PERFORMANCE AND ENERGY ANALYSIS WITH THE SNIPER MULTI- CORE SIMULATOR
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

PERFORMANCE
AND
ENERGY
ANALYSIS
WITH
THE
SNIPER
MULTI-‐CORE
SIMULATOR
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
IBRAHIM
HUR
KENZO
VAN
CRAEYNEST,
MATHIJS
ROGIERS
AND
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
INTEL
EXASCIENCE
LAB
• SoEware
and
hardware
for
ExaFLOPS-‐scale
machines
• CollaboraWon
between
Intel,
imec
and
5
Flemish
universiWes
• Study
Space
Weather
as
an
HPC
workload
Space Weather
Visualization
Modeling
Simulation Toolkit
Architectural Simulation Hardware design
2
GAINING
APPLICATION
INSIGHT
–
OVERVIEW
• Sniper
Overview
• Interval
SimulaWon
and
CPI
Stacks
• Accuracy
and
ValidaWon
• HW/SW
Co-‐opWmizaWon
• Sniper
Internals
– Running
Sniper
– ValidaWon
Details
– Sampled
SimulaWon
Details
– Interval
SimulaWon
Details
3
THE
SNIPER
MULTI-‐CORE
SIMULATOR
OVERVIEW
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
IBRAHIM
HUR,
KENZO
VAN
CRAEYNEST
AND
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY

TRENDS
IN
PROCESSOR
DESIGN:
CORES
Number
of
cores
per
node
is
increasing
– 2001:
Dual-‐core
POWER4
– 2005:
Dual-‐core
AMD
Opteron
– 2011:
10-‐core
Intel
Xeon
Westmere-‐EX
– 2012:
Intel
MIC
Knights
Corner
(60+
cores)
Westmere-‐EX,
Source:
Intel
Xeon
Phi
(MIC),
Source:
Intel
5
DEMANDS
ON
SIMULATION
ARE
INCREASING
LLC
Cache
Sizes
• Increasing
cache
sizes
60
50
– SimulaWon
requires
realisWc
40
Mbytes
30
applicaWon
working
sets
20
10
– Scaled-‐down
applicaWons
might
not
0
exhibit
the
same
behavior
Jan-‐93
Jul-‐98
Jan-‐04
Jul-‐09
Dec-‐14
IPF
x86
• Increasing
core
counts
• MulW-‐threaded
workloads
Xeon
Phi,
Source:
Intel
• New
soluWons
are
needed
6
NODE-‐COMPLEXITY
IS
INCREASING
• Significant
HPC
node
architecture
changes
– Increases
in
core
counts
• More,
lower-‐power
cores
(for
energy
efficiency)
– Increases
in
thread
(SMT)
counts
– Cache-‐coherent
NUMA
• OpWmizing
for
efficiency
Source:
Wikimedia
Commons
– How
do
we
analyze
our
current
soEware?
– How
do
we
design
our
next-‐generaWon
soEware?
7

OPTIMIZING
TOMORROW’S
SOFTWARE
• Design
tomorrow’s
processor
using
today’s
hardware
• OpWmize
tomorrow’s
soEware
for
tomorrow’s
processors
• SimulaWon
is
one
promising
soluWon
– Obtain
performance
characterisWcs
for
new
architectures
– Architectural
exploraWon
– Early
soEware
opWmizaWon
8
UPCOMING
CHALLENGES
• Direct
hardware
execuWon
does
not
provide
insight
– Reasons
for
a
loss
in
performance
is
now
always
easy
to
determine
– Does
not
allow
for
performance
predicWon
• Future
systems
will
be
diverse
– Varying
processor
speeds
– Varying
failure
rates
for
different
components
– Homogeneous
applicaWons
show
heterogeneous
performance
• SoEware
and
hardware
soluWons
are
needed
to
solve
these
challenges
– Handle
heterogeneity
(reacWve
load
balancing)
– Handle
fault
tolerance
– Improve
power
efficiency
at
the
algorithmic
level
(extreme
data
locality)
• Hard
to
model
accurately
with
analyWcal
models
9
FAST
AND
ACCURATE
SIMULATION
IS
NEEDED
• SimulaWon
use
cases
– Pre-‐silicon
soEware
opWmizaWon
– Architecture
exploraWon
• Cycle-‐accurate
simulaWon
is
too
slow
for
exploring
mulW/many-‐core
design
space
and
soEware
• Key
quesWons
– Can
we
raise
the
level
of
abstracWon?
– What
is
the
right
level
of
abstracWon?
– When
to
use
these
abstracWon
models?
10
FAST
OR
ACCURATE
SIMULATION?
Cycle-‐accurate
simulator
Higher-‐abstracWon
level
simulator
performance
performance
?
?
?
A
B
C
D
E
A
B
C
D
E
architecture
architecture
11
THE
ARCHITECTURE
DESIGN
WATERFALL
AnalyWcal
models
High-‐level
simulaWon
Cycle-‐accurate
1010
simulaWon
105
#
architectures
1000
considered
10
1
Traces
/
RepresentaWve
Microbenchmarks
/applicaWons
benchmarks
applicaWons
Program
characterisWcs
Pre-‐silicon
soEware
opWmizaWon,
co-‐design
design
process
(Wme)
12
SNIPER:
A
FAST
AND
ACCURATE
SIMULATOR
• Hybrid
simulaWon
approach
– AnalyWcal
interval
core
model
– Micro-‐architecture
structure
simulaWon
• branch
predictors,
caches
(incl.
coherency),
NoC,
etc.
