Automated Source Code Generation and Auto-completion Using Deep Learning: Comparing and Discussing Current Language-Model-Related Approaches
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Automated Source Code Generation and Auto-completion Using Deep Learning:
Comparing and Discussing Current Language-Model-Related Approaches
Juan Cruz-Benito1 * Sanjay Vishwakarma2† , Francisco Martin-Fernandez1 , Ismael Faro1 ,
1
IBM Quantum. IBM T.J. Watson Research Center.
Yorktown Heights, NY 10598, USA
2
Electrical and Computer Engineering. Carnegie Mellon University.
Mountain View, USA
juan.cruz@ibm.com, svishwak@andrew.cmu.edu, paco@ibm.com, ismael.faro1@ibm.com
arXiv:2009.07740v4 [cs.CL] 12 Jan 2021
Abstract and Nguyen 2015; Bielik, Raychev, and Vechev 2016; Cruz-
Benito et al. 2018) used different techniques such as graph-
In recent years, the use of deep learning in language mod- based statistical LMs, probabilistic LMs, or Deep Learning
els gained much attention. Some research projects claim that
(DL) LMs to suggest code to programmers similarly to auto-
they can generate text that can be interpreted as human-
writing, enabling new possibilities in many application ar- completer features in IDEs. LMs were used to generate auto-
eas. Among the different areas related to language process- mated source code based on sample code inputs or pseudo-
ing, one of the most notable in applying this type of model- code and evaluating how this generated code performs (Oda
ing is programming languages. For years, the Machine Learn- et al. 2015; Tiwang, Oladunni, and Xu 2019; Fedus, Good-
ing community has been researching this software engineer- fellow, and Dai 2018). Another exciting application of NLP
ing area, pursuing goals like applying different approaches to into source code languages is the automatic translation be-
auto-complete, generate, fix, or evaluate code programmed by tween different languages. The work reported in (Nguyen,
humans. Considering the increasing popularity of the Deep- Nguyen, and Nguyen 2013; Roziere et al. 2020) explores
Learning-enabled language models approach, we detected a different supervised and unsupervised approaches to mi-
lack of empirical papers that compare different deep learn-
grate code between different programming languages to im-
ing architectures to create and use language models based
on programming code. This paper compares different neu- prove interoperability or port codebases written in obsolete
ral network architectures like AWD-LSTMs, AWD-QRNNs, or deprecated languages (such as COBOL or Python2). An-
and Transformer while using transfer learning and different other example found is the use of Bayesian networks, atten-
tokenizations to see how they behave in building language tion mechanisms, and pointer networks (Proksch, Lerch, and
models using a Python dataset for code generation and fill- Mezini 2015; Li et al. 2017; Donahue, Lee, and Liang 2020)
ing mask tasks. Considering the results, we discuss each ap- to fill a given code portion with missings.
proach’s different strengths and weaknesses and what gaps There is a more general understanding of the natural lan-
we find to evaluate the language models or apply them in a guages’ different characteristics in the NLP broad field.
real programming context. Since there exist many research fields related to human lan-
guages, there is a richer background on existing language
Introduction characteristics. For example, there is much knowledge on
aspects like the minimal representation units of a word in a
We are digitally surrounded by computational Language specific language, the most used words of a language, or if
Models (LMs) that guide us while writing to reduce the user a word is a neologism or not. Programming languages share
effort, suggest different options for words/sentences to en- some syntax similarities with spoken languages. However, it
hance our style, or fix our grammatical/correctness errors does not have the same restrictions in the sense of common
accurately (Kannan et al. 2016; Bryant and Briscoe 2018; words or neologisms (Allamanis et al. 2015; Karampatsis
Ghosh and Kristensson 2017). Many of the keys we press and Sutton 2019), or other syntax restrictions and features
while writing on a keyboard act as part of the inputs to com- such as punctuation, format, or style. Every programming
pose new datasets for those models that shape how we com- language has indeed reserved words and symbols to denote
municate with others. Nevertheless, does it happen in the different actions, resources, or syntax. However, there is an
same way when we write code? Succinctly, yes. Accord- essential part of the source code that is only limited by the
ing to some recent surveys found in the literature (Alla- programmer’s imagination, the conventions existing, or the
manis et al. 2018; Chen, Le, and Babar 2020), the Natu- guides for good practices. As (Karampatsis and Sutton 2019)
ral Language Processing (NLP) subfield related to program- claims,
ming language includes examples of LMs used in several
tasks and contexts. For example, the authors of (Nguyen [...] traditional language models limit the vocabulary to
a fixed set of common words. For code, this strong as-
* Contact author sumption has been shown to have a significant negative
†
Intern at IBM Quantum at the time of writing this paper effect on predictive performance [...]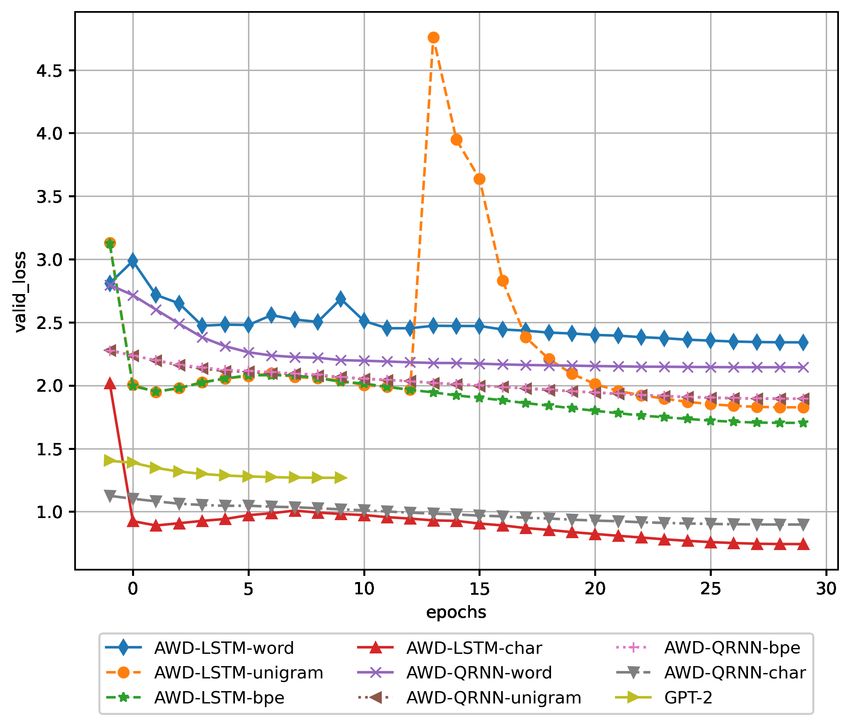
In that paper, Karampatsis and Sutton 2019 present how ity et al. 2017), the One-Billion Word benchmark (Chelba
segmenting words into subword units can improve source et al. 2014), or The Hutter Prize Wikipedia dataset 3 .
