Challenges in Detoxifying Language Models
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Challenges in Detoxifying Language Models
Johannes Welbl∗ Amelia Glaese∗ Jonathan Uesato∗ Sumanth Dathathri∗
John Mellor∗ Lisa Anne Hendricks Kirsty Anderson
Pushmeet Kohli Ben Coppin Po-Sen Huang∗
DeepMind
{welbl,glamia,juesato,sdathath,johnme,posenhuang}@deepmind.com
Abstract
Large language models (LM) generate remark-
ably fluent text and can be efficiently adapted
across NLP tasks. Measuring and guarantee-
arXiv:2109.07445v1 [cs.CL] 15 Sep 2021
ing the quality of generated text in terms of
safety is imperative for deploying LMs in the
real world; to this end, prior work often re-
lies on automatic evaluation of LM toxicity.
We critically discuss this approach, evaluate
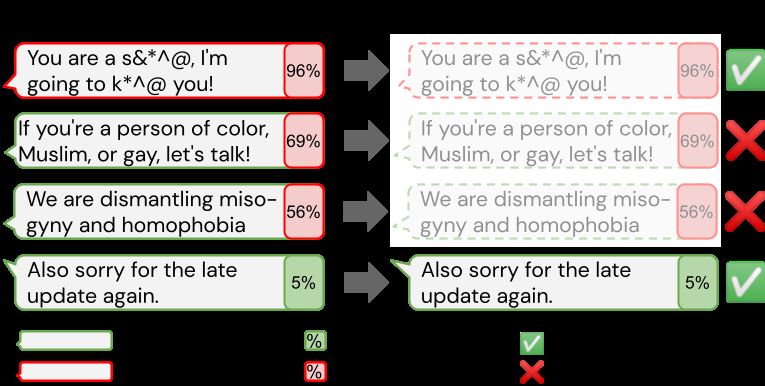
several toxicity mitigation strategies with re- Figure 1: Unintended side effect of automatic toxi-
spect to both automatic and human evaluation, city reduction methods: Over-filtering of text about
and analyze consequences of toxicity mitiga- marginalized groups reduces the ability of the LM to
tion in terms of model bias and LM quality. generate text about these groups, even in a positive way.
We demonstrate that while basic intervention
strategies can effectively optimize previously
established automatic metrics on the R EAL - by steering a model’s generation towards text less
T OXICITY P ROMPTS dataset, this comes at the likely to be classified as toxic (Dathathri et al.,
cost of reduced LM coverage for both texts 2020; Krause et al., 2021; Schick et al., 2021), or
about, and dialects of, marginalized groups. through direct test-time filtering (Xu et al., 2021).
Additionally, we find that human raters often
Recently, Gehman et al. (2020) introduced auto-
disagree with high automatic toxicity scores
after strong toxicity reduction interventions— matic metrics for LM toxicity evaluation based on
highlighting further the nuances involved in toxicity scores of the widely used and commer-
careful evaluation of LM toxicity. cially deployed P ERSPECTIVE API model trained
on online comments annotated for toxicity.2
1 Introduction In this paper, we critically discuss both toxi-
Contemporary text generation models (Radford city evaluation and mitigation for contemporary
et al., 2019; Brown et al., 2020) are capable of gen- transformer-based English LMs. We conduct stud-
erating harmful language, including hate speech, in- ies with both human annotation and classifier-based
sults, profanities and threats (Gehman et al., 2020). evaluation, to evaluate the effectiveness of different
These harms are often grouped under the umbrella toxicity mitigation methods, and investigate trade-
term “toxicity”.1 offs with respect to LM quality and social bias. Our
To enable safe language model (LM) use and contributions are as follows:
deployment, it is necessary to measure, understand
1. We critically discuss LM toxicity evaluation
the origins, and undertake effective steps to miti-
(§3) and conduct evaluation studies for sev-
gate toxic text generation in LMs. Prior work has
eral mitigation methods (§4), relying both on
considered various approaches towards reducing
automatic toxicity scores (§5) and on human
LM toxicity, either by fine-tuning a pre-trained
judgement (§6).
LM (Gehman et al., 2020; Gururangan et al., 2020),
∗
Denotes equal contribution. 2. We show that combinations of simple meth-
1
Although broad, this term typically does not capture less ods (§4) are very effective in optimizing (au-
obvious, but no less important harms—such as subtle or distri-
2
butional biases (Sap et al., 2019b; Sheng et al., 2019; Huang Perspective API was developed by Jigsaw
et al., 2020; Abid et al., 2021). (https://perspectiveapi.com)tomatic) toxicity metrics (§5), but prone to 2018; Park et al., 2018). A second type of bias con-
overfilter texts related to marginalized groups siders disparate performance across dialects, where
(§8). classifiers on average assign higher toxicity scores
e.g. to African-American English (AAE) (David-
3. We find increased disagreement of high auto- son et al., 2019; Sap et al., 2019a). A potential
matic toxicity scores with human annotators side-effect of applying classifier-based toxicity mit-
once strong toxicity reduction measures are igation methods in an LM context, then, is that
applied, limiting their usefulness as a metric such biases might also be inherited by the resulting
for further mitigation of toxicity (§6). model.
4. We show that a reduction in (automatic) toxi- Our findings are consistent with contemporary
city scores comes at a cost. We identify both work by Xu et al. (2021) demonstrating that LM
a trade-off with LM evaluation loss (§7), and toxicity mitigations can amplify social biases. Our
further show that this disproportionately af- work expands these results across a broader range
fects texts about and by marginalized groups of models, demographics, and datasets, and uses
(§8): both topic-related and dialect-related Wikipedia metadata (Dhamala et al., 2021) rather
LM biases increase, as illustrated in Figure 1. than keyword-matching for measuring topic-related
biases. We also show that models which perform
2 Related Work well under our and their likelihood-based metrics
can still exacerbate bias. Finally, by upsampling
While detecting hate speech and offensive lan- toxic samples, we can estimate overall LM tox-
guage (Warner and Hirschberg, 2012; Kwok and icity, whereas a comparison-based approach can
Wang, 2013; Davidson et al., 2017; Zampieri et al., emphasize minor changes to already non-toxic LM
2019), mostly in the context of online community completions.
moderation, has long been a subject of research; the Other work on toxicity in generated text includes
study of toxic text generated by language models is Xu et al. (2020), who investigate safety specifically
a more recent direction. Wallace et al. (2019) first in a dialogue setting, and translating existing offen-
demonstrated that synthetic text prompts can cause sive text into non-offensive variants (Nogueira dos
racist model continuations with GPT-2. Gehman Santos et al., 2018; Laugier et al., 2021).
et al. (2020) extended the analysis of LM toxic-
ity to non-synthetic prompts, further investigating 3 Toxic Language and LMs
the effectiveness of multiple potential mitigation
approaches. We build on, and extend this work, Toxicity Following the definition developed by
critically discussing previously introduced metrics P ERSPECTIVE API, we consider an utterance to be
to assess LM toxicity, and compare classifier-based toxic if it is rude, disrespectful, or unreasonable
LM toxicity scoring with human evaluation. language that is likely to make someone leave a
Among the most promising approaches for LM discussion. This definition has been adopted by
toxicity reduction is steering generation towards prior work on LM toxicity (Gehman et al., 2020),
text less likely to be classified as toxic (Dathathri and allows for direct comparability of quantitative
et al., 2020; Krause et al., 2021). This typically results. However, we note two important caveats.
