Dual-Awareness Attention for Few-Shot Object Detection - arXiv
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 1
Dual-Awareness Attention for
Few-Shot Object Detection
Tung-I Chen1 , Yueh-Cheng Liu1 , Hung-Ting Su1 , Yu-Cheng Chang1 , Yu-Hsiang Lin1 , Jia-Fong Yeh1 ,
Wen-Chin Chen1 , Winston H. Hsu1,2
1 National Taiwan University, 2 Mobile Drive Technology
Abstract—While recent progress has significantly boosted few- techniques such as building category prototypes [9], [10],
arXiv:2102.12152v3 [cs.CV] 16 Sep 2021
shot classification (FSC) performance, few-shot object detection ranking similarity between inputs [11], [3] and feature map
(FSOD) remains challenging for modern learning systems. Ex- concatenation [12], [13] are all widely adopted. However,
isting FSOD systems follow FSC approaches, ignoring critical
issues such as spatial variability and uncertain representations, unlike FSC aiming to classify images, FSOD is a much
and consequently result in low performance. Observing this, we more complicated task requiring to identify and locate ob-
propose a novel Dual-Awareness Attention (DAnA) mechanism jects precisely. In this work, we summarize three potential
that enables networks to adaptively interpret the given support concerns that could restrict the performance of FSOD (see
images. DAnA transforms support images into query-position- Fig. 1). (a) First of all, prior methods [10], [1], [2], [13],
aware (QPA) features, guiding detection networks precisely by
assigning customized support information to each local region of [4], [14] performed global pooling on support features to
the query. In addition, the proposed DAnA component is flexible ensure computational efficiency. However, the lack of spa-
and adaptable to multiple existing object detection frameworks. tial information would cause difficulty in measuring object-
By adopting DAnA, conventional object detection networks, wise correlations. (b) Secondly, convolutional neural networks
Faster R-CNN and RetinaNet, which are not designed explic- (CNN) are physically inefficient at modeling varying spatial
itly for few-shot learning, reach state-of-the-art performance
in FSOD tasks. In comparison with previous methods, our distributions [15], so the methods using convolution-based
model significantly increases the performance by 47% (+6.9 AP), attention [16], [13] would suffer the same restriction. (c)
showing remarkable ability under various evaluation settings. Furthermore, previous works [10], [1], [2], [13], [3], [4]
Index Terms—Deep learning, object detection, visual attention, took mean features across multiple support images as class-
few-shot object detection. specific representations, which heavily relies on an implicit
assumption that the mean features will still be representative
in the embedding space.
I. I NTRODUCTION To verify the aforementioned concerns are worth studying,
Few-shot object detection (FSOD) is a recently emerging we conduct a pilot study with the hypothesis: If the spatial
and rapidly growing research topic, which has great potential information, variability and feature uncertainty are all trivial
in many real-world applications. Unlike conventional object in FSOD, the choice of support images will not severely
detectors, few-shot object detectors can be adapted to novel affect the performance. In the experiment, the four well-trained
domains with only few annotated data, saving the costly data FSOD models are tested on the same query set 100 times but
re-collection and re-training processes whenever the down- the given support images will be different each time. As shown
stream task changes. in Fig. 2, even though we fix the query set, previous methods
However, though considerable effort in recent years has can easily be influenced by the choice of supports, resulting
been devoted, existing FSOD methods [1], [2], [3], [4], [5] in a huge range of performance (up to 4.4 AP). On the other
suffer extremely low performance in comparison with tradi- hand, our method, which solves the concerns summarized in
tional object detectors [6], [7]. In addition, it seems previous Fig. 1, achieves the highest and firmest performance.
methods suffer performance drop not only on the novel domain In this work, we present a novel Dual-Awareness Attention
but also on the base (training) domain [8], [4]. Moreover, (DAnA) mechanism comprised of Background Attenuation
by carrying out experiments, we discovered that previous (BA) and Cross-Image Spatial Attention (CISA) modules.
FSOD models based on Faster R-CNN [6] are incapable of Inspired by wave interference, we propose a BA module where
reaching the performance that Faster R-CNN can achieve when each feature vector (1 × 1 × C) of a high-level feature map
being evaluated on base classes (see Tab. II). Though the (H ×W ×C) is viewed as a wave along the channel dimension.
models have been trained on a lot of annotated data, they By extracting the most representative feature vector from a
still have difficulty in recognizing the objects they have seen. feature map and adding it back to the feature map, those
We therefore assume the modifications associated with few- local features having different wave patterns from the extracted
shot learning applied in prior attempts somehow undermine the feature will be blurred and therefore can be easily recognized
ability of detection networks, resulting in limited performance. as noise by the detection network. Those foreground features,
To recast traditional object detectors into few-shot object on the other hand, can maintain the wave patterns and be
detectors, prior works tend to leverage the methods that have preserved after the addition. Thus, the BA module not only
been proved effective at few-shot classification (FSC). The attenuates irrelevant features but preserves the target informa-
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 2
none head
airscrew none
el
nn
Spatial Information Misalignment
ha
#c
head tail
(a) loss of spatial information due to global pooling (b) spatial misalignment in convolution-based attention
Query Match
(image to be tested)
airplane
airplane
Feature Fusion
average
Support Set
Prediction
(few examples) Uncertainty
(c) uncertain class representations caused by average pooling
Fig. 1: Illustration of few-shot object detection and the concerns in previous methods (a-c). (a) Previous works seek
computational efficiency by encoding support images into global feature vectors, causing the loss of spatial and local
information. (b) The convolution-based attention has difficulty in modeling relationships across objects with varying spatial
distributions. (c) Performing average pooling across multiple high-level features might cause uncertainty in the resulting feature
representation.
tion as well. capture object-wise correlations.
To determine whether two objects belong to the same class, • We conduct comprehensive experiments to fairly assess
a person might first determine the most representative features each approach. Extensive experiments manifest the effec-
among objects (e.g., dog paws, bird wings) and then make his tiveness and robustness of the proposed methodology.