code modeling. Similarly, other researchers (Ganin et al. The AWD-LSTM is a variation of the famous Long
2016; Kim et al. 2016; Karpathy 2016) dug in representing Short-Term Memory (LSTM) architecture (Hochreiter and
source code vocabulary with a similar emphasis on model- Schmidhuber 1997). The LSTM is a type of Recurrent Neu-
ing words using sub-word units and envisioning their impor- ral Network (RNN) especially capable of processing and
tance when using neural networks (NNs). Nevertheless, how predicting sequences. That ability with sequences is the rea-
that word segmentation affect the accuracy or the appropri- son why LSTMs have been employed largely in LMs (Kim
ateness of the code generated or auto-completed in some et al. 2016). The AWD-LSTM includes several optimiza-
modern LM using deep learning approaches? That kind of tions compared to the regular LSTM. Two of the most im-
question raises the main goal for this paper: discover what portant ones are the use of Average Stochastic Gradient De-
kinds of associations between different modern neural net- scent (ASGD) and the WeightDropout. The ASGD is used
work architectures and tokenization models produce the best as the NN’s optimizer to consider the previous weights (not
results when creating LMs to generate and auto-complete only the current one) during each training iteration. The
source code. WeightDropout introduces the dropout technique (Srivastava
To pursue that goal, this research aims to conduct exper- et al. 2014) to avoid overfitting but with the characteristic of
iments combining different deep neural network (DNN) ar- returning zero, not with a subset of activations between lay-
chitectures with different tokenization and pre-trained mod- ers, like in traditional dropout, but with a random subset of
els over an existing Python dataset. Using that experimenta- weights.
tion, we want to investigate the combinations that improve The QRNN is another type of RNN that includes alternate
code generation and auto-completion tasks (for example, convolutional and pooling layers in the architecture. This de-
filling the blanks) while checking the outcomes from those sign makes the QRNN able to capture better long-term se-
tasks using metrics like accuracy and human assessment. quences and train much faster since the convolutional layers
The rest of the paper is as follows: Section 2 presents allow the computation of intermediate representations from
the different approaches followed during the research, the the input in parallel. They can be up to 16 times faster at train
DNNs used, the software methods and data employed. Sec- and test time than LSTMs while having better predictive ac-
tion 3 describes results achieved during the research accord- curacy than stacked LSTMs of the same hidden size. We
ing to different metrics and tests, while section 4 discusses use a QRNN modified (AWD-QRNN) to include the same
these findings and the implications of the results as appro- ASGD and WeightDropout modifications to improve its sta-
priate. Finally, Section 5 presents some conclusions. bility and optimize its capabilities, as for the AWD-LSTM.
We utilize AWD-LSTM and AWD-QRNN to produce
Materials and methods LMs capable of solving the task of generating source code
based on input as in the literature (Merity, Keskar, and
We have trained a set of deep neural networks using different Socher 2018a,b; Wang, Gong, and Liu 2019; Gong et al.
architectures, tokenization techniques, and software libraries 2018; Takase, Suzuki, and Nagata 2018; Yang et al. 2018;
to develop this research work. Following, we introduce the Krause et al. 2018; Merity, Keskar, and Socher 2018a;
different materials and methods employed for that purpose. Howard and Ruder 2018; Eisenschlos et al. 2019).
The Transformer is probably the most popular current
Deep Neural Networks and tokenization models DNN architecture in NLP due to its performance and re-
used cent state-of-the-art results in many tasks. It is an encoder-
Regarding the DNN architectures employed, we chose to use decoder architecture in which each layer uses attention
the following ones: ASGD Weight-Dropped LSTM (AWD- mechanisms. This use of (self-)attention mechanisms makes
LSTM) (Merity, Keskar, and Socher 2018b), Quasi Recur- Transformer able to model the relationships between all
rent Neural Networks (QRNNs) (Bradbury et al. 2017), and words in a sentence regardless of their respective position.
Transformer (Vaswani et al. 2017). These DNN architec- That implies a significant improvement over RNNs, en-
tures have been reportedly getting some state-of-the-art re- abling much more parallelization of data processing and un-
sults (Merity, Keskar, and Socher 2018b; Wang, Gong, and blocking the training over more massive datasets. The excel-
Liu 2019; Gong et al. 2018; Takase, Suzuki, and Nagata lent results of the Transformer architecture empowered the
2018; Yang et al. 2018; Krause et al. 2018; Rae et al. 2019; NLP community to create new state-of-the-art transformer-
Dai et al. 2019; Baevski and Auli 2018; Merity, Keskar, and based models (Young et al. 2018) like those used in the cur-
Socher 2018a; Howard and Ruder 2018; Eisenschlos et al. rent research: GPT-2 (Radford et al. 2019), BERT (Devlin
2019; Brown et al. 2020; Devlin et al. 2019) recently in the et al. 2019), and RoBERTa (Liu et al. 2019).
NLP field in several groundbreaking digital products1,2 and We choose to use GPT-2 since it is a causal transformer
in some of the most known datasets like the Penn Tree Bank (unidirectional) that can predict the next token in a sequence.
(Mikolov et al. 2011), WikiText-2 and WikiText-103 (Mer- So, it can generate source code based on input, allowing
us to compare the results with the AWD-LSTM and AWD-
1
https://openai.com/blog/openai-api/ QRNN experiments. Regarding BERT and RoBERTA, we
2
https://blog.google/products/search/search-language-
3
understanding-bert/ http://prize.hutter1.net/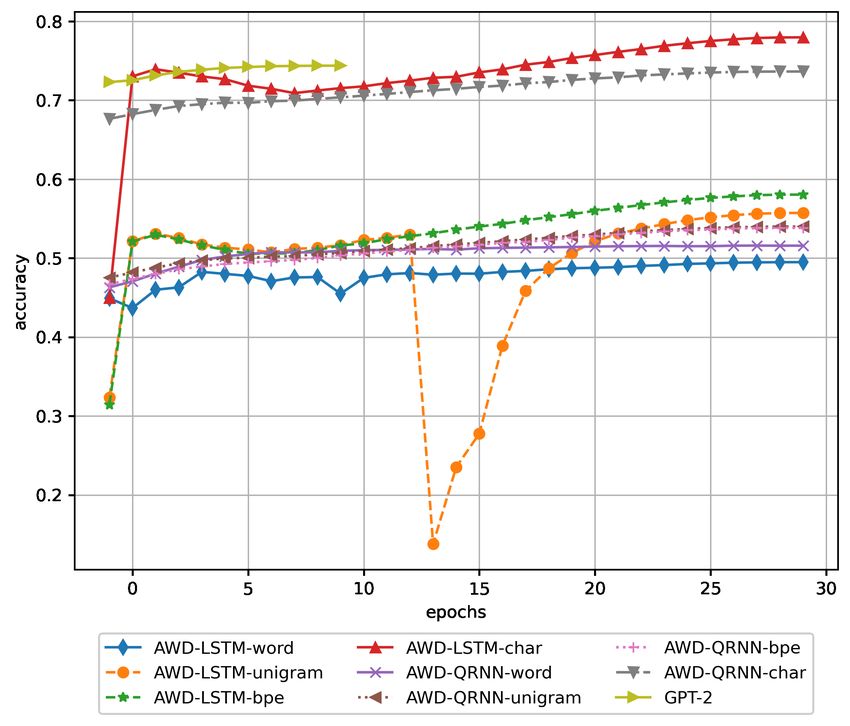
used them to study how a masked modeling approach can fer learning approach similar to other researchers in exist-
perform auto-complete source code. In that case, we did not ing literature (Howard and Ruder 2018; Ruder et al. 2019;
use them for text generation, as in the other experiments, Chronopoulou, Baziotis, and Potamianos 2019; Eisenschlos
since BERT and RoBERTa are not designed for text gen- et al. 2019). We employed the pre-trained models on En-
eration. However, they can generate text (more diverse but glish texts to later fine-tune the models for the selected tasks
slightly worse in quality) (Wang and Cho 2019). using the GitHub CodeSearchNet dataset. The deep-neural-
Considering the tokenization techniques, for every AWD- networks-related source code was coded using the FastAI
LSTM and AWD-QRNN, we chose the following types of library (versions 1.0.61 and 2 dev 0.0.21). To apply the dif-
tokens: word, unigram, char, and byte-pair encoding (BPE) ferent tokenization techniques into the AWD-LSTMs and
(Sennrich, Haddow, and Birch 2016) -albeit some stud- QRNNs, we replaced the default Spacy tokenizer (Honnibal
