Nvidia Tesla GPU Computing. Revolutionizing High Performance Computing.
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

NVIDIA® TESLA® GPU COMPUTING
REVOLUTIONIZING HIGH PERFORMANCE
COMPUTING
To learn more, go to www.nvidia.com/tesla
©2010 NVIDIA, the NVIDIA logo, CUDA, GPUDirect, Parallel Nsight, and Tesla are trademarks and/or registered trademarks of NVIDIA Corporation
in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are
associated. All rights reserved. 09/2010
GPUS ARE REVOLUTIONIZING COMPUTING
The high performance computing (HPC) industry’s need for
computation is increasing, as large and complex computational
problems become commonplace across many industry segments.
Traditional CPU technology, however, is no longer capable of scaling
in performance sufficiently to address this demand.
The parallel processing capability of the GPU allows it to divide
complex computing tasks into thousands of smaller tasks that can
be run concurrently. This ability is enabling computational scientists
and researchers to address some of the world’s most challenging
computational problems up to several orders of magnitude faster.
“ The convergence of new, fast GPUs optimized
for computation as well as 3-D graphics
acceleration and industry-standard software
development tools marks the real beginning
of the GPU computing era.”
This advancement represents a
Nathan Brookwood
Principal Analyst & Co-Founder, Insight64
From climate modeling to advances in
5X
Adobe digital
content creation
50X
MATLAB Computing
18X
Video Transcoding
Elemental Tech
80X
Weather Modeling
20X
3D Ultrsound
TechniScan
100X
Astrophysics
30X
Gene Sequencing
U of Maryland
146X
Medical Imaging
36X
Molecular Dynamics
U of Illinois, Urbana
149X
Financial Simulation
AccelerEyes Tokyo Institute of Technology RIKEN U of Utah Oxford
dramatic shift in HPC. In addition to medical tomography, NVIDIA® Tesla™
Co-processing refers to dramatic improvements in speed, GPUs are enabling a wide variety of
the use of an accelerator, GPUs also consume less power than segments in science and industry to
such as a GPU, to offload conventional CPU-only clusters. progress in ways that were previously
the CPU to increase GPUs deliver performance increases impractical, or even impossible, due
computational efficiency. of 10x to 100x to solve problems to technological limitations. WHY GPU COMPUTING? As sequential processors, CPUs Tesla GPU computing is delivering
in minutes instead of hours–while are not designed for this type of transformative increases in
With the ever-increasing demand performance for a wide range of HPC
outpacing the performance of computation, but they are adept
for more computing performance, industry segments.
traditional computing with x86-based at more serial based tasks such
the HPC industry is moving toward a
CPUs alone. as running operating systems and
hybrid computing model, where GPUs
organizing data. NVIDIA believes in
and CPUs work together to perform
applying the most relevant processor
general purpose computing tasks.
to the specific task in hand.
Conventional CPU computing As parallel processors, GPUs excel
100x
architecture can no longer support Performance Advantage at tackling large amounts of similar
the growing HPC needs. by 2021
data because the problem can be split
Source: Hennesse]y &Patteson, CAAQA, 4th Edition.
into hundreds or thousands of pieces
and calculated simultaneously.
10000
20% year
1000
Performance vs VAX
52% year
100
10
CPU
25% year GPU
Growth per year
1
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006 2016
NVIDIA TESLA
GPUS ARE REVOLUTIONIZING
COMPUTING
GPU COMPUTING APPLICATIONS The CUDA parallel computing
architecture, with a combination of
Libraries and Middleware
hardware and software.
Language Solutions Device level APIs
Java and
Direct
C C++ Fortran Python OpenCL™
Compute
interfaces
Core comparison between
NVIDIA GPU CUDA Parallel Computing Architecture
a CPU and a GPU.
