SAPO Seman*c API Luís Sarmento
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
SAPO
Seman*c
API
Luís
Sarmento
las@co.sapo.pt
Seman*c?
• What
is
a
“Seman*c
API”:
– API
providing
methods
for
seman*c
processing
of
text
“documents”
–
Suppor*ng
“intelligent”
applica*on:
• Text-‐Mining
• Informa*on
Extrac*on
• Informa*on
Retrieval
• Informa*on
Visualiza*on
Why?
• At
SAPO
we
aim
at
developing
more
intelligent
applica*ons
– Providing
beNer
content
to
Users
– Improving
Search
• We’ve
been
working
in
partnership
with
Universi*es
to
develop
tools
and
resources
that
will
support
such
intelligent
applica*ons
– Sapo
Labs
@
Universidade
do
Porto
Seman*c
API’s:
4
flavors
• API’s
providing:
– Lexical-‐seman,c
Informa,on
• E.g.
lists
of
names,
lists
of
words
by
classes
– Elementary
Language
Processing
Opera*ons
• E.g.
Tokeniza*on,
Named-‐En*ty
Recogni*on
– Text
Classifica*on
Methods
• E.g.
topic
classifica*on
of
news
or
query
strings
– Access
to
Dis*lled
Informa*on
(DEMO)
• E.g.
quota*ons
extracted
from
news
Philosophy
• Before
beginning:
– How
to
bring
R&D
to
applica*ons?
– How
can
we
do
R&D
in
a
commercial
se_ng?
– How
can
we
make
a
lot
of
science
converge
to
something
that
we
can
make
available
to
a
user?
– How
can
we
make
it
sustainable?
• This
is
important
to
explain:
– How
we
are
developing
our
API’s?
– Why
we
started
with
these
API’s?
Philosophy
(II)
• Simple
tools
built
on
top
of
each
other
– BoNom
up
approach
– First,
build
simple.
Then,
build
beNer
using
other
tools
that
have
been
developed
in
the
mean*me
• User
help
developing
tools
– Do
not
wait
for
the
“ul*mate
version”
to
deploy
• Build
something
and
deploy
– Improve
using
feedback
– Focus
on
user
needs
• Think
only
a
few
steps
ahead:
do
not
over
op*mize!
Philosophy
(III)
• “Knowledge”
resources
are
more
stable
than
“tools”
– Tools
depend
on
programming
languages
– Tools
are
hard
to
document
– Tools
are
very
hard
to
maintain
– Tools
end
up
becoming
very
dependent
on
one
(set
of)
developer(s)
– Tool
maintenance
is
difficult
to
pass
to
other
people
Philosophy
(IV)
• Knowledge:
– Development
tends
to
be
incremental
– Transference
is
easier
(csv
file?)
– There
are
also
problems,
of
course…
• Maintenance
can
be
hard
(so
we
need
tools?)
• Design
Data
Schemes
can
easily
become
too
complex
• Our
approach:
– Focus
on
building
simple
knowledge
bases
– Build
tools
to
expand
and
maintain
knowledge
bases
– Build
“good”
tools
making
the
most
use
of
knowlegde
Tools
on
top
of
knowledge:
Example
• If
we
knew
that
“Pedro
Passo
Coelho”:
– Is
a
valid
person
name
– May
have
“Passos
Coelho”
as
an
varia*on
– May
be
the
name
of
a
person
that
is
also
“primeiro
ministro
português”,
or
“chefe
do
governo”
in
most
news
• …
and
similar
informa*on
for
thousands
of
other
names/people
Tools
on
top
of
knowledge:
Example
(II)
• Then
we
could:
– Build
a
simple
dic*onary-‐based
NER;
or…
– Automa*cally
tag
a
corpus
to
train:
• a
(beNer)
NER
• an
anaphora
resolu*on
system
– Try
to
learn
how
to
paraphrase
• Therefore,
we
focus
on
building
the
knowledge
resources,
and
building
tools
on
top
Knowledge Resources LEXICAL-‐SEMANTIC RESOURCES
Lexical-‐Seman*c Resources • Resources consis*ng of lists of “words” organized in categories • Provide informa*on for genera*ng: – Extrac*on paNerns – Higher-‐level features for classifica*on procedures • We developed two resources: – Sapo Seman,c Lists – “common” lexicon – Sapo Verbetes – informa*on about en**es
Sapo
Seman*c
Lists
(SSLists)
• This
is
our
most
elementary
resource
– Lists
of
words
grouped
by
“class”.
