training of deep
data on arXiv or other scientific websites, we only bidirectional transformers for language understand-
ing. arXiv preprint arXiv:1810.04805.
use the tip of an iceberg to construct this dataset,
and we are expecting to implement the methods in William B Dolan and Chris Brockett. 2005. Automati-
other scientific domains. For instance, we can ob- cally constructing a corpus of sentential paraphrases.
tain a biomedical paraphrase dataset from PubMed. In Proceedings of the Third International Workshop
on Paraphrasing (IWP2005).
We hope that ParaSCI can be used to augment
training data for various NLP tasks, such as ma- Li Dong, Jonathan Mallinson, Siva Reddy, and Mirella
chine translation in scientific field, and make more Lapata. 2017. Learning to paraphrase for question
answering. arXiv preprint arXiv:1708.06022.
contributions to the development of NLP.
Yao Fu, Yansong Feng, and John P Cunningham. 2019.
Acknowledgments Paraphrase generation with latent bag of words. In
Advances in Neural Information Processing Systems,
This work was supported by National Natural Sci- pages 13623–13634.
ence Foundation of China (61772036), Beijing
Ankush Gupta, Arvind Agarwal, Prawaan Singh, and
Academy of Artificial Intelligence (BAAI) and Key Piyush Rai. 2018. A deep generative framework for
Laboratory of Science, Technology and Standard in paraphrase generation. In Thirty-Second AAAI Con-
Press Industry (Key Laboratory of Intelligent Press ference on Artificial Intelligence.
Media Technology). We appreciate the anonymous
Wuwei Lan, Siyu Qiu, Hua He, and Wei Xu. 2017.
reviewers for their helpful comments. Xiaojun Wan A continuously growing dataset of sentential para-
is the corresponding author. phrases. In Proceedings of The 2017 Conference on
Empirical Methods on Natural Language Process-
ing (EMNLP), pages 1235–1245. Association for
Computational Linguistics.
References
Akiko Aizawa, Takeshi Sagara, Kenichi Iwatsuki, and Tsung-Yi Lin, Michael Maire, Serge Belongie, James
Goran Topic. 2018. Construction of a new acl an- Hays, Pietro Perona, Deva Ramanan, Piotr Dollár,
thology corpus for deeper analysis of scientific pa- and C Lawrence Zitnick. 2014. Microsoft coco:
pers. In Third International Workshop on SCIentific Common objects in context. In European confer-
DOCument Analysis (SCIDOCA-2018), Nov. 2018. ence on computer vision, pages 740–755. Springer.
Xiaodong Liu, Yelong Shen, Kevin Duh, and Jianfeng
Ron Artstein and Massimo Poesio. 2008. Inter-coder
Gao. 2018. Stochastic answer networks for ma-
agreement for computational linguistics. Computa-
chine reading comprehension. In Proceedings of the
tional Linguistics, 34(4):555–596.
56th Annual Meeting of the Association for Compu-
tational Linguistics (Volume 1: Long Papers), pages
Rahul Bhagat and Eduard Hovy. 2013. What is a para- 1694–1704, Melbourne, Australia. Association for
phrase? Computational Linguistics, 39(3):463–472. Computational Linguistics.
Chutima Boonthum. 2004. iSTART: Paraphrase recog- Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kin-
nition. In Proceedings of the ACL Student Research ney, and Daniel S. Weld. 2020. S2ORC: The Seman-
Workshop, pages 31–36, Barcelona, Spain. Associa- tic Scholar Open Research Corpus. In Proceedings
tion for Computational Linguistics. of ACL.
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gul- Jonathan Mallinson, Rico Sennrich, and Mirella Lap-
cehre, Dzmitry Bahdanau, Fethi Bougares, Holger ata. 2017. Paraphrasing revisited with neural ma-
Schwenk, and Yoshua Bengio. 2014. Learning chine translation. In Proceedings of the 15th Con-
phrase representations using rnn encoder-decoder ference of the European Chapter of the Association
for statistical machine translation. arXiv preprint for Computational Linguistics: Volume 1, Long Pa-
arXiv:1406.1078. pers, pages 881–893.Eleni Miltsakaki, Rashmi Prasad, Aravind K Joshi, and Bonnie L Webber. 2004. The penn discourse tree- bank. In LREC. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic eval- uation of machine translation. In Proceedings of the 40th annual meeting on association for compu- tational linguistics, pages 311–318. Association for Computational Linguistics. Ellie Pavlick, Pushpendre Rastogi, Juri Ganitkevitch, Benjamin Van Durme, and Chris Callison-Burch. 2015. Ppdb 2.0: Better paraphrase ranking, fine- grained entailment relations, word embeddings, and style classification. In Proceedings of the 53rd An- nual Meeting of the Association for Computational Linguistics and the 7th International Joint Confer- ence on Natural Language Processing (Volume 2: Short Papers), pages 425–430. Yu Su and Xifeng Yan. 2017. Cross-domain se- mantic parsing via paraphrasing. arXiv preprint arXiv:1704.05974. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information pro- cessing systems, pages 5998–6008. John Wieting and Kevin Gimpel. 2018. ParaNMT- 50M: Pushing the limits of paraphrastic sentence em- beddings with millions of machine translations. In Proceedings of the 56th Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 451–462, Melbourne, Australia. Association for Computational Linguistics. Wei Xu, Chris Callison-Burch, and Bill Dolan. 2015. Semeval-2015 task 1: Paraphrase and semantic simi- larity in twitter (pit). In Proceedings of the 9th inter- national workshop on semantic evaluation (SemEval 2015), pages 1–11. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Eval- uating text generation with bert. arXiv preprint arXiv:1904.09675.
A Appendices
Examples of semantic consistency evaluation are
shown in the following table.
Sentence A Sentence B Score
Task-oriented dialog We use a set of 318
systems help users to English function words
1
achieve specific goals from the scikit-learn
with natural language. package.
End-to-end task-oriented
Task-oriented dialog
dialog systems usually
systems help users to
suffer from the challenge 2
achieve specific goals
of incorporating knowl-
with natural language.
edge bases.
Opinion mining has re- Analysis has received
cently received consider- much attention in recent 3
able attentions. years.
We evaluated EMDQN
We evaluated all agents
on the benchmark suite
on 57 Atari 2600 games
of 57 Atari 2600 games 4
from the arcade learning
from the arcade learning
environment.
environment.
Here we will concentrate We will put some empha-
only on those aspects sis on those aspects that
5
that are directly relevant are immediately relevant
to the odderon. to the odderon.
Table 8: Examples of semantic consistency evaluation.You can also read

















































