"AUTOML FOR TINYML WITH ONCE-FOR-ALL NETWORK" - SONG HAN - MIT APRIL 28, 2020 - TINYML FOUNDATION
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

“AutoML for TinyML with Once-for-All Network”
Song Han – MIT
April 28, 2020
tinyML Talks Sponsors Additional Sponsorships available – contact Bette@tinyML.org for info

Next tinyML Talk
Next tinyML Talk
Date Date Presenter
Presenter
Topic / Title
Topic / Title
Thursday Hans
Thursday Reyserhove
Hans Reyserhove Embedded Computer
Embedded Computer Vision
Vision Hardware
Hardware
May 14
May 14 Postdoctoral
PostdoctoralResearch
Research through theEyes
through the Eyes
of of
an an
AR AR Glass
Glass
Scientist, Facebook
Scientist, FacebookReality
Reality
LabsLabs
Jamie Campbell
Jamie Campbell Using TensorFlow Lite for Microcontrollers
Using TensorFlow Lite for Microcontrollers
Software Engineering
Software Engineering for High-Efficiency NN Inference on Ultra-
for High-Efficiency NN Inference on Ultra-
Manager, Synopsys Low Power Processors
Manager, Synopsys Low Power Processors
Webcast start time is 8 am Pacific time
Webcast startis approximately
Each presentation time is 8 am Pacific
30 minutes time
in length
Each presentation is approximately 30 minutes in length
Please contact talks@tinyml.org if you are interested in presenting
Please contact talks@tinyml.org if you are interested in presenting
Song Han
Song Han is an assistant professor in MIT’s Department of
Electrical Engineering and Computer Science. His research
focuses on efficient deep learning computing. He has proposed
“deep compression” that can reduce neural network size by an
order of magnitude, and the hardware implementation “efficient
inference engine” that first exploited model compression and
weight sparsity in deep learning accelerators. He received a best
paper award at the ICLR’16 and FPGA’17. He is a recipient of NSF
CAREER Award and MIT Technology Review Innovators Under 35.
Many of the pruning, compression, and acceleration techniques
have been integrated into commercial AI chips. He was the co-
founder and chief scientist of DeePhi Tech that was acquired by
Xilinx. He earned a PhD in electrical engineering from Stanford
University.
AutoML for TinyML
with Once-for-All Network
Song Han
Massachusetts Institute of Technology
Once-for-All, ICLR’20
AutoML for TinyML
with Once-for-All Network
fewer engineers small model
many engineers less computation
large model
Less Engineer Resources: AutoML
Less Computational Resources: TinyML
A lot of computation
Once-for-All, ICLR’20
Our 1st generation solution
HAQ: Hardware-aware
DAC ’18, June 24–29, 2018, San Francisco, CA, USA Automated Quantization
Song Han and William J. Dally
Peaks: our RL agent automatically learns 1x1 convolutions
have less redundancy and can be pruned less.
[CVPR 2019], oral
Crests: our RL agent automatically learns 3x3 convolutions have
AMC: AutoML for Model Compression
more redundancy and can be pruned more.
Residual Block 1 Residual Block 2 Residual Block 3 Residual Block 4
[ECCV 2018]
Figure 14: The pruning policy (sparsity ratio) given by our reinforcement learning agent for ResNet-50.
50%
50% ResNet50 Density Pruned by Human Expert neural network. In Proceedings of the 43rd International Symposium on Computer
(#non-zero weights/ total #weights)
ResNet50 Density Pruned by AMC (the lower the better) Architecture. IEEE Press, 243–254.
43%
[9] Song Han, Huizi Mao, and William J Dally. 2015. Deep compression: Compressing
38%
deep neural networks with pruning, trained quantization and hu�man coding.
arXiv preprint arXiv:1510.00149 (2015).
31% 31%
[10] Song Han, Je� Pool, John Tran, and William Dally. 2015. Learning both weights
Density
30% 30% 29%
28% 28%
25%
and connections for e�cient neural network. In Advances in Neural Information
23%
20% 20%
Processing Systems. 1135–1143.
19%
[11] Yihui He and Song Han. 2018. AMC: Automated Model Compression and Accel-
13%
eration with Reinforcement Learning. arXiv preprint arXiv:1802.03494 (2018).
10% [12] Geo�rey Hinton, Oriol Vinyals, and Je� Dean. 2015. Distilling the knowledge in
a neural network. arXiv preprint arXiv:1503.02531 (2015).