decision according to these features. Inspired by such a nature,
we propose CISA to adaptively transform support images II. R ELATED W ORKS
into various query-position-aware (QPA) vectors. To be more A. Few-Shot Classification
specific, each QPA vector carries specific support information Few-shot classification (FSC) has multiple branches, includ-
that is considered the most relevant to each local query region. ing the optimization-based and metric-based approaches. The
By measuring correlations between the query regions and their optimization-based methods [18], [19], [20], [21], [22] aim to
corresponding QPA vectors, the model can easily determine learn a good initialization parameter set that can swiftly be
whether the regions should be the parts of the target object. adapted to new tasks within few gradient steps. The metric-
Also, CISA provides a more efficient and effective way to based methods [11], [23], [9], [12], [24], [25], on the other
summarize information among multiple support images. Those hand, compute the distance between learned representations
QPA vectors conditioned on the same query region would in the embedding space. The concept of prototypical rep-
represent relevant information, and therefore taking the mean resentation [9] is widely adopted in FSC, which takes the
feature across them is more effective than previous manners. mean feature over different support images as a class-specific
By better utilizing support images, our method achieves the embedding. Such a strategy is intuitive yet the data scarcity
most significant improvement as the number of support images in few-shot scenarios might lead to biased prototypes and
increases (see Tab. II). consequently hinder the performance [24]. To enhance the
In this paper, we evaluate models across various settings, in- reliability of class representations, Tian et al. [25] leveraged
cluding the multi-shot, multi-way, cross-domain, and episode- pre-trained embedding and showed that using good represen-
based evaluations. In Tab. I, we show our method significantly tations is more effective than applying sophisticated meta-
outperforms the strongest baseline [17] by 6.9 AP under the learning algorithms. Although the attempts have successfully
30-shot setting. Furthermore, we are the first to test FSOD boosted the performance of FSC, the progress of few-shot
models on novel domains without fine-tuning (Tab. II and object detection (FSOD) is still in a very early stage. In this
Tab. III) to further evaluate the generalization ability of each work, we explore novel attention mechanisms and significantly
method. We also offer a comprehensive ablation study to enhance the performance of FSOD.
demonstrate the impact of each proposed component.
Our main contributions can be summarized as follows: B. Attention Mechanism
• We point out the critical issues in previous FSOD meth- The attention modules were first developed in natural lan-
ods that lead to the limited performance and the lack of guage processing (NLP) to facilitate machine translation [26],
robustness. [27], [28]. Recently, inspired by the great success of Trans-
• We present novel dual-awareness attention to precisely former [29], researchers start to explore the self-attention
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 3
and distance metric learning [10] to achieve quick adaption to
novel domains. As recasting object detection problem into the
few-shot learning paradigm, the idea of current methods could
(a) Support images with noisy backgrounds and various spatial distributions be somewhat similar to multiple-instance learning (MIL) [49],
[50], [51]. For FSOD, we can also perceive a query image as
Test #1 AP
a bag, aiming to identify the positive image patches in it by
capturing the contexts relevant to given support images [49].
Test #2
Recently, there is an important line of works encoding
support images into global vectors, measuring the similarity
Image Pool
between feature vectors and the RoI proposals inferred by
Test #N
detection networks [1], [2]. Following the spirit, [13] perceived
Meta R-CNN FGN Attention RPN Ours
the task as a guided process where support features are used to
Support Set Prediction
guide the object detection networks. Inspired by [16], Fan et
(b) Pilot study of robustness against noise and spatial variability
al. [3] measured the correlations by regarding support images
Fig. 2: Illustration of the pilot study. We carry out an experi- as kernels and performing a convolution-based operation over
ment to test whether the noise and spatial variability of support queries. Current works have a tendency to take mean features
images would seriously influence FSOD results. The standard as class representations and measure cross-image correlations
deviations of AP of the four methods are [0.72, 0.81, 0.68, 0.46] by either feature concatenation or element-wise product [2],
respectively. Our method is effective at capturing object-wise [10], [13], [3]. We argue that these techniques will engender
correlations irrespective of the choice of support images. serious issues (illustrated in Fig. 1) in FSOD, degenerating the
performance even on the seen (training) categories.
mechanism on computer vision (CV) problems [30], [31],
III. M ETHODOLOGY
[32], [33], [15], [34], attempting to break the physical re-
strictions of CNN. Wang et al. [30] presented a pioneering A. Problem Definition
approach, Non-local (NL) Neural Networks, leveraging self-
attention to capture long-range dependencies in an image. Hu Let s be a support image and S = {si }M i=1 be a support
et al. [35] adopted a self-attention function on channels, re- set that represents a specific category. An individual FSOD
weighting features along the channel dimension. Following task can be formulated as T = {(S 1 , ..., S N ), I}, where I
NL, [31] described the features as information flows that can is a query image comprised of multiple instances and back-
be bidirectionally propagated; [33] showed that simplifying grounds. Given T , the model should detect all the objects in
NL block does not deteriorate its ability but rather enhance the I belonging to the target categories {S 1 , ..., S N }. The object
performance; recently, Yin et al. [36] succeeded in capturing categories in a training dataset are divided into two disjoint
better visual clues by proposing a disentangled NL block. parts: base classes C base and novel classes C novel . To train a
|H|
Emami et al. [37] combined spatial attention with GAN to FSOD model, a meta-training set Htrain = {Ti }i=1 should be
handle image-to-image translation tasks. Li et al. [38] explored constructed, where all the bounding box annotations belong to
attention in both spatial and temporal dimensions, improving C base . Similarly, a meta-testing set Htest is constructed where
the performance of video action detection. all the target objects belong to C novel . It is allowed to use a fine-
The main differentiating factor between the proposed DAnA tuning set H f inetune to fine-tune the mdoel before evaluating
and aforementioned attention mechanisms is that DAnA can on Htest . However, in an N-way K-shot setting, only K box
capture cross-image dependencies and interpret support im- annotations of each novel category can be used to fine-tune
ages adaptively according to the given query. It would be the model [10], [1].
plausible that the idea of DAnA can be applied to other To summarize, the primary goal of FSOD is to leverage
research topics aiming to capture shared attributes among rich source-domain knowledge in Htrain to learn a model
images with diverse backgrounds, viewpoints and illumination that can swiftly generalize to target domains where only few
conditions [39], [40], [41], yet in this work we will emphasize annotated data are available. Instead of only considering the
the application in FSOD only. features of I, the model f (I|S) is trained to recognize objects
conditioned on the given support information.
C. Few-Shot Object Detection
B. Dual-Awareness Attention
Deep-learning-based object detectors have shown remark-
able performance in many applications. Two-stage detec- 1) Overview: FSOD relies on limited support information
tors [42], [43], [6], [44] are usually dominant in performance, to detect novel objects, and therefore we consider two im-
and one-stage detectors [7], [45], [46], [47] are superior in run- portant aspects: (1) The quality of support features, and (2)
time efficiency. Most modern object detectors are category- how to better construct correlations between support and query
specific, which means they are incapable of recognizing images. In this work, we propose an attention mechanism
objects of unseen categories. To explore generalized object comprised of two novel modules to undermine the influence
detectors, previous attempts exploited transfer learning [48] of noise and precisely measure object-wise correlations.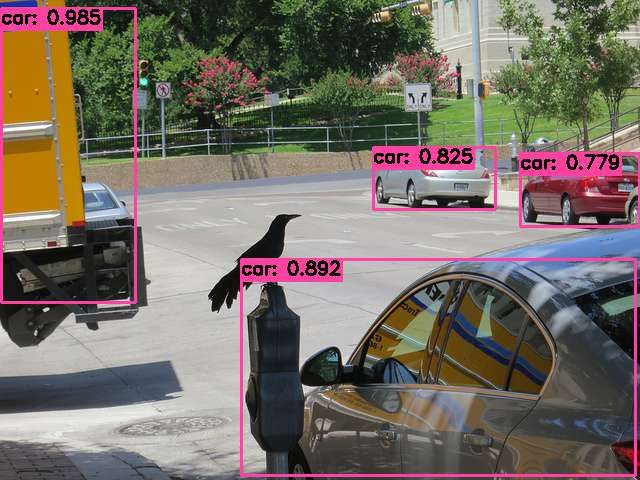
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 4
Attention
1×$%×&%
enhanced
Foreground Features We softmax LeakyReLU
1×!
