E2.4 DEVELOPMENT OF SUPERVISED CATEGORIZATION MODELS, TOPIC MODELLING AND EXTRACTION OF CLINICAL INFORMATION COMPUTING.
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Project Acronym:ICTUSnet Project code: SOE2/P1/E0623
E2.4 DEVELOPMENT OF
SUPERVISED
CATEGORIZATION MODELS,
TOPIC MODELLING AND
EXTRACTION OF CLINICAL
INFORMATION
COMPUTING.Due date: 30/04/2020
Actual submission date: 30/04/2021
WP2. WP Development and integration of 'Machine
Responsible partner: BSC
Learning' algorithms
Version: 04
Status: Final
Dissemination level: Public / Consortium
Project funded by the Interreg Sudoe Programme through the European Regional Development Fund (ERDF)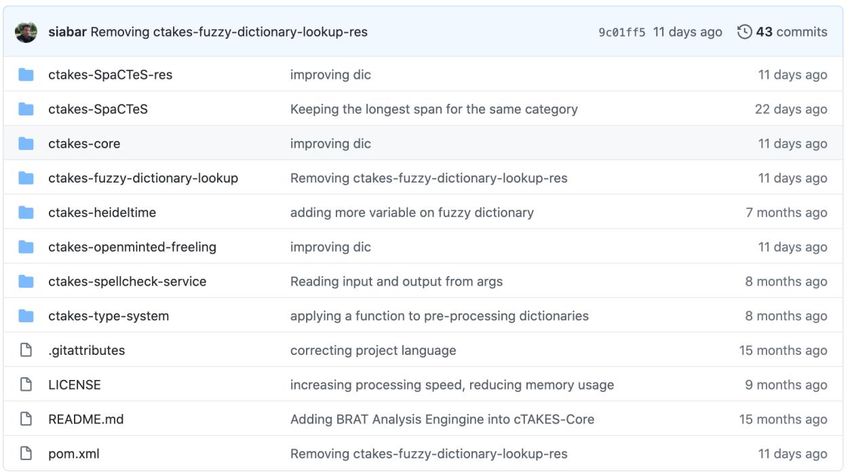
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Deliverable description:
This deliverable describes the methodology used in WP2 to develop the SUPERVISED CATEGORIZATION
MODELS, TOPIC MODELLING AND EXTRACTION OF CLINICAL INFORMATION using deep learning
techniques. The results obtained by the deep learning models are remarkable, reaching 91% F1 on
average.
Revision history
Version Date Comments Partner
01 12/2020 First version BSC
02 02/2021 Second version BSC
03 04/2021 Final version BSC
Authors
Name Partner
Marta Villegas Montserrat BSC
Aitor González Agirre BSC
Joan Llop BSC
Siamak Barzegar BSC
Contributors
Name Partner
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 2 of 65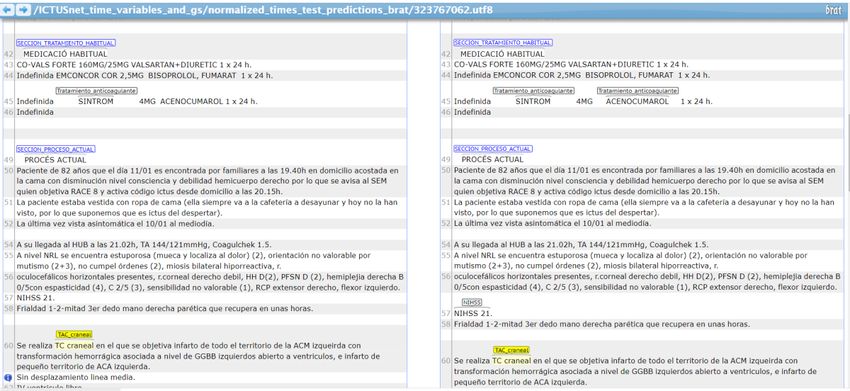
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
ABBREVIATIONS AND ACRONYMS
HUSE Hospital Universitario Son Espases
XML Extensible Markup Language
HER Electronic Health Record
TTR Type Token Ratio
BRAT Brat Rapid Annotation Tool
F1 F1 score
IAA Inter-Annotator Agreement
NER Named Entity Recognition
NERC Named Entity Recognition and Classification
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 3 of 65
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
TABLE OF CONTENTS
INRODUCTION .............................................................................................................. 6
1. METHODOLOGY .................................................................................................... 6
2. VARIABLES OF INTEREST & MAIN CHALLENGES .............................................. 9
Section headers ........................................................................................................ 10
Main diagnosis and related attributes ........................................................................ 10
Procedures and their attributes ................................................................................. 11
Treatments ................................................................................................................ 13
Rating scales............................................................................................................. 13
3. THE GOLD STANDARD ........................................................................................ 14
4. THE PRE-ANNOTATION TOOL ............................................................................ 16
5. EVALUATION OF THE RULE BASED PRE-ANNOTATION SYSTEM ................... 17
6. DEEP LEARNING METHODS ............................................................................... 19
Evaluation method..................................................................................................... 21
7. RESULTS .............................................................................................................. 24
Biomedical and clinical models .................................................................................. 27
Summary and conclusions ........................................................................................ 29
Code & Demos .......................................................................................................... 30
8. USAGE GUIDELINES............................................................................................ 32
9. LIST OF FIGURES ................................................................................................ 32
10. LIST OF TABLES ............................................................................................... 33
ANNEX 1 List of non-header variables and their frequency........................................... 34
ANNEX 2 List of header variables and their frequency.................................................. 36
ANNEX 3 Detailed results for the Biomedical model ..................................................... 37
ANNEX 4 Detailed results for the Clinical model ........................................................... 40
ANNEX 5 ICTUSnet cTAKES pipeline Installation Guidelines for developers ............... 43
ANNEX 6 ICTUSnet cTAKES Developing Guidelines ................................................... 52
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 4 of 65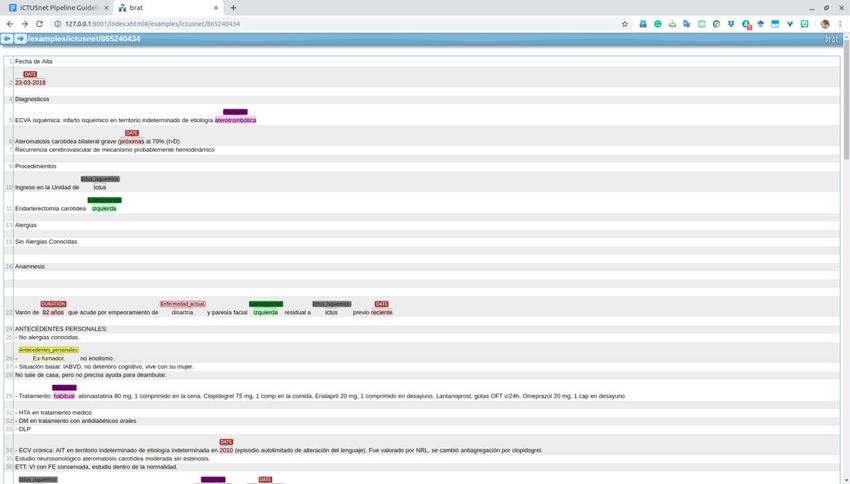
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
EXECUTIVE SUMMARY
This deliverable describes the methodology used in WP2 to develop the SUPERVISED
CATEGORIZATION MODELS, TOPIC MODELLING AND EXTRACTION OF CLINICAL INFORMATION
using deep learning techniques. The document fully reports the main challenges of the task, the
rule-based system for the pre-annotation task, and the eventual supervised model. The results
are reported in detail, and two models are compared. The annexes of the document contain
additional material and information. The document contains links to the code in GitHub and the
