CORONAVIRUS-RELATED SENTIMENT AND STOCK PRICES - DIVA
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

DEGREE PROJECT IN FINANCE PROGRAM: REAL ESTATE AND FINANCE FIRST CYCLE, 15 CREDITS STOCKHOLM, SWEDEN 2020 Coronavirus-Related Sentiment and Stock Prices Measuring Sentiment Effects on Swedish Stock Indices Olga Piksina Patricia Vernholmen KTH INSTITUTIONEN FÖR FASTIGHETER OCH BYGGANDE 1
Bachelor of Science Thesis Title: Coronavirus-Related Sentiment and Stock Prices: Measuring Sentiment Effects on Swedish Stock Indices Authors: Olga Piksina, Patricia Vernholmen Institution: Institution of Real Estate and Construction Management Bachelor Thesis number: TRITA-ABE-MBT-20482 Archive number: Supervisor: Andreas Fili Keywords: market sentiment, behavioural finance, market efficiency, coronavirus, Swedish stock market, text analytics, sentiment analysis, news mining Abstract This thesis examines the effect of coronavirus-related sentiment on Swedish stock market returns during the coronavirus pandemic. We study returns on the large cap and small cap price indices OMXSLCPI and OMXSSCPI during the period January 2, 2020 – April 30, 2020. Coronavirus sentiment proxies are constructed from news articles clustered into topics using latent Dirichlet allocation and scored through sentiment analysis. The impact of the sentiment proxies on the stock indices is then measured using a dynamic multiple regression model. The results show that the proxies representing fundamental changes in our model — Swedish Politics and Economic Policy — have a strongly significant impact on the returns of both indices, which is consistent with financial theory. We also find that sentiment proxies Sport and Coronavirus Spread are statistically significant and impact Swedish stock prices. This implies that coronavirus-related news influenced market sentiment in Sweden during the research period and could be exploited to uncover arbitrage. Finally, the amount of sentiment-inducing news published daily is shown to have an impact on stock price volatility. 2
Examensarbete kandidatnivå Titel: Coronavirus-relaterat sentiment och aktiepriser: En studie av sentimenteffekter på svenska aktieindex Författare: Olga Piksina, Patricia Vernholmen Institution: Fastigheter och Byggande Examensarbete kandidatnivå nummer: TRITA-ABE-MBT-20482 Arkiv nummer: Handledare: Andreas Fili Nyckelord: marknadssentiment, beteendefinans, marknadseffektivitet, coronaviruset, svensk aktiemarknad, textanalys, sentimentanalys, news mining Sammanfattning Denna studie undersöker den effekt coronavirus-relaterat sentiment haft på avkastningen på svenska aktieindex under coronaviruspandemin. Vi studerar avkastningen på large cap- och small cap-prisindexen OMXSLCPI och OMXSSCPI under perioden 2 januari 2020 – 30 april 2020. Proxier för coronavirus- sentiment konstrueras från nyhetsartiklar som klustrats i ämnen genom latent Dirichlet-allokering och poängsatts genom sentimentanalys. Sentimentproxiernas påverkan på aktieindexen mäts sedan med en dynamisk multipel regressionsmodell. Resultaten visar att proxierna som representerar fundamentala förändringar i vår modell — svensk politik och ekonomisk policy — har en starkt signifikant inverkan på avkastningen på båda indexen, vilket är konsekvent med finansiell teori. Vi finner även att sentimentproxierna sport och spridning av coronaviruset är statistiskt signifikanta i sin påverkan på svenska aktiepriser. Detta innebär att coronavirus-relaterade nyheter påverkade marknadssentiment i Sverige under undersökningsperioden och skulle kunna användas för att upptäcka arbitrage. Slutligen visas mängden sentimentframkallande nyheter publicerade per dag ha en inverkan på aktieprisvolatilitet. 3
Acknowledgements We would like to extend our genuine gratitude to our supervisor, Dr. Andreas Fili, whose guidance and support made this work possible. We wish to express our sincere thanks to Dr. Bertram Steininger for sharing meaningful insights into text analytics and recent research in the field. We would also like to thank Dr. Olga Rud for her recommendations on the material used for this study. Our special thanks goes to Stephen Rosewarne who kindly agreed to proofread this thesis. Furthermore, we are thankful to our family members and friends Christoffer Linné, Marina and Laura Vernholmen, Manne Svensson, Helene Törnqvist and Leo P. Thank you all for your unwavering support and inspiration. 4

Table of Contents 1. INTRODUCTION 8 1.1 Research Purpose and Questions 8 1.2 Contribution to the Field 10 1.3 Disposition 10 2. REVIEW OF THE LITERATURE 10 2.1 Fundamental Analysis vs. Technical Analysis 10 2.2 Efficient Market Hypothesis 11 2.3 Behavioural Finance 12 2.4 Event Studies and EMH 16 2.5 Text Analytics in Finance 16 2.5.1. Sentiment Analysis through Computational Linguistics 17 3. METHOD AND MATERIALS 18 3.1 Description 18 3.2 Limitations 19 3.3 Stock Indices 20 3.4 News 20 3.4.1 Collection 20 3.4.2 Preprocessing Textual Data 21 3.4.3 Topic Modelling and Scoring 21 3.4.4 Sentiment Proxies 23 3.4.5 Sentiment Analysis 26 3.4.6 Allocation of News to Dates 27 3.5 Economic Indicators 27 3.6 Multiple Regression 27 3.6.1 Model Specification 27 4. RESULTS 28 4.1 Autocorrelation Analysis 28 4.2 Cross-Correlation Matrices 29 4.3 Specified Regression Model 30 4.3.1 Variance Inflation Factors 30 5
4.4 Regression Outputs 30 4.5 Market Volatility and Coronavirus-Related News 32 5. ANALYSIS 32 5.1 Sustainability Aspects 34 5.2 Further Research 35 6. CONCLUSION 35 REFERENCES 37 6