ies show that BPE is suboptimal for pre-training (Bostrom and Montani 2017) with Google Sentencepiece (Kudo and
and Durrett 2020)-. For the Transformer models, we used Richardson 2018), following a similar approach to (Czapla,
the default ones from the pre-defined models: Wordpiece Howard, and Kardas 2018). In the development of Trans-
method (Schuster and Nakajima 2012) for BERT and BPE former architectures to see how they perform filling the
over raw bytes instead of Unicode characters for GPT-2 and blanks and generating texts, we used HuggingFace’s Trans-
RoBERTa. The different techniques were selected because former library combined with FastAI v2 (following the Fas-
they produce different tokens’ granularity that can enrich tAI’s example6 ), as included on the code repository that
our experimentation: full words, sub-words of specific sizes, supports this paper. To train the neural networks, we have
character-sized tokens, or byte pairs. Also, they enable us used some techniques worth to mention (all the details are
to compare the tokenization between the different types of in the code repository). To find the most appropriate learn-
models and tasks to solve. ing rate to use automatically, we used the function lr find
provided by FastAI following the proposal of (Smith 2017).
Experimentation details This function trains the DNN over the dataset for a few itera-
The dataset used for the experimentation is the Python tions while varying from very low to very high learning rates
dataset included in the “GitHub CodeSearchNet Challenge at the beginning of each mini-batch of data to find which
dataset” (Husain et al. 2019). It includes 2 million (com- is optimal one regarding error (loss) metrics until the DNN
ment, Python code) pairs from open-source libraries. As ob- diverges. To pursue a faster convergence, we schedule the
served during the dataset preparation for our experiments, learning rate as described in (Smith and Topin 2019) using
there are about 11 million Python code sentences. The rea- the one cycle policy (fit one cycle) in FastAI. Considering
son to choose this dataset is that it has already been used the transfer learning technique used, we trained the first “one
in previous research related to NLP and source code. The cycle” on the top of the existing pre-trained model to later
full dataset includes several languages: Go, Java, JavaScript, unfreeze all the model layers and do a more extended train-
PHP, Python, and Ruby. We chose to use only the Python ing (10-30 epochs) to improve the results. Regarding other
part of the dataset because it enables us to compare the ex- training details, in general, we used the default parameters
isting literature that uses Python language more than other from FastAI, except for a fixed multiplier to control all the
programming languages. The software libraries and pack- dropouts (drop mult) in AWD-LSTMs and AWD-QRNNs
ages used primarily during the research were the follow- set to 0.3 because of some heuristics discovered during test-
ing: FastAI (Howard and Gugger 2020), Google Senten- ing this research. Also, we decided to train similar archi-
cePiece (Kudo and Richardson 2018), and HuggingFace’s tectures using a fixed number of epochs to make the mod-
Transformers (Wolf et al. 2020). he preprocessing applied els comparable. For the AWD-LSTM and AWD-QRNN, we
to the dataset included removing most of the code com- used 30 epochs for fine-tuning because we found during
ments and autoformatting the code according to the PEP-8 the experimentation that the most remarkable improvement
Python style guide using the autopep84 package. Regarding for every model produced occurs during that range of it-
the AWD-LSTM networks, we have been using the FastAI- erations. Similarly, we fine-tuned the transformers for ten
provided base models pre-trained using the Wikitext-103 epochs since we did not find a significant improvement after
dataset (Merity et al. 2017). There are no default pre-trained that. For more information about the training setup and soft-
models in the FastAI’s AWD-QRNN version of those net- ware details, please refer to the repository that supports this
works, so we trained them from scratch. As we introduced, paper and the FastAI documentation.
regarding the Transformer architectures, we have been us- Finally, the hardware used to run the different soft-
ing three standard pre-trained models as a basis: GPT-2, ware and neural networks training was a computer running
BERT, and RoBERTa. In each case, the exact pre-trained Ubuntu Linux 18.04 LTS Bionic Beaver (64 bits). It has two
model used were gpt2, bert-base-cased, and roberta-base. Nvidia Tesla V100 GPUs x 16 gigabytes of RAM (Nvidia
These pre-trained models are available from HuggingFace’s CUDA version 10.1), a CPU with 16 cores Intel(R) Xeon(R)
model5 . CPU E5-2690 v4 @ 2.60GHz, 120 gigabytes of RAM, and
As the reader could infer from the previous explana- 120 Gigabytes for the primary disk (HDD).
tions about using pre-trained versions, we followed a trans- All the supporting materials and software details related
to this paper are publicly available in a GitHub repository
4
https://pypi.org/project/autopep8/
5 6
https://huggingface.co/models https://docs.fast.ai/tutorial.transformers(Cruz-Benito and Vishwakarma 2020a). The NN models
produced are under the Zenodo record (Cruz-Benito and
Vishwakarma 2020b).
Results
This section presents the results achieved after the full train-
ing of the selected DNN architectures with the different to-
kenization models.
As outlined in the previous section, we trained AWD-
LSTM and AWD-QRNN DNN architectures using differ-
ent tokenization models - word, unigram, BPE, and char-,
and Transformer, using three different base models (GPT-2,
BERT, and RoBERTa). We trained every AWD-LSTM and
AWD-QRNN using one epoch to fit the model’s head and
fine-tuned for 30 epochs. Meanwhile, the Transformer net-
works were trained equally for one epoch to fit the head and Figure 1: Evolution of the accuracy of neural networks de-
fine-tune the models for ten epochs. voted to source code generation during the training epochs
We followed a two-way strategy to evaluate the NNs
trained: use the NN training metrics and human evaluation
of the models’ output. The metrics used are some of the most
common in the literature: accuracy for the validation set and
loss for the training and validation sets. They help the re-
searchers understand how the NN acts over time, how the
model is fitted to the dataset, and the performance and error
scores while using training and validation datasets. In this
case, the accuracy is the score concerning the LM’s ability
to predict the next word of filling the missings accurately
given a sequence of words from the validation set. The loss
metrics report the error after applying the DNN to the train-
ing or validation set, respectively. Every implementation de-
tail related to the DNNs and the metrics is available in the
GitHub repository (Cruz-Benito and Vishwakarma 2020a).
