Spatio-Temporal Interest Points for Video Analysis
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
CHI 2009 ~ Student Research Competition April 4-9, 2009 ~ Boston, MA, USA
Spatio-Temporal Interest Points for
Video Analysis
Ramsin Khoshabeh James D. Hollan Introduction
University of California University of California Researchers from many disciplines are taking
San Diego, USA San Diego, USA advantage of increasingly accessible digital video
ramsin@hci.ucsd.edu hollan@hci.ucsd.edu recording and storage facilities to assemble extensive
collections of real world activity data, making activity
an object of scientific scrutiny in ways never before
possible. The ability to record and share such data has
created a critical moment in the practice of behavioral
Abstract
research as well as an unprecedented opportunity to
In this paper, we discuss the potential for effective
advance human-centered computing.
representations of video data to aid analysis of large
datasets of video clips and describe a prototype
A key obstacle to fully capitalizing on this opportunity is
developed to explore the use of spatio-temporal
the huge time investment required for analysis using
interest points for action recognition. Our focus is on
current methods. There are myriad important research
ways that computation can assist analysis.
questions to be addressed. Questions include, for
example, how to more effectively browse large video
Keywords
collections, search for specific content of interest, and
Video Analysis, Video Coding, Spatio-Temporal Interest
index the video data for future reference.
Points, Action Recognition, Sparse Action Shapes
Many current approaches, especially video streaming
ACM Classification Keywords
websites, try to avoid having to deal with the
I2.10. Artificial Intelligence: Vision and Scene
complexity of the medium by tagging clips with text
Understanding: Video Analysis.
labels. However, simple tagging discards the rich
content of the video and creates the added burden of
labeling. While analysis of general video data has for
Copyright is held by the author/owner(s). the most part been ignored, significant advances have
CHI 2009, April 4–9, 2009, Boston, Massachusetts, USA. been made in research with static images. Image
ACM 978-1-60558-247-4/09/04. processing techniques have been developed for a vast
array of tasks from object detection and tracking to
3455
CHI 2009 ~ Student Research Competition April 4-9, 2009 ~ Boston, MA, USA
content-based image retrieval. Similar attention has yet human analyst, many constraints typically imposed on
to be devoted to spatio-temporal data contained in performance can be relaxed since the goal is not
videos. The majority of video processing techniques, necessarily to have 100% accuracy but to take
particularly in action recognition, either use detection- advantage of algorithms that can assist analysis.
based tracking or motion-based clustering. In the
former, objects are detected in individual frames and We present a prototype to demonstrate the viability of
tracked over time, while, in the latter, clusters of spatio-temporal interest points for video analysis.
motion flow fields are used to extract action content. Taking advantage of their sparse representation of
video data, we represent actions as a set of co-
More recently, researchers [2, 5, 8, 11] have exploited occurring STIPs. Given an action selected by a user
interest-point-detection algorithms, such as the Harris over space and time, we are able to retrieve similar
Corner Detector, to extract features of images that are actions without having to train a classifier. In doing
fairly robust and useful for object representation. By this, we hope to motivate exploration of a novel way to
extending the two-dimensional representations, spatio- represent video inspired by state-of-the-art STIP
temporal interest point (STIP) detectors provide approaches. Our contribution is the direct application of
impressive action classification in complicated scenes. spatio-temporal interest points for cooperative human-
computer video analysis. Humans identify initial actions
Currently video analysts spend considerable time of particular interest while the machine retrieves similar
manually browsing through video while attempting to actions from the video dataset. We also formalize the
understand real-world behavior. One way that notion of a sparse action shape for action recognition.
technology can help overcome the analysis bottleneck This novel representation readily permits human
for rich video data is for designers of tools to accept interaction by allowing a user to easily identify an
that it is a manual job and support the craftwork of action for the system to analyze.
