INTELLIGENZA ARTIFICIALE AL SERVIZIO DELLA SCUOLA SCENARI E OPPORTUNITÀ - 28 giugno 2019 Alghero Fiorella Operto Scuola di Robotica
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

INTELLIGENZA ARTIFICIALE AL SERVIZIO DELLA SCUOLA SCENARI E
OPPORTUNITÀ
28 giugno 2019
Alghero
Fiorella Operto
Scuola di Robotica
L’INTELLIGENZA ARTIFICIALE SOSTITUIRÀ I DOCENTI UMANI?
OGGI, TUTTI STIAMO IMPARANDO TRAMITE IA
E-LEARNING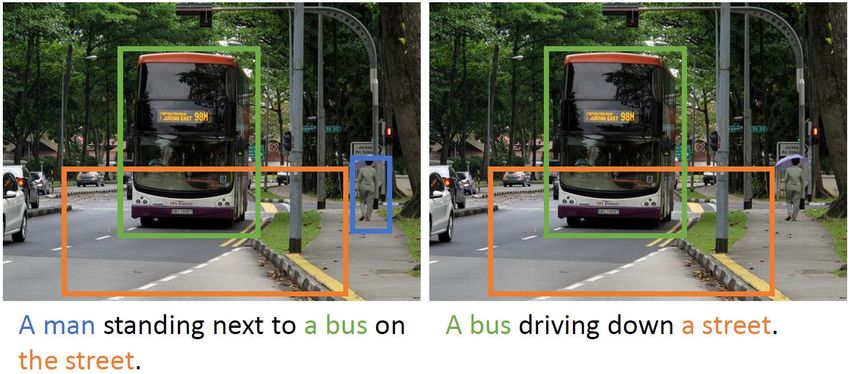
Seamless, Spotify, Airbnb, Pocket…
DISRUPTING INNOVATION?

The digital skills gap in Europe Having a digitally skilled labour force and population, more broadly, is crucial for the creation of a Digital Single Market in Europe and for receiving its benefits, for European competitiveness and for an inclusive digital society. Currently, however, 44% of European citizens do not have basic digital skills. 37% of people in the labour force – farmers, bank employees, and factory workers alike – also lack sufficient digital skills, despite the increasing need for such skills in all jobs. Europe also lacks skilled ICT specialists to fill the growing number of job vacancies in all sectors of the economy. A crucial issue underpinning this is the need to modernise our education and training systems, which currently do not prepare young people sufficiently for the digital economy and society, and to move to a life-long learning approach so that people can adapt their skills sets throughout their life-times as needed. https://ec.europa.eu/digital-single-market/en/digital-skills-jobs-coalition

"R-learning lesson nella Korea del Sud

IA A SCUOLA
CONTENERE I COSTI
I DATI: ANALIZZATI DA IA (UNA VOLTA IN MANUALE)
AGGIORNAMENTO DEI PROGRAMMI IN TEMPI RAPIDI
EDUCAZIONE PERMANENTE (LIFE-LONG LEARNING)
PERSONALIZZAZIONE DEI PROGRAMMI
MODELLATI SULLO/A STUDENTE
IL GENDER NELL’EDUCAZIONE
INCLUSIONE
Intelligent Tutoring Systems
Apprendimento delle lingue (Automatic Speech Recognition (ASR)
Correzione difetti di pronuncia
Correttori di refusi
https://app.grammarly.com
ROBOTICA EDUCATIVA
Olimpiadi di Robotica First Lego League NAO Challenge
BYOR JUNIOR •Sensore di luce •Sensore di umidità •4x LED (bianco, rosso, verde, blu)
ROBOETICA PROBLEMI SINGULARITY? PIU’ PROSAICAMENTE… PERDITA DI POSTI DI LAVORO PRIVACY ADDICTION DIGITAL DIVIDE HUMAN IN HERARCHY DIVENTARE PIU’ UMANI
GRAZIE! ☺ operto@scuoladirobotica.it
Intelligenza e Visione Artificiale:
tecnologie e opportunità per il mondo Education
Lorenzo Baraldi
{name.surname}@unimore.it
University of Modena and Reggio Emilia, ItalyAIMAGELAB Who • 6 Staff people (Professors and Researchers) • 12 PhD Students • 5 Research assistants, SW developers • 3 (ex) spinoff companies Open collaborations • Facebook FAIR (F), Eurecom (F) • Panasonic (USA) • Ferrari (I), Maserati (I) • CNR (I) • MIUR, EU and Italian public bodies • Italian SuperComputing Resource Allocation – CINECA • Computer Vision Foundation, CVPL-IAPR, AIXIA Aimage Lab UNIMORE and Ferrari spa
THIS TALK
Outline
• Introduction to Artificial Intelligence
• AI for Images: Convolutional Neural Networks
• Vision and Language
• Vision, Language and Action
3LEARNING
A neural network: a composition of differentiable functions with learnable parameters.
