An Hybrid and Syntactic Machine Translation Model for English to Ahirani Language
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
International Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
An Hybrid and Syntactic Machine Translation Model for English
to Ahirani Language
UDAY C. PATKAR, DR. PRASADU PEDDI, DR. SUHAS H. PATIL
1
Ph.D. Scholar, Department of Computer Engineering, Shri JagdishprasadJhabarmalTibrewala
University, Vidyanagari, Jhunjunu, Rajasthan
2
Professor, Shri JagdishprasadJhabarmalTibrewala University, Vidyanagari, Jhunjunu, Rajasthan
3
Professor, Bharati Vidyapeeth Deemed University College of Engineering, Katraj, Pune
patkarudayc@gmail.com1
*Corresponding author: patkarudayc@gmail.com
ABSTRACT:In India, being the nation of many diverse by clan it being a place of people
from all caste, religion, languages, ethnicities. Language is a key to human communication:
Spoken and written language can be separated as well. But it becomes almost impossible to
communicate with when there is a language barrier. Though in the state of Maharashtra,
Marathi is the predominant language, Ahirani is spoken widely. A large percentage of
Ahirani residents lack familiarity with the language so they have a hard time understanding
the phrases and/Ahirani residents are unable to fully comprehend the language, which
makes it difficult for them to understand Due to the general population having little
language comprehension, this segment of the population is of people finds it difficult to
comprehend other languages. To begin with, machine translation requires a dilemma, which
makes it a more difficult and hence requires additional steps. Next, it becomes a challenge
to manage translation divergences. The diversity of the source language presents will be
preserved as long as long as sentences are identical in terms of the original language do not
have corresponding translations that are congruent in terms of meaning and syntax. In order
to better identify and analyze all of the discrepancies, a more thorough analysis of machine
translation issues is needed. The present study is based on Ahirani language design and
development.
KEY WORDS:Indian Languages, Machine Translation, Natural Language Processing,
Lexical Analysis, Computational Linguistics, Rule Based Translation
1. INTRODUCTION
Machine powered translation is a key research area in Natural Language (NL) that aims
to remove language as an impediment to communication and knowledge access through the
use of bi-lingual machine translation. The machine translation research was conducted from
English to Urdu, Hindi, and various other Indian languages to other Indian dialects like
Telugu and other foreign ones like Arabic, and Chinese as well as well as to work on
translation from English to Urdu.
The research issue to solve is the culture of Marathi language, which has been derived
from Sanskrit and is spoken and used by more than 0.8 billion people. The order of words is a
big issue in the translation of spring language to objective language. Marathi is the most
widely spoken language in Maharashtra. The language structure is twin documented from left
to right, from top to bottom of the text. Marathi words are derived from Sanskrit „Nava',
which is derived from „Navin', and month in English is derived from „Maas', which is derived
976
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSC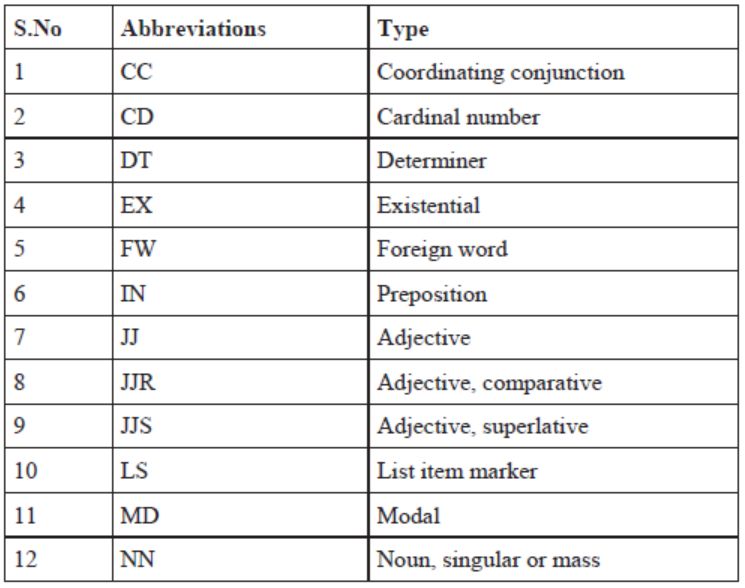
International Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
from „Machine.' Individuals from various cultures and languages are unable to communicate
easily, and a translation system will help to close the void. This research work is intended to
summarize before translating, which will aid Marathi scholars in their analysis of some
English writer's research work. There are various issues and problems to resolve in every
research work. This research work is trying to formulate building dynamic Machine
Translation framework T= [context assertive phrase, interrogative sentences] with sentiment
analysis to highlight insignificant paragraph from paper. As the first script for the research
project progresses, this is the first research paper covering literature. Examine and include a
brief introduction to the proposed work.