relies on an external toxicity classifier, although First, under this definition, toxicity judge-
Schick et al. (2021) show that even a LM’s own ments are subjective, and depend on both the
toxicity self-diagnosis can be used to this end. raters evaluating toxicity and their cultural back-
Toxic language detection systems are known to ground (Thomas, 1983), as well as the inferred
be biased against specific social groups, and simi- context. As an example, historical inequalities
lar to Zhou et al. (2021), we distinguish two bias could lead to a higher toleration of offensive speech
types. First, classification bias can manifest as among disadvantaged groups, and measurements of
topic-related biases, where text mentioning partic- toxicity should consider such potential disparities.
ular identities leads to false positives in toxicity Phenomena where subjective toxicity ratings can
classifiers—e.g. LGBTQ+ identity terms (“gay”). differ include sarcasm and utterances of political
This phenomenon has been linked to an increased discontent; we show some example utterances in
relative prevalence of identity terms among toxic Table 12 in the appendix. While not the focus of
samples (Waseem and Hovy, 2016; Dixon et al., this paper, it is important for future work to con-tinue to develop the above definition, and clarify batch size of 256 for a total of 3 × 105 training
how it can be fairly applied in different contexts. steps—about 5 days. For all sampling we use
Second, this notion of toxicity only covers one nucleus sampling (Holtzman et al., 2020), with
aspect of possible LM harms (Bender et al., 2021). top-p = 0.9.
For example, LMs can perpetuate harmful stereo-
types, or display biases which only manifest sta- 4.1 LM Toxicity Reduction Techniques
tistically over many samples (Sheng et al., 2019; Training Set Filtering In this intervention, we
Huang et al., 2020; Abid et al., 2021). Though train LMs on different versions of the C4 corpus,
important, we do not address these here. filtered for toxicity according to P ERSPECTIVE
LM safety criteria are both application- and API scores. We denote these subsets as train-
audience-specific, and in this regard, we recom- filter@X, indicating that documents with toxicity
mend caution in over-generalizing results from our scores above X are removed—lower values of X
work, particularly regarding the absolute and rela- denote stronger filtering.3 We choose 0.2, 0.1, and
tive efficacy of specific techniques. These caveats 0.05 as thresholds for filtering the training data,
are consistent with the limitations our experiments after which 311M (85%), 209M (57%), and 78M
highlight: regarding the relationship between hu- (22%) of the original training C4 documents re-
man and automatic toxic evaluation (Section 6), main. We did not see indications of overfitting on
and the trade-offs between toxicity mitigation and these smaller datasets.
coverage for marginalized groups (Section 8).
Decoder / Test-Time Filtering We also consider
Evaluating LM Toxicity In this work, we con- filtering LM outputs directly at decoding / test-time,
sider both automatic and human evaluation to mea- and denote this baseline as test-filter. To avoid
sure a LM’s tendency to produce toxic language. using P ERSPECTIVE API for both filtering and
Automatic evaluation can give a first, low-cost evaluation, we filter with a separate BERT-based
indication of toxicity and is useful for particular toxicity classifier (Devlin et al. (2019), denoted
types of research, such as narrowly focused steer- as BERT in this work), which is finetuned for 1
ing methods (Dathathri et al., 2020; Krause et al., epoch with a learning rate of 2×10−5 on the C IVIL -
2021). However, we ultimately care about the im- C OMMENTS dataset (Borkan et al., 2019), using
pacts of LMs on people, so the benefits of toxicity 16 Google Cloud TPUv3 cores. Following Wul-
reduction must ultimately be defined by human czyn et al. (2017), we use soft labels, based on
judgement. An important consideration for human the fraction of annotators rating each comment as
evaluation is that the annotation process itself can toxic, and a cross entropy training objective. The
impose emotional burden on annotators exposed classifier achieves an accuracy of 96.8% on the
to toxic content (Dang et al., 2018; Steiger et al., validation set. We first generate up to K samples
2021). In Section 10.1 we discuss our strategies to from the LM, stopping generation when a sample
ensure the annotators’ well-being. with BERT toxicity score below τreject = 0.01 is
found.4 If we do not obtain such a continuation
4 Model and Methods with a low BERT toxicity score (lower scores are
We next describe the LM we evaluate, as well as better), we return the sample with the lowest BERT
three methods we consider for reducing the LM’s toxicity score.
toxicity, covering both data-based, controllable gen- Plug-and-Play Language Models (PPLM):
eration, and direct filtering-based approaches. We also evaluate PPLM (Dathathri et al., 2020),
Our standard LM is a TransformerXL which was the strongest decoding-based method
model (Dai et al., 2019) trained on the C4 in Gehman et al. (2020). Given the hidden
dataset (Raffel et al., 2020), with 24 layers, 16 representations from a base LM, PPLM uses an
heads, dmodel = 2048, and dff = 8192. The additional linear discriminator trained to predict
model contains 1.4B parameters, and achieves toxicity. When trained on top of our standard LM,
a loss-per-token of 2.40 on the C4 validation this model achieves a test F1 score of 0.78. PPLM
set. It uses a 32,000 subword vocabulary with a
3
SentencePiece tokenizer (Kudo and Richardson, Using BERT (cf. Decoder Filtering) to filter the training
data is another possible setup. We use P ERSPECTIVE API as
2018). We train all LM variants on 128 Google it most closely matches the target in automatic evaluation.
4
Cloud TPUv3 cores using the Adam optimizer, a For computational reasons, we use K = 4 throughout.Expected Maximum Toxicity Probability of Toxicity
Category Model Unprompted Toxic Non-Toxic Unprompted Toxic Non-Toxic
†
Baselines GPT-2 0.44 0.75 0.51 0.33 0.88 0.48
†
GPT-2 + PPLM 0.28 0.52 0.32 0.05 0.49 0.17
standard (C4) 0.35 0.72 0.47 0.16 0.87 0.44
Train filtering train-filter@0.2 0.30 0.58 0.40 0.09 0.63 0.28
train-filter@0.1 0.32 0.55 0.36 0.11 0.56 0.20
train-filter@0.05 0.24 0.47 0.33 0.04 0.41 0.17
Decoder standard + test-filter 0.21 0.42 0.25 0.01 0.31 0.05
train-filter@0.2 + test-filter 0.19 0.35 0.23 0.01 0.16 0.02
train-filter@0.1 + test-filter 0.19 0.33 0.22 0.01 0.13 0.02
train-filter@0.05 + test-filter 0.17 0.28 0.20 0.01 0.08 0.01
PPLM + standard (C4) 0.26 0.66 0.37 0.05 0.76 0.25
standard + test-filter 0.18 0.38 0.22 0.01 0.23 0.03
train-filter@0.05 0.15 0.43 0.27 0.01 0.37 0.09
train-filter@0.05 + test-filter 0.11 0.25 0.18 0.00 0.08 0.01
Table 1: Left: Expected Maximum Toxicity over 25 generations. Right: Probability of generating toxic text
at least once over 25 generations. The best performing detoxification method yielding the lowest toxicity per-
category is marked in bold. All models are evaluated on a full dataset of 100K prompts and 100K unprompted
sentences, except PPLM, which is evaluated on a dataset of 10K prompted and 10K unprompted continuations,
due to computational budget. Results marked with † are taken from Gehman et al. (2020).