Terminology list OMXSLCPI Price index of all Large Cap companies listed on Stockholm Stock Exchange (Market value of 1 billion euro or more. Nasdaq, 2020). OMXSSCPI Price index of all Small Cap companies listed on Stockholm Stock Exchange (Market value below 150 million euro. Nasdaq, 2020). Market Sentiment “[...] a belief about future cash flows and investment risks that is not justified by the facts at hand” (Baker and Wurgler, 2007). Market value of an asset = fundamental value + sentiment value. Proxy A proxy is “a variable used instead of the variable of interest when that variable of interest cannot be measured directly” (Oxford University Press, 2009). Proxies used in this study fall into two mutually exclusive categories: 1. Fundamental proxies, representing news which can cause fundamental change to asset values, and 2. Sentiment proxies, which reflect investor sentiment. Proxies belonging to one category have no influence on the other. Web Scraping Automated gathering of data from the internet through any means other than a program interacting with an API (Mitchell, 2018). Latent Dirichlet Allocation Unsupervised machine learning algorithm used to cluster previously (LDA) unlabelled text data according to topics (method known as topic modelling). It finds the most common words appearing in the text and clusters them, thus uncovering themes in text (see Blei, Ng and Jordan, 2003). Text Analytics “[...] large-scale, automated processing of plain text language in digital form to extract data that is converted into useful quantitative or qualitative information” (Das, 2014). Corpus Collection of text documents which can be readily processed in an automated way. Tokenisation Part of data preprocessing identifying basic units, known as tokens, in text corpora. Some methods tokenise by words or entities delimited by blank spaces while others make tokens of more complex entities such as idioms or expressions (Webster and Kit, 1992). 7
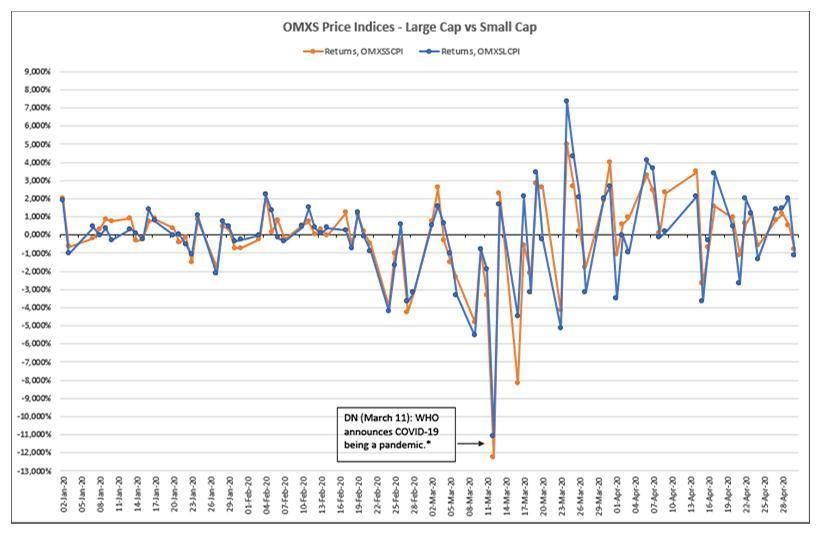
1. Introduction On the 11th of March, 2020, the World Health Organisation (WHO) declared the novel coronavirus disease 2019 (COVID-19) outbreak a global pandemic. The outbreak originated in Wuhan, China in December 2019 and has since spread throughout the entire world. In addition to a serious health emergency, the spread of the disease in the majority of the world’s countries has led to a deep economic crisis predicted by many to become a recession similar to the Great Depression. Stock markets all over the globe have reacted with varying degrees of panic, and widespread future uncertainty has resulted in two of the largest single day drops in the Dow Jones Industrial Average. The Swedish stock market has also experienced days of historic decline (see Figure 1). At the time of writing, the pandemic is ongoing and there is no clear outlook on how it is going to develop or when it will end. The coronavirus outbreak has also been remarkable due to its receiving unprecedented, near total media coverage across the globe. With a huge part of the world’s population being isolated or confined to their homes, the current pandemic has become a unique event with news rapidly spreading around the world. Information on the spread of the coronavirus and measures taken by governments in response to the crisis have alternated with news of skyrocketing unemployment rates, industries at risk of collapse, and the total economic impact of the pandemic on the global community. Our primary hypothesis is that non-economic news has made a significant impact on how investors on the Swedish stock market have valued assets during the pandemic. We assume movement on the market is influenced by blanket media coverage of the pandemic as well as various measures the Swedish government and central bank have introduced in response to the crisis. Our hypothesis has its basis in the theory of behavioural finance that indicates investors’ mood, fear and emotions impact the decision making process (Kahneman and Tversky, 1979; Statman, 1995; Shleifer and Vishny, 1997; Donadelli, Kizys and Riedel, 2017; Bukovina, 2016). 1.1 Research Purpose and Questions In this paper, our aim is to analyse how coronavirus-related news has impacted the stock market in Sweden during the period January 2, 2020 – April 30, 2020, when several European countries and the United States became epicentres of the COVID-19 pandemic. 8
This study aims to address the following questions: 1. Did coronavirus-related news in Sweden generate sentiment that could be observed on the Swedish stock market? 2. Which type(s) of news had the greatest impact on stock returns? 3. Is it possible to use sentiment proxies extracted from coronavirus-related news to make profitable investments? Figure 1: Source: NASDAQ Nordic, http://www.nasdaqomxnordic.com/ * News of the coronavirus outbreak was first reported in the media after 17:00 CET on the evening of 11th March, 2020. The arrow points to the following day (12th March) because these first news reports could not impact stock prices on the day of the announcement. 9
1.2 Contribution to the Field Sentiment analysis is a relatively new method of studying financial markets. The emerging field of behavioural finance has provided analysts with numerous studies on how sentiment impacts asset pricing (Baker and Wurgler, 2007; Kaplanski and Levy, 2008; Statman, 2014). Investor sentiment is presumably unique for each market, which is why applying known sentiment effects from one market to another is ill-advised (Lang and Schaefers, 2015). This work contributes to existing research by performing an empirical study that analyses the effects of coronavirus-related news on Swedish stock prices, combining text mining techniques with multiple regression methodology. This exploratory study deals with a unique and extreme sequence of events, and it is unclear whether these findings will prove useful to future sentiment research. However, we believe our conclusions could be interesting for future research on Swedish stock market changes related to media coverage of low-probability and high-consequence events. 1.3 Disposition The structure of this thesis is as follows: Section 2 reviews relevant literature to present the current state of research. Section 3 details our research method. Section 4 presents our empirical findings which are then analysed in Section 5. Finally, Section 6 includes discussion of our results and conclusions. 2. Review of the Literature 2.1 Fundamental Analysis vs. Technical Analysis Stock markets have always attracted investors willing to grow their capital. Due to their dynamic and volatile nature, stock market investments are associated with high levels of risk. Financial analysis has been used for decades to understand movement of capital markets and to forecast stock price development. When analysing capital markets to support their decisions in buying, selling or holding stocks, investors have mainly been using two techniques — fundamental analysis and technical analysis. Which type of analysis investors choose depends on what they believe about the characteristics of the market. According to Murphy (1999), both methodologies aim to satisfy the same need, namely understanding in which direction the market moves. The only difference is that a fundamentalist would want to know why the market behaves as it does, while a technician would solely analyse market action itself (Murphy, 1999). 10
