Multimodal Integration of Human-Like Attention in Visual Question Answering
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Multimodal Integration of Human-Like Attention
in Visual Question Answering
Ekta Sood1 , Fabian Kögel1 , Philipp Müller2 , Dominike Thomas,1 , Mihai Bâce1 , Andreas Bulling1
1
University of Stuttgart, Institute for Visualization and Interactive Systems (VIS), Germany
2
German Research Center for Artificial Intelligence (DFKI)
{ekta.sood,fabian.koegel,dominike.thomas,mihai.bace,andreas.bulling}@vis.uni-stuttgart.de
{philipp.mueller}@dfki.de
Abstract patterns of influence on attention processes on im-
ages (Yu et al., 2019b; Jiang et al., 2020).
Human-like attention as a supervisory signal
to guide neural attention has shown signifi- Simultaneously, an increasing number of works
have demonstrated the effectiveness of integrating
arXiv:2109.13139v1 [cs.CV] 27 Sep 2021
cant promise but is currently limited to uni-
modal integration – even for inherently multi- human-like attention into neural attention mecha-
modal tasks such as visual question answering nisms across a wide range of tasks, including image
(VQA). We present the Multimodal Human- captioning (Sugano and Bulling, 2016), text com-
like Attention Network (MULAN) – the first prehension tasks (Sood et al., 2020b), or sentiment
method for multimodal integration of human-
analysis and grammatical error detection (Barrett
like attention on image and text during train-
ing of VQA models. MULAN integrates at- et al., 2018). Research on integrating human-like at-
tention predictions from two state-of-the-art tention into neural attention mechanisms for VQA
text and image saliency models into neural has also attracted increasing interest (Qiao et al.,
self-attention layers of a recent transformer- 2018; Selvaraju et al., 2019; Wu and Mooney, 2019;
based VQA model. Through evaluations on Chen et al., 2020; Shrestha et al., 2020). However,
the challenging VQAv2 dataset, we show that despite the inherent multimodality of the VQA task,
MULAN achieves a new state-of-the-art per-
these works only integrate human-like attention on
formance of 73.98% accuracy on test-std and
73.72% on test-dev and, at the same time, has
images. A method for predicting and integrating
approximately 80% fewer trainable parame- human-like attention on text, which has obtained
ters than prior work. Overall, our work under- state-of-the-art performance in downstream NLP
lines the potential of integrating multimodal tasks, has only recently been proposed (Sood et al.,
human-like and neural attention for VQA. 2020b) and multimodal integration of human-like
attention remains unexplored.
1 Introduction
We fill this gap by proposing the Multimodal
Visual question answering (VQA) is an important Human-like Attention Network (MULAN) – the
task at the intersection of natural language process- first method for multimodal integration of human-
ing (NLP) and computer vision that has attracted like attention in VQA. In contrast to previous uni-
significant research interest in recent years (An- modal integration methods on images alone, our
tol et al., 2015; Malinowski and Fritz, 2014; Ma- method allows human attention information to act
linowski et al., 2015; Yu et al., 2019b). One of as a link between text and image input. MULAN
its key challenges is, by its very nature, to jointly integrates state-of-the-art human saliency models
analyze and understand the language and visual for text and images into the attention scoring func-
input computationally. State-of-the-art methods for tions of the self-attention layers of the MCAN VQA
VQA rely on neural attention mechanisms to en- architecture (Yu et al., 2019b). This way, human at-
code relations between questions and images and, tention acts as an inductive bias directly modifying
for example, focus processing on parts of the im- neural attention processes. To model human-like
age that are particularly relevant for a given ques- attention on text we make use of the recently pro-
tion (Yu et al., 2017, 2019b; Jiang et al., 2020; posed Text Saliency Model (TSM) (Sood et al.,
Anderson et al., 2018). An increasing number of 2020b) that we adapt to the VQA task while train-
methods make use of multiple Transformer-based ing the MCAN framework. Human attention on
attention modules (Vaswani et al., 2017): they en- images is integrated using the recent multi-duration
able attention-based text features to exert complex saliency model (Fosco et al., 2020) that also models
the temporal dynamics of attention. We train our started experimenting with human-inspired neural
model on the VQAv2 dataset (Goyal et al., 2017) attention and showed that adding neural attention
and achieve state-of-the-art performance of 73.98% mechanisms improved performance for VQA. Shih
accuracy on test-std and 73.72% test-dev. Notably, et al. (2016) added a region selection layer to pin-
given that our model is based on the MCAN small point relevant areas of an image and improved from
variant, we require significantly fewer trainable pa- Antol et al. (2015) by 5%. Similarly, Anderson
rameters than the large variant. et al. (2018) demonstrated that using bottom-up
Our contributions are three-fold: First, we pro- attention was preferable to top-down, and won first
pose a novel method to jointly integrate human-like place in the 2017 VQA Challenge. Jiang et al.
attention on text and image into the MCAN VQA (2018) further expanded on this work by optimiz-
framework (Yu et al., 2019b). Second, we evalu- ing the model architecture and won the 2018 VQA
ate our method on the challenging test-std VQAv2 challenge. Follow-up works combined learned
benchmark (Goyal et al., 2017) and show that it visual and language attention in order to narrow
outperforms the state of the art on both test-std and down which part of the image and question are
test-dev while requiring about 80% fewer trainable relevant, first with alternating attention (Lu et al.,
parameters. Finally, through detailed analysis of 2016), dual attention (Nam et al., 2017), and fi-
success and failure cases we provide insights into nally multi-level attention (Yu et al., 2017). The
how MULAN makes use of human attention in- success of Transformers (Vaswani et al., 2017) in
formation to correctly answer questions that are NLP tasks also inspired new work in VQA. Yu et al.
notoriously difficult, e.g. longer questions. (2019b) created the Transformer-inspired Modular
Co-Attention Network (MCAN) that combines self-
2 Related Work attention with guided-attention to leverage the inter-
action within and between modalities. Jiang et al.
