A Multiple Feature Integration Model to Infer Occupation from Social Media Records
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
A Multiple Feature Integration Model
to Infer Occupation from Social Media Records
Xiang Wang, Lele Yu, Junjie Yao, and Bin Cui
Department of Computer Science
Key Lab of High Confidence Software Technologies (Ministry of Education)
Peking University
{kingflying.pkueecs,yulele214}@gmail.com,
{junjie.yao,bin.cui}@pku.edu.cn
Abstract. With the rapid development of more and more social media
applications, lots of users are connected with friends and their daily life
and opinions are recorded. Social media provides us an unprecedented
way to collect and analyze billions of users’ information. Proper user
attribute identification or profile inference becomes more and more at-
tractive and feasible. However, the flourishing social records also pose
great challenge in effective feature selection and integration for user pro-
file inference. This is mainly caused by the text sparsity and complex
community structures.
In this paper, we propose a comprehensive framework to infer user’s
occupation from his/her social activities recorded in micro-blog message
streams. A multi-source integrated classification model is set up with
some fine selected features. We first identify some beneficial basic content
features, and then we proceed to tailor a community discovery based
latent dimension solution to extract community features.
Extensive empirical studies are conducted on a large real micro-blog
dataset. Not only we demonstrate the integrated model shows advantages
over several baseline methods, but also we verify the effect of homophily
in users’ interaction records. The different effects of heterogeneous inter-
active networks are also revealed.
Keywords: User Profile Modeling, Occupation Inference, Feature
Selection, Heterogeneous Network, Micro-blog.
1 Introduction
In the recent fast availability of Web 2.0 and social network services, social media
has become more and more popular among the world and has already exerted
great influence on billions of users’ ordinary life. Based on recent statistics, Face-
book has more than one billion registered users and enjoys 660 million active
users every day. Twitter has around 500 millions registered users and several
hundreds of million messages are posted everyday1.
1
http://goo.gl/90KjQ,
http://blog.twitter.com/2013/03/celebrating-twitter7.html
X. Lin et al. (Eds.): WISE 2013, Part II, LNCS 8181, pp. 137–150, 2013.
c Springer-Verlag Berlin Heidelberg 2013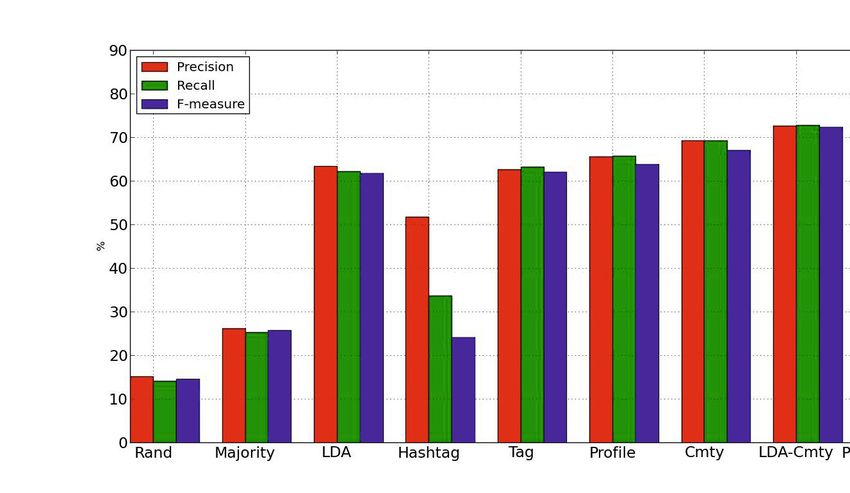
138 X. Wang et al. The explosive development of social media has brought great opportunities to many fields. Billions of users’ life are recorded. Enterprise and research areas face an unprecedent opportunity to extract and analyze users’ taste, interest and other information. Since usually little information is explicitly provided by users themselves due to privacy or other concerns, automatic user attribute inference is required to infer the missing attributes of users like gender, age and interest. Through accurate attribute inference, personalized and targeting services, such as product and content recommendation, can be improved to each individual user. Occupation inference can also be introduced to adjust the advertising and user profile modeling. Besides these great opportunities, challenges also exist. The main challenge is caused by the complicated nature of social media: the extreme rich features of data, low quality of social content and complex user interaction network within them. Recently, several works have focused on the task of user attribute inference. For example, [16] implemented a classification method to infer three charac- teristics of users: political affiliation, ethnicity identification and affiliation to Starbucks. [12] used a community detection method to identify the department and college affiliation of undergraduate students. Inference of gender, age, loca- tion and other attributes were discussed in [18,10,15,1]. A common assumption to infer user attribute is homophily [11]. Homophily indicates that similar users tend to interact with each other. User attribute inference can be resolved through the information of similar users. However, there are still many unsolved challenges to infer user attribute on social media. First, user representation is difficult because we need to extract proper features from lots of noisy data, and different features should be used for different inference tasks. A flexible way to integrate features is also valuable so that user representation can quickly be achieved for different tasks. Another challenge is information rich heterogeneous networks. Heterogeneous networks are network systems consisting of multiple object types and multiple link types. In social media sites, users can be connected through friendship, co- discussion and mention activities. [8] discussed knowledge about such networks is often hidden in massive links. [20] put forward a concept called meta-path to encode the different relationships in heterogeneous networks to cluster ob- jects under the limited guidance of users. However, many facets of heteroge- neous networks, such as unstructured data and cyber-physical networks, are still untouched. In this paper, we propose a multi-source integration model to infer the oc- cupation of users on social media sites. We carry out a comprehensive feature analysis on a large real dataset, and identify language behaviors of users in different occupation categories are very different. Besides, we propose a latent network factor, i.e., latent social dimension to capture the community structure of users. To integrate these features, we represent each user as a feature vec- tor and utilize the supervised machine learning classification framework to infer user’s occupation.