Fundamental analysis aims to identify mispriced assets, thus the main belief of fundamentalists is that the market prices are often incorrect. The main purpose of this type of analysis is to identify the intrinsic value of securities and compare it with the actual market price. The intrinsic value is set at the equilibrium on the market by supply and demand forces (Griffioen, 2003). A fundamental analyst would look at companies’ financial statements and calculate important multiples and ratios. While this form of economic analysis is time consuming and tedious, it is not sufficient to provide a complete picture of why an asset may be mispriced. Other aspects of fundamental analysis include broader industry analysis, and subjecting individual companies to deeper levels of scrutiny (Griffioen, 2003). The fundamental analysis is therefore based not only on mathematical calculations and financial statements, but also on analysts’ knowledge of the market and on their assumptions and beliefs. This could hold as an explanation of why there are investors on the market willing to buy and sell the same assets at the same time. Investors presumably reach different interpretations and conclusions when presented with the same information. Technical analysis is based on the premise that prices on the market move in trends and that those trends tend to repeat, leading to market swings. Technicians believe market prices could react to multiple factors and analysing causes of the market moves would be excessive, because stock prices get instantaneously corrected reacting to these underlying factors. Essential for the technicians is to recognise the direction of the market and even more essential doing this before others recognise the move. Thus technical analysts assume the fall in price of a security could be derived from higher supply or lower demand on that security which in turn reflects changes in the fundamentals (Murphy, 1999). Technical analysis is therefore limited to studying charts and graphs with the past market price (returns) movements to make predictions about the future. 2.2 Efficient Market Hypothesis While a detailed description of traditional finance evolution lies outside the scope of this study, we assume mentioning one of the most important assumptions of standard finance is of great importance. According to traditional finance theories, investors act rationally and always aim to maximise their profits while minimising their risks (De Bondt, 1995). The efficient market hypothesis (EMH) introduced and described by Eugene Fama represents one of the pillars of standard finance. The theory suggests no analysis of publicly available information could be used to outperform the market since stock prices adjust to new information instantaneously and unbiasedly, making the idea of ‘beating the market’ a utopia. The theory implies financial analysts are worthless, and the best investment strategy would simply be following market indices. To gain abnormal returns investors 11
would need to have access to information that is not known to the public, insider information (Fama, 1970). EMH stands out among traditional finance theories because it recognises the existence of irrational investors. However, Fama concludes that irrational investors’ trading is insufficient in volume to impact asset prices significantly. He points out that such investors would quickly be corrected by arbitrageurs forcing security prices to move to their fundamental values. Fama also suggests that not all market participants have to process the entire body of information available in the market because even a significant proportion of informed investors would take care of the efficient pricing of market securities (Fama, 1970). Whether financial analysis is capable of providing investors with necessary insights for outperforming the market has been highly debatable. De Bondt (1995) calls financial analysts’ roles paradoxical. He wonders, on the one hand, how efficient market hypothesis proponents could explain the existence of well paid financial analysts on the market if their job is worthless. On the other hand, he implies a competing view of an irrational market has difficulty explaining why professional investors consistently fail to beat market indices. At the AIMR conference in 1995 De Bondt said: “Despite its many insights, modern finance offers only a set of asset-pricing theories for which no empirical support exists and a set of empirical facts for which no theory exists.” 2.3 Behavioural Finance In standard or traditional finance humans are rational, therefore they aim to maximise their utility taking as little risk as possible. Pricing assets on capital markets is thus an unemotional and straightforward process and a correct price of an asset should be equal to the discounted present value of all future cash flows. For a long period of time, traditional finance theories were used to explain market movements and develop investment strategies. The reality, however, has been steadily challenging the standard finance assumption of rational and unemotional market participants. In the light of efficient markets, events such as price bubbles (e.g. the Swedish real estate bubble of the 1990s, the dot-com bubble) or stock market crashes (e.g. the Black Monday crash of October 1987) have not been able to find satisfactory explanations in the field of traditional finance. This has given rise to a new finance paradigm where irrationality of people, individual biases and cognitive factors hit the spotlight. In an attempt to explain market anomalies and improve market development analysis, financial researchers came to direct their views to other disciplines. Behavioural finance then emerged as an 12