0%
Conv1 ResBlock1 ResBlock2 ResBlock3 ResBlock4 FC Total
[13] Matthew B Johnson and Beth Stevens. 2018. Pruning hypothesis comes of age.
(2018).
Proxyless Neural Architecture Search Figure 15: Our reinforcement learning agent (AMC) can
prune the model to a lower density than achieved by human
[14] Norman P. Jouppi, Cli� Young, Nishant Patil, David Patterson, Gaurav Agrawal,
and et al. . 2017. In-Datacenter Performance Analysis of a Tensor Processing
Unit. In ISCA.
experts without loss of accuracy. (Human expert: 3.4⇥ com-
[ICLR 2019] pression on ResNet50. AMC : 5⇥ compression on ResNet50.)
[15] Alex Krizhevsky, Ilya Sutskever, and Geo�rey E Hinton. 2012. Imagenet classi�-
cation with deep convolutional neural networks. In NIPS.
[16] Mary Yvonne Lanzerotti, Giovanni Fiorenza, and Rick A Rand. 2005. Micro-
5 CONCLUSION miniature packaging and integrated circuitry: The work of EF Rent, with an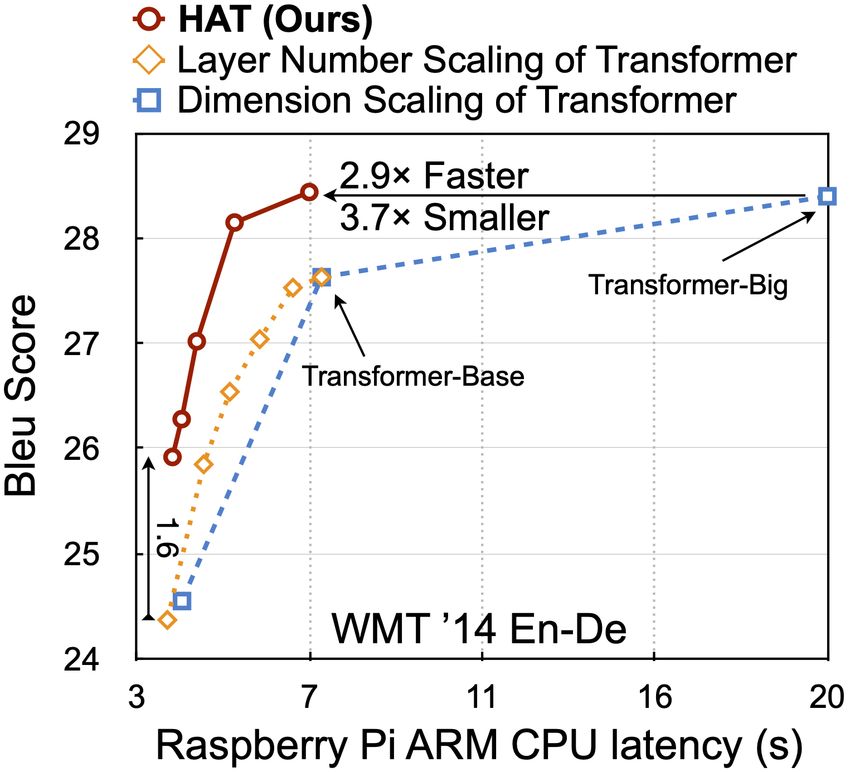
Challenge: Efficient Inference on Diverse Hardware Platforms
Cloud AI Mobile AI Tiny AI (AIoT)
less less
resource resource
• Memory: 32GB • Memory: 4GB • Memory: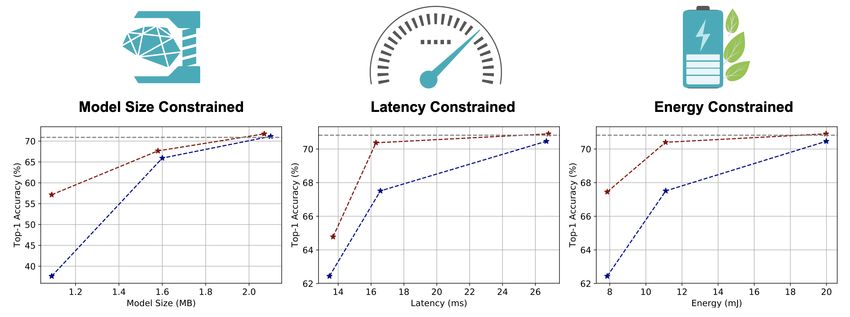
Challenge: Efficient Inference on Diverse Hardware Platforms
Design Cost (GPU hours)
200
for training iterations:
forward-backward();
The design cost is calculated under the assumption of using MobileNet-v2.
