Automatic Translation of Noun Compounds from English to Hindi
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Automatic Translation of Noun Compounds from English to Hindi
Thesis submitted in partial fulfillment
of the requirements for the degree of
MS by Research
in
Computer Science with specialization in NLP
by
Prashant Mathur
200502016
mathur@research.iiit.ac.in
Language Technology Research Center
International Institute of Information Technology
Hyderabad - 500032, INDIA
October, 2011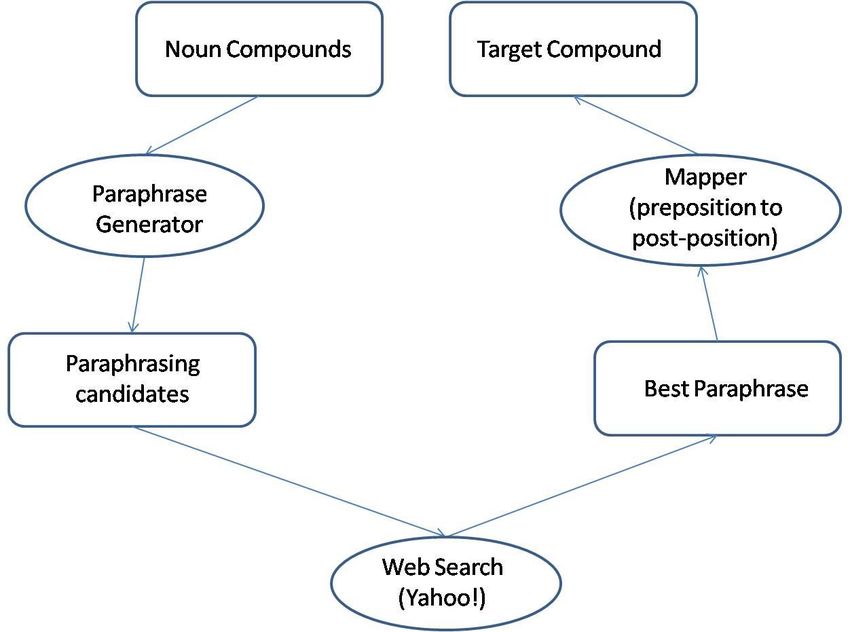
Copyright c Prashant Mathur, 2010
All Rights Reserved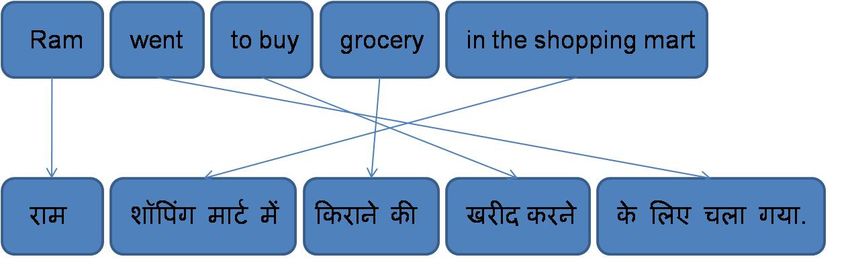
International Institute of Information Technology
Hyderabad, India
CERTIFICATE
It is certified that the work contained in this thesis, titled “Automatic Translation of Noun Compounds
from English to Hindi” by Prashant Mathur, has been carried out under my supervision and is not
submitted elsewhere for a degree.
Date Advisor: Dr. Soma Paul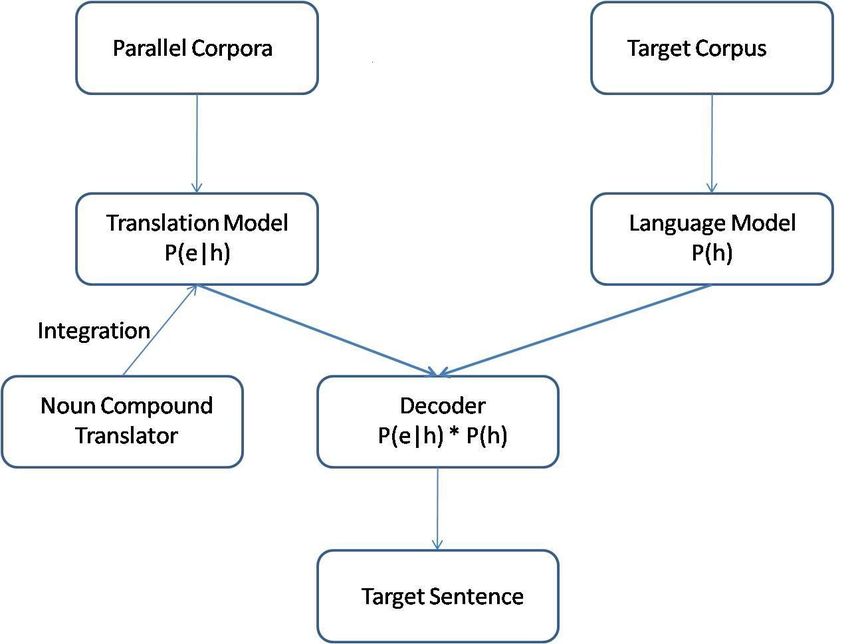
To Papa and Mummy For being the world’s best parents
Acknowledgments
I would like to express my deepest of gratitude for my advisor Dr. Soma Paul, without whom this
thesis would’nt have been possible. She always inspired me and had faith in my ability to rise to the
occasion and deliver the best work. She equally worked with me on the thesis as I did. She taught me
the course Computational Linguistics and since then I am working with her. I am also thankful to Prof.
Rajeev Sangal for his valuable comments on thesis. I started my journey in LTRC under the supervision
of Dr. V. Sriram on Machine Translation. Everytime I asked for his help he was there clearing my
doubts. Thanks for all the proof reading Sir and the inspiration you gave me that I ended up pursuing
Post-Graduation studies on Machine Translation.
The only unsinkable ship is FRIENDSHIP. I would also like to thank my Lab mates and my friends
Vipul Mittal, Sambhav Jain, Bharat Ram, Himani, Karthik, Siva Reddy, Avinesh, Ravikiran, Samar
Hussain for creating such a wonderful working environment in LTRC. I would also like to thank my
batchmates Abhijeet, Raman, Piyush, Himank, Shrikant, Aditya, Manish, Subhashis, Karan, Chirag,
Maruti, Prashant K., Vibhav for being the friends they were. It would be disrespectful of me if I didn’t
mention my 5th year buddies Mahaveer, Kulbir Chacha, Saurabh, Rahul, Abhishek.
Last year wasn’t fun if there were no playing cards and computer games. I would really like to mention
my CS buddies and my clan IM M ORT ALS.