innovative new discipline combining aspects of sociology, psychology, anthropology and finance (Ricciardi and Simon, 2000) with the focus of studying the behaviour of people and the transmission of this behaviour into capital markets. In particular, this newer discipline started challenging the notions of standard finance such as human rationality and efficiency of the markets, suggesting there are other factors explaining market anomalies and volatility. As Statman (1995, p.15) put it: “People in standard finance are rational. People in behavioural finance are normal.” Early research in the field presented the modern financial paradigm with behavioural investors who were not consistent in their attitudes towards risk. In accordance with Prospect theory, people are risk-averse in the domain of gains and risk-seeking in the domain of losses (Kahneman and Tversky, 1979). Simply put, investors feel the loss stronger than a gain of the same amount of money and are therefore prepared to pay to avoid losses as readily as they pay to generate profits. Prospect theory, with its empirical evidence, has since become a central concept in behavioural finance. Another finding of behavioural finance is that investors exhibit bounded rationality, in other words their decisions are limited by cognitive mistakes, psychological biases and emotions. The existence of fully rational investors cannot be verified in reality (Shleifer and Vishny, 1997). A constantly growing number of market participants has also come to influence market movements. Trading is no longer exclusively accessible to institutional investors. Developing technology and an emerging number of trading platforms has given rise to non-professional “hobby” traders. They trade more often and act unpredictably, making markets even more volatile. Their access to professional financial forums is limited, and they often turn to information sources such as news outlets and social media to support their decisions on the stock market. These retail investors are also more likely to trade on market sentiment (Bukovina, 2016; Baker and Wurgler, 2007). 2.3.1 Market Sentiment In the field of finance, sentiment is often described as the mood or emotions of people which may influence capital markets. This implies asset-pricing should not be fully associated with fundamental changes in the economy or individual securities. Kaplanski and Levy (2008) state sentiment is a much broader concept and could be described as “any misperception leading to asset mispricing”. Mood and fear can therefore be considered examples of how the potential for irrational behaviour in investors can result in shifts in market sentiment. Baker and Wurgler (2007) define market sentiment as “investors’ beliefs” about future returns and risks when these beliefs are not necessarily supported by available information related to fundamentals. In this paper we use “market sentiment” as a broader interpretation described in the aforementioned works so that any factor beyond changes in fundamentals is seen as sentiment. 13
Behavioural finance studies have been aiming at better understanding whether market sentiment has an impact on investors’ decisions while pricing assets. Statman (2014) concluded the phenomenon that investors sell securities when the market reaches its bottom could be explained by fear of growing risk and smaller belief of future returns. He also explains that many investors tend to buy securities when the market is already overheated because of the excitement that mitigates risk perception and exaggerates expectations of future returns. These future returns expectations could probably explain irrational exuberance behind stock market speculative bubbles much better than standard finance theories could. In a similar way the disposition effect theory is based on a number of misleading emotions that influence investors’ decisions. Regret of realising losses is described as an emotion forcing investors to hold on bad stocks for a longer period of time than it is rational. Pride and thrill, on the other hand, make investors sell winning stocks too early in a hurry to realise their gains (Shefrin and Statman, 1984). Symeonidis, Daskalakis and Markellos (2010) inferred sunny weather could be associated with increased volatility of the markets in the US. They conclude good weather could result in good moods and increased communication among investors on the market driving up trading volumes and thereby volatility. Events such as disease outbreaks or epidemics are known to increase the overall anxiety level and pessimism in the society and thus create negative sentiment (Donadelli, Kizys and Riedel, 2017). Evidence is prolific that financial decisions are driven by sentiment as behavioural finance studies provide us with results ascertaining the existing relationship between stock returns and market sentiment. Sentiment studies of recent years often do not question whether sentiment has an impact on stock prices. Researchers have seemingly accepted that it does. A new direction of research does not simply study sentiment impact on the stock market but also points out that different stocks are disproportionately reactive to market sentiment. Baker and Wurgler (2007) ascertained that stocks of smaller, younger, high volatility and growth companies are more prone to market sentiment than large cap and mature stocks. They explain this disproportional sensitivity depends on two factors: smaller and younger stocks are more difficult to arbitrage and value. Baker and Wurgler (2007) pointed out that during the dot-com bubble, the majority of speculative stocks were small start-ups with no historical data to lean against, thus valuation mistakes were very probable considering general excitement around the Internet at that time. Consequently, while studying market sentiment, it is more reasonable to look at small and large cap stocks separately than analyse dependency of aggregate stock prices on sentiment. The presence of market sentiment raises a question of how it could be extracted, measured and analysed. Studying news and social media content to extract market sentiment has become common in recent behavioural research. Many attempts have been made to use qualitative textual content for 14