10
Challenge: Efficient Inference on Diverse Hardware Platforms
Design Cost (GPU hours)
(1)for search episodes: //meta controller 40K
for training iterations:
expensive!
forward-backward();
if good_model: break;
for post-search training iterations: expensive!
forward-backward();
The design cost is calculated under the assumption of using MnasNet.
Once-for-All, ICLR’20
[1] Tan, Mingxing, et al. "Mnasnet: Platform-aware neural architecture search for mobile." CVPR. 2019. 11Challenge: Efficient Inference on Diverse Hardware Platforms
Diverse Hardware Platforms
2019 2017 2015 2013
(2)
for devices: Design Cost (GPU hours)
(1)for search episodes: //meta controller 40K
for training iterations:
expensive! 160K
forward-backward();
if good_model: break;
for post-search training iterations: expensive!
forward-backward();
The design cost is calculated under the assumption of using MnasNet.
Once-for-All, ICLR’20
[1] Tan, Mingxing, et al. "Mnasnet: Platform-aware neural architecture search for mobile." CVPR. 2019. 12Challenge: Efficient Inference on Diverse Hardware Platforms
Diverse Hardware Platforms
…
12 9 6
Cloud AI (10 FLOPS) Mobile AI (10 FLOPS) Tiny AI (10 FLOPS)
(2)
for many devices: Design Cost (GPU hours)
(1)for search episodes: //meta controller 40K
for training iterations:
expensive! 160K
forward-backward();
if good_model: break; 1600K
for post-search training iterations: expensive!
forward-backward();
The design cost is calculated under the assumption of using MnasNet.
Once-for-All, ICLR’20
[1] Tan, Mingxing, et al. "Mnasnet: Platform-aware neural architecture search for mobile." CVPR. 2019. 13Challenge: Efficient Inference on Diverse Hardware Platforms
Diverse Hardware Platforms
…
12 9 6
Cloud AI (10 FLOPS) Mobile AI (10 FLOPS) Tiny AI (10 FLOPS)
(2)
for many devices: Design Cost (GPU hours)
(1)for search episodes: //meta controller 40K → 11.4k lbs CO2 emission
for training iterations:
expensive! 160K → 45.4k lbs CO2 emission
forward-backward();
if good_model: break; 1600K → 454.4k lbs CO2 emission
for post-search training iterations: expensive!
forward-backward();
1 GPU hour translates to 0.284 lbs CO2 emission according to
Once-for-All, ICLR’20
Strubell, Emma, et al. "Energy and policy considerations for deep learning in NLP." ACL. 2019. 14Problem:
TinyML comes at the cost of BigML
(inference) (training/search)
We need Green AI:
Solve the Environmental Problem of NAS
Evolved Transformer ICML’19, ACL’19
Ours 52 4 orders of magnitude ACL’20
Hardware-Aware TransformerOur new solution, OFA: Decouple Training and Search
Conventional NAS Once-for-All:
(2)for devices: for OFA training iterations:
forward-backward(); training
(1) for search episodes:
decouple
for training iterations: => for devices:
forward-backward(); for search episodes:
search
if good_model: break; sample from OFA;
for post-search training iterations: if good_model: break;
forward-backward(); direct deploy without training;
Once-for-All, ICLR’20 16Challenge: Efficient Inference on Diverse Hardware
Platforms
Diverse Hardware Platforms
…
12 9 6
Cloud AI (10 FLOPS) Mobile AI (10 FLOPS) Tiny AI (10 FLOPS)
for OFA training iterations: Design Cost (GPU hours)
forward-backward(); training
40K → 11.4k lbs CO2 emission
decouple
for devices:
search 160K → 45.4k lbs CO2 emission
for search episodes:
sample from OFA; 1600K → 454.4k lbs CO2 emission
if good_model: break;
direct deploy without training; Once-for-All Network
1 GPU hour translates to 0.284 lbs CO2 emission according to
Once-for-All, ICLR’20
Strubell, Emma, et al. "Energy and policy considerations for deep learning in NLP." ACL. 2019. 17Once-for-All Network:
Decouple Model Training and Architecture Design
once-for-all network
Once-for-All, ICLR’20 18Once-for-All Network:
Decouple Model Training and Architecture Design
once-for-all network
Once-for-All, ICLR’20 19Once-for-All Network:
Decouple Model Training and Architecture Design
once-for-all network
Once-for-All, ICLR’20 20Once-for-All Network:
Decouple Model Training and Architecture Design
once-for-all network
…
Once-for-All, ICLR’20 21Challenge: how to prevent different subnetworks
from interfering with each other?