demo developed. The results of the deep learning models are remarkable, reaching 91% F1 on
average and they demonstrate that the use of language technologies can be of great help in
clinical information extraction tasks, as in the case of ICTUSnet.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 5 of 65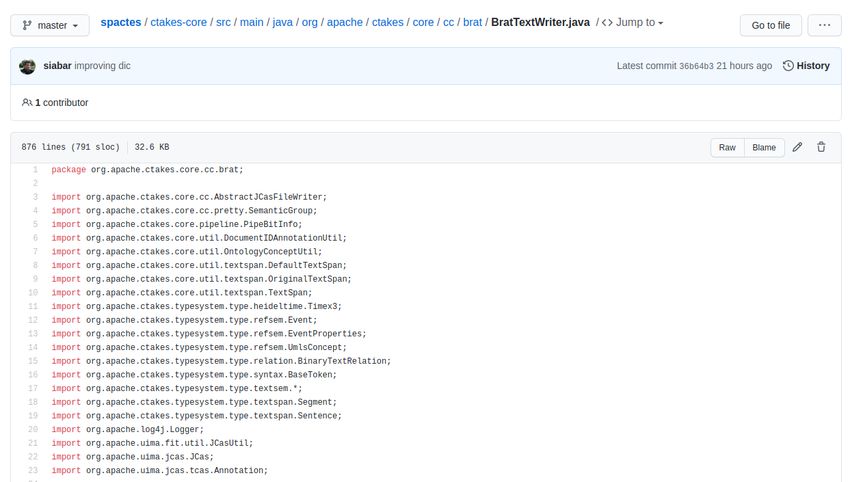
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
INRODUCTION
In this document, we describe the methodology followed when developing the supervised models
for clinical information extraction and the results achieved. The objective of the supervised
models is to support human experts when identifying and extracting relevant variables from
stroke discharge reports to fill in the Ictus Registry. The set of relevant variables (i.e. variables of
interest) were defined in WP1. The ultimate objective of the task is to assess the extent to which
text mining technologies are able to meet the needs of a scenario such as the one in ICTUSnet.
From now on this document is organized as follows:
Section 1 describes the methodology followed in WP2.
Section2 analyzes the variables of interest focusing on the challenges of the clinical information
extraction task in the context of the ICTUSnet project.
Section 3 gives some statistical information about the Gold Standard used to train and evaluate
the deep learning models.
Section 4 describes the rule based pre-annotation system used to support the manual annotation
task. The corresponding installation guidelines and user manual can be found in the Annexes of
this document.
Section 5 reports the performance of the rule-based system. In this assessment task, we used the
same test set used to evaluate the deep learning models. Note that the objective of this evaluation
is just to evaluate the performance of the system, a fair comparison with deep learning models is
not possible since the rule based system has already seen the test set.
Section 6 describes the development of the deep learning models and the methodology used to
evaluate the systems.
Finally, Section 7 reports and analyses the results, summarizes the main conclusions and gives the
links to the demos.
The rest of the document contains list of tables and figures and a number of annexes with
supplementary information.
1. METHODOLOGY
Following standard deep learning techniques we used neural networks to generate a domain
specific language model and, then, we fine-tuned (adapted) the mode to a specific task (i.e.
Named Entity Recognition and Classification, NERC).
To train the supervised models for this information extraction task, we need annotated data. The
annotation task was done by domain experts and governed by annotation guidelines that
unambiguously determine the rules to be applied. The annotation guidelines used in the project
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 6 of 65
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
can be found in the Deliverable E2.5. Figure 1illustrates the process of model generation (using
large amounts of biomedical domain data) and model tuning (using a small set of annotated data)
to train the model to perform some specific task.
Figure 1: General schema for model generation and model tuning
To ease the manual annotation task, we developed a rule based pre-annotation system that (i)
identifies and normalizes section headers and (ii) identifies and normalizes the variables of
interest. For additional information about the section headers’ normalization see Deliverable E2.3
“Application For The Standardization of Multilingual Clinical Documents”. The automatic pre-
annotation system was developed in an iterative way, so that the process was split into different
steps, each consisting of 50 to 100 discharge reports. At each new bunch of pre-annotated files,
the system was evaluated against the human annotations and modified to improve its
performance. For the most part, the improvements consisted of the inclusion of new terms in the
dictionary because, as the annotators worked on new reports, they found new variants and forms
that initially were not expected. Figure 2 illustrates this iterative process.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 7 of 65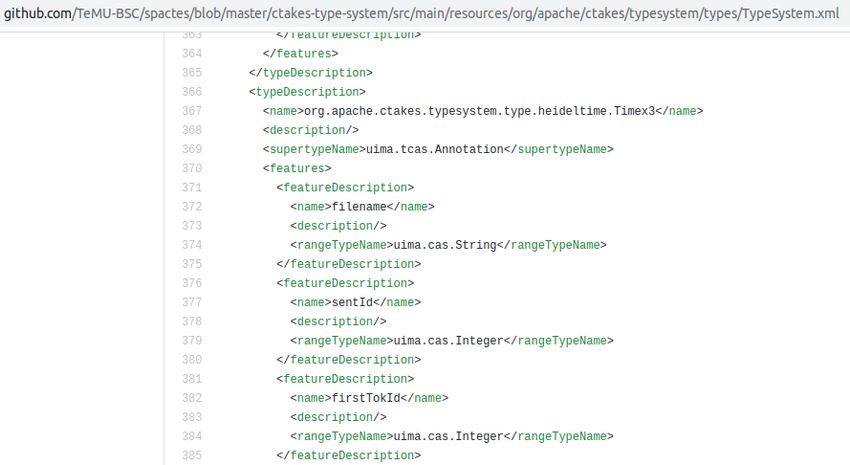
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Figure 2 Iterative (pre)-annotation process
For the manual annotation task we had a team of 4 annotators (3 nurses and 1 doctor) and used
the BRAT annotation tool, properly configured to our scenario. The training phase was particularly
long due to the difficulty of the task and the lack of consensus in certain aspects. The whole
manual annotation process included 17 bunches of approximately 50 to 100 files each (some of
them were repeated). In the initial training stage, the annotators work together and the guidelines
were updated to solve the problems and issues that arose. In the second stage and for the first 5
bunches, all files were annotated by at least two annotators and different inter–annotator
agreement (IAA) calculus were performed. Once the IAA was good enough, we started the real
annotation phase. During the process, we (i) had regular meetings to clarify doubts, (ii) used a
WhatsApp group to facilitate communication between annotators and guideline writers and (iii)
established a “trouble report” system where annotators collected doubts that were discussed and
eventually solved by the responsible of the guidelines. During the whole process, the guidelines
were modified and updated accordingly. Figure 3 shows the manual annotation process.