Language has characteristics such as being subjective, constructive, imaginative,
systematic, vocalic, social, non-instinctive, and traditional. Phonemes, morphemes, lexemes,
syntax, and meaning are the five primary components of language. These elements, along
with grammar, semantics, and pragmatics, work together to establish effective contact
between individuals. The Central Institute of Indian Languages is an Indian research and
teaching institute located in Mysore that is part of the Ministry of Human Resource
Development's Language Bureau. It was founded on July 17, 1969, to aid in the creation and
implementation of the Government of India's language policy and to organize the
development of Indian languages through research in the areas of language study, language
pedagogy, language technology, and language use in society. The Institute promotes Indian
languages through a number of systematic programs. Khandeshi is an Indo-Aryan language
spoken mainly in the districts of Jalgaon, Dhule, and Nandurbar in Maharashtra, India. It is
made up of Dangri and Ahirani dialects. The words “Ahirani” and “Khandeshi” refer to cast-
based names after Ahirs and region-based names after Khandesh. The design and
development of a computer-based translation model of English words to Khandeshi words is
covered in this paper.
Computer Translation is the conversion of a source language to a target language
performed on a wide scale by a machine. India is a country with a rich cultural diversity, as
well as a wide range of spoken languages. The Indian is held by five big divisions. English to
Ahirani translation Translator is a branch of computer science and linguistics dealing with the
interactions of computers and natural (human) language. EALTsystems translate data from
electronic databases into human-readable language. Natural systems translate human
language samples into more formal representations, such as parse trees or first-order logic
constructs, that computer programs can manipulate. The EALT definition is depicted below.
977
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSC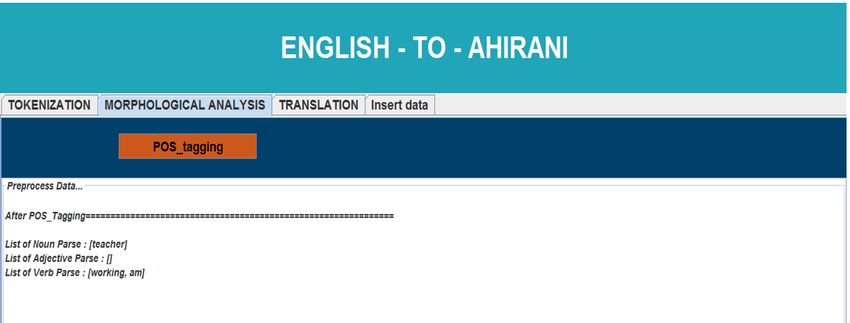
International Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
Easy English affirmative sentences are translated to Ahirani using a rule-based English
to Ahirani translator. We are translating simple English affirmative sentences to Ahirani
sentences in this research project. This is, in essence, a machine translation. We chose the
transfer-based approach, which sits on the precipice between the semantic and direct
approaches. For this, we created a parser that allows us to map an English sentence to the
rules and then convert it to the target language[2].
Languages of Hindi as the official language and English as a second language. English is
the most commonly used language in the world, and it requires research to translate English
documents into native languages in order to acquire information. The English language has
been recognized as a significant communication language in the world [1,2]. Marathi is the
state language of Maharashtra, and in today's world of information, many articles and web
articles are written in English, most of which are in regional languages. A wealth of
knowledge is published by language experts on relevant topics related to the local spoken
language. The issue is that these papers and articles are written in various languages, for
which computer-assisted translation is a quicker and better solution than human-assisted
translation. For assistance and correspondence instructions, the government needs a
translation system. Major organizations such as IIT Bombay, C-DAC, and IIT Hyderabad
have invested heavily in research to develop a better fully automated machine translation
system. The research assessment of their work indicates a substantial change in software
development [4]. They have taken a number of methods, each with its own methodology, to
resolve different research concerns and problems in machine translation. Despite the fact that
major ventures have been on English to Hindi, Tamil, Bangala, Urdu, and other languages.