Apart from those metrics, we assessed the models’ quality Figure 2: Evolution of the accuracy of neural networks de-
by applying them in the proposed tasks -generate text and voted to filling the blanks during the training epochs
auto-complete- and observing how they perform.
Training results model combination performed better in the case of ac-
curacy metrics was the AWD-LSTM with char tokeniza-
Table 1 displays the final metrics for the different NNs at tion (accuracy 0.779633). The second one was the GPT-
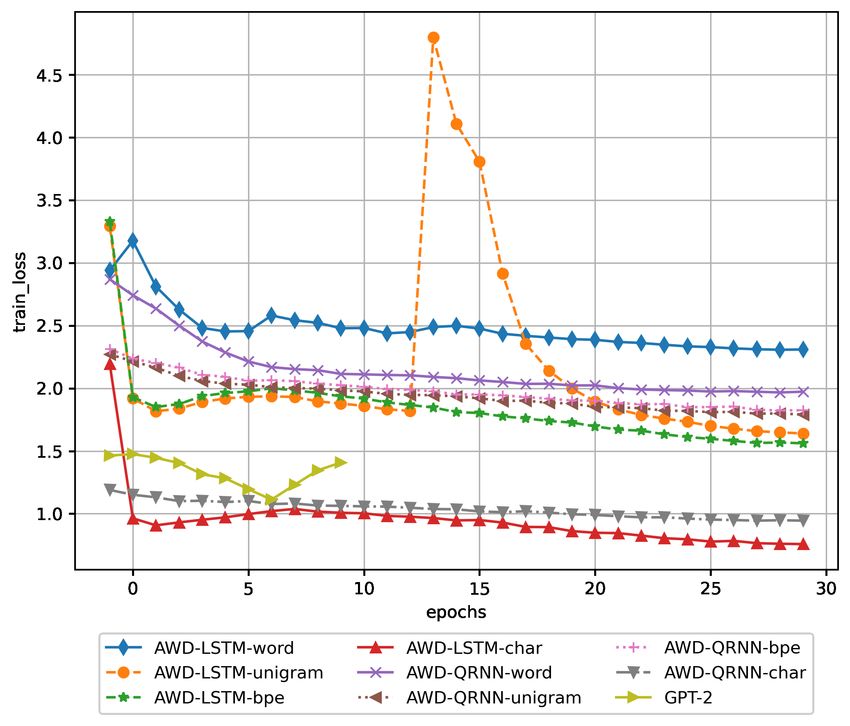
the end of the training. Similarly, figures 1 and 2 show the 2 transformer model -BPE over raw bytes tokenization-
evolution of each model’s accuracy during the training. Fig- (0.743738), and the third one the AWD-QRNN with char to-
ures 3, 4, 5, and 6 show the training loss and validation loss kenization (0.736358). Related to AWD-LSTM and AWD-
evolution along the training epochs. QRNN architectures’ combination with other tokenization
techniques, we obtained poor results on accuracy: between
DNN architecture Epochs Accuracy Train loss Validation loss Pre-trained?
AWD-LSTM word 31 0.494893 2.308937 2.341698 Yes 0.494893 to 0.580373. On the other hand, according to the
AWD-LSTM unigram
AWD-LSTM BPE
31
31
0.557226
0.580373
1.639875
1.561393
1.826841
1.703536
Yes
Yes
results shown in Table 1 and Figure 2, both models (BERT
AWD-LSTM char 31 0.779633 0.757956 0.742808 Yes and RoBERTa) had excellent accuracy results in the trans-
AWD-QRNN word 31 0.515747 1.972508 2.144126 No
AWD-QRNN unigram 31 0.539951 1.790150 1.894901 No former models intended for auto-completion 0.999238 and
AWD-QRNN BPE 31 0.538290 1.824709 1.896698 No
AWD-QRNN char 31 0.736358 0.944526 0.897850 No 0.999468, respectively.
GPT-2 11 0.743738 1.407818 1.268246 Yes
BERT 11 0.999238 0.014755 0.004155 Yes
About how the pre-training and transfer learning af-
RoBERTa 11 0.999468 0.010569 0.002920 Yes fects the results, the two top results regarding the accu-
racy come up from pre-trained models in the English lan-
Table 1: Results after full training of each NN architecture guage (0.779633 and 0.743738), yet the third-best result
was from a non-pre-trained network (0.736358). Compar-
On the one hand, according to the results displayed in Ta- ing the similar networks, the average (mean) accuracy of
ble 1 and Figure 1, for neural networks intended for auto- the AWD-LSTM pre-trained versions is 0.603031 (standard
mated source code generation -AWD-LSTM, AWD-QRNN, deviation -std- of 0.123144), while the average accuracy of
and Transformer GPT-2-, the overall NN-tokenization AWD-QRNN non-pre-trained versions was 0.582587 (std ofFigure 3: Evolution of the training loss of DNNs devoted to Figure 5: Evolution of the validation loss of DNNs devoted generating source code during the training epochs to generating source code during the training epochs Figure 4: Evolution of the training loss of neural networks Figure 6: Evolution of the validation loss of neural networks devoted to filling the blanks during the training epochs devoted to filling the blanks during the training epochs 0.103107). The only combination NN-tokenization model code: AST-LSTM AST-LSTM (accuracy 90.3%) (Tiwang, that worked worse when it was pre-trained was the one with Oladunni, and Xu 2019) or AST-MLP (90.1%) (Tiwang, the word tokenization. Oladunni, and Xu 2019). So, considering this, our results Regarding the observed losses, it is worth commenting are good in terms of accuracy compared to the existing peer- that the AWD-LSTM char, AWD-QRNN char, and the three reviewed literature. As a side note, we did not find models transformer models (GPT-2, BERT, RoBERTa) could be available publicly to compare with, neither in these nor in trained for more epochs or with a higher learning rate. The other peer-reviewed papers. For the models devoted to auto- model may be be underfitting since the training loss is higher complete code (BERT and RoBERTa), as of now, we did than the validation loss (Table 1, figures 3, 4, 5, and 6). not find peer-reviewed papers trying to solve this task using To put in context the accuracy achieved during the ex- Transformer architectures. perimentation, we compare the results with the existing lit- erature. The papers (Tiwang, Oladunni, and Xu 2019; Li Results of using the trained DNN models et al. 2017; Raychev, Bielik, and Vechev 2016) present mod- Following, we introduce some examples of how the different els trained to generate Python code considered state of the neural networks generated source code or auto-completed it. art when published. Our three best models trained to gen- These examples are used to assess the model’s output qual- erate source code outperform the approaches based on the ity, avoiding relying only on the NN metrics. This valida- following architectures: Vanilla LSTM (accuracy: 67.3%) tion using more methods than the simple metrics is com- (Li et al. 2017), Attention LSTM (69.8%) (Li et al. 2017), mon in the AI and NLP fields. Many papers employ human Pointer Mixture Network (70.1%) (Li et al. 2017), or Proba- evaluation or specialized metrics to grasp better the model’s bilistic Model (69.2%) (Raychev, Bielik, and Vechev 2016). performance and capture any other particular detail or qual- Our models perform worse than other approaches based on ity indicator on the related task proposed. In this case, we the abstract syntax tree (AST) instead of using the textual show only those with the best accuracy results. To gener-
ate source code, we show output from AWD-LSTM char, {’sequence’: ’[CLS] from pandas import def [SEP]’,
’score’: 8.858884393703192e-05,
AWD-QRNN char, and GPT-2. For auto-completion, we ’token’: 19353,
show results from BERT and RoBERTa. For the source code ’token_str’: ’def’}]
generation, every model faced the same challenges (Cruz- RoBERTa
Benito and Vishwakarma 2020a). Those are the results when [{’sequence’: ’from pandas import\n’,
any of them try to generate five different sentences with the ’score’: 0.6224209666252136,
’token’: 50118,
input from pandas import: ’token_str’: ’_
C’},
{’sequence’: ’from pandas import.’,
AWD-LSTM char ’score’: 0.22222988307476044,
’token’: 4,
"from pandas import defaults as _rp pandas =" ’token_str’: ’.’},
{’sequence’: ’from pandas import ’,
"from pandas import DataFrameEncoder if self" ’score’: 0.038354743272066116,
"from pandas import OrderedDict else: passed" ’token’: 1437,
’token_str’: ’_
G’},
"from pandas import sequence if type(seq1) i"