Figure 3 Manual annotation process
As illustrated in Figure 1 above at the beginning of this section, we used a large biomedical data
set to generate a biomedical pre-trained language model. For this, we collected a big biomedical
corpora gathering data from a variety of medical resources, namely scientific literature, clinical
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 8 of 65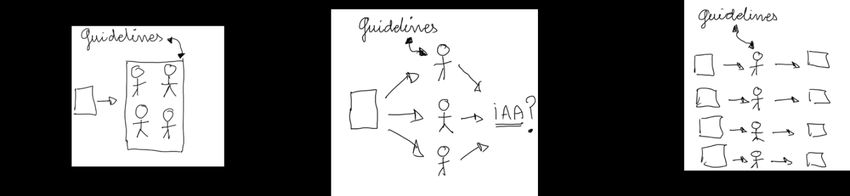
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
cases and crawled data.
We used the resulting corpus to train a biomedical RoBERTa-base model with 12 layers/heads
and hidden layer size 768, for a total number of 126M parameters.
Then, we adapted the model to the clinical domain by overtraining it with 120MB of clinical
textual data (including ICTUSnet data provided by AQuAS, Son Espases and IACS). We continued
the training process for 48h more, and then selected the best model based on perplexity, using a
patience of 20.
Finally, we fine-tuned our pre-trained models for NER task using the ICTUSnet Gold Standard
dataset. The gold standard was split into train, dev and test sets with standard proportions: 80%
for training (656 documents), 10% for valid (83 documents), and 10% for test (83 documents). In
this splitting we made sure that the proportions of the diagnoses were preserved for each of the
sets. We fine-tuned for 10 epochs and selected the best epoch validating on the dev set.
We used both, the Biomedical and the Clinical models to generate and compare the predictions.
Figure 4 illustrates the whole process.
Figure 4: General overview of the methodology
2. VARIABLES OF INTEREST & MAIN CHALLENGES
In this section we analyze the kind of variables included in the project and the challenges they
pose. As described in the annotations guidelines (see Deliverable 2.5), variables can be classified
into four categories as follows.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 9 of 65
Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Section headers
The objective of the system is to identify and normalize section headers by mapping them into
the corresponding Archetype (as suggested by the Spanish Ministry). For a detailed description of
this normalization process and the pre-annotation tool see Deliverable E2.3 “Application For The
Standardization of Multilingual Clinical Documents”.
Note that section header identification cannot be reduced to a mere dictionary look up task
because most elements in the dictionary can only be considered headers under certain
circumstances. For example; when they are capitalized and/or follow certain structural patterns.
Figure 5 shows some section header annotations in BRAT style: first column has the annotation
ID; second column encodes the normalized tag; third and fourth columns serve to encode the
initial and final character positions of the mention and, finally, the last column shows the
mentions as they occur in the text.
Figure 5Headers’ annotations in BRAT style.
Main diagnosis and related attributes
This includes three main diagnoses: ictus isquémico, ataque isquémico transitorio and hemorragia
cerebral and their associated attributes: affected vessel, localization, lateralization and etiology.
The lack of a common naming convention for diagnoses made this task particularly difficult, as
often the diagnose is not explicitly named (or it is wrongly named). In our case, for the (pre)-
annotation service, diagnosis annotation was addressed as a NER task and an extra diagnosis
entity (‘other’) was added for those underspecified or ambiguous namings that need some kind
of interpretation (see the Annotation Guidelines in Deliverable 3.5 for further details).
Note also that diagnosis and related attributes are ‘context dependent’. As a general rule, the
criteria to identify the main diagnosis is by choosing the first disease in the DIAGNOSE section and
the rest of diseases in the report are not considered. Similarly, the related attributes are also
context dependent. Concretely, they are only relevant provided they are related to the main
diagnosis and, consequently, must appear close to it. All other vessels, localizations, lateralizations
and etiologies in the text are irrelevant for the task. Figure 6 shows the pre-annotations
suggested by the pre-annotation service and Figure 7 shows them in BRAT format.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 10 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Figure 6 Predictions suggested by the automatic pre-annotation tool
Figure 7 Diagnosis annotations in BRAT format
Procedures and their attributes
This includes five procedures and a number of associated temporal information as listed below:
Procedures
Trombolisis_intravenosa
Trombectomia_mecanica
Trombolisis_intraarterial
Test_de_disfagia
Tac_craneal
Associated temporal information
Fecha Tc cranial inicial
Hora Tc cranial inicial
Fecha trombólisis iv
Hora inicio primer bolus de la trombólisisrtPA
Fecha trombectomía mecánica
Hora punción arterial para la trombectomía mecánica (groinpuncture)
Fecha primera serie para la trombectomía mecánica
Hora primera serie para la trombectomía mecánica
Fecha recanalización
Hora recanalización
Fecha finalización trombectomía
Hora finalización trombectomía
Fecha trombólisis intraarterial
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 11 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Hora trombólisis intraarterial
Identifying procedures in the reports is a classical NER task. However, identifying and extracting
associated temporal information is a much more complex task. The strategy followed in the
guidelines was to ask annotators to annotate (i) mentions of procedures (as in a standard NER
task) and (ii) temporal expressions that include a textual part in which the procedure is explicitly
mentioned and a temporal expression (a date or time). Figure 8 and Figure 9 show two examples
that illustrate the difficulty of the task.
Figure 8 Annotation of procedures
In this example, we have two annotations, one that maps the span tractament fibrinolitic amb
rtPA to the standard form “trombolisis intravenosa”. In the second one, we have a long textual
evidence that maps to “hora primer bolus trombolisis rtPA”. In this case, the time information
included needs to be identified and normalized. In Figure 9 we can see the same annotation in
BRAT style. Note that, for the time variable, we have an extra annotation line where the time
expression is normalized.
Figure 9 Annotations in BRAT style for “Trombolisisintravenosa” and “Hora inicio primer bolus de la
trombólisisrtPA”.
Again, in Figure 10 we have three annotations, one for the Tombolisis_intravenosa (with textual
mention: rtPA) , another for Hora_primer_bolus_trombolisis_rtPA (with textual evidence: Hora
de inicio del rtPA 15:44) and the last one for Tiempo_puerta_aguja (with textual evidence:
tiempopuertaaguja 17 minutos). For the last two examples, we have a textual evidence from
where the system needs to extract the relevant temporal information.
Figure 10 Additional annotation examples for procedures
In these cases, when computing the inter-annotator agreement, only the standardized temporal
information (encoded in the BRAT Notes field as shown in Figure 9 above) is taken into account.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 12 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
The span (i.e. the textual evidence) is not evaluated. See Section 6 for more details on the
evaluation methods.
For TAC craneal, we followed a different strategy: all evidences in text were annotated and related
temporal attributes (date and time) were encoded provided they occur in the same line (See the
annotation guidelines in Deliverable D2.5 for detailed information). Figure 11 shows the way the
annotation of “tac craneal” was addressed: (i) all mentions in text are annotated and (ii) time
expressions next to any tac craneal are encoded as associated temporal attributes.
Figure 11Annotation of TAC craneal and its associated temporal information
Treatments
For treatments, the objective is to find anticoagulants and antiaggregants and to classify them as
“pre admission medication” or “discharge medication”. This task is essentially a NER task that
includes a classification part (pre-admission vs discharge). This classification mostly depends on
the context of the mention (i.e. the section in which the medication is listed).