quantitative analysis and predictions (Bukovina, 2016). Researchers have been steadily studying how financial news could be processed and categorised with the help of different computer based techniques (Lee et al., 2014). The amount of data involved is enormous and its effective and quick analysis by humans is no longer feasible. Traders see an advantage in developing algorithms for textual data analysis and in creating stock price predictive models and automated trading systems (Atkins, Niranjan and Gerding, 2018). Evidence suggests such models can improve stock prices predictions made by traditional financial analysts. Studies on how non-financial news influences market sentiment and stock markets are numerous but plagued by a persisting difficulty to extract and distill news relevant to the analysis. Also, these studies have most often analysed social media driven market sentiment and been carried out on the US market. It is therefore questionable if the results could be replicated on other markets. Moreover, the research results on sentiment impact on stock markets are contradictory (Lang and Schaefers, 2015) and prove that market sentiment can change over time. It is also obvious that sentiment differs depending on event, market and even culture. Kaplanski and Levy (2014) showed through the example of the football sentiment from 2010 FIFA World Cup study how sophisticated investors adjusted their trading strategies and weakened the football sentiment effect on the US stock market at the last stage of the tournament. A real challenge, however, has been in creating a model that is reliable in establishing a connection between news and evolving stock prices, because adjustments on the fundamental changes in the economy have to be made. The authors suggested that when studying market sentiment, one should analyse economic news in terms of its potential for both positive and negative impact, and include the economic news as a non-sentiment fundamental variable that impacts stock prices in the predictive model. Another difficulty for sentiment analysis is to distinguish what market sentiment at different periods of time consists of, and which component of this sentiment plays the most significant role. Baker and Wurgler (2007) propose measuring market sentiment by breaking it down into sentiment proxies. According to them, extracting potential sentiment proxies can be useful for future models measuring sentiment impact on stock markets, even though these proxies are imperfect and noisy. They suggest combining different imperfect measures such as surveys on investors’ beliefs, option implied volatility measures, trading volume, retail investor trades and mood proxies. Baker and Wurgler (2007) have constructed a sentiment index level that includes several of these proxies to smooth out idiosyncrasies. Studying existing research on sentiment measures we arrive at a conclusion that there are not many established methods at the moment, and that researchers are actively exploring new methods by merging existing models and constructing their own ones. 15
2.4 Event Studies and EMH One of the most frequently used methods to determine whether market sentiment related to a certain event gets effectively incorporated into stock prices is the event study method. Event studies are most suitable for analysing the sentiment effect of a single event or a series of rare events on a stock’s price or a sector’s returns. One must define the event and estimation windows and subsequently calculate the stock’s abnormal return. The abnormal return is the stock’s return over the event window minus the expected return of the stock over the event window (MacKinley, 1997). There are several methods to calculate abnormal returns to carry out an event study. MacKinley (1997) suggests models for calculating expected returns with a constant mean return, or market models. Measuring and analysing abnormal returns for the stock provides a researcher with insights on whether the market has efficiently incorporated this event into the stock’s price. Discussion of an event study often deals with implications of EMH and the market’s capacity to timely and rationally assess relevant information. Some events are more commonplace than others and are generally easier to analyse. It is not surprising that event studies often arrive at different conclusions in regard to market efficiency. 2.5 Text Analytics in Finance The importance of analysing text springs from its “nuances and behavioural expression which is not possible to convey using numbers” (Das, 2014, p.4). Text analysis is used to convert textual data to quantitative or qualitative information. It includes everything from simple methods for summarising and visualising large bodies of text in order to make it easier to comprehend to complex methods of quantifying vast amounts of unstructured text data. Depending on the goal, there are many different tools which can be employed. Text analytics in finance has primarily focused on measuring effects on stock prices and indices as well as analysing corporate reports (Cohen, Malloy and Nguyen, 2020). It can be performed by either the use of dictionaries, lexicons or machine learning (Das, 2014). The choice of method depends on the type of inputs and desired outputs, for example, in machine learning, a regression model is used to predict continuous output variables whereas classification models are used for discrete output variables. Also, supervised models are used for classification with prespecified outputs whereas unsupervised ones are used for clustering inputs in previously unspecified ways (Mitchell, 1997; Das, 2014; Cohen, Malloy and Nguyen, 2020). Several researchers have underlined the usefulness of unsupervised machine learning models on financial data, in quantifying and visualising financial stability tendencies (Li, et al., 2017), modelling 16
