Text mining methods for online topics and reviews using machine learning - IOPscience
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Journal of Physics: Conference Series
PAPER • OPEN ACCESS
Text mining methods for online topics and reviews using machine
learning
To cite this article: S viraja ravi et al 2021 J. Phys.: Conf. Ser. 1916 012215
View the article online for updates and enhancements.
This content was downloaded from IP address 46.4.80.155 on 02/08/2021 at 23:24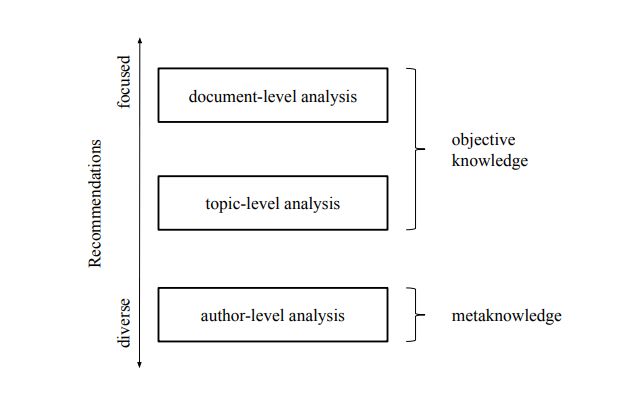
ICCCEBS 2021 IOP Publishing
Journal of Physics: Conference Series 1916 (2021) 012215 doi:10.1088/1742-6596/1916/1/012215
Text mining methods for online topics and reviews using
machine learning
S viraja ravi1, Dilip kumar B1, Gokhul Raj S P J1, Divyacharan A1
virajaraviS@skct.edu.in, 17tucs030@skct.edu.in, 17tucs038@skct.edu.in,
17tucs033@skct.edu.in
Abstract. The objective of recommender frameworks is, fundamentally, to assist individuals
with finding things they may like, i.e., things that fit their inclinations, character, and needs.
Depending on the individual space, those things can be books, films, music, inns, and
significantly more. Normally, suggestions are in view of past client collaborations (e.g., films a
client saw, lodgings a client booked, and so forth) This work in progress paper centers around
news recommender frameworks. In view of the idea of information (e.g., continually new
things, short thing lifetime, and so forth), proposals in view of past cooperation are particularly
difficult to make. Subsequently, news recommender frameworks intensely depend on the
genuine substance of information. While past work fundamentally considers one part of the
substance of news stories, we together examine and talk about in this work a given corpora of
news stories on three unique levels (i.e., archive level, subject level, and creator level). The
generally point is to set to give the premise to an extensive news recommender framework,
which comes to past exactness and considers likewise variety and luck. We exhibit that
significant data can be extricated out of a given corpora, and contrasts in creator, time, and
theme can be appeared. Moreover, the creator level investigation shows that records can be
grouped in view of the composing style of creators.
1. Introduction
1.1 Outline Of Data Mining
Information mining (in some cases called information or disclosure) is the movement of
investigation of unique point of view and truncation in to valuable information data that can be utilized
to grow income and decrease cost. Information mining programming is individual various consistent
devices for dissecting the data's Actually, the information mining is cycle of choice connections or
example between fields in immense social information bases [1].
1.2 Data Mining Techniques
While huge scope data innovation have been growing piece of exchange and insightful
frameworks. Information mining programming breaks down connections and examples in put away
exchange information dependent on delivery end client questions [2].
1.3 Overview Of Datamining
Content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution
of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
Published under licence by IOP Publishing Ltd 1ICCCEBS 2021 IOP Publishing
Journal of Physics: Conference Series 1916 (2021) 012215 doi:10.1088/1742-6596/1916/1/012215
Information mining is the expectation apparatus for enormous data sets it serves to huge association
center around the more significant information's in their information stockrooms. It's an apparatus to
foresee the forthcoming patterns, permitting association/business to settle on hands on information
driven choices. The modernized, planned examinations introduced by information mining push
forward of the investigations past measures gave by customary apparatuses common of choice
emotionally supportive networks. That customarily was to time taken cycle to determine the business
questions. The shrouded designs in source data set, disclosure anticipating data specialists potentially
miss since it lies outside their desires [3].