Above all I would like to mention my cousins and my dear ones Krishna Mathur, Devika, Chandni
Mathur, Deepika Mathur for being there at the time I needed them and sometimes on the other side of
the outburst. Love you all.
vAbstract
The present work attempts to build an automatic translation system of nominal compound (NC) from
English to Hindi. A noun compound is a sequence of nouns acting as a single noun, e.g., colon cancer,
suppressor protein, colon cancer tumor suppressor protein. They comprise 3.9% and 2.6% of all tokens
in the Reuters corpus and the British National Corpus (BNC), respectively. As of today, no good system
exists for the translation of multi-word expressions from English to any Indian languages. We have
evaluated two state-of-the-art systems, Moses and Google Translation system, to check the Noun Com-
pound translation accuracy from English to Hindi. Google translation system results in an accuracy of
57% while Moses, a statistical machine translation system, returns an accuracy of 48% on a test data of
300 Noun Compounds. The above figures indicate that automatic NC translation from English to Hindi
is an important subtask of machine translation system. We build a Noun Compound Translation system
(NCT) which returns an accuracy of 64% on the same set of test data.
This thesis examines two approaches for translation of Noun Compounds from English to Hindi. We
have done a manual study on 50K parallel sentences from English to Hindi and have found out that Noun
Compounds in English are translated into Noun Compound in Hindi in over 40% of the cases. In other
cases they are translated into varied syntactic constructs. Among them the most frequent construction
type is “Modifier + Post-Position + Head” which occurs in 35% of all the cases. Some examples are
“cow milk” → “gAya kA dUXa”, “wax work” → “mOMa para ciwroM”. This observation motivates
both the approaches for translation in the present thesis. The approaches are called in this work as: a)
Translation of NC by paraphrasing on source side and mapping the paraphrase to target construct and
b) Context based translation by searching and ranking translation candidate on target side.
In the first approach English nominal compounds are automatically paraphrased and the paraphrases are
translated into Hindi constructions. The paraphrasing is done with prepositions following [Lauer 1995]
approach of paraphrasing of nominal compound. For example, “cow milk” is paraphrased as ‘milk from
cow’, “blood sugar” is paraphrased as ‘sugar in blood’. Since English prepositions have one-to-one
mapping to post-position in Hindi, English paraphrases are easily translated into Hindi using the map-
ping schema. Assuming that lexical substitution for component nouns of the compound is correct, this
method examines how paraphrasing of English nominal compound acts as an aid for translation.
In the second approach, we, at first, generate translation templates for the target language. These tem-
plates are all possible Hindi construction types that English nominal compounds can be translated into.
Context based translation system take context into consideration while translating. We translate noun
vivii compound by taking the sentence in which the compound occurs as the context. For example, the expres- sion “finance minister” is the nominal compound to be translated in the sentence “The finance minister declared the financial budget for this year”. Other content words in the sentence such as ‘declared’, ‘financial’, ‘budget’, ‘year’ form the context. We apply a Word-sense-disambiguation tool for selecting the correct sense of the component nouns of NC in the given context. We use a bilingual dictionary to get the Hindi translation of the component nouns in the sense selected by WSD tool. Thus context based lexical substitution is accomplished for the target language. The output of lexical substitution is placed in the translation templates and the resulted construction is searched on a Hindi indexed corpus of 28 million words. For ranking, a reference ranking based on the frequency of occurrence of the translate candidates in full in the TL corpora is taken as baseline. To improve on the baseline, a stronger ranking measure is borrowed from [Tanaka & Baldwin 2003b]. The context based translation system approach is adopted in the present work for building the noun compound translation system (NCT) which is integrated to Moses. The outputs of Moses and Moses integrated with NCT are compared. Evaluation of the system is carried out at two levels: by automatic evaluation metric BLEU and by manual evaluation technique. The issue of automatic evaluation is discussed in detail which motivates manual evaluation under the given circumstance.
Contents
Chapter Page
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Approaches to Machine Translation . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Problem Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Noun Compound in English and its Translation . . . . . . . . . . . . . . . . . . . . . 3
1.5 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.6 Various approaches for translation of Noun Compounds . . . . . . . . . . . . . . . . . 6
1.6.1 Translation of NC by paraphrasing on source side and mapping the paraphrase
to target construct . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.6.2 Context Based Machine Translation . . . . . . . . . . . . . . . . . . . . . . . 7
1.7 Developing an Integrated MT System and its Evaluation . . . . . . . . . . . . . . . . 8
1.8 Contribution of the Thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.9 Chapterization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Translation of Noun Compounds using paraphrasing on source side . . . . . . . . . . . . . . 11
2.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Related Works . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4 Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.5 Paraphrasing of Noun Compounds . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.6 Experiments & Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.7 Translation of Noun Compounds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.7.1 Mapping English Preposition to Hindi Post-position . . . . . . . . . . . . . . 20
2.8 Translation of Noun Compounds: Experiments and Result . . . . . . . . . . . . . . . 21
2.9 Conclusion and Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3 Context Based Translation of Noun Compounds . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.4 Preparation of Data and Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.4.1 Preparation of Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.4.2 Generation of Translation Templates . . . . . . . . . . . . . . . . . . . . . . . 31
3.4.3 Sense Selection for components of Noun Compound . . . . . . . . . . . . . . 32
3.4.4 Corpus Search and Ranking . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
viiiCONTENTS ix
3.5 Results and Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4 Integration of Noun Compound Translator with Moses and its Evaluation . . . . . . . . . . . 37
4.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.3 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.4 Data Preparation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.5 Moses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.6 Integration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.7 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.8 Conclusion and Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5 Conclusion and Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Appendix A: Templates for candidate generation . . . . . . . . . . . . . . . . . . . . . . . . 52
Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55List of Figures
Figure Page
1.1 Translation of Noun Compounds through Paraphrasing . . . . . . . . . . . . . . . . . 7
1.2 Noun Compound Translator (NCT) . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Moses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4.1 Phrase based Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.2 Distance based Reordering : Reordering distance is measured on the foreign input side.