Once trained, it can predict an output.
Input: Output:
Artificial
Sensors Intelligence Movement
Data Text
How do we train it?
We define an error (loss) as function of the learnable parameters, then iteratively change the parameters so that
the error is minimized.
4GRADIENT DESCENT How do we train it? We define an error (loss) as function of the learnable parameters, then iteratively change the parameters so that the error is minimized.
LEARNING
Machine Learning is a type of Artificial Intelligence that provides
computers with the ability to learn without being explicitly
programmed.
Machine Learning
Algorithm
Labeled Data
Training
Prediction
Learned Model Prediction
Data
Provides various techniques that can learn from and make predictions on data
6CONVOLUTIONAL NEURAL NETWORKS
7CONVOLUTIONAL NEURAL NETWORKS
Class Scores
Cat: 0.9
Dog: 0.05
Fully-Connected: Car: 0.01
4096 to 1000 ...
Vector:
4096CONVNETS ARE EVERYWHERE
Detection Segmentation
[Farabet et al., 2012]
[Faster R-CNN: Ren, He, Girshick, Sun 2015]CONVNETS ARE EVERYWHERE [Taigman et al. 2014] [Simonyan et al. 2014]
MASK-RCNN ALSO DOES POSE He et al, “Mask R-CNN”, arXiv 2017
F
L
e NEURAL STYLE TRANSFER
e
ic
-t
F
u
e
ri
e
L
1
i
3
&
J-
u
s
t
i
n
JDumoulin, Shlens, and Kudlur, “A Learned Representation for Artistic Style”, ICLR 2017.
o
h 84 May 17, 2018VISUAL-SEMANTIC RETRIEVAL
Beyond tags and pre-defined concepts: embed text and images into common embedding spaces
Query caption: four men standing, one with an Query caption: brown teddy bear with glasses Query caption: two beach chairs and a white
entire bunch of carrots in his mouth. sitting on blue couch. and red umbrella at a beach.
CyTIR-Net txt2img CyTIR-Net txt2img CyTIR-Net txt2img
Query caption: a man on a snowboard using a Query caption: a man surfing on a blue green Query caption: a woman riding a bike down a
parachute. wave. street next to a divider.
CyTIR-Net txt2img CyTIR-Net txt2img CyTIR-Net txt2img
M. Cornia, L. Baraldi, H.R. Tavakoli, R. Cucchiara. “CyTIR-Net: a Unified Cycle-Consistent Neural Model for Text and Image Retrieval.”
ECCVW 2017.SPEAKING THE SAME LANGUAGE: GENERATING DESCRIPTIONS
..a white shark swims
+ in the ocean water..
CONV-NET Recurrent NET (LSTM)
Generated caption: A woman is Generated caption: A boat is in the Generated caption: A woman in a red
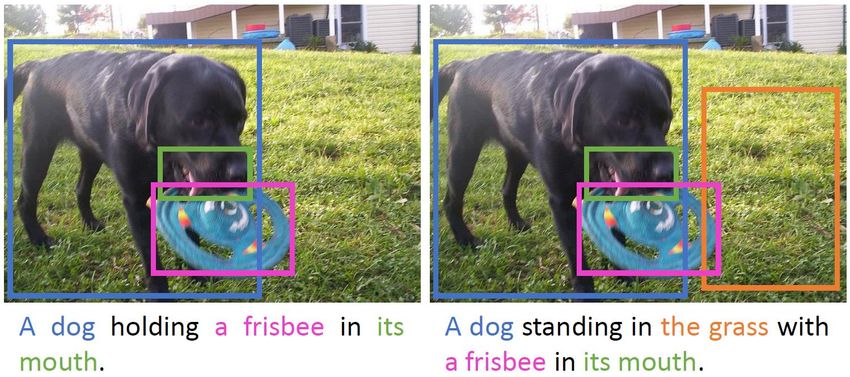
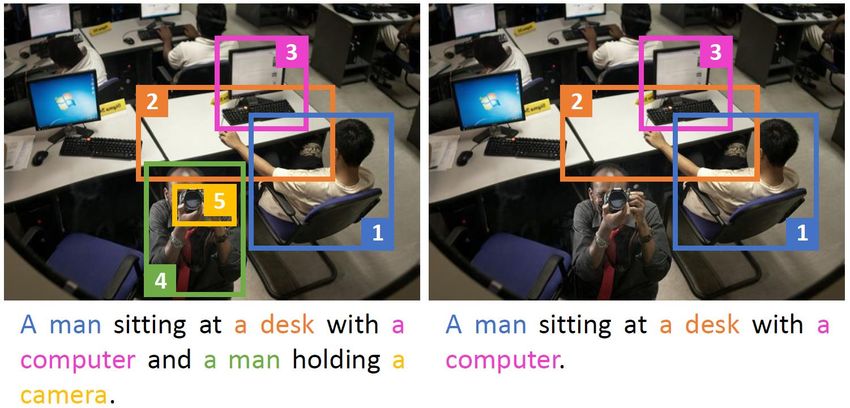
looking at a television screen. water near a large mountain. jacket is riding a bicycle.QUALITATIVE RESULTS GT: A large passenger jet sitting on top of an airport runway. Prediction: A large jetliner sitting on top of an airport runway. GT: Family of five people in a green canoe on a lake. Prediction: A group of people sitting on a boat in a lake. GT: Two people in Swarthmore College sweatshirts are playing frisbee. Prediction: A man and a woman are playing frisbee on a field.