CPU GPU
Multiple Cores Hundreds of Cores
Parallel critical portions of an application CUDA PARALLEL With support for C++, GPUs based on
Acceleration to take advantage of the hundreds COMPUTING the Fermi architecture make parallel
of parallel cores in the GPU. The ARCHITECTURE processing easier and accelerate
Multi-core programming with x86
rest of the application remains the performance on a wider array of
CPUs is difficult and often results CUDA™ is NVIDIA’s parallel computing
same, making the most efficient use applications than ever before. Just a
in marginal performance gain when architecture. Applications that
of all cores in the system. Running few applications that can experience
going from 1 core to 4 cores to 16 leverage the CUDA architecture can
a function of the GPU involves significant performance benefits
cores. Beyond 4 cores, memory be developed in a variety of languages
rewriting that function to expose include ray tracing, finite element
bandwidth becomes the bottleneck to and APIs, including C, C++, Fortran,
its parallelism, then adding a few analysis, high-precision scientific
further performance increases. OpenCL, and DirectCompute. The
new function-calls to indicate which computing, sparse linear algebra,
CUDA architecture contains hundreds
To harness the parallel computing functions will run on the GPU or the sorting, and search algorithms. The next generation CUDA parallel
of cores capable of running many
power of GPUs, programmers can CPU. With these modifications, the computing architecture, codenamed
thousands of parallel threads, while
“
simply modify the performance- performance-critical portions of the “Fermi”.
application can now run significantly
the CUDA programming model lets
I believe history
programmers focus on parallelizing
faster on the GPU.
their algorithms and not the
will record Fermi as a
mechanics of the language. significant milestone.”
The latest generation CUDA
Dave Patterson
architecture, codenamed “Fermi”, is Director, Parallel Computing
the most advanced GPU computing Research Laboratory, U.C.
Berkeley
architecture ever built. With over
three billion transistors, Fermi is Co-author of Computer
making GPU and CPU co-processing
Architecture: A Quantitative
Approach
pervasive by addressing the full-
spectrum of computing applications.
NVIDIA TESLA
GPUS ARE REVOLUTIONIZING
COMPUTING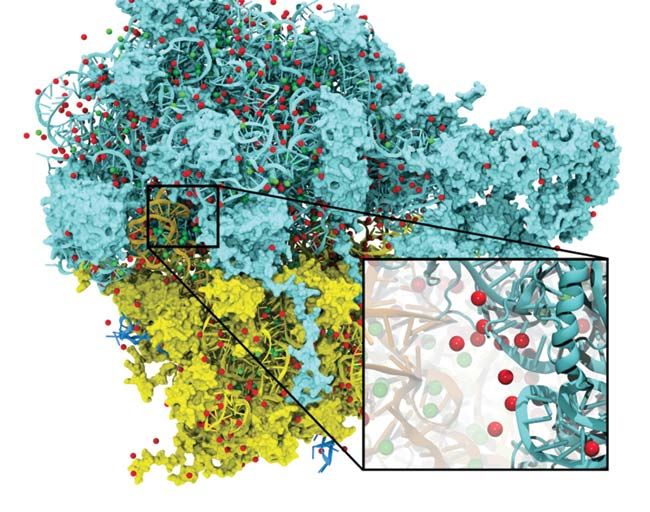
Solution Stone and his team
turned to the NVIDIA CUDA parallel
processing architecture running
and its mutations—but it also bought
them time to make other important
discoveries. Further calculations
“ The benefits of
GPU computing can
on Tesla GPUs to perform their showed that genetic mutations which be replicated in other
molecular modeling calculations and render the swine or avian flu resistant research areas as well.
simulate the drug resistance of H1N1 to Tamiflu had actually disrupted
All of this work is made
mutations. Thanks to GPU technology, the “binding funnel,” providing new
understanding about a fundamental
speedier and more
the scientists could efficiently run
multiple simulations and achieve mechanism behind drug resistance. efficient thanks to GPU
Ribosome for protein synthesis. potentially life-saving results faster.
In the midst of the H1N1 pandemic,
technology, which for us
Impact The GPU-accelerated the use of improved algorithms means quicker results
calculation was completed in just based on CUDA and running on Tesla as well as dollars and
over an hour. The almost thousand- GPUs made it possible to produce
energy saved.” said
WHO BENEFITS FROM GPU University of Illinois: Accelerated molecular fold improvement in performance actionable results about the efficacy
Stone.
