AUTOMATICALLY DETECTING AND ALERTING E-COMMERCE WEB SITE FAKE REVIEWS THROUGH SENTIMENT ANALYSIS
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Journal of Xi'an University of Architecture & Technology ISSN No : 1006-7930
AUTOMATICALLY DETECTING AND
ALERTING E-COMMERCE WEB SITE
FAKE REVIEWS THROUGH SENTIMENT
ANALYSIS
Paul Jasmine Rani. L1 , Meenakshiammal.R2, Sindhu.S3 Rishii K P4 , Shakthi Saravanaa R.B5 , 1Associate
Professor, Department of Computer Science and Engineering, Rajalakshmi Institute of Technology Chennai ,
2
Associate Professor, Rohini College of Enginering and Technology, 3Assistant Professor, SRN Institute of Science
and Technlogy, 4,5ug scholar, Department of computer Science and Engineering, Rajalakshmi Institute of
Technology pauljasminrani.l@ritchennai.edu.in,saimeenumani@gmail.com,sindhus2@srmist.edu.in,
rishiikpr@gmail.com, bossman22042001@gmail.com.
Abstract— This is an era where the popularity and the The sentiment is formulated usually as a two-class
market for any product is defined by its corresponding reviews. classification problem, positive and negative. Reading,
The demand of the product and thereby it’s stock value reviewing and guessing the polarity of the product or service
increases , whereas the demand towards the product and its is a tiresome process and also consumes a lot of time,
stock value decreases when the reviews are mostly positive and therefore automated techniques are used for sentiment
negative respectively. Therefore the sellers are sometimes
analysis. There are three major classifications in sentiment
benefitted , but always the loss is for the customers (online
purchasers). It is necessary to provide a detailed and true analysis, namely: document level, sentence level, and aspect
review for the product from the verified buyer , so that the level. It is important to distinguish between these three which
others can choose on their own without any bias . But the review will determine different tasks of sentiment analysis. The
systems are often targeted by opinion spamming. This paper document level takes a document as an opinion on its aspect,
classifies reviews and determines whether they are real or fake and it aims to classify an opinion document as a negative or
in the first place itself . If the reviews are positive and actual, positive opinion. The sentence level using SA is used to set
then there is no problem. But if the reviews are fake, it may up an opinion stated in every sentence. The aspect level is
destroy the market of the product. A study conducted on fake based on the idea that an opinion consists of a sentiment
reviews states that there are almost 50 thousand fake reviews in (positive or negative), and its sentiment analysis aims to
72 million reviews. In this paper , sentiment analysis is used in categorize the sentiment based on specific aspects of entities.
identification of these fake reviews , and by applying sentiment
analysis coupled with SVM algorithm we can also remove these
Some challenges are faced by fake review detection, when
biased and fake reviews at once . To determine the fake reviews, opinion spammers use different account names alongside
Support Vector Machine algorithm is trained over a predefined different IP’s , it becomes almost impossible to tag them as
dataset of reviews to extract features for classification. The fake. The dataset we use is from any ecommerce website such
source of the data is from any ecommerce website . The IP as amazon, flipkart etc.. After we collect these datasets, SA
address of the device that reviews the product is also identified, technique is applied on them to classify the documents as
and if the system recognizes multiple reviews from the same IP original positive and original negative reviews or fake
address, then it marks them as fake. positive and fake negative reviews. It is to be noted that not
only reviews that are negative are marked as fake, but also
Keywords— review analysis, sentiment analysis, fake reviews reviews that are positive and being spammed more than one
,support vector machine.
time is also considered a fake one. Spammers use this method
I. INTRODUCTION of opinion spamming to either discredit a product or service,
though the product is worthy, in order to decrease the
Opinions and reviews are increasingly used by company’s worth, or to increase the sales of the product and
individuals and organizations to make purchase decisions, provide the company or seller with fame and popularity,
marketing, product design, etc. . There are N number of thereby increasing their stock and demand value. Detecting
products that are being displayed in these sites whose market such fake reviews is a challenge, for example, fake consumer
is decided by the corresponding reviews. Positive reviews reviews are not only affecting individual consumers but also
provide the businessman and sellers with fame and profit corrupt purchaser’s confidence in online shopping. Machine
which increases their market value. This gives imposters to learning along with sentiment analysis provides a good
post fake reviews to discredit their product or service they chance in the detection of fake reviews in movie review,
provide. They are called fake reviewers or opinion spammers. ecommerce, and other domains. We wish to classify the
Due to fake reviews the users will make wrong decisions and reviews from the dataset taken from ecommerce website and
the product sale will decrease, this will result in a loss for the movie reviews as real ones or fake using sentiment analysis
owners. This paper gives the solution to this problem by algorithms along with supervised learning techniques.
applying sentiment analysis to detect and eliminate fake
reviews.