In the illustration each foreign phrase is annotated with a dashed arrow indicating the
extent of reordering. For instance the 2nd English phrase translates the foreign word 6,
skipping over the words 4-5, a distance of +2. . . . . . . . . . . . . . . . . . . . . . . 42
4.3 Lexicalized Reordering (Y-Axis : Source Phrase, X-Axis : Target Phrase) . . . . . . . 42
xList of Tables
Table Page
2.1 Frequency of Paraphrases for “finance minister” resulted from Web search. . . . . . . 18
2.2 Frequency of Paraphrases for “welfare agencies” resulted from Web search. . . . . . . 18
2.3 Frequency of Paraphrases for antelope species after Web search. . . . . . . . . . . . . 19
2.4 Paraphrasing Accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5 Distribution of Preposition on Lauer test data of 218 NC . . . . . . . . . . . . . . . . 20
2.6 Comparison of our approach with Lauer’s Approach . . . . . . . . . . . . . . . . . . 20
2.7 Mapping of English Preposition to Hindi postposition from aligned English-Hindi par-
allel corpora. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.8 Preposition-Postposition Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.9 Translation Accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.10 Translation Accuracy for some individual prepositions . . . . . . . . . . . . . . . . . 22
3.1 Distribution of translations of English NC from English Hindi parallel corpora. . . . . 25
3.2 Number of Senses Listed in Wordnet . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.3 Synset selected by WSD tool . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.4 Translation using bilingual dictionary . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.5 Ranking using baseline frequency model . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.6 Ranking using CTQ Metric Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.7 Ranking after inclusion of default genitive translation i.e.. X kA Y, X ke Y, X kI Y as
templates. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.1 Corpus Statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2 NC translation accuracy(Surface Level) on the test data. . . . . . . . . . . . . . . . . . 45
4.3 BLEU scores on the test data. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.4 BLEU scores on the development set . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.5 5 point scale for Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.6 Human Judgment score of translation of sentences and the NC Translation accuracy . . 48
4.7 Performance of systems on top 3 constructions for NC Translation . . . . . . . . . . . 48
xiChapter 1
Introduction
1.1 Introduction
Machine Translation is a sub-field of Computational Linguistics that makes use of computers to
translate text/speech from one language to another. Efforts to build machine translation systems started
almost as soon as electronic computers came into existence. Computers were used in Britain to crack the
German Enigma code in World War II and decoding language codes is what we call machine translation
in today’s world. Warren Weaver, one of the pioneering minds in machine translation, wrote in 1947:
When I look at an article in Russian, I say: “This is really written in English, but it has
been coded in some strange symbols. I will now proceed to decode”.
Hindi is a widely spoken language and it is the principal official language of the Republic of India. On
the other hand, English is internationally popular language. In India, English as a language has played
a major role in administration, legal and education sector since British period. Presently, an awareness
has been developed in this country for using regional languages for government document writing, for
primary and higher education and every other domain of public life. In this context, it has become very
important to build system which can translate English to various Indian languages. With the existence
of huge text resources in internet and India being one of the most prominent users of web, even com-
mercial companies are finding it necessary to venture out for building machine translation.
With the emergence of India in the global market as one of the superior powers, and Hindi being its of-
ficial language, the language has reached to outside world too. English to Hindi translation has become
of great importance because the country has good trade relations with English spoken countries such
as USA, Australia, England and other European nations. English is an international industrial language
and companies from all around the world are investing in Indian market. English to Hindi translation has
become a necessity if the companies want to promote or pass information to those people who cannot
understand English. The coming of industries from abroad such as Quillpad, AIAIOO labs, MSR labs
has boosted the translation service industry in India, but as we know everyone wants the world to be
more automaticised and so the development of such tool is what one needs.
1Whenever there is a language barrier between two individuals every time an intervention by a bi-lingual
speaker is required which is a costly task. We are striving to make the world an automated state and
so are we. An automated machine translation system can reduce the human task to quite an extent.
A typical Machine Translation system can be used anywhere where there are two different individuals
trying to communicate but non of them knows a common language which creates a communication gap.
Some of the popular translation systems that are being developed are Google Translate, Yahoo! Babel
fish, Bing-Translator, Moses [Koehn et al. 2007]. In India two of the major projects on machine trans-
lation are Anusaaraka, English to Indian Language Machine Translation Project(EILMT). Anusaaraka
is an English to Indian language accessing (translation) software, which employs algorithms derived
from Panini’s Ashtadhyayi (Grammar rules). The EILMT system aims to design and deploy a Machine
Translation System from English to Indian Languages in Tourism and Healthcare Domains. The project
is funded by Department of Information Technology, MCIT, Government of India. Shakti is also a ma-
chine translation system from English to Indian languages. It is currently being developed at Language
Technology Research Centre.
These applications on translation from one language to another has become so popular and widely used
that people are developing Mobile Applications such as Speech-to-Speech translator, Speech-to-text,
Text-to-Text on different OS platforms like Android, iOs, Symbian.
1.2 Approaches to Machine Translation
Translation can be defined as a process in two steps :
1. Decoding the meaning of source text.
2. Re-Encoding the meaning in the target language.
There are 4 basic types of Machine Translation systems
1. Rule Based Machine Translation : Translation process that uses the linguistic information of
both source and target language such as morphological information, difference in syntactic be-
haviour.
(a) Transfer based Machine Translation : Translation process which builds intermediate repre-
sentation of source text that captures its ”meaning” in order to generate the correct transla-
tion. [Tsuji & Fujita 1991]
(b) Interlingual Machine Translation : source text is transformed into an interlingual, i.e. source-
/target-language-independent representation. The target language is then generated out of
the interlingua. [Lampert 2004]
(c) Dictionary based Machine Translation : Word by word translation using a bi-lingual dictio-
nary. [Muegge 2006]
22. Statistical Machine Translation : Statistical Machine Translation is a typical example of Ma-
chine Translation where we need statistical models which come from analyzing a parallel text
corpora to predict translation of a sentence from one language to another. [Brown et. al. 1993]
3. Example Based Machine Translation : In this translation is accomplished by decomposing a
sentence into certain phrases, then by translating these phrases, and finally by properly composing
these fragments into one long sentence. Phrasal translations are translated by analogy to previous
translations. [Brown 1996]
4. Hybrid Machine Translation : A combination of statistical, example-based and rule-based ap-
proach that leverages the best use out of each system.
1.3 Problem Statement
The thesis aims at automatic translation of English Noun Compound into Hindi within a sentence.
Here is an example:
English : The ‘coast guard’ was constituted by a ‘parliament act’ in the year 1978.
Hindi : 1978 meM bhArawa sarakAra ne ‘saMsada dvArA pArita adhiniyama’ ke aMtagarta ‘taTarak-
Saka dala’ kA gaThana kiyA .
The expression parliament act is translated to saMsada dvArA pArita adhiniyama while coast guard
translates to tatarakRaka dala. In the first case, the source language compound is translated as a phrasal
construction in Hindi; while in the second case, the noun compound remains as a noun compound in
Hindi.
We attempt to develop a system that automatically translate English nominal compound into Hindi. The
tool is named as Noun Compound Translation system (NCT). We also integrate the NCT tool with a
state-of-the-art translation system, Moses and evaluate the integrated System.
1.4 Noun Compound in English and its Translation
Compounds have regularly received attention of linguists. Noun compounds are abundant in English
and pose an important challenge for the automatic analysis of English written text. A two word noun
compound (henceforth NC) is a construct of two nouns, the rightmost noun being the head (H) and the
preceding noun the modifier (M). The noun constituents together act as a single noun [Downing 1977].