Extracted Y !×$%×&% Z
Extracted Feature
Support Feature Support
Feature Feature Background Attenuation Block
blurred
Background Features
BA Block
!×$%×&% pi 1 pi 2
Background Attenuation Block
Wr softmax
…
…
weighted
average
Z1 Z2 1×$%&% #$'&'
sum
Support Feature Maps & average !′×$%&%
Attention Maps Wk QPA Vectors
QPA Vectors
Query Feature Map
softmax
average
(Head) Wq attention maps append
!′×$'&' pi
…
(Paw)
CISA Block
X $'&'×$(&%
Cross-Image Spatial Attention Block Cross-Image Spatial Attention Block
Fig. 3: Illustration of our proposed methods. In the BA block, Fig. 4: Detailed structures of the two proposed modules.
the extracted feature is superimposed on the feature map ⊗ denotes matrix multiplication, and ⊕ denotes broadcast
to undermine irrelevant background features while maintain element-wise addition; W denotes a learned weight matrix;
distinguishing information. In the CISA block, support feature Y and X are support and query feature maps respectively; Z 1
maps are adaptively transformed into query-position-aware denotes the 1st feature map in the support set processed after
(QPA) vectors, which are customized support information for the BA block; pi denotes the query-position-aware support
each query region. vector based on the ith pixel of X.
2) Background Attenuation Block: It is infeasible to always Consequently, we propose a much softer attention strategy
ensure high-quality support images in real-world scenarios. to remove noise. In physics, interference is a term indicating
Those noise in support images will inhibit models from reach- two signals superpose to form a resultant signal of greater
ing robustness (see Fig 2). We propose a novel mechanism, or lower amplitudes. Inspired by that, we view each feature
Background Attenuation (BA), to undermine the irrelevant vector of Y as a C-dimensional signal and superimpose the
support information. The detailed structure of BA block is extracted feature G on those signals
illustrated in Fig. 4, where a support image s and a query Z = Y + α · LeakyReLU(G) (3)
image I are encoded into a support feature map Y ∈ RC×HS ×WS
and a query feature map X ∈ RC×HQ ×WQ by a shared CNN where α is a constant hyper-parameter, and the nonlinear
backbone. In BA block, the feature map Y will be reshaped function is used to rectify the results. As illustrated in Fig. 3,
and transformed by a linear learnable matrix We ∈ RC×1 . The if the original signals (e.g., regions belonging to the dog) are
process can be formulated as aligned with G along the channel dimension, the features can
be enhanced or maintained. On the contrary, those signals
exp(We yi ) associated with unrelated regions (e.g., the Frisbee) will be
ABA (yi ) = σ (We yi ) = (1)
∑ j∈Ω exp(We y j ) blurred after addition due to the significant difference with
G. Thus, the BA block can benefit detection networks by
where yi ∈ R1×C denotes the feature vector at ith pixel of providing more discriminative support features. It is worth
Y ; Ω is the set of all pixel indices and σ is the softmax mentioning the idea of BA is different from the channel-
function applied along the spatial dimension. Thus, the learned wise attention [35], [32] which re-weights feature maps along
aggregation of Y can be obtained by the channel dimension. In addition, unlike [33] constructing
heavy linear transformation matrices to rew-eight semantic
G= ∑ ABA (yi ) · yi . (2)
dependencies, BA block is more efficient since We ∈ RC×1
i∈Ω
is the only learnable weights in it.
Intuitively, G ∈ R1×C should represent the most important fea- 3) Cross-Image Spatial Attention Block: Since even the
ture of Y according to the resulting attention maps. However, intra-class objects would have obvious deviation in appear-
we empirically discover that using the learned attention maps ance, the model should learn to focus on those most represen-
to filter out noise would harm the performance (see Tab. VI). tative parts of the objects to determine the similarity among
By visualization, we observe that only few narrow regions of them. The core idea of Cross-Image Spatial Attention (CISA)
support image contribute to the aggregated feature G. Such a is to adaptively transform each support feature map into query-
naive attention process leads to a considerable loss of support position-aware (QPA) support vectors that represent specific
information and therefore deteriorate the ability of models. information of a support image. The first step of CISA is
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 5
10shot 30shot
Method
BA Block AP AP75 AP AP75
TFA w/cos [8] 10.0 9.3 13.7 13.4
support features
CISA Block RPN
RoIAlign
CISA Block
Feature Reweighting [1] 5.6 4.6 9.1 7.6
RoI features Meta R-CNN [2] 8.7 6.6 12.4 10.8
query feature Attention RPN [3] 11.1 10.6 - -
prediction Cls &
Bbox Reg IFSOD [4] 5.1 - - -
DAnA-FasterRCNN
MPSR [5] 9.8 9.7 14.1 14.2
Viewpoint Estimation [17] 12.5 9.8 14.7 12.2
level 4
BA Block4 CISA Block4 level n awareness DAnA-FasterRCNN (Ours) 18.6 17.2 21.6 20.3
BA Block3 CISA Block3
level 3
TABLE I: The performance on novel categories of COCO.
level 4
concatenation
All the models are trained on base categories and then fine-
support feature pyramids level 3
Cls & Bbox Reg
tuned on a small set of novel samples (e.g., 10 shots of each
Cls & Bbox Reg category). After fine-tuning, models will be evaluated on the
Cls & Bbox Reg
DAnA-RetinaNet query feature pyramid
novel classes. “-”: no reported results.
Fig. 5: The model architectures of DAnA-FasterRCNN and
will carry relevant features (resolve Fig. 1 (c)). Furthermore,
DAnA-RetinaNet. Our proposed components are flexible and
it breaks the physical restriction of CNN since all the query
can be easily combined with existing object detection frame-
features are aligned with their customized QPA vectors (re-
works which are not originally designed for FSOD.
solve Fig. 1 (b)).
similar to QKV attention [29], transforming X and Z into the C. Model Architecture
query and key embeddings Q = Wq X, K = Wk Z by learned To apply the DAnA component to existing object detection
0
weight matrices Wq ,Wk ∈ RC×C respectively. The similarity frameworks, we can simply combine the output P ∈ RC×HQ ×WQ
scores between the query and support can then be measured with X into PX ∈ R2C×HQ ×WQ and send it to the modules
by such as the region proposal network (RPN) to propose re-
δ (X, Z) = σ ((Q − µQ )> (K − µK )) (4) gions having high responses with the given supports (see
where µQ and µK are the averaged embedding values over all Fig. 5). In our experiments, we choose Faster R-CNN [6]
pixels; the softmax function σ is performed over the spatial and RetinaNet [7] as the backbones to verify the effectiveness
dimension. Furthermore, we add a simplified self-attention of the DAnA mechanism. For DAnA-FasterRCNN, one CISA
term [33] in CISA because we assume the attention should block is employed before RPN and the other is applied in
be based on not only query-support correlations but also the the second stage taking cropped RoI features as inputs. For
support image itself. Thus, the CISA attention function is DAnA-RetinaNet, we apply both BA and CISA modules to
formulated as each level of the feature pyramids.