Volume XII, Issue IV, 2020 Page No: 5507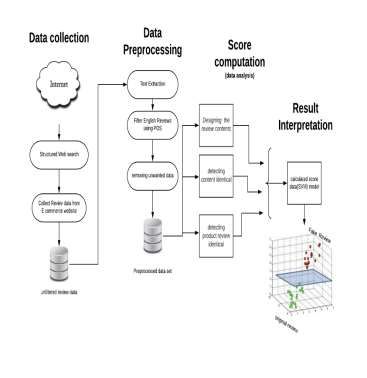
Journal of Xi'an University of Architecture & Technology ISSN No : 1006-7930
II. RELATED WORK show that the automatically extracted topics match
A. [1] analyze the market of fake review suppliers and the manually extracted ones, while also significantly
their fake reviewing methods and found that decreasing the manual effort.
developers purchase reviews to comparatively I. [6] implemented support-vector network for the
costly costs of a couple of bucks or alter reviews in restricted case where the training data can be
exchange portals. Recently, several techniques and separated without errors. It extends the result to non-
approaches are brought up within the field of fake separable training data.
review detection.
III. BACKGROUND AND SURVEY
B. [2]process and reviewing a brand new mobile
Fake reviews tend to own a lot of red flags that
application. it's used for testing purpose , beta
facilitate AI technology to spot them. , the language
testing, metadata correction , hardware employed in a fake review usually includes formal product
compatibility and software system necessities. It names, model numbers and selling jargon. Also, reviewer
determines the live element and app support. profiles sometimes fail to replicate a standard pattern of
C. [4] presents emotion Text, a toolkit for human’s product or service reviews. and plenty of times, fake reviews
feeling recognition from text. It provides empirical are published too oftentimes in a very short span of your time.
proof of the performance of EmoTxt. To the best of By assessing these aspects, AI technology will establish false
reviews from legitimate ones. With the employment of
our knowledge and data, emotion Text is the 1st
machine learning and AI algorithms, the capability to find
ASCII text file toolkit supporting each feeling of fake reviews can increase. which will facilitate to improve the
human's mind recognition from text and coaching of legitimacy of product and repair reviews so better client
custom emotion classification models. choices will be made. It’s no secret that AI technology offers
D. [5] analyze the adapting data retrieval techniques businesses a bonus in terms of client review analyses.
together with modeling and evaluating them on However, the employment of AI technology is additional
completely different level in the eyes of public unremarkably accustomed examine client complaints,
preferences and requests. Machine learning is employed to
market knowledge. Results show that the capture client information from reviews to make client
mechanically extracted topics match the manually profiles.
extracted ones, but also tend to decrease the manual
effort. The process is reviewed in a brand new mobile app
to see its political campaign as a live element of the app store.
E. [6] enforced support-vector network for the
It includes ratings, exploitation of same emblem, repeating
restricted case wherever the coaching information comments by completely different usernames. the corporate
will be separated without any errors. It extends the may receive both positive and negative review. Positive
result to non-separable training data.[1] analyze the incase to extend sales, supply and development, and in
market of fake review providers and their fake negative may be reporting and protesting . The fake review
reviewing strategies and found that developers buy market is divided into 3 sections.
reviews to relatively expensive prices of a few PROVIDERS : company, salesman, etc
dollars or deal with reviews in exchange portals.
Recently, many techniques and approaches have OFFERS : conditions, consumers, etc
been proposed in the field of fake review detection. POLICIES : detection of fake review
F. [2]process and reviewing a new mobile application.
It is used for testing purpose , beta testing, accurate The characteristics of fake review includes the
application ,category ,detection rate, frequencies.
metadata , hardware compatibility and software
requirements. It determines the live component and
app support.
G. [4] presents Emotion Text, a toolkit for emotion
recognition from text, trained and tested on a gold
standard of about 9K question, answers, and
comments from online interactions. It provides
empirical evidence of the performance of EmoTxt.