Some examples are ‘cow milk’, ‘road condition’, ‘machine translation’, ‘colon cancer’, ‘suppressor
protein’ and so on. A noun compound can have a more complex structure as illustrated in ‘customer
satisfaction indices’, ‘wrought iron office chair’ ‘routine health check up’, ‘fire and rescue service de-
partment’ and so on. The analysis of the aforementioned noun compounds can be done as follows:
31. ‘Customer satisfaction indices’: [[Customer satisfaction] indices]
2. ‘wrought iron office chair’: [[wrought iron] [office] chair]
3. ‘routine health check up’: [routine [health [check up]]]
4. ‘fire and rescue service department’: [[[[fire] and [rescue]] service] department]
The complex structure of noun compound establishes the fact that analysis and translation of these com-
pounds from one language to another is not an easy task. The translation becomes significantly difficult
in those cases when the source language NC is represented in a varied manner in the target language
as is the case with English - Hindi language pair. We have done a manual study on the BNC corpus in
which we have found that English noun compounds can be translated in Hindi in following varied ways:
1. Noun Compound
(a) Hindu Texts → hiMdU SAstroM
(b) Milk Production → dugdha utpAdana
2. Genetive Construction
(a) Rice Husks → cAval kI bhUsI
(b) Room Temperature → kamare kA tApamAna
3. Adjective Noun Construction
(a) Nature Care → prAkritika cikitsA
(b) Hill Camel → pahARI UMTa
4. Other Syntactic Phrase
(a) Wax Work → mom par citroM
(b) Body Pain → SarIr meM dard
5. One Word
4(a) Cow Dung → gobara
6. Others
• Hand Luggage → hATa meM le jAye jAne vala sAmAn.
When the compound is made up of more than two words, the translation issues also become more acute
sometimes. For example, let us study following cases of translation:
1. ‘body pain cure’ → ‘SarIra meM darda kA ilAja’,
2. ‘state forest department’ → ‘rAjya vana vibhAga’
3. ‘Hindi language alphabet’ → ‘hindI bhASa kI varNamAlA’.
In first case “E1 E2 E3 ” is translated into “H1 post-position H2 post-position H3 ”, in second case the
compound “E1 E2 E3 ” remains a compound “H1 H2 H3 ”; while in the third case “E1 E2 E3 ” is translated
as “H1 H2 post-position H3 ”. In the present work, we will be handling only bigram noun compound
for translating them into Hindi.
Furthermore, compounding is an extremely productive process in English. The frequency spectrum of
compound types follows a Zipfian or power-law distribution, so in effect many compound tokens en-
countered belong to a “long tail” of low-frequency types. Over half of the two-noun compound types
in the British National Corpus occur just once. Taken together, the factors of low frequency and high
productivity means that achieving a robust on noun-compound interpretation is an important goal for
broad-coverage in semantic processing.
1.5 Motivation
Noun Compounds constitutes an important part of English running texts. Translation of Noun Com-
pounds is a very widely researched topic. No work specific to noun compound translation from English
to Hindi has been attempted till now. We have given some sentences with NC for translation to the
EILMT system. The output that the system returns is the following:
English : ‘Keep the room temperature to 30 degrees, I am suffering from body pain .’
Hindi : ‘30 digrI ko kakSa tApamAna ko rakheM, meM SarIr dard se kaSta bhugawa rahA hUM’
In this example the translations of the Noun Compounds ‘room temperature’ and ‘body pain’ is not
correct. The performance of existing translation system makes the point clear that there exists no sat-
isfactorily efficient Noun Compound translation tool from English to Hindi although the need of one is
unprecedented in the context of machine translation. This observation motivates the present work to de-
velop English-Hindi noun compound translator tool. Similar algorithm will work for Indian languages
which are closely related to Hindi.
51.6 Various approaches for translation of Noun Compounds
There are various approaches for translation of Noun Compounds such as Transfer based machine
translation, Memory Based Machine Translation, Word-to-word compositional MT etc. The review
of translation of noun compound as discussed in the previous section motivates us to implement two
approaches both of which are corpus driven statistical approach. The two approaches can be described
as a) Translation by paraphrasing on source side and mapping the paraphrase to target construct and
b) Context based translation by searching and ranking translation candidate on target side. The two
approaches are introduced here and their implementation will be described in chapter 2 and 3.
1.6.1 Translation of NC by paraphrasing on source side and mapping the paraphrase to
target construct
We develop a system that uses paraphrase on source side as an aid to translate a Noun Compound
from English to Hindi. In this work we present a way of using paraphrasal interpretation of English
nominal compound for translating them into Hindi. Input Nominal compound is first paraphrased auto-
matically with the 8 prepositions as proposed by [Lauer 1995] for the task. The detail of the process is
described in Chapter 2. English prepositions have one-to-one mapping to post-positions in Hindi. We
obtain an accuracy of 71% over a set of gold data of 250 Nominal Compound. The translation-strategy
is motivated by the following observation: It is only 50% of the cases that English nominal compound
is translated into nominal compound in Hindi. In other cases, they are translated into varied syntac-
tic constructs. Among them the most frequent construction type is “Modifier + Postposition + Head”.
The translation module also attempts to determine when a compound is translated using paraphrase and
when it is translated into a Nominal compound.
The following flow chart describes the approach: In this method we assume the translation of compo-
nents nouns to be correct because our objective of conducting the experiment is to evaluate the accuracy
of translation of paraphrase construct. We implement another method for translation of Noun Com-
pounds which is described in chapter 3.
6Figure 1.1 Translation of Noun Compounds through Paraphrasing
1.6.2 Context Based Machine Translation
In Context Based Machine Translation we translate a Noun Compound taking the sentence as the
context. The translation is carried out in two steps:
1. Context information is utilized for correct lexical substitution of components nouns of English
NC.
2. Hindi templates for potential translation candidates are generated which are searched in the target
language data.
Let us consider the following example, Soil on the river bank eroded due to the flood. The expression
river bank is the noun compound and the content words make the context (in this case: soil, river, bank,
eroded, flood). We use a Word-sense-disambiguation tool [Patwardhan et. al. 2005] to derive the sense
of the component nouns used in the compound in the given context. We will see in Chapter 3 that cor-
rect sense selection of component nouns significantly improves the translation of the compound. Once
correct sense is selected for component nouns and the nouns are substituted in Hindi for that sense, the
substituent words are fit in translation template to generate the translation candidates. These transla-
tion candidates are searched in Web and the best translation candidate selected by ranking method (see
chapter 3) is taken to be the translation of the noun compound.