In addition, we follow the modification applied in [3],
ACISA (X, Z) = δ (X, Z) + β ·Wr Z (5) replacing the multi-class classification output with the binary
one. Since the pipeline of FSOD can be regarded as a matching
where β is a constant coefficient; Wr ∈ RC×1 . Note that the process based on given supports, we suggest the binary output
output of ACISA (X, Z) has the shape of HQWQ × HSWS , which could better fit the problem scenarios where an instance will
indicates the fact that we have obtained multiple support be either positively or negatively labeled. The rest details of
attention maps (HSWS ) conditioned on each spatial location of the proposed models remain the same as the original Faster
the query feature map (HQWQ ). The QPA vectors can therefore R-CNN and RetinaNet.
be obtained by
pi = ∑ ACISA (X, Z)i j · z j (6) IV. E XPERIMENTS
j∈Ω
A. Implementation Details
where Ω denotes all pixel indices of the support feature map. By default, we employ the pretrained ResNet50 as the
The equation shows that all the vectors of Z are adaptively feature extractor, and the batch size is set to 32 for all
weighted and aggregated into a vector pi ∈ R1×C according the experiments. All the models including baselines were
to each query position i (resolve Fig. 1 (a)). Additionally, if implemented in Pytorch [52] on a workstation with 4 NVIDIA
there are K-shot images available in a support set {s}K , we Tesla V100. The shorter side of query images is resized to
can perform average pooling across the resulting QPA vectors 600 pixels, while the longer side is cropped at 1000. Each
1 K support image will be zero-padded and then resized to a square
pi = ∑ pi,k (7) image of 320 × 320. The embedding dimension C0 in the
K k=1
weight matrices Wq and Wk is a quarter of the number of
without the concern of uncertainty, because those QPA vectors original feature channels C. The constant coefficients α and β
pi,k conditioned on the same entry i have been refined and of the proposed modules are 0.5 and 0.1 individually. For those
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 6
Novel Categories Base Categories
Method # parameters FPS
AP AP50 AP75 AP AP50 AP75
Faster R-CNN† [6] N/A N/A N/A 34.3 58.3 35.6 4.76 × 107 31
# Way 1way 1way 1way 1way 1way 1way
# Given Supports 1shot 3shot 5shot 1shot 3shot 5shot 1shot 3shot 5shot 1shot 3shot 5shot 1shot 3shot 5shot 1shot 3shot 5shot
Meta R-CNN† [2] 8.7 11.1 11.2 19.9 25.3 25.9 6.8 8.5 8.6 27.3 28.6 28.5 50.4 52.5 52.3 27.3 28.4 28.2 4.76 × 107 28
FGN† [13] 8.0 10.5 10.9 17.3 22.5 24.0 6.9 8.8 9.0 24.7 25.5 26.9 44.3 46.4 47.6 25.0 25.5 27.4 1.48 × 108 23
Attention RPN† [3] 8.7 10.1 10.6 19.8 23.0 24.4 7.0 8.2 8.3 20.6 22.4 23.0 37.2 40.8 42.0 20.5 22.2 22.4 1.03 × 108 21
DAnA-FasterRCNN 11.9 14.0 14.4 25.6 28.9 30.4 10.4 12.3 13.0 27.8 29.4 32.0 46.3 50.6 54.1 27.7 30.3 32.9 1.42 × 108 24
TABLE II: The 1-way, zero-shot evaluation on COCO. All the few-shot models are trained on base categories and then tested
on novel domains without fine-tuning. Note that the performance of Faster R-CNN [6] on base classes can serve as the upper
bound because all the methods in this table leverage [6] as their backbone detector. In comparison with baselines, the relative
mAP improvement of our method is up to 49% on novel categories, and the performance gap with the traditional object detector
has been reduced. The model size and inference speed are reported as well. † : re-implemented results.
Novel Categories Base Categories
Method
AP AP50 AP75 AP AP50 AP75
# Way 1way 3way 5way 1way 3way 5way 1way 3way 5way 1way 3way 5way 1way 3way 5way 1way 3way 5way
# Given Supports 5shot 5shot 5shot 5shot 5shot 5shot
Meta R-CNN† [2] 11.2 11.0 10.2 25.9 25.2 23.4 8.6 8.6 8.0 28.5 27.4 26.2 52.3 50.8 48.7 28.2 26.8 25.7
FGN† [13] 10.9 10.8 9.6 24.0 23.4 21.2 9.0 9.1 8.1 26.9 25.1 23.6 47.6 45.4 42.4 27.4 25.3 23.8
Attention RPN† [3] 10.6 9.8 9.0 24.4 22.8 20.8 8.3 7.9 7.3 23.0 21.3 20.2 42.0 39.8 37.7 22.4 20.6 19.7
DAnA-FasterRCNN 14.4 13.7 12.6 30.4 28.2 25.9 13.0 12.4 11.3 32.0 31.0 29.5 54.1 52.2 49.9 32.9 31.7 30.3
TABLE III: The multi-way, zero-shot evaluation on COCO. Under the N-way setting, we introduce a support set comprised
of N categories to the model and therefore the model should detect the objects belonging to any of these N categories.
Fig. 6: Visualization of the AP on each base (training) category of COCO. A well-developed few-shot object detector should
be comparable to the traditional object detector on the training categories if it has not been fine-tuned. This figure demonstrates
our model indeed achieves competitive performance on training categories and even surpasses the traditional one on particular
classes.
models based on Faster R-CNN [6], we adopt SGD with an We define the 20 COCO categories intersecting with PASCAL
initial learning rate of 0.001, which decays into 0.0001 after 12 VOC [54] as the novel classes, while the rest 60 categories
epochs; the four anchor scales are [602 , 1202 , 2402 , 4802 ] and covered by COCO but not VOC to be the base classes.