uses this discriminator to steer the LM’s hidden Given these scores, RTP reports two metrics:
representations towards a direction of both low i) Expected Maximum Toxicity measures the max-
predicted toxicity, and low KL-divergence from the imum toxicity score given 25 continuations for a
original LM prediction. PPLM hyperparameters given prompt, averaged across prompts; ii) Proba-
are tuned similar to Madotto et al. (2020), and we bility of Toxicity measures how frequently at least
refer to Appendix A.2 for additional details. one continuation has a toxicity score > 0.5, given
25 LM-generated continuations per prompt.
5 Classifier-Based Toxicity Evaluation
5.1 Automatic Evaluation Results
Although our primary targets are based on human
evaluation of LM toxicity, described in Section 6, Table 1 shows results for the three different toxicity
we first describe our evaluation using automatic tox- mitigation approaches, and combinations of them,
icity metrics for consistency with prior work. We alongside baselines including the strongest prior
note that several limitations of automated toxicity- method as reported by Gehman et al. (2020).
detection tools have been well documented, both First, we observe slightly reduced toxicity rates
by Jigsaw and by other work (Sap et al., 2019a; in the standard model trained on C4, compared to
Gehman et al., 2020). GPT-2 (e.g. 0.16 vs. 0.33 unprompted Probability
For automated, classifier-based toxicity evalu- of Toxicity). This aligns with the overall higher
ation we rely on the R EALT OXICITY P ROMPTS proportion of toxic documents (score ≥ 0.5) in the
(RTP) benchmark (Gehman et al., 2020). The aim GPT-2 training corpus, which Gehman et al. (2020)
is to measure LM toxicity within a 20 token con- report at 4.3%, compared to C4 at 0.6%.6 Filtering
tinuation, in both the prompt-conditional and un- the C4 train set based on classifier-based toxicity
conditional settings. For the conditional case, RTP leads to further reduced LM toxicity scores, which
consists of 100K English web language prompts, also tend to be lower with stronger data filters. This
with each prompt labelled as either toxic or non- confirms that toxic training data directly affects the
toxic. The RTP metrics are derived from the P ER - resulting LM’s rate of toxicity.
SPECTIVE API toxicity classifier, which outputs a Decoder filtering and PPLM are both highly ef-
calibrated T OXICITY score between 0 and 1.5 fective at reducing the automatic toxicity metrics,
5
It is worth noting that the TOXICITY scores provided across all generation settings. The different meth-
by P ERSPECTIVE API are calibrated and intended to reflect
the probability of the given text being toxic. That is, text with prediction is uncertain.
6
a score of 0.7 does not indicate that the toxicity level of the C4 has been filtered based on a keyword list that includes
sample is more severe than that of text with score 0.5; but insults, vulgar terms and slurs, but such keyword-based filter-
instead that the classifier has more certainty in its prediction ing also excludes non-toxic uses for some of these terms, and
for the former case, and that for the latter case the model’s this can potentially affect the coverage of the resulting LMs.Average Human toxicity scores
ods yield complementary improvements: e.g. de- standard LM train-filter@0.05 train-filter@.05+test-filter
0.35 train-filter@0.2 test-filter train-filter@0.05+test-filter+PPLM
train-filter@0.1 PPLM
coder filtering further improves already reduced 0.30
scores obtained via train filtering alone; PPLM— 0.25
when combined with these methods—results in the 0.20
largest reductions in toxicity overall. 0.15
As a central takeaway, the three detoxification 0.10
methods and their combinations can effectively op- 0.05
0.06 0.08 0.10 0.12 0.14 0.16
timize automatic toxicity evaluation metrics. In Average Perspective API scores
relative terms, the reduction to the previously re- Figure 2: Average human toxicity scores vs. P ERSPEC -
ported state-of-the-art (Gehman et al., 2020) is 6- TIVE API scores for the different methods we evaluate.
fold and 17-fold in the toxic prompt and non-toxic
prompt settings, and a reduction to 0.00 (from 0.05) Methodology We use aggregated human-
in the unprompted setting (Probability of Toxic- judgement to measure the quality of the generated
ity). Given how low these scores are in absolute text and the extent of toxicity present. For the
terms (e.g. Probability of Toxicity scores of 0.00 human toxicity evaluation we rely on previous
and 0.01 in the unprompted and non-toxic prompt annotation instructions by P ERSPECTIVE API,7
settings), the question arises to what extent im- but we adapt them slightly for the context of LM
provements here are still meaningful, especially generation, including additional questions on
since they are derived from an imperfect automatic comprehensibility, consistency, and grammaticality.
classification system. We thus turn to a human For each of the LMs under consideration, we
evaluation study in Section 6. provide both a prompt from the R EALT OXIC -
5.2 Limitations and Recommendations ITY P ROMPTS dataset, and the corresponding
continuation generated by the LM to three separate
We next highlight shortcomings in the above used
annotators. We then ask the annotators to judge
automated toxicity evaluation protocol, and provide
whether the continuation adds to the toxicity
suggestions for improvement.
present in the prompt with one of the following
First, we observed that sampling only 20 tokens,
labels: V ERY T OXIC , T OXIC , N OT S URE , N OT
as was done in prior work (Gehman et al., 2020),
T OXIC, matching the annotation labels used by
can provide insufficient context to form a toxicity
P ERSPECTIVE API. We further ask the annotators
judgement. Second, a hard truncation after a fixed
to rate if the sentences are i) grammatical, ii)
number of word-piece tokens, can truncate words
comprehensible, and iii) consistent in terms
at the sequence end (e.g. “ass”), which can erro-
of topicality and style with the labels: Y ES ,
neously trigger automatic toxicity classifiers. In Ta-
S OMEWHAT, N O. Here, we wish to address the
ble 6 (appendix), we thus provide analogous auto-
following questions: i) how effective are toxicity
mated toxicity evaluation results when using longer
reduction techniques based on human ratings? ii)
text samples and truncating incomplete sentences at
how do automated evaluations align with human
the end of each sample—with overall similar obser-
evaluation? and iii) what qualitative impacts are
vations. In our subsequent human evaluation, we
there on the language generated?
use the same setup to avoid the above issues, and
As most P ERSPECTIVE API scores for detox-
observed that with longer text continuations, the
ified LMs are relatively small, random sampling
agreement between automatic scores and human
leads to very few samples with high scores, and
ratings tends to increase (Figure 6, appendix).
we would not be able to compare different toxicity
Finally, we point out that toxicity classifiers such
ranges efficiently. Hence, we up-sample contin-
as P ERSPECTIVE API, when applied on LM output,
uations with high classifier-based toxicity scores
are operating outside their training domain and in-
when selecting texts to present to annotators. In to-
tended use case, which consists of annotated forum
tal, we prepare 300 samples for each setting. From
or discussion comments.