CONTROLLABLE CAPTIONING
To extend captioning to unknown domains, we decompose
the problem of captioning as that of attending a sequence
of regions. Potentially:
• We can include out-of-vocabulary words which are not
found in the training set.
• We can control which regions are described and in
which order, and give more importance to important
classes rather than to useless classes.
M. Cornia, L. Baraldi, R. Cucchiara, Show, control and Tell: A
Framework for generating Controllable and Grounded
Captions, CVPR 2019.CONTROLLABLE IMAGE CAPTIONING Results when Controlling with a sequence of regions [1] Cornia Marcella, Lorenzo Baraldi, and Rita Cucchiara. "Show, Control and Tell: A Framework for Generating Grounded and Controllable Captions." CVPR 2019.
CONTROLLABLE IMAGE CAPTIONING Results when Controlling with a set of regions [1] Cornia Marcella, Lorenzo Baraldi, and Rita Cucchiara. "Show, Control and Tell: A Framework for Generating Grounded and Controllable Captions." CVPR 2019.
CONTROLLABLE IMAGE CAPTIONING Results when Controlling with a set of regions [1] Cornia Marcella, Lorenzo Baraldi, and Rita Cucchiara. "Show, Control and Tell: A Framework for Generating Grounded and Controllable Captions." CVPR 2019.
CONNECTING VISION, LANGUAGE AND ACTIONS
• The navigation goal is given by a
natural language instruction;
• Visual information helps
progressing towards the target;
• The agent must know when to
stop (i.e. goal reached).VISION AND LANGUAGE NAVIGATION
Agent position (and next action)
Dynamic Response Map
Instruction:
Walk up the stairs.
Turn right at the top of the stairs and walk along the red ropes.
Walk through the open doorway straight ahead along the red carpet.
Walk through that hallway into the room with couches and a marble coffee table.VISION AND LANGUAGE NAVIGATION
Agent position (and next action)
Dynamic Response Map
Instruction:
Walk up the stairs.
Turn right at the top of the stairs and walk along the red ropes.
Walk through the open doorway straight ahead along the red carpet.
Walk through that hallway into the room with couches and a marble coffee table.VISION AND LANGUAGE NAVIGATION
Agent position (and next action)
Dynamic Response Map
Instruction:
Walk up the stairs.
Turn right at the top of the stairs and walk along the red ropes.
Walk through the open doorway straight ahead along the red carpet.
Walk through that hallway into the room with couches and a marble coffee table.VISION AND LANGUAGE NAVIGATION
Agent position (and next action)
Dynamic Response Map
Instruction:
Walk up the stairs.
Turn right at the top of the stairs and walk along the red ropes.
Walk through the open doorway straight ahead along the red carpet.
Walk through that hallway into the room with couches and a marble coffee table.VISION AND LANGUAGE NAVIGATION
Agent position (and next action)
Dynamic Response Map
Instruction:
Walk up the stairs.
Turn right at the top of the stairs and walk along the red ropes.
Walk through the open doorway straight ahead along the red carpet.
Walk through that hallway into the room with couches and a marble coffee table.26
Thank you!
aimagelab.ing.unimore.it
Marcella Cornia Matteo Tomei Federico Landi Matteo Stefanini Lorenzo Baraldi Massimiliano Corsini Rita CucchiaraYou can also read

















