the structure of the stock market (Doyle and Elkan, 2009) and specifically on financial text data for which no a priori categorisation of their content exists (Feuerriegel and Pröllochs, 2018). One example of an unsupervised machine learning model for clustering is topic modelling using Latent Dirichlet Allocation (LDA). It is a generative probabilistic model for collections of discrete data such as text corpora which finds the words that occur the most throughout the corpus, clustering them into topics and calculating the probabilities of each document belonging to each topic respectively (Blei, Ng and Jordan, 2003). Feuerriegel and Pröllochs (2018) measured the impact of topics within corporate filings on the stock market to identify topics which are of relevance to investors, motivating the use of LDA by the fact that previous studies on the effect of specific disclosure topics on the market (Tetlock, 2007; Vuolteenaho, 2002 and Chan, 2003 cited in Feuerriegel and Pröllochs, 2018, p. 3) had evaluated the effect of one topic at a time and ignored disclosures not belonging to any of the given topics. They stated the advantages of employing LDA as avoiding subjective bias due to manual topic extraction, greater flexibility with topic selection accordingly with the text corpus and the ability to process vast amounts of text, which would be “prohibitively difficult and costly with manual labelling” (p.4). 2.5.1 Sentiment Analysis through Computational Linguistics Another form of text analysis, which has recently been highly recognised for its usefulness among academics and business people, is automated sentiment analysis. Part of mathematical language theory known as quantitative linguistics, it is a way of extracting subjective expressions from unstructured text and classifying them according to their sentiment (Alessia, et al., 2015). Many programming languages support this type of analysis, i.e. R with the packages dplyr, tidyr (Wickham and Henry, 2020), textdata (Hvitfeldt and Silge, 2020) and tidytext (Robinson and Silge, 2020) to mention a few. The steps in sentiment analysis, as described by Alessia, et al. (2015), are data collection, text preparation, sentiment detection, sentiment classification and presentation of output, and can be done using either a lexicon-based or machine learning-based approach or a hybrid of the same. Lexicons are dictionaries with words which are each given a sentiment orientation or score. The lexicon is joined with preprocessed, so called “tidy” data (Wickham and Henry, 2020), to determine the affective content of the text and its polarity (Devitt and Ahmad, 2007). Sentiment analysis processes within computational linguistics have previously been widely used in financial contexts, with a few examples including forecasting stock prices (Tetlock, 2007; Day and Lee, 2016) and analysis of the market’s response to sentiment in financial press releases (Federal Reserve Bank of St. Louis, 2006). 17
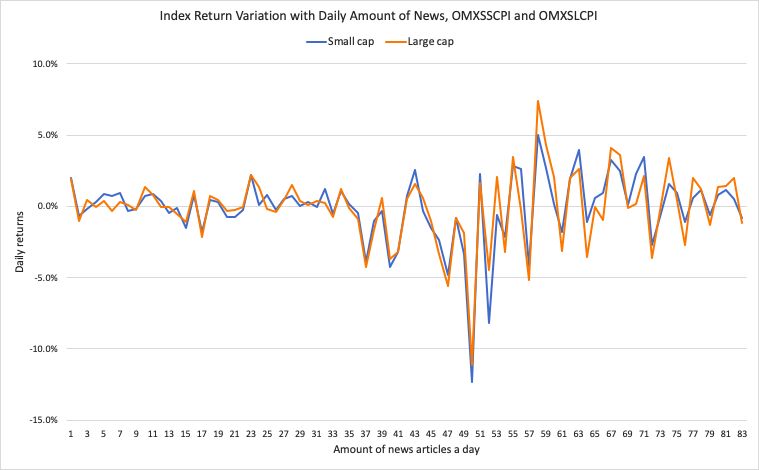
3. Method and Materials 3.1 Description Our findings were expected to explain whether or not investors’ perceptions of news on the disease, mortality and the sequence of events associated with the coronavirus influenced the behaviour of the Swedish stock market. Keeping in mind that small and large cap stocks can move differently and exhibit different levels of volatility, we considered them separately by analysing both OMXSSCPI and OMXSLCPI indices. Our model was intended to shed light upon the types of coronavirus-related news that had the biggest impact on investor sentiment and explore the possibility of using those news categories to adjust future trading strategies. We aimed to examine whether uncommon events may bring with them new arbitrage opportunities. The impact of coronavirus-related sentiment on the Swedish stock indices OMXSSCPI and OMXSLCPI was measured using a multiple regression model. The independent variables were created through a three-step process: first, news articles related to the coronavirus were gathered as a source of text containing fundamentals and sentiment. Second, relevant news topics were chosen automatically from the text data by the degree of importance in the total body of extracted news through the use of latent Dirichlet allocation. The topics were weighted for each news article in accordance to probability measures, giving articles topic scores. Third, each news article was assigned a sentiment score using sentiment analysis to account for negative or positive events in each topic. The topic score was then combined with the sentiment score to provide an overall article-specific proxy score. Then, proxy scores per article were merged to the same date to create single daily observations per business day. Finally, daily returns on OMXSSCPI and OMXSLCPI were regressed on the sentiment proxy variables. A possible source of uncertainty in the models was that the news sentiment variables might show a certain degree of multicollinearity, i.e. news about deaths might affect the probability of upcoming news about restrictions due to containment of the virus spread. This was assessed through the use of the variance inflation factor (VIF) which shows the degree of correlation between independent variables (Fox and Weisberg, 2018). Statistical software calculated a VIF for each independent variable. A commonly used method for examining the impact of news on returns is the event study method previously described in the literature review. However, this method was not employed in the study of the impact of coronavirus-related news due to the daily media coverage. The extensive supply of news articles made it nearly impossible to isolate individual events from each other. Due to overlap, an event 18