Our work is related to previous works on 1) vi-
(2020) further built on this architecture and won
sual question answering, 2) using neural attention
the 2020 VQA Challenge. Tan and Bansal (2019)
mechanisms, and 3) using human-like attention as
improved input encoding with a Transformer and
a supervisory signal.
transfer learning, while Li et al. (2020) modified
Visual Question Answering. Using natural lan- input encodings by adding an object tag to help
guage to answer a question based on a single image align images and text semantically.
(Antol et al., 2015) has been a topic of increas-
ing interest in recent years (Malinowski and Fritz, Supervision Using Human Attention. Despite
2014; Malinowski et al., 2015). Antol et al. (2015) its advantages, it was also demonstrated that neu-
built the first, large-scale VQA dataset that pro- ral attention may focus on the wrong area of an
vided open-ended, free-form questions created by image (Das et al., 2016; Chen et al., 2020). To
humans. Given that models have been shown to ex- rectify this, human attention was brought in as an
ploit bias in datasets (Agrawal et al., 2016), Goyal additional supervisory signal. Researchers investi-
et al. (2017) expanded the VQA dataset by bal- gated differences between neural and human atten-
ancing it so that each question had two images, tion in VQA (Das et al., 2016; Chen et al., 2020)
with two different answers to the same question. and created datasets containing human attention
Tests on this new dataset (VQAv2) obtained sig- maps (Fosco et al., 2020; Chen et al., 2020; Das
nificantly reduced performance for current models, et al., 2016). At the same time, integrating hu-
showing how prevalent answer bias was before. man attention supervision showed to be promis-
Another challenge in VQA remains the lack of in- ing in closely related computer vision (Sugano
consistency in answer predictions (Shrestha et al., and Bulling, 2016; Karessli et al., 2017) or NLP
2019; Zhang et al., 2016; Selvaraju et al., 2020) tasks (Barrett et al., 2018; Sood et al., 2020a). Sood
and reduced performance for compositional ques- et al. (2020b) proposed a novel text saliency model
tions (Agrawal et al., 2017; Andreas et al., 2016; that, by combining a cognitive model of reading
Shrestha et al., 2019) or linguistic variation (Shah with human attention supervision, beat state-of-the-
et al., 2019; Agrawal et al., 2018). art results on paraphrase generation and sentence
compression. For VQA tasks, Gan et al. (2017)
Neural Attention Mechanisms. To imbue mod- combined human attention on images and seman-
els with more reasoning capabilities, researchers tic segmentation of questions. Using ground truth
human attention, Wu and Mooney (2019) penal- kens and represented using 300-D GloVe (Penning-
ized networks for focusing on the wrong area of ton et al., 2014) word embeddings. The n × 300
an image, while Selvaraju et al. (2019) guided neu- embeddings are further passed through a one-layer
ral networks to look at areas of an image that hu- LSTM with hidden size dy and all intermediate
mans judged as particularly relevant for question hidden states form the final question representa-
answering. Chen et al. (2020) continued in this tion matrix Y ∈ Rn×dy . Both representations are
direction by using human attention to encourage zero-padded to accommodate the varying number
reasoning behaviour from a model. Since obtaining of grid features and question words.
ground truth human attention annotations is costly
Base model. In general, an attention function
and time-consuming, Qiao et al. (2018) trained a
computes an alignment score between a query and
network on the VQA-HAT dataset to automatically
key-value pairs and uses the score to re-weight the
generate human-like attention on unseen images,
values. Attention methods differ in their choice of
then used these saliency maps to create the en-
scoring function, whether they attend to the whole
hanced Human-Like ATention (HLAT) dataset.
(global/soft) or only parts (local/hard) of the input,
3 Method and whether queries and key-value pairs are projec-
tions from the same inputs (self-attention) or differ-
The core contribution of our work is to propose ent inputs (guided attention). The Deep Modular
MULAN, the first multimodal method to integrate Co-Attention Network (MCAN) for VQA (Yu et al.,
human-like attention on both the image and text 2019b) is a Transformer-based network (Vaswani
for VQA (see Figure 1 for an overview of the et al., 2017) that runs multiple layers of multi-
method). At its core, our method builds on the headed self-attention (SA) and guided-attention
recent MCAN model (Yu et al., 2019b,a), which (GA) modules in an encoder-decoder architecture
won the 2019 VQA challenge as well as being the using the scaled dot-product score function.
basis of the 2020 winning method utilizing grid A schematic of an SA module is shown in Fig-
features (Jiang et al., 2020). We adapted the open ure 2 in gray. It consists of two sub-layers: the
source implementation1 and trained the small vari- multi-headed attention and a feed-forward layer.