analysis by hand. Still, no matter how powerful these
facilities are, they can only ease the craftwork process. Related Work
Throughput is always going to be no more than a In 2005 Laptev [5] formalized space-time interest
dribble. Automation of segmenting, labeling, and points. Building from work on the Harris Detector for
synchronizing has the potential to fundamentally the extraction of corners in images, he was able to
accelerate the process. derive a 3-dimensional detector that locates corners in
space-time. Intuitively, this corresponds to a corner in
Recent work on action recognition has promise to assist an image that changes direction over time. Later,
with coding of video data. Current work focuses on Laptev et al. [6] demonstrated how this detector could
improving the video processing techniques for be used to learn realistic human actions. Dollár et al.
particular datasets. Typically a classification framework [2] took a slightly different approach by first computing
trained on many instances of an action to be recognized a response function over smoothed versions of video
(e.g., walking or boxing) is constructed. To assist a frames. Cuboids, or cubic windows, were then
3456CHI 2009 ~ Student Research Competition April 4-9, 2009 ~ Boston, MA, USA
extracted at local maxima of this response function and facial expressions, color videos, black and white videos,
actions were represented as a collection of cuboids. low-resolution videos, and noisy videos to name just a
Wong and Cipolla [11] presented an alternative few). This makes the problem extremely difficult.
approach using global information. They used non- Furthermore, it is rarely the case that many instances
negative matrix factorization to extract motion of the same exact action can be gathered to train a
components in the video and then computed STIPs classifier, especially if the classifier is required to be
based on a difference-of-Gaussians approach. All three useful for analysis of just a single video. Current
approaches showed promising results for using STIPs to methodologies do not provide adequate solutions.
classify a predetermined set of actions in videos. In
fact, Niebles et al. [8] showed that STIPs could be used We conjecture that if video could be represented in a
in a generative probabilistic model framework to learn a general way, similar to how Lowe’s Scale-Invariant
set of complex human actions. Feature Transform (SIFT) [7] compactly and robustly
represents image features, then problems with video
Goldman et al. [3] explored the usage of image analysis could be simplified.
processing techniques to aid common tasks in video
analysis, such as annotation and navigation. Using We have developed a prototype that first extracts
particle videos [10] (point trajectories based on optical spatio-temporal interest points from an entire video.
flow fields), they tracked the motion of particles We then manually select an action in space-time,
throughout the frames of a video. This enabled a user consisting of a small number of STIPs and then
to navigate a video by directly dragging an object in the exhaustively compare this point collection with the rest
scene (and consequently the cluster of particles of the video to identify actions with a similar set. Action
associated with it). Furthermore, users could annotate windows are assigned a distance score and we retrieve
an object with a tag that would remain associated with the k closest matches.
it over space and time. This research is an interesting
example of how the processing power of computers can Interest Point Extraction
be combined with human analysis skills to simplify We compute spatio-temporal interest points following
complex tasks. However, it relied mainly on processing the method described by Laptev in [5]. In one sense,
performed on individual images. We believe that there this can be seen as a form of dimensionality reduction,
is great potential to do similar tasks and more by but it is more than that because actions are actually
levering spatio-temporal interest points for analysis. correlated to corners in space and time. This equates to
a spatial corner changing direction over time. We use
Approach the Laptev detector to illustrate that there is promise
The main difficulty with analyzing video is the high- for sparse representations of video. Others, [e.g. 8],
dimensional complexity of the data. Adding to this is have mentioned that the Laptev detector is too sparse
the fact that real-world videos come in all “shapes and for complex action detection, but the reduction of the
sizes” (people walking, people dancing, animals eating, space is to our advantage when datasets become large.
3457CHI 2009 ~ Student Research Competition April 4-9, 2009 ~ Boston, MA, USA
Sparse Action Shapes Action Recognition
The descriptors generated by the Laptev detector Once the sparse action shape has been extracted from
produce 162-dimensional vectors. Much in the same the user selected region of space and time, it is
spirit as a “bag-of-words” representation, we group the exhaustively compared with shapes formed by placing
generated vectors using k-Means clustering to fashion a an equally sized window over all other STIPs in the
word vocabulary. Each of the cluster nodes represents video not overlapping with the current action. This
a different “word” so that every action consists of a could be generalized by looking at multi-scale windows
unique group of these words. However, in contrast to to account for zooming or actions performed faster or
[8] and numerous others, our approach is not to slower but would increase computational time.