window could not be successfully constructed and yield meaningful results. Also, an event study utilises excess returns on the observed stock or index compared to another index. This was not feasible to assess due to the coronavirus being a global series of events, meaning there could be no comparison index left unaffected. 3.2 Limitations The actualisation of this study in the midst of the ongoing pandemic posed as a limitation as well as an advantage. Due to the crisis only having begun, only the beginning effect and strong panic were shown in the news without any crisis reversal which would be needed in order to fully examine the situation from a time-series perspective. In analysing the text data, a significant amount of noise was present due to the data being collected in real time. However, performing this research during the pandemic is also what makes it so valuable. At the beginning, one can make predictions and get results, then compare them to see what has changed and work on iteratively improving the accuracy of the model. This also demonstrates how models can be designed in the best possible way to account for the fact that they are analysing a continuously developing situation. The lack of prior research on the topic is clear. The idea of analysing the impact of market sentiment on stock prices is not new and numerous studies have been introduced for several decades, using both theoretical-manual and automated approaches such as the aforementioned event study and text analysis methodologies. However, to the best of our knowledge, there are very few studies, if any, analysing the effects of news-derived sentiment on the Swedish stock market in the context of uncommon events. The coronavirus pandemic is a unique event for the entire world, and particularly challenging for Sweden, because an analogy between the disease spread and other tragic events like natural disasters, disease outbreaks or wars cannot be drawn. Sweden has not experienced any calamities of this nature in modern times. In our study, we thus rely on international research with a prevalence of evidence from the United States. We recognise that assumptions about market inefficiency, weather influencing stock market prices or behaviour of influential figures might not have the same effect in Sweden as it would in other countries. We were also limited by the shortage of available data in performing the text analysis. Analysing news articles published in Swedish, we encountered not only a lack of notable Swedish dictionaries for sentiment analysis, but also of an epidemic-related lexicon in particular. Creating such a lexicon would require a study on its own and was outside of our scope. In light of this limitation, we translated the news articles from Swedish to English using Microsoft Translator. We acknowledge this might have 19
contributed to uncertain results in topic modelling, however manual random sample controls yielded satisfactory results with the meaning of the articles intact. As mentioned in the description of our methodology above, we recognise that stock price patterns are influenced by real changes in the economy and not primarily by sentiment. A reliable economic indicator index consisting of main economic factors, such as employment rate, GDP growth, consumption of durables and non-durables, service consumption and production index are essential for building a robust statistical model. At this moment, such an index is not present in Sweden and is not feasible to construct from the data available due to a difference in time-series frequencies for the different indicators. For our work, we would have needed daily indicator data, however the Swedish official statistics agency publishes these figures on monthly and quarterly bases. We recognise using economic and political news articles published in a daily newspaper to model real changes in the Swedish economy is not ideal and acknowledge there is room to address this particular issue in a better way. 3.3 Stock Indices Historical data for the Stockholm Small Cap and Large Cap price indices (OMXSSCPI and OMXSLCPI) are collected from the Nasdaq Nordic website (The Nasdaq Group, 2020) for the period of January 2nd, 2020, to April 30th, 2020. 3.4 News The data source for collection of the news data was chosen with considerations regarding the target group; investors in the Swedish stock market. Considering the features of a reliable source and readability and preference of the target group, Dagens Nyheter, a renown Swedish news site, was chosen. The site has a subsection aggregating news articles covering the coronavirus, containing both economic and non-economic news (Dagens Nyheter, 2020). 3.4.1 Collection News articles on websites are unstructured strings of text. In order to use the data for text analysis, the website was scraped using the Google Chrome extension tool “Web Scraper” (Web Scraper, 2020). Using this tool, the text was extracted from the news website through the site’s CSS selectors (see the selector graph in figure 2) and rendered as structured text in a .csv file. The start URL was https://www.dn.se/om/det-nya-coronaviruset/. Pagination was used to navigate to each page of the website to extract all news to one file. 20