ant of the MCAN using the grid features2 . We Both are encompassed by a residual connection
first introduce the feature representations and the and layer normalization. The attention sub-layer
MCAN framework and subsequently explain our projects the input feature embeddings into queries
novel multimodal integration method3 . Q ∈ Rn×d , keys K ∈ Rn×d , and values V ∈
Rn×d with a common hidden dimension d. For a
Feature Representations. We represent the in- query q the attended output is calculated with:
put images by spatial grid features, following the
extraction methodology of Jiang et al. (2020). A qK T
A(q, K, V ) = softmax( √ )V (1)
Faster R-CNN with ResNet-50 backbone (Ren d
et al., 2015; He et al., 2016) is pre-trained on Ima-
geNet (Deng et al., 2009) and VG (Krishna et al., As in the Transformer (Vaswani et al., 2017), this is
2016) and then the object proposal and RoI pooling calculated for multiple queries at once with QK T
(used for region features in Anderson et al. (2018)) and the results of several heads with different pro-
is removed. The remaining ResNet directly out- jections for Q, K, V are combined.
puts the grid features. We obtain up to 19x32 fea- The GA module is set up identically to the SA
tures (depending on aspect ratio) per image. The module except the queries and key-value pairs are
final image representation is X ∈ Rm×dx with provided by separate inputs. In this way, text fea-
m ∈ [192, 608], where m represents the number of tures can guide attention on image features. Intu-
features, and dx the feature embedding dimension. itively, the attention layer reconstructs the queries
The input questions are represented as in MCAN: from a linear combination of the values, emphasiz-
tokenized at word-level, trimmed to n ∈ [1, 14] to- ing interactions between them. The value space is
projected from the input features, which in the GA
1
https://github.com/MILVLG/openvqa case is a fusion space between the modalities.
2
https://github.com/facebookresearch/ The MCAN encoder stacks multiple layers of
grid-feats-vqa
3
Our implementation and other supporting material will SA on text features Y ∈ Rny ×dy before feeding
be made publicly available the result of the last layer into the decoder. The
TSM
Question:
What color GloVe+ Attention
FC
is the sign? LSTM Reduction
MCAN
FC BCE
Encoder - Decoder
Grid Attention
FC
Feats. Reduction
Answer:
Yellow
Multi-duration Attention
Saliency Maps
Figure 1: Overview of the Multimodal Human-like Attention Network (MULAN). Our method proposes multi-
modal integration of human-like attention on questions as well as images during training of VQA models. MULAN
leverages attention predictions from two state-of-the-art text (Sood et al., 2020b) and image saliency models (Fosco
et al., 2020).
decoder stacks modules with SA on image features
X ∈ Rnx ×dx and GA between the encoder result Add + Normalize
and the SA output. After the last layer, the resulting
feature matrices from both encoder and decoder are Feed Forward
flattened to obtain the attended features ỹ ∈ Rd and
x̃ ∈ Rd and fused by projecting them into the same
space and adding them. The VQA task is formu- Add + Normalize
lated as classification, so a final projection into the
answer dimension and a sigmoid function conclude α
the network. Jiang et al. (2020) improved the per-
formance of the original MCAN by replacing the Human Attention
K V Q
Weights
region image features with spatial grid features. We
use their model as a baseline for our experiments.
Y
Human-Like Attention Integration. Although
the importance of fusing both modalities has been Figure 2: Schematic of a self-attention (SA) layer. The
vanilla SA layer is shown in gray, while our human at-
underlined by many previous works and is the driv-
tention integration approach in red.
ing idea behind co-attention, the integration of ex-
ternal guidance has only been explored in the image
domain (Gan et al., 2017; Qiao et al., 2018; Sel-
varaju et al., 2019; Wu and Mooney, 2019; Chen part of MCAN (see Figure 1) and on the image
et al., 2020; Shrestha et al., 2020). after the first GA module that integrates text and
We integrate human-like attention into both the image. This early integration is motivated by Brun-
text and image streams of the MCAN base model. ner et al. (2020) who investigated the token mixing
For both streams, we use the same basic principle that occurs in self-attention layers. They found
of integration into SA modules (see Figure 2). We that the contribution of the original input token
propose a new attention function AH for the SA to the embedding at the same position quickly de-
layer, multiplying human-like attention weights creases after the first layer, making the integration
α ∈ Rn (Rm for image features) into the attention of re-weighting attention weights less targeted at
score. For the query qi corresponding to the i- later layers. We opted to integrate human-like im-
th input feature embedding, we calculate the i-th age attention in the SA module after the first GA
attended embedding: module (as opposed to before) because this allows
text-attention dependent features to interact during
qi K T · α i integration of human-like attention on the image.