1.4 The Scope Of Data Mining
Extent of information mining to gets from certain similitudes among looking for extremely
valuable industry data in a tremendous data set. For instance, to find the connected points in gigabytes
of store up scanner information and digging a mountain for a layer of valuable information. Find
shrewdly examining precisely esteem dwells commonly measure need filtering through an amount of
materials. In the information mining innovation executed a few open doors by giving these capacities:-
Computerized forecast of patterns and practices. Information mining innovation is the cycle of choice
anticipating information in enormous data sets. Questions that typically necessary wide active
examination would now be able to be addressed straightforwardly from the information rapidly. A
standard case of a prescient difficulty is focused on advertising. It utilizes the information on point of
reference special mailings to perceive the objectives fundamentally expected to exploit return on
endeavor in future mailings. Past prescient is bother incorporates separate bankruptcy and different
types of dodge, and distinguishing sections of an occupants liable to respond likewise to given
procedures.
1.5 Web Opinion Data Mining Concept
The advancement of Web 2.0 sites, client created content (UGC, for example, item surveys,
online journals, micro blogs, etc, has been developing violently. Mining the notion data in the
enormous client produced substance can help sense the general's assessments towards different points,
for example, subjects, brands, debacles, occasions, VIPs, etc, and is valuable in numerous
applications. For instance, specialists have discovered that breaking down the assessments in text can
possibly foresee variety of financial exchange costs and official political decision results. Ordering the
conclusions of monstrous microblog message is likewise useful in substitute or enhance customary
surveying, is costly also tedious. Item survey assessment investigation can assist organizations with
improving their subjects and administrations, and assist clients with settling on more educated choices.
Dissecting the estimations of client produced content is additionally demonstrated valuable for client
premium mining, customized suggestion, social promoting, client connection the executives, and
emergency the board. Along these lines, supposition arrangement is a hot exploration point in both
modern and scholarly fields. A natural answer for this issue is to prepare a text specific assessment
classifier for each Trends utilizing the marked examples of this Trends.
2 Related Work
[4], has proposed A significant data gathering conduct has consistently to discover other's opinion.
With developing accessibility and assessment of rich assets for example, online survey locales,
individual web journals, new chances and difficulties emerge as individuals presently and do
effectively using data advancements to search and comprehend the assessments of other. The
unexpected ejection of movement in zone of feeling mining and slant examination, which manages
computational treatment of assessment, conclusion, and subjectivity in content has consequently
happened to some extent as an immediate reaction to flood of revenue in new frameworks that
manage sentiment as five star object.
2ICCCEBS 2021 IOP Publishing
Journal of Physics: Conference Series 1916 (2021) 012215 doi:10.1088/1742-6596/1916/1/012215
[5] has proposed, We play an examination of all text distributed on micro blogging stage,
Twitter in the second 50% of 2008. . We contrast our outcomes with a record of well known occasion
assembled from media and sources. We find that occasions in social, political and financial circle do
have a quick and exceptionally explicit impact on different components of public disposition. We
conjecture that enormous scope examination of disposition can give strong stage to demonstrate
aggregate emotive patterns as far as their prescient incentive with respect to social just as finance
markers. Microblogging is an inexorably well known type of correspondence on web. It permits
clients to communicate brief content updates general society or to a chose gathering of contact.
[6], has proposed We interface proportions of general feeling estimated from surveys with
conclusion estimated from text. We investigate a few overviews on customer certainty and political
assessment over the 2008 - 2009 period and discover they relate slant word frequencies in
contemporaneous Twitter messages. While outcomes fluctuate across dataset, in a few cases the
connections are as high as 80% and catch significant huge scope patterns. The outcomes feature the
capability of text streams as a substitute and supplement for customary surveying. On the off chance
that we need to say the degree to which the U.S populace likes or abhorrences Barack Obama, a
conspicuous activity is to request an irregular example from individuals (i.e., survey). Overview and
surveying procedure, broadly created through the twentieth century (Krosnick, Judd, and Wittenbrink
gives various instruments and strategies to achieve delegate general feeling estimation.
[7], has proposed Merchants selling points in the web regularly to request their clients audit
themes ,that they have bought to the related administrations. As online business is getting well known,
the quantity of client surveys for an item develops quickly. For a well known item, the quantity of
surveys can be in hundreds or thousands. This makes it hard for a likely client to peruse them to settle
on an educated choice, whether to buy an item. It additionally makes it hard for the maker of an item
to follow along and oversee clients feeling. For the producer, there are extra challenges on the ground,
that numerous trader destinations may sell on similar items and the maker regularly creates numerous
sorts of subjects. In this exploration, we plan to mine and sum up all the client surveys of an item. This
rundown task is not quite the same as conventional content synopsis, since we just mine the highlights
of an item ,which the clients have communicated their suppositions feeling which can be good or
negative.