978
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSC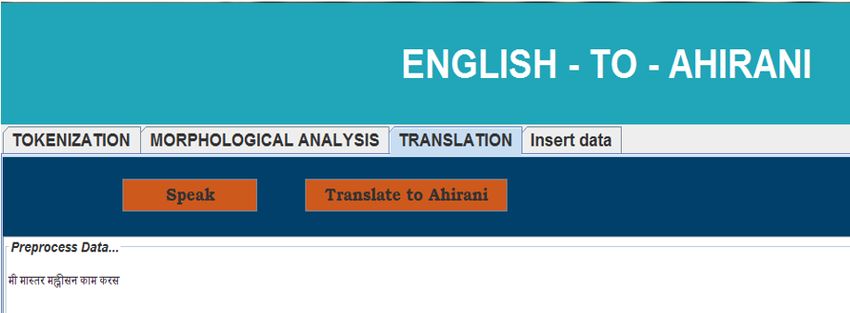
International Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
There is less work available in English to Marathi translation. P.S.Battacharya's work at IIT
Mumbai is lauded for the development of a wordnet in a Marathi parallel corpus for Marathi
English and Hindi, as well as the Interlingua approach in translation, which is also a hybrid
approach in machine translation[3].
This research article is divided into five parts. Subdivision I provides an introduction to
the topic, subdivision II provides related work and a survey of structures, subdivision III
provides the core methodology in our work, subdivision IV provides implementation
specifics, subdivision V provides a comparative analysis, and subdivision VI provides
evaluation parameters.
2. THEORETICAL BACKGROUND
2.1 Stages of Language Processing
When it comes to explaining what happens inside a Natural Language Processing, the
best way is by means of the „levels of language'. This is also known as the synchronic model,
and which posits that human language is governed by one step-by-by-step approach.
New research in psycholinguistics says that language processing has discovered that it's
much more dynamic; one can process the levels in any order they want. When studying
subjects such as literature, the insight we might be that we use knowledge that is usually
considered at a higher cognitive level for purposes that are at a lower level To deal with
excess water-flow, regular irrigation, as opposed to irregular rainfall, is a critical component
of a farming to maximize the productivity of the food and fiber you grow in your land while
minimizing your reliance on outside sources of water and risk of drought.
Morphology: This stage is about morphemes, which are made up of basic meanings
Lexical: Each individual word is associated with different potentials and evaluations, so both
humans and NLP systems interpret those. These words, although widely used in speech and
writing, do not all have one single labels; multiple processing occurs that affects word level
comprehension, the primary process of assigning one tag to each. In this processing, the
terms which may occur as part of a whole words are treated as though they were part of a
compound according to their likelihood of being part of being a whole words.
Syntactic: It is particularly useful for unpacking a sentence into its constituent parts and
studying the relationship between the various parts of a sentence structures. Both the
grammar and the parser are needed for this expansion. Expanding this phrase: For structural
dependency relationships to be articulated, the terms must be (almost certainly) output as a (a
non-linear string that may contain two sets of values).
Pragmatic: This stage deals with using language in contexts to better comprehend the
intended by the author expanding on decoding: Also, the aim is to describe the extra meaning
that exists in texts that isn't directly represented in them. Knowing intentions, strategies,
and/goals on a global scales is a major prerequisite for understanding and predicting
outcomes. Many Neuro-Linguistic programs can rely on either on knowledge bases or
inference modules.
979
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
2.2 Different Techniques of Machine Translation Scheme
1) Machine translation based on Examples:
While it is generally agreed that bilingual corpora are an excellent resources for language
translation, particularly for machine translation, many people also contend that a non-finished
products are necessary because of how they improve results, enhance the quality of the
process. It is merely an analogization, which can be thought of as a machine learning
implementation that uses the reasoning process of induction.
2) Transfer-Based Machine Translation:
It's transfer-based and interlingua-based machine translation that shares a similar view: Both
models attempt to make it possible to construct an interdependent intermediate representation
from each source sentence in order to produce the target one that is expected to match it
exactly. In interlingua-based MT, it must be a representation that is independent of the inter-
dialects in question, but in transfer-based MT, it must have some relationship to the
languages being transposed.
3) Statistical Machine Translation
More basic to the algorithm is a two-language approach used in the Statistical machine
translation method that goes through the bilingual corpus. The technology of statistical
machine translation was first introduced by Warren Weaver in 1949. Nowadays, the study of
machine translation is by far the most studied method of machine translation. Since
translation is quick for languages with small numbers of cognates, expensive to expand, and
doesn't require large amounts of time and resources, it, this technique is an example of
"successful" research on Machine Translation. Many other classification methods include
word/phrase or syntax categorization. Classifying based on hierarchical relationships
necessitates sub-categorization, among others.