Once-for-All, ICLR’20 22Solution: Progressive Shrinking
19
• More than 10 different sub-networks in a single once-for-all network, covering
4 different dimensions: resolution, kernel size, depth, width.
• Directly optimizing the once-for-all network from scratch is much more challenging
than training a normal neural network given so many sub-networks to support.
Once-for-All, ICLR’20 23Solution: Progressive Shrinking
19
• More than 10 different sub-networks in a single once-for-all network, covering
4 different dimensions: resolution, kernel size, depth, width.
• Directly optimizing the once-for-all network from scratch is much more challenging
than training a normal neural network given so many sub-networks to support.
Progressive Shrinking
Jointly fine-tune
Train the Shrink the model once-for-all
both large and
full model (4 dimensions) network
small sub-networks
• Small sub-networks are nested in large sub-networks.
• Cast the training process of the once-for-all network as a progressive shrinking and
joint fine-tuning process.
Once-for-All, ICLR’20 24Connection to Network Pruning
Network Pruning
Train the Shrink the model Fine-tune single pruned
full model (only width) the small net network
Progressive Shrinking
Fine-tune
Train the Shrink the model once-for-all
both large and
full model (4 dimensions) network
small sub-nets
• Progressive shrinking can be viewed as a generalized network pruning with much
higher flexibility across 4 dimensions.
Once-for-All, ICLR’20 25Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial
Randomly sample input image
size for each batch
Once-for-All, ICLR’20 26Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial
Randomly sample input image
size for each batch
Once-for-All, ICLR’20 27Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial
Randomly sample input image
size for each batch
Once-for-All, ICLR’20 28Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial
Randomly sample input image
size for each batch
Once-for-All, ICLR’20 29Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial
Randomly sample input image
size for each batch
Once-for-All, ICLR’20 30Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial
Randomly sample input image
size for each batch
Once-for-All, ICLR’20 31Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial
7x7
5x5
3x3
Transform Transform
Matrix Matrix
25x25 9x9
Start with full kernel size
Smaller kernel takes centered weights via a transformation matrix
Once-for-All, ICLR’20 32Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial
7x7
5x5
3x3
Transform Transform
Matrix Matrix
25x25 9x9
Start with full kernel size
Smaller kernel takes centered weights via a transformation matrix
Once-for-All, ICLR’20 33Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial
7x7
5x5
3x3
Transform Transform
Matrix Matrix
25x25 9x9
Start with full kernel size
Smaller kernel takes centered weights via a transformation matrix
Once-for-All, ICLR’20 34Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial
7x7
5x5
3x3
Transform Transform
Matrix Matrix
25x25 9x9
Start with full kernel size
Smaller kernel takes centered weights via a transformation matrix
Once-for-All, ICLR’20 35Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial
7x7
5x5
3x3
Transform Transform
Matrix Matrix
25x25 9x9
Start with full kernel size
Smaller kernel takes centered weights via a transformation matrix
Once-for-All, ICLR’20 36Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial
7x7
5x5
3x3
Transform Transform
Matrix Matrix
25x25 9x9
Start with full kernel size
Smaller kernel takes centered weights via a transformation matrix
Once-for-All, ICLR’20 37Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial
O1
unit i unit i unit i
O1
O2
O2
O3
train with full depth shrink the depth shrink the depth
Gradually allow later layers in each unit
to be skipped to reduce the depth
Once-for-All, ICLR’20 38Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial
O1
unit i unit i unit i
O1
O2
O2
O3
train with full depth shrink the depth shrink the depth
Gradually allow later layers in each unit
to be skipped to reduce the depth
Once-for-All, ICLR’20 39Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial
O1
unit i unit i unit i
O1
O2
O2
O3
train with full depth shrink the depth shrink the depth
Gradually allow later layers in each unit
to be skipped to reduce the depth
Once-for-All, ICLR’20 40Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial
O1
unit i unit i unit i
O1
O2
O2
O3
train with full depth shrink the depth shrink the depth
Gradually allow later layers in each unit
to be skipped to reduce the depth
Once-for-All, ICLR’20 41Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial
O1
unit i unit i unit i
O1
O2
O2
O3
train with full depth shrink the depth shrink the depth
Gradually allow later layers in each unit
to be skipped to reduce the depth
Once-for-All, ICLR’20 42Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial
O1
unit i unit i unit i
O1
O2
O2
O3
train with full depth shrink the depth shrink the depth
Gradually allow later layers in each unit
to be skipped to reduce the depth
Once-for-All, ICLR’20 43Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial Partial
channel channel
importance importance
0.02 0.82
channel reorg.