• Hardware-‐validated,
Pin-‐based
• Models
mulW/many-‐cores
running
mulW-‐
threaded
and
mulW-‐program
workloads
• Parallel
simulator
scales
with
the
number
of
simulated
cores
• Available
at
http://snipersim.org
13
TOP
SNIPER
FEATURES
• Interval
SimulaWon
Core
Model
• MulW-‐threaded
ApplicaWon
Sampling
• CPI
Stacks
and
InteracWve
VisualizaWon
• Parallel
MulWthreaded
Simulator
• x86-‐64
and
SSE2
support
• Validated
against
Core2,
Nehalem
• Thread
scheduling
and
migraWon
• Full
DVFS
support
• Shared
and
private
caches
• Modern
branch
predictor
• Supports
pthreads
and
OpenMP,
TBB,
OpenCL,
MPI,
…
• SimAPI
and
Python
interfaces
to
the
simulator
• Many
flavors
of
Linux
supported
(Redhat,
Ubuntu,
etc.)
14
SNIPER
LIMITATIONS
• User-‐level
– Perfect
for
HPC
– Not
the
best
match
for
workloads
with
significant
OS
involvement
• FuncWonal-‐directed
– No
simulaWon
/
cache
accesses
along
false
paths
• High-‐abstracWon
core
model
– Not
suited
to
model
all
effects
of
core-‐level
changes
– Perfect
for
memory
subsystem
or
NoC
work
• x86
only
15
SNIPER
HISTORY
• November,
2011:
SC’11
paper,
first
public
release
• May
2012,
version
3.0:
Heterogeneous
architectures
• November
2012,
version
4.0:
Thread
scheduling
and
migraWon
• December
2012,
version
4.1:
VisualizaWon
(2D
and
3D)
• April
2013,
version
5.0:
MulW-‐threaded
applicaWon
sampling
• June
2013,
version
5.1:
Advanced
visualizaWon
• Today:
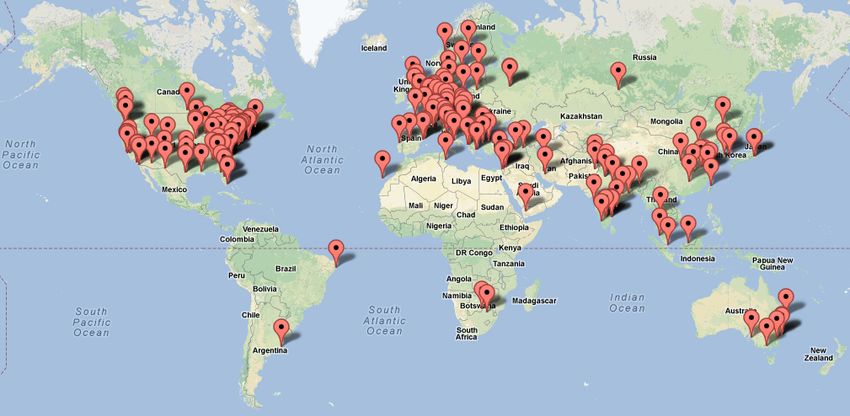
400+
downloads
from
45
countries
16
THE
SNIPER
MULTI-‐CORE
SIMULATOR
INTERVAL
SIMULATION
&
CPI
STACKS
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
IBRAHIM
HUR,
KENZO
VAN
CRAEYNEST
AND
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
NEEDED
DETAIL
DEPENDS
ON
FOCUS
Single-‐event
Required
Component
Jme
scale
sim
Jme
RTL
single
clock
cycle
millions
of
cycles
Too
slow
OOO
execuWon
Core
memory
ops
L1
cache
access
LLC
access
Off-‐socket
microseconds
seconds
Not
accurate
enough
18
INTERVAL
MODEL
Out-‐of-‐order
core
performance
model
with
in-‐order
simulaWon
speed
branch
mispredicWon
I-‐cache
miss
long-‐latency
load
miss
effecWve
dispatch
rate
interval
1
interval
2
interval
3
Wme
D.
Genbrugge
et
al.,
HPCA’10
S.
Eyerman
et
al.,
ACM
TOCS,
May
2009
T.
Karkhanis
and
J.
E.
Smith,
ISCA’04,
ISCA’07
19
KEY
BENEFITS
OF
THE
INTERVAL
MODEL
• Models
superscalar
OOO
execuWon
• Models
impact
of
ILP
• Models
second-‐order
effects:
MLP
• Allows
for
construcWng
CPI
stacks
20
CYCLE
STACKS
CPI
• Where
did
my
cycles
go?
• CPI
stack
– Cycles
per
instrucWon
– Broken
up
in
components
• Normalize
by
either
– Number
of
instrucWons
(CPI
stack)
– ExecuWon
Wme
(Wme
stack)
• Different
from
miss
rates:
L2
cache
I-‐cache
cycle
stacks
directly
quanWfy
Branch
the
effect
on
performance
Base
21
CYCLE
STACKS
FOR
PARALLEL
APPLICATIONS
By
thread:
heterogeneous
behavior
in
a
homogeneous
applicaWon?
L1
L1
L1
L1
L1
L1
L1
L1
L2
L2
L2
L2
L2
L2
L2
L2
L3
data
L3
DRAM
22
USING
CYCLE
STACKS
TO
EXPLAIN
SCALING
BEHAVIOR
23
USING
CYCLE
STACKS
TO
EXPLAIN
SCALING
BEHAVIOR
• Scale
input:
applicaWon
becomes
DRAM
bound
24
USING
CYCLE
STACKS
TO
EXPLAIN
SCALING
BEHAVIOR
• Scale
input:
applicaWon
becomes
DRAM
bound
• Scale
core
count:
sync
losses
increase
to
20%
25
THE
SNIPER
MULTI-‐CORE
SIMULATOR
SIMULATOR
ACCURACY
AND
HARDWARE
VALIDATION
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
IBRAHIM
HUR,
KENZO
VAN
CRAEYNEST
AND
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
HARDWARE
VALIDATION
• Why
validaWon?