COMPUTING? available through GPU computing of Tamiflu during a single afternoon.
modeling enables rapid response to H1N1
Computational scientists and advanced algorithms empowered This would have taken weeks or
and researchers who are the scientists to perform “emergency months of computing to produce
Challenge A first step in This determination involved a the same results using conventional
using GPUs to accelerate computing” to study biological
mitigating a global pandemic, like daunting simulation of a 35,000- approaches.
their applications are problems of extreme current
H1N1, requires quickly developing atom system, something a group
seeing results in days relevance and share their results with
drugs to effectively treat a virus of University of Illinois, Urbana-
instead of months, even the medical research community.
that is new and likely to evolve. This Champaign scientists, led by John
minutes instead of days.
requires a compute-intensive process Stone, decided to tackle in a new way This speed and performance increase
to determine how, in the case of using GPUs. not only enabled researchers to
H1N1, mutations of the flu virus fulfill their original goal—testing
Conducting this kind of simulation on
protein could disrupt the binding Tamiflu’s efficacy in treating H1N1
a CPU would take more than a month
pathway of Tamiflu, rendering it
to calculate...and that would only
potentially ineffective.
amount to a single simulation, not the
multiple simulations that constitute a
complete study.
NVIDIA TESLA
Case Study: University of Illinois
Using imaging devices like a CT Impact GPUs provide 20x more
scan, scientists are able to create computational power and an order
a model of a patient’s circulatory of magnitude more performance
system. From there, an advanced per dollar to the application of
fluid dynamics simulation of the blood image reconstruction and blood
flow through the patient’s arteries flow simulation, finally making such
can be conducted on a computer to
Harvard University: advanced simulation techniques
identify areas of reduced endothelial practical at the clinical level.
Finding Hidden Heart Problems Faster sheer stress on the arterial wall. Without GPUs, the amount of
A complex simulation like this one computing equipment—in terms of
Challenge Heart attacks are the plaque could greatly improve
requires billions of fluid elements to size and expense—would render a
the leading cause of death worldwide. patient care and save lives.
be modeled as they pass through an hemodynamics approach unusable.
Heart attacks are caused when
Solution A team of researchers, artery system. An area of reduced Because it can detect dangerous
plaque that has built up on artery
including doctors at Harvard Medical sheer stress indicates that plaque arterial plaque earlier than any
walls dislodges and blocks the flow
School and Brigham & Women’s has formed on the interior artery other method, it is expected that
of blood to the heart. Up to 80% of
Hospital in Boston, Massachusetts, walls, preventing the bloodstream this breakthrough could save
heart attacks are caused by plaque
have discovered a non-invasive from making contact with the inner numerous lives when it is approved
that is not detectable by conventional
way to find dangerous plaque in a wall. The overall output of the for deployment in hospitals and
320 detector-row CT has enabled medical imaging. Even viewing the
patient’s arteries. Tapping into the simulation provides doctors with research centers.
single heart beat coronary imaging 20% that is detectable requires
so that the entire coronary contrast computational power of GPUs, they an atherosclerotic risk map. The
invasive endoscopic procedures which
opacification can be evaluated at can create a highly individualized map provides cardiologists with the
involve running several feet of tubing
a single time point. The full 3D model of blood flow within a patient in location of hidden plaque and can
course of the arteries, in turn, into the patient in an effort to take
a study of blood flow which is called serve as an indicator as to where
allows researchers to simulate the pictures of arterial plaque.
hemodynamics. stents may eventually need to
blood flowing through it by using
This level of uncertainty with regard placed—and all of this knowledge
computational fluid flow simulations, The buildup of plaque is highly
and subsequently compute the to the exact location of potentially is gained without invasive imaging
correlated to the shape—or
endothelial shear stress. deadly plaque poses a significant techniques or exploratory surgery.
geometry—of a patient’s arterial
challenge for cardiologists.
structure. Bends in an artery tend to
Historically, it has been a guessing
be areas where dangerous plaque is
game for heart specialists to
especially concentrated.
determine if and where to place
arterial stents in patients with
blockages. Knowing the location of
NVIDIA TESLA
Case Study: Harvard University
“
Solution MotionDSP, a software Using NVIDIA Tesla GPUs, MotionDSP’s
company based in San Mateo, customers, which include a variety of With the GPU, we’re
California, has developed “super- military-funded research groups, are bringing better video
resolution” algorithms that allow it making UAVs safer and more reliable to all ISR platforms,
to reconstruct video with better and while reducing deployment costs,
including smaller UAVs.
cleaner detail, increased resolution improving simulation accuracy and
and reduced noise. All of which are dramatically boosting performance.