{’sequence’: ’from pandas import\n\n’,
"from pandas import conditional_insertion as" ’score’: 0.028566861525177956,
’token’: 50140,
AWD-QRNN char ’token_str’: ’_
C_C’},
{’sequence’: ’from pandas import.’,
’score’: 0.021909384056925774,
"from pandas import webbrowser self.login fr" ’token’: 479,
"from pandas import __http_args or [ ’Pipeli" ’token_str’: ’_
G.’}]
"from pandas import iterations is not None p"
"from pandas import service params to servic" For auto-completion, we observe that almost no auto-
"from pandas import difference if not isinst" completion is right. The more accurate sentences from the
Python language point are the ones in which the mask to-
GPT-2 ken has been replaced by white space or by a dot. Neverthe-
"from pandas import time, np\n
"
less, they are not correct but closer to be right compared to
"from pandas import pandas from time.time.datetime import Date\n the other ones. One interesting thing is that BERT assigns
with n"
"from pandas import gtk, os\n
a very high score to a predicted mask, which is not correct,
from pandas_utils import pandas_utils\n and shallow scores to the other possible solutions (also in-
import pylint"
"from pandas import wcpy\n correct). In the case of RoBERTa, it gives lower scores to
import cpy_context as cpy_context\n all the solutions, yet also fails on the correctness: the second
"
"from pandas import gkpy\n sentence predicted (score 0.222) can be closer to be right
"""\n
... pass\n
compared to the first one (score 0.622).
kwargs = cg"
To assess the generation, we do not focus on the semantics
Discussion
of the imports used or whether they are part of the Pandas li- Considering the results obtained, one could convincingly as-
brary or not, but on the language’s correctness. In general, sert that the tokenization model used profoundly affects the
from a Python language perspective, the outputs from GPT- results when generating automated source code. Although
2 are better. The outputs include line breaks, indentation, and that may be accurate, we must discuss it carefully.
fair use of multiple inputs in one sentence (except in one of
the outputs). The AWD-LSTM and AWD-QRNN failed to Discussing the outcomes from resulting models
auto-generate an import sentence appropriately, or at least, First, our overall results are consistent with the existing liter-
they fail regarding the usual manner used by regular users. ature (Karampatsis and Sutton 2019; Ganin et al. 2016; Kim
As a final comment on this, the other models trained failed et al. 2016; Karpathy 2016). Sub-word tokenization works
on similar issues, plus they do not get enough semantic con- better in the case of modeling source code, as 2019 stated.
text related to the Pandas library. Every result obtained is consistent in that sense. Even more,
Similarly, concerning the source code auto-completion, as 2016 envision, char tokenization probably should the best
both BERT and RoBERTa tried to autofill the mask token option to try by default when dealing with LMs and source
in the sentence from pandas import [MASK]. These are the code. Furthermore, according to the results achieved, mod-
results: els such as GPT-2 -using a tokenization model based on BPE
BERT over raw bytes- can outperform LSTM/QRNN models like
[{’sequence’: ’[CLS] from pandas import [SEP] [SEP]’,
those we tested to grasp better the internals of a program-
’score’: 0.9969683289527893, ming language. As showcased during the results, even if
’token’: 102,
’token_str’: ’[SEP]’},
GPT-2 was not the best model in terms of accuracy, it gave
{’sequence’: ’[CLS] from pandas import [CLS] [SEP]’, better code outputs than the other ones selected for the com-
’score’: 0.0010887219104915857,
’token’: 101, parison.
’token_str’: ’[CLS]’}, As future work, it would be great to check if the better
{’sequence’: ’[CLS] from pandas import. [SEP]’,
’score’: 0.0004200416151434183, textual output in the case of GPT-2 is because of a) it is a
’token’: 119, much bigger and better pre-trained model (163,037,184 pa-
’token_str’: ’.’},
{’sequence’: ’[CLS] from pandas import ; [SEP]’, rameters against 36,491 for AWD-LSTM and AWD-QRNN
’score’: 0.00027348980074748397,
’token’: 132,
models), b) it is related to dataset’s size or quality, c) if it is
’token_str’: ’;’}, related to both causes or, d) if it is related to other issues.Continuing with the comments about the accuracy, one 2016) use custom datasets, but we find a lack in the liter-
may note that the textual outputs generated by AWD-LSTM ature of well-recognized code datasets to use. Comparing
char, AWD-QRNN char, and GPT-2 could be polished to with other recent papers in the NLP field used as the basis
be more accurate. The final training loss is higher than the for this research (Radford et al. 2019; Devlin et al. 2019; Liu
validation loss for the three selected DNN architectures, et al. 2019; Brown et al. 2020), the dataset may be relatively
which can be a sign of underfitting. We find the same is- small to train a big LM to accomplish appropriately chal-
sue (train loss ¡¡ valid loss) for BERT and RoBERTa-based lenging tasks like generating source code or auto-completing
models. Whether the purpose of this paper is not to produce it. Future work may be testing these or new approaches in
state-of-the-art results per se, we continued the training for bigger datasets to train big LMs focused on modeling the
over five more epochs to verify it. The improvement ob- Python language and checking whether the results are bet-
tained from extending the training for the best approaches ter. Recent examples of LMs -such as GPT-3 (Brown et al.
was residual in general, so we decided to report the results 2020)- claim to produce accurate textual outputs even in
for 1+30 epochs in AWD-LSTMs and AWD-QRNNs, and contexts in which they were not trained. Part of the expla-
1+10 epochs for Transformer. nation given for that ability is the use of gargantuan datasets
combined with Transformer and other attention-based archi-
Examining the effect of pre-training and transfer tectures. So, those approaches can also be relevant to other
learning contexts like ours. Another line for future research can be us-
ing datasets focused on specific libraries or Python aspects
Regarding the pre-training and transfer learning, every pre- and verify if these approaches specialize positively for those
trained model (on English-based datasets) got better accu- contexts the DNN models used in this paper.