– Debugging
– Verifying
modeling
assumpWons
– Balance
between
accuracy
and
generality
• e.g.:
loop
buffer
in
Nehalem/Westmere;
uop-‐cache
in
Sandy
Bridge
• Current
status:
– Validated
against
Core2
(internal,
results
@
SC’11)
– Nehalem
ongoing
(public
version)
27
EXPERIMENTAL
SETUP:
ARCHITECTURE
L1 L1 L1 L1
L1I
L1I
L1 L1I
L1 L1I
L1 L1
D
L1I
D
L1I
L1 D
L1I
L1 D
L1I
L1 L1
D
L1I
D
L1I
L1 D
L1I
L1 D
L1I
L1 L1
D
L1I
D
L1I
D
L1I
D
L1I
D
D
D
D
L2
L2
L2
L2
L2
L2
L2
L2
L3
L3
L3
L3
DRAM
28
INTERVAL
PROVIDES
NEEDED
ACCURACY
The
interval
core
model
provides
consistent
accuracy
of
25%
avg.
abs.
error,
with
a
minimal
slowdown
29
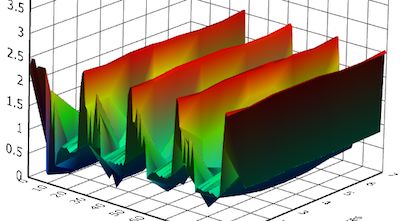
APPLICATION
OPTIMIZATION
• Splash2-‐Raytrace
shows
very
bad
scaling
behavior
• CPI
stack
shows
why:
heavy
lock
contenWon
• Conversion
to
use
locked
increment
instrucWon
helps
30
SIMULATOR
PERFORMANCE
Sniper
currently
scales
to
2
MIPS
Typical
simulators
run
at
10s-‐100s
KIPS,
without
scaling
31
MANY-‐CORE
SIMULATIONS
High
simulaWon
speed
up
to
1024
simulated
cores
– Efficient
simulaWon:
L1-‐based
benchmarks
execute
faster
– Host
system:
dual-‐socket
Xeon
X5660
(6-‐core
Westmere),
96
GB
RAM
32
POWER-‐AWARE
HW/SW
CO-‐OPTIMIZATION
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
KENZO
VAN
CRAEYNEST
AND
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
POWER-‐AWARE
HW/SW
CO-‐OPTIMIZATION
• Hooked
up
McPAT
(MulW-‐Core
Power,
Area,
Timing
framework)
to
Sniper’s
output
staWsWcs
• Evaluate
different
architecture
direcWons
(45nm
to
22nm)
with
near-‐constant
area
• Compare
performance,
energy
efficiency
[Heirman
et
al.,
PACT
2012]
core
cache
8
cores
16
cores,
no
L3,
stacked
DRAM
baseline:
2x
quad-‐core
16
slow
cores
16
thin
cores
34
POWER-‐AWARE
HW/SW
CO-‐OPTIMIZATION
Baseline
8-‐core
3D
Low-‐frequency
Dual-‐issue
#Cores
2x
4
8
16
16
16
Frequency
2.66
GHz
3.059
GHz
3.059
GHz
1.8
GHz
3.059
GHz
Voltage
1.2
V
1.2
V
1.2
V
1.025
V
1.2
V
Issue
width
4
4
4
4
2
ROB
size
128
128
128
128
32
L2/core
256
KB
512
KB
256
KB
256
KB
256
KB
L3
2x
8
MB
32
MB
-‐
2
x
8
MB
2
x
8
MB
Area
2
x
243
mm2
151
mm2
181
mm2
208
mm2
187
mm2
Max.
power
2
x
99
W
80
W
130
W
58
W
102
W
35
ore for all of the selected benchmarks. How-
g the large input, 3D is considerably more 3
POWER-‐AWARE
HW/SW
CO-‐OPTIMIZATION
or three out of five of the applications con-
hows that architecture studies should take
ing reduced input sizes. s
2
1
ARE/SOFTWARE CO-DESIGN
• Heat
transfer:
stencil
on
regular
grid
ne step further and we use Sniper/McPAT
0
B
0 0
tudy in which Used
– we in
the
optimize bothExaScience
hardware Lab
as
component
of
Space
WBeather
modeling
e do this for an important scientific kernel,
omputation. –Our Important
kernel,
part
kernel implementation al- of
Berkeley
Figure 7: Dwarfs
(structured
Illustration grid)
of three iterations of the heat
transfer simulation, applied to an 8 8 tile. To sat
• Improve
m emory
off data locality with redundant computa-
les finding an optimum software configura-
l ocality:
W ling
isfy othever
data
mulWple
dependencies Wme
steps
up to the third step o
– Trade
hardware setting, and viceoff
versa.
locality
with
redundant
computaWon
the stencil, redundant computations (on the darker
dots) are performed at the boundaries of the tile
ansfer application
– OpWmum
depends
on
relaWve
Fromcost
(performance
&
energy)
[11].
of
computaWon,
mputation benchmark data
transfer
à
requires
integrated
simulator
models heat transfer
2D grid over a number of time steps. The
ation involves stencil computation in which 32Performance (GFLOP/s)
peak floating-point performance
a given point in time at each grid location
nation
3 of the temperatures of that location 16 th re
d wid du
s at the previous time step. a n nd
y b an
o r tc
mentation of the heat transfer equation com- 8 m e m om
2 pu
ime step at a time, and iterates over the ak tat
pe ion
apply the stencil operation at each grid lo-
4
ment).