A Multiple Feature Integration Model to Infer Occupation 139
Analyses and experiments are conducted on Sina Weibo2 , the largest mi-
croblog platform in China. Comprehensive results demonstrate the significant
advantage of our proposed model. The contributions of this paper can be sum-
marized as follows:
1. We systematically analyze the feature representation of users and dive into
the network structure to capture users’ latent community affiliations.
2. We propose a multi-source supervised classification framework combined
with both content-based and community-based features.
3. We conduct several experiments and the results show the good performance
of both content and community features, and especially the community ones.
Besides, we validate homophily assumption in this user inference task.
The rest of this paper is organized as follows. In Section 2 we discuss related
work. Section 3 introduces the problem definition and approach framework. Sec-
tion 4 details the feature selection and engineering work in the inference model.
Section 5 presents experiments and evaluations on a real large dataset and finally
we conclude this work in Section 6.
2 Related Work
Research in this paper is related to several areas. Here we briefly review the
corresponding literature.
User Profiling: Works in this field focus on expertise modeling, influence infer-
ence, and interest extraction.[22] proposed a model to propagate interests of an
item among users via their friendships. [10] put forward an unified discriminative
influence probabilistic model to identify users’ locations. [3] measured user’s in-
fluence from in-degree, retweets, mentions, topics and time respectively. Another
common method to infer user profiling is collective classification [19]. The idea
of collective classification is to infer user attribute using neighbors’ information.
Normally a relational classifier is constructed based on the relational features
of labeled data, and then an iterative process is required to infer the unlabeled
data. However, the main drawback of collective inference is that it only consid-
ers the direct neighbors of users and the interactions between indirectly linked
users are ignored. Besides, collective classification fails to capture the presence
of underlying factors that actually influence user’s behaviors.
Community Detection: Community detection has been a trending topic for
a long time. Traditional community detection algorithm uses closeness metric,
by adding edges into an empty network one by one. However, to cut the hi-
erarchical tree and determine the final network community, manual division is
required. [6] put forward edge betweenness metric to divide community. This
method removes edges with larger betweenness from the original network, which
is opposite to closeness method. [14] proposed modularity metric to identify com-
munity. Larger modularity means that there is larger number of intra-community
2
http://weibo.com/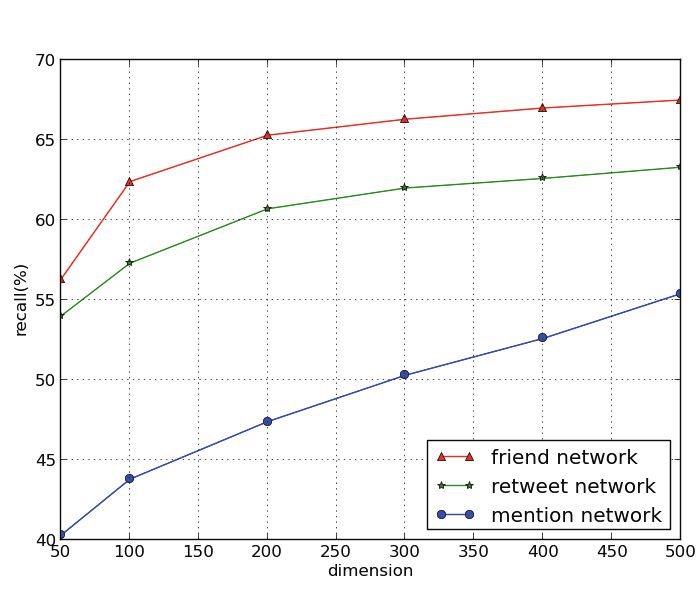
140 X. Wang et al.
edges than inter-community edges. Many previous work used community metric
to infer user attribute. [12] used a greedy algorithm to maximize a new eval-
uation metric called normalized conductance, which measures the quality of a
single community, to detect communities, and then assigned an identical at-
tribute value to users in the same community. The disadvantage of this method
is that using labeled data in community to infer the unlabeled data involves too
much noise and can’t capture the interactions between communities.
3 Problem Formulation and Approach Framework
In this section, we first define the problem of user occupation inference and
then introduce our multi-source integration framework to infer users’ occupation
information.
Data Scenario: Dataset used in this work is based on one of largest micro-blog
platforms–Sina Weibo3 . Users can post, re-tweet and comment messages. At the
same time, they can follow other users. Everyday, hundreds of millions messages
are posted and spread in this social media site4 . Sina Weibo has already labeled
a small subset of its users and categorize them into 12 occupation classes, such as
entertainment, media and government5. We use the open API provided by Sina
Weibo to crawl these users’ data and get about ten thousand accounts. Profiles,
tweets, tags, friend and follower lists are collected. After removing some low
active users, we select 65828 accounts for later empirical study. Here, we can
not only identify the difference in users’ language behaviors from their posted
messages but also catch the strength variety of users’ interactions by utilizing
the community structure.