4) Rule-Based Machine Translation (RBMT)
In a classical machine translation (also known as “classical machine translation” machine
translation or “knowledge-based machine translation” , linguistic information about the
source and target languages are essentially given by bilingual or multilingual dictionaries and
grammars (with morphology, morphology, and syntax details for languages covered) that
basically comprise rule information about the semantic, morphological, and syntactic facets.
constrained by the choice of input sentences, an RBMT method derives multiple target
sentences on the basis of morphological, syntactic, and semantic analysis of the sources
involved.
3. REVIEW OF LITERATURE
Natural language processing is usually comes into play when systems are used to
manipulate or to work with text or speech As part of the present research [5], a text-to-to-
speech system has synthesizes text by incorporating Natural Language Processing (NLP)
before proceeding with Digital Signal Processing (DSP) to form the synthesized words. were
able to create a basic, but helpful text-to-app that synthesizes written text to speech and stores
it as an mp3 file.
Bridging the language scripts to speech to deaf individuals would aid in fostering will
boost the civil Narrow-domesticating population Most of the literature about converting
980
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
English text to speech mentions how hard it is to do, but it has not been done very
successfully, if there's something you're interested in learning about text to speech
conversion, research on local languages should yield results. In this paper [6], they claim that
Kann text can be converted to speech using this algorithm (2). We convert directly from
registered speech parameters rather than deriving a concatenated values from live speech data
here. the algorithm is also takes part in a global comparisons, where it is competing with
another synthesizer which is commonly used for language learning purposes in language and
its use is at the root of most communication problems. If a person is not proficient in English,
they simply look at a grid icons that have been enlarged on a screen to see as to how their text
will be displayed in the original language. This study represents a new area of research since
it presents data from 53 different languages in the possibility of making it's results usable in
many others.
It's built on a proof-of-concept prototype, which enables the user to understand the
information in the images, depending on their linguistic preference[7]. Graphinge refers to an
extraction of text from images, as well as text translation of the extracted text to different
languages for viewing and presentation. with Tesseract OCR [optical character recognition],
and the Google Speech API [application program interface]. This allows the travellers to ease
their minds, since they can now listen to English audio information they prefer. Furthermore,
it can also be used for the visually impaired. This device is great for people who want to hear
the text being spoken in their native tongue.
To expand upon the rule-based text-to-to-speech synthesis which has proven useful, this, it
has incorporated natural phonetics and lexical formant techniques [8], and formed the
resulting product into a concatenation. The simulation demonstrates that the capabilities of
managing words, phrases, sentences, and paragraphs for better speech recognition on the best
than our current system in Marathi With an accuracy of 91% the overall system can predict
91% of how long a process will last. To increase accuracy, extra efforts are needed in regard
to the recognition of stressed syllables and voice emphasis.
The article breaks down the text into its smallest pieces and compiles it into spoken
sounds, which are stored in the database to generate the output. The discussed work [9] thus
uses concatenation in-based speech synthesis on the MATLAB 2010 platform, which is
considered high-quality and clear-sounding. applied text retrieval is widely used as assistive
tools for those who have dyslexia, or literacy disabilities, or more specifically for those who
have visual disability Although other useful uses for the software include the avoidance of
eyestrain while reading (either in paper or digital formats), minimizing document production
costs due to printing out digital text, English translation, and digital writing/editing, and
encouraging listening comprehension, they are to improve foreign language skills and
pronunciation.
EquivAbstract: The paper [10] provides a rule-based method for translating simple English
sentences into assertive Marathi. a result assertive statement or something descriptive of the
system takes a straightforward sentence as an input and gives out phrases that describe that
the given out the things or situations (lexemes). a second time. The tokenizer recognizes each
of the newly created English characters as well as being a character in the English dictionary
(lexicon). when a lexical items have tokens associated with them, it is also retrieved their
morphological details as needed. The morphemes are grouped on the details found in the
word itself, instead of extracting anything before a proper root is encountered. Groups that
981
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
are set up on a particular spot provide feedback on the manner in which written sentences can
be grammatical. In bottom-up parsing, the syntax is checked by examining the parsing depth
This provides a reliable method for finding the target language word in the sentence because
of its search dictionary expands the syntax (Marathi) token. If the required Marathi word has
not been found for each and collocated with the equivalent English word, then a Marathi
sentence is created with those that can render the English translation of the text. The paper
points out the fundamentals of producing English sentences as well as an alternative ways to
rearrange their vocabulary and proofing advanced language laws.