1 This implementation has very poor 1/2 1 2 4 8 16
se each data element is used only once per Arithmetic intensity (FLOP/byte)
the time a data element is used again —B Total performance
0
e step — the 0 processor will have touched
0
2
Useful performance (256 tiles)
ements, and hence, when B simulating a large Useful performance (1282 tiles) 36
POWER-‐AWARE
HW/SW
CO-‐OPTIMIZATION
• Match
Wle
size
to
L2
size,
find
opWmum
between
locality
and
redundant
work
–
depending
on
their
(performance/
energy)
cost
• Isolated
opWmizaWon:
(a) Performance (simulated time steps per second)
300 – Fix
HW
architecture,
explore
SW
parameters
8-core
300
3D
300
low-frequency
300
dual-issue
250 250 250 250
Steps/time (1/s)
Steps/time (1/s)
Steps/time (1/s)
Steps/time (1/s)
200
150
– Fix
SW
parameters,
explore
HW
architecture
200
150
200
150
200
150
• Co-‐opWmizaWon
yields
1.66x
more
performance,
or
1.25x
100 100 100 100
50 50 50 50
0 0 0 0
more
energy
efficiency,
than
isolated
opWmizaWon
0 1 2 3 4 0 1 2 3 4 0 1 2 3 4 0 1 2 3 4
Arithmetic intensity (FLOP/byte) Arithmetic intensity (FLOP/byte) Arithmetic intensity (FLOP/byte) Arithmetic intensity (FLOP/byte)
32 64 128 256 512 32 64 128 256 512 32 64 128 256 512 32 64 128 256 512
(b) Energy e⌅ciency (simulated time steps per Joule)
8-core 3D low-frequency dual-issue
2.5 2.5 2.5 2.5
Steps/Energy (1/J)
Steps/Energy (1/J)
Steps/Energy (1/J)
Steps/Energy (1/J)
2.0 2.0 2.0 2.0
1.5 1.5 1.5 1.5
1.0 1.0 1.0 1.0
0.5 0.5 0.5 0.5
0.0 0.0 0.0 0.0
0 1 2 3 4 0 1 2 3 4 0 1 2 3 4 0 1 2 3 4
Arithmetic intensity (FLOP/byte) Arithmetic intensity (FLOP/byte) Arithmetic intensity (FLOP/byte) Arithmetic intensity (FLOP/byte)
32 64 128 256 512 32 64 128 256 512 32 64 128 256 512 32 64 128 37
256 512SAMPLED
SIMULATION
OF
MULTI-‐THREADED
APPLICATIONS
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
OVERVIEW
• How
can
we
create
a
representaWve
sample
of
a
mulW-‐threaded
applicaWon?
• Prior
Work
• Key
ContribuWons
of
this
Work
• Results
and
EvaluaWon
39
WORKLOAD
REDUCTION
IS
THE
KEY
• Many
workload
reducWon
techniques
exist
today
– ReducWon
• Smaller
input
sizes
• Reduced
numbers
of
iteraWons
– Sampling:
only
part
of
the
workload
needs
to
be
simulated
in
detail,
whole-‐program
performance
can
be
extrapolated
• SimPoint
• SMARTS
• FlexPoints
40
SAMPLING
MULTI-‐THREADED
WORKLOADS
• Define:
synchronizing
mulW-‐threaded
applicaWon
– Use
locks
(mutexes),
barriers,
etc.
– ApplicaWon
where
mulWple
threads
are
working
to
solve
a
problem
together
• MulW-‐threaded
applicaWon
complexiWes
– We
want
to
determine
applicaWon
runWme,
not
CPI
– Can
be
different
performance
per
thread
(e.g.
NUMA,
load
imbalance)
– InstrucWon
count
cannot
be
used
to
determine
fast-‐
forward
length
(per-‐thread
CPI,
thread
idle
Wme)
41
MULTI-‐THREADED
SAMPLING
• Goal
– Reduce
mulW-‐threaded
applicaWon
simulaWon
Wme
– Accurately
predict
applicaWon
runWme
• Key
ContribuWons
– Sampling
in
Wme
is
a
requirement
for
sampling
simulaWon
of
mulW-‐threaded
applicaWons
– Take
into
account
thread
details
during
fast-‐
forwarding
• Thread
synchronizaWon
(mutexes,
barriers,
etc.)
• Per-‐thread
CPI
– ApplicaWon
phase
behavior
is
criWcal
for
accurate
sampling
42
CURRENT
SAMPLING
SOLUTIONS
• Current
mulW-‐threaded
soluWons
are
not
sufficient
– Flex
Points
• Specifically
designed
for
non-‐synchronizing
throughput
(server)
workloads
• Issue:
Assumes
no
correlaWon
between
threads
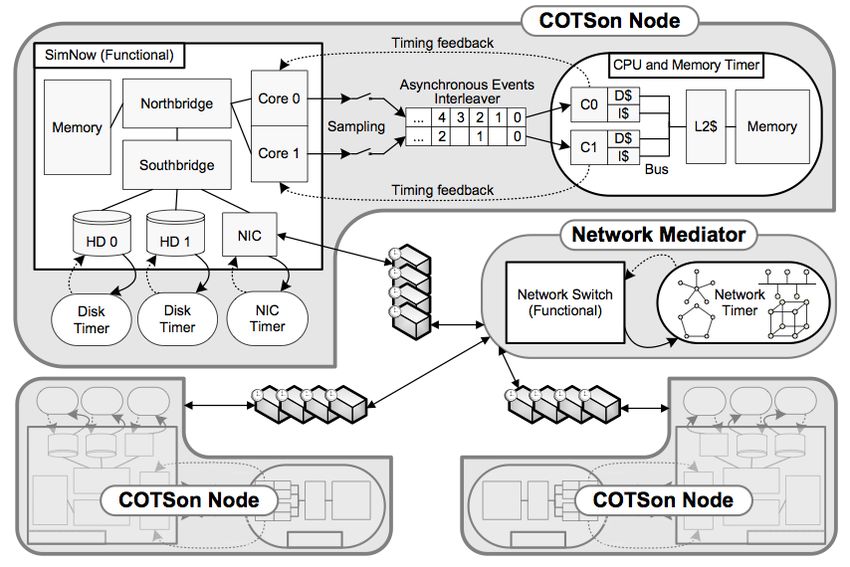
– COTSon’s
Dynamic
Sampling
(Argollo
et
al.,
Ryckbosch
et
al.)
