Scalable Crowdsourced Social Media Annotation - Understanding Europe's Fashion Data Universe - FashionBrain
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Horizon 2020
Understanding Europe’s Fashion Data Universe
Scalable Crowdsourced Social
Media Annotation
Deliverable number: D5.1
Version 2.0
Funded by the European Union’s Horizon 2020 research and
innovation programme under Grant Agreement No. 732328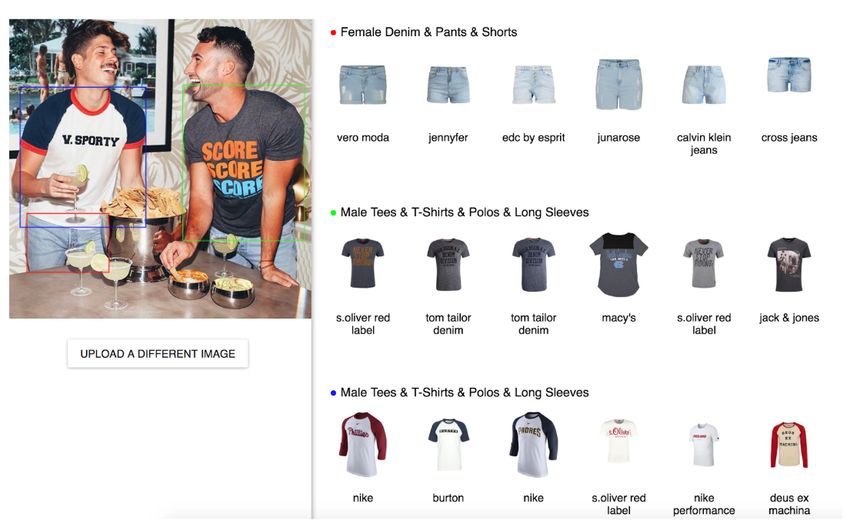
Project Acronym: FashionBrain
Project Full Title: Understanding Europe’s Fashion Data Universe
Call: H2020-ICT-2016-1
Topic: ICT-14-2016-2017, Big Data PPP: Cross-sectorial and
cross-lingual data integration and experimentation
Project URL: https://fashionbrain-project.eu
Deliverable type Report (R)
Dissemination level Public (PU)
Contractual Delivery Date 31 May 2018
Resubmission Delivery Date 27 February 2019
Number of pages 14, the last one being no. 8
Authors Marko Jocić, Matthias Dantone - Fashwell
Peer review Alessandro Checco - USFD
Change Log
Version Date Status Partner Remarks
0.1 29/05/2018 Draft Fashwell
0.2 15/06/2018 Full Draft Fashwell
1.0 30/06/2018 Final Fashwell, USFD Rejected 15/10/2018
1.1 07/12/2018 Revised Draft Fashwell
2.0 27/02/2019 Resubmitted Final Fashwell, USFD
Deliverable Description
This deliverable consists of a publicly available website with data visualization
functionality. We demonstrate that we analyzed hundreds of fashion blogs,
Instagram profiles and that we are able to constantly update the profiles with
recently published images.
ii
Abstract
This deliverable consists of a publicly available website with data visualization
functionality. We demonstrate that we analyzed hundreds of fashion blogs,
Instagram profiles and that we are able to constantly update the profiles with
recently published images.
We present the dataset that we collected for this deliverable and provide some basic
statistics on it.
We outline the two main ways on how the fashion products are annotated: automatic
annotation by our machine learning algorithm and refinement of these automatic
annotation by using crowdsourcing. For both of these approaches we argue some
benefits and drawbacks.