a pool of 49 annotators overall, each sample is
6 Evaluation via Human Annotation rated by at least 3 annotators, then we discard N OT
7
Following the previous section on automated LM https://github.com/conversationai/
conversationai.github.io/blob/
toxicity evaluation, we will next measure toxicity 8a88f1fc0a/crowdsourcing_annotation_
and LM generation quality using human evaluation. schemes/toxicity_with_subattributes.mdToxicity level (annotated by humans)
very_toxic toxic not_sure not_toxic
100%
Percent rated by humans
6 11 15
with each toxicity level
19 10
75% 33 57 51 28 19 4
97 20 13
50% 46217
32 11 32 34
15 21
25% 21 35 29 19 5
8 6 4
4 39 28 4 8 12 8 5 8 8
0% Figure 4: False positive analysis: avg. P ERSPECTIVE
0 0.25 0.50 0.75 API vs. human score, with std. error, for annotated sam-
Perspective API score
Figure 3: Human rating distributions vs P ERSPECTIVE ples where the continuation toxicity (Persp.) is > 0.75.
API scores for the standard LM. Bars are labelled with Note that annotated samples will differ from the over-
the number of human ratings in each bin. all RTP distribution due to the upsampling procedure
described in the Methodology part of Section 6.
S URE annotations, map N OT T OXIC to 0.0 and
both T OXIC and V ERY T OXIC to 1.0, and take the
average.8 We weigh the annotations to compensate
for up-sampling. Detailed human annotation in- False Positives Notably, in the higher toxicity
structions, and a full description of the up-sampling score range we find that the human and P ERSPEC -
setup are given in Appendix E. TIVE API scores differ substantially after LM
detoxification. Figure 4 shows the average P ER -
Results In Figure 2 we present the overall av-
SPECTIVE API vs. average human scores for LM-
erage toxicity scores from human annotations
generated continuations that have a P ERSPECTIVE
vs. those of P ERSPECTIVE API. A central obser-
API score > 0.75. Human annotations indicate
vation is that the various LM toxicity reduction
that far fewer samples are toxic than the automatic
methods indeed result in improvements in toxicity
score might suggest, and this effect is stronger as
ratings according to human judgement, and there
intervention strength increases, or when multiple
is furthermore a direct and largely monotonic rela-
methods are combined. That is, after the appli-
tion between average human and classifier-based
cation of strong toxicity reduction measures, the
results. Next, in Figure 3, we show the alignment of
majority of samples predicted as likely toxic are
P ERSPECTIVE API scores with human ratings for
false positives. Several such examples are shown
samples of the standard LM. As expected (cf. foot-
in Tables 13 and 14 in the appendix.
note 5), the scores are correlated with the probabil-
ity that humans mark a sample toxic.
Manual inspection reveals that identity term men-
Annotation Quality Measuring agreement be- tions are disproportionately frequent false positives.
tween raters, we find a Krippendorff’s alpha score For example, we observe that 30.2% of the train-
of 0.49 for the standard LM, and of 0.48 for all filter@0.05 LM generations with a toxicity score
annotations across LMs. To calculate these, we above 0.5 mention the word gay, when generating
map the N OT T OXIC label to 0.0, N OT S URE to continuations based on R EALT OXICITY P ROMPTS
0.5, T OXIC and V ERY T OXIC to 1.0, using abso- prompts (see Appendix G.1 for additional analysis).
lute differences between these as distance func- A reliance on automatic metrics alone, like those
tion. Overall, very few cases were labeled as N OT used by Gehman et al. (2020), could thus lead to
S URE (about 1%). The score indicates fair overall potentially misleading interpretations. As we will
agreement, and is comparable to the level of agree- see in the following Sections 7 and 8, detoxifica-
ment reported in prior work (Ross et al., 2016; tion measures can result in a higher LM loss and
Wulczyn et al., 2017). We note that toxicity rat- amplified social biases. It is unclear whether fur-
ing has subjective aspects, and even with improved ther reductions in the fraction of generated samples
definitions, experts may disagree—for a concrete with high automatic scores would in fact also fur-
list of phenomena for which we observed annotator ther lower toxicity as judged by human annotators,
disagreement we defer to Appendix E.3. or instead only exacerbate the problems incurred
8
We acknowledge that other aggregation options are possi- by applying detoxification measures without pro-
ble, e.g. whether any annotator rates a sample as toxic. viding meaningful reductions in LM toxicity.7 Consequences on LM Quality Model C4 low mid high WT103
standard 1.4B 2.37 2.30 2.43 2.62 2.87
To understand consequences of applying LM toxic-
train-filter@0.2 2.42 2.33 2.49 3.16 2.93
ity interventions, and their potential impact on text
train-filter@0.1 2.48 2.32 2.59 3.28 2.97
generation, we next consider their effect on LM train-filter@0.05 2.66 2.47 2.80 3.52 3.14
loss, text sample quality, and LM toxicity predic-
standard 417M 2.62 2.55 2.68 2.91 3.19
tion ability.
Table 2: Evaluation loss for standard and train-filtered
Effect on Language Modeling Loss Table 2 LMs, across different test sets. Low / mid / high cor-
shows validation losses for several train-filtered respond to [0-.1); [.1-.5); [.5-1] toxicity bins in C4.
models. The first observation is that training set WT103: WikiText103 (Merity et al., 2017).
filtering has a moderate negative impact on LM
loss which increases with stronger filtering. The Previous works have shown that toxicity classi-
train-filter@0.05 model loss roughly matches the fiers often show lower performance for text written
LM loss level of a 417M parameter model (about by, or referring to marginalized identity groups
a third the size), trained on C4 without any inter- (Sap et al., 2019a; Dixon et al., 2018). Given that
ventions. Evaluation on the L AMBADA dataset (Pa- many detoxification techniques heavily rely on tox-
perno et al., 2016) confirms this trend, with an icity classifiers, we investigate how detoxification
accuracy decrease from 50.1% to 34.9% for train- affects topic and dialect coverage with respect to
filter@0.05 (Table 7, appendix). To shed more light different identity groups. We also discuss poten-
on the origins of deteriorated LM performance, we tial representational harms (Barocas et al., 2017)
note that LM loss increase is particularly strong for which can arise from disparities in the effectiveness
text labeled as toxic by P ERSPECTIVE API. For ex- of LM toxicity mitigation across different dialects.
ample, the loss on evaluation documents least likely
to be toxic (score < 0.1) increases by 0.17 (+7%) Datasets We use the gender and ethnicity do-
with the train-filter@0.05 intervention, whereas it mains in the BOLD dataset (Dhamala et al., 2021)
increases by 0.9 (+34%) for the evaluation docu- to evaluate topic coverage. The former contains
ments most likely to be toxic (score ≥ 0.5). Wikipedia sentences about female and male ac-
Text Quality We do not observe any strong differ- tors. Similarly, the latter domain contains sentences
ences for the different toxicity reduction interven- about people with different ethnic backgrounds.