[8], has proposed In item surveys, it is seen that the circulation of extremity appraisals over
audits composed by various clients or assessed dependent on various themes are frequently slanted in
reality. Thusly, fusing client and item data would be useful for the assignment of notion
characterization of audits. In any case, existing methodologies overlooked the transient idea of surveys
posted by a similar client or assessed on a similar item. We contend that the fleeting relations of
surveys may be possibly valuable for learning client and item installing and consequently propose
utilizing a grouping model to insert these worldly relations into client and item portrayals in order to
improve the exhibition of report level estimation examination.
[9], has proposed It is significant for various applications, for example, government and
business knowledge to investigate and investigate the dispersion of general suppositions via online
media. In any case, the fast proliferation and extraordinary variety of general sentiments via online
media present incredible difficulties to successful investigation of feeling dispersion. In this paper, we
present a visual examination framework called OpinionFlow to enable experts to recognize feeling
engendering designs and gather experiences. Enlivened by the data dispersion model and the
hypothesis of specific presentation, we build up a sentiment dissemination model to estimated feeling
proliferation among Twitter clients.
3ICCCEBS 2021 IOP Publishing
Journal of Physics: Conference Series 1916 (2021) 012215 doi:10.1088/1742-6596/1916/1/012215
[10],has proposed Over the most recent couple of many years, twitter asyncronous
frameworks have been utilized, among the numerous accessible arrangements, to moderate data and
psychological over-burden issue by recommending related and applicable text to the clients. In this
respects, various advances have been made to get a high-caliber and calibrated twitter asyncronous
framework. In any case, architects face a few conspicuous issues and difficulties. In this work, we
have contacted assortment of points like normal Language Processing, Text Classification, Feature
determination, Feature positioning, and so forth Every single one of these subjects was utilized to use
the enormous data moving through twitter.
3 Proposed Methodology
3.1 Text Rating Prediction
In this module there are Greedy and Dynamic Blocking Algorithms twitter nonconcurrent framework
procedures Proposed: avaricious algorithm.it is a live Content based methodology prescribes text like
the client favored previously. Dynamic Greedy methodology recommends text that clients with
comparative inclinations have loved previously. It can join both substance based and synergistic
separating approaches. The proposed framework utilizes Greedy and Dynamic Blocking Algorithms
approach. While offering proposals to every client, twitter offbeat framework plays out the
accompanying two errands.
3.2 Greedy & Dynamic Blocking Algorithms Text Based Collaborative
Filtering
In this module utilizes the arrangement of text the dynamic client has evaluated and figures
the closeness between these text and target text and afterward chooses N most comparable text. Text'
relating similitudes are additionally registered. Utilizing the most comparable text, the forecast is
figured. The data sifting module is liable for real recovery and determination of motion pictures from
the film information base. In view of the information accumulated from the learning module, data
separating measure is finished as shown in Figure 1.
3.3 Text Similarity Computation
In this module the likeness calculation between two text a (target text) and b is to initially
discover the clients who have appraised both of these text. There are number of various approaches to
register closeness. The proposed framework utilizes changed cosine likeness technique which is more
valuable because of the taking away the relating client normal from every co-appraised pair.
Comparability between text an and b is given.
4ICCCEBS 2021 IOP Publishing
Journal of Physics: Conference Series 1916 (2021) 012215 doi:10.1088/1742-6596/1916/1/012215
Figure 1. Overall Architecture Diagram
4 Experimental Setup
For our examinations, we utilized mainstream devices, for example, WEKA and SPSS is a
generally utilized AI device that underpins different displaying calculations for information
preprocessing, bunching, grouping, relapse and highlight determination. SPSS modeler is a
mainstream information mining program, with interesting graphical UI and high expectation
exactness. It is generally used in business showcasing, asset arranging, clinical examination, law
implementation and public security. In all analyses, ten crease cross approval was used to access the
characterization precision. The Zero R classifier was used to get a pattern precision, which predicts
the dominant class.
4 .1 Text Based Classification
Utilizing Naive Bayes Multinomial (NBM), Naive Bayes (NB), and Support Vector Machines
(SVM-L) with straight piece classifiers, we found the grouping an element in number of text and
successive terms. The correlation of an arrangements utilizing various classifiers for text-based order.
TD speaks to the pattern definition. Model(x,y) speaks to classifier model which is used to
characterize themes, with x number of text per subject and y to the top regular terms. For instance,
NB(100,1000) speaks to the exactness , utilizing NB classifier with hundred texts for every subjects
and thousand most continuous terms (from text based demonstrating results).