In Table 1, we provide the occupation distribution of this dataset. We find
that media accounts for the largest proportion(26%), followed by entertainment
class (18%). The percentage of public welfare is smallest, which is only 1%.
Table 1. Occupation Distribution of Verified Users on Sina Weibo
Transport Government Finance Electronic Public welfare Education
1.9% 14.4% 8.9% 2.8% 1.2% 10.0%
Estate Media Service Entertainment Others Medical
8.8% 26.1% 3.7% 17.9% 3.0% 1.3%
To make our problem clear and unambiguous, we give the formal definition
of it in the following.
Definition 1. There are K occupation labels κ = {c1 , . . . , cK }. Given a social
network G = (V, E, Y ) where V is the set of user vertices, E is the set of con-
nection edges and Y is the set of users’ occupation labels. yi ∈ Y and yi ∈ κ
3
http://weibo.com
4
http://www.36kr.com/p/201443.html
5
Verified Account: http://verified.weibo.com/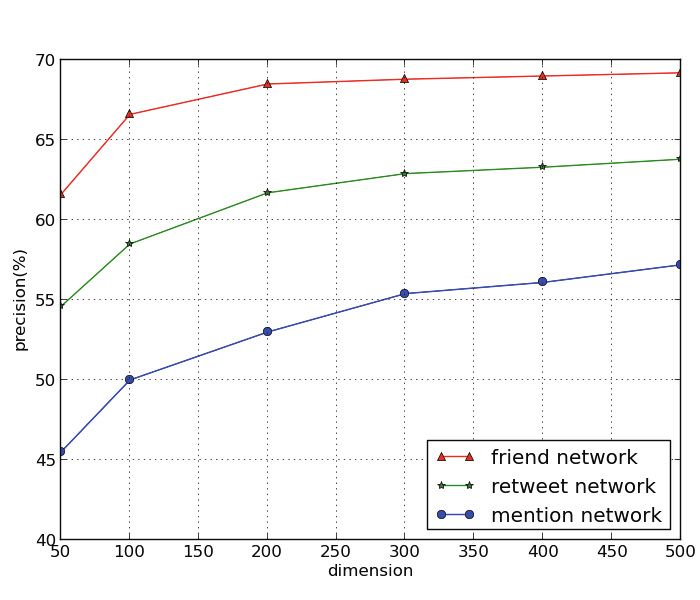
A Multiple Feature Integration Model to Infer Occupation 141
represents the occupation label of user vertex i, and we have already labeled the
occupation labels Yknow of some vertices Vknow . The occupation inference task is
aiming to select the occupation labels Yunknow for the remaing vertices Vunknow .
Multi-source User Occupation Inference Model: To solve this problem, we
utilize both the content and network features, and then transform this problem
into a machine learning classification task. Figure 1 is the framework of our
multi-source inference model. We can divide this approach into two stages:
Content-based Feature
Known labels
Tweet content Tag
Training
Hashtag Profile Classifiers
Feature
integration
Multi-source Feature selection
Inference
Unknown labels
Community-based Feature
Fig. 1. Multi-source User Occupation Inference Model
1. Feature Selection and Integration: We integrate features from two categories.
One is content feature, including tweet content, hashtag, tag and profile.
Actually, we also investigate some other possible features, like location, tem-
poral pattern of behaviors and linguistic characteristics, but these features
don’t perform well in our task. Another class of features is community, i.e.,
latent social dimension used in this work. We use it to capture the latent
community affiliations of users so that the global network information can
be utilized.
After this selection, we then represent each user as a feature vector, which
combines these two types of social media features. New features can be easily
added into our model .
2. Model Prediction: After feature extraction and user representation, we choose
a de facto supervised machine learning classifier to infer user’s occupation.
Common classifiers include naive bayes, decision tree, support vector machine
and logistic regression. Theoretically, any classifier is adaptive in this case.
However, the actual utility needs to be verified through experiments. As
to the latent social dimension, it is very important for classifier to choose
effective and significant community dimensions so that the inference can
be optimized. We also conduct comparisons between different classifiers in
section 5.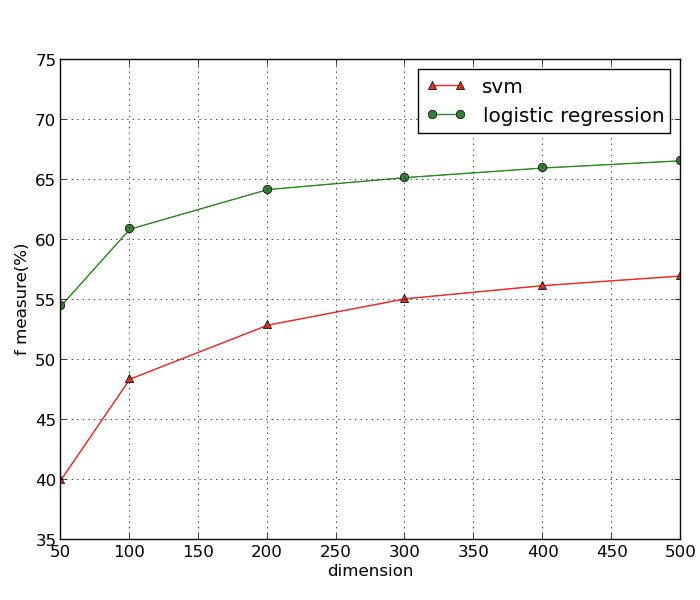
142 X. Wang et al.
4 Feature Selection
In this section, we introduce the features used in occupation inference work. Sina
Weibo is a rich social media platform, with a large variety of user generated
content and multiple types of user interactions.