channel 0.15 reorg. 0.11
sorting
sorting 0.85 0.46 O3
O2
0.63 O2
O1 O1
O1
train with full width progressively shrink the width progressively shrink the width
Gradually shrink the width
Keep the most important channels when shrinking via channel sorting
Once-for-All, ICLR’20 44Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial Partial
channel channel
importance importance
0.02 0.82
channel reorg.
channel 0.15 reorg. 0.11
sorting
sorting 0.85 0.46 O3
O2
0.63 O2
O1 O1
O1
train with full width progressively shrink the width progressively shrink the width
Gradually shrink the width
Keep the most important channels when shrinking via channel sorting
Once-for-All, ICLR’20 45Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial Partial
channel channel
importance importance
0.02 0.82
channel reorg.
channel 0.15 reorg. 0.11
sorting
sorting 0.85 0.46 O3
O2
0.63 O2
O1 O1
O1
train with full width progressively shrink the width progressively shrink the width
Gradually shrink the width
Keep the most important channels when shrinking via channel sorting
Once-for-All, ICLR’20 46Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial Partial
channel channel
importance importance
0.02 0.82
channel reorg.
channel 0.15 reorg. 0.11
sorting
sorting 0.85 0.46 O3
O2
0.63 O2
O1 O1
O1
train with full width progressively shrink the width progressively shrink the width
Gradually shrink the width
Keep the most important channels when shrinking via channel sorting
Once-for-All, ICLR’20 47Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial Partial
channel channel
importance importance
0.02 0.82
channel reorg.
channel 0.15 reorg. 0.11
sorting
sorting 0.85 0.46 O3
O2
0.63 O2
O1 O1
O1
train with full width progressively shrink the width progressively shrink the width
Gradually shrink the width
Keep the most important channels when shrinking via channel sorting
Once-for-All, ICLR’20 48Progressive Shrinking
Full Elastic Full Elastic Full Elastic Full Elastic
Resolution Kernel Size Depth Width
Partial Partial Partial Partial
channel channel
importance importance
0.02 0.82
channel reorg.
channel 0.15 reorg. 0.11
sorting
sorting 0.85 0.46 O3
O2
0.63 O2
O1 O1
O1
train with full width progressively shrink the width progressively shrink the width
Gradually shrink the width
Keep the most important channels when shrinking via channel sorting
Once-for-All, ICLR’20 49progressively shrink the width
Progressive Shrinking
put it
Published as a conference paper at ICLR 2020 together:
D [4, 3, 2] W [6, 4, 3]
K [7, 5, 3] D [4, 3] W [6, 4]
Sample D at each Channel sorting
Sample D at each Channel sorting
Sample K at each layer
unit; sample K (Fig. 4)
Skip top (4-D) Sample E at each
Generate kernel Keep the first D layers Sample W at each Once-
Train full
weights (Fig. 3) at each unit (Fig. 3) layer; sample K, D for-all
network Network
Fine-tune weights Fine-tune weights
K=7 Fine-tune weights &
Fine-tune weights Fine-tune weights
Elastic Resolution D = 4 transformation matrix
R [128, 132, …, 224] W = 6 Elastic Kernel Size Elastic Depth Elastic Width
D = 4, W = 6 W = 6, K [7, 5, 3] D [4, 3, 2], K [7, 5, 3]
Figure 2: Illustration of the progressive shrinking process to support different depth D, width W ,
kernel size K and resolution R. It leads to a large space comprising diverse sub-networks (> 1019 ).
sequence of layers where only the first layer has stride 2 if the feature map size decreases (Sandler
Once-for-All, ICLR’20 50Performances of Sub-networks on ImageNet
w/o PS w/ PS
78
ImageNet Top-1 Acc (%)
75 3.5%
3.7%
3.4%
3.4% 3.3%
73 3.5%
2.8%
70
2.5%
67
D=2 D=2 D=2 D=2 D=4 D=4 D=4 D=4
W=3 W=3 W=6 W=6 W=3 W=3 W=6 W=6
K=3 K=7 K=3 K=7 K=3 K=7 K=3 K=7
Sub-networks under various architecture configurations
D: depth, W: width, K: kernel size
• Progressive shrinking consistently improves accuracy of sub-networks on ImageNet.