iii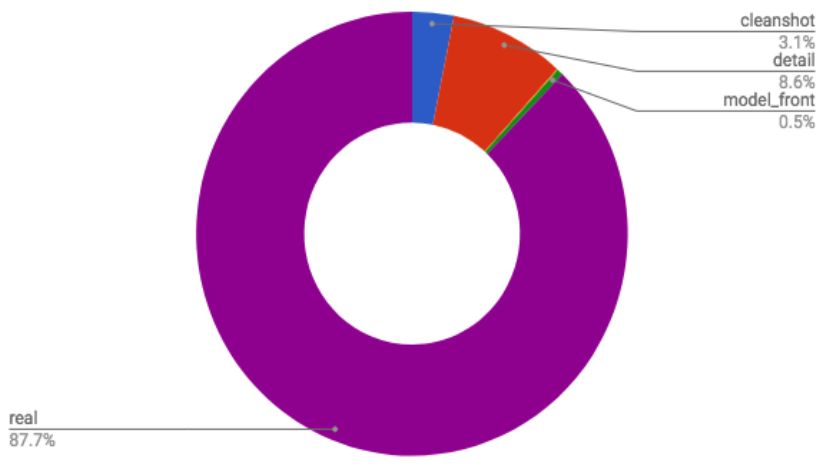
Table of Contents
List of Figures v
List of Acronyms and Abbreviations vi
1 Introduction 1
1.1 Scope of this Deliverable . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 Demonstration website 2
3 Data 3
4 Annotation 5
4.1 Automatic annotation . . . . . . . . . . . . . . . . . . . . . . . . . . 5
4.2 Annotation refinement with crowdsourcing . . . . . . . . . . . . . . . 6
Bibliography 8
ivList of Figures
2.1 Screenshot of the publicly available website that shows the collected
fashion blogger images and annotated products in these images. . . . 2
3.1 Number of products per category. . . . . . . . . . . . . . . . . . . . . 3
3.2 Number of products per image. . . . . . . . . . . . . . . . . . . . . . 4
3.3 Image style. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
4.1 An example result of automatic annotation. . . . . . . . . . . . . . . 6
4.2 An example of annotation refinement using crowdsourcing. . . . . . . 7
vList of Acronyms and Abbreviations
GDPR General Data Protection Regulations
WP Work Package
vi1 Introduction
Social media, image sharing platforms and bloggers have transformed the entire
fashion discovery journey. Which fashion product is popular, trendy and a best-
seller is defined by its presence on social media. Fashion bloggers are used by
brands to distribute and influence this process. Bloggers are getting paid by brands
and retailers to wear a specific product because they have a significant reach on the
relevant social media platforms. In this deliverable we crawled 100 fashion blogger
accounts from Instagram and identified all fashion products in the images. The
images including the annotated products have been made available to the public on
a demonstration website.
1.1 Scope of this Deliverable
Scope This deliverable presents a scalable way for annotating fashion products in
social media images.
Dependencies Machine learning algorithm that is used to annotate fashion
products is presented in deliverable D6.2. Crowdsourcing solution that is used
to refine the products annotations are presented in Deliverable 3.1.
Contribution This deliverable will contribute to task T5.2, where we will use the
same dataset to extract attributes of the annotated fashion products.
Collaborations The dataset which resulted from this deliverable was given to
University of Fribourg for their research on fashion trend prediction.
Datasets In this deliverable we collect a dataset of 100 Instagram fashion
influencers. For each influencer we download 100 images, which results in
a dataset with around 11,000 images.
D5.1 – Scalable Crowdsourced Social Media Annotation 12 Demonstration website
The demonstration website (https://fashionbrain-project.eu/scalable-crowdsourced-
social-media-annotation-demo) displays the images from the collected Instagram
dataset. The annotated products can be seen by clicking on an image. The
screenshot in Figure 2.1 shows the layout of the website.
Figure 2.1: Screenshot of the publicly available website that shows the collected
fashion blogger images and annotated products in these images.
The novel website demo is compliant with the General Data Protection Regulations
(GDPR)1 . For example, the consortium does not host these Instagram images, but
they are served by Instagram directly. More specifically, we follow Article 17 of
GDPR [1], which concerns the user’s rights to data erasure. This means if a user
chooses to delete his/her data from Instagram, it will also be automatically deleted
from this demonstration website.
Moreover, a Consent Manager2 has been introduced, to allow influencers to withdraw
consent, should they wish to do so.
1
We refer to Deliverable D9.3 for more information.
2
https://fashionbrain-project.eu/data-ethics-and-privacy, see Deliverable D9.2 and
D9.3 for more information.
D5.1 – Scalable Crowdsourced Social Media Annotation 23 Data
For this WP we downloaded around 100 images from 100 Instagram bloggers, which
resulted in a total of 11’007 images. This list of the Instagram fashion influencers
have been the output of the deliverable D6.3. The Instagram API [2] has been
used to download the images, as well as the corresponding metadata like number
of likes, comments and title. Some statistics about the images processed are shown
below. An image classification algorithm has been used to analyze the content of
the images.
Figure 3.1 shows number of products per fashion category in the collected images.
The most common category of products detected in the images were denim pants
and jackets and coats. Less popular categories were scarves, wraps and socks. A
number of categories sat midway in popularity such as bags, eyewear and shoes.
Figure 3.1: Number of products per category.
Figure 3.2 shows number of detected products per image. Most images had between
1 and 4 products detected, with very few images having more than 6 products. Some
images did not have any products detected, and this is due to the use of other post
types such a text only posts (motivation quotes) or nature shots.
Figure 3.3 shows the analysis of the style of collected image by Fashwell’s proprietary
image classification algorithm. The vast majority of images were detected as “real”
D5.1 – Scalable Crowdsourced Social Media Annotation 33. Data
Figure 3.2: Number of products per image.
images, indicating an image with a non-studio background. The next most detected
photographic style was detail shots, indicating an image that does not include all
of the product, but only a detail of it. Clean shot images represent full product
pictures - these were the least common.
Figure 3.3: Image style.