4.1 Content Feature
Personal Profile: Personal profile refers to the information provided by users
themselves when they register Sina Weibo account, such as gender, location. Be-
cause the profile data returned by Sina Weibo API is in dictionary format, we
choose keys such as description, verified reason and screen name as user’s per-
sonal profile. Description is personal description given by users; verified reason
refers to the reasons why this user was verified by Sina Weibo; screen name
means the nickname of Sina Weibo users.
Personal Tag: Personal tags are key words provided by users themselves to
describe personal interest. For example, a programmer may use Technology, Mo-
bile Internet and Programming Language as his personal tags. Few research has
touched this feature before. After tentative analysis, we find that around 76%
users have personal tags. Based on the idea of homophily, we try to collect the
tags from their neighbors, which can be regarded as a complement of their own
tags. To utilize neighbors’ tags, we implement the following method. We combine
user’s own tags with tags of his top-k most similar neighbors based on similarity
measure. We use the Jaccard Similarity Coefficient6 to measure the similarity of
users. After joining neighbors’ tags, we find that nearly every user has at least
one tag and the average number of tags of users are between 10 and 20 based
on the choice of k.
It should be noted that neighbors here refer to bi-follower friends. Bi-follower
friends imply two users following each other. Friends or neighbors mentioned
in this paper refer to bi-follower friends by default. Bi-follower friends indicate
stronger relationship than one-directional relationship and thus can filter much
noise.
Hashtag: A hashtag is a word or phrase fixed between the symbol #. It serves
as a symbol to integrate similar tweets. The usage of hashtags is related to
the occupations of users. For example, users from public welfare may concern
hashtags like Beijing Rescue Team and Social Public Welfare while users of
IT companies may be interested in Iphone5 and Google I/O Conference. After
extracting hashtags from tweets, we implement word filtering strategy based on
word frequency and represent users as hashtag vectors.
Tweet Content: Sina Weibo allows users to post tweets within 140 words. It is
intuitive to observe that users of different occupations often post tweets which
are different in content. For example, a property developer may be accustomed to
use words like housing, bank, inflation, while a famous singer may like using words
6
http://en.wikipedia.org/wiki/Jaccard_index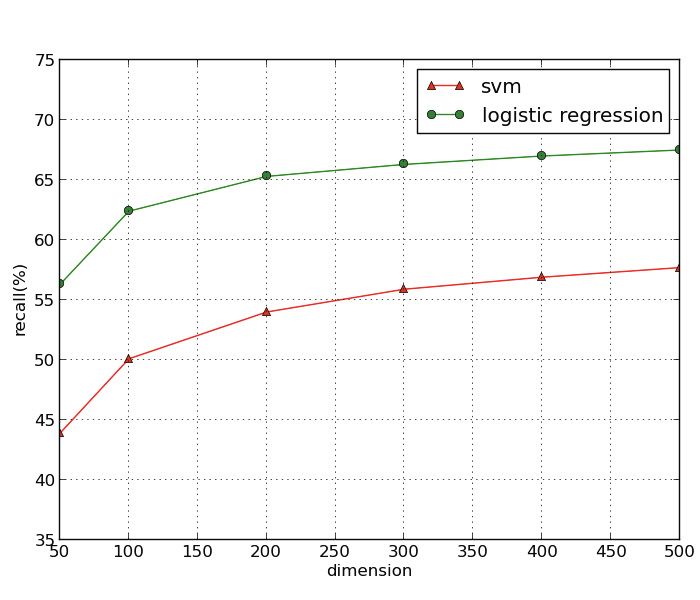
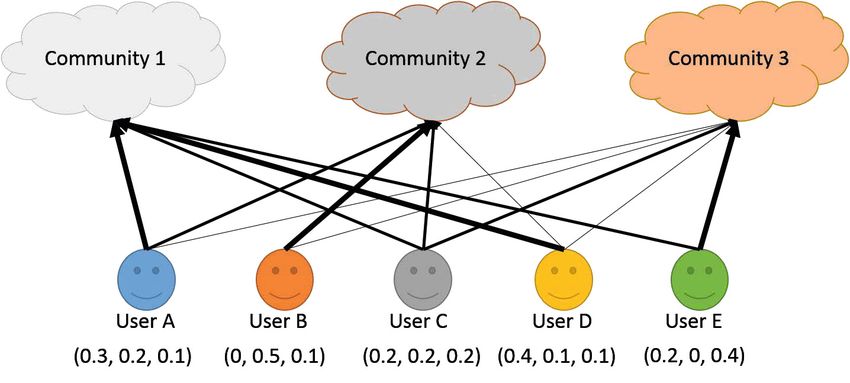
A Multiple Feature Integration Model to Infer Occupation 143 such as singing, composer, popularity. However, it is still difficult to represent tweet content due to the following causes. First, the distribution of tweets is unbalanced. The number of tweets posted by most users is comparatively small, while only a small fraction of users post many tweets, which follows the Power- Law distribution. Another challenge is noise, which is caused by user’s arbitrary writing habits and ordinary user’s low quality background. In order to solve the content representation problem, many methods have been proposed. Probabilistic Latent Semantic Analysis (PLSA) was introduced in [9] to project similar words into a latent dimension. Its disadvantage is the single topic assumption of each document. Latent Dirichlet Allocation(LDA) [2] was later proposed to solve the disadvantage of PLSA, and it allows multiple topics in each document, which is considered as state-of-the-art method. In this paper, we treat the tweets of a user as a document and use LDA to represent each user as a probabilistic distribution among topics. This method could identify user’s latent topic distribution from their posted content. 4.2 Community Feature Here we continue to discuss extraction method of community feature. There are a variety of heterogeneous networks on Sina Weibo, such as friendship, retweet and mention network(using @ ). One important phenomenon in social network is community structure. Here we set up a new community feature, i.e., latent social dimension, based on community structure of users to infer their occupations. Latent Social Dimension: [21] presented a new way to utilize community structure, which is called latent social dimension. Actually, latent social dimen- sion represents the affiliation of users to different communities. Figure 2 is a toy example to illustrate latent social dimension. There are three communities and five users in this graph. One user can affiliate to multiple communities and the thickness of lines between users and communities indicates the strength of affiliation. The mathematical format of latent social dimension is actually a vec- tor, with each dimension corresponding to each community. Take User A as an example. User A can be represented as a vector< 0.3, 0.2, 0.1 >. 0.3 means the strength of affiliation between community 1 and user A is 0.3. Fig. 2. A user and community interactive graph to illustrate latent social dimension