AH (q, K, V, α) = softmax( √ )V (2)
d To obtain human-like attention scores for questions
We integrate human-like attention on the ques- and images, we make use of domain-specific atten-
tion text into the first SA module in the encoder tion networks that we discuss in the following.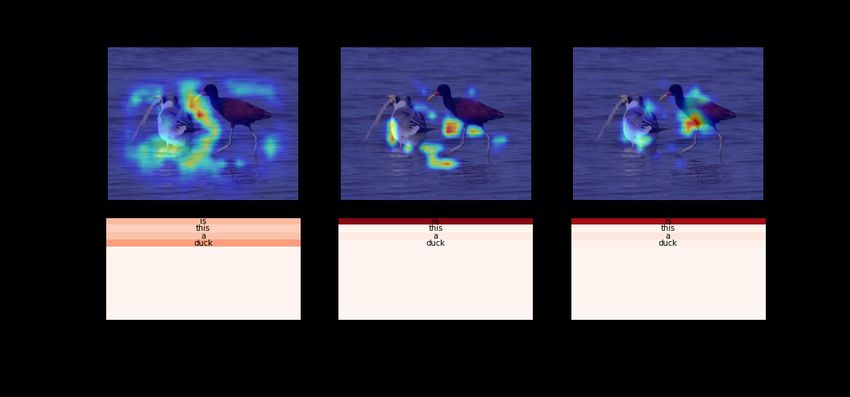
Model test-std test-dev the Transformer heads was kept at 512. The in-
creased dimensions in the MCAN large configura-
MULAN (multimodal) 73.98% 73.72%
tion did not bring performance advantages in our
Text only (TSM) 73.77% 73.52%
preliminary experiments, so we opted for fewer pa-
Image only (MDS) 73.67% 73.39%
rameters. In the added TSM model we set the hid-
No Integration 73.65% 73.39%
den dimension for both BiLSTM and Transformer
Li et al. (2020) 73.82% 73.61% heads to 128. We used 4 heads and one layer. Even
Jiang et al. (2020) 72.71% 72.59% including the trainable parameters added by the
TSM model, our full MULAN model has signifi-
Table 1: Results showing test-std and test-dev accu- cantly fewer parameters than MCAN large (MU-
racy scores of our model (trained on train+val+vg) LAN: 58M, MCAN large: 203M). We kept the
and ablated versions over different datasets. MULAN
MCAN Adam Solver and the corresponding learn-
achieves state-of-the-art on both benchmarks.
ing rate schedule and trained over 12 epochs with
batch size 64. The pre-trained TSM model is
Text Attention Model. For text, we make use trained jointly with the MCAN. Results on test-
of the recently introduced Text Saliency Model std were obtained after training on train and val
(TSM) (Sood et al., 2020b) that yields an attention splits and a subset of Visual Genome vg, for results
weight for every token in the question. TSM is on val we trained on train. We trained on single
pre-trained on synthetic data obtained from a cog- Nvidia Tesla V100-SXM2 GPUs with 32GB RAM.
nitive reading model as well as on real human gaze Average runtime was 2.6h for models trained on
data. Sood et al. (2020b) proposed a joint training train (36h for convergence) and 5.3h for models
approach in which TSM predictions are integrated trained on train+val+vg (68h for convergence).
into the Luong attention layer (Luong et al., 2015)
of a downstream NLP task and fine-tuned while 4 Experiments
training for this downstream task. We follow a We used VQAv24 , the balanced version (Goyal
similar methodology and fine-tune the TSM while et al., 2017) of the VQA dataset (Antol et al., 2015),
training our VQA network. for all our experiments. VQAv2 is among the most
popular benchmark datasets in the field and con-
Image Attention Model. For images, we ob-
tains 1.1M human-annotated questions on 200K
tain human-like attention using the state-of-the-art
images from MS COCO (Lin et al., 2014), split
Multi-Duration Saliency (MDS) method (Fosco
into train, val, and test-dev/test-std sets. The anno-
et al., 2020). MDS predicts human attention alloca-
tations for the test splits have been held back for
tion for viewing durations of 0.5, 3, and 5 seconds.
online evaluation of models submitted to the an-
Because our integration approach requires a single
nual challenge. The standard evaluation metric5 is
attention map per image, we use the output of MDS
simple overall accuracy, for which agreement with
for the 3 second viewing duration as suggested by
three out of the 10 available annotator answers is
the original authors. The input images are of dif-
considered as achieving an accuracy of 100%. In
ferent aspect ratios which leads to black borders in
practice the machine accuracy is calculated as mean
the obtained fixed-size MDS maps after re-scaling.
over all 9 out of 10 subsets.
However, the grid features are extracted from im-
The standard evaluation is misleading because
ages with their original aspect-ratios. Therefore,
the same overall accuracy can be achieved by an-
to obtain a single attention weight per feature, we
swering very different sets of questions. Hence,
remove the borders from the MDS maps, overlay
we evaluated accuracy overall for comparison with
the grid features and sum the pixel values in every
other work, but also binned “per question-type” as
grid cell. The values are then normalized over the
proposed by Kafle and Kanan (2017) to compensate
total sum to produce a distribution.
for class imbalance and answer bias skewing the
Implementation Details. We trained the net- evaluation. For this, we used their question types
work using the basic configuration and hyperpa- that categorize questions by the task they solve and
rameters of MCAN small. The input features were added a reading category for questions that are an-
set to dy = 512 and after the change to grid fea- 4
https://visualqa.org/download.html
5
tures, dx = 2048. The hidden dimension d inside https://visualqa.org/evaluation.html
swered by text on the image. Because they label TSM MDS test-std
only about 8% of VQAv2 val, we annotated the
1 2 (ours) 73.98%
full val set using a BiLSTM network pre-trained
2 2 73.64%
on TDIUC (1.6M samples) and hand-crafted regu-
1, 3, 5 2 73.73%
lar expressions (245K samples). These additional
1 1–6 71.55%
annotations allowed us to assess the performance
1–3 2 73.49%
changes of our model in more detail.
