Programming Techniques for Supercomputers - RRZE Moodle
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Socket 1 Socket 0
Programming Techniques
for Supercomputers
© Intel
Prof. Dr. G. Wellein(a,b)
Dr. G. Hager(a)
J. Hammer(b), C.L. Alappat(b)
(a)HPC Services – Regionales Rechenzentrum Erlangen
(b)Department für Informatik
University Erlangen-Nürnberg
Sommersemester 2020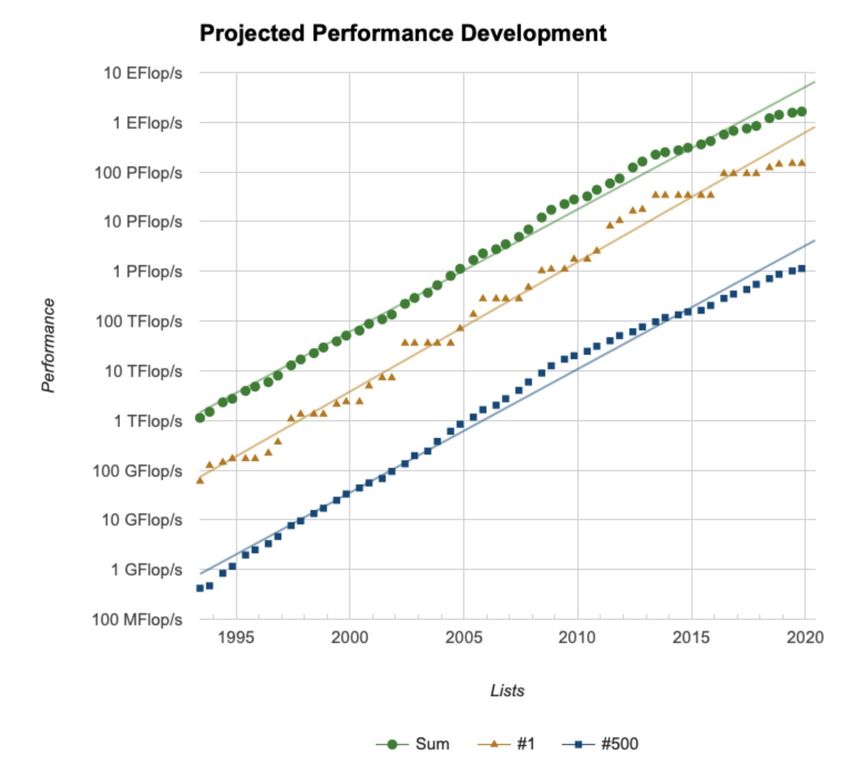
Audience & Contact
▪ Audience
▪ Computational Engineering
▪ Computer Science
▪ Computational & Applied Mathematics
▪ Physics, Engineering, Materials Science, Chemistry,…
▪ Contact:
▪ Gerhard Wellein: gerhard.wellein@fau.de (Lecture&Tutorial)
▪ Georg Hager: georg.hager@fau.de (Lecture&Tutorial)
▪ Julian Hammer: julian.hammer@fau.de (Tutorial)
▪ Christie Louis Alappat: christie.alappat@fau.de (Tutorial & CAM)
▪ For questions first use moodle – forum (see next slide)
April 22, 2020 PTfS 2020 2
Format of course
▪ Lecture only: 5 ECTS
▪ Material covered in the lecture
▪ Register in “meincampus”
▪ Written exam: 60 Minutes
▪ Lecture & Exercises: (5 + 2.5) ECTS
▪ Material covered in lecture AND tutorial
▪ Register for lecture AND exercise in “meincampus”
▪ Written exam: 90 Minutes
▪ Bonus system based on total credits of returned exercise sheets:
▪ 60% - 79% an upgrade in the final mark of 1 stage, e.g. 2.7 → 2.3
▪ 80% and higher upgrade in the final mark of 2 stage, e.g. 2.7 → 2.0
▪ You must pass the exam before “boost” is applied! 1.0 is still best mark
▪ No “supporting material” allowed in exam
▪ PTFS-CAM students: Please contact me via email
April 22, 2020 PTfS 2020 3
Organization & Format
▪ 4 hrs of lecture (2 x 2hrs) / week
▪ 2 hrs of tutorial (for 7.5 ECTS and CAM students) / week
▪ Lecture/Tutorial is completely documented in moodle LMS:
http://tiny.cc/PTfS (see also PTfS univis entry)
▪ Please enroll into the lecture and specify your matriculation
number!