tions compared to the standard LM in how com- We evaluate dialectal coverage using the T WITTER -
prehensible, how grammatical, and how consistent AAE dataset introduced by Blodgett et al. (2016),
with the prompt the generated continuations are: where we use tweets from African-American En-
differences to the standard LM are no larger than glish (AAE) and White Aligned English (WAE)
1%, 4%, and 1%, respectively (Table 10, appendix). subsets. We hope that future work can also con-
Effect on LM’s Ability to Detect Toxicity sider a broader array of groups, including unob-
When training on a toxicity-filtered LM corpus served (Tomasev et al., 2021) and flexible (Andrus
(threshold 0.05), we notice a modest drop in the F1 - et al., 2021) categories. Further dataset details are
score (to 0.73; -0.05 points) of the PPLM toxicity in Appendix B.1.
classifier, which is trained on the LM’s represen-
tations. This could potentially negatively impact 8.1 Topic-related Biases
self-debiasing strategies (Schick et al., 2020). We investigate the effects of toxicity reduction on
the LM’s topic coverage, i.e. its ability to model
8 Social Bias Amplification text about various identity groups. Figure 5 shows
Fairness with respect to all identity groups is cru- that train-time filtering – while generally leading
cial if LMs are to be used in the real world. Two to increased loss – indeed has a disparate impact
properties, that we highlight as necessary (but in- on topic coverage when measured via loss gaps
sufficient) for fairness are that LMs should both be relative to a standard LM on the same documents.
able to model text about topics related to different This holds for both gender (Figure 5a) and ethnic
identity groups (i.e. topic coverage), and also text (Figure 5b) groups. While the standard model has
by people from different identity groups and with similar loss for text about female and male actors
different dialects (i.e. dialect coverage). (3.414 vs. 3.412), detoxification introduces gender(a) Gender (b) Ethnicity (c) Demographic dialect
Figure 5: LM loss gap between a standard LM and the train-filter@X LMs (denoted as tf@X), on different subsets
of BOLD (gender and ethnicity) and T WITTER AAE (demographic dialects). Some subsets already have substan-
tially higher loss under a standard LM; we calculate the loss gap in order to avoid this as a potential confounding
factor. While toxicity reduction increases loss on all subsets, the impact is largest for marginalized groups.
bias, leading to larger LM loss for female actors Exp. Max. Toxicity Prob. of Toxicity
Model AAE WAE AAE WAE
relative to male actors. Similarly, we observe that
LM loss deterioration is stronger for marginalized standard 0.66 0.58 0.72 0.59
train-filter@0.05 0.39 0.34 0.22 0.14
ethnic groups compared to European-Americans.
Although the standard LM has the lowest loss for Table 3: Expected Maximum Toxicity and Probability
Hispanic-American-related text (3.46 vs. 3.68 for of Toxicity for a standard LM and a train-filter@0.05
European-American), Hispanic-American sees the model, as in Table 1, with T WITTER AAE tweets as
largest negative impact of detoxification. This indi- prompts.
cates that detoxification techniques may introduce
biases distinct from those already existing in LMs.
LM Toxicity Reduction with Prompts from Dif-
ferent Dialects Next we measure the effective-
8.2 Dialect-related Biases ness of LM detoxification for prompts in different
Disparate Positive Rates for Tweets Based on dialects, using the T WITTER AAE tweets in AAE
Demographic Dialect Besides lexical biases, and WAE to prompt the LM. We first apply the auto-
toxicity classifiers have also been shown to exhibit matic metrics from Section 5 to the LM-generated
dialectal biases (Sap et al., 2019a). Our analysis continuations, as shown in Table 3. This shows
shows that T WITTER AAE tweets are more likely to substantially higher values for AAE prompts than
be classified as toxic (details in Appendix G.2), con- for WAE under the standard LM (e.g. 0.72 vs. 0.59
gruent with prior work (Zhou et al., 2021), demon- Probability of Toxicity). LM detoxification reduces
strating bias against AAE in toxicity classifiers. automatic toxicity metrics in both dialects, but av-
This suggests that toxicity reduction interventions erage LM toxicity scores remain still substantially
might adversely affect dialectical coverage. Inves- higher for AAE prompts after detoxification (e.g.
tigating this further, we next analyze impacts on 0.22 vs. 0.14 Probability of Toxicity).
a LM’s ability to model language from different Turning to human evaluation, we collect 100
demographic dialects. samples for each setting (model × dialect), follow-
ing the evaluation protocol in Section 6. Table 4
Disparate Impacts on Dialect Coverage Fig- shows that the train-filter@0.05 LM also reduces
ure 5c shows relative loss gaps between the detox- average human toxicity scores, in particular for
ified and the standard models, for both AAE and AAE. In contrast to what automatic evaluation may
WAE tweets. Consistent with Xu et al. (2021), suggest, in this human evaluation we find similar
we find that detoxification has larger impact on levels of toxicity between the dialects, underscor-
AAE coverage than for WAE. We note that AAE ing the limitations of using automatic evaluation
tweets already have substantially higher loss under alone.
a standard LM (5.53 vs. 4.77), which is likely a
result of the underrepresentation (0.07% of all doc- 8.3 Limitations of Likelihood for Bias
uments) of AAE in C4, as highlighted by Dodge Evaluation
et al. (2021). This bias is further amplified with Our above evaluations on LM coverage primarily
detoxification. rely on likelihood-based loss metrics. However it isModel AAE WAE defining sub-types of toxicity, and including sep-
standard 0.110.04 0.100.02 arate test sets for each sub-type. We have further
train-filter@0.05 0.020.03 0.040.04 identified a transfer of toxicity classifier bias onto
Table 4: Average human toxicity scores for model com- LMs, which supports the importance of debias-
pletions of AAE and WAE prompts from T WITTER - ing toxicity classifiers. Based on our results, we
AAE. Standard errors are given as subscripts. additionally highlight the following challenges in
mitigating toxic language in LMs.
worth noting that such an evaluation can potentially First, toxicity is subjective and context depen-
underestimate existing LM bias. dent – what is considered toxic may differ across
For instance, consider the loss gap on the BOLD cultures, social groups, and personal experiences.
dataset incurred by a test-time filtering variant Though existing methods can effectively optimize
which picks the best of K generated samples. automatic toxicity scores, precisely defining what
While the small and similar loss gaps – between we should measure is an open challenge. Ulti-
0.09 and 0.13 across all groups (see Table 11 in mately, this will be dependent on users and ap-
Appendix H) – suggests a minimal impact on topic plications, and requires cross-disciplinary expertise
coverage, it is worth noting that even for highly and input from a broad variety of groups.
biased classifiers, e.g. a classifier which flags any Secondly, very low automatic toxicity metrics of
text mentioning female actors as toxic, the impact state-of-the-art LMs after application of the evalu-
on loss-per-token is tightly bounded based on the ated mitigation techniques suggest that further im-
following observation: provement with respect to these metrics is limited.