We’re helping these
ideal for the live streaming of video platforms perform to
impact Using only CPUs to execute
from the cameras attached to a UAV.
the kind of sophisticated video post-
their potential by being
MotionDSP: GPUs increasing importance in MotionDSP’s product, Ikena ISR, processing algorithms required for smarter about how
Armed Forces targets NVIDIA’s CUDA GPU parallel effective reconnaissance would result in we utilize COTS PC
computing architecture allowing it up to six hours of processing for each one
technology.” said Sean
Challenge Unmanned Aerial The challenge is that the resulting to render, stabilize and enhance live hour of video—not a viable solution when
Vehicles (UAVs) represent the latest images need to be rendered, video faster and more accurately than real-time results are critical. In contrast,
Varah, chief executive
in high-tech weaponry deployed stabilized and enhanced in real-time its competitors. Ikena ISR features Tesla GPUs enable MotionDSP’s Ikena officer of MotionDSP.
to strengthen and improve the and across vast distances in order computationally intense, advanced ISR software to process any live video “Our technology makes
military’s capabilities. But with new to be useful and accurate. Once they motion-tracking algorithms that source in real-time with less than 200ms
the impossible possible,
technologies come new challenges, have been processed, the images provide the basis for sophisticated of latency. Moreover, instead of requiring
such as capturing actionable can give infantry critical information image stabilization and super- expensive CPU-clustered computing
and this is making
“Super-resolution” algorithms that intelligence while flying at speeds about potential challenges ahead— resolution video reconstruction. systems to complete the work, Ikena can our military safer and
allow MotionDSP to reconstruct upwards of 140 mph, 10 miles above the end goal being to ensure the Perhaps most importantly, it can all be perform at full capacity on a standard better prepared.”
video with better and cleaner detail, the earth. safety and protection of military run on off-the-shelf Windows laptops workstation small enough to fit inside of
increased resolution and
personnel in the field. and servers. the military’s field vehicles.
reduced noise. One key feature of the UAV is that it
is capable of providing a real-time Using CPUs alone, this process is
stream of detailed images taken with very time consuming and doesn’t
multiple different cameras situated allow information to be viewed
on the vehicle itself. in real-time. As a result, military
action could be based on potentially
outdated intelligence data and
inaccurate guides.
NVIDIA TESLA
Case Study: MotionDSP
Bloomberg: GPUs increase accuracy and reduce
processing time for bond pricing
Challenge Getting mortgage and
buying a home is a complex financial
transaction, and for lenders, the
competitive pricing and management
of that mortgage is an even greater
challenge. Transactions involving
thousands of mortgages at once are
a routine occurrence in financial
markets, spurred by banks that wish
Known as collateralized debt
obligations (CDO) and collateralized
mortgage obligations (CMO), baskets
of thousands of loans are publicly
traded financial instruments. For the
banks and institutional investors who
buy and sell these baskets, timely
pricing updates are essential because
of fast-changing market conditions.
“ One of the challenges Bloomberg always faces is that we have
very large scale. We’re serving all the financial and business
community and there are a lot of different instruments and
models people want calculated. ”
This technique requires calculating
huge amounts of data, from interest
In addition, the capital outlay for the
new GPU-based solution was one-
Shawn Edwards,
CTO, Bloomberg
to sell off loans to get their money
Bloomberg, one of the world’s leading rate volatility to the payment behavior tenth the cost of an upgraded CPU GPU ACCELERATION
back sooner.
financial services organizations, prices of individual borrowers. These data- solution, and further savings are being Large calculations that
CDO/CMO baskets for its customers intensive calculations can take hours realized due to the GPU’s efficient had previously taken up
by running powerful algorithms that to run with a CPU-based computing power and cooling needs. to two hours can now be
model the risks and determine the price. grid. Time is money, and Bloomberg completed in two minutes.