Once-for-All, ICLR’20 51How about search?
for OFA training iterations:
training forward-backward();
decouple
for devices:
search for search episodes:
sample from OFA; //with evolution
if good_model: break;
direct deploy without training;
Once-for-All, ICLR’20 52How to evaluate if good_model? — by Model Twin
Accuracy/Latency predictor
RMSE ~0.2%
OFA Acc Dataset
Network [Architecture, Accuracy]
Accuracy
Prediction Model Predictor-based
Architecture Search Specialized
Sub-Network
Latency
Prediction Model
Latency Dataset
[Architecture, Latency]
Once-for-All, ICLR’20 532.6x faster than EfficientNet, 1.5x faster than MobileNetV3
OFA OFA
EfficientNet MobileNetV3
81 77
76.4
80.1 2.6x faster
80 75 74.9
79.8
Top-1 ImageNet Acc (%)
Top-1 ImageNet Acc (%)
75.2
79.8
73.3
79 73 73.3
78.7 1.5x faster
78.8 71.4
78 71
. 8 % h i g h e r 70.4
3
accuracy 4% higher
77 69 accuracy
76.3 67.4
76 67
0 50 100 150 200 250 300 350 400 18 24 30 36 42 48 54 60
Google Pixel1 Latency (ms) Google Pixel1 Latency (ms)
• Training from scratch cannot achieve the same level of accuracy
Once-for-All, ICLR’20 54More accurate than training from scratch
OFA OFA
EfficientNet MobileNetV3
OFA - Train from scratch OFA - Train from scatch
81 77
76.4
80.1 2.6x faster
80 75 74.9
79.8
Top-1 ImageNet Acc (%)
Top-1 ImageNet Acc (%)
75.2
79.8
73.3
79 73 73.3
78.7 1.5x faster
78.8 71.4
78 71
. 8 % h i g h e r 70.4
3
accuracy 4% higher
77 69 accuracy
76.3 67.4
76 67
0 50 100 150 200 250 300 350 400 18 24 30 36 42 48 54 60
Google Pixel1 Latency (ms) Google Pixel1 Latency (ms)
• Training from scratch cannot achieve the same level of accuracy
Once-for-All, ICLR’20 55OFA: 80% Top-1 Accuracy on ImageNet
81
14x less computation
595M MACs Xception
Once-for-All (ours) InceptionV3
80.0% Top-1
79 EfficientNet ResNetXt-50
NASNet-A
DPN-92
ImageNet Top-1 accuracy (%)
MBNetV3 DenseNet-169 ResNetXt-101
77
ProxylessNAS DenseNet-264
AmoebaNet DenseNet-121
75
MBNetV2 ResNet-101
PNASNet ResNet-50
ShuffleNet InceptionV2
73 DARTS 2M 4M 8M 16M 32M 64M
IGCV3-D
Model Size The higher the better
→
71
69
0
MobileNetV1 (MBNetV1)
1 2 3 4
Handcrafted
5
AutoML
6
The lower the better
7
→8 9
MACs (Billion)
• Once-for-all sets a new state-of-the-art 80% ImageNet top-1 accuracy under
the mobile vision setting (< 600M MACs).