Figure 12 Annotation of treatments
In this example, we can see that Acido acetilsalicílico is encoded as “Tratamiento anticoagulante
al alta” because it is listed in the section SECCION_TRATAMIENTO_AL_ALTA. Again, these are
context sensitive variables. All anticoagulants and antiaggregants that fall outside relevant
sections are labeled as anticoagulants or antiaggregants without any further classification.
Rating scales
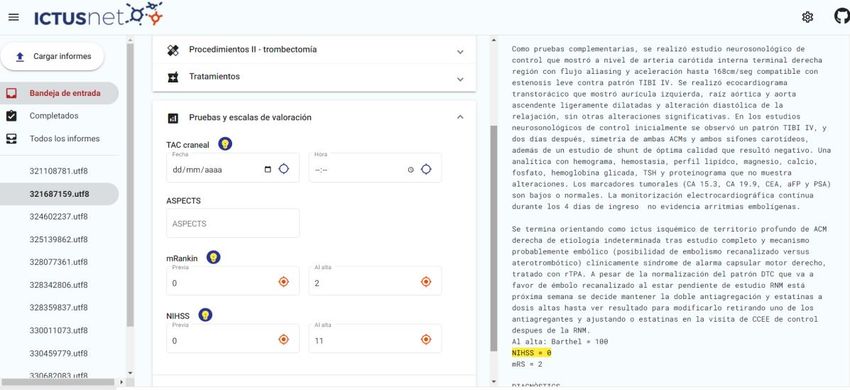
The relevant scales to be annotated include:
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 13 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
ASPECTS
mRankin_alta
mRankin_previa
NIHSS_previa
NIHSS_alta
The main challenge in this case is to find the numerical value of the rating scale (often this comes
in a complex format, see Figure 13) and to distinguish between previa/al_alta scales. Note, again,
that in the vast majority of cases, this previa/al_altadistinction is not explicitly expressed in the
reports.
Figure 13 NIHSS annotation example with a complex numerical sequence
Figure 14 mRanking annotation examples
3. THE GOLD STANDARD
The Gold Standard includes a total of 1,006 annotated files with more than 79,000 different
annotations. More than 39,000 annotations were section headers distributed as follows.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 14 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Table 1 Frequency of section headers
As reported in Deliverable D2.2, section headers show an unbalanced distribution and there are
a few frequent headers and along tail of rather infrequent headers. See ANNEX 1 for the list of
the rest of the variables, here we just list the 20 top most frequent variables.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 15 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
VARIABLE COUNTS
FECHA 11502
HORA 5903
TAC_craneal 4666
Trombolisis_intravenosa 1288
Trombectomia_mecanica 982
NIHSS_previa 964
Fecha_TAC 910
Fecha_de_alta 890
Fecha_de_ingreso 888
Ictus_isquemico 803
Lateralizacion 739
Hora_inicio_sintomas 726
Arteria_afectada 711
Fecha_inicio_sintomas 700
Etiologia 682
mRankin_previa 668
NIHSS 587
Fecha_llegada_hospital 571
NIHSS_alta 570
Tratamiento_antiagregante_alta 550
Table 2 20 top most frequent variables
4. THE PRE-ANNOTATION TOOL
The pre-annotation system includes three components that are sequentially executed as follows:
A section normalizer, a python script that identifies and normalizes section headers. The output
of the script is an .ann file ready to be used in BRAT. See Deliverable E2.3 “Application For The
Standardization of Multilingual Clinical Documents” for further details. The code of this
component can be found in GitHub in the following repository: https://github.com/TeMU-
BSC/EHR-HeaderDetector-AnnotationAnalyser.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 16 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
An annotation pipeline developed in cTAKES framework that identifies and normalizes the
variables of interest. The output of the script is an .ann file ready to be used in BRAT. See
Appendix5 of this document for the documentation about the “Installation guidelines” and
Appendix6 for the “Developing guidelines”. The code of this component can be found in GitHub
in the following repository: https://github.com/TeMU-BSC/spactes
An annotation merger component that:Merges the annotations in (1) and (2) in a single .ann file
and removes ‘irrelevant’ annotations. (e.g. Removing diagnostic variables such as
Ictus_isquemico, Ataque_isquemico_transitorio, Hemorragia_cerebral and their attributes if they
annotated out off the DIAGNOSIS section).The code of the merger component can be found in the
following GitHub repository: https://github.com/TeMU-BSC/brat-merger
5. EVALUATION OF THE RULE BASED PRE-ANNOTATION SYSTEM
We run the rule-based pre-annotation system with the test set defined for the deep learning
evaluation to assess the performance of the system and to compare it with the deep learning
models (see next section for further details on the train/dev/test split of the gold standard). Note,
however, that this is not a fair comparison as, contrary to the deep learning models, the rule-
based system already ‘saw’ the test set. This explains, for example, the good performance of the
section headers predictions. In this case, for the lexicon look up system, the task was rather easy
as all header mentions were in the dictionary. Remember that, in the iterative development
approach described in previous section, at each iteration, new mentions are included in the
lexicon.
Table 3 reports the results for each variable ordered by frequency, with most frequent variables
on top. As we can see in the table, for certain time variables, the results are 0 (marked in red). We
decided not to address the annotation of these ‘time variables’ due to the complexity of the task.
Annotating this type of information led us to define a list of ad hoc regular expressions that was
difficult to maintain and did not bring much benefit to the pre-annotation task, so we decided to
identify times and dates without going into further classification. Note also that, for treatments
and rating scales, we ignored the previa/alta distinction and collapsed the two options into a
single underspecified tag.