Impact As Bloomberg customers
wanted a new solution that would allow Smaller runs that had
make CDO/CMO buying and selling
them to get pricing updates to their taken 20 minutes can now
decisions, they now have access to
customers faster. be done in just seconds.
the best and most current pricing
Financial engineering is integral to
Solution Bloomberg implemented information, giving them a serious
today’s buying and selling decisions.
an NVIDIA Tesla GPU computing competitive trading advantage in a
solution in their datacenter. By market where timing is everything.
porting this application to run on the
NVIDIA CUDA parallel processing
architecture to harness the power of
GPUs, Bloomberg received dramatic
improvements across the board. Large
calculations that had previously taken
up to two hours can now be completed
in two minutes. Smaller runs that had
taken 20 minutes can now be done in
just seconds.
NVIDIA TESLA
Case Study: Bloomberg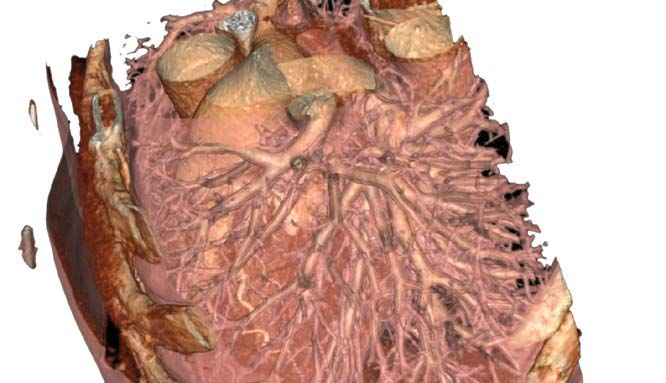
This step change in performance “Access to high
significantly increases the amount of
data that geoscientists can analyze in a
performance,
given timeframe. Plus, it allows them high quality 3D
to fully exploit the information derived computational tools on
from 3D seismic surveys to improve a workstation platform
subsurface understanding and reduce
risk in oil and gas exploration and
drastically changes
exploitation. the productivity
Impact NVIDIA CUDA is allowing ffA
curve in 3D seismic
to provide scalable high performance analysis and seismic
computation for seismic data on interpretation, giving
ffA: Accelerating 3D seismic interpretation hardware platforms equipped with one our users a real edge in
or more NVIDIA Tesla and Quadro FX
GPUs. The latest benchmarking results
oil and gas exploration
Challenge In the search for oil Solution UK-based company ffA
and gas, the geological information provides world leading 3D seismic using Tesla GPUs have produced and de-risking field
streamling with GPUs provided by seismic images of the analysis software and services to the performance improvements of up to development.”
for Better Results 37x versus high end dual quad core
earth is vital. By interpreting the data global oil and gas industry. Its software
produced by seismic imaging surveys, tools extract detailed information from CPU workstations.
40 geoscientists can identify the likely 3D seismic data, providing a greater
30
presence of hydrocarbon reserves and
understand how to extract resources
most effectively. Today, sophisticated
understanding of complex 3D geology,
improving productivity and reducing
uncertainty within the interpretation
“ CUDA-based
PUGs power large
Speedups
20 visualization systems and process. The sophisticated tools are computation tasks
computational analysis tools are used compute-intensive so it can take and interactive
to streamline what was previously a hours, or even days, to produce results
10
subjective and labor intensive process. on conventional high performance
computational
workstations. workflows that we
0 Today, geoscientists must process
Quad-Core Tesla
increasing amounts of data as With the recent release of its
could not hope to
CPU GPU + CPU
dwindling reserves require them CUDA enabled 3D seismic analysis implement effectively
The latest benchmarking to pinpoint smaller, more complex application, ffA users routinely achieve otherwise.” said Steve
results using Tesla GPUs reservoirs with greater speed and over an order of magnitude speed-up Purves, ffA Technical Data courtesy of RMOTC
have produced performance accuracy. compared with performance on high
improvements of up to 37x end multi-core CPUs.