144 X. Wang et al.
The advantage of latent social dimension compared to collective classification
is that latent social dimension can capture the interactions between users from
the whole network while collective classification can only infer user attribute
with neighbors’ help.
It is intuitive to conclude that users of same occupation are more likely to
connect with each other in networks and thus are more likely to form community
structure. Users of different occupations tend to form different communities, and
thus their latent social dimensions are different. We will validate this assumption
in section 5.
Extraction of Latent Dimension: This task is based on community detec-
tion algorithm. Traditional graph partition-based algorithm [7] aims to minimize
the number of edges between communities. [13] points out that minimizing the
number of edges between communities is not a good metric because it tends to
divide most nodes into one community. A better metric to divide communities is
modularity. Modularity is defined as number of intra-edges in our target network
minus number of intra-edges in a comparable random network. Intra-edges means
edges inside communities, not between communities. Community detection task
is to maximize modularity function. The advantage of modularity-based algo-
rithm is that it can find the communities which naturally exist in the network,
without the need to pre-assign the number of communities to be detected.
To simplify our explanation, we make some definitions. We assume that the
number of users in the network is n and the number of edges is m. We first
define adjacent matrix A: Aij = 1 if there is an edge between node i and node j;
Aij = 0 otherwise. Here we ignore the direction of the graph, that is Aij = Aji
and we also don’t consider the weight of edge. Next, we define modularity:
1
Q= [Aij − Pij ]δ(gi , gj ) (1)
2m ij
where gi represents the community of node i. δ is a function. δ(r, s) = 1 if r = s
and δ(r, s) = 0 if r = s. Pij represents probability that there is an edge between
node i and node j in a random network. For convenience, we choose Pij as:
ki kj
Pij = (2)
2m
where ki indicates the degree of node i and can be calculated as ki = j Aij .
Now we consider the problem of dividing the network into c communities. We
first define index matrix S: S = (s1 |s2 | . . . |sc ). Every column of S is a index
vector of 0 or 1, which can be regarded as a latent community. 0 or 1 represents
the disaffiliation or affiliation to this community. The formal definition of S is:
Sij = 1 if node i belongs to community j; 0 otherwise. Then modularity can be
revised as:
1
Q= T r(S T BS) (3)
2m
where B = A − P , which is called modularity matrix. Modularity matrix B
is a real symmetric matrix and its function is the same as that of Laplacian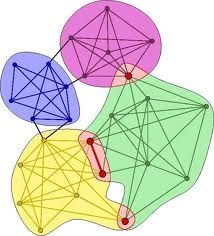
A Multiple Feature Integration Model to Infer Occupation 145
Matrix in standard spectral partitioning. We decompose B as B = U DU T ,
where U = (u1 |u2 | . . .) is a matrix made up of the eigenvectors of B and D is a
diagonal matrix made up of eigenvalues of B. Then we can revise modularity as:
n c
1
Q= βj (uTj sk )2 (4)
2m j=1
k=1
According to [17], when the column vectors of S are proportional to the leading
eigenvectors of B, modularity can be maximized. To avoid the problem of 0 or 1
in S, we relax S to be continuous. In this case, when S is made up of the top-c
eigenvectors of B, modularity can be maximized theoretically. We should note
that the number of communities, c, is uncertain. We need to choose proper c
to maximize modularity in practice. According to equation 4, only when βj is
positive can it have positive effect on modularity. As a result, the maximum of
c will not exceed the number of positive eigenvalues of B.
With the discussion of the above features, we can enrich the classification
framework introduced in Section 3. Empirical study will be presented in the
next Section.