tag ex tp fp fn acc pre rec f1
NIHSS 786 726 205 60 0.733 0.780 0.924 0.846
TAC_craneal 625 621 115 4 0.839 0.844 0.994 0.913
mRankin 275 258 16 17 0.887 0.942 0.938 0.940
SECCION_EXPLORACIONES_COMPLEMENTARI 217 208 0 9 0.959 1.000 0.959 0.979
AS
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 17 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
SECCION_MOTIVO_DE_INGRESO 203 200 5 3 0.962 0.976 0.985 0.980
SECCION_TRATAMIENTO_Y_RECOMENDACIO 200 200 0 0 1.000 1.000 1.000 1.000
NES_AL_ALTA
SECCION_PROCESO_ACTUAL 185 185 13 0 0.934 0.934 1.000 0.966
SECCION_EXPLORACION_FISICA 177 177 4 0 0.978 0.978 1.000 0.989
SECCION_TRATAMIENTO_HABITUAL 155 149 6 6 0.925 0.961 0.961 0.961
SECCION_EVOLUCION 147 146 0 1 0.993 1.000 0.993 0.997
Trombolisis_intravenosa 146 134 128 12 0.489 0.511 0.918 0.657
Hora_primer_bolus_trombolisis_rtPA 137 0 0 137 0.000 0.000 0.000 0.000
SECCION_ANTECEDENTES 137 133 1 4 0.964 0.993 0.971 0.982
SECCION_EXPLORACION_FISICA_DURANTE_H 136 91 3 45 0.655 0.968 0.669 0.791
OSPITALIZACION
Trombectomia_mecanica 122 109 55 13 0.616 0.665 0.893 0.762
SECCION_EXPLORACION_FISICA_EN_URGENC 121 80 0 41 0.661 1.000 0.661 0.796
IAS
Ictus_isquemico 117 104 4 13 0.860 0.963 0.889 0.924
SECCION_DESTINO_AL_ALTA 113 109 0 4 0.965 1.000 0.965 0.982
Etiologia 110 88 17 22 0.693 0.838 0.800 0.819
SECCION_DIAGNOSTICOS 110 109 8 1 0.924 0.932 0.991 0.960
ASPECTS 107 106 52 1 0.667 0.671 0.991 0.800
SECCION_EXPLORACIONES_COMPLEMENTARI 104 96 5 8 0.881 0.950 0.923 0.937
AS_EN_PLANTA_DE_NEUROLOGIA
Tratamiento_antiagregante 93 92 42 1 0.681 0.687 0.989 0.811
SECCION_ANTECEDENTES_PATOLOGICOS 91 91 6 0 0.938 0.938 1.000 0.968
SECCION_TRATAMIENTO_AL_ALTA 91 87 3 4 0.926 0.967 0.956 0.961
Tratamiento_anticoagulante 86 86 123 0 0.411 0.411 1.000 0.583
SECCION_EXPLORACIONES_COMPLEMENTARI 75 70 2 5 0.909 0.972 0.933 0.952
AS_EN_URGENCIAS
SECCION_SITUACION_FUNCIONAL 72 67 0 5 0.931 1.000 0.931 0.964
Arteria_afectada 64 60 27 4 0.659 0.690 0.938 0.795
Lateralizacion 59 49 8 10 0.731 0.860 0.831 0.845
SECCION_TIPO_DE_INGRESO 53 53 0 0 1.000 1.000 1.000 1.000
Hora_inicio_trombectomia 52 0 0 52 0.000 0.000 0.000 0.000
SECCION_PROCEDIMIENTOS 50 50 1 0 0.980 0.980 1.000 0.990
SECCION_EXPLORACION_FISICA_AL_ALTA 46 46 0 0 1.000 1.000 1.000 1.000
SECCION_ANTECEDENTES_PERSONALES 42 40 0 2 0.952 1.000 0.952 0.976
SECCION_RECOMENDACIONES 42 40 0 2 0.952 1.000 0.952 0.976
Hora_recanalizacion 41 0 0 41 0.000 0.000 0.000 0.000
SECCION_MOTIVO_DEL_ALTA 40 0 0 40 0.000 0.000 0.000 0.000
Hora_primera_serie_trombectomia 36 0 0 36 0.000 0.000 0.000 0.000
Hora_fin_trombectomia 32 0 0 32 0.000 0.000 0.000 0.000
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 18 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
SECCION_ANTECEDENTES_QUIRURGICOS 32 18 4 14 0.500 0.818 0.562 0.667
Localizacion 31 29 35 2 0.439 0.453 0.935 0.611
SECCION_CONTROL 31 31 0 0 1.000 1.000 1.000 1.000
Test_de_disfagia 27 24 0 3 0.889 1.000 0.889 0.941
Tiempo_puerta_aguja 22 0 0 22 0.000 0.000 0.000 0.000
Hemorragia_cerebral 18 17 3 1 0.810 0.850 0.944 0.895
Hora_TAC 17 0 0 17 0.000 0.000 0.000 0.000
SECCION_ANTECEDENTES_FAMILIARES 10 10 0 0 1.000 1.000 1.000 1.000
SECCION_DIAGNOSTICO_PRINCIPAL 10 10 0 0 1.000 1.000 1.000 1.000
SECCION_DIAGNOSTICOS_SECUNDARIOS 9 9 0 0 1.000 1.000 1.000 1.000
Ataque_isquemico_transitorio 8 4 3 4 0.364 0.571 0.500 0.533
ALL 5710 5012 894 698 0.759 0.849 0.878 0.863
Table 3 Performance of the rule based pre-annotation system. With: number of examples (ex), true positives (tp),
false positives (fp), false negatives (fn) accuracy (acc), precision (pre), recall (rec) and F1.
When considering header sections alone, the performance is much better, reaching and average
F1 score of 95%. For diagnosis related variables the system gets 82.21% in F1. The score in this
case is lower because diagnosis variables are ‘context sensitive’ and this poses an additional
problem. Note that, when comparing the results with the table above, the precision is much lower
compared to recall, as the system produces more false positives. The results demonstrate that
context sensitive variables produce false positives.
tag ex tp fp fn acc pre rec f1
Arteria_afectada 64 60 27 4 0.659 0.690 0.938 0.795
Ataque_isquemico_transitorio 8 4 3 4 0.364 0.571 0.500 0.533
Etiologia 110 88 17 22 0.693 0.838 0.800 0.819
Hemorragia_cerebral 18 17 3 1 0.810 0.850 0.944 0.895
Ictus_isquemico 117 104 4 13 0.860 0.963 0.889 0.924
Lateralizacion 59 49 8 10 0.731 0.860 0.831 0.845
Localizacion 31 29 35 2 0.439 0.453 0.935 0.611
ALL 407 351 97 56 0.696 0.783 0.862 0.821
Table 4 Performance of the rule-based pre-annotation system for diagnosis variables
6. DEEP LEARNING METHODS
As introduced in Section 1, we used neural networks to generate a domain specific language
model and, then, we adapted the model (fine tuned it) to a specific task (i.e. Named Entity
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 19 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Recognition, NER). To generate a biomedical language model we need large amounts of
biomedical data. We created this biomedical corpora gathering data from a variety of medical
resources, namely scientific literature, clinical cases and crawled data. We cleaned each corpus
independently applying a cleaning pipeline with customized operations designed to read data in
different formats, split into sentences, detect the language, remove noisy and bad-formed
sentences, finally deduplicate and eventually output the data with their original document
boundaries. Finally, in order to avoid repetitive content, we concatenated the entire corpus and
deduplicate again between them. Table 5 shows detailed information related to each dataset
before and after the cleaning process, in terms of data size, number of sentences and tokens.
Table 5 The Biomedical corpus
We used the resulting corpora to train a Roberta-base model with 12 layers/heads and a hidden
layer sizes of 768 for a total number of 126M parameters. We kept the original Roberta hyper-
parameter configuration and trained with a masked language model objective. The model was
trained for 48 hours using 16 NVIDIA V100 GPUs of 16GB DDRAM. After training, we selected as
the best model the checkpoint that achieved the lowest perplexity. Note that, it turned out that
the best model for perplexity matched the best model for loss.
Then, we adapted the model to the clinical domain by further pre-training with 120MB of clinical
textual data (including nearly 34MB of ICTUSnet data provided by AQuAS, Son Espases and IACS).
The data was preprocessed using a cleaning pipeline with customized operations designed to
read data, split documents into sentences, detect the language, and remove noisy and bad-
formed sentences. Specifically, the pipeline applies statistical language models, heuristic filters,
and hand-written preprocessing rules to keep the documents with the most quality, and restore
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 20 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
or discard sentences that are probably bad-formed or too noisy. Also, the text is formatted such
that it can be input to the model. At the end of the process we ended with 151MB of cleaned
clinical textual data.
We started from the best model checkpoint obtained on the biomedical corpora and continued
the training with two different strategies based on the learning rate, thus generating two models:
Initializing the learning rate to the same value used at the beginning of the training with
biomedical data. We discharged this model based on a preliminary evaluation.