E.g.:
• List
of
Countries
• List
of
job
descrip*ons
• List
of
geo-‐markers
• List
are
organized
in
a
two
level
“hierarchy”
of
classes
– Words
can
belong
to
mul*ple
classes
SSLists
(II)
• It
is
NOT
an
“ontology”
– Very
difficult
to
design
and
maintain
– We
use
an
open
hierarchy
with
only
two
levels
• But
elements
in
lists
can
have
any
type
of
proper*es
(key
value):
– E.g.
List
“na*onali*es”
• "words":
{
– "austríacos":
{"number":
"p”,"category":
"a_nc”,"gender":
"m”},
– "neozelandês":
{"number":
"s”,"category":
"a_nc”,"gender”:"m”},
– ...
SSLists:
Access
• Lists
are
available
via
a
Web-‐Service
– Web
Demo
SSLists: Examples • Some examples: • Web Demo
SSLists:
Maintenance
• Create
Lists
as
needed
– This
is
mo*vated
by
needs
from
other
projects
– Rather
ad-‐hoc
• We
try
to
link
our
lists
to
Wikipedia
Lists
– We
use
custom
extractors
to
obtain
more
data
from
Wikipedia
• Expand
using
semi-‐automa*c
methods
SSLists:
Semi-‐Automa*c
Expansion
• We
base
expansion
on
a
simple
intui*on:
– elements
of
the
same
class
tend
to
appear
in
lists
inside
text
documents
• Syntac*cally,
one
way
that
lists
can
be
built
is
using
coordina*on:
“…
A,
B
and
C…”
– “Similar
yellow
and
blue
waves
are
visible…”
–
“exercises
to
help
engineers
and
scien,sts
with
grammar”
(examples
taken
by
“googling”)
SSLists:
Semi-‐Automa*c
Expansion
(II)
• Simple
algorithm
to
expand
lists:
– Given
an
ini*al
set
of
seed
elements
S
=
(s1,s2,
…sn)
– Query
a
large
text
base
for
candidates
cx
that
match…
• “si
and
cx”
or
“cx
and
si”
…
for
si
in
S
– Rank
cx
by
number
of
elements
in
S
matched
• Or
use
any
more
sophis*cated
ranking
to
avoid
– Present
candidates
to
operator
for
valida*on
• Or
take
top
N
elements
and
add
it
automa*cally
Sapo
Verbetes
• Resource
containing
informa*on
about
en**es
(People,
Organiza*ons,…)
– Most
informa*on
Informa*on
Extrac*on
applica*ons
revolve
around
en**es
• Verbetes
is
built
and
maintained
using
fully-‐
automated
methods
• Informa*on
about
en**es
is
con*nually
harvested
from
news
sources
– on
an
hourly
basis
Sapo
Verbetes:
current
data
• Each
“Verbete”
contains
(mostly
for
people):
– Official
Name
– Name
Varia*ons
– Job
descrip*ons
• First
*me
seen
(on
news)
• Last
Time
seen
(on
news)
• IsAc*ve
flag
– IsAlive
flag
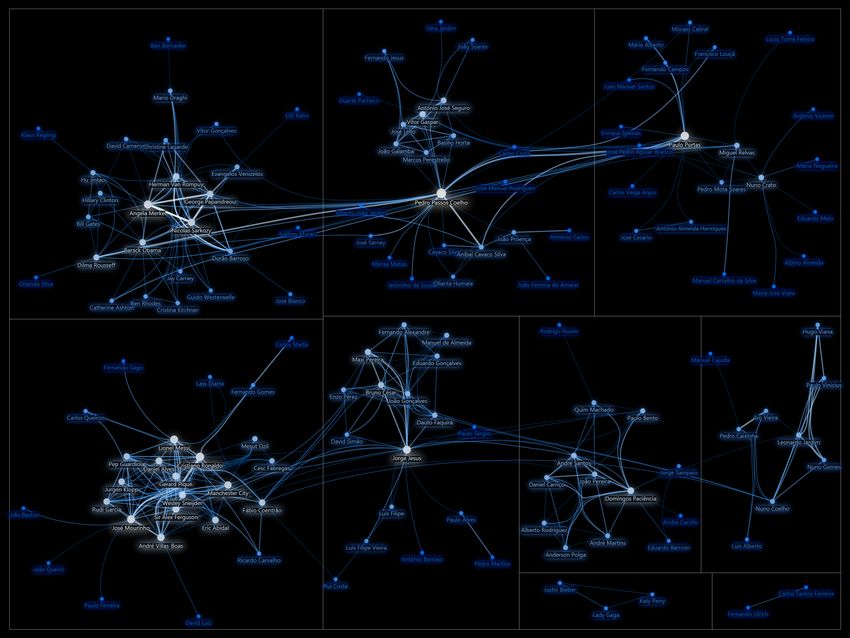
– Social
Graph:
the
list
of
en**es
with
which
it
occurs
– Counts
for
everything
on
a
daily
basis
– Context
informa*on
(tags
&
*tles
taken
from
news
items)
Sapo
Verbetes:
work
in
progress
• For
each
en*ty:
– Wikipedia
page
(and
info
from
Wikipedia
box)
– Photo
/
Logo
– TwiNer
account
– All
other
informa*on
we
may
require…
• Name
disambigua*on
– Currently
our
“key”
is
the
name
• For
most
cases,
ambiguity
is
not
as
severe
as
it
may
seem
• Only
a
few
really
problema*c
ambiguous
cases
How
are
we
building
Verbetes?