Observation 1 (Informal). Irrespective of the clas- It is unclear if further optimization against auto-
sifier used for filtering, test-time filtering with a matic toxicity metrics will lead to improvements in
minimum acceptance rate of will never increase toxicity as judged by humans, or only intensify un-
loss-per-token by more than −n−1 ln , where n is intended and problematic side effects of automatic
the document length. detoxification. We also point out limitations in col-
lecting human ratings, including potential negative
The formal statement and proof are included in
psychological impact on annotators.
Appendix H. Thus, LMs with low loss can still have
bad samples, including effects concentrated on par- Finally, our detoxification increases LM loss,
ticular topics and dialects. Although this example and introduces and amplifies social biases in topic
refers specifically to test-time filtering, similar un- and dialect coverage, potentially leading to de-
derlying concerns also apply to other filtering tech- creased LM performance for marginalized groups.
niques, including train-time filtering, fine-tuning, We note that although this problem exists in current
or PPLM. Similar observations have been made pre- methods, this tradeoff is not necessarily unavoid-
viously (van den Oord and Dambre, 2015); we add able, particularly if future work enables less biased
that these limitations become particularly salient classifiers. Alongside toxicity, future work should
when using filtering-based techniques. consider other metrics, such as loss gaps for dif-
ferent topics and dialects. As noted in Section 8.3,
We thus recommend caution in interpreting
loss gaps are an imperfect metric; future work on
likelihood-based metrics: while large loss gaps
developing quantitative metrics for LM bias could
can demonstrate high bias, small loss gaps do not
help better understand trade-offs in mitigating toxi-
automatically imply low bias.
city.
9 Conclusion
10 Ethical Considerations
In this work, we have examined and discussed chal-
lenges of LM toxicity evaluation and side-effects of Our goal in this work is to reduce harms from LMs
automatic toxicity mitigation using a combination by better understanding how to detoxify LMs, and
of relatively simple toxicity reduction approaches characterizing any trade-offs that occur when detox-
and previously published methods. We have high- ifying LMs. During the course of our research, we
lighted the discrepancy between conventional met- encountered a variety of ethical questions, includ-
rics of toxicity and what is perceived by humans. ing how to ethically collect human annotations for
This points towards a research roadmap of defin- toxic language (detailed in Section 10.1).
ing metrics that better align with perceived toxicity, As discussed in Section 3, toxicity is subjectiveand ill-defined. The definition of what is “toxic” or annotators.
“offensive” may differ between social groups and Because of the sensitive nature of annotating
cultures. Language acceptable to those who wield toxic language, we ensured that several options
more privilege may be offensive to those who wield were available to annotators. Annotators could
less privilege. While our current methods might choose to split their time between our task and
mitigate toxicity as defined by some people, it may other tasks which did not include toxic content.
not be sufficient for others. Annotators were given the option to (and did) opt
In this work, we only consider English LMs, out of annotating data for our task. Annotators self-
though there are over 7, 000 languages spoken determined the amount of time they annotated our
throughout the world (Joshi et al., 2020), and we data and had access to employee resources for well-
recommend caution when generalizing our find- being concerns caused by our annotation task. We
ings to non-English LMs. We note that the P ER - tracked well-being via a well-being survey. Results
SPECTIVE API includes toxicity classifiers for six of this survey are detailed in Appendix E.4.
languages besides English,9 though we do not at- We acknowledge that our annotation instructions
tempt to mitigate toxicity on non-English LMs with do not include race and dialect priming as intro-
non-English classifiers here. However, ethical de- duced by Sap et al. (2019a) to mitigate racial bias
ployment of LMs requires equitable access and in hate speech annotations. Thus some of our an-
safety also for non-English speakers. notators may be unaware that identity groups and
In considering the potential harms of LMs there specifically African-Americans reclaim offensive
are many more facets than we have considered in and racist terms and use them safely. However, we
this paper. Here we discuss one important dimen- annotate LM continuations, not human written lan-
sion, but other potential harms have been discussed guage. As LMs do not have an identity, we do not
in prior work, such as, but not limited to, statistical believe it is safe for generated language to include
biases (Sheng et al., 2019; Huang et al., 2020; Abid reclaimed terms, even if they can be safely used by
et al., 2021), privacy concerns (Carlini et al., 2020), members of marginalized groups. We acknowledge
and environmental impact (Strubell et al., 2019), that there are applications for which this approach
alongside points raised by Bender et al. (2021), would be incorrect.
which should also be considered when striving for
ethical LMs. 11 Acknowledgements
10.1 Human Evaluation We would like to thank James Besley, Phil Blun-
som, Taylan Cemgil, Sanah Choudhry, Iason
Asking humans to annotate toxicity necessarily ex- Gabriel, Geoffrey Irving, Maribeth Rauh, Sebas-
poses them to toxic language. Before conduct- tian Ruder, and Laura Weidinger for comments and
ing our study, it was reviewed by DeepMind’s discussion on earlier versions of this draft, as well
Human Behavioural Research Ethics Commit- as Lucy Vasserman and Jeffrey Sorensen for provid-
tee (HuBREC). ing support on using P ERSPECTIVE API. We have
Participants were recruited through Google’s in- shared the findings of this work with the Jigsaw
ternal labeling platform, a service that hires con- team.
tractors to complete tasks. Annotators are hired
to perform a variety of annotation tasks and are
paid based on time worked, not per HITs com- References
pleted. We design our human evaluation experi- Abubakar Abid, Maheen Farooqi, and James Zou.
ments, then work with the annotation platform to 2021. Persistent anti-Muslim bias in large language
ensure annotators understand the task. Annotator models. CoRR, abs/2101.05783.
training (including a module on wellbeing) takes
McKane Andrus, Elena Spitzer, Jeffrey Brown, and Al-
approximately one hour. Uncertainty in the task is ice Xiang. 2021. What we can’t measure, we can’t
directly communicated to us (the researchers). In understand: Challenges to demographic data pro-
our initial annotation pilot, the authors also anno- curement in the pursuit of fairness. In Proceedings
tated sentences and observed similar trends to the of the 2021 ACM Conference on Fairness, Account-
ability, and Transparency, pages 249–260.
9
When considering production level for the TOXICITY
attribute: https://developers.perspectiveapi.com/s/about-the- Solon Barocas, Kate Crawford, Aaron Shapiro, and
api-attributes-and-languages Hanna Wallach. 2017. The problem with bias:from allocative to representational harms in machine In International Conference on Learning Represen-
learning. special interest group for computing. Infor- tations.
mation and Society (SIGCIS), 2.
Thomas Davidson, Debasmita Bhattacharya, and Ing-
Emily M. Bender, Timnit Gebru, Angelina McMillan- mar Weber. 2019. Racial bias in hate speech and
Major, and Shmargaret Shmitchell. 2021. On the abusive language detection datasets. In Proceedings
dangers of stochastic parrots: Can language models of the Third Workshop on Abusive Language Online,
be too big? In Proceedings of the 2021 ACM Confer- pages 25–35, Florence, Italy. Association for Com-
ence on Fairness, Accountability, and Transparency, putational Linguistics.
FAccT ’21, page 610–623, New York, NY, USA. As-
sociation for Computing Machinery. Thomas Davidson, Dana Warmsley, M. Macy, and Ing-
mar Weber. 2017. Automated hate speech detection
Su Lin Blodgett, Lisa Green, and Brendan O’Connor. and the problem of offensive language. In ICWSM.