racy than its non-pre-trained counterparts except in word
tokenization models. It seems to be strongly related to the Related to evaluating the code generated or filled, we ob-
statements we introduced at the beginning of this paper, cit- served in the literature different approaches (Celikyilmaz,
ing (Allamanis et al. 2015; Karampatsis and Sutton 2019) Clark, and Gao 2020; Roziere et al. 2020). In the con-
about the source code does not have the same restrictions text of LMs modeling source code, many papers and soft-
in the sense of common words or neologisms. In this sense, ware libraries devoted to translating between programming
the conclusion comes into our mind rapidly: if we consider languages typically evaluate text generation using methods
source code words in “word” units, they probably will not and metrics like BLEU (Papineni et al. 2002), or variants
fit in the fixed set of words used in a human language like like SacreBLEU (Post 2018). Other papers like (Tiwang,
English. So, the LM’s knowledge acquired during the pre- Oladunni, and Xu 2019) rely on the accuracy to assess an
training is not entirely valid when we get out of that fixed set LM’s performance based on deep learning. Some models
of words that compose a language. Most words in the pro- can even solve different tasks that are part of existing bench-
gramming language are neologisms for the LMs pre-trained marks (Weston et al. 2015) or are evaluated, checking their
in English, and thus, it needs to incorporate them and their perplexity (similarly to those that evaluate the model using
relationships into the learned knowledge. For the sub-word the accuracy). The current tendency in large models is to
units, the LM can be less sensible to the neologisms. Po- evaluate them using human intervention to evaluate the out-
tentially, it could be more robust the more divided a word put’s quality (Radford et al. 2019; Brown et al. 2020). We
is since the set of bytes or chars is more straightforward assessed the models using accuracy during our experiments
than the chunks present in richer constructions or informa- and evaluated the models’ textual outputs based on our prior
tion units. human knowledge. It would be interesting for the future to
plan new evaluation processes involving larger cohorts of
Going deeper into this research, concerning the pre-
source code experts to evaluate the models such as (Radford
training effect over LMs modeling source code, it could be
et al. 2019; Brown et al. 2020) do. One of the potential new
worth researching the relationship between the pre-training
assessments can be usability tests conducted with program-
in different human-spoken languages and the LM ability to
mers. They can compare the code they would write against
work with existing source code specific programming lan-
the code proposed by any of the DNNs presented here and
guages.
the result from other common code auto-completion tools
included in integrated development environments. As we
Reviewing the textual assessment of resulting LMs outlined in the results section, relying only on metrics like
About the tests made generating source code or filling in accuracy should not be enough. As in our case, accuracy
the blanks using the trained LMs, we think that, in general, and the other metrics can be a good indicator of the model’s
the textual results obtained are not so good, yet they are in- performance, yet we need to verify LMs behavior and qual-
formative of how LMs are working and how they can be ity using complementary methods like specialized metrics or
improved. One of the things that can explain these results human evaluation. For tasks like auto-completion or source
is the dataset used. In this case, we used a public dataset code generation, there are no existing specialized metrics
that other researchers can use to make results and experi- (like BLEU in translation, for example), so one of the fu-
ments comparable and replicable. In the literature, we do ture research lines is improving the evaluation of LMs for
not find a standard dataset for these tasks against which source code. Based on some existing ideas in broad NLP,
we can compare easily. Other papers (Tiwang, Oladunni, there are many opportunities to explore in that sense. From
and Xu 2019; Li et al. 2017; Raychev, Bielik, and Vechev new test suites for language models used in source code con-texts (Roziere et al. 2020) to behavioral testing (Ribeiro et al. Bielik, P.; Raychev, V.; and Vechev, M. 2016. PHOG: proba-
2020) or human-centric evaluation of the models (Celiky- bilistic model for code. In International Conference on Ma-
ilmaz, Clark, and Gao 2020) with particular emphasis on chine Learning, 2933–2942.
reproducible and unbiased assessments, or combinations of
Bostrom, K.; and Durrett, G. 2020. Byte Pair Encoding is
automatic testing and human-centric assessments.
Suboptimal for Language Model Pretraining. In Findings
of the Association for Computational Linguistics: EMNLP
Conclusions 2020, 4617–4624. Online: Association for Computational
Linguistics. URL https://www.aclweb.org/anthology/2020.
This paper compares how different approaches to tokeniza- findings-emnlp.414.
tion models, deep neural network architectures, pre-trained
models, and transfer learning affect the results from lan- Bradbury, J.; Merity, S.; Xiong, C.; and Socher, R. 2017.
guage models used to generate source code or auto-complete Quasi-recurrent neural networks. In Proceedings of the
software pieces. We studied different DNN architectures like 5th International Conference on Learning Representations
AWD-LSTM, AWD-QRNN, and Transformer to seek which (ICLR 2017). URL https://arxiv.org/pdf/1611.01576.pdf.
kind of them work better with different tokenization mod- Brown, T. B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.;
els (word, unigram, BPE, and char). Also, we compared the Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell,
pre-training effect on the results given by LMs after training A.; et al. 2020. Language models are few-shot learners. Ad-
them and fine-tuning them via transfer learning to work with vances in Neural Information Processing Systems 33. URL
other languages (English language to Python programming https://arxiv.org/pdf/2005.14165.pdf.
language). As a result of this work, we find that in small
LMs (like our AWD-LSTM and AWD-QRNN models), the Bryant, C.; and Briscoe, T. 2018. Language model based
tokenization using char-sized chunks works better than us- grammatical error correction without annotated training
ing any other tokenization models. In larger models like the data. In Proceedings of the Thirteenth Workshop on Inno-
Transformer GPT-2, the accuracy was slightly worse than vative Use of NLP for Building Educational Applications,
the other architectures. However, GPT-2 raised better results 247–253.
on the source code generation tests (even using another to- Celikyilmaz, A.; Clark, E.; and Gao, J. 2020. Eval-
kenization approach like BPE over raw bytes). For source uation of Text Generation: A Survey. arXiv preprint
code auto-completion, we tested some transformer models arXiv:2006.14799 .
like BERT and RoBERTA. While their accuracy was above
any other models, they did not perform very well when per- Chelba, C.; Mikolov, T.; Schuster, M.; Ge, Q.; Brants, T.;
forming the tasks proposed in our tests. In general, we find Koehn, P.; and Robinson, T. 2014. One Billion Word Bench-
that pre-trained models work better, even if they were not mark for Measuring Progress in Statistical Language Mod-
trained initially for a programming language like Python eling. In Fifteenth Annual Conference of the International
(our models were pre-trained using the English language). Speech Communication Association.
Finally, related to evaluating tasks like automating source Chen, H.; Le, T. H. M.; and Babar, M. A. 2020. Deep
code generation and source code auto-completion, we raise Learning for Source Code Modeling and Generation: Mod-
concerns about the literature gaps and propose some re- els, Applications and Challenges. ACM Computing Surveys
search lines to work on in the future. (CSUR) .
Chronopoulou, A.; Baziotis, C.; and Potamianos, A. 2019.
Acknowledgments An Embarrassingly Simple Approach for Transfer Learning
We thank the IBM Quantum team and the IBM Research from Pretrained Language Models. In Proceedings of the
ETX team for the insightful discussions about this research 2019 Conference of the North American Chapter of the As-
and the support received during the development of this re- sociation for Computational Linguistics: Human Language
search. Technologies, Volume 1 (Long and Short Papers), 2089–
2095.