• Issue:
Doesn’t
properly
handle
synchronizaWon
during
fast-‐forwarding
Argollo
et
al.,
ACM
SIGOPS
Wenisch,
et
al.,
IEEE
MICRO
2006
OperaWng
Systems
Review
43
MULTITHREADED
FAST-‐FORWARDING
• Use
Wme
as
the
base
unit
for
sampling
• Propagate
Wme
from
waker
to
waiter
(as
in
detailed)
• Use
instrucWon
count
as
a
low-‐overhead
fast-‐forwarding
method
• Use
per-‐thread
non-‐idle
CPI
from
recent
detailed
interval
wait
IPC
1
wake
IPC
0
Wme
44
detailed
fast-‐forward
detailed
APPLICATIONS
ARE
PERIODIC
npb-‐E,
class
A,
8
threads
45
IDENTIFY
PERIODICITIES
• ApplicaWon
periodiciWes
are
idenWfied
in
a
micro-‐architectural
independent
manner
BBV
AutocorrelaJon
npb-‐E,
class
A,
8
threads,
with
550k
and
1.14M
insn
periodiciWes
OMP
Call
Structure
npb-‐lu,
class
A,
8
threads
with
high
variability
(not
used)
46
SAMPLING
PROCESS
• Sampling
sufficiently
above
or
below
the
period
will
minimize
error
PeriodiciWes
RunWme
limit
Best
Region
Good
Region
47
RESULTS
• Predicted
Most-‐Accurate
Results
– Average
absolute
error
of
3.5%
– Average
speedup
of
2.9x,
maximum
of
5.8x
48
THE
SNIPER
MULTI-‐CORE
SIMULATOR
RUNNING
SIMULATIONS
AND
PROCESSING
RESULTS
WIM
HEIRMAN,
TREVOR
E.
CARLSON,
KENZO
VAN
CRAEYNEST,
IBRAHIM
HUR
AND
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
OVERVIEW
• Obtain
and
compile
Sniper
• Running
• ConfiguraWon
• SimulaWon
results
• InteracWng
with
the
simulaWon
– SimAPI:
applicaWon
– Python
scripWng
50
RUNNING
SNIPER
• Download
Sniper
– hup://snipersim.org/w/Download
• Download
tar.gz
• Git
clone
~/sniper$
export
SNIPER_ROOT=$(pwd)
#optional
~/sniper$
make
• Running
an
applicaWon
~/sniper$
./run-‐sniper
-‐-‐
/bin/true
~/sniper/test/fft$
make
run
51
RUNNING
SNIPER
• Integrated
benchmarks
distribuWon
– hup://snipersim.org/w/Download_Benchmarks
~/benchmarks$
export
BENCHMARKS_ROOT=$(pwd)
~/benchmarks$
make
~/benchmarks$
./run-‐sniper
–p
splash2-‐fft
\
–i
small
–n
4
• Standardizes
input
sets
and
command
lines
• Includes
SPLASH-‐2,
PARSEC
52
REGION
OF
INTEREST
• Skip
benchmark
iniWalizaWon
and
cleanup
• Mark
code
with
ROI
begin
/
end
markers
– SimRoiStart()
/
SimRoiEnd()
in
your
own
applicaWon
– $
./run-‐sniper
-‐-‐roi
-‐-‐
test/fft/fft
• Already
done
in
benchmarks
distribuWon
– benchmarks/run-‐sniper
implies
-‐-‐roi
– Use
-‐-‐no-‐roi
to
override
• Cache
warming
during
pre-‐ROI
period
– Use
-‐-‐no-‐cache-‐warming
to
override
53
MPI
WORKLOADS
• Supports
single-‐node
shared-‐memory
MPI
– MPICH2
and
derivaWves
(Intel
MPI,
etc.)
• Add
-‐-‐mpi
to
the
Sniper
opWons
when
running
mpirun
– Example:
Intel
MPI,
Source:
Intel
~/sniper/test/mpi$
../../run-‐sniper
-‐-‐mpi
-‐n
4
\
-‐c
gainestown
-‐-‐
mpirun
-‐np
4
./pi
• Hybrid
single-‐node
MPI+OpenMP
applicaWons
are
also
supported
54
SIMULATION
RESULTS
• Files
created
aEer
each
simulaWon:
– sim.cfg:
all
configuraWon
opWons
used
for
this
run
(includes
defaults,
all
-‐c
and
-‐g
opWons)
– sim.out:
basic
staWsWcs
(number
of
cycles,
instrucWons
per
core,
cache
access
and
miss
rates,
…)
– sim.stats[.sqlite3]:
complete
set
of
all
recorded
staWsWcs
at
key
points
in
the
simulaWon
(start,
roi-‐begin,
roi-‐end,
stop)
• Use
the
sniper_lib
Python
package
for
parsing
55
SIMULATION
RESULTS
sniper_lib.get_results()
parses
sim.cfg,
sim.stats
and
returns
configuraWon
and
staWsWcs
(roi-‐end
–
roi-‐begin)
for
all
cores
~/sniper/tools$
python
>
import
sniper_lib
>
results
=
sniper_lib.get_results(resultsdir
=
‘..’)