the three aspect ratios are [0.5, 1.0, 2.0]; the momentum and 2) FSOD Training: Following the paradigm of meta-
weight decay coefficients are set to 0.9 and 0.0005. For DAnA- learning, the training data are organized into episodes. Each
RetinaNet, we construct a pyramid with levels P3 through episode contains one or more support sets, a query image and
P7 (Pl has resolution 2l lower than the input) and adopt corresponding ground truth annotations. Unlike the queries in
Adam with a learning rate of 0.00001. We adopt the two-way FSC, a query image in FSOD might contain multiple objects
contrastive training strategy, which is first proposed in [3], to of different categories. Therefore, in each training step we
train the baselines and our models. will choose one of the object categories as the target class. A
support set of the target class will be offered and the model
B. Experimental Settings should learn to detect the target objects conditioned on the
1) Dataset: In the experiments, we leverage the challenging given support information. Note that all the bounding box
Microsoft COCO 2017 [53] benchmark for evaluation. COCO annotations belonging to the novel classes have been removed
has 80 object classes, consisting of a training set with 118,287 in order the prevent models from peeking at the novel task.
images and a validation set with 4,952 images. Generally, the 3) FSOD Evaluation: Generally, N-way K-shot in the few-
validation split of COCO will serve as the testing data due shot paradigm indicates that we can use K images of each
to the fact that the testing split is not released to the public. novel category to adapt the models before testing. However,
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 7
Novel Categories Base Categories Novel Categories
Method Method
AP AP AP AP75
# Way 1way 1way # Way 1way 1way
# Given Supports 1shot 3shot 5shot 1shot 3shot 5shot # Given Supports 1shot 3shot 5shot 1shot 3shot 5shot
Meta R-CNN† [2] 7.8 9.0 9.3 33.7 34.8 35.1 Meta R-CNN† [2] 14.7 17.0 17.4 13.1 15.0 15.2
FGN† [13] 6.7 7.4 7.7 30.5 31.2 32.1 FGN† [13] 14.9 16.7 17.9 13.8 15.5 16.8
Attention RPN† [3] 6.8 7.4 7.7 23.7 26.6 27.2 Attention RPN† [3] 15.0 17.1 18.1 13.7 15.4 16.2
DAnA-RetinaNet 9.1 10.3 11.5 36.5 36.9 37.2 DAnA-RetinaNet 16.6 18.8 19.5 15.5 17.7 18.4
DAnA-FasterRCNN 10.0 11.6 11.9 36.5 38.1 38.6 DAnA-FasterRCNN 17.9 21.3 21.6 17.0 20.2 20.4
TABLE IV: The results of PASCAL2COCO evaluation. All TABLE V: Following [10], we construct class-balanced
the models are trained on PASCAL VOC 2007 and tested episodes from COCO for evaluation. In addition, we report the
on COCO 2014. In this setting, the base domain denotes the performance of two different detection networks adopting the
20 classes shared between PASCAL VOC and COCO, while proposed DAnA component. Even though the performance of
the novel domain denotes the other 60 classes in the COCO DAnA-RetinaNet is less remarkable than DAnA-FasterRCNN,
dataset. it still significantly outperforms the baselines which are based
on Faster R-CNN, showing the effectiveness of our proposed
attention mechanism.
we observe previous works adopted different evaluation set-
tings and fine-tuning protocols, leading to the ambiguity in
evaluation. For instance, since a query in FSOD might consist
Faster R-CNN, and therefore we can fairly analyze the impact
of multiple objects of different categories, Kang et al. [1]
brought by different attention mechanisms. Note that we have
defined that there should be only K box annotations of each
slight modifications on these methods: 1) For the model
category in the fine-tuning set, while Chen et al. [48] adopted
architectures, we replace the multi-class classification output
the protocol of collecting K query images of each category to
with the binary one as explained in III-C. 2) For training,
fine-tune their models. To thoroughly evaluate the proposed
we apply the two-way contrastive strategy [3] to each method
method, in Tab. I we follow the widely-used protocol in [1]
since we empirically observe it can improve the performance.
and compare our results with those works adopting the same
In addition, as we discussed in Sec. IV-B3, all the methods
setting. Furthermore, we carry out additional experiments
are evaluated without fine-tuning under such a protocol.
under our proposed zero-shot protocol (Tab. II, III, IV, V),
where we do NOT leverage any annotated data of the novel Tab. II shows the results predicted with different numbers
classes to fine-tune models. We expect a well-developed few- of support images. With 5-shot support images given at
shot object detector can deal with novel objects as long as few inference, DAnA-FasterRCNN outperforms FGN and Atten-
support images are given, reducing the costly data re-collection tion RPN by 3.5/6.4/4.0 and 3.8/6.0/4.7 mAP respectively
and annotations processes. on AP/AP50 /AP75 metrics. Moreover, the proposed model
achieves the most significant improvement as the shot in-
creases, supporting our argument that DAnA can better retrieve
C. Generic FSOD Protocol the information carried within support images by leveraging
The performance of each method under the general FSOD QPA features.
protocol is reported in Tab. I. In this table, we comply with Intuitively, without being fine-tuned on the novel domain,
the evaluation protocol widely used in previous works and a well-developed FSOD model should perform well on base
compare our results with the numbers reported in previous pa- classes. In order to evaluate to what extent the ability of
pers. As we have discussed in Sec. IV-B1, the models will not detection networks has been undermined by the modifications,
be exposed to the annotations of the 20 novel classes during we also provide the performance of Faster R-CNN [6], which
training. After training, there will be K = 10, 30 bounding box is the backbone of these few-shot object detectors. The Faster
annotations per novel class can be used to fine-tune the models. R-CNN is trained on the 60 base classes and has not been
Under such a challenging setting, Tab. I shows our method exposed to the novel categories. The performance of it can be
significantly outperforms the other baselines. By equipping regarded as the upper bound of performance on base classes.
with DAnA, Faster R-CNN conspicuously outperforms the By precisely capturing object-wise correlations, our model
strongest baseline [17] by 6.1 and 6.9 AP under the 10-shot has a much smaller gap with the upper bound comparing
and 30-shot settings respectively. with baselines. Additionally, we report the model sizes and
inference speed in Tab. II as well. The proposed DAnA
D. Zero-shot FSOD Protocol component only causes little additional cost in comparison to
In this section, we evaluate the models under a more prior approaches.
challenging setting without fine-tuning. Note that the word In Tab. III, we further evaluate each method under the multi-
“zero-shot” here is not referred to the zero-shot learning way evaluation setting. Under the multi-way setting, models
paradigm [55] but referred to the fact that we do not take must detect more than one object category conditioned on the
any novel image to fine-tuned the models. In order to evaluate given support set. Suppose there are M categories in a query
each method under an unified protocol, we re-implement three image, we will randomly sample N classes from them to form
previous methods: Meta R-CNN [2], FGN [13] and Attention an N-way support set. Sometimes the number of object classes
RPN [3]. These baselines and our model are all based on in a query image will be less than N, and we just select other
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 8
Architecture Average Pooling Denoising Combination Novel Categories
E. Ablations
RPN across QPA features Mask BA product concat AP AP50
a X X 12.6 26.9 In Tab. VI, we show the results of the ablation study to
b X X X 13.5 28.4
c X X X 11.4 24.2 analyze the impact brought by each component.
d X X X X 10.5 22.8
e X X X 11.3 22.3 a) Whether CISA is effective at utilizing support images:
f X X X X 13.8 28.8
In Sec. III-B3, we argue that the issue of feature uncertainty
TABLE VI: The results of ablations. (a,b) shows the ef- can be addressed by performing average pooling across query-
fectiveness of using QPA features. (b,f) and (d,f) show the position-aware (QPA) vectors. In the ablations, we investigate
effectiveness of the proposed BA mechanism. (e,f) shows RPN the improvement brought by our CISA component. For setting
is a critical component to fully represent the advantages of (a), we directly take the mean feature over multiple images as
DAnA. the class representations. The ablation (a, b) suffices to show
that transforming ordinary features into QPA vectors indeed
brings improvement on the performance.
b) Why not just denoise by soft attention: To attenuate
N − M classes to form an N-way support set. noise in support images, it is intuitive to directly learn a soft
attention mask and reweights the importance of each pixel.