References Cruz-Benito, J.; Faro, I.; Martı́n-Fernández, F.; Therón, R.;
and Garcı́a-Peñalvo, F. J. 2018. A Deep-Learning-based
Allamanis, M.; Barr, E. T.; Bird, C.; and Sutton, C. 2015. proposal to aid users in Quantum Computing programming.
Suggesting accurate method and class names. In Proceed- In International Conference on Learning and Collaboration
ings of the 2015 10th Joint Meeting on Foundations of Soft- Technologies, 421–430. Springer.
ware Engineering, 38–49.
Cruz-Benito, J.; and Vishwakarma, S. 2020a.
Allamanis, M.; Barr, E. T.; Devanbu, P.; and Sutton, C. 2018. cbjuan/tokenizers-neural-nets-2020-paper: v1.0 doi:
A survey of machine learning for big code and naturalness. 10.5281/zenodo.4011767. URL https://github.com/cbjuan/
ACM Computing Surveys (CSUR) 51(4): 1–37. tokenizers-neural-nets-2020-paper/.
Baevski, A.; and Auli, M. 2018. Adaptive Input Representa- Cruz-Benito, J.; and Vishwakarma, S. 2020b. NN mod-
tions for Neural Language Modeling. In International Con- els produced by cbjuan/tokenizers-neural-nets-2020-paper:
ference on Learning Representations. v1.0 doi:10.5281/zenodo.4293857.Czapla, P.; Howard, J.; and Kardas, M. 2018. Universal lan- Husain, H.; Wu, H.-H.; Gazit, T.; Allamanis, M.; and
guage model fine-tuning with subword tokenization for pol- Brockschmidt, M. 2019. Codesearchnet challenge: Eval-
ish. arXiv preprint arXiv:1810.10222 . uating the state of semantic code search. arXiv preprint
Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J. G.; Le, Q.; and arXiv:1909.09436 .
Salakhutdinov, R. 2019. Transformer-XL: Attentive Lan- Kannan, A.; Kurach, K.; Ravi, S.; Kaufmann, T.; Tomkins,
guage Models beyond a Fixed-Length Context. In Proceed- A.; Miklos, B.; Corrado, G.; Lukacs, L.; Ganea, M.; Young,
ings of the 57th Annual Meeting of the Association for Com- P.; et al. 2016. Smart reply: Automated response suggestion
putational Linguistics, 2978–2988. for email. In Proceedings of the 22nd ACM SIGKDD In-
ternational Conference on Knowledge Discovery and Data
Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2019.
Mining, 955–964.
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding. In NAACL-HLT (1). Karampatsis, R.-M.; and Sutton, C. 2019. Maybe deep neu-
ral networks are the best choice for modeling source code.
Donahue, C.; Lee, M.; and Liang, P. 2020. Enabling arXiv preprint arXiv:1903.05734 .
Language Models to Fill in the Blanks. In Proceed-
ings of the 58th Annual Meeting of the Association for Karpathy, A. 2016. The unreasonable effectiveness of recur-
Computational Linguistics, 2492–2501. Online: Association rent neural networks URL http://karpathy.github.io/2015/05/
for Computational Linguistics. doi:10.18653/v1/2020.acl- 21/rnn-effectiveness.
main.225. URL https://www.aclweb.org/anthology/2020. Kim, Y.; Jernite, Y.; Sontag, D.; and Rush, A. M. 2016.
acl-main.225. Character-Aware Neural Language Models. In Proceedings
Eisenschlos, J.; Ruder, S.; Czapla, P.; Kadras, M.; Gug- of the Thirtieth AAAI Conference on Artificial Intelligence,
ger, S.; and Howard, J. 2019. MultiFiT: Efficient Multi- AAAI’16, 2741–2749. AAAI Press.
lingual Language Model Fine-tuning. In Proceedings of Krause, B.; Kahembwe, E.; Murray, I.; and Renals, S. 2018.
the 2019 Conference on Empirical Methods in Natural Lan- Dynamic Evaluation of Neural Sequence Models. In Dy,
guage Processing and the 9th International Joint Confer- J.; and Krause, A., eds., Proceedings of the 35th Inter-
ence on Natural Language Processing (EMNLP-IJCNLP), national Conference on Machine Learning, volume 80 of
5702–5707. Hong Kong, China: Association for Computa- Proceedings of Machine Learning Research, 2766–2775.
tional Linguistics. doi:10.18653/v1/D19-1572. URL https: Stockholmsmässan, Stockholm Sweden: PMLR. URL http:
//www.aclweb.org/anthology/D19-1572. //proceedings.mlr.press/v80/krause18a.html.
Fedus, W.; Goodfellow, I.; and Dai, A. M. 2018. MaskGAN: Kudo, T.; and Richardson, J. 2018. SentencePiece: A sim-
Better Text Generation via Filling in the . In Inter- ple and language independent subword tokenizer and deto-
national Conference on Learning Representations. Online. kenizer for Neural Text Processing. In Proceedings of the
URL https://arxiv.org/pdf/1801.07736.pdf. 2018 Conference on Empirical Methods in Natural Lan-
guage Processing: System Demonstrations, 66–71.
Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle,
H.; Laviolette, F.; Marchand, M.; and Lempitsky, V. 2016. Li, J.; Wang, Y.; Lyu, M. R.; and King, I. 2017. Code com-
Domain-adversarial training of neural networks. The Jour- pletion with neural attention and pointer networks. In Pro-
nal of Machine Learning Research 17(1): 2096–2030. ceedings of the Twenty-Seventh International Joint Confer-
ence on Artificial Intelligence (IJCAI-18), 4159–41655.
Ghosh, S.; and Kristensson, P. O. 2017. Neural networks for
text correction and completion in keyboard decoding. arXiv Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.;
preprint arXiv:1709.06429 . Levy, O.; Lewis, M.; Zettlemoyer, L.; and Stoyanov, V.
2019. Roberta: A robustly optimized bert pretraining ap-
Gong, C.; He, D.; Tan, X.; Qin, T.; Wang, L.; and Liu, T.-Y. proach. arXiv preprint arXiv:1907.11692 .
2018. Frage: Frequency-agnostic word representation. Ad-
vances in neural information processing systems 31: 1334– Merity, S.; Keskar, N. S.; and Socher, R. 2018a. An anal-
1345. ysis of neural language modeling at multiple scales. arXiv
preprint arXiv:1803.08240 .