To the best of our knowledge, Emotion Text is the
first open-source toolkit supporting both emotion
recognition from text and training of custom
emotion classification models.
H. [5] analyze the adapting information retrieval
techniques including modeling and evaluating them
on different publicly available data sets. Results
Volume XII, Issue IV, 2020 Page No: 5508
Journal of Xi'an University of Architecture & Technology ISSN No : 1006-7930
classification scheme, but instead they create confusion to our
classifier. In this study, we used a 820 English waste words
list. Waste words removal helps to decrease the memory
needs while Classifying the reviews.
Algorithm for preprocessing(POS method)
1# : take away all blank rows if any.
2# : Modify all the word to lower_case letter. This is needed
in python interprets 'review' and 'REVIEW' differently
dataset1['text']=[ent.low() for entry in dataset1['text']]
3# : Tokenization :
In this each and every entry in the dataset1 will be spilt into
set of words
dataset1['text']= [word_token(entry) for entry in
dataset1['text']]
4# : Remove waste words, Non-Numeric and perform Word
(Analyzer requires Pos tagger to know if the word is noun
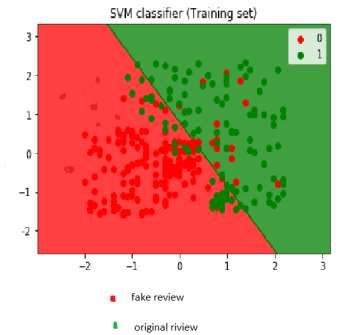
Figure 1:data representation about website reviews or verb or adjective etc. By default the data set is set to be
Noun)
IV. DESIGN AND METHODOLOGY map_tag= defaultdict(lambda : wn.NOUN)
A. Data collection tag_map['J'] = wn.ADJ
tag_map['V'] = wn.VERB
Data is collected from the website to find out the
tag_map['R'] = wn.ADV
fake review and data set which is used in this paper is a set of
product reviews as well as the related data collected from for index,entry in list(dataset1['text']):
amazon.com. From October to December 2019, some sample # Stating Empty List to retain the words that follow
has been collected, in total, over 6.2 millions of product the protocol for this step
reviews in which the products belong to six main categories Final_words = zero
are identified i.e.. Cooking related items, musical
if word not in stopwords.words('english') and
instruments, beauty, book, electronic, furniture and fashion
These online reviews were posted by over 2.2 millions of word.isalpha():
reviewers towards 10,175 products. Each review includes the word_Final = word_Lemmatiz.leme(word,tag_map[tag[0]])
following information: reviewer unique ID, product ID,
rating ,review time , helpfulness, review text, Posted # Initializing WordNetLemmr()
sequence
word_Lemmatiz = WordNetLemmatizer()
( pos_tagger procedure will provide the 'tag' i.e if
B. Sentiment text extraction and data preprocessing the word is Noun(N) or Verb(V) or something else.)
for word, tagger in pos_tagger(entry):
Each and every word of a sentence has its peculiar # Below situation is to check for Stop words and
role that defines how the word is used. This roles are also consider only letters and not numbers
known as the parts of speech. There are eight parts of speech
in English: verb , noun, the pronoun, the adjective, the words.append(word_Final)
adverb, the preposition, the conjunction, and the interjection.
(POS) taggers have been developed in natural language # The final treated set of words for each repetition
processing, to classify words based on their parts of speech. will be collected in 'text_final'
This will be the first step of the preprocessing stage . For dataset1.loc[index,'text_final'] = str(Final_words)
sentiment analysis, to extract the text a POS tagger is very
useful because of the following two reasons: 1) Words like C. Fake review detection computation
nouns and pronouns usually do not contain any opinion. It is
able to filter out such words with the help of a POS tagger; 2)
A POS tagger can be used to differentiate words that can be ● Designing the review contents
used in different parts of speech. After differentiating words Designing the review contents Let Rw = {rw[l], rw[2], ...,
data preprocessing has to be done using waste word list ie., rw[n]} be a review sequence, and number in index indicates
Some of the words are usually used (e.g., "a," "the," "of," "I," the posted order of review(time in which posted), the review
"you," "it," "and") but do not give any significant data to our rw[i] contains multiple information: review unique ID
Volume XII, Issue IV, 2020 Page No: 5509Journal of Xi'an University of Architecture & Technology ISSN No : 1006-7930
rw[i].uid, posted time rw[i].time, review content Random, Score[i] = T
rw[i].content and product ID rw[i].prd.