Use the learning rate value reached by the best checkpoint trained on the biomedical
corpora.
We decided to stop the training using an early stopping method on perplexity score with patience
of 20 epochs and delta of 0.01 perplexity units.
Finally, to evaluate the resulting two models, we fine-tuned them for Named Entity Recognition
(NERC) task over the ICTUSNet dataset. The dataset was split into train, dev and test sets with
standard 80-10-10 proportions. We fine-tuned for 10 epochs and for each model we selected the
best epoch validating on the dev set. For easy of reading, we reproduce here again part of the
figure about the methodology in Section 1.
Figure 15 Deep learning process
The evaluation method
We first split the annotated data (Gold Standard) as follows: 80% for train (656 documents), 10%
for valid (83 documents), and 10% for test (83 documents). When splitting, we maintained the
same percentage of each of the 3 diagnoses in the splits (ischemic stroke, transient ischemic
attack and cerebral hemorrhage). Note that, due to the small number of documents, and the
imbalance between these diagnoses, there was a risk that there would be no examples in
validation or in test.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 21 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Then we moved the annotations from the BRAT standoff format to the BIO/IOB (beginning, inside,
outside) format, which is a very common tag format for NER. The prefix "B" in front of a Tag
indicates the beginning of a chunk, and an "I" indicates that we are still inside that chunk. The "O"
tag is used to indicate that a token does not correspond to any of the entities to be tagged.Table
6shows an example of a tag phrase in BIO format with one token per line.
token tag
Vive O
con O
su O
esposa O
, O
independiente O
para O
ABVD O
, O
mRs B-mRankin_previa
O I-mRankin_previa
. O
Table 6 BIO/IOB format for evaluation
We used both the Biomedical model and the Clinical model to generate the predictions using the
test set and compared them against the correct annotations
Given the high number of tokens assigned to the class "O", we do not take them into account for
the case where both for the predictions and the GS we have an O label (this avoids raising the
result by the fact that O is the majority class, i.e. that the vast majority of tokens do not belong to
any of the entities). Following the previous example inTable 6, only the columns marked in gray
in Table 7 would be evaluated (in red text the wrong ones, in green text the correct predictions):
token GS prediction
Vive O O
con O O
su O O
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 22 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
esposa O O
, O O
independiente O O
para O O
ABVD O B-Antecedente
, O O
mRs B-mRankin_previa B-mRankin_previa
0 I-mRankin_previa I-mRankin_previa
. O O
Table 7 Evaluating annotations
Once the lines with double O were removed, we evaluated the model using standard metrics:
accuracy, precision, recall and F1.
In the case of dates and times, the system must provide us with 1) the normalized date or time,
and 2) the textual evidence that supports for the previous normalized data or time. As we saw in
Section 2, the textual evidences of temporal entities vary greatly in their length, from just the
date/time, to full sentences. In this scenario, we only evaluate a prediction as correct if and only
if the normalization is exactly the same and the span of the prediction and the human annotation
overlap. If the normalization matches, but the spans do not correspond to the same snippet of
text, the prediction is considered incorrect. Similarly, if the text spans correspond to the same
snippet, but the normalization does not match, the prediction is considered wrong. In the
following lines we give some examples of correct/incorrect time predictions. For each example,
the first image corresponds to the GS and the second one corresponds to the prediction.
In this example, the spans are clearly different but the tag and the normalized time (19:50) are
the same, consequently the annotation is correct.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 23 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Again, in this example the two spans are different (note the extra h in the second one) but the tag
and the normalized time (13:03) are the same. This is a correct prediction.
Once more, in this new example, the spans are different but the tag and the normalized time
expression (13:33) are correct.
Finally, in this example, the prediction clearly fails as it predicts two time tags that are not encoded
in the gold standard (image on top).
7. RESULTS
Table 8 below shows the initial results for each variable listed by frequency order. As we can see
in Figure 16, a good number of variables (15 out o 51) are above 95% in F1 score and almost half
of the variables (24 out of 51) are between 76% and 95%. Only 14 variables are below 76% in F1.
We marked in red the low results.
Variable ex acc pre rec F1
TAC_craneal 621 0.964 0.961 0.984 0.973
NIHSS_previa 383 0.461 0.507 0.687 0.584
NIHSS 238 0.233 0.310 0.338 0.324
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 24 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
SECCION_EXPLORACIONES_COMPLEMENTARIAS 213 0.930 1.000 0.976 0.988
SECCION_MOTIVO_DE_INGRESO 205 0.976 0.965 0.988 0.976
SECCION_TRATAMIENTO_Y_RECOMENDACIONES_AL_ALTA 200 0.990 1.000 0.976 0.988
SECCION_PROCESO_ACTUAL 192 0.970 0.935 1.000 0.967
SECCION_EXPLORACION_FISICA 179 0.962 0.963 0.975 0.969
NIHSS_alta 167 0.740 0.855 0.810 0.832
Trombolisis_intravenosa 161 0.824 0.814 0.878 0.845
SECCION_TRATAMIENTO_HABITUAL 155 0.905 0.928 0.987 0.957
mRankin_previa 147 0.801 0.817 0.879 0.847
SECCION_EVOLUCION 147 0.936 0.963 0.987 0.975
SECCION_ANTECEDENTES 138 0.935 0.983 0.922 0.952
Trombectomia_mecanica 119 0.741 0.779 0.815 0.797
Ictus_isquemico 117 0.791 0.841 0.879 0.859
mRankin_alta 117 0.765 0.818 0.766 0.791
SECCION_DIAGNOSTICOS 116 0.894 0.953 0.953 0.953
SECCION_EXPLORACION_FISICA_DURANTE_HOSPITALIZACION 111 0.626 0.667 0.833 0.741
Etiologia 109 0.750 0.833 0.727 0.777
SECCION_DESTINO_AL_ALTA 109 1.000 1.000 1.000 1.000
ASPECTS 107 0.702 0.759 0.820 0.788
SECCION_EXPLORACIONES_COMPLEMENTARIAS_EN_PLANTA_ 102 0.570 0.621 0.692 0.655
DE_NEUROLOGIA
SECCION_EXPLORACION_FISICA_EN_URGENCIAS 95 0.735 0.846 0.759 0.800
SECCION_ANTECEDENTES_PATOLOGICOS 93 0.921 0.923 1.000 0.960
SECCION_TRATAMIENTO_AL_ALTA 91 0.905 0.935 0.906 0.921
SECCION_EXPLORACIONES_COMPLEMENTARIAS_EN_URGENCI 75 0.867 0.778 0.840 0.808
AS
Arteria_afectada 74 0.659 0.768 0.811 0.789
SECCION_SITUACION_FUNCIONAL 67 0.792 0.857 0.909 0.882
Lateralizacion 53 0.783 0.870 0.887 0.879
SECCION_TIPO_DE_INGRESO 53 1.000 1.000 1.000 1.000