4.2 Network Based Classification
Presents the examination of grouping exactness and u various classifiers for the networkbased
arrangements. Plainly, C5.0 choice tree classifier gives the best arrangement exactness (70.96%)
trailed by k-Nearest Neighbor (63.28%), Support Vector Machine (54.349%) and Logistic Regression
(53.457%). C5.0 choice tree classifier accomplishes 3.68 occasions to the higher exactness contrasted
with Zero R pattern classifier. The 70.96% exactness is excellent thinking about the order we subject
into 18 classes. As far as we could possibly know, the quantity of classes utilized in our analysis is lot
bigger than quantits of classes utilised in any previous examination works (two-class arrangement is
the most well-known).
5ICCCEBS 2021 IOP Publishing
Journal of Physics: Conference Series 1916 (2021) 012215 doi:10.1088/1742-6596/1916/1/012215
5 Conclusion & Future Work
Over the most recent couple of many years, twitter asyncronous frameworks have been
utilized, among the numerous accessible arrangements, to moderate data and psychological over-
burden issue by recommending related and applicable text to the clients. In this respects, various
advances have been made to get a high-caliber and calibrated twitter asyncronous framework. In any
case, architects face a few conspicuous issues and difficulties. In this work, we have contacted
assortment of points like normal Language Processing, Text Classification, Feature determination,
Feature positioning, and so forth Every single one of these subjects was utilized to use the enormous
data moving through twitter.
Understanding twitter was as significant as knowing the subjects being referred to. The consequences
of the past investigations, driven us to the end that highlight choice is a totally need in a content
grouping framework. This was demonstrated when we contrasted our outcomes and a framework that
utilizes precisely the same dataset without highlight determination. We had the option to accomplish
33.14% and 28.67% improvement with sack of-words and TF-IDF scoring procedures
correspondingly
Reference
[1] B. Pang and L. Lee, Opinion mining and sentiment analysis, Found. Trends Inf. Retrieval,
2(1/2), pp. 1–135, 2018.
[2] J. Bollen, H. Mao, and A. Pepe, Modeling public mood and emotion: Twitter sentiment and
socio-economic phenomena, in Proc. Int. AAAI Conf. Weblogs Social Media, 2019, pp. 17–21.
[3] D. Devikanniga, A. Ramu, and A. Haldorai, Efficient Diagnosis of Liver Disease using Support
Vector Machine Optimized with Crows Search Algorithm, EAI Endorsed Transactions on
Energy Web, p. 164177, Jul. 2018. doi:10.4108/eai.13-7-2018.164177
[4] H. Anandakumar and K. Umamaheswari, Supervised machine learning techniques in cognitive
radio networks during cooperative spectrum handovers, Cluster Computing, vol. 20, no. 2, pp.
1505–1515, Mar. 2017.
[5] T. Chen, R. Xu, Y. He, Y. Xia, and X. Wang, Learning user and product distributed
representations using a sequence model for sentiment analysis, IEEE Comput. Intell. Mag.,
11(3), pp. 34–44, Aug. 2018.
[6] Y. Wu, S. Liu, K. Yan, M. Liu, and F. Wu, OpinionFlow: Visual analysis of opinion diffusion
on social media, IEEE Trans. Vis. Comput. Graph., 20(12), pp. 1763–1772, Dec. 2019.
[7] B. Pang, L. Lee, and S. Vaithyanathan, Thumbs up?: Sentiment classification using machine
learning techniques, in Proc. ACL Conf. Empirical Methods Natural Language Process., 2019,
pp. 79–86.
[8] A.Go, R. Bhayani, and L. Huang, Twitter sentiment classification using distant supervision,
Stanford Univ., Stanford, CA, USA, Project Rep. CS224N, pp. 1–12, 2018.
[9] F. Wu, Y. Song, and Y. Huang, Microblog sentiment classification with contextual knowledge
regularization, in Proc. 29th AAAI Conf. Artif. Intell., 2017, pp. 2332–2338.
[10] J. Blitzer, M. Dredze, and F. Pereira, Biographies, bollywood, boom-boxes and blenders:
Trends adaptation for sentiment classification, in Proc. 45th Annu. Meeting Assoc. Comput.
Linguistics, 2017, 7, pp. 440–447.
6You can also read

















