Fan et al. [13] evaluated models under the COCO2VOC In Tab. VI, “Mask” means we leverage CNN to learn a soft
setting, where models are trained on the 60 COCO categories attention mask and perform element-wise product between the
disjoint with VOC, and then tested on PASCAL VOC [54]. In mask and the support feature map. As it can be observed, the
this work, we consider a much more challenging setting termed result suggests that using the BA module is more effective
PASCAL2COCO, where models are trained on PASCAL VOC than using general soft attention by preserving much more
2007 and tested on the COCO benchmark. The 60 categories information.
disjoint with VOC will serve as the novel categories, which is c) How to combine query features and QPA vectors:
opposite to the setting in [13]. In Tab. IV, even the models are Since the resulting QPA features will have the same size
applied to a domain that is more complicated than the training as query feature maps, they can be combined by either
domain, the models equipped with DAnA still demonstrate concatenation or element-wise product. According to (b, c),
remarkable ability. we conclude that concatenation is a better strategy for DAnA.
In Tab. V, we apply the same zero-shot protocol but follow d) The importance of RPN: In the experiments, we
the tradition in FSC to construct episodes. Instead of directly have compared the two proposed detection networks, DAnA-
testing by COCO validation split, we follow the episode-based FasterRCNN (with RPN) and DAnA-RetinaNet (without
evaluation protocol defined in RepMet [10] to prepare 500 RPN). Based on the results in Tab. IV and V, we conclude
random evaluation episodes in advance. In each episode, take that RPN is a critical component in our problem. Nonetheless,
N-way K-shot evaluation for example, there will be K support there could be other factors influencing the results, such as the
images and 10 query images for each of the N categories. use of feature pyramids and Focal Loss [7]. Therefore, in the
Consequently, there will be K × N support images and 10 × N ablations (e), we re-train a DAnA-RetinaNet but remove the
query images in each episode. feature pyramids from it. However, we still adopt the Focal
Loss in (e) because either RPN or Focal Loss is necessary
In Tab. IV and Tab. V, we have compared DAnA- to prevent the model from being severely deteriorated by
FasterRCNN with another proposed framework, DAnA- numerous negative anchors. The result (e, f) shows that,
RetinaNet, to evaluate the performance as adopting different without the influence of feature pyramids, the model including
detection networks. Generally, the two-stage few-shot object RPN has significantly better performance. To conclude, we
detectors [8], [2], [3], [5], [17] with region proposal net- suggest RPN is an indispensable component to fully represent
work (RPN) have higher performance than the one-stage [1], the effectiveness of DAnA.
[4] methods (see Tab. I). Nonetheless, though our DAnA-
RetinaNet is based on the one-stage object detector, it still out-
performs previous methods using two-stage networks, which F. Visualizations
suffices to verify the effectiveness and dexterity of our DAnA. The examples of few-shot object detection are demonstrated
On the other hand, it seems the use of feature pyramids in Fig. 7. In FSOD, the prediction is dependent on the object
does not help DAnA-RetinaNet reach better results. The category of the given support set. Notably, all the target
result could be caused by the lack of RPN. Without RPN, instances in Fig. 7 belong to the novel classes, so the model
networks must tackle a nearly exhaustive list of potential has never been trained to recognize these objects. However,
object locations. Furthermore, in FSOD, those foregrounds given few support images, the proposed model is capable of
irrelevant to the presented support set should be classified as recognizing and locating the instances. The last row of Fig. 7
backgrounds as well. Therefore, the huge amount of anchors presents a failure case where a motorcycle is given yet the
and the extremely imbalanced foreground-background ratio bicycle in the query is detected.
would seriously undermine the ability of DAnA-RetinaNet. We also visualize the cross-image spatial attention (CISA)
To conclude, we suggest RPN plays a deep role in fully in Fig. 8. The CISA module is capable of capturing the
presenting the advantages of DAnA, which is verified by the semantic correspondence between the query and support. Take
aforementioned experiments and the ablation study. (e) for example, given the head (colored in red) or the feet of
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 9
Query and support Prediction Ground truth Query and support Prediction Ground truth
Fig. 7: At training, the model has never seen the novel categories, including bird, car, dog, person, motorcycle, bicycle, etc.
However, given different support examples, our model is capable of recognizing unseen target objects in the query image. The
last row represents the failure case where the model confuses a bicycle with a motorcycle.
1
2 1 1
2
2
Query Supports Position1 Position2 Query Supports Position1 Position2 Query Supports Position1 Position2
(a) (b) (c)
1 2
1 1
2 2
Query Supports Position1 Position2 Query Supports Position1 Position2 Query Supports Position1 Position2
(d) (e) (f)
Fig. 8: For each query image, we consider two different regions (colored in red and blue) and visualize their corresponding
support attention maps. The CISA module is capable of capturing the semantic correspondence between the query and support
images (e.g., the head or legs of an animal). (f) represents the case where neither of the support categories exists in the query
image.
a human (colored in blue), the attention maps will highlight state-of-the-art results. We are excited to point out a new
the head or the feet areas of the support images. The result direction to solve FSOD tasks. We encourage future works
(f) represents the case that neither of the support categories to extend our method to other challenging tasks such as few-
exists in the query image, which shows that if there is no shot instance segmentation and co-salient object detection.
corresponding contextual information, CISA has a tendency
to highlight the most distinguishing components that can best ACKNOWLEDGMENT
describe an object. This work was supported in part by the Ministry of Science
and Technology, Taiwan, under Grant MOST 110-2634-F-002-
V. C ONCLUSION
026. We benefit from NVIDIA DGX-1 AI Supercomputer
In this work, we observed the problem of spatial misalign- and are grateful to the National Center for High-performance
ment and feature uncertainty in the challenging few-shot object Computing.
detection (FSOD) task. We propose a novel and effective
Dual-Awareness Attention (DAnA) mechanism to tackle the R EFERENCES
problem. Our method is adaptable to both one-stage and two-
[1] B. Kang, Z. Liu, X. Wang, F. Yu, J. Feng, and T. Darrell, “Few-shot
stage object detection networks. DAnA remarkably boosts the object detection via feature reweighting,” in Proceedings of the IEEE
FSOD performance on the COCO benchmark and reaches International Conference on Computer Vision, 2019, pp. 8420–8429.
IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 10
[2] X. Yan, Z. Chen, A. Xu, X. Wang, X. Liang, and L. Lin, “Meta r- [26] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by
cnn: Towards general solver for instance-level low-shot learning,” in jointly learning to align and translate,” arXiv preprint arXiv:1409.0473,
Proceedings of the IEEE International Conference on Computer Vision, 2014.
2019, pp. 9577–9586. [27] M.-T. Luong, H. Pham, and C. D. Manning, “Effective ap-
[3] Q. Fan, W. Zhuo, C.-K. Tang, and Y.-W. Tai, “Few-shot object detection proaches to attention-based neural machine translation,” arXiv preprint
with attention-rpn and multi-relation detector,” in Proceedings of the arXiv:1508.04025, 2015.
IEEE/CVF Conference on Computer Vision and Pattern Recognition, [28] J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin,
2020, pp. 4013–4022. “Convolutional sequence to sequence learning,” arXiv preprint
[4] J.-M. Perez-Rua, X. Zhu, T. M. Hospedales, and T. Xiang, “Incremental arXiv:1705.03122, 2017.
few-shot object detection,” in Proceedings of the IEEE/CVF Conference [29] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez,
on Computer Vision and Pattern Recognition, 2020, pp. 13 846–13 855. Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances
[5] J. Wu, S. Liu, D. Huang, and Y. Wang, “Multi-scale positive in neural information processing systems, 2017, pp. 5998–6008.
sample refinement for few-shot object detection,” arXiv preprint [30] X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural net-
arXiv:2007.09384, 2020. works,” in Proceedings of the IEEE conference on computer vision and
[6] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time pattern recognition, 2018, pp. 7794–7803.
object detection with region proposal networks,” in Advances in neural [31] H. Zhao, Y. Zhang, S. Liu, J. Shi, C. Change Loy, D. Lin, and J. Jia,
information processing systems, 2015, pp. 91–99. “Psanet: Point-wise spatial attention network for scene parsing,” in
[7] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss Proceedings of the European Conference on Computer Vision (ECCV),
for dense object detection,” in Proceedings of the IEEE international 2018, pp. 267–283.
conference on computer vision, 2017, pp. 2980–2988. [32] J. Fu, J. Liu, H. Tian, Y. Li, Y. Bao, Z. Fang, and H. Lu, “Dual attention
network for scene segmentation,” in Proceedings of the IEEE Conference
[8] X. Wang, T. E. Huang, T. Darrell, J. E. Gonzalez, and F. Yu,
on Computer Vision and Pattern Recognition, 2019, pp. 3146–3154.
“Frustratingly simple few-shot object detection,” arXiv preprint
[33] Y. Cao, J. Xu, S. Lin, F. Wei, and H. Hu, “Gcnet: Non-local networks
arXiv:2003.06957, 2020.
meet squeeze-excitation networks and beyond,” in Proceedings of the
[9] J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot IEEE International Conference on Computer Vision Workshops, 2019,
learning,” in Advances in neural information processing systems, 2017, pp. 0–0.
pp. 4077–4087. [34] X. Zhu, D. Cheng, Z. Zhang, S. Lin, and J. Dai, “An empirical study of
[10] L. Karlinsky, J. Shtok, S. Harary, E. Schwartz, A. Aides, R. Feris, spatial attention mechanisms in deep networks,” in Proceedings of the
R. Giryes, and A. M. Bronstein, “Repmet: Representative-based metric IEEE International Conference on Computer Vision, 2019, pp. 6688–
learning for classification and few-shot object detection,” in Proceedings 6697.
of the IEEE Conference on Computer Vision and Pattern Recognition, [35] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in
2019, pp. 5197–5206. Proceedings of the IEEE conference on computer vision and pattern
[11] G. Koch, R. Zemel, and R. Salakhutdinov, “Siamese neural networks for recognition, 2018, pp. 7132–7141.
one-shot image recognition,” in ICML deep learning workshop, vol. 2. [36] M. Yin, Z. Yao, Y. Cao, X. Li, Z. Zhang, S. Lin, and H. Hu, “Disen-
Lille, 2015. tangled non-local neural networks,” arXiv preprint arXiv:2006.06668,
[12] F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. Torr, and T. M. Hospedales, 2020.
“Learning to compare: Relation network for few-shot learning,” in [37] H. Emami, M. M. Aliabadi, M. Dong, and R. B. Chinnam, “Spa-gan:
Proceedings of the IEEE Conference on Computer Vision and Pattern Spatial attention gan for image-to-image translation,” IEEE Transactions
Recognition, 2018, pp. 1199–1208. on Multimedia, vol. 23, pp. 391–401, 2020.
[13] Z. Fan, J.-G. Yu, Z. Liang, J. Ou, C. Gao, G.-S. Xia, and Y. Li, [38] J. Li, X. Liu, W. Zhang, M. Zhang, J. Song, and N. Sebe, “Spatio-
“Fgn: Fully guided network for few-shot instance segmentation,” in temporal attention networks for action recognition and detection,” IEEE
Proceedings of the IEEE/CVF Conference on Computer Vision and Transactions on Multimedia, vol. 22, no. 11, pp. 2990–3001, 2020.
Pattern Recognition, 2020, pp. 9172–9181. [39] D. Zhang, D. Meng, C. Li, L. Jiang, Q. Zhao, and J. Han, “A self-
[14] W. Liu, C. Zhang, G. Lin, and F. Liu, “Crnet: Cross-reference networks paced multiple-instance learning framework for co-saliency detection,”
for few-shot segmentation,” in Proceedings of the IEEE/CVF Conference in Proceedings of the IEEE international conference on computer vision,
on Computer Vision and Pattern Recognition, 2020, pp. 4165–4173. 2015, pp. 594–602.
[15] H. Hu, Z. Zhang, Z. Xie, and S. Lin, “Local relation networks for image [40] J. Han, G. Cheng, Z. Li, and D. Zhang, “A unified metric learning-based
recognition,” in Proceedings of the IEEE International Conference on framework for co-saliency detection,” IEEE Transactions on Circuits and
Computer Vision, 2019, pp. 3464–3473. Systems for Video Technology, vol. 28, no. 10, pp. 2473–2483, 2017.
[16] L. Bertinetto, J. Valmadre, J. F. Henriques, A. Vedaldi, and P. H. Torr, [41] Q. Fan, D.-P. Fan, H. Fu, C.-K. Tang, L. Shao, and Y.-W. Tai, “Group
“Fully-convolutional siamese networks for object tracking,” in European collaborative learning for co-salient object detection,” in Proceedings of
conference on computer vision. Springer, 2016, pp. 850–865. the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
[17] Y. Xiao and R. Marlet, “Few-shot object detection and viewpoint 2021, pp. 12 288–12 298.
estimation for objects in the wild,” arXiv preprint arXiv:2007.12107, [42] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature
2020. hierarchies for accurate object detection and semantic segmentation,”
[18] S. Ravi and H. Larochelle, “Optimization as a model for few-shot in Proceedings of the IEEE conference on computer vision and pattern
learning,” 2016. recognition, 2014, pp. 580–587.