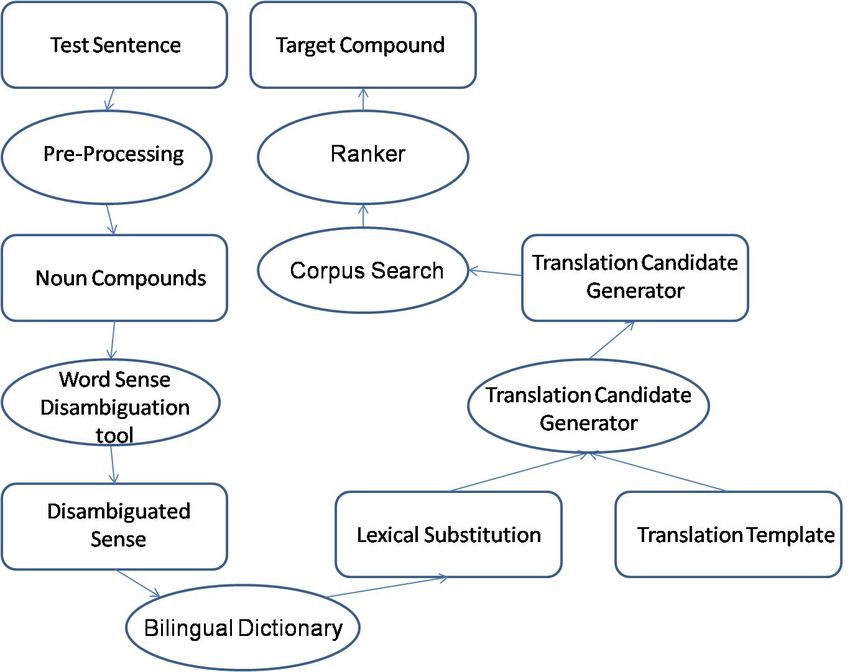
In this work we present an architecture of a “Context Based Machine Translation - Noun Compound
Translator” that has been able to give an accuracy of 57% accuracy over a test set of 200 Noun Com-
7pounds. Figure 1.2 represents functionality of Noun Compound Translator tool. We integrated the NCT
tool with state-of-the-art translation system, Moses as discussed in next section.
Figure 1.2 Noun Compound Translator (NCT)
1.7 Developing an Integrated MT System and its Evaluation
We present a translation system by combining the state-of-the-art machine translation tool, Moses
and Noun Compound Translator. The need to do this integration arises from our urge to know whether
the output of NCT brings in any improvement to the overall quality of sentence translation when the
system is plugged in to a full-fledged machine translation system. NCT is a phrase based system and
hence integrating it with another phrase based system ,which Moses is, makes the integration an easier
task than integrating it with a Syntax based SMT or any other SMT systems such as Example-based MT,
Tree based MT. Integrated system is built by combining Moses phrase based model and the translations
from NCT system. Moses decoder uses the enhanced model for translation of sentences.
The integrated system is also evaluated both manually and automatically. We will evaluate the systems
on test data of 300 parallel sentences containing Noun Compounds(NCs) and its translation.
Figure 1.3 represents the functionality of the Moses system combined with NCT tool.
8Figure 1.3 Moses
1.8 Contribution of the Thesis
1. Two approaches for translation of Noun Compounds are presented and compared with state of the
art system.
(a) Proposed a new approach for translation of Noun Compounds by paraphrasing on source
side.
(b) Developed a context based machine translation system (Noun Compound Translator) for
English-Hindi language pair.
2. The principle mechanism of two approaches are different
(a) Paraphrases of NCs are searched on English web corpus i.e. search source language corpus.
(b) Hindi translated candidates are searched on indexed hindi corpus i.e. search on target lan-
guage corpus.
3. NCT tool is built as a module that can easily be integrated with any working machine translation
system.
4. The system is integrated with state-of-the-art Statistical machine translation system, Moses and
evaluated.
95. Evaluation of the system is carried out at two levels: by automatic evaluation metric BLEU and
by manual evaluation technique.
1.9 Chapterization
This thesis is divided in a number of Chapters. Chapter 2 explains the approach of translating para-
phrase of English noun compound into Hindi. Chapter 3 describes Context based MT system that we
have integrated with a full-fledged MT system, Moses. The integration is described in chapter 4. The
evaluation report of translation after integration is also presented in this chapter. Finally the conclusion
chapter summarizes our work and discusses the future task.
10Chapter 2
Translation of Noun Compounds using paraphrasing on source side
2.1 Overview
This chapter argues that paraphrasing of source language noun compound can be used as an aid in
translation of English noun compounds in Hindi. We have discussed and implemented paraphrase by
preposition method for interpreting noun compound in this chapter. The result of the implementation is
also reported. For example, the meaning of nominal compound ‘carbon deposit’ and ‘wax work’ can be
conveyed as ‘deposit of carbon’ and ‘work on wax’.
In this method, we have automatically paraphrased English noun compounds with 8 prepositions as
proposed by [Lauer 1995]. We have used the paraphrase frequency found on the web as the base for
scoring that paraphrase. We have developed one-to-one mapping of English preposition to post-position
in Hindi. Finally we have translated the top 3 paraphrases into Hindi using a mapping schema and
bilingual dictionary. We have got an accuracy of 71% over a set of gold data of 250 Noun Compounds.
We have assumed that lexical substitution of constituent nouns of the compound is correct during eval-
uation because our objective of conducting the experiment is to evaluate the accuracy of translation of
paraphrase construct. The translation-strategy is motivated by the following observation: It is only 50%
of the cases that English noun compound is translated into noun compound in Hindi. In other cases,
they are translated into varied syntactic constructs. Among them the most frequent construction type is
“Modifier + Postposition + Head”. The translation module also attempts to determine when a compound
is translated using paraphrase and when it is translated into a Noun compound.
2.2 Introduction
Noun compounds are abundant in English and compounding is a highly productive phenomenon.
[Baldwin & Tanaka 2004] has calculated that noun compounds comprise 3.9% and 2.6% of all tokens
in the Reuters corpus and the British National Corpus (BNC), respectively. The frequency spectrum of
NCs follows a Zipfian or a power-law distribution, so in effect many compound tokens encountered in a
text belong to a “long tail” of low frequency types as described in [Seaghdha 2008]. It is difficult to list
11in a dictionary all compounds that are likely to be encountered. [Tanaka & Baldwin 2003b] has reported
that even for relatively frequent noun compounds that occur ten or more times in BNC, static English
dictionaries provide only 27% coverage.
Understanding the syntax and semantics of noun compounds is difficult but important for many natural
language applications including machine translation. Rackow [Rackow et al. 1992] has observed two
main issues in translating a noun compound from source language to target language (a) correctness in
the choice of the appropriate target lexeme during lexical substitution and (b) correctness in the selec-
tion of the right target construct type. The issue stated in (a) involves correct selection of sense of the
component words of NCs followed by substitution of source language word with that of target language
that best fits for the selected sense [Mathur & Paul 2009]. From the perspective of machine translation,
the issue of selecting the right construct of target language becomes very significant because English
NCs are translated into varied construct types in Hindi.