>
print
results
{‘config’:
{‘general/total_cores’:
‘64’,
‘perf_model/core/frequency’:
‘2.66’,
…},
‘results’:
{‘performance_model.instruction_count’:[123],
‘performance_model.elapsed_time’:
[23000000],
…}}
56
SIMULATION
RESULTS
• Let’s
compute
the
IPC
for
core
0
• Core
frequency
is
variable
(DVFS)
so
cycle
count
has
to
be
computed
– Time
is
in
femtoseconds,
frequency
in
GHz
>
instrs
=
results[‘results’]
[‘performance_model.instruction_count’][0]
>
cycles
=
results[‘results’]
[‘performance_model.elapsed_time’][0]
*
float(results[‘config’][‘perf_model/core/frequency’])
*
1e-‐6
#
femtoseconds
-‐>
nanoseconds
>
ipc
=
instrs
/
cycles
2.0
57
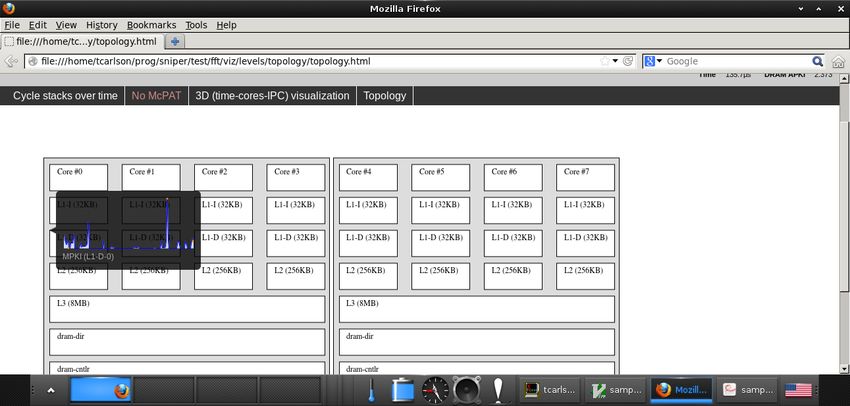
SIMULATION RESULTS • CPI stacks (user of sniper_lib) $ ./tools/cpistack.py [-‐-‐time|-‐-‐cpi|-‐-‐abstime] CPI CPI % Time % Core 0 depend-‐int 0.20 23.42% 23.42% depend-‐fp 0.16 18.94% 18.94% branch 0.12 14.04% 14.04% ifetch 0.04 4.16% 4.16% mem-‐l1d 0.21 24.41% 24.41% mem-‐l3 0.02 2.72% 2.72% mem-‐dram 0.05 5.73% 5.73% sync-‐mutex 0.02 2.59% 2.59% sync-‐cond 0.03 3.01% 3.01% other 0.01 0.97% 0.97% total 0.84 100.00% 0.00s Core 1 depend-‐int 0.20 23.92% 23.92% depend-‐fp 0.16 18.79% 18.79% branch 0.12 13.72% 13.72% mem-‐l1d 0.20 24.06% 24.06% mem-‐l3 0.06 6.79% 6.79% sync-‐mutex 0.04 5.22% 5.22% sync-‐cond 0.05 5.60% 5.60% other 0.02 1.89% 1.89% total 0.85 100.00% 0.00s 58
INTERACTING
WITH
SNIPER
input/
binary
cmdline
configuraWon
applicaWon
SimAPI
Python
scripts
Sniper
simulator
staWsWcs
visualizaWon
59
APPLICATION
SIMAPI
• Calling
simulator
API
funcWons
from
your
C
program
#include
– SimInSimulator()
• Return
1
when
running
inside
Sniper,
0
when
running
naWvely
– SimGetProcId()
• Return
processor
number
of
caller
– SimRoiStart()
/
SimRoiEnd()
• Start/end
detailed
mode
(when
using
./run-‐sniper
-‐-‐roi)
– SimSetFreqMHz(proc,
mhz)
/
SimGetFreqMHz(proc)
• Set
/
get
processor
frequency
(integer,
in
MHz)
– SimUser(cmd,
arg)
• User-‐defined
funcWon
60
PYTHON
SCRIPTING
• Low-‐level
script
• Execute
“foo”
at
each
barrier
synchronizaWon
import
sim_hooks
def
foo(t):
print
'The
time
is
now',
t
sim_hooks.register(sim_hooks.HOOK_PERIODIC,
foo)
61
PYTHON
SCRIPTING
• Access
configuraWon,
staWsWcs,
DVFS
• Live
periodic
IPC
trace:
– See
scripts/ipctrace.py
for
a
more
complete
example
class
IPCTracer:
def
setup(self,
args):
sim.util.Every(1*sim.util.Time.US,
self.periodic)
self.instrs_prev
=
0
def
periodic(self,
t,
t_delta):
freq
=
sim.dvfs.get_frequency(0)
cycles
=
t_delta
*
freq
*
1e-‐9
#
fs
*
MHz
-‐>
cycles
instrs
=
long(sim.stats.get('performance_model',
0,
'instruction_count'))
print
'IPC
=',
(instrs
–
self.instrs_prev)
/
cycles
self.instrs_prev
=
instrs
62
INTERVAL
CORE
SIMULATION
DETAILS
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
OVERVIEW
• SimulaWon
Methodologies
– Trace,
Integrated,
FuncWonal-‐directed
• Core
Models
– One-‐IPC
– Interval
• Interval
Model
and
SimulaWon
Detail
• CPI-‐Stacks
64
ONE-‐IPC
MODELING
–
TOO
SIMPLE?