The document in this study [11] provided a methodology for authorship recognition in the
Marathi language. Two distinctly different corpora, each representing an interpretation for the
text that reflected the patterns that the writer of the words that occur most frequently and that
we identified in the original (statistical similarity model and SMORDT-Sequential minimal
optimization with rule- based Decision Tree approach). In order to show that feature
extraction in any model is important, we then we checked and validated the method of feature
extraction of this experiment uses. Based on the three different factors ( Recall, Precision,
and Accuracy), the proposed strategy has been executed over a wide range of time.
When society becomes more urbanized, the need for fresh air becomes greater.
Technology has increased the amount of data so that the amount of which has doubled every
two years since it was first reported to date. As a result, it has required the use of computers
to understand, interpret, interpret, and apply data, with minimal human input. Many of these
text source code text segments are difficult to comprehend, but some have been translated
into their "code-mixed" or machine code-like languages, which are particularly tricky to
analyse. This work [12] has already been completed in this field and this advances it. and
comparability is applied to classifying these documents for training and testing the classes of
the learning system (Bag of Words, and Human Priors (NB, SVM)) as well as evaluating it,
Marathi and Hindi text-translated documents (classifications, which explores the subjectivity
of data using Support Vector Machines and Naïve Bayes) with the goal of deciding which
classification methodology to employ for handling them The simple machine learning
algorithms often have better results, however, or in numerous cases equal, to the analytical
approaches.
It is an option for Marathi-speaking users to write a sentence in which each clause begins
with two words in order to be sure that they have unambiguous word separation [13]. The
Marathi language does not include the start-sentence indication found in English, which is
why it is difficult to define sentence ends. Dependable systems take into account many pieces
of information to correctly decide the end of a statement.
Translation App [14] (a tool for using speech to support English) is targeted toward those
who are language minorities who wish to translate Malayalam text to their own tongue and
engage the Kerala. The accuracy of machine translation and text-to-to-speech is improved by
means of various combination approaches, including both MT and TTS. The grammar-based
translation process of expanding on the part of the English text combined with a
morphological analysis and a Malayalam/Tamil/English dictionary is used when Malayalam
is the source of the translation. From each of the translated Malayalam syllables, words, they
are, (each having one), individual ones. a large number of syllable-recordings are made and
registered in the syllable database Malayalam words are concatenated and synthesized to
produce a synthesized. The accuracy of machine translation into Malayalam is 70% for the
982
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
first two iterations and 73% for the three expand stages. of the voice output, the device must
make use the features of naturalness and intelligibility to verify the accuracy In the evaluation
process, 87% of the sentences are correctly formed.
4. IMPLEMENTATION
The key component in accurate knowledge representation is interpretation; therefore, the
core technique employs mapping one-to-one rules in English to relevant rules in Marathi
language, which are handcrafted in structure and parsing analysis of OPEN NLP. It is shown
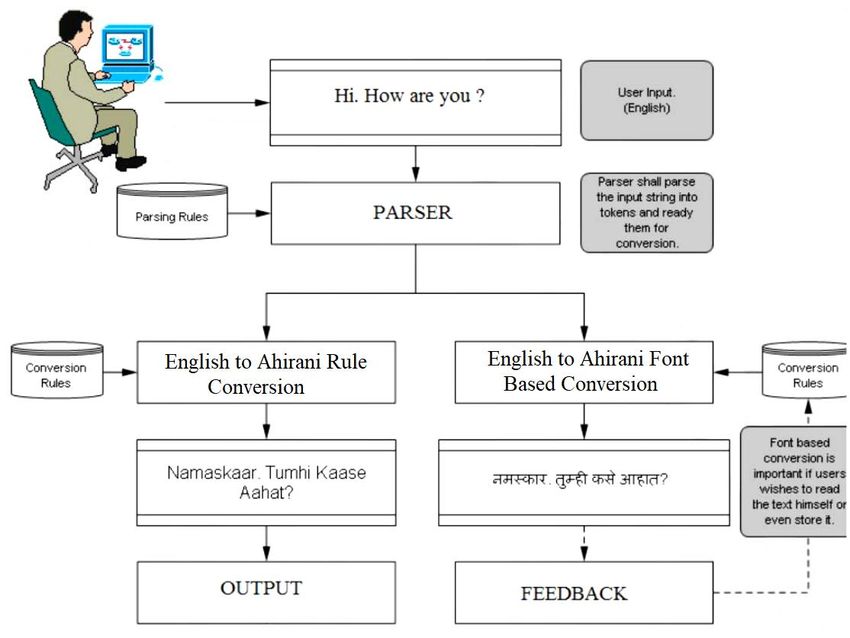
in Figure 2 that the techniques employed are based on lexical analysis to detect subject and
object nouns, and subsequently to apply Ahirani morphology are suitable nouns. Many of the
open source libraries on the Extend Packages page have been created for use with the goal of
making it easier to use and more effective to install and to the hiwii platforms.