Director.
versus high end dual quad
core CPU workstations.
NVIDIA TESLA
Case Study: ffA
The Shift to Parallel Computing
and the Path to Exascale
Approximately every 10 years, the world of supercomputing experiences a
fundamental shift in computing architectures. It was around 10 years ago when
cluster-based computing largely superseded vector-based computing as the
de facto standard for large-scale computing installations, and this shift saw
the supercomputing industry move beyond the petaFLOP performance barrier.
With the next performance target being exascale-class computing, it is time for
a new shift in computing architectures— the move to parallel computing.
The shift is already underway.
NVIDIA TESLA
GPUS ARE REVOLUTIONIZING
COMPUTING“ Future computing architectures will be hybrid
systems with parallel-core GPUs working in
tandem with multi-core CPUs.”
In November 2008, Tokyo Institute
of Technology became the first
supercomputing center to enter
Jack Dongarra,
University Distinguished Professor at University of Tennessee
What is even more impressive than
its overall performance is the power
that it consumes. Jaguar delivers
“ Five years from
now, the bulk of
serious HPC is going
to be done with some
kind of accelerated
heterogeneous
architecture.” said
Steve Scott, CTO,
Cray, Inc.
and tertiary oil recovery using multi-
scale simulation of porous materials,
the simulation of nano- and micro-
flow in chemical and bio-chemical
processes, and much more.
These computational problems
represent a tiny fraction of the entire
landscape of computational challenges
that we face today and these problems
are not getting any smaller. The sheer
quantity of data that many scientists,
engineers and researchers must “Nebulae”, powered by 4640 Tesla
the Top500 with a GPU-based 1.77 petaFLOPs, yet it consumes analyze is increasing exponentially and 20-series GPUs, is one of the fastest
supercomputers in the world.
hybrid system —a system that more than 7 megawatts of power supercomputing centers are over-
uses GPUs and CPUs together to to do so. To put that into context, 7 subscribed as demand is outpacing
deliver transformative increases megawatts is enough energy to power the supply of computational resources.
CAS is one of the world’s most dynamic
in performance without breaking 15,000 homes. In contrast, Nebulae If we are to maintain our rate of
research and educational facilities.
the bank with regards to energy delivers 1.27 petaFLOPs, yet it does innovation and discovery, we must take
Prof. Wei Ge, Professor of Chemical
consumption. The system, called this within a power budget of just computational performance to a level
Engineering at the Institute of Process
TSUBAME 1.2, entered the list at 2.55 megawatts. That makes it twice where it is 1000 times faster than what
Engineering at CAS, introduced GPU
number 24. as power-efficient as Jaguar. This it is today. The GPU is a disruptive force
computing to the Beijing facility in 2007
TSUBAME 1.2, by Tokyo Institute of difference in computational throughput in supercomputing and represents
Fast forward to June 2010 and to help them with discrete particle and
Technology, was the first Tesla GPU and power is owed to the massively the only viable strategy to successfully
hybrid systems have started to make molecular dynamics simulations. Since
based hybrid cluster to reach Top500. parallel architecture of GPUs, where build exascale systems that are
appearances even higher up the list. then, parallel computing has enabled
hundreds of cores work together affordable and not prohibitive to build
“Nebulae”, a system installed at the advancement of research in dozens
within a single processor, delivering and operate.
Shenzhen Supercomputing Center of other areas, including: real time
unprecedented compute density for
in China, equipped with 4640 Tesla simulations of industrial facilities, the
next generation supercomputers.
20-series GPUs, made its entry into design and optimization of multi-phase
the list at number 2, just one spot Another very notable entry into and turbulent industrial reactors using
behind Oak Ridge National Lab’s this year’s Top500 was the Chinese computational fluid dynamics, the
“Jaguar”, the fastest supercomputer Academy of Sciences (CAS). The “Mole optimization of secondary
in the world. 8.5” supercomputer at CAS uses 2200
Tesla 20-series GPUs to deliver 207
teraFLOPS, which puts it at number 19
in the Top500.