● detecting content identical (P1) If the score value is less than threshold value then
If the reviewer rw[i].uid posts his/her own assessments
constantly, rw[i].content would have a comparative high E.Support vector machine
similarity with his/her reviews. We keep a review centroid for
each reviewer, which consists of the terms' average incidence In this paper we have a tendency to used Support vector
rates in the reviews posted by rw[i].uid. The database of machine (SVM) to classify the review input training data is
centroid should be updated whenever the frequency is taken from the score and also the trained data set is taken .
increased Thus, we can evaluate the content identical of the SVM could be a methodology for the classification of each
detected review as follows: linear and nonlinear information. If the dataset is linearly
Su = identical(rw[i].content, Cr[i].u) severable, the SVM searches for the linear best separating
hyperplane (the linear kernel), that could be a call boundary
that separates information of 1 category from another. once
● detecting product review identical (p2) the information set is as input it's processed in SVM model
and that they give the output as original review severally and
A fake review might be the duplicate or nearby-duplicate faux review severally .Mathematically, a separating
of an current one on the same product. If the product is more hyperplane is written as:
similar and If so, it would be directly associated with that
product. If there are multiple reviews between the fake review W·X+b=0,
and the normal ones copied, viewers always cannot detect the wherever W could be a weight vector and W=w
fake review because most of the viewer wish is to read the one,w2,...,wn. X could be a training tuple. b could be a scalar.
reviews in the first few pages .So first few page review are so as to optimize the hyperplane, the matter primarily
very important Compared with the normal reviews, fake transforms to the diminution of diminution, that is eventually
reviews would have higher similarity with the "review computed as:
centroid" of the product. Finally to calculate the identity of
the similar product Sp.
Sp = identical(rw[i].c, Cr[i].p)
● The review frequency of a product (p3)
Various fake reviews happening in a short time interval
would make more effect. If a product is very frequently in a
small time window, it might be attacked. To get positive
review or negative review time factor plays a major role.
Suppose if it gets with in short time, this could be caused by
other reasons like promotions. we also consider it as an index
of fake reviewers actions.
D. Final score calculation
Score= (al*Su + a2* Sp + a3*fq) /
where attributes a1,a2,a3….an are the weight parameters
turning the contributions of frequency F1, F2, ... , F6
separately. Since the fake review score is standardized
between o and i. we can determine whether a review is a spam
with a predetermined threshold T:
Normal , Score[i] < T
Figure .3. Proposed System Architecture
Spam ,Score[i] > T
Volume XII, Issue IV, 2020 Page No: 5510Journal of Xi'an University of Architecture & Technology ISSN No : 1006-7930
V. RESULTS AND DISCUSSION
In this section, we provide experimental results of
completely different supervised machine learning
approaches to distinguish sentiment of our datasets
which is compared with product review dataset V1 and
product Review dataset V2 Also, we have used similar
methodologies at the same time to detect fake reviews.
Our experimental approaches tend to study the accuracy
of all sentiment classification algorithms, and how to
determine which algorithm is more accurate.
Furthermore, we were able to find out fake positive
reviews and fake negative reviews through the proposed
model.
Figure 5. Output of SVM model
Table-I The result of our Experiment.
Experiment Fake Fake SVM Threshold VI. CONCLUSION
Positive Negative
review review
In this paper, we have taken the problem of
identifying fake reviews which is from the review
Dataset-V1 20.5 22.2 83.5 81.4 sequences using sentiment analysis. Online
Dataset-V2 26.8 26.3 75.4 79 product reviews from Amazon.com are selected as
our primary dataset. To examine and evaluate the
proposed model , we have made an attempt to
create a dataset from a real-life review data set.
More number of experiments have been
conducted to analyze the effectiveness of the
proposed model. From the proposed model we
Trained data set result were able to easily find out the fake reviews and
mark it as fake.
100
50
VII. REFERENCES
0
Fake Positive Fake SVM Threshold [1]. 9to5Mac (2017) Bell faces $1.25M fine for
review Negative posting fake reviews of its app in the App Store.
review https://9to5mac.com/2015/10/14/bell-fake-app-
Dataset-V1 Dataset-V2 store-reviews/
Figure 4: graph of the experiment [2].Apple (2017) App Store Review Guidelines.
https://developer.apple.com/app-
store/review/guidelines/
[3]. Bird S, Klein E, Loper E (2009) Natural
language processing with python, 1st edn.