generate these words to create a codebook for
modeling a handful of predetermined of actions. To compare two shapes, we use Procrustes Analysis [4,
Instead, we make no assumptions about the possible 9]. Procrustes analysis performs a linear transformation
actions in a video to allow for any arbitrary action to be of the points in one shape to best fit them with the
identified. We use the clustering to discretize the space points in another. The criterion for the goodness-of-fit
of the STIP descriptors. Rather than being an element is the sum of the squared distances between the
of a 162-dimensional space, each interest point takes aligned sets of points. The lower this dissimilarity
on an integer value in the range [1,k]. measure is between a set of sparse action shapes, the
more likely it is that they represent the same action.
We assume that we have enough information to
identify an action using the relative spatio-temporal
locations and discretized values of its constituent STIPs.
So for a given space-time window containing an action,
we create what we call the sparse action shape. A
sparse action shape is simply the shape formed by
linking the 4-D points, {x, y, t, v}, associated with
each STIP in the action, where x, y, and t are the
space-time location of the interest point and v is the
cluster label (word) assigned to it. This differs from [1]
where action shapes are defined as the complex
silhouettes of foreground objects after the background
has been removed. Our sparse representation permits
using shape analysis to compare thousands of action
shapes without heavy performance bottlenecks.
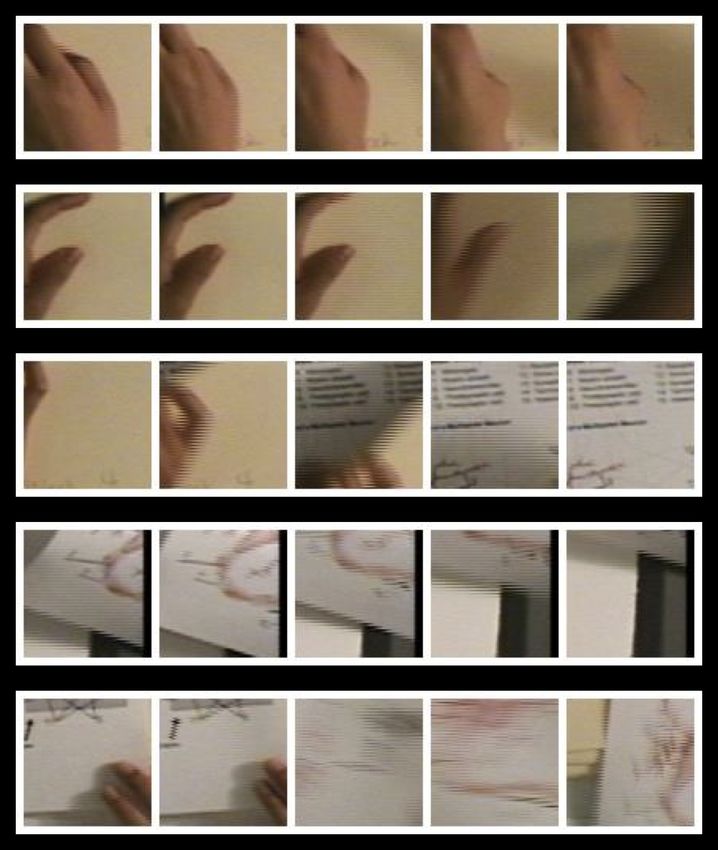
Figure 1. Top: A pointing action selected. Bottom: Showing 5
selected frames of the ~1 sec. long action from start to finish.
3458CHI 2009 ~ Student Research Competition April 4-9, 2009 ~ Boston, MA, USA
Results
Fig. 1 shows an illustration of an exemplar action being
selected from a clip of two people studying over a
tabletop. Using this query action, we compute the
Procrustes analysis for the other STIPs found in the
video. Fig. 2 shows the dissimilarity measure for this
sparse action shape with all other shapes. A score
closer to zero means a better match. We select the five
closest matches and retrieve the corresponding actions.
Fig. 3 illustrates 5 snapshots of each of these actions.