▪ Homework assignments, announcements etc. all handled via moodle
▪ Use forum for questions or discussion with other students
April 22, 2020 PTfS 2020 4
Organization & Format: Lecture (online)
▪ Audio recordings of lecture (incl. slides) will be provided
on FAU Videoportal
▪ New lectures available: Monday noon & Thursday noon
▪ Availability and links will be posted in moodle (http://tiny.cc/PTfS)
▪ Online Question & Answer (via zoom) for lectures
▪ Every Wednesday (16:15 – 17:15)
▪ If everybody agrees the sessions will be recorded and made
available on moodle
▪ Q&A session only covers the last 4 lectures….
April 22, 2020 PTfS 2020 5
Organization & Format: Tutorial (online)
▪ New exercise sheet posted every Thursday in moodle
▪ To be returned via moodle until next Thursday (8 a.m.)
▪ Online Question & Answer (via zoom) for (old & new)
exercise sheet
▪ Every Monday (14:15 – 15:45)
▪ If everybody agrees the sessions will be recorded and made
available on moodle
▪ Q&A session only covers the old and new exercise sheets….
April 22, 2020 PTfS 2020 6
Organization & Format: PTfS-CAM (online) ▪ In addition to lecture & exercise, CAM students have to do a programming and performance modeling project (Conjugate Gradient solver) ▪ PTfS-CAM students have to register via e-mail ▪ If you did not, please send an e-mail to gerhard.wellein@fau.de and christie.alappat@fau.de ▪ All registered students will receive an e-mail next week for a zoom meeting April 22, 2020 PTfS 2020 7

Format of the course
▪ Prerequisite (for exercises):
▪ Basic programming knowledge in C/C++ or FORTRAN
▪ Using LINUX / UNIX OS environments (including ssh)
▪ Recommended
▪ First experiences with parallel programming – though we will introduce
necessary basics
▪ Tutorials:
▪ You must submit your homework assignments for inspection to qualify for
bonus!
▪ Do the exams and programming exercises even if you do not submit!
▪ Some topics will be covered (in more detail) in the tutorials
▪ Topics additionally covered in the tutorials are part of the 7.5 ECTS exam
▪ Practical parallelization skills will be tested in the 7.5 ECTS exam!
April 22, 2020 PTfS 2020 10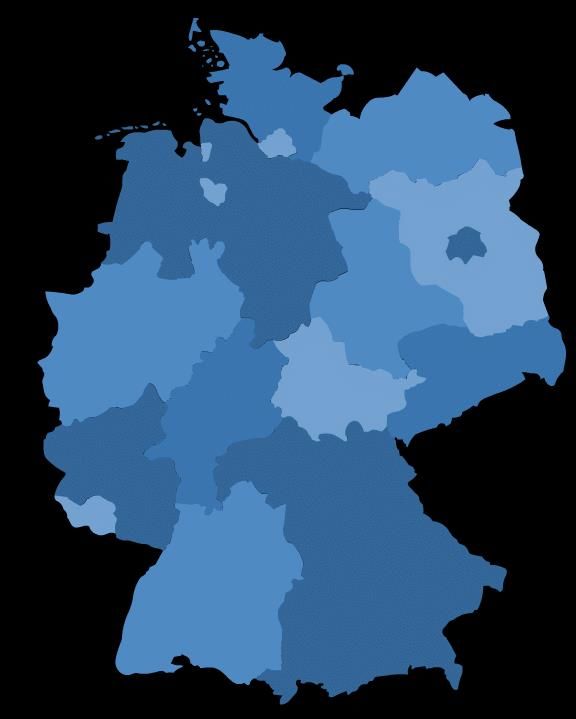
Supporting material
▪ Books:
▪ G. Hager and G. Wellein:
Introduction to High Performance Computing
for Scientists and Engineers.
CRC Computational Science Series, 2010.
ISBN 978-1439811924
▪ see moodle for a very early version
▪ 10 copies are available in the library
▪ discounted copies – ask us
▪ J. Hennessy and D. Patterson: Computer Architecture. A Quantitative
Approach. Morgan Kaufmann Publishers, Elsevier, 2003. ISBN 1-55860-
724-2
▪ W. Schönauer: Scientific Supercomputing.