We have done a manual study on 50K parallel sentences from English to Hindi and have found out that
Noun Compounds in English are translated into Noun Compound in Hindi in over 40% of the cases.
In other cases they are translated into varied syntactic constructs. Among them the most frequent con-
struction type is “Modifier + Post-Position + Head” which occurs in 35% of all the cases (for illustration
see Chapter 1). The paraphrases can facilitate the translation in those cases. For example, let us take
the compound ‘wax work’ and ‘carbon deposit’. The paraphrase of these compounds is ‘work on wax’
and ‘deposit of carbon’. Since English preposition can mostly be mapped to Hindi postposition in one-
to-one manner, the paraphrases can efficiently be translated to correct Hindi constructions as follows:
‘work on wax’ → ‘mOm para citra’ (wax on work) and ‘deposit of carbon’ → ‘kOyle kA bhandAra’
(coal of deposit).
Currently there exist two different approaches in Computational Linguistics for interpretation of
Noun Compounds. They are:
1. Labeling the semantics of compound with a set of abstract relations [Girju et. al. 2003]
Eg. Chocolate Bar → bar made of chocolate (MAKE - relation)
2. Paraphrasing the compound in terms of syntactic constructs.
Paraphrasing, again, is done in three ways:
1. With prepositions (“war story” → “story about war”) [Lauer 1995].
2. With verb+preposition nexus (“war story” → “story pertaining to war”, “noise pollution” → “pol-
lution caused by noise”) [Finin 1980], [Nakov & Hearst 2005], [Nastase & Szpakowicz 2003].
3. With Copula (“tuna fish” → “fish that is tuna”) [Vanderwende 1995].
We have implemented the first approach for paraphrasing.
This chapter motivates the advantage of expanding English noun compounds into “paraphrases with
12prepositions” for translating them into Hindi. “Paraphrasing with Preposition” has the following ad-
vantages: (a) Annotation is simpler; (b) Learning is easier and (c) Data sparseness is less; (d) Most
importantly, English prepositions have one to one Hindi postposition correspondents most of the times.
Therefore we have chosen the strategy of “paraphrasing with prepositions” over “Paraphrasing with
Verbs+Preposition” approach for the task of translation. The chapter explores the possibility of main-
taining one to one correspondence of English-Hindi preposition-postpositions and examines the accu-
racy of translation. The English NCs are paraphrased using 8 prepositions as mentioned in [Lauer 1995].
The task of translating English NCs into Hindi syntactic constructs is divided in two levels
1. Paraphrasing by Preposition
(a) Paraphrase the NC using 8 prepositions.
(b) Paraphrasing candidates are searched in Web corpus.
(c) An algorithm is devised to determine when the paraphrase is to be ignored and the source
language NC to be translated as NC or transliterated in NC.
2. Translation
(a) English preposition is replaced by Hindi corresponding postposition.
(b) Bi-lingual dictionary is used to translate the Noun components.
We have manually created a data set of 250 Noun Compounds extracted from BNC corpus for the pur-
pose of evaluation of paraphrasing with preposition method & subsequent translation. The gold standard
data consists of paraphrases of each noun compound and their translation.
The chapter is divided into following sections. The next section presents a review of related works,
the attempts made for automatic paraphrasing of noun compound. Section 2.4 discusses the method of
preparing gold data for evaluation. Section 2.5 describes the implementation of paraphrasing approach.
The result of paraphrasing is presented in Section 2.6. The schema of mapping English preposition to
Hindi post-position is described in Section 2.7.1. This schema is used for translating English paraphrases
into Hindi constructions. Finally an evaluation result of translation is reported in section 2.7.
2.3 Related Works
This section surveys various methods of paraphrasing noun compounds as listed in previous section.
Paraphrasing English NCs is a widely studied issue and this section will predominantly study those
works. Scholars (such as [Levi 1978], [Finin 1980]) agree there is a limited number of relations that oc-
cur with high frequency among the constituents of noun compounds. However, the number and the level
of abstraction of these frequently used semantic categories are not agreed upon. They can vary from a
13few prepositional paraphrases [Lauer 1995] to hundreds and even thousands more specific semantic re-
lations [Finin 1980]. [Lauer 1995], uses eight prepositions for paraphrasing nominal compounds. They
are: of, for, with, in, on, at, about, and from. For example, the noun compound “bird sanctuary”, can be
interpreted both as “sanctuary of bird” and “sanctuary for bird”.
The automatic interpretation of noun compounds is a difficult task for both unsupervised and supervised
approaches. Currently, the best-performing NC interpretation methods in computational linguistics fo-
cus only on two-word noun compounds and rely either on rather ad-hoc, domain-specific, hand-coded
semantic taxonomies, or on statistical models on large collections of unlabeled data.
The majority of corpus based statistical approaches to noun compound interpretation collects statis-
tics on the occurrence frequency of the noun constituents and uses them in a probabilistic model
([Resnik 1993]; [Lapata & Keller 2004]).
[Lauer 1995] is the first scholar to devise and test an unsupervised probabilistic model for noun com-
pound interpretation on Grolier encyclopedia, an 8 million word corpus, based on a set of 8 prepositional
paraphrases. His probabilistic model computes the probability of a preposition p given a noun-noun pair
n1-n2 and finds the most likely prepositional paraphrase
p∗ = argmaxP (p|n1, n2) (2.1)
The ultimate goal of [Lauer 1995] work is to perform semantic analysis of arbitrary noun com-
pounds, although the experiments were done on two word noun compounds that can have prepositional
paraphrase. A probabilistic model for noun compound paraphrasing is developed based on meaning dis-
tributions theory. The model combines information from both head and modifier in order to determine
the semantic relation between them. Compounds can be paraphrased with three possible groups :
1. Copula : fish that is a tuna
2. Verbal-nexus compounds or nominalization : construction of buildings
3. Prepositional Compounds : bars of steel, stories about war
Lauer has experimented with Prepositional Compounds only. He has used Warren’s(1978) study to
construct the list of possible prepositions. The study yielded 7 prepositions ‘of’, ‘for’, ‘in’, ‘at’, ‘on’,
‘from’, ‘with’, but Lauer has included one more preposition about because these preposition constitutes
about 3.6% of total cases. Thus, there were 8 prepositions that Lauer has used in this experiment for
paraphrasing.
Lauer has addressed the following issue in his work: “Given a Noun Compound which preposition
among the list of 8 prepositions is most likely to occur as a paraphrase of the compound.” To build a
statistical learner for this problem he has given a probabilistic model that compute the probability of 8
14prepositions and gives the most likely one. The function is defined as
(∀n1 , n2 ∈ N )(A(n1 , n2 ) = argmaxp∈P P r(p|n1 , n2 )) (2.2)
With assumptions such as:
1. Probability of modifier is independent of the head.
2. Each role/preposition is equally likely.
We get the following equation.