O’Reilly Media, Inc
[4]. Calefato F, Lanubile F, Novielli N (2017)
Emotxt: a toolkit for emotion recognition from
text. arXiv:170803892
Volume XII, Issue IV, 2020 Page No: 5511Journal of Xi'an University of Architecture & Technology ISSN No : 1006-7930
[5]. Carreno L V G, Winbladh K (2013) “ [15] S.Pradeep Kumar ; O. Pandithurai,Sixth
Analysis of user comments: an approach for sense technology,2013 International Conference
software requirements evolution. In: 2013 35th on Information Communication and Embedded
international conference on software engineering Systems (ICICES)
(ICSE).
https://doi.org/10.1109/ICSE.2013.6606604, pp [16] K. Sriprasadh ;Saicharansrinivasan ; O.
582–591 Pandithurai ; A. saravanan,A novel method to
secure cloud computing through multicast key
[6]. Cortes C, Vapnik V (1995) Support-vector management,2013 International Conference on
networks. Mach Learn 20(3):273–297. Information Communication and Embedded
https://doi.org/10.1007/BF00994018 Systems (ICICES)
[7] Finkelstein A, Harman M, Jia Y, Martin W, [17] O. Pandithurai ; N. suganya ; S. Naresh ; Jaya
Sarro F, Zhang Y (2017) Investigating the Krishna Deva ; B. Suresh,Accessing the required
relationship between price, rating, and popularity information from an applications in cloud through
in the blackberry world app store. Inf Softw SMS,2013 International Conference on
Technol87:119–139. Information Communication and Embedded
https://doi.org/10.1016/j.infsof.2017.03.002. Systems (ICICES)
http://www.sciencedirect.com/science/article/pii/
S095058491730215X [18] O. Pandithurai ; M. Poongodi ; S. Pradeep
Kumar ; C. Gopala Krishnan,A method to support
[8] .Fritz C O, Morris P E, Richler J J (2012) multi-tenant as a service,2011 Third International
Effect size estimates: current use, calculations, Conference on Advanced Computing,pp 157-162
and interpretation. J Exp Psychol Gen 141(1):2
[9]. Gao C, Xu H, Hu J, Zhou Y (2015) Ar-
[19] C.P. Indumathi ; B. Galeebathullah ; O.
tracker: “track the dynamics of mobile apps via
user review mining” ,IEEE symposium on Pandithurai,Analysis of test case coverage using data
service-oriented system engineering (SOSE).
mining technique,2010International conference on
IEEE, pp 284–290,2017
communication control and computing technologies,pp
[10]. Google (2017) Google play user ratings, 806-809
reviews, and installs.
[20] V. Rajesh ; O. Pandithurai ; S. Mageshkumar,Wireless
https://play.google.com/about/storelisting-
promotional/ratings-reviews-installs/ sensor node data on cloud,2010International
conference on communication control and computing
[11] . Google (2018) Google Play Prohibited and
technologies,pp 476-481
RestrictedContent.
https://support.google.com/contributionpolicy/an [22] G. Sivasankari and O. Pandithurai,Web User Session
swer/7400114
Traffic Tracing Via Clustering Techniques,2010
International Conference on Computer Applications
[12] Daniel Martens1 · Walid Maalej1,” Towards
understanding and detecting fake reviews in app Database Systems,pp 220-229
stores”, Empirical Software Engineering (2019)
24:3316–3355
[13] Elshrif Elmurngi, Abdelouahed Gherbi,”
Detecting Fake Reviews through Sentiment
Analysis Using Machine Learning Techniques”,
The Sixth International Conference on Data
Analytics,2017.
[14] O. Pandithurai, Dr. C. Sureshkumar, High-
Performance Multipath Routing Algorithm Using
CPEGASIS Protocol in Wireless Sensor Cloud
Environment,2016 Scientific research An
academic publisher,vol.7,PP. 3246-3252
Volume XII, Issue IV, 2020 Page No: 5512You can also read

















