(cf. http://www.rz.uni-karlsruhe.de/~rx03/book/)
April 22, 2020 PTfS 2020 11
Supporting material
▪ Documentation:
▪ http://www.openmp.org
▪ http://www.mpi-forum.org
▪ http://developer.intel.com/products/processor/manuals
▪ http://developer.amd.com/documentation/guides
▪ The big ones and more useful HPC related information:
▪ http://www.top500.org
April 22, 2020 PTfS 2020 12Related teaching activities
▪ Regular seminar on
“Efficient numerical simulation on multicore processors” (MuCoSim)
▪ 5 ECTS
▪ 2 hrs per week
▪ 2 talks + written summary
▪ Topics from code optimization, code parallelization and code benchmarking on
latest multicore / manycore CPUs and GPUs
▪ This semester: Thursday 16:00 – 17:30 – RRZE (online)
▪ See moodle: http://tiny.cc/MuCoSim
▪ Also offered during winter term
April 22, 2020 PTfS 2020 13SCOPE OF THE LECTURE April 22, 2020 PTfS 2020 14
Scope of the lecture
Understand relevant hardware features/concepts
of modern HPC systems and
derive efficient programming/implementation strategies
→Identify basic hardware concepts
(single core, chip/device, node-level, massively parallel)
→Learn strategies how to efficiently use (program) the hardware
(code modifications, OpenMP/CUDA, MPI)
→Establish appropriate performance expectations/models to
→assess the attainable performance and
→identify the “hardware bottleneck”
April 22, 2020 PTfS 2020 15Scope of the lecture
▪ Hardware coverage:
▪ Single-core + Multi-Core Intel Core/Xeon (5 generations) & AMD
▪ Many-core / GPU: Intel Xeon Phi & NVIDIA P100/V100
▪ Shared memory nodes (multiple multi-/many-core & GPUs)
▪ Distributed memory computers (multiple/many nodes)
▪ Programming models (mostly basic introduction; performance issues):
▪ OpenMP (shared memory nodes)
▪ CUDA (GPUs)
▪ MPI (distributed memory)
▪ Performance Models – how fast may a code run on a given architecture??
▪ Expectations
▪ Roofline Model [Williams&Patterson, 2009]
▪ (ECM Model)
April 22, 2020 PTfS 2020 16Scope of the lecture
▪ Introduction
▪ Performance: Basics, Measuring & Reporting, Benchmarks
▪ Modern (multicore) processors
▪
Performance Analysis and Modeling
Single core: Basics, Pipelining, Superscalarity, SIMD
▪ Memory Hierarchy: Caches & Main Memory
▪ Multicore: Technology & Basics
▪ Manycore / GPU (*)
▪ Parallel computers: Shared Memory
▪ Shared-memory system architectures: UMA, ccNUMA
▪ OpenMP basics
▪ Performance Modelling / Engineering:
▪ Roofline Model
▪ Case Studies: Dense&Sparse Matrix-Vector-Multiplication / Stencils
▪ Shared Memory in depth
▪ Advanced OpenMP, Pitfalls, Data Placement
▪ Parallel computers: Distributed Memory
▪ Architecture & Communication networks
▪ MPI in a nutshell
▪ Hardware performance monitoring and model validation (*)
April 22, 2020 PTfS 2020 17Scope of the lecture – a typical example
!$OMP PARALLEL DO
do k = 1 , 400 Parallelize
do j = 1 , 400; do i = 1 , 400
y(i,j,k)= b*( x(i-1,j,k)+ x(i+1,j,k)+ x(i,j-1,k)+
x(i,j+1,k)+ x(i,j,k-1)+ x(i,j,k+1))
enddo; enddo
enddo
!$OMP END PARALLEL DO
Establish limit simple
performance model
(Here: Roofline)
Parallelize
Single core performance
optimization
Intel® Xeon® Prozessor E5-2670
April 22, 2020 PTfS 2020 18Code optimization/parallelization – no black boxes!
possible
optimization
white box
input data
insight:
CODE bottleneck
Y
model
simplified description OK?
of system (HW+SW) N
modeling predictions validation
adjust model
→ insight
„Performance Engineering“
April 22, 2020 PTfS 2020 19Introduction
Supercomputers:
The Big Ones and the working horsesMost powerful computers in the world: TOP500
▪ Top 500: Survey of the 500 most powerful supercomputers
▪ http://www.top500.org
▪ How to rate the performance?