Hochreiter, S.; and Schmidhuber, J. 1997. Long short-term
Merity, S.; Keskar, N. S.; and Socher, R. 2018b. Regular-
memory. Neural computation 9(8): 1735–1780.
izing and Optimizing LSTM Language Models. In Interna-
Honnibal, M.; and Montani, I. 2017. spacy 2: Natural tional Conference on Learning Representations.
language understanding with bloom embeddings, convolu- Merity, S.; Xiong, C.; Bradbury, J.; and Socher, R. 2017.
tional neural networks and incremental parsing URL https: Pointer sentinel mixture models. In Proceedings of the
//spacy.io/. 5th International Conference on Learning Representations
Howard, J.; and Gugger, S. 2020. Fastai: A layered API for (ICLR 2017). URL https://arxiv.org/pdf/1609.07843.pdf.
deep learning. Information 11(2): 108. Mikolov, T.; Deoras, A.; Kombrink, S.; Burget, L.; and
Howard, J.; and Ruder, S. 2018. Universal Language Model Černockỳ, J. 2011. Empirical evaluation and combination
Fine-tuning for Text Classification. In Proceedings of the of advanced language modeling techniques. In Twelfth an-
56th Annual Meeting of the Association for Computational nual conference of the international speech communication
Linguistics (Volume 1: Long Papers), 328–339. association.Nguyen, A. T.; and Nguyen, T. N. 2015. Graph-based sta- Acoustics, Speech and Signal Processing (ICASSP), 5149–
tistical language model for code. In 2015 IEEE/ACM 37th 5152. IEEE.
IEEE International Conference on Software Engineering, Sennrich, R.; Haddow, B.; and Birch, A. 2016. Neural Ma-
volume 1, 858–868. IEEE. chine Translation of Rare Words with Subword Units. In
Nguyen, A. T.; Nguyen, T. T.; and Nguyen, T. N. 2013. Lexi- Proceedings of the 54th Annual Meeting of the Associa-
cal statistical machine translation for language migration. In tion for Computational Linguistics (Volume 1: Long Papers),
Proceedings of the 2013 9th Joint Meeting on Foundations 1715–1725.
of Software Engineering, 651–654. Smith, L. N. 2017. Cyclical learning rates for training neural
Oda, Y.; Fudaba, H.; Neubig, G.; Hata, H.; Sakti, S.; Toda, networks. In 2017 IEEE Winter Conference on Applications
T.; and Nakamura, S. 2015. Learning to generate pseudo- of Computer Vision (WACV), 464–472. IEEE.
code from source code using statistical machine translation Smith, L. N.; and Topin, N. 2019. Super-convergence: Very
(t). In 2015 30th IEEE/ACM International Conference on fast training of neural networks using large learning rates.
Automated Software Engineering (ASE), 574–584. IEEE. In Artificial Intelligence and Machine Learning for Multi-
Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W.-J. 2002. Domain Operations Applications, volume 11006, 1100612.
BLEU: a method for automatic evaluation of machine trans- International Society for Optics and Photonics.
lation. In Proceedings of the 40th annual meeting of the Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; and
Association for Computational Linguistics, 311–318. Salakhutdinov, R. 2014. Dropout: a simple way to prevent
Post, M. 2018. A Call for Clarity in Reporting BLEU neural networks from overfitting. The journal of machine
Scores. In Proceedings of the Third Conference on Machine learning research 15(1): 1929–1958.
Translation: Research Papers, 186–191. Brussels, Belgium: Takase, S.; Suzuki, J.; and Nagata, M. 2018. Direct Out-
Association for Computational Linguistics. doi:10.18653/ put Connection for a High-Rank Language Model. In Pro-
v1/W18-6319. URL https://www.aclweb.org/anthology/ ceedings of the 2018 Conference on Empirical Methods in
W18-6319. Natural Language Processing, 4599–4609.
Proksch, S.; Lerch, J.; and Mezini, M. 2015. Intelligent code Tiwang, R.; Oladunni, T.; and Xu, W. 2019. A Deep Learn-
completion with Bayesian networks. ACM Transactions on ing Model for Source Code Generation. In 2019 Southeast-
Software Engineering and Methodology (TOSEM) 25(1): 1– Con, 1–7. IEEE.
31. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones,
Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; and L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. At-
Sutskever, I. 2019. Language Models are Unsupervised tention is all you need. In Advances in neural information
Multitask Learners . processing systems, 5998–6008.
Rae, J. W.; Potapenko, A.; Jayakumar, S. M.; Hillier, C.; and Wang, A.; and Cho, K. 2019. BERT has a Mouth, and It
Lillicrap, T. P. 2019. Compressive Transformers for Long- Must Speak: BERT as a Markov Random Field Language
Range Sequence Modelling. In International Conference on Model. In Proceedings of the Workshop on Methods for
Learning Representations. Optimizing and Evaluating Neural Language Generation
(NAACL HLT 2019), 30–36.
Raychev, V.; Bielik, P.; and Vechev, M. 2016. Probabilistic
model for code with decision trees. ACM SIGPLAN Notices Wang, D.; Gong, C.; and Liu, Q. 2019. Improving Neural
51(10): 731–747. Language Modeling via Adversarial Training. In Chaud-
huri, K.; and Salakhutdinov, R., eds., Proceedings of the
Ribeiro, M. T.; Wu, T.; Guestrin, C.; and Singh, S. 2020.
36th International Conference on Machine Learning, vol-
Beyond Accuracy: Behavioral Testing of NLP Models with
ume 97 of Proceedings of Machine Learning Research,
CheckList. In Proceedings of the 58th Annual Meeting of
6555–6565. Long Beach, California, USA: PMLR. URL
the Association for Computational Linguistics, 4902–4912.
http://proceedings.mlr.press/v97/wang19f.html.
Online: Association for Computational Linguistics. doi:
10.18653/v1/2020.acl-main.442. URL https://www.aclweb. Weston, J.; Bordes, A.; Chopra, S.; Rush, A. M.; van
org/anthology/2020.acl-main.442. Merriënboer, B.; Joulin, A.; and Mikolov, T. 2015. Towards
ai-complete question answering: A set of prerequisite toy
Roziere, B.; Lachaux, M.-A.; Chanussot, L.; and Lample, tasks. arXiv preprint arXiv:1502.05698 .
G. 2020. Unsupervised Translation of Programming Lan-
guages. Advances in Neural Information Processing Systems Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.;
33. Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; Davi-
son, J.; Shleifer, S.; von Platen, P.; Ma, C.; Jernite, Y.; Plu,
Ruder, S.; Peters, M. E.; Swayamdipta, S.; and Wolf, T. J.; Xu, C.; Le Scao, T.; Gugger, S.; Drame, M.; Lhoest,
2019. Transfer learning in natural language processing. In Q.; and Rush, A. 2020. HuggingFace’s ransformers: State-
Proceedings of the 2019 Conference of the North American of-the-Art Natural Language Processing. In Proceedings
Chapter of the Association for Computational Linguistics: of the 2020 Conference on Empirical Methods in Natu-
Tutorials, 15–18. ral Language Processing: System Demonstrations, 38–45.
Schuster, M.; and Nakajima, K. 2012. Japanese and korean Online: Association for Computational Linguistics. URL
voice search. In 2012 IEEE International Conference on https://www.aclweb.org/anthology/2020.emnlp-demos.6.Yang, Z.; Dai, Z.; Salakhutdinov, R.; and Cohen, W. W. 2018. Breaking the Softmax Bottleneck: A High-Rank RNN Language Model. In International Conference on Learning Representations. Young, T.; Hazarika, D.; Poria, S.; and Cambria, E. 2018. Recent trends in deep learning based natural language pro- cessing. IEEE Computational Intelligence magazine 13(3): 55–75.
You can also read

















