1–6 2 73.73%
We performed a series of experiments to evalu-
1–6 2–6 73.50%
ate the performance of our proposed method. To
shed more light on the importance of multimodal
Table 2: Layer-wise integration ablation study results,
integration, we first compared different ablated on test-std. We integrate human-like attention at dif-
versions of our method on test-dev and test-std. ferent layer combinations. TSM question attention
Specifically, we compared multimodal with text- weights are integrated into encoder SA modules, MDS
only, image-only, and integration of human-like image attention weights into decoder SA modules.
attention. Afterwards, we evaluated performance
of the multimodal method when integrating human-
like attention at different layers of the Transformer et al. (2020). Notably, we observe a systematic
network. Finally, we evaluated more fine-grained increase in performance as a result of human-like
performance values of the multimodal, unimodal, attention integration. Our base model without any
and no attention integration method for the differ- integration reaches 73.65% on test-std. While the
ent question types. For all of these experiments, integration of human-like attention on only images
we report accuracy on test-std with training on the (73.67%) or text (73.77% on test-std) can lead to an
union of train, val and vg sets. increase in performance, our full MULAN model
employing multimodal integration is the best per-
forming approach. This further underlines the im-
portance of jointly integrating human-like attention
on both text and images for the VQA task, which
is inherently multimodal.
Layer-Wise Integration Experiments. We
evaluated the integration of human-like attention
on questions and images for different layers in
the MCAN encoder-decoder architecture (see
Table 2). We investigated the integration of TSM
outputs into different SA layers of the encoder, and
the integration of MDS outputs into different SA
Figure 3: Performance improvements of our multi-
modal integration method (MULAN) relative to the
modules of the decoder. Among all investigated
baseline (No Integration), depending on the question combinations, the initial integration into the first
length. Results show a significant increase in accuracy layer of the encoder and the second layer of
for longer questions, in particular when questions have the decoder performed best (73.98% accuracy).
seven or more tokens. Integrating TSM predictions into the second
encoder layer decreased the overall accuracy
to 73.64%, which is in line with the reasoning
5 Results and Discussion
discussed in Brunner et al. (2020), where with
Overall Performance. Table 1 shows results of layer depth feature embeddings are increasingly
our MULAN model along with current state-of-the- mixed and therefore less attributable to the input
art approaches and ablations of our method. Our word token at the same position. The TSM predicts
method outperforms the current state of the art (Li attention weights for specific word tokens. We
et al., 2020), reaching accuracy scores of 73.98% further investigated the integration of TSM and
on test-std and 73.72% on test-dev, as compared MDS predictions at multiple layers in the MCAN
to 73.82% and 73.61%. Our model also uses ap- architecture. However all options resulted in
proximately 80% less trainable parameters than Li decreased performance in comparison to MULAN.
Question type Bin Size No Integration text-only image-only MULAN
reading 31 K 42.46 42.28 42.40 42.30
activity recognition 15 K 74.55 74.72 74.59 75.01
positional reasoning 26 K 61.74 61.97 61.85 62.01
object recognition 28 K 82.59 82.50 82.49 82.68
counting 24 K 59.77 59.70 59.44 59.82
object presence 17 K 86.45 86.47 86.59 86.57
scene recognition 15 K 79.19 79.10 79.20 79.19
sentiment understanding 14 K 83.59 83.77 83.53 83.92
color 25 K 80.56 80.52 80.31 80.56
attribute 4K 69.36 69.09 69.37 69.65
utility affordance 11 K 66.33 66.40 66.64 66.42
sport recognition 6K 85.39 85.38 85.93 85.60
Overall VQAv2 val Accuracy: 70.06 70.09 70.03 70.28*
Table 3: Performance on VQAv2 val split in terms of per-question-type accuracy of the proposed multimodal
integration method (MULAN) and the unimodal ablations text-only or image-only and no integration of human
attention (No Integration). Because the online evaluation of VQAv2 only returns overall accuracy, we cannot
obtain fine-grained accuracy for test-std or test-dev. A star indicates statistically significant p at p < 0.05.
MULAN
epoch 1: "nothing" epoch 8: "refrigerator" epoch 13: "refrigerator"
No Integration
epoch 1: "food" epoch 8: "food" epoch 13: "nothing"
Figure 4: Visualization of the weights in the attention reduction modules for text and image features. We compared
MULAN and the baseline model (No Integration) at epochs 1, 8, and 13. The input question was “What is the child
digging around in?”, the correct answer is “fridge”. Classification outputs are given for each considered epoch.
Our results indicate that early integration of els obtain inferior performance to our full model
human-like attention at a single point for both text on the validation set (statistically significant at the
and image is optimal for the VQA task. 0.05 level). For most categories, MULAN achieves
the highest accuracy. Moreover, in comparison to
Category-Specific Performance. To obtain a the baseline, our method is the best performing one
deeper understanding of our improvements over in 10 out of 12 categories with especially clear im-
baseline approaches, we categorized question types provements in activity recognition and sentiment
into 12 fine-grained bins, similarly to Kafle and analysis categories. MULAN expectedly reduces
Kanan (2017). Table 3 shows a detailed breakdown accuracy on reading questions that other models
of accuracy results by category type. We used the can most likely only answer by bias exploitation,
validation set, rather than the test set, since we and improves on small bins like attribute. The dis-
needed access to the ground truth annotations to tances between the models are small in absolute
calculate the per-category accuracy. For the same terms, but given the vastly different bin sizes the
reason, we can only perform the paired t-test on the relative improvements are large. This underlines
full validation set. As can be seen, all ablated mod- the robustness of improvements with human-like
attention integration and, in particular, multimodal the question text. Figure 5 shows three additional
integration. examples of our method compared to the baseline
from the final epoch. The top and middle examples
Sequence-Length Analysis. Previous works show how our method is able to correctly answer
have shown that VQA models often converge to the question, while the baseline fails. The bottom
the answer after processing only the first words of example shows an error case of our method.