SECCION_EXPLORACION_FISICA_AL_ALTA 51 0.807 0.810 0.895 0.850
SECCION_PROCEDIMIENTOS 51 0.962 0.955 1.000 0.977
Tratamiento_antiagregante_alta 51 0.828 0.886 0.929 0.907
Tratamiento_anticoagulante_alta 48 0.583 0.745 0.729 0.737
SECCION_RECOMENDACIONES 43 0.851 0.909 0.952 0.930
SECCION_ANTECEDENTES_PERSONALES 42 0.909 0.913 0.913 0.913
SECCION_ANTECEDENTES_QUIRURGICOS 31 0.750 0.690 0.909 0.784
SECCION_CONTROL 31 0.879 0.935 0.935 0.935
Localizacion 28 0.614 0.641 0.962 0.769
Test_de_disfagia 27 1.000 1.000 1.000 1.000
Tratamiento_antiagregante_hab 26 0.893 0.926 0.962 0.943
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 25 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
SECCION_MOTIVO_DEL_ALTA 24 0.000 0.000 0.000 0.000
Tratamiento_anticoagulante_hab 22 0.395 0.484 0.682 0.566
Hemorragia_cerebral 18 0.536 0.500 0.727 0.593
Tratamiento_anticoagulante 17 0.292 0.311 0.824 0.452
Tratamiento_antiagregante 15 0.565 0.619 0.867 0.722
SECCION_ANTECEDENTES_FAMILIARES 10 0.833 0.833 1.000 0.909
SECCION_DIAGNOSTICOS_SECUNDARIOS 9 0.889 0.750 0.750 0.750
Ataque_isquemico_transitorio 8 0.333 0.750 0.500 0.600
mRankin 8 0.176 0.286 0.500 0.364
SECCION_DIAGNOSTICO_PRINCIPAL 8 0.364 0.500 0.500 0.500
ALL 5322 0.765 0.833 0.887 0.859
Table 8 Initial results for all variables, Biomedical model
Figure 16 Initial F1 results histogram for the Biomedical model
When analysing the low results in detail, we see that most of them are for low frequency variables
and/or have to do with the previa/alta distinction discussed in Section 2. Low frequency variables
are difficult to assess, models need sufficient examples to learn and we cannot draw any
conclusions beyond noting the lack of sufficient data. Especially critical is the case of NHISS
variables on top of the table. Here, the system clearly fails to distinguish between previa/alta. In
most cases, the model correctly assigned the right label in the B(igining)part of the annotation
(see Table 7), but assigned a wrong label in the following I(nside) parts of the annotation. Instead
of defining a script that forced a label matching between B and I parts of the tags, we decided to
collapse tags and ignore this previa/alta distinction. As discussed in Section 5, for the task in hand,
we considered that suggesting high quality underspecified tags and ask users to classify them was
a better strategy than producing low quality pre-annotations. Correcting wrong pre-annotations
is a hard task and causes distrust in the system. Consequently, we prepared a new gold standard
dataset where these previa/alta tags were replaced by underspecified tags and run again the
evaluation.
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 26 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Biomedical and clinical models
In the following lines we report and compare the eventual results for the Biomedical and Clinical
models. See ANNEX 3 and ANNEX 4 further information about the results for each model.
Table 9 shows the global average results comparing both models. As we can see, the differences
in true positives and F1 are minimal and show that retraining with clinical data has not brought
any advantage to the system. From the results in the table, we can only point out that the
Biomedical model has 5.48% more false positives than the Clinical model, and 6.36% less false
negatives. In any case the differences in accuracy, precision and recall are insignificant.
Model Examples Tp Fp Fn Acc Pre Rec F1
Biomedical 5455 5125 675 330 0.836 0.884 0.940 0.911
Clinical 5455 5104 638 351 0.838 0.889 0.936 0.912
Table 9 Global average results comparing Biomedical and Clinical models
In Table 10, we compare the results for all variables. For each variable, we give the frequency, the
F1 score in both models and the difference between them (diff column). We highlighted the
variables having a difference greater than 3%. As we can see, (i) main differences are for less
frequent variables and, (ii) of these, the time variables are better predicted by the clinical model.
tag examples Biomedical Clinical diff
NIHSS 786 0.847 0.830 1.7
TAC_craneal 625 0.983 0.983 0.0
mRankin 275 0.961 0.966 -0.5
SECCION_EXPLORACIONES_COMPLEMENTARIAS 217 0.954 0.954 0.0
SECCION_MOTIVO_DE_INGRESO 203 0.983 0.974 0.9
SECCION_TRATAMIENTO_Y_RECOMENDACIONES_AL_ALTA 200 0.980 0.990 -1.0
SECCION_PROCESO_ACTUAL 185 0.981 0.981 0.0
SECCION_EXPLORACION_FISICA 177 0.969 0.972 -0.3
SECCION_TRATAMIENTO_HABITUAL 155 0.937 0.950 -1.3
SECCION_EVOLUCION 147 0.964 0.961 0.3
Trombolisis_intravenosa 146 0.925 0.906 1.9
SECCION_ANTECEDENTES 137 0.974 0.962 1.2
SECCION_EXPLORACION_FISICA_DURANTE_HOSPITALIZACION 136 0.842 0.803 3.9
Trombectomia_mecanica 122 0.799 0.816 -1.7
SECCION_EXPLORACION_FISICA_EN_URGENCIAS 121 0.886 0.836 5.0
Ictus_isquemico 117 0.895 0.896 -0.1
SECCION_DESTINO_AL_ALTA 113 0.968 0.968 0.0
Etiologia 110 0.854 0.861 -0.7
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 27 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
SECCION_DIAGNOSTICOS 110 0.943 0.960 -1.7
ASPECTS 107 0.811 0.869 -5.8
SECCION_EXPLORACIONES_COMPLEMENTARIAS_EN_PLANTA_ 104 0.755 0.813 -5.8
DE_NEUROLOGIA
Tratamiento_antiagregante 93 0.882 0.875 0.7
SECCION_ANTECEDENTES_PATOLOGICOS 91 0.937 0.937 0.0
SECCION_TRATAMIENTO_AL_ALTA 91 0.941 0.945 -0.4
Tratamiento_anticoagulante 86 0.667 0.687 -2.0
SECCION_EXPLORACIONES_COMPLEMENTARIAS_EN_URGENCI 75 0.938 0.938 0.0
AS
SECCION_SITUACION_FUNCIONAL 72 0.966 0.973 -0.7
Arteria_afectada 64 0.756 0.764 -0.8
Lateralizacion 59 0.875 0.850 2.5
SECCION_TIPO_DE_INGRESO 53 0.981 0.991 -1.0
SECCION_PROCEDIMIENTOS 50 0.961 0.980 -1.9
SECCION_EXPLORACION_FISICA_AL_ALTA 46 0.893 0.893 0.0
SECCION_ANTECEDENTES_PERSONALES 42 0.988 0.988 0.0
SECCION_RECOMENDACIONES 42 0.864 0.930 -6.6
SECCION_MOTIVO_DEL_ALTA 40 1.000 1.000 0.0
SECCION_ANTECEDENTES_QUIRURGICOS 32 0.853 0.870 -1.7
Localizacion 31 0.703 0.714 -1.1
SECCION_CONTROL 31 0.921 0.984 -6.3
Test_de_disfagia 27 1.000 1.000 0.0
Hora_TAC 22 0.750 0.842 -9.2
Tiempo_puerta_aguja 18 0.955 0.978 -2.3
Hora_primer_bolus_trombolisis_rtPA 18 0.895 0.919 -2.4
Hemorragia_cerebral 17 0.684 0.743 -5.9
Hora_recanalizacion 10 0.667 0.909 -24.2
SECCION_ANTECEDENTES_FAMILIARES 10 0.909 0.824 8.5
SECCION_DIAGNOSTICO_PRINCIPAL 9 0.842 1.000 -15.8
Hora_inicio_trombectomia 9 1.000 0.941 5.9
SECCION_DIAGNOSTICOS_SECUNDARIOS 8 0.941 0.533 40.8
Ataque_isquemico_transitorio 6 0.615 0.769 -15.4
Hora_primera_serie_trombectomia 5 0.600 0.600 0.0
Hora_fin_trombectomia 5 1.000 1.000 0.0
ALL 5455 0.911 0.912 -0.097
Table 10 Comparing Biomedical and Clinical models
Figure 17 displays the differences between the models. Blue line shows the frequency of the
variables whereas the yellow line shows the differences between the F1 scores in the two models.