• Simple
high-‐abstracWon
model,
oEen
used
in
uncore
studies
• AlternaWve
for
memory
access
traces
– Aims
to
provide
more-‐realisWc
access
pauerns
– Allows
for
Wming
feedback
• But:
One-‐IPC
core
models
do
not
exhibit
ILP/MLP
– Memory
request
rates
are
not
as
accurate
as
more
detailed
simulators
– #
outstanding
requests
incorrect:
underesWmate
required
queue
sizes
– No
latency
is
hidden:
overesWmate
runWme
improvements
65
CONSTRUCTING
CPI
STACKS
CPI
• Interval
simulaWon:
track
why
Wme
is
advanced
– No
miss
events
• Dispatch
instrucWons
at
base
CPI
• Increment
base
component
– Miss
event
• Fast-‐forward
Wme
by
X
cycles
• Increment
component
by
X
L2
cache
I-‐cache
Branch
Base
66
INTERVAL
SIMULATION
FROM
30,000
FEET
DRAM
Cache
Hierarchy
I$
BP
LSQ
Issue
Decode
ExecuWon
Commit
Fetch
Queue
Units
ROB
Interval
simulaWon
considers
instrucWons
(in-‐order)
at
dispatch
• dispatch
not
possible
– InstrucWon
cache
/
TLB
miss
– Branch
mispredicWon
(not
dispatching
useful
instrucWons)
– Front-‐end
refill
aEer
mispredicWon
– ROB
full:
long-‐latency
miss
at
head
of
ROB
67
INTERVAL
SIMULATION
FROM
30,000
FEET
DRAM
Cache
Hierarchy
I$
BP
LSQ
Issue
Decode
ExecuWon
Commit
Fetch
Queue
Units
ROB
Interval
simulaWon
considers
instrucWons
(in-‐order)
at
dispatch
• dispatch
not
possible
• dispatch
possible:
at
rate
governed
by
ROB
– Liule’s
law:
progress
rate
=
#elements
/
Wme
spent
in
queue
– Computed
using
ROB
fill
and
criWcal
path
through
ROB
• Computed
using
dynamic
instrucWon
dependencies
and
latencies
68
LONG
BACK-‐END
MISS
EVENTS
ISOLATED
LONG-‐LATENCY
LOAD
S.
Eyerman
et
al.,
ACM
TOCS,
May
2009
69
LONG
BACK-‐END
MISS
EVENTS
OVERLAPPING
LONG-‐LATENCY
LOADS
S.
Eyerman
et
al.,
ACM
TOCS,
May
2009
70
CORE
MODELS
(ONGOING)
• Key
quesWon:
required
accuracy
vs.
simulaWon
speed
/
simulator
complexity
– Cycle-‐accurate
memory
request
stream
for
uncore
studies
– Accurate
performance
impact
(overlap)
of
memory
latency
– ImplementaWon
complexity
when
making
changes
(research)
• Interval
model
– Issue
contenWon
(structural
hazards)
– Cycle-‐accurate
memory
hierarchy
support
• ROB-‐based
model
– Free
issue
contenWon
and
cycle-‐driven
memory
support
– Higher
accuracy,
slower
(~2x
total)
71
SAMPLED
SIMULATION
OF
MULTI-‐THREADED
APPLICATIONS
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
MULTITHREADED
FAST-‐FORWARDING
• Use
Wme
as
the
base
unit
for
sampling
– Time
is
common
across
threads,
unlike
instrucWons
• Use
instrucWon
count
as
a
low-‐overhead
fast-‐forwarding
method
– FuncWonal-‐execuWon
only
provides
instrucWon
count,
but
we
sWll
require
Wme
for
fast-‐forwarding
• Use
per-‐thread
non-‐idle
CPI
from
previous
detailed
interval
IPC
0
Wme
73
detailed
fast-‐forward
detailed
SAMPLE SELECTION It is possible to get good accuracy at high speed, but not reliably Detailed (D) fast-‐forward (F/D) 74
MAIN
PROBLEM:
ALIASING
• When
applicaWon
exhibits
periodicity
near
detailed
interval
length,
aliasing
errors
near
one
period:
average
not
OK
IPC
exactly
one
period:
average
OK
detailed
• New
problem
to
mulW-‐threaded
sampling:
– SMARTS
uses
>10,000
sampling
units:
average
IPC
is
obtained
– SimPoint
sampling
units
can
sWll
alias
applicaWon
periods
– Key
insight:
we
need
single
sample
accuracy
for
fast-‐forward
IPC
• Sampling
parameters
determined
by
applicaWon
periodicity
75
IDENTIFY
PERIODICITIES
• We
do
this
in
an
architecture-‐independent
way
• Sampling
sufficiently
above
or
below
the
period
will
minimize