a question, a behavior that has been characterized
Q: What is the baby sheep in the foreground doing?
as “jumping to conclusions” (Agrawal et al., 2016). A: nursing
Human-like attention integration might be useful
to combat this effect as the TSM was previously
shown to successfully predict human-like attention
distributions across all salient words in the input
MULAN: "nursing" No Integration: "eating"
sequence (Sood et al., 2020b). As this effect might
be especially pronounced for longer questions, we
Q: Is the man sitting in the sun?
investigated whether human-like attention integra- A: no
tion in MULAN can especially improve on those
questions (Agrawal et al., 2016). Figure 3 shows
the results of an evaluation where we analyzed the
improvements of our system relative to the base-
line model, depending on the question length. We MULAN: "no" No Integration: "yes"
find that while MULAN improves for all questions
independent of their length, its advantage is espe- Q: Is this a duck?
A: no
cially significant for questions that contain seven
tokens or more (relative improvements of 0.3% or
more), indicating that MULAN can improve upon
the above-described challenge.
MULAN: "yes" No Integration: "no"
Attention Visualizations. To further investigate
MULAN’s ability to answer longer questions than Figure 5: Visualization of attention distributions for
MULAN and the baseline (No Integration). The up-
the baseline model, we visualized the attention
per examples show improvements of MULAN over the
weights in the attention reduction modules after baseline, while the bottom shows a failure case.
the encoder/decoder, which merge the text and im-
age features to one attended feature vector each.
These weights represent the final impact of the 6 Conclusion
transformed features. Figure 4 shows examples
from the validation set with the corresponding pre- In this paper, we propose the first method for multi-
dictions comparing our method to the baseline at modal integration of human-like attention on both
epochs 1, 8 and 13. The input question was “What image and text for visual question answering. Our
is the child digging around in?” and the correct Multimodal Human-like Attention Network (MU-
answer is “fridge”. Our method it able to correctly LAN) method integrates state-of-the-art text and
predict that the child is digging in the fridge as op- image saliency models into neural self-attention
posed to the baseline that outputs “nothing”. MU- layers by modifying attention scoring functions
LAN focuses on both the token “digging” as well of transformer-based self-attention modules. Eval-
as the location, which is in front of the child. In uations on the challenging VQAv2 dataset show
contrast, the attention of the baseline model is more that our method not only achieves state-of-the-art
spread out, failing to focus on the relevant cues. In- performance (73.98% on test-std and 73.72% on
terestingly, the focus of attention in the baseline test-dev) but also does so with fewer trainable pa-
evolved over several epochs of training, unlike MU- rameters than current models. As such, our work
LAN which quickly converged to a stable attention provides further evidence for the potential of inte-
distribution. This indicates that initial human-like grating human-like attention as a supervisory signal
attention maps on the image are indeed adapted in neural attention mechanisms.
using attention-based information extracted from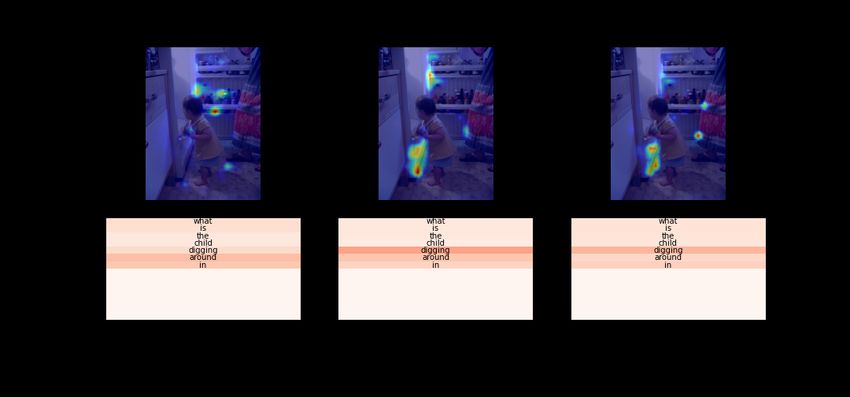
References Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai
Li, and Li Fei-Fei. 2009. Imagenet: A Large-Scale
Aishwarya Agrawal, Dhruv Batra, and Devi Parikh. Hierarchical Image Database. In Proceedings of
2016. Analyzing the Behavior of Visual Question the 2009 IEEE/CVF Conference on Computer Vision
Answering Models. In Proceedings of the 2016 and Pattern Recognition (CVPR), pages 248–255.
Conference on Empirical Methods in Natural Lan-
guage Processing (EMNLP), pages 1955–1960. As- Camilo Fosco, Anelise Newman, Pat Sukhum, Yun Bin
sociation for Computational Linguistics. Zhang, Nanxuan Zhao, Aude Oliva, and Zoya Bylin-
skii. 2020. How Much Time Do You Have? Mod-
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and
eling Multi-Duration Saliency. In Proceedings of
Aniruddha Kembhavi. 2018. Don’t Just Assume;
the 2020 IEEE/CVF Conference on Computer Vision
Look and Answer: Overcoming Priors for Visual
and Pattern Recognition (CVPR), volume 1, pages
Question Answering. In Proceedings of the 2018
4473–4482.