X
(∀n1 , n2 ∈ N )(A(n1 , n2 ) = argmaxp∈P P r(c1 |p)P r(c2 |p))) (2.3)
c1 ∈φ1 (n1 );c2 ∈φ1 (n2 )
where φ is the syntactic mapping from concepts (c1 , c2 ∈C)toN ouns(n1 , n2 ). The steps to build the
paraphrasing technique are the following:
1. Build a gold data set of two word noun compounds with their correct paraphrase.
2. Define a pair of patterns for extracting examples of the nouns modified by, and the nouns governed
by, eight prepositions.
3. Estimate P r(c1 |p) and P r(c2 |p) for each preposition.
4. Use the distribution to estimate the best preposition for paraphrasing.
This method has resulted in an accuracy of 40% on the test set of 400 Noun Compounds developed by
Lauer. We have used the same 8 prepositions for paraphrasing on our test data of Noun Compounds.
[Lapata & Keller 2004] has demonstrated that web counts can be used to approximate bigram frequen-
cies. They have applied this method in Interpretation of Compounds Nouns. For majority of tasks,
they have found that n-gram frequencies obtained from web are better than that of obtained from large
corpus. Keller and Lapata has shown in their previous work (’03) that the web frequencies
1. correlate with the frequencies obtained from edited BNC corpus(100M words).
2. correlate with the frequencies recreated using smoothing methods.
They have used the model proposed by Lauer
X
p∗ = argmaxp P r(t1 |p)P r(t2 |p) (2.4)
t1 ∈cats(n1 );t2 ∈cats(n2 )
where t1 and t2 represents concepts. This model is tested by Lauer on both concept level and Lexical
level, however, in this chapter they worked on lexical version. Unlike using normal queries, they have
preferred using augmented queries and thus generated three types of queries :
151. Literal Queries : use the quoted n-gram directly
2. Near Queries : Use of a NEAR b type queries to expand the n-gram where NEAR stands for a
window of 10 words.
3. Inflected Queries : that uses all morphological forms in an expanded query. e.g. “history change”
can be expanded as “histories change”, “history changed” ....
Lapata and Keller has shown that usage of Web as a target corpus and of inflected queries can certainly
improve the performance of the system. Their system return an accuracy of 55.71% when search for
the queries is done on Altavista search engine. Since this method has shown a great improvement in
paraphrasing accuracy and has established a correlation between web counts and BNC corpus, we have
borrowed [Lapata & Keller 2004] method for paraphrasing with some additional features.
[Nakov & Hearst 2005] has shown that a hidden noun-noun semantic relation can be expressed explic-
itly with the help of Web search engine queries. Queries are those construction that expresses a Noun
Compound as a relative clause containing wild card characters to be filled with a verb. For example,
a compound like tear gas can be interpreted as gas that causes tears, gas that brings tears or gas that
produces tears. For extracting verbs from these type of paraphrases they have devised the following
queries and have used Google to extract the snippets:
gas THAT * tear where, THAT stands for ‘that’, ‘which’, ‘who’.
The query can be generalized into: n2 that * n1 where n1 n2 are the noun components and ‘*’ stands for
one to eight words. Issuing this query they have retrieved first 1000 snippets and have considered only
those snippets for which the sequence of words following n1 is non-empty and contains at least one
non-noun. Then they have shallow parsed the snippets to extract the verbs and the following preposi-
tion. They have also ensured that there is only one verb phrase between verb and n1 to disallow complex
clauses.
Another work that subsequently overlaps with paraphrasing is that of [Kim & Baldwin 2006]. They
have worked on interpretation of Noun Compound via Verb Semantics. They have developed an auto-
matic method for interpreting NC based on semantic relations. A set of seed verbs is used to represent a
single semantic relation; for example NC within the sentence The bald headed guy owns the Mercedes
is taken as an evidence of POSSESSOR relation. Their work can be divided in number of steps: First, 3
huge corpora (BNC, WSJ and Brown) are taken. Sentences are parsed using RASP parser. Second, sen-
tences are filtered by selecting only those one which have “H”(Head) and “M”(Modifier). Third, verbs
are extracted from the sentence and are mapped to the seed words using Wordnet::Similarity Measure
and thus generate the templates like
S(have, own, possessV , M SU BJ , H OBJ ) (2.5)
where V is the set of seed words. Fourth, a set of semantic relations is retrieved from which they select
the best-fitting relation using TiMbl Classifier.
16There exists no work which has attempted to translate nominal compound by paraphrasing them first
and translating the paraphrases in target language next. In this regard, the approach proposed is first of
its kind to be attempted. We will describe our method of paraphrasing in Section 2.5.
2.4 Data
We have created two data sets for evaluating our algorithm. One set contains 218 nominal compounds
which originally occurs in Lauers test set of 400 noun compounds [Lauer 1995]. We have taken this data
to compare our system with that of Lauers using his data set. To evaluate the quality of paraphrasing
& translation of NC together we have created our own dataset since no reference data is available for
such task. The second test set consists of 250 bigram noun compounds which are extracted from BNC
corpus [Lou Burnard 2000]. This data is manually paraphrased on source side and translated into Hindi
for evaluating both paraphrasing and translation techniques. BNC has varied amount of text ranging
from news- paper article to letters, books etc.
2.5 Paraphrasing of Noun Compounds
This section describes the procedure of paraphrasing by preposition that we have adopted. The
system is comprised of the following stages:
1. Generating prepositional paraphrasing candidates for English NC using brute force.
2. Giving paraphrase as a query in Web search
3. Filtering the result using the heuristics
4. Selection of the best paraphrase.
Each noun compound is paraphrased with all eight prepositions under consideration. Our examination
of parallel corpora (for details see Chapter 3) has revealed the fact that English NC remains a NC in
Hindi for 40% times. This observation motivates us to design an algorithm that will determine whether
an English NC is to be translated as an analytic construct or retained as an NC in Hindi. We have
used Yahoo! search engine for querying “Head Preposition Modifier” in the web for a given input NC
(“Modifier Head”) to get the frequency of the paraphrase. For example, paraphrases for the NC “finance
minister” and their frequency are given in Table 2.1:
In the above table we notice that the distribution is widely varied. For some paraphrase the count
is very low (for example ‘minister about finance’ has count 2) while the highest count is 5420000 for
‘minister of finance’. The wide distribution is apparent even when the range is not that high as illustrated
in Table 2.2 :
17Paraphrase Web Frequency
minister about finance 2
minister from finance 16
minister on finance 34300
minister for finance 1370000
minister with finance 43
minister by finance 20
minister to finance 508
minister in finance 335
minister at finance 64
minister of finance 5420000
Table 2.1 Frequency of Paraphrases for “finance minister” resulted from Web search.