error
D
=
Detailed
period
F
=
Fast-‐forward
(mulWple
of
D)
76
EXPERIMENTAL
SETUP
• Sniper
MulW-‐core
Simulator
– Nehalem-‐style
architecture
• 2
sockets,
4
cores
per
socket
• 2.66
GHz,
128-‐entry
ROB
• 32
KB
L1-‐I,
32KB
L1-‐D,
256
KB
L2/core,
8MB
L3/4
cores
• Benchmarks
– NAS
Parallel
Benchmarks
3.3.1,
class
A
inputs
– Parsec
2.1,
simlarge
input
set
– SPEC
OMP2001,
train
input
set
77
THREAD
SYNCHRONIZATION
COMPARISON
Even
with
oracle
per-‐thread
CPI
knowledge
up-‐front,
our
proposed
methodology
provides
a
more
accurate
soluWon
78
MULTI-‐THREADED
SAMPLING
• Key
ContribuWons
– Sampling
in
Wme
is
a
requirement
for
sampling
simulaWon
of
mulW-‐threaded
applicaWons
– Take
into
account
thread
details
during
fast-‐
forwarding
• Thread
synchronizaWon
• Per-‐thread
CPI
– Taking
into
account
applicaWon
phase
behavior
is
criWcal
for
accurate
sampling
• Predicted
Most-‐Accurate
Results
– Average
absolute
error
of
3.5%
across
applicaWons
– Average
speedup
of
2.9x,
maximum
of
5.8x
79
MULTI-‐THREADED
SAMPLING
RELEASE
• Sniper
5.0
Release
– MulW-‐threaded
sampling
infrastructure
– Available
from:
• hup://snipersim.org
Interval
core
model,
CPI-‐stacks,
advanced
visualizaWon
support,
automaWc
topology
generaWon,
parallel
mulW-‐threaded
simulator,
mulW-‐program
and
mulW-‐threaded
applicaWon
support,
x86
and
x86-‐64
support,
hardware
validated,
full
DVFS
support,
shared
and
private
cache
support,
scheduling
support,
heterogeneous
configuraWon,
modern
branch
predictor,
OpenMP,
MPI,
TBB,
OpenCL,
integrated
benchmarks,
SPLASH-‐2,
most
of
Parsec,
McPAT
integraWon,
SimAPI,
Python
scripWng,
single-‐opWon
debugging,
modern
OS
support,
Pin-‐based,
staWsWcs
database,
stackable
configuraWons
80
RESULTS
• Predicted
Fastest
Results
– Average
speedup
of
3.8x,
maximum
of
8.4x
– Average
absolute
error
of
5.1%
81
THE
SNIPER
MULTI-‐CORE
SIMULATOR
SIMULATOR
ACCURACY
AND
HARDWARE
VALIDATION
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
IBRAHIM
HUR,
KENZO
VAN
CRAEYNEST
AND
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
EXPERIMENTAL
SETUP
• Benchmarks
– Complete
SPLASH-‐2
suite
• 1
to
16
threads
• Linux
pthreads
API
– Extensive
use
of
microbenchmarks
to
tune
parameters
and
track
down
problems
• Hardware
– Four-‐socket
Intel
Xeon
X7460
machine
– Core2
(45nm,
Penryn)
with
6
cores/socket
83
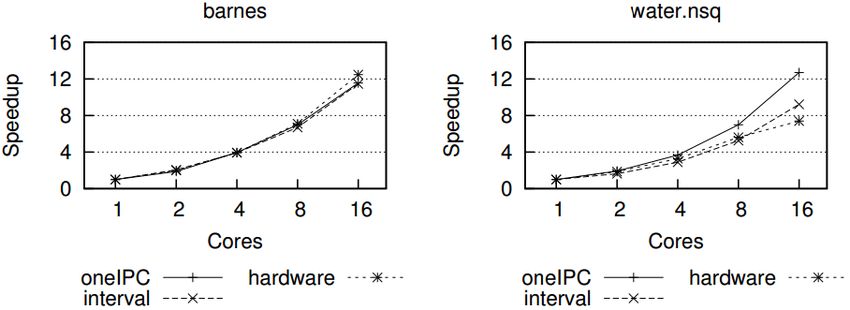
INTERVAL:
GOOD
OVERALL
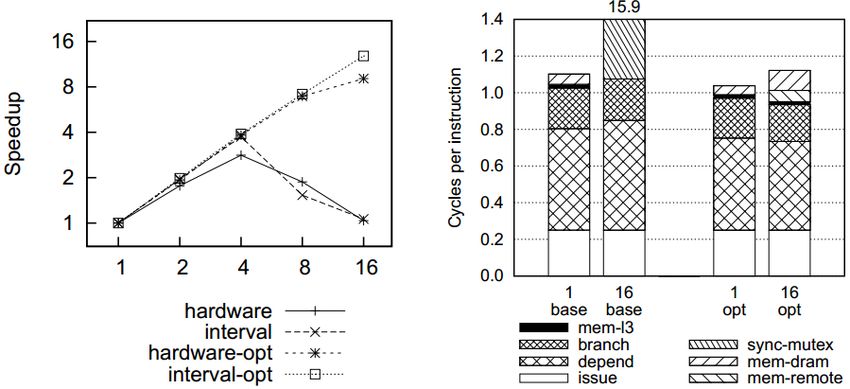
ACCURACY
Good
accuracy
for
the
enWre
benchmark
suite
84
INTERVAL:
BETTER
RELATIVE
ACCURACY
• ApplicaWon
scalability
is
affected
by
memory
bandwidth
• Interval
model
provides
more
realisWc
memory
request
streams,
which
results
in
a
more
accurate
scaling
predicWon
85
VALIDATING
FOR
NEHALEM
2
1.8
HW
Measurement
/
Sniper
Result
1.6
1.4
1.2
1
0.8
0.6
0.4
0.2
0
2
1.8
HW
Measurement
/
Sniper
Result
1.6
1.4
1.2
1
0.8
0.6
0.4
0.2
0
86
REFERENCES
• Sniper
website
– hup://snipersim.org/
• Download
– hup://snipersim.org/w/Download
– hup://snipersim.org/w/Download_Benchmarks
• Ge€ng
started
– hup://snipersim.org/w/Ge€ng_Started
• QuesWons?
– hup://groups.google.com/group/snipersim
– hup://snipersim.org/w/Frequently_Asked_QuesWons
87
GAINING
INSIGHT
INTO
PROGRAM
PERFORMANCE
TREVOR
E.
CARLSON,
WIM
HEIRMAN,
IBRAHIM
HUR
KENZO
VAN
CRAEYNEST
AND
LIEVEN
EECKHOUT
HTTP://WWW.SNIPERSIM.ORG
WEDNESDAY,
SEPTEMBER
4TH,
2013
7TH
PARALLEL
TOOLS
WORKSHOP,
DRESDEN,
GERMANY
You can also read

















