The project should be written into a programming language, to would be translated into
computer code and stored in a repository of code, and then deployed into the target
framework. A dictionary collection has been made to store proper nouns and adverbs. The
OPENNLP kit contains Sentence detection (), Tokenization (), parsing, and Tokenizing in the
chunks (where Sentence and Tokenizing are used as separate functions). The Ahirani
language is to English rules have been mapped by the openLP package's data structure of the
OPENNLP project Accurate knowledge is key to success in the Six Step design is central to
the proposed approach
The framework is web deployed and web based, extracting information from URLs and
web pages as well as various online content. The output of summarization is input to the
translation module, and the translated output is cross-lingual information retrieval
architecture of Cross-lingual information retrieval system.
983
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
Figure 2. System Architecture of the Proposed Framework
The architecture of system consists of six phases .
984
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
Stage 1: In this stage, the dataset of which is dictonary of English to Ahirani words has been
created will be given as an input along with the test dataset. Here, the statements will be
separated into Tokens first. This step will give us the list of keywords. In the next step
stemming and stop words removal will be performed and the list unique words will be
selected.
Stage 2: The next phase is of NLP Processing. Here the POS Taging will be performed. Part-
of-speech tagging (POS tag or POS tag or message), also known as grammatical tagging or
word category ambiguity, is the method of classifying words in a text (corpus) as belonging
to a specific part of speech based on both their meaning and their context—that is, their
relationship to corresponding and related words in a phrase, sentence, or paragraph. This
condensed method is typically used to teach school-age children how to identify words in the
form of nouns, verbs, adjectives, verbs, and so on. POS marking is often used when creating
lemmatizes, which are used to shorten a word's root form. The method of labeling words in
the body of the corresponding part of a speech tag based on their meaning and description is
known as POS tagging. Table 1 depicts a POS marking example.
Table 1. POS Tagging Set
The POS tagger produces information about the words in the input sentences by suffixing the
alphabet based on the tag set in Table-I. Tagging is performed by loading a "qualified" file
containing the information needed by the tagger to tag the input words.
For Example:
Input Sentence: Dasaratha ruled in Ayodhya
Output Sentence: Dasaratha_NN, ruled_VBD, in_IN,
Ayodhya_NN
The tagged words are then passed on to the declension tagger.
Phase 3: Here the words will be classified using the Machine Translator mechanism where
we have used the Recurrent Neural Network and Hidden Markev Model.
985
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
The RNN works as follows:
1. A single time step of the input is provided to the network.
2. Then calculate its current state using set of current input and the previous state.
3. The current ht becomes ht-1 for the next time step.
4. One can go as many time steps according to the problem and join the information
from all the previous states.
5. Once all the time steps are completed the final current state is used to calculate the
output.
6. The output is then compared to the actual output i.e the target output and the error is
generated.
7. The error is then back-propagated to the network to update the weights and hence the
network (RNN) is trained.
The Pseudo Code for RNN is as follows:
8. EXPERIMENTAL ANALYSIS
When evaluating research projects, the capacity, our only concern is how long a query
response takes to find, but also mathematical recall is ignored, making it difficult to evaluate.
We need to take into consideration other criteria, such as quality and security in order to get a
better overall view of the impact on the community.
986
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
The result of the POS Tagging phase is as follows:
Figure 3. POS Tagging
Following figure 4 sows the machine translation phase output after classification and
translation.
Figure 4. Machine Translation Output.
The comaprison of Accuracy of our Hybrid approach is shown in figure 5. The comparision
shows that the translation accuracy of our hybrid approach is near about 93 % in comparision
to the statistical and rule based approaches as discussed in the literatures.