Discussion
From the given example, we show that we are able to
retrieve arbitrary actions using spatio-temporal interest
points. We accomplished this without having to perform
rigorous training of a classifier or having to predefine
Figure 2. Dissimilarity measure between query action and all
actions of interest. STIP shapes.
However, inspecting the results reveals that, while the
majority of the actions retrieved had a hand moving
through the scene, it was not necessarily a pointing
action being performed. One possible explanation could
be that because the Laptev detector identifies space-
time corners, it located many places similar to the input
query of a finger coming to a stop. Nonetheless, the
results could still be highly beneficial to an individual
analyzing the video, possibly suggesting additional
meaningful actions. A possible reason why the 4th result
was returned may be that the curved red figure elicited
a similar detector response as that of the fingertip
when moving through the scene. We want to
emphasize that the purpose of this prototype was to
motivate work in exploring better descriptors for
representing videos.
Figure 3. The 5 actions (hand movement) with highest
response. Each row represents a single action over time.
3459CHI 2009 ~ Student Research Competition April 4-9, 2009 ~ Boston, MA, USA
Implications References
We have already mentioned how HCI could benefit from [1] Blank, M., Gorelick, L., Shechtman, E., Irani, M.,
interfaces that combine learning systems with the user and Basri, R. Actions as Space-Time Shapes. In Proc.
ICCV, 2005.
for cooperative tasks of video analysis. STIPs could
readily lend themselves to this. Furthermore, a robust [2] Dollár, P., Rabaud, V., Cottrell, G., and Belongie,
S. Behavior Recognition via Sparse Spatio-Temporal
representation of video data could lead to videos
Features. In Proc. ICCV VS-PETS, 2005.
becoming easier to search and compare with one
another. This might allow users to search for videos [3] Goldman, D.B., Gonterman, C., Curless, B.,
Salesin, D., and Seitz, S.M. Video Object Annotation,
based upon their content and thus speed navigation
Navigation, and Composition. In Proc. UIST, 2008.
and aid analysis.
[4] Gower, J.C. Generalized Procrustes analysis.
Psychometrika, vol.40, pp.33–51, 1975.
Conclusions and Future Work
We have shown that STIP detectors present a novel [5] Laptev, I. On Space-Time Interest Points.
International Journal of Computer Vision, 64(2/3),
approach to the general problem of video analysis.
pp.107-123, 2005.
Current STIP detectors are largely based on intuitions
[6] Laptev, I., Marszałek, M., Schmid, C., and
derived from 2D image detectors designed to work on a
Rozenfeld, B. Learning realistic human actions from
highly specialized problem. We intend to continue to movies. In Proc. CVPR 2008.
explore general STIPs and what we see as the exciting
[7] Lowe., D.G. Distinctive Image Features from Scale-
ability to exploit the inherent structure of space-time
Invariant Keypoints. International Journal of Computer
data. Vision, 60(2), pp.91–110, 2004.
[8] Niebles, J.C., Wang, H., and Fei-Fei, L.
We are also developing a video analysis interface that Unsupervised learning of human action categories using
will take advantage of the strengths of spatio-temporal spatio-temporal words. In Proc. BMVC, 2006.
interest points. We plan to continue exploiting users’ [9] Rohlf, J. and Slice, D.E. Extensions of the
abilities to provide input in an adaptive machine- Procrustes method for the optimal superimposition of
learning environment that involves online learning and landmarks. Syst. Zool., vol.39, pp.40–59, 1990.
relevance feedback architectures. [10] Sand, P. and Teller, S. Particle video: Long-range
motion estimation using point trajectories. In Proc.
Acknowledgements CVPR, 2006.
The authors would like to thank the members of the [11] Wong, S.F. and Cipolla, R. Extracting
Distributed Cognition and Human-Computer Interaction spatiotemporal interest points using global information.
lab for their continued support. This work is funded by In Proc. ICCV, 2007.
NSF Grant #0729013 and a UCSD Chancellor’s [12] Wong, S.F., Kim, T.K., and Cipolla, R. Learning
Interdisciplinary Grant. motion categories using both semantic and structural
information. In Proc. CVPR, 2007.
3460You can also read