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR). Chuang Gan, Yandong Li, Haoxiang Li, Chen Sun,
and Boqing Gong. 2017. VQS: Linking Segmen-
Aishwarya Agrawal, Aniruddha Kembhavi, Dhruv Ba-
tations to Questions and Answers for Supervised
tra, and Devi Parikh. 2017. C-VQA: A Com-
Attention in VQA and Question-Focused Semantic
positional Split of the Visual Question Answering
Segmentation. In Proceedings of the IEEE/CVF In-
(VQA) v1.0 Dataset. In arXiv:1704.08243.
ternational Conference on Computer Vision (ICCV),
Peter Anderson, Xiaodong He, Chris Buehler, Damien pages 1811–1820.
Teney, Mark Johnson, Stephen Gould, and Lei
Zhang. 2018. Bottom-Up and Top-Down Attention Yash Goyal, Tejas Khot, Douglas Summers-Stay,
for Image Captioning and Visual Question Answer- Dhruv Batra, and Devi Parikh. 2017. Making the
ing. In Proceedings of the 2018 IEEE/CVF Confer- v in VQA Matter: Elevating the Role of Image Un-
ence on Computer Vision and Pattern Recognition derstanding in Visual Question Answering. In Pro-
(CVPR), volume 1, pages 6077–6086. ceedings of the 2017 IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and 6325–6334.
Dan Klein. 2016. Neural Module Networks. In Pro-
ceedings of the 2016 IEEE/CVF Conference on Com- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian
puter Vision and Pattern Recognition (CVPR), pages Sun. 2016. Deep Residual Learning for Image
39–48. Recognition. In Proceedings of the 2016 IEEE/CVF
Conference on Computer Vision and Pattern Recog-
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Mar- nition (CVPR).
garet Mitchell, Dhruv Batra, C Lawrence Zitnick,
and Devi Parikh. 2015. VQA: Visual Question An- Huaizu Jiang, Ishan Misra, Marcus Rohrbach, Erik
swering. In Proceedings of the IEEE/CVF Inter- Learned-Miller, and Xinlei Chen. 2020. In Defense
national Conference on Computer Vision (ICCV), of Grid Features for Visual Question Answering. In
pages 2425–2433. Proceedings of the 2020 IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR).
Maria Barrett, Joachim Bingel, Nora Hollenstein,
Marek Rei, and Anders Søgaard. 2018. Sequence Yu Jiang, Vivek Natarajan, Xinlei Chen, Marcus
Classification with Human Attention. In Proceed- Rohrbach, Dhruv Batra, and Devi Parikh. 2018.
ings of the ACL SIGNLL Conference on Computa- Pythia v0.1: the Winning Entry to the VQA Chal-
tional Natural Language Learning (CoNLL), pages lenge 2018.
302–312.
Kushal Kafle and Christopher Kanan. 2017. An Anal-
Gino Brunner, Yang Liu, Damián Pascual, Oliver ysis of Visual Question Answering Algorithms. In
Richter, Massimiliano Ciaramita, and Roger Watten- Proceedings of the IEEE/CVF International Confer-
hofer. 2020. On Identifiability in Transformers. In ence on Computer Vision (ICCV), pages 1983–1991.
International Conference on Learning Representa-
tions (ICLR), pages 1–35. Nour Karessli, Zeynep Akata, Bernt Schiele, and An-
dreas Bulling. 2017. Gaze Embeddings for Zero-
Shi Chen, Ming Jiang, Jinhui Yang, and Qi Zhao. 2020. Shot Image Classification. In Proceedings of the
AiR: Attention with Reasoning Capability. In Euro- 2017 IEEE/CVF Conference on Computer Vision
pean Conference on Computer Vision (ECCV). and Pattern Recognition (CVPR), pages 4525–4534.
Abhishek Das, Harsh Agrawal, C. Lawrence Zitnick, Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin John-
Devi Parikh, and Dhruv Batra. 2016. Human At- son, Kenji Hata, Joshua Kravitz, Stephanie Chen,
tention in Visual Question Answering: Do Humans Yannis Kalanditis, Li-Jia Li, David A Shamma,
and Deep Networks Look at the Same Regions? In Michael Bernstein, and Li Fei-Fei. 2016. Visual
Proceedings of the 2016 Conference on Empirical Genome: Connecting Language and Vision Using
Methods in Natural Language Processing (EMNLP), Crowdsourced Dense Image Annotations. Interna-
pages 932–937. tional Journal of Computer Vision.
Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Ramprasaath R. Selvaraju, Stefan Lee, Yilin Shen,
Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hongxia Jin, Shalini Ghosh, Larry Heck, Dhruv Ba-
Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng tra, and Devi Parikh. 2019. Taking a HINT: Lever-
Gao. 2020. Oscar: Object-Semantics Aligned Pre- aging Explanations to Make Vision and Language
training for Vision-Language Tasks. In European Models More Grounded. In Proceedings of the
Conference on Computer Vision (ECCV), volume IEEE/CVF International Conference on Computer
12375, pages 121–137. Vision (ICCV).
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Ramprasaath R. Selvaraju, Purva Tendulkar, Devi
Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, Parikh, Eric Horvitz, Marco Tulio Ribeiro, Be-
and C Lawrence Zitnick. 2014. Microsoft COCO: smira Nushi, and Ece Kamar. 2020. SQuINTing at
Common Objects in Context. In European Confer- VQA Models: Introspecting VQA Models with Sub-
ence on Computer Vision (ECCV), pages 740–755. Questions. In Proceedings of the 2020 IEEE/CVF
Conference on Computer Vision and Pattern Recog-
Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. nition (CVPR), pages 10003–10011.