5 Experiments
In this section, we report our evaluation experiments on Sina Weibo. We first
compare results of different inference models and different classifiers. Then we
validate our homophily assumption from two aspects and finally dive into the
heterogeneous networks characters.
5.1 Baseline and Evaluation Metrics
To demonstrate the improvement of the proposed model, we select the following
baselines:
– Weighted Random Model(WRand): This model ignores any content and net-
work information and simply classifies user to a random occupation with the
probability proportional to the percentage of that occupation.
– Majority Model(Majority): This model also ignores any content and net-
work information. Users are classified into the same occupation label which
accounts for the largest proportion of all the occupations.
– Content-based Model : This model considers the content-based feature. We
classify this model into 4 parts: tweet content model(LDA), hashtag model
(Hashtag), tag model(Tag) and profile model(Profile).
– Community-based Model(Cmty): This model only contains the latent social
dimension feature.
– Combined Model : This model contains both content and community features.
We divide this model into 4 parts: tweet content and community(LDA-
Cmty), hashtag and community(Hashtag-Cmty), tag and community(Tag-
Cmty) and finally profile and community(Profile-Cmty).
We choose common evaluation metrics to evaluate our model. They are Pre-
cision, Recall and F-measure respectively.
146 X. Wang et al.
5.2 Classifier Choice
Figure 3 shows the performance of different classifiers using community feature.
Here we take logistic regression and support vector machine(SVM) for example.
From the result, we can find that though the precisions of these two classifiers
are almost the same, SVM performs much worse than logistic regression in recall,
more than 10% lower, which finally results in the poor f-measure for SVM.
This study indicates that regarding the dimension selection for the community
feature, logistic regression performs much better than SVM.
Fig. 3. Comparison of Different Classifiers
5.3 Inference Performance
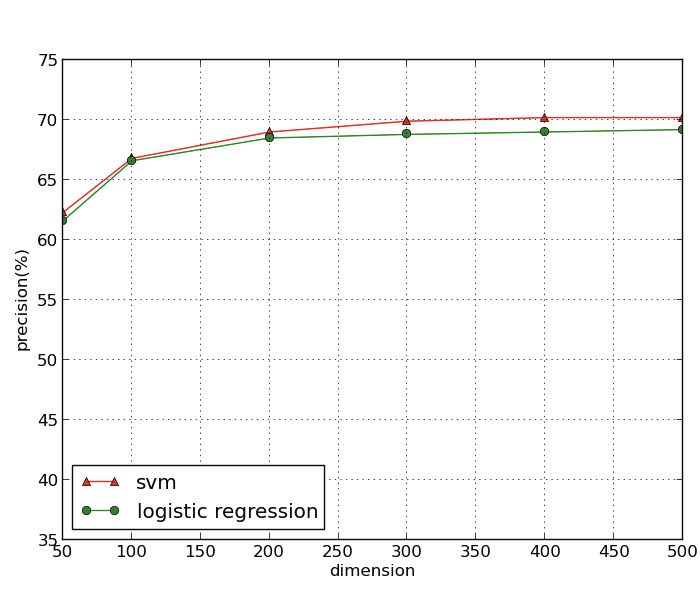
Figure 4 shows the results of different inference models. To let different models
comparable, we set the dimension of Hashtag, T ag, P rof ile, Cmty to all 500.
From the results, we observe that W Rand and M ajority perform very poor
because they do not consider any content and community information. For the
other four models based on content, we find that the performance of LDA, T ag
and P rof ile are almost the same, i.e., about 60% for all metrics while the per-
formance of Hahstag is comparably poor, with f-measure just 24%. For Cmty
model, it outperforms all the content-based models, with nearly 70% precision,
recall and f-measure. Thus we can conclude that the community feature, i.e.,
latent social dimension, performs better than content-based features in our oc-
cupation inference task. The benefit of this finding is that we can infer user’s oc-
cupation just based on network structure, without incorporating what he tweets
or what he re-tweets. This is especially important for users who seldom post any
tweets or make any comments.
5.4 Homophily Characters
In Section 4, we discuss the homophily hypothesis, i.e., users of same occupa-
tion are more likely to gather together and establish connections, thus forming
significant community structure. We verify this assumption in this section from
the following two aspects.A Multiple Feature Integration Model to Infer Occupation 147
Fig. 4. Comparison of Different Inference Models(Logistic Regression Classifier)
– Verification 1 : [4] points out that when the value of modularity in community
discovery is larger than 0.3, an obvious community structure can be observed
in the network. Based on this , we calculate the modularity of friend network
and we get 0.59 which is much larger than 0.3. Thus, we are sure to conclude
that a significant community structure exists in friend network.
– Verification 2 : After verifying significant community structure in friend net-
work, we analyze whether there is a dominant occupation in these commu-
nities. Figure 5 explains the occupation distribution of top-10 communities
detected from friend network. The red color indicates dominant occupation
in this community. We find that there is always a dominant occupation in
top-10 communities. This also indicates that users of the same occupation
are more likely to connect with each other and form community structure.