Paraphrase Web Frequency
agencies about welfare 1
agencies from welfare 16
agencies on welfare 64
agencies for welfare 707
agencies with welfare 34
agencies in welfare 299
agencies at welfare 0
agencies of welfare 92
Table 2.2 Frequency of Paraphrases for “welfare agencies” resulted from Web search.
During our experiment we have come across three typical cases: (a) No paraphrase is available when
searched; (b) Frequency counts of some paraphrases for a given NC is very low and (c) Frequency of
a number of paraphrases cross a threshold limit. The threshold is set to be mean of all the frequencies
of paraphrases. Each of such cases signifies something about the data and we build our translation
heuristics based on these observations. When no paraphrase is found in web corpus for a given NC, we
consider such NCs very close-knit constructions and translate them as noun compound in Hindi. This
generally happens when the NC is a proper noun or a technical term. Similarly when there exists a
number of paraphrases each of those crossing the threshold limit, it indicates that the noun components
of such NCs can occur in various contexts and we select the first 3 paraphrase as probable paraphrase
of NCs for such cases. For example, the threshold value for the NC finance minister is: Threshold =
6825288/8 = 853161. The two paraphrases considered as probable paraphrase of this NC are therefore
“minister of finance” and “minister for finance”. The remaining paraphrases are ignored. When count
of a paraphrase is less than the threshold, they are removed from the data. We presume that such low
frequency does not convey any significance of paraphrase. On the contrary, they add to the noise for
18probability distribution. For example, all paraphrases of “antelope species” except “species of antelope”
is very low as shown in Table 2.3. They are not therefore considered as probable paraphrases.
Paraphrase Web Frequency
species about antelope 0
species from antelope 44
species on antelope 98
species for antelope 8
species with antelope 10
species in antelope 9
species at antelope 8
species of antelope 60600
Table 2.3 Frequency of Paraphrases for antelope species after Web search.
2.6 Experiments & Results
For a given NC we have used a brute force method to find the paraphrase structure. We have used
Lauer’s prepositions (of, in, about, for, with, at, on, from, to, by) for prepositional paraphrasing. Web
search is done on all paraphrases and frequency counts are retrieved. Mean frequency (F) is calculated
using all frequencies retrieved. All those paraphrases that give frequency more than F are selected. We
have first tested the algorithm on 250 test data of our selection. The result of the top three paraphrases
are given below :
Selection Technique Precision
Top 1 61.6%
Top 2 67.20%
Top 3 71.6%
Table 2.4 Paraphrasing Accuracy
We have also tested the algorithm on Lauer’s test data (first 218 compounds out 400 of NCs) and have
obtained the following results (see Table 2.5 ). Each of the test data is paraphrased with a preposition
which best explain the relationship between the two noun components. Lauer gives X for compounds
which cannot be paraphrased by using prepositions For eg. tuna fish.
OLauer : Number of occurrence of each preposition in Lauer test data
OCI : Number of correctly identified preposition by our method
In Table 2.6 we compare our result with that of Lauer’s on his data. We have given the results
maintaining the following criteria:
19Prep OLauer OCI Percentage
Of 54 37 68.50%
For 42 20 47.62%
In 24 9 37.50%
On 6 2 33.33%
Table 2.5 Distribution of Preposition on Lauer test data of 218 NC
1. only “N prep N” is considered.
2. Non-Prepositions (X) are also considered which are referred to as ‘All’ in the Table 2.6.
Case Our Method Lauer’s
N-prep-N 43.67% 39.87%
All 42.2% 28.8%
Table 2.6 Comparison of our approach with Lauer’s Approach
2.7 Translation of Noun Compounds
For translation of Noun Compounds we first paraphrase the compounds with preposition as described
in Section 2.5. The paraphrases are then translated into Hindi.
In many cases English prepositions can be semantically overloaded. For example, the NC “Hindu
law” can be paraphrased as “law of Hindu”. This paraphrase can mean “Law made by Hindu” (not
for Hindu people alone though) or “Law meant for Hindu” (law can be made by anyone, not by the
Hindus necessarily). Such resolution of meaning is not possible from “preposition paraphrase”. The
chapter argues that this is not an issue from the point of view of translation at least. It is because
the Hindi correspondent of ‘of’, which is ‘kA’, is equally ambiguous. The translation of “Hindu law”
is “hinduoM kA kAnUn” and the construction can have both aforementioned interpretations. Human
users can select the right interpretation in the given context. The next subsection describes the mapping
of English preposition to Hindi post-position in details.
2.7.1 Mapping English Preposition to Hindi Post-position
The strategy of mapping English preposition to Hindi post-position is a crucial one for the present
task of translation. The decision is mainly motivated by a preliminary study of aligned parallel corpora
of English and Hindi in which we have observed the following distribution of translation probabilities
of Lauer’s 8 prepositions as shown in Table 2.7.
20Prep Post-Pos Sense Prob.
kA Possession 0.13
ke Possession 0.574
of
kI Possession 0.29
se Possession 0.002
from se Source .999
meM Location 0.748
at
par Location .219
se Instrument 0.628
with
ke sAtha Association 0.26
par Loc./Theme 0.987
on
ko Theme 0.007
about ke bAre meM Subj.Matter 0.68
in meM Location .999
ke lie Beneficiary 0.72
for
ke Possession 0.27
Table 2.7 Mapping of English Preposition to Hindi postposition from aligned English-Hindi parallel
corpora.
Table 2.7 shows that English prepositions are mostly translated into one Hindi postposition except
for a few cases such as “at”, “with” and “for”. The probability of “on” getting translating into “ko” and
“of” into “se” is very less and therefore we are ignoring them in our mapping schema. The preposition
“at” can be translated into “meM” and “para” and both postpositions in Hindi can refer to “location”.
However, the two prepositions “with” and “for” can be translated into two distinct relations as shown in
Table 2.7. From our parallel corpus data, we therefore find that these prepositions are semantically over-
loaded from Hindi language perspective. The right sense and thereafter the right Hindi correspondent
can be selected in the context. In the present task, we are selecting the mapping with higher probability.
English Prepositions are mapped to one Hindi Post-position for all cases except for “at” and “about”.
The final correspondence as used in the present work is given in Table 2.8.
Hindi post-positions can be multi-word as in “ke bAre meM”, “ke liye” and so on as shown in Table
2.8. For the present study, lexical substitution of head noun and modifier noun are presumed to be cor-
rect.
2.8 Translation of Noun Compounds: Experiments and Result
In this section we check for the accuracy of translation of English paraphrases of NCs into Hindi.
For this task we have used the gold standard paraphrase data of 250 noun compounds which we have
manually created. The same set of noun compound is given to Google translator for translation. We
21You can also read

















