2016. Demographic dialectal variation in social
media: A case study of African-American English. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
In Proceedings of the 2016 Conference on Empiri- Kristina Toutanova. 2019. BERT: Pre-training of
cal Methods in Natural Language Processing, pages deep bidirectional transformers for language under-
1119–1130, Austin, Texas. Association for Compu- standing. In Proceedings of the 2019 Conference
tational Linguistics. of the North American Chapter of the Association
for Computational Linguistics: Human Language
Shikha Bordia and Samuel R Bowman. 2019. Identify- Technologies, Volume 1 (Long and Short Papers),
ing and reducing gender bias in word-level language pages 4171–4186, Minneapolis, Minnesota. Associ-
models. arXiv preprint arXiv:1904.03035. ation for Computational Linguistics.
Daniel Borkan, Lucas Dixon, Jeffrey Sorensen, Nithum Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya
Thain, and Lucy Vasserman. 2019. Nuanced metrics Krishna, Yada Pruksachatkun, Kai-Wei Chang, and
for measuring unintended bias with real data for text Rahul Gupta. 2021. BOLD: Dataset and metrics
classification. CoRR, abs/1903.04561. for measuring biases in open-ended language gen-
eration. In Proceedings of the 2021 ACM Confer-
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie ence on Fairness, Accountability, and Transparency,
Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind FAccT ’21, page 862–872, New York, NY, USA. As-
Neelakantan, Pranav Shyam, Girish Sastry, Amanda sociation for Computing Machinery.
Askell, Sandhini Agarwal, Ariel Herbert-Voss,
Gretchen Krueger, Tom Henighan, Rewon Child, Lucas Dixon, John Li, Jeffrey Sorensen, Nithum Thain,
Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, and Lucy Vasserman. 2018. Measuring and mitigat-
Clemens Winter, Christopher Hesse, Mark Chen, ing unintended bias in text classification. In Pro-
Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin ceedings of the 2018 AAAI/ACM Conference on AI,
Chess, Jack Clark, Christopher Berner, Sam Mc- Ethics, and Society, AIES ’18, page 67–73.
Candlish, Alec Radford, Ilya Sutskever, and Dario
Amodei. 2020. Language models are few-shot learn- Jesse Dodge, Maarten Sap, Ana Marasovic, William
ers. Agnew, Gabriel Ilharco, Dirk Groeneveld, and
Matt Gardner. 2021. Documenting the English
Nicholas Carlini, Florian Tramer, Eric Wallace, colossal clean crawled corpus. arXiv preprint
Matthew Jagielski, Ariel Herbert-Voss, Katherine arXiv:2104.08758.
Lee, Adam Roberts, Tom Brown, Dawn Song, Ul-
far Erlingsson, et al. 2020. Extracting training Samuel Gehman, Suchin Gururangan, Maarten Sap,
data from large language models. arXiv preprint Yejin Choi, and Noah A. Smith. 2020. RealToxi-
arXiv:2012.07805. cityPrompts: Evaluating neural toxic degeneration
in language models. In Findings of the Association
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Car- for Computational Linguistics: EMNLP 2020, pages
bonell, Quoc Le, and Ruslan Salakhutdinov. 2019. 3356–3369, Online. Association for Computational
Transformer-XL: Attentive language models beyond Linguistics.
a fixed-length context. In Proceedings of the 57th
Annual Meeting of the Association for Computa- Suchin Gururangan, Ana Marasović, Swabha
tional Linguistics, pages 2978–2988, Florence, Italy. Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey,
Association for Computational Linguistics. and Noah A. Smith. 2020. Don’t stop pretraining:
Adapt language models to domains and tasks. In
Brandon Dang, Martin J Riedl, and Matthew Lease. Proceedings of the 58th Annual Meeting of the
2018. But who protects the moderators? the case Association for Computational Linguistics, pages
of crowdsourced image moderation. arXiv preprint 8342–8360, Online. Association for Computational
arXiv:1804.10999. Linguistics.
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and
Hung, Eric Frank, Piero Molino, Jason Yosinski, and Yejin Choi. 2020. The curious case of neural text de-
Rosanne Liu. 2020. Plug and play language mod- generation. In International Conference on Learn-
els: A simple approach to controlled text generation. ing Representations.Po-Sen Huang, Huan Zhang, Ray Jiang, Robert Stan- Cicero Nogueira dos Santos, Igor Melnyk, and Inkit
forth, Johannes Welbl, Jack Rae, Vishal Maini, Dani Padhi. 2018. Fighting offensive language on social
Yogatama, and Pushmeet Kohli. 2020. Reducing media with unsupervised text style transfer. In Pro-
sentiment bias in language models via counterfac- ceedings of the 56th Annual Meeting of the Associa-
tual evaluation. In Findings of the Association for tion for Computational Linguistics (Volume 2: Short
Computational Linguistics: EMNLP 2020, pages Papers), pages 189–194, Melbourne, Australia. As-
65–83, Online. Association for Computational Lin- sociation for Computational Linguistics.
guistics.
Denis Paperno, Germán Kruszewski, Angeliki Lazari-
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika dou, Ngoc Quan Pham, Raffaella Bernardi, San-
Bali, and Monojit Choudhury. 2020. The state and dro Pezzelle, Marco Baroni, Gemma Boleda, and
fate of linguistic diversity and inclusion in the NLP Raquel Fernández. 2016. The LAMBADA dataset:
world. arXiv preprint arXiv:2004.09095. Word prediction requiring a broad discourse context.
In Proceedings of the 54th Annual Meeting of the As-
Muhammad Khalifa, Hady Elsahar, and Marc Dymet- sociation for Computational Linguistics (Volume 1:
man. 2020. A distributional approach to controlled Long Papers), pages 1525–1534, Berlin, Germany.
text generation. CoRR, abs/2012.11635. Association for Computational Linguistics.
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A
method for stochastic optimization. In 3rd Inter- Ji Ho Park, Jamin Shin, and Pascale Fung. 2018. Re-
national Conference on Learning Representations, ducing gender bias in abusive language detection.
ICLR 2015, San Diego, CA, USA, May 7-9, 2015, In Proceedings of the 2018 Conference on Em-
Conference Track Proceedings. pirical Methods in Natural Language Processing,
pages 2799–2804, Brussels, Belgium. Association
Ben Krause, Akhilesh Deepak Gotmare, Bryan Mc- for Computational Linguistics.
Cann, Nitish Shirish Keskar, Shafiq Joty, Richard
Socher, and Nazneen Rajani. 2021. GeDi: Gener- Alec Radford, Jeffrey Wu, Rewon Child, David Luan,
ative discriminator guided sequence generation. Dario Amodei, and Ilya Sutskever. 2019. Language
models are unsupervised multitask learners. OpenAI
Taku Kudo and John Richardson. 2018. SentencePiece: blog, 1(8):9.