Community Entertai Governmen Public
Education Service Estate Media Medical Others Electronic Transport Finance
size nment t welfare
1823 0.095 0.049 0.012 0.252 0.188 0.023 0.017 0.015 0.052 0.042 0.010 0.245
1319 0.019 0.033 0.595
0.020 0.047 0.014 0.014 0.011 0.020 0.087 0.006 0.134
984 0.023 0.447 0.027 0.034 0.061 0.012 0.045 0.021 0.066 0.075 0.149 0.039
927 0.068 0.037 0.013 0.024 0.035 0.011 0.040 0.634 0.071 0.033 0.008 0.027
810 0.075 0.101 0.017 0.060 0.064 0.044 0.017 0.002 0.072 0.475 0.021 0.049
715 0.022 0.076 0.001 0.006 0.027 0.580 0.069 0.048 0.091 0.052 0.014 0.015
693 0.017 0.014 0.001 0.003 0.087 0.007 0.694 0.006 0.088 0.020 0.046 0.016
644 0.012 0.022 0.003 0.042 0.054 0.009 0.002 0.006 0.017 0.030 0.764 0.039
485 0.501 0.019 0.008 0.016 0.031 0.019 0.153 0.023 0.167 0.049 0.012 0.002
336 0.042 0.021 0.015 0.036 0.054 0.074 0.083 0.024 0.196 0.009 0.435 0.012
270 0.089 0.063 0.004 0.052 0.085 0.537 0.004 0.019 0.019 0.067 0.015 0.048
250 0.172 0.020 0.012 0.012 0.080 0.028 0.128 0.004 0.396 0.036 0.044 0.068
239 0.025 0.100 0.004 0.548 0.151 0.013 0.038 0.013 0.038 0.029 0.004 0.038
100 0.060 0.080 0.000 0.000 0.090 0.050 0.110 0.010 0.480 0.080 0.010 0.030
100 0.040 0.030 0.060 0.170 0.080 0.000 0.100 0.030 0.390 0.050 0.020 0.030
Fig. 5. The Occupation Distribution of top 10 Communities Detected(Friend Network)148 X. Wang et al.
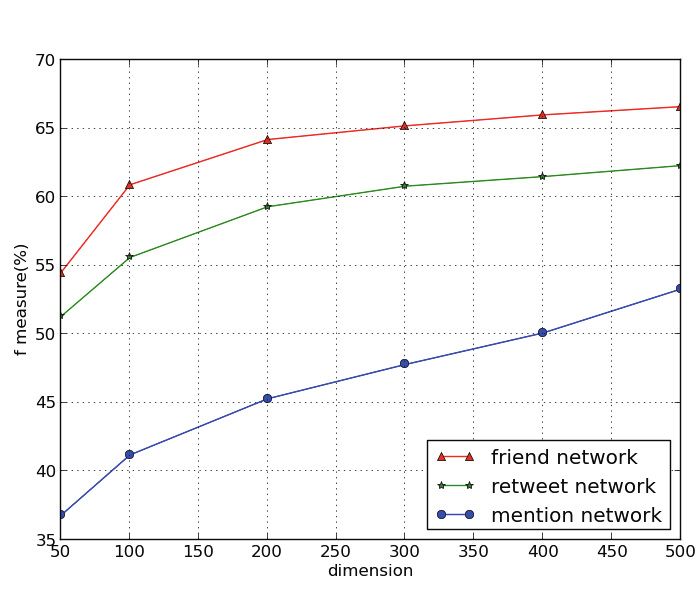
5.5 Heterogeneous Network Effects
Heterogeneous networks, refer to networks made up of different types of ob-
jects or different interaction patterns. Here, we mainly focus on three hetero-
geneous networks based on different interaction types: friend network, retweet
network and mention network. Friend network refers to networks made up of
bi-follower relationships. Retweet network forms due to the retweeting actions
between users. Mention network is created by users using @ to mention each
other. Figure 6 is the inference result of three networks using just community
feature. From the result, we can conclude that friend network performs best in
all three metrics and retweet network performs a little worse than friend net-
work while mention network performs worst. One interesting phenomenon is that
even though both retweet network and mention network are created due to user
interaction behaviors, the performances of them are quite different.
To investigate the reason, we conduct a tentative analysis of three networks.
From Table 2, we find that the statistical features of friend network and retweet
network are almost the same while mention network is much sparser, with more
than 10000 users of degree zero, which might be a reason for the poor perfor-
mance of mention network. [5] points out that in social network, the mention
function(@ ) often plays a role to connect users having different or even opposed
opinions and behaviors, which results in the poor homophily phenomenon in
mention network.
Fig. 6. Inference Performance of Different Heterogeneous Networks
Table 2. Statistical Characters of Heterogeneous Networks
Friend Network Retweet Network Mention Network
Links 2770378 2745765 776177
Average degree 42 41 12
Number of nodes
618 3714 10811
with degree of zeroA Multiple Feature Integration Model to Infer Occupation 149
6 Conclusions
In this paper, we propose a multi-source model to infer users’ occupation cate-
gories on micro-blog platforms. We utilize both users’ posted content feature and
their interaction community features in this model. The content feature includes
tweet content, hashtag, personal tag and personal profile. For the network fea-
ture, we propose to use latent social dimension, in order to better identify user’s
latent affiliation. Then we model this inference task as a supervised classification
problem and introduce the manually labeled source to train a inference model.
We systemically analyze the data characters on a real large micro-blog(Sina
Weibo) dataset and demonstrate the advantage of proposed approach. At the
same time, we also reveal the patterns of different user interaction communities
and homophily phenomenon among users of the same occupation category.