2016. Hierarchical Question-Image Co-Attention
for Visual Question Answering. In Advances in Neu- Meet Shah, Xinlei Chen, Marcus Rohrbach, and Devi
ral Information Processing Systems 29 (NeurIPS), Parikh. 2019. Cycle-Consistency for Robust Visual
pages 1–9. Question Answering. In Proceedings of the 2019
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 6642–6651. IEEE.
Minh-Thang Luong, Hieu Pham, and Christopher D
Manning. 2015. Effective Approaches to Attention- Kevin J Shih, Saurabh Singh, and Derek Hoiem. 2016.
Based Neural Machine Translation. In Proceed- Where to Look: Focus Regions for Visual Question
ings of the 2015 Conference on Empirical Methods Answering. In Proceedings of the 2016 IEEE/CVF
in Natural Language Processing (EMNLP), pages Conference on Computer Vision and Pattern Recog-
1412–1421. nition (CVPR), pages 4613–4621.
Mateusz Malinowski and Mario Fritz. 2014. A Multi- Robik Shrestha, Kushal Kafle, and Christopher Kanan.
World Approach to Question Answering about Real- 2019. Answer Them All! Toward Universal Visual
World Scenes based on Uncertain Input. In Ad- Question Answering Models. In arXiv:1903.00366.
vances in Neural Information Processing Systems
(NeurIPS), volume 27, pages 1682–1690. Robik Shrestha, Kushal Kafle, and Christopher Kanan.
2020. A Negative Case Analysis of Visual Ground-
Mateusz Malinowski, Marcus Rohrbach, and Mario ing Methods for VQA. In Proceedings of the 58th
Fritz. 2015. Ask Your Neurons: A Neural-Based Annual Meeting of the Association for Computa-
Approach to Answering Questions about Images. In tional Linguistics, pages 8172–8181. Association
Proceedings of the IEEE/CVF International Confer- for Computational Linguistics.
ence on Computer Vision (ICCV), pages 1–9.
Ekta Sood, Simon Tannert, Diego Frassinelli, Andreas
Hyeonseob Nam, Jung-Woo Ha, and Jeonghee Kim. Bulling, and Ngoc Thang Vu. 2020a. Interpreting
2017. Dual Attention Networks for Multimodal Rea- Attention Models with Human Visual Attention in
soning and Matching. In Proceedings of the 2017 Machine Reading Comprehension. In Proceedings
IEEE/CVF Conference on Computer Vision and Pat- of the ACL SIGNLL Conference on Computational
tern Recognition (CVPR), volume 1, pages 2156– Natural Language Learning (CoNLL), pages 12–25.
2164.
Ekta Sood, Simon Tannert, Philipp Müller, and An-
dreas Bulling. 2020b. Improving Natural Language
Jeffrey Pennington, Richard Socher, and Christopher D.
Processing Tasks with Human Gaze-Guided Neural
Manning. 2014. GloVe: Global Vectors for Word
Attention. In Advances in Neural Information Pro-
Representation. In Proceedings of the 2014 Con-
cessing Systems (NeurIPS), pages 1–15.
ference on Empirical Methods in Natural Language
Processing (EMNLP), pages 1532–1543. Yusuke Sugano and Andreas Bulling. 2016. Seeing
with Humans: Gaze-Assisted Neural Image Caption-
Tingting Qiao, Jianfeng Dong, and Duanqing Xu. 2018. ing. In arXiv:1608.05203.
Exploring Human-Like Attention Supervision in Vi-
sual Question Answering. In Thirty-Second AAAI Hao Tan and Mohit Bansal. 2019. LXMERT: Learn-
Conference on Artificial Intelligence (AAAI), pages ing Cross-Modality Encoder Representations from
7300–7307. Transformers. In Proceedings of the 2019 Confer-
ence on Empirical Methods in Natural Language
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Processing (EMNLP), pages 5100–5111.
Sun. 2015. Faster R-CNN: Towards Real-Time Ob-
ject Detection with Region Proposal Networks. In Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
Advances in Neural Information Processing Systems, Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz
volume 28, pages 91–99. Kaiser, and Illia Polosukhin. 2017. Attention is Allyou Need. In Advances in Neural Information Pro- cessing Systems (NeurIPS), volume 30, pages 5998– 6008. Jialin Wu and Raymond J. Mooney. 2019. Self-Critical Reasoning for Robust Visual Question Answering. In Advances in Neural Information Processing Sys- tems (NeurIPS), pages 1–11. Dongfei Yu, Jianlong Fu, Tao Mei, and Yong Rui. 2017. Multi-Level Attention Networks for Visual Question Answering. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 4187–4195. Zhou Yu, Yuhao Cui, Zhenwei Shao, Pengbing Gao, and Jun Yu. 2019a. OpenVQA. https://github. com/MILVLG/openvqa. Zhou Yu, Jun Yu, Yuhao Cui, Dacheng Tao, and Qi Tian. 2019b. Deep Modular Co-Attention Net- works for Visual Question Answering. In Proceed- ings of the 2019 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 6281–6290. Peng Zhang, Yash Goyal, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. 2016. Yin and Yang: Balancing and Answering Binary Visual Questions. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 5014–5022.
You can also read

















