When the values are positive, the Biomedical model outperforms the clinical one. When the
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 28 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
values are negative, the Clinical model outperforms the biomedical one. The closer to 0, the more
equal the results are between the two models. Clearly, the largest differences are found among
the less frequent variables.
Figure 17 Differences between Biomedical and Clinical models.
Summary and conclusions
The information extraction task was complex and ambitious, with 51 different types of
variables.
The manual annotation phase was laborious and long, due to the difficulty of the task and the
lack of clear criteria. Only the tremendous effort dedicated by the annotation team, the
technological support team, and the experts defining the annotation guidelines made it
possible to obtain an eventual gold standard of quality.
Even so, and from today's perspective, we believe that a better selection of the variables
would have yielded better results without detriment to the interest of the project.
In most cases, the variables were what we have called 'context-dependent', which adds an
extra difficulty of the task.
Temporal variables are a case apart: in most cases the textual evidence shows an enormous
variety. Such is the variety that, for the pre-annotation tool, we decided not to address the
coding of these variables and limited ourselves to coding dates and times without going any
further.
The results of the deep learning models are pretty good, reaching 91% F1 on average. That
is without applying any other (post)-process for system improvement. In this exercise we just
wanted to evaluate the performance of deep learning techniques.
The model managed to learn complex aspects such as the 'context sensitivity' (this is very
clear in the diagnostic variables, for example).
The model managed to successfully learn the complex temporal variables that we had given
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 29 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
up in the rule based system. In the following table we can see the good performance despite
the low frequencies.
Time variable Examples Biomedical Clinical
Hora_TAC 22 0.750 0.842
Tiempo_puerta_aguja 18 0.955 0.978
Hora_primer_bolus_trombolisis_rtPA 18 0.895 0.919
Hora_recanalizacion 10 0.667 0.909
Hora_inicio_trombectomia 9 1.000 0.941
Hora_primera_serie_trombectomia 5 0.600 0.600
Hora_fin_trombectomia 5 1.000 1.000
Figure 18 Performance for time variables
Retraining with clinical data does not improve the model. We believe that (i) more clinical
data (from the stroke domain) would have a better impact and (ii) mixing data from the
very beginning would have positive effect, but this remains to be demonstrated
In any case, we are very satisfied with the results obtained and they demonstrate that the
use of language technologies can be of great help in challenging clinical information
extraction tasks, as in the case of ICTUSnet.
Code & Demos
The code for the “(Pre)-annotation Pipeline for the ICTUSnet Project” described in this document
is dockerised and freely available in the Docker Hub repository
(https://hub.docker.com/r/bsctemu/ictusnet) to ease its deployment and distribution. The
repository contains two different pipelines (tags):
bsctemu/ictusnet:ctakes – with the Initial version based on the Apache cTAKES.
bsctemu/ictusnet:deeplearning – with the Deep Learning version based on transformers.
Since the Docker repository is linked to GitHub (https://github.com/TeMU-BSC/ictusnet-ctakes),
at any new commit in the GitHub repository, the Docker is automatically updated.
We developed a demo; these are the links to the demo, the demo’s code in GitHub and the
video tutorial:
Link to the demo: http://temu.bsc.es:81/ (see the screen shoot below)
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 30 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
Link to GitHub demo’s code: https://github.com/TeMU-BSC/ictusnet-webapp
Link to the a video tutorial on YouTube:
https://www.youtube.com/watch?v=uXfAtjK_MqA
Figure 19 Screenshot of the prototype demo
We also provide a link to the BRAT annotation tool, where we can compare the annotations of
the gold standard with the predictions made by the deep learning system
https://temu.bsc.es/ICTUSnet/diff.xhtml?diff=%2FICTUSnet_time_variables_and_gs%2Ftest_bra
t_gs%2F#/ICTUSnet_time_variables_and_gs/normalized_times_test_predictions_brat/32376706
2.utf8
Figure 20 Screenshot of the BRAT tool comparing GS (left) and predictions (right)
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 31 of 65Project Acronym: ICTUSnet
Project code: SOE2/P1/E0623
8. USAGE GUIDELINES
The instructions for the installation and execution of the annotation tool are listed in the
readme file of the repository on GitHub https://github.com/TeMU-BSC/ictusnet-deeplearning
To see a running example of the system, integrated in a web application, see the live demo tool
at http://temu.bsc.es:81/. The link to he demo’s code is in GitHub https://github.com/TeMU-
BSC/ictusnet-webapp
The Deliverable 2.2 gives further details about the demo and how to integrate the system in a
web application.
9. LIST OF FIGURES
Figure 1: General schema for model generation and model tuning ................................. 7
Figure 2 Iterative (pre)-annotation process ..................................................................... 8
Figure 3 Manual annotation process ............................................................................... 8
Figure 4: General overview of the methodology .............................................................. 9
Figure 5Headers’ annotations in BRAT style. ................................................................ 10
Figure 6 Predictions suggested by the automatic pre-annotation tool ........................... 11
Figure 7 Diagnosis annotations in BRAT format............................................................ 11
Figure 8 Annotation of procedures ................................................................................ 12
Figure 9 Annotations in BRAT style for “Trombolisisintravenosa” and “Hora inicio primer
bolus de la trombólisisrtPA”. ......................................................................................... 12
Figure 10 Additional annotation examples for procedures ............................................. 12
Figure 11Annotation of TAC craneal and its associated temporal information ............... 13
Figure 12 Annotation of treatments ............................................................................... 13
Figure 13 NIHSS annotation example with a complex numerical sequence .................. 14
Figure 14 mRanking annotation examples .................................................................... 14
Figure 15 Deep learning process .................................................................................. 21
Figure 16 Initial F1 results histogram for the Biomedical model .................................... 26
Figure 17 Differences between Biomedical and Clinical models. .................................. 29
Figure 18 Performance for time variables ..................................................................... 30
Figure 19 Screenshot of the prototype demo ................................................................ 31
Figure 20 Screenshot of the BRAT tool comparing GS (left) and predictions (right) ...... 31
Figure 21 Final F1 histogram for the Biomedical model ................................................ 39
Figure 22 F1 histogram for the Clinical model ............................................................... 41
ICTUSnet: E2.4Development of supervised categorization models, topic modelling and extraction of clinical
information via cognitive computing. 30/04/2021
02 Page 32 of 65You can also read

















