With the continuous growth of social media services, effective user profile
extraction and user interest modeling become more and more important. Oc-
cupation inference model proposed in this paper has several promising future
direction. For example, we can extract users’ occupation evolution, profile vari-
ety and interest distribution among different groups.
Acknowledgements. This research was supported by the National Natural
Science foundation of China under Grant No. 61272155 and 61073019.
References
1. Backstrom, L., Sun, E., Marlow, C.: Find me if you can: improving geographical
prediction with social and spatial proximity. In: Proceedings of the 19th Interna-
tional Conference on World Wide Web, pp. 61–70. ACM (2010)
2. Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent dirichlet allocation. The Journal of
Machine Learning Research 3, 993–1022 (2003)
3. Cha, M., Haddadi, H., Benevenuto, F., Gummadi, K.P.: Measuring user influence
in twitter: The million follower fallacy. In: 4th International AAAI Conference on
Weblogs and Social Media (ICWSM), vol. 14, page 8 (2010)
4. Clauset, A., Newman, M.E., Moore, C.: Finding community structure in very large
networks. Physical Review E 70(6), 066111 (2004)
5. Conover, M.D., Ratkiewicz, J., Francisco, M., Gonçalves, B., Flammini, A.,
Menczer, F.: Political polarization on twitter. In: Proc. 5th Intl. Conference on
Weblogs and Social Media (2011)
6. Girvan, M., Newman, M.E.: Community structure in social and biological networks.
Proceedings of the National Academy of Sciences 99(12), 7821–7826 (2002)
7. Hagen, L., Kahng, A.B.: New spectral methods for ratio cut partitioning and clus-
tering. IEEE Transactions on Computer-Aided Design of Integrated Circuits and
Systems 11(9), 1074–1085 (1992)
8. Han, J.: Mining heterogeneous information networks by exploring the power of
links. In: Gama, J., Costa, V.S., Jorge, A.M., Brazdil, P.B. (eds.) DS 2009. LNCS,
vol. 5808, pp. 13–30. Springer, Heidelberg (2009)
9. Hofmann, T.: Probabilistic latent semantic analysis. In: Proceedings of the Fif-
teenth Conference on Uncertainty in Artificial Intelligence, pp. 289–296. Morgan
Kaufmann Publishers Inc. (1999)150 X. Wang et al.
10. Li, R., Wang, S., Deng, H., Wang, R., Chang, K.C.-C.: Towards social user pro-
filing: unified and discriminative influence model for inferring home locations. In:
Proceedings of the 18th ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, pp. 1023–1031. ACM (2012)
11. McPherson, M., Smith-Lovin, L., Cook, J.M.: Birds of a feather: Homophily in
social networks. Annual Review of Sociology, 415–444 (2001)
12. Mislove, A., Viswanath, B., Gummadi, K.P., Druschel, P.: You are who you know:
inferring user profiles in online social networks. In: Proceedings of the Third ACM
International Conference on Web Search and Data Mining, pp. 251–260. ACM
(2010)
13. Newman, M.E.: Finding community structure in networks using the eigenvectors
of matrices. Physical Review E 74(3), 036104 (2006)
14. Newman, M.E.: Modularity and community structure in networks. Proceedings of
the National Academy of Sciences 103(23), 8577–8582 (2006)
15. Otterbacher, J.: Inferring gender of movie reviewers: exploiting writing style, con-
tent and metadata. In: Proceedings of the 19th ACM International Conference on
Information and Knowledge Management, pp. 369–378. ACM (2010)
16. Pennacchiotti, M., Popescu, A.-M.: Democrats, republicans and starbucks affi-
cionados: user classification in twitter. In: Proceedings of the 17th ACM SIGKDD
International Conference on Knowledge Discovery and Data Mining, pp. 430–438.
ACM (2011)
17. Pothen, A., Simon, H.D., Liou, K.-P.: Partitioning sparse matrices with eigenvec-
tors of graphs. SIAM Journal on Matrix Analysis and Applications 11(3), 430–452
(1990)
18. Rao, D., Yarowsky, D., Shreevats, A., Gupta, M.: Classifying latent user attributes
in twitter. In: Proceedings of the 2nd International Workshop on Search and Mining
User-Generated Contents, pp. 37–44. ACM (2010)
19. Sen, P., Namata, G., Bilgic, M., Getoor, L., Galligher, B., Eliassi-Rad, T.: Collec-
tive classification in network data. AI Magazine 29(3), 93 (2008)
20. Sun, Y., Norick, B., Han, J., Yan, X., Yu, P.S., Yu, X.: Integrating meta-path
selection with user-guided object clustering in heterogeneous information networks.
In: Proceedings of the 18th ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, pp. 1348–1356. ACM (2012)
21. Tang, L., Liu, H.: Relational learning via latent social dimensions. In: Proceedings
of the 15th ACM SIGKDD International Conference on Knowledge Discovery and
Data Mining, pp. 817–826. ACM (2009)
22. Yang, S.-H., Long, B., Smola, A., Sadagopan, N., Zheng, Z., Zha, H.: Like like alike:
joint friendship and interest propagation in social networks. In: Proceedings of the
20th International Conference on World Wide Web, pp. 537–546. ACM (2011)You can also read

















