987
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
Figure 5. Graphical Evaluation of Hybrid System
9. CONCLUSION REMARKS
We have studied the topic of Ahirani divergence classifiers in this paper. As well as
structural and syntactic divergence, we have found it worthwhile to take into account the
classification of translation. The relationship between Ahirani and English divergences has
been explored in the literature in detail but we have only dealt with divergences that have not
been covered directly or remotely. We have shown here that the Ahirani-English translation
divergence is more complicated than current works can describe. To get accurate translation,
we have to investigate all of the grammatical as well as some extra-grammatical features of
both in Ahirani and English.
REFERENCES
[1] Pramod Salunkhe , Mrunal Bewoor , Suhas Pati , Shashank Joshi ,Aniket kadam, “Summarization and
Hybrid Machine Translation System for English to Marathi: A Research Effort in
InformationRetriveal System (H-Machine Translation” ,Discovery The International journal (ISI
thomas retuers indexed).2015.
[2] Pramod Salunkhe , Mrunal Bewoor , Dr.Suhas Patil “A Research Work on English to Marathi Hybrid
Translation System”, (IJCSIT) International Journal of Computer Science and Information
Technologies, Vol. 6 (3) 2015, 2557-2560.s
[3] S. B. Kulkarni , P. D. Deshmukh “Linguistic Divergence Patterns in English to Marathi Translation
International Journal of Computer Applications (09 75 8887) Volume 87 No.4, February 2014.
[4] J. Ramanand, Akshay Ukey, Brahm Kiran Singh,Pushapak Bhattacharyya “Mapping and Structural
Analysis of MultilingualWordnets”
[5] Bulletin of the IEEE Computer Society Technical Committee on Data Engineering.
[6] Sreelekha.S, Raj Dabre, Pushpak Bhattacharyya “Comparison of SMT and RBMT,The Requirement
of Hybridization for Marathi Hindi MT” [online pdf].
[7] Amruta Godase, Sharvari Govilkar“Survey Of Machine Translation Development for Indian Regional
Languages” International Journal of Modern Trends in Engineeringand Research IJMTER- 2014.
[8] M.L.Dhore & S.X.Dixit (2011) “English to Devnagari Translation for UI Labels of Commercial web
based Interactive
988
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCInternational Journal of Grid and Distributed Computing
Vol. 14, No. 1, (2021), pp. 976-989
[9] Applications, International Journal of Computer Applications (0975 – 8887) Volume 35 –No.10,
December 2011.
[10] Devika Pishartoy, Priya, Sayli Wandkar (2012) “Exteneding capabilities of English to Marathi
machine Translator.,I JCSI International Journal of Computer Science Issues, Vol. 9, Issue 3, No 3,
May 2012.
[11] priyanka-choudhary “ A approach for interlingua example based EM Translation, IJCSIT,2015.
[12] Abhay A, Anita G, Paurnima T, Prajakta G (2013), “Rule based English to Marathi translation of
Assertive sentence International Journal of Modern Trends in Engineering and Research 2014.
[13] Kadam Aniket Kadam, A.D. Dept. Inf. Tech., BVDUCOEP, Pune, India ; Joshi, S.D. ; Medhane, S.P,
“Question Answering Search engine short review and road-map to future QA Search Engine”,
Electrical, Electronics, Signals, Communication and Optimization (EESCO), 2015 ,
10.1109/EESCO.2015.7253949.
[14] Kadam Aniket ,Prof.S.D.Joshi, prof.S.P.Medhane, “QAS” International Journal of Application or
Innovation in Engineering & Management IJAIEM , Volume 3, Issue 5, May 2014 May 2015.
[15] Kadam Aniket ,Prof.S.D.Joshi, prof.S.P.Medhane, “QAS” International Journal of Application or
Innovation in Engineering & Management IJAIEM , Volume 3, Issue 5, May 2014 May 2015.
[16] Kadam Aniket ,Prof.S.D.Joshi, prof.S.P.Medhane “Search Engines to QAS: Explorative Analysis”,
International Journal of Application or Innovation in Engineering & Management IJAIEM , Volume
3, Issue 5, May 2014 May 2015IJAIEM May 2015 .
989
ISSN: 2005-4262 IJGDC
Copyright ⓒ 2021 SERSCYou can also read

















