D5.1 – Scalable Crowdsourced Social Media Annotation 44 Annotation
In this section, Fashwell quickly reviews the work presented in Deliverable 6.2 and
Deliverable 3.1 and shows how the work developed in these two WP contributed to
this deliverable. All 11007 fashion blogger images have been linked/annotated with
the most similar products of the product database. The annotation process can be
divided into two different tasks:
• the automatic annotation
• refinement of automatic annotation using crowdsourcing
The automatic annotation takes advantage of state of the art computer vision and
deep learning to find the most similar products in the database. The second task
leverages the wisdom of the crowd to refine and verify the automatic annotation.
4.1 Automatic annotation
In the Deliverable 6.2, we presented our work in the FashionBrain project in
correspondence to the task of named entity linking using computer vision and
machine learning. The presented approach outperforms all publicly available
methods on the academic benchmark presented in (Liu et al. 2016 [3]) (details
about the experiment can be found in D6.2).
The conceptual idea behind our method is to understand an embedding space where
visually similar products are close to each other, whereas visually dissimilar products
are further apart. Visual similarity can be described with many different features of
a product such as the category, color, pattern, neck type, sleeve length, etc.
The presented approach localizes different fashion objects in the fashion blogger
image and ‘projects’ the relevant product image patch into the embedding space.
The Euclidean distance in that embedding space is used to describe the similarity -
more similar products are close to each other, and vice versa. Fashwell’s approach
outperforms current state-of-the-art methods, but there are still areas to improve.
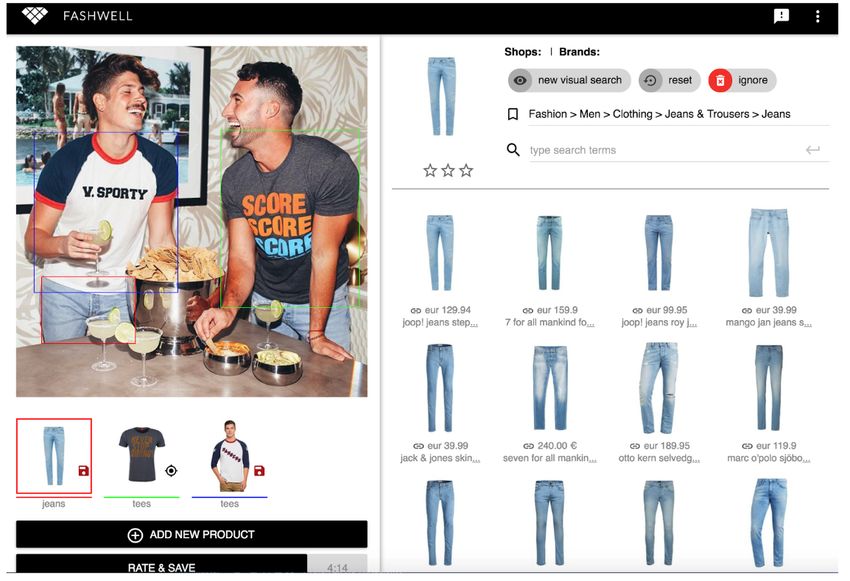
An example result of the methods can be found in Figure 4.1.
D5.1 – Scalable Crowdsourced Social Media Annotation 54. Annotation 4.2. Annotation refinement with crowdsourcing
Figure 4.1: An example result of automatic annotation.
4.2 Annotation refinement with crowdsourcing
Since the automatic annotation approach is not perfect, we built an online tool
where workers around the world could help us verify and improve the annotations.
The design and concept of crowdsourcing refinement tool has already been discussed
in the WP3.
A screenshot of the tool is shown in Figure. The tool starts with the automatic
results of named entity linking approach and uses computer vision and deep learning
to quickly improve the annotations.
On average, a worker needs around 2 minutes to annotate an image perfectly. The
time highly depends on the number of products in an image and on the image
quality. The workers have been hired using a freelancing platform [4].
D5.1 – Scalable Crowdsourced Social Media Annotation 64. Annotation 4.2. Annotation refinement with crowdsourcing
Figure 4.2: An example of annotation refinement using crowdsourcing.
D5.1 – Scalable Crowdsourced Social Media Annotation 7Bibliography
[1] GDPR. General data protection regulations, 2018. URL https://ec.
europa.eu/commission/priorities/justice-and-fundamental-rights/
data-protection/2018-reform-eu-data-protection-rules_en.
[2] Instagram Developer Platform. Instagram developer platform, 2018. URL
https://developers.facebook.com/products/instagram/.
[3] Luo P. Qiu S. Wang X. Liu, Z. and X. Tang. Deepfashion: Powering robust
clothes recognition and retrieval with rich annotations. EEE Conference on
Computer Vision and Pattern Recognition, pages 1096–1104, 2016.
[4] Upwork. Upwork crowdsourcing platform, 2018. URL https://www.upwork.
com.
D5.1 – Scalable Crowdsourced Social Media Annotation 8You can also read

















