• Harvest
news
using
a
fully
automated
process
• We
mostly
exploit
a
recurrent
paNern
in
news:
– “Portuguese
Prime
Minister,
Passos
Coelho,
will
visit
the
United...”
And
many
possible
varia*ons….
• These
paNerns
are
very
frequent
in
news
sources
and
can
be
extracted
using
a
set
of
rela*vely
simple
heuris*cs
How
are
we
building
Verbetes?
(II)
• “Portuguese
Prime
Minister,
Passos
Coelho,
…”
• Rules
were
manually
developed
using:
– Simple
heuris*cs
for
finding
names
of
people
– Using
informa*on
contained
in
SSLists
• about
na*onali*es
• Jobs
/
ergonyms
• Result:
– Tuples
of
form
Can
we
rely
on
this
strategy?
• We
are
processing
thousand
of
news
per
day
• Good
tuples
tend
to
be
found
frequently
– Incorrect
tuples
tend
to
be
different
amongst
each
other:
“white
noise”
• They
do
not
add
up:
incorrect
tuples
have
low
counts
• Valida*on
by
“frequency
count”
Finding
Main
&
Alterna*ve
Names
• We
assume
that,
within
the
same
news
item,
names
are
not
ambiguous
– Awer
matching
an
extrac*on
paNern
and
finding
all
names
in
the
news
item,
we
can
match
them
using
a
simple
fuzzy
name
match:
•
“Portuguese
Prime
Minister,
Passos
Coelho,
…
bla
bla
…
Passos
Coelho
…
bla
bla
….
Pedro
Passo
Coelho
…bla
bla
Coelho
…
“
• From,
Passos
Coelho,
we
find:
– Longest
Name:
Pedro
Passo
Coelho
– Name
varia*on:
Passos
Coelho,
Coelho
Job
Descrip*ons
• Job
descrip*ons
have
many
varia*ons
– hNp://services.sapo.pt/Informa*onRetrieval/
Verbetes/WhoIs?name=Pedro%20Passos%20Coelho
• For
each
job
descrip*on
of
each
en*ty
we
keep:
– the
number
of
*mes
it
was
extracted
from
news
– date
of
the
first
and
of
last
extrac*on
– we
also
try
to
find
some
modifiers
• “ex”,
“former”,
...
• Some
work
is
being
done
in
automa*caly
learning
paraphrases
of
job
descrip*ons
“Social Network” of En**es
Verbetes as a Web-‐Service • Demo!
Lexical-‐Seman*c
Resources:
What’s
next?
• Lists:
– Automa*c
discovery
of
new
lists
• Not
just
expanding
– Find
rela*ons
between
elements
of
different
lists
• Using
simple
surface
paNerns
over
large
text
bases
• Using
search
log
informa*on:
– hNps://services.sapo.pt/Informa*onRetrieval/QueryProcessing/GetAffineQueries?
keyword=carros&limit=3&jsonText=true
• Map
elements
and
classes
to
other
resources
– PAPEL
(Wordnet-‐like
resource
for
Portuguese)
Lexical-‐Seman*c
Resources:
What’s
next?
(II)
• Verbetes:
– Extract
informa*on
about
other
types
of
en**es
• Organiza*ons
– Automa*c
detec*on
of
ambiguous
cases
– Detec*on
of
rela*on
between
en**es
• P
(works
for
company)
C
• P1
is
married
with
P2
– Link
references
to
other
repositories
• E.g.:
GeoNetPT,
Wikipedia
Seman*c
API’s:
4
flavors
• API
providing:
– Lexical-‐seman,c
Informa,on
• E.g.
lists
of
names,
lists
of
words
by
classes
– Elementary
Language
Processing
Opera*ons
• E.g.
Tokeniza*on,
Named-‐En*ty
Recogni*on
– Text
Classifica*on
Methods
• E.g.
topic
classifica*on
of
news
or
query
strings
– Access
to
Dis*lled
Informa*on
(DEMO)
• E.g.
quota*ons
extracted
from
news
You can also read

















