NVIDIA TESLA
The Shift to Parallel
Computing and the Path to
ExascaleNVIDIA TESLA
World’s First Computational GPU
The Tesla brand of products is Highly Reliable
designed for high-performance > ECC protection for
computing, and offers exclusive uncompromised data
computing features. reliability
Superior Performance > Stress tested for zero error
> Highest double precision tolerance
floating point performance > Manufactured by NVIDIA
> Large HPC data sets > Enterprise-level support
supported by larger on-board that includes a three-year
memory warranty
> Faster communication with Designed for HPC
InfiniBand using NVIDIA
> Integrated into leading OEM
GPUDirect™
including workstations,
servers, and blades
NVIDIA TESLA
GPUS ARE REVOLUTIONIZING
COMPUTINGTesla Data Center Products
Available from OEMs and certified resellers, Tesla GPU computing products are
designed to supercharge your computing cluster.
Highest Performance, Highest Efficiency
Performance Performance/$ Performance/watt
Gflops Gflops/$K Gflops/kwatt
750 70 800
8x
60
4x
600
5x 600
50
450 40
TESLA GPU COMPUTING SOLUTIONS 400
30
300
The Tesla 20-series GPU computing solutions are designed from the ground up
20
200
for high-performance computing and are based on NVIDIA’s latest CUDA GPU 150
architecture, code named “Fermi”. It delivers many “must have” features for HPC 10
including ECC memory for uncompromised accuracy and scalability, C++ support, 0 0 0
and 7x double precision performance compared to CPUs. Compared to the typical CPU Server GPU-CPU CPU Server GPU-CPU CPU Server GPU-CPU
Server Server Server
quad-core CPUs, Tesla 20-series GPU computing products can deliver equivalent
performance at 1/10th the cost and 1/20th the power consumption. CPU 1U Server: 2x Intel Xeon X5550 (Nehalem) 2.66 GHz, 48 GB memory, $7K, 0.55 kw
GPU-CPU 1U Server: 2x Tesla C2050 + 2x Intel Xeon X5550, 48 GB memory, $11K, 1.0 kw GPU-CPU server solutions deliver up
to 8x higher Linpack performance.
Tesla M2050/M2070 GPU Computing Tesla S2050 GPU Computing System
Modules enables the use of GPUs and is a 1U system powered by 4 Tesla
CPUs together in an individual server GPUs and connects to a CPU server.
node or blade form factor.
NVIDIA TESLA
GPU computing SOLuTIONSTesla Workstation Products DEVELOPER ECOSYSTEM AND WORLDWIDE EDUCATION
Workstations powered by Tesla GPUs Designed to deliver cluster-level performance on a workstation, the NVIDIA Tesla In just a few years, an entire software ecosystem has developed around the CUDA
outperform conventional CPU-only GPU Computing Processors fuel the transition to parallel computing while making architecture—from more than 350 universities worldwide teaching the CUDA
solutions in life science applications. personal supercomputing possible—right at your desk. programming model, to a wide range of libraries, compilers and middleware that
help users optimize applications for GPUs.
Highest Performance, Highest Efficiency The NVIDIA GPU Computing Ecosystem
MIDG: Discontinuous AMBER Molecular FFT: cuFFT 3.1 in OpenEye ROCS Radix Sort A rich ecosystem of software
Galerkin Solvers for Dynamics (Mixed Double Precision Virtual Drug CUDA SDK applications, libraries, programming
PDEs Precision) Screening language solutions, and service
providers supporting the CUDA
120 8 8 180 8 RESEARCH & parallel computing architecture.
EDUCATION LIBRARIES
7 7 160 7
100
6 6 140 6 INTEGRATED
80 DEVELOPMENT MATHEMATICAL
5 5 120 5
Speedups
ENVIRONMENT
CUDA
PACKAGES
60 4 4 100 4
LANGUAGES CONSULTANTS,
3 3 80 3
40 & APIs TRAINING, &
2 2 40 2 CERTIFICATION
20
1 1 20 1 ALL MAJOR TOOLS
0 0 0 0 0 PLATFORMS & PARTNERS
Intel Xeon X5550 CPU
Tesla C2050
Tesla C2050/C2070 GPU Computing
Processor delivers the power of
a cluster in the form factor of a
NVIDIA TESLA
workstation.