→ Solve large dense system of equations: A x = b („LINPACK“)
▪ Max. performance achieved with 64-Bit Floating Point Numbers: Rmax
▪ Published twice a year (ISC in Germany, SC in USA)
▪ First: 1993 (CM5/1,024 procs.): 60 GFlop/s (TOP1)
▪ Nov. 2019 (IBM+NVIDIA/2.4*106 procs.): 148,600,000 GFlop/s (TOP1)
▪ Performance increase: 76% p.a. from 1993 – 2019
April 22, 2020 PTfS 2020 21Most powerful computers in the world: TOP500
▪ Performance measures: MFlop/s, GFlop/s, TFlop/s, PFlop/s, EFlop/s
▪ Number of FLOATING POINT operations per second
▪ FLOATING POINT operations: Typically Add & Multiply operations
(Reason: Part 3 of the lecture)
▪ Performance may depend on accuracy (of input operands):
▪ double precision, double: 64 Bit
▪ single precision, float: 32 Bit
▪ half precision: 16 Bit
▪ Default: 64 Bit
▪ See Chapter 3 for details
106: MFlop/s 1012: TFlop/s Single node
109: GFlop/s 1015: PFlop/s TOP500 systems
1018: EFlop/s TOP1 in 2021/2 (?)
April 22, 2020 PTfS 2020 22TOP3 as of November 2019
LINPACK Peak Power@
Performance Performance LINPACK
Number of
processors
Investment for such systems: 150 – 200 M€
Power bill @ 15ct/kWhr: 1 MW → € 1,300,000 p.a.
Source: www.top500.org
April 22, 2020 PTfS 2020 23TOP10 as of November 2019 Most systems use accelerators, e.g. GPUs: 1,2,4,6,7,8,10 Leading systems: US / China Two systems from Europe: 6,9 SuperMUC-NG (LRZ Garching) April 22, 2020 PTfS 2020 24
Performance Trend & Projection
ExaFlop/s machine
In 2021 ?!
600 m USD investment at
Oakridge Nat. Lab. [1]
Basic trend:
Slope changes → performance increase slows down
Source: www.top500.org
[1] https://www.olcf.ornl.gov/2019/05/07/no-scaling-back-doe-cray-amd-to-bring-exascale-to-ornl/
April 22, 2020 PTfS 2020 25HPC Centers in Germany: A view from Erlangen
Jülich Supercomputing
Center
Hannover Berlin
JUWELS (Cluster)
9.9 PF/s
FZ Jülich
Erlangen/ Nürnberg
(0.5 PF/s)
HLRS-Stuttgart
LRZ-München
HLR Stuttgart SuperMUC-NG: 26.8 PF/s
Hawk: 26 PF/s
April 22, 2020 PTfS 2020 26RRZE: „Meggie”-cluster
• 728 Compute nodes (14.560 cores)
• 2 Intel Xeon E5-2630 v4 (Broadwell) 2.2 GHz (10 cores)
• 20 cores/ node + SMT cores
• 64 GB main memory
• NO local disks
• Peak Performance: Rpeak = 0.5 PF/s
512.000.000.000 Floating Point Ops/s
• #346@TOP500 – Nov. 2016
Rmax = 0.48 PF/s
• Intel OmniPath network:
Up to 100 Gbit/s
• Price: € 2,5 Mio.
• Power consumption: 120 KW - 210 KW (depending on workload)
PTfS 2020
27RRZE: „Emmy”-cluster
▪ 544 compute nodes (10.880 cores) with
▪ 2 Intel Xeon E5-2660v2 (Ivy Bridge) 2.2 GHz (10 cores)
→ 20 cores/ node + SMT cores
▪ 64 GB main memory – NO local disks
▪ 8 accelerator nodes same CPUs
▪ 8 nodes with 2 x NVIDIA K20 GPGPUs
▪ Vendor: NEC (Dual-Twin – Supermicro)
▪ Power consumption: ~160 KW
(backdoor heat exchanger)
▪ Full QuadDataRate Infiniband fat tree
BW ~ 3 GB/s / direction and < 2 µs latency
▪ Parallel Filesystem: 400 TB+ Peak performance:
(max. 7 GB/s) 234 TFlop/s (all devices)
191 TFlop/s LINPACK (CPUs)
▪ Operating system: LINUX #210 in TOP500 / Nov. 2013
April 22, 2020 PTfS 2020 28Power consumption@RRZE
260 nodes@2.66 GHz (2009)
540 nodes@2.2 GHz (2013)
720 nodes@2.2 GHz (2016)
Trends:
• Clock speed reduces / stagnates
• (Minor) energy efficiency improvements
• Power consumption depends on workload
Not shown: Electric power for cooling is approx 50% of power drawn by clusters
April 22, 2020 PTfS 2020 29You can also read

















