Once-for-All, ICLR’20 56OFA Enables Fast Specialization on Diverse Hardware Platforms
OFA MobileNetV3 MobileNetV2
77 77 77
76.3 76.4
75.8
Top-1 ImageNet Acc (%)
74.7 74.7 74.7
75 75 75
75.2 75.2 75.2
73.1 73.4 73.0
73 73.3 73 73.3 73 73.3
71.5
70.5 71.1
71 71 71
70.4 70.4 70.4
69 69 69
67.4 67.4 67.4
67 67 67
25 40 55 70 85 100 23 28 33 38 43 48 53 58 63 68 7 10 13 16 19 22 25
Samsung S7 Edge Latency (ms) Google Pixel2 Latency (ms) LG G8 Latency (ms)
77 76.4 77 77
75.3 75.7
73.8 74.6 73.7
Top-1 ImageNet Acc (%)
73 72.6 73 73 72.8
72.0
71.1
72.0 72.0 69.6 71.5
69 69.8 69 69.8 69
67.0 69.0
66 65.4 66 65.4 66
63.3
62 62 62
60.3 60.3
58 58 59.1
58
10 14 18 22 26 30 9 11 13 15 17 19 3.0 4.0 5.0 6.0 7.0 8.0
NVIDIA 1080Ti Latency (ms) Intel Xeon CPU Latency (ms) Xilinx ZU3EG FPGA Latency (ms)
Batch Size = 64 Batch Size = 1 Batch Size = 1 (Quantized)
Once-for-All, ICLR’20 57We need Green AI
Solve the Environmental Problem of NAS
Evolved TransformerHow to save CO2 emission
1. Once for all: Amortize the search cost 2. Lite-transformer: Human-in-the-loop
across many sub-networks and design. Apply human insights of HW&ML,
deployment scenarios rather than “just search it”
Once-for-All, ICLR’20 Lite Transformer, ICLR’20OFA has broad applications • Efficient Transformer • Efficient Video Recognition • Efficient 3D Vision • Efficient GAN Compression
OFA’s Application: Hardware-Aware Transformer
American Life 36156
US car including 126000
fuel
Evolved 626155
Efficient NLP on mobile devices
Transformer
enable real time conversation
HAT (Ours)
between speakers using6000
different
languages
“Nice to meet you” “Encantada de conocerte”
“만나서 반갑습니다”
ACL 2020 Submission ***. Confidential Review Copy. DO NOT DISTRIBUTE.
“ ”
“Freut mich, dich kennenzulernen”
00 Human Life 750
(Avg. 1 year)
11,023 BLEU Model Size Reduction
01 American Life 751
(Avg. 1 year)
36,156 Transformer Float32 41.2 705MB –
02 HAT Float32 41.8 227MB 3⇥ 752
US Car w/ Fuel
126,000
03 (Avg. 1 lifetime) HAT 8 bits 41.9 57MB 12⇥ 753
04 Evolved 626,155 HAT 4 bits 41.1 28MB 25⇥ 754
Transformer
05 12041× 755
HAT (Ours) 52
Table 5: K-means quantization of HAT models on
06 0 175K 350K 525K 700K 756
WMT’14 En-Fr. 4-bit quantization reduces model size
07 CO2 Emission (lbs) 757
by 25⇥ with only 0.1 BLEU loss than transformer base-
08 758
Figure 9: The design cost 3.7x smaller
measured in model size, line.
pounds of same 8-bit quantization even
performance increases BLEU
on WMT’14 En-De;by 0.1
09 CO2 emission. Our 3x,framework for searching
1.6x, 1.5x faster on HAT re-
Raspberrythan its
Pi,float
CPU,version.
GPU than Transformer Baseline 759
10 duces the search cost by four orders of magnitude than
12,000x less CO 2 than evolved transformer 760
Evolved Transformer (So et al., 2019).
settings for NLP tasks and proposed a multi-branch
11 761
mobile Transformer. However, it relied on FLOPs
HAT, ACL’20OFA’s Application: Efficient Video Recognition
75
OFA + TSM (large) ResNet50 + TSM
Kinetics Top-1 Accuracy (%)
Same Acc.
74
7x less computation
73 ResNet50 + I3D
OFA + TSM (small)
72
Same Comp.
71 +3.0% Acc.
70
MobileNetV2 + TSM
69
0 10 20 30 40
Computation (GFLOPs)
7x less computation, same performance as TSM+ResNet50
same computation, 3% higher accuracy than TSM+MobileNet-v2
TSM, ICCV’19OFA’s Application: Efficient 3D Recognition
AR/VR: a whole backpack
of computer
Accuracy v.s. Latency Tradeoff
self-driving: a whole trunk of GPU
4x FLOPs reduction and 2x speedup over MinkowskiNet
3.6% better accuracy under the same computation budget.
followup of PVCNN, NeurIPS’19 (spotlight)OFA’s Application: GAN Compression
8-21x FLOPs reduction on CycleGAN, Pix2pix, GauGAN
1.7x-18.5x speedup on CPU/GPU & Mobile CPU/GPU
GAN Compression, CVPR’20 64Summary: Once-for-All Network
• We introduce once-for-all network for efficient inference on diverse hardware platforms.