GPU computing ECOSYSTEMNVIDIA’s CUDA architecture has the industry’s most robust language and API In addition to the CUDA C development tools, math libraries, and hundreds of
support for GPU computing developers, including C, C++, OpenCL, DirectCompute, code samples in the NVIDIA GPU computing SDK, there is also a rich ecosystem of
and Fortran. NVIDIA Parallel Nsight, a fully integrated development environment solution providers:
for Microsoft Visual Studio is also available. Used by more than six million
developers worldwide, Visual Studio is one of the world’s most popular Libraries and Middleware Solutions
development environments for Windows-based applications and services. Adding > Acceleware FDTD libraries GPU Debugging Tools
functionality specifically for GPU computing developers, Parallel Nsight makes the > CUBLAS, complete BLAS library* > Allinea DDT
power of the GPU more accessible than ever before. > CUFFT, high-performance FFT > Fixstars Eclipse plug-in
routines* > NVIDIA cuda-gdb*
> CUSP > NVIDIA Parallel Nsight for Visual
> EM Photonics CULA Tools, Studio
heterogeneous LAPACK > TotalView Debugger
implementation
GPU Performance Analysis Tools
> NVIDIA OptiX and other AXEs*
> NVIDIA Performance Primitives for > NVIDIA Visual Profiler*
image and video processing > NVIDIA Parallel Nsight for Visual
(www.nvidia.com/npp)* Studio
> Thrust > TAU CUDA
> Vampir
Compilers and Language Solutions
> CAPS HMPP Cluster and Grid Management
Solutions
> NVIDIA CUDA C Compiler (NVCC),
supporting both CUDA C and CUDA > Bright Cluster Manager
C++* > NVIDIA system management
> Par4All interface (nvidia-smi)
> PGI CUDA Fortran > Platform Computing
> PGI Accelerator Compilers for C Math Packages
and Fortran
> Jacket by AccelerEyes
> PyCUDA
> Mathematica 8 by Wolfram
> MATLAB Distributed Computing
NVIDIA Parallel Nsight Development
Server (MDCS) by Mathworks
Environment
> MATLAB Parallel Computing
NVIDIA Parallel Nsight software NVIDIA Parallel Nsight software is the industry’s first development environment for Toolbox (PCT) by Mathworks
integrates CPU and GPU development, massively parallel computing integrated into Microsoft Visual Studio, the world’s
allowing developers to create optimal most popular development environment. It integrates CPU and GPU development,
GPU-accelerated applications.
allowing developers to create optimal GPU-accelerated applications.
Parallel Nsight supports Microsoft Visual Studio 2010, advanced debugging
and analysis capabilities, as well as Tesla 20-series GPUs, built on the latest
generation CUDA parallel computing architecture codenamed “Fermi”. For more
information, visit developer.nvidia.com/object/nsight.html.
NVIDIA TESLA
GPU computing ECOSYSTEMConsulting and Training Education and Certification
Consulting and training services are > CUDA Certification (www.nvidia.
available to support you in porting com/certification)
applications and learning about > CUDA Center of Excellence
(research.nvidia.com)
developing with CUDA. For more
> CUDA Research Centers (research.
information, visit www.nvidia.com/
nvidia.com/content/cuda-research-
object/cuda_consultants.html.
centers)
> CUDA Teaching Centers (research.
nvidia.com/content/cuda-teaching-
centers)
> CUDA and GPU computing books
(www.nvidia.com/object/cuda_
books.html)
* Available with the latest CUDA toolkit at www.nvidia.com/getcuda
For more information about the CUDA Certification Program,
visit www.nvidia.com/certification. To learn more about NVIDIA Tesla, go to www.nvidia.com/tesla.You can also read

















