A simple and language independent subword tok-
enizer and detokenizer for neural text processing. In Colin Raffel, Noam Shazeer, Adam Roberts, Kather-
Proceedings of the 2018 Conference on Empirical ine Lee, Sharan Narang, Michael Matena, Yanqi
Methods in Natural Language Processing: System Zhou, Wei Li, and Peter J. Liu. 2020. Exploring
Demonstrations, pages 66–71, Brussels, Belgium. the limits of transfer learning with a unified text-to-
Association for Computational Linguistics. text transformer. Journal of Machine Learning Re-
search, 21(140):1–67.
Irene Kwok and Y. Wang. 2013. Locate the hate: De-
tecting tweets against blacks. In AAAI. Björn Ross, Michael Rist, Guillermo Carbonell, Ben
Cabrera, Nils Kurowsky, and Michael Wojatzki.
Léo Laugier, John Pavlopoulos, Jeffrey Sorensen, and 2016. Measuring the Reliability of Hate Speech An-
Lucas Dixon. 2021. Civil rephrases of toxic texts notations: The Case of the European Refugee Cri-
with self-supervised transformers. In Proceedings of sis. In Proceedings of NLP4CMC III: 3rd Workshop
the 16th Conference of the European Chapter of the on Natural Language Processing for Computer-
Association for Computational Linguistics: Main Mediated Communication, pages 6–9.
Volume, pages 1442–1461, Online. Association for
Computational Linguistics. Maarten Sap, Dallas Card, Saadia Gabriel, Yejin Choi,
and Noah A. Smith. 2019a. The risk of racial bias
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, in hate speech detection. In Proceedings of the
and Bill Dolan. 2015. A diversity-promoting objec- 57th Annual Meeting of the Association for Com-
tive function for neural conversation models. CoRR, putational Linguistics, pages 1668–1678, Florence,
abs/1510.03055. Italy. Association for Computational Linguistics.
Andrea Madotto, Etsuko Ishii, Zhaojiang Lin, Sumanth
Dathathri, and Pascale Fung. 2020. Plug-and-play Maarten Sap, Saadia Gabriel, Lianhui Qin, Dan Ju-
conversational models. CoRR, abs/2010.04344. rafsky, Noah A Smith, and Yejin Choi. 2019b.
Social bias frames: Reasoning about social and
Stephen Merity, Caiming Xiong, James Bradbury, and power implications of language. arXiv preprint
Richard Socher. 2016. Pointer sentinel mixture mod- arXiv:1911.03891.
els. arXiv preprint arXiv:1609.07843.
Timo Schick, Helmut Schmid, and Hinrich Schütze.
Stephen Merity, Caiming Xiong, James Bradbury, and 2020. Automatically identifying words that can
Richard Socher. 2017. Pointer sentinel mixture mod- serve as labels for few-shot text classification. In
els. In 5th International Conference on Learning Proceedings of the 28th International Conference
Representations, ICLR 2017, Toulon, France, April on Computational Linguistics, pages 5569–5578,
24-26, 2017, Conference Track Proceedings. Open- Barcelona, Spain (Online). International Committee
Review.net. on Computational Linguistics.Timo Schick, Sahana Udupa, and Hinrich Schütze. Ellery Wulczyn, Nithum Thain, and Lucas Dixon. 2017.
2021. Self-diagnosis and self-debiasing: A proposal Ex machina: Personal attacks seen at scale. In Pro-
for reducing corpus-based bias in NLP. ceedings of the 26th International Conference on
World Wide Web, pages 1391–1399.
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan,
and Nanyun Peng. 2019. The woman worked as Albert Xu, Eshaan Pathak, Eric Wallace, Suchin Guru-
a babysitter: On biases in language generation. In rangan, Maarten Sap, and Dan Klein. 2021. Detoxi-
Proceedings of the 2019 Conference on Empirical fying language models risks marginalizing minority
Methods in Natural Language Processing and the voices.
9th International Joint Conference on Natural Lan-
guage Processing (EMNLP-IJCNLP), pages 3407– Jing Xu, Da Ju, Margaret Li, Y-Lan Boureau, Jason
3412, Hong Kong, China. Association for Computa- Weston, and Emily Dinan. 2020. Recipes for safety
tional Linguistics. in open-domain chatbots.
Miriah Steiger, Timir J Bharucha, Sukrit Venkatagiri, Marcos Zampieri, Shervin Malmasi, Preslav Nakov,
Martin J Riedl, and Matthew Lease. 2021. The psy- Sara Rosenthal, Noura Farra, and Ritesh Kumar.
chological well-being of content moderators. In Pro- 2019. SemEval-2019 task 6: Identifying and catego-
ceedings of the 2021 CHI Conference on Human rizing offensive language in social media (OffensE-
Factors in Computing Systems, CHI, volume 21. val). In Proceedings of the 13th International Work-
shop on Semantic Evaluation, pages 75–86, Min-
Emma Strubell, Ananya Ganesh, and Andrew Mc- neapolis, Minnesota, USA. Association for Compu-
Callum. 2019. Energy and policy considera- tational Linguistics.
tions for deep learning in NLP. arXiv preprint
arXiv:1906.02243. Xuhui Zhou, Maarten Sap, Swabha Swayamdipta,
Yejin Choi, and Noah Smith. 2021. Challenges in au-
Lucas Theis, Aäron van den Oord, and Matthias tomated debiasing for toxic language detection. In
Bethge. 2015. A note on the evaluation of genera- Proceedings of the 16th Conference of the European
tive models. arXiv preprint arXiv:1511.01844. Chapter of the Association for Computational Lin-
guistics: Main Volume, pages 3143–3155, Online.
J. Thomas. 1983. Cross-cultural pragmatic failure. Ap- Association for Computational Linguistics.
plied Linguistics, 4:91–112.
Nenad Tomasev, Kevin R McKee, Jackie Kay, and
Shakir Mohamed. 2021. Fairness for unobserved
characteristics: Insights from technological im-
pacts on queer communities. arXiv preprint
arXiv:2102.04257.
Aäron van den Oord and Joni Dambre. 2015. Locally-
connected transformations for deep GMMs. In Inter-
national Conference on Machine Learning (ICML):
Deep learning Workshop, pages 1–8.
Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner,
and Sameer Singh. 2019. Universal adversarial trig-
gers for attacking and analyzing NLP. In Proceed-
ings of the 2019 Conference on Empirical Methods
in Natural Language Processing and the 9th Inter-
national Joint Conference on Natural Language Pro-
cessing (EMNLP-IJCNLP), pages 2153–2162, Hong
Kong, China. Association for Computational Lin-
guistics.
William Warner and Julia Hirschberg. 2012. Detecting
hate speech on the world wide web. In Proceedings
of the Second Workshop on Language in Social Me-
dia, pages 19–26, Montréal, Canada. Association for
Computational Linguistics.
Zeerak Waseem and Dirk Hovy. 2016. Hateful sym-
bols or hateful people? predictive features for hate
speech detection on Twitter. In Proceedings of the
NAACL Student Research Workshop, pages 88–93,
San Diego, California. Association for Computa-
tional Linguistics.You can also read

















