• We present an effective progressive shrinking approach for training once-for-all networks.
Progressive Shrinking
Fine-tune
Train the Shrink the model once-for-all
both large and
full model In 4 dimensions network
small sub-nets
• Once-for-all network surpasses MobileNetV3 and EfficientNet by a large margin under all scenarios,
setting a new state-of-the-art 80% ImageNet Top1-accuracy under the mobile setting (< 600M MACs).
• First place in the 3rd Low-Power Computer Vision Challenge, DSP track @ICCV’19
• First place in the 4th Low-Power Computer Vision Challenge @NeurIPS’19, both classification & detection.
• Released 50+ different pre-trained OFA models on diverse hardware platforms (CPU/GPU/FPGA/DSP).
net, image_size = ofa_specialized(net_id, pretrained=True)
• Released the training code & pre-trained OFA network that provides diverse sub-networks without training.
ofa_network = ofa_net(net_id, pretrained=True)
Project Page: https://ofa.mit.eduReferences
Model Compression & NAS
- Once-For-All: Train One Network and Specialize It for Efficient Deployment, ICLR’20
- ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware, ICLR’19
- APQ: Joint Search for Network Architecture, Pruning and Quantization Policy, CVPR’20
- HAQ: Hardware-Aware Automated Quantization with Mixed Precision, CVPR’19
- Defensive Quantization: When Efficiency Meets Robustness, ICLR’19
- AMC: AutoML for Model Compression and Acceleration on Mobile Devices, ECCV’18
Efficient Vision:
- GAN Compression: Learning Efficient Architectures for Conditional GANs, CVPR’20
- TSM: Temporal Shift Module for Efficient Video Understanding, ICCV’19
- PVCNN: Point Voxel CNN for Efficient 3D Deep Learning, NeurIPS’19
Efficient NLP:
- Lite Transformer with Long Short Term Attention, ICLR’20
- HAT: Hardware-aware Transformer, ACL’20
Hardware & EDA:
- SpArch: Efficient Architecture for Sparse Matrix Multiplication, HPCA’20
- Transferable Transistor Sizing with Graph Neural Networks and Reinforcement Learning, DAC’20
66Make AI Efficient: Tiny Computational Resources Tiny Human Resources Media Coverage: Website: songhan.mit.edu github.com/mit-han-lab youtube.com/c/MITHANLab
Diverse Hardware Platforms, 50+ Pretriained Models are Released
Once-for-All, ICLR’20 68OFA for FPGA Accelerators
MobileNetV2 MnasNet OFA (Ours)
50.0 80.0
Arithmetic Intensity (OPS/Byte)
40%
ZU3EG FPGA (GOPS/s)
higher 57%
37.5 60.0
higher
25.0 40.0
12.5 20.0
0.0 0.0
Measured results on FPGA
• Non-specialized neural networks do not fully utilize the hardware resource. There is a large room for
improvement via neural network specialization.
Once-for-All, ICLR’20Copyright Notice
This presentation in this publication was presented as a tinyML® Talks webcast. The content reflects the
opinion of the author(s) and their respective companies. The inclusion of presentations in this
publication does not constitute an endorsement by tinyML Foundation or the sponsors.
There is no copyright protection claimed by this publication. However, each presentation is the work of
the authors and their respective companies and may contain copyrighted material. As such, it is strongly
encouraged that any use reflect proper acknowledgement to the appropriate source. Any questions
regarding the use of any materials presented should be directed to the author(s) or their companies.
tinyML is a registered trademark of the tinyML Foundation.
www.tinyML.orgCopyright Notice
This presentation in this publication was presented as a tinyML® Talks webcast. The content reflects the
opinion of the author(s) and their respective companies. The inclusion of presentations in this
publication does not constitute an endorsement by tinyML Foundation or the sponsors.
There is no copyright protection claimed by this publication. However, each presentation is the work of
the authors and their respective companies and may contain copyrighted material. As such, it is strongly
encouraged that any use reflect proper acknowledgement to the appropriate source. Any questions
regarding the use of any materials presented should be directed to the author(s) or their companies.
tinyML is a registered trademark of the tinyML Foundation.
www.tinyML.orgYou can also read

















