[43] R. Girshick, “Fast r-cnn,” in Proceedings of the IEEE international
[19] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for
conference on computer vision, 2015, pp. 1440–1448.
fast adaptation of deep networks,” arXiv preprint arXiv:1703.03400,
[44] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie,
2017.
“Feature pyramid networks for object detection,” in Proceedings of the
[20] Z. Li, F. Zhou, F. Chen, and H. Li, “Meta-sgd: Learning to learn quickly IEEE conference on computer vision and pattern recognition, 2017, pp.
for few-shot learning,” arXiv preprint arXiv:1707.09835, 2017. 2117–2125.
[21] A. Nichol, J. Achiam, and J. Schulman, “On first-order meta-learning [45] H. Law and J. Deng, “Cornernet: Detecting objects as paired key-
algorithms,” arXiv preprint arXiv:1803.02999, 2018. points,” in Proceedings of the European Conference on Computer Vision
[22] K. Lee, S. Maji, A. Ravichandran, and S. Soatto, “Meta-learning (ECCV), 2018, pp. 734–750.
with differentiable convex optimization,” in Proceedings of the IEEE [46] Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: Fully convolutional
Conference on Computer Vision and Pattern Recognition, 2019, pp. one-stage object detection,” in Proceedings of the IEEE international
10 657–10 665. conference on computer vision, 2019, pp. 9627–9636.
[23] O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra et al., “Matching [47] X. Zhou, D. Wang, and P. Krähenbühl, “Objects as points,” arXiv
networks for one shot learning,” in Advances in neural information preprint arXiv:1904.07850, 2019.
processing systems, 2016, pp. 3630–3638. [48] H. Chen, Y. Wang, G. Wang, and Y. Qiao, “Lstd: A low-shot transfer
[24] J. Liu, L. Song, and Y. Qin, “Prototype rectification for few-shot detector for object detection,” arXiv preprint arXiv:1803.01529, 2018.
learning,” arXiv preprint arXiv:1911.10713, 2019. [49] G.-J. Qi, X.-S. Hua, Y. Rui, T. Mei, J. Tang, and H.-J. Zhang, “Concur-
[25] Y. Tian, Y. Wang, D. Krishnan, J. B. Tenenbaum, and P. Isola, “Rethink- rent multiple instance learning for image categorization,” in 2007 IEEE
ing few-shot image classification: a good embedding is all you need?” Conference on Computer Vision and Pattern Recognition. IEEE, 2007,
arXiv preprint arXiv:2003.11539, 2020. pp. 1–8.IEEE TRANSACTIONS ON MULTIMEDIA, VOL, 23, 2021 11
[50] P. Dollár, B. Babenko, S. Belongie, P. Perona, and Z. Tu, “Multiple Yu-Hsiang Lin received the M.S. degree in statistics
component learning for object detection,” in European conference on from National Yang Ming Chiao Tung University,
computer vision. Springer, 2008, pp. 211–224. Hsinchu, Taiwan, in 2019. He is currently a research
[51] B. Babenko, M.-H. Yang, and S. Belongie, “Robust object tracking with assistant at National Tsing Hua University, Taiwan.
online multiple instance learning,” IEEE transactions on pattern analysis His research interests include object detection, nat-
and machine intelligence, vol. 33, no. 8, pp. 1619–1632, 2010. ural language processing, sentiment analysis, and
[52] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, deep learning.
A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in
pytorch,” 2017.
[53] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan,
P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in
context,” in European conference on computer vision. Springer, 2014,
pp. 740–755.
[54] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisser-
man, “The pascal visual object classes (voc) challenge,” International Jia-Fong Yeh received the B.S. degree and the
journal of computer vision, vol. 88, no. 2, pp. 303–338, 2010. M.S. degree in Computer Science and Information
[55] R. Socher, M. Ganjoo, H. Sridhar, O. Bastani, C. D. Manning, and A. Y. Engineering from National Taiwan Normal Univer-
Ng, “Zero-shot learning through cross-modal transfer,” arXiv preprint sity (NTNU), Taiwan, in 2017 and 2019, respec-
arXiv:1301.3666, 2013. tively. He is currently pursuing his Ph.d. degree
in Computer Science and Information Engineering
at Natioal Taiwan University (NTU), Taiwan. His
research interests include machine learning (ML),
evolutionary algorithms (EAs), and computer games
Tung-I Chen received the B.E. degree in the Depart- (CG). Recently, He is devoted to the study on few-
ment of Biomedical Engineering, National Cheng shot learning. Jia-Fong is a student member of IEEE.
Kung University (NCKU) in 2019, and the M.S.
degree in the Department of Computer Science & In-
formation Engineering, National Taiwan University
(NTU) in 2021. His research interests include com-
puter vision, object detection and machine learning Winston H. Hsu (S’03–M’07–SM’12) received
theory. the Ph.D. degree in electrical engineering from
Columbia University, New York, NY, USA. He
is keen to realizing advanced researches towards
business deliverables via academia-industry collab-
orations and co-founding startups. Since 2007, he
has been a Professor with the Graduate Institute
of Networking and Multimedia and the Department
of Computer Science and Information Engineering,
Yueh-Cheng Liu received M.S. degree from com- National Taiwan University. His research interests
puter science department in National Taiwan Uni- include large-scale image/video retrieval/mining, vi-
versity (NTU) in 2020. He is currently a research sual recognition, and machine intelligence. Dr. Hsu served as the Associate
assistant in vision science lab in EE department at Editor for the IEEE TRANSACTIONS ON MULTIMEDIA and on the
National Tsing Hua University. His research interests Editorial Board for the IEEE MultiMedia Magazine.
include computer vision, robotic learning, and 3D
scene understanding.
Wen-Chin Chen received a BS in mathematics from
National Taiwan University and a PhD in compputer
science from Brown University in 1976 and 1984.
He has been the Professor of Computer science
and Information Engineering department of National
Hung-Ting Su is currently pursuing the Ph.D. de- Taiwan University since 1987. His research interests
gree with the Graduated Institute of Networking are in the areas of design and analysis of algorithms,
and Multimedia, National Taiwan University, Taipei, multimedia systems and quantumn algorithms.
Taiwan. His current research interests include multi-
modal comprehension and unsupervised learning.
Yu-Cheng Chang received his M.S. degree from the
Department of Computer Science and Information
Engineering, National Taiwan University, Taipei,
Taiwan, in 2020. His research interests include ma-
chine learning and medical image processing.You can also read

















