Figure 2: Selector graph over the coronavirus news sitemap. TitleLink denotes the link to each news article on the start page and Text the content of the article. 3.4.2 Preprocessing Textual Data Once the data was collected, it underwent preprocessing in order to be readily usable by quantitative linguistics programs. The text rendered from web scraping was as presented in the CSS-selectors; containing punctuation, numbers and both upper and lower casing. The text was stripped of all of these. Following that, the text was tokenised using a whitespace tokeniser, rendering each part of text separated with blank spaces as a token and later stemmed using a Swedish Snowball stemmer, connecting all tokens with the same word stem into the same token. Stop words, extremely common words of little value to the text (Manning, Raghavan and Schütze, 2008), were omitted. The preprocessing method differed for the topic modelling and sentiment analysis and will be described more in-depth in the following sub-chapters for each method. 3.4.3 Topic Modelling and Scoring As scraped news data is not classified a priori, LDA was employed in order to find the most commonly appearing words in the text corpus. The LDA was performed using the KNIME Analytics Platform, an open source data science software (Berthold, et al., 2020). The platform allows the user to perform data analysis and build, test and deploy models using built in nodes. In order to be able to perform text analysis, the data, originally in strings, was transformed to a corpus with documents using the Strings to Documents node. Then, Swedish stop words were removed through the creation of a custom dictionary filter using a stop word list from a Github repository (Dahlgren, 2019). Further, punctuation was erased, the documents were converted to lowercase and stemmed using a Swedish Snowball stemmer. The use of code and text from Github repositories brings with it risks and potential for errors due to the fact the authors are not renowned and trusted sources. To minimise errors, the preprocessed text was viewed and examined after the completion of each preprocessing step. The 21
design choice between using Swedish text translated to English to be able to use built-in stop word removers, or using the original text and with a sourced stop word list, was made in favour of using the original text due to concerns regarding how important meaning could be lost in translation and topics modelled incorrectly as a consequence. The Topic Extractor (Parallel LDA) node was configured to extract ten topics with 20 terms each after empirical testing of different combinations of topics and terms. The extracted terms are visualised in Figure 3. Figure 3: Word cloud of the most common words appearing in Swedish Coronavirus-related news articles, sized according to relative weight in the corpus. Feature extraction and topic assignment is a crucial step in determining which variables to extract as sentiment proxies from the coronavirus-related news. The words that appear in the news most often are likely to give a reasonable understanding of what the topic in question deals with. We understand that one news article might contain information belonging to several topics. Therefore, we, in contrast to previous research (Feuerriegel and Pröllochs, 2018) did not assign each document to one topic, but rather to multiple topics. We assigned each article to the topics for which its probability of belonging exceeded 0.25, yielding a topic score for each article of 1 for belonging topics and 0 for non-belonging topics. The aforementioned researchers used topic modelling to extract topics from financial texts that could be relevant for investors. We extracted topics from non-financial texts that theoretically should not be relevant for investors, but we hypothesised that they are. A trade-off 22
was made here between allocating individual articles to a single topic, thus missing out on a lot of data, or introducing noise into the model by allocating articles to several topics each. We deemed it more important to make our data as exhaustive as possible, and therefore chose to allocate articles to several topics. 3.4.4 Sentiment Proxies Coronavirus-related news is not an investor survey or mood proxy, because it does not directly reflect what investors think or feel. We should not forget that news articles are written by journalists, and not investors themselves. We aim to model the way the information contained within the articles can influence investors. We find it reasonable to assume that coronavirus-related news is sentiment driving information which in turn can be deconstructed and analysed. Thus, the modelled topics are assumed to be potential proxies for coronavirus-related sentiment caused by the news. Further we detail the topics and motivate our choice of proxies that can be useful for measuring disease-related news sentiment. Swedish Restrictions. The Swedish strategy in response to the coronavirus pandemic has been very different to that of many other countries in the world. Understandably, it has drawn a lot of attention from international media as a consequence and remains widely discussed in Sweden, polarising society. Some people in Sweden had supported the relatively passive line the Public Health Agency of Sweden (FoHM) and their government had chosen, while others were very critical and urged politicians to implement a more stringent regime of heavy social restrictions in line with those introduced in other countries. Although Sweden had at no stage closed down its economic activity or enacted a curfew for citizens, some considerable restrictions were implemented during March and April, 2020. For instance, people could not meet in groups of more than 50 people at a time. Travelling from one region to another within Sweden was not recommended and deemed inappropriate unless work- related or for serious personal reasons. Swedish institutions responsible for handling the crisis have held press conferences daily to inform citizens on regulations and recommendations in conjunction with the emerging crisis. The keywords with highest weights in this topic had roots like Swed-, close, school, Stockholm, Public Health Agency (one word in Swedish), institution, travel, pupil, spread, follow. This proxy was named REST. Swedish Politics. This topic covered how politicians in Sweden had tackled the crisis during the first months of the coronavirus outbreak. The topic was different from the previous one in that it dealt with the political actions of Swedish leaders regarding economic, social and political concerns, and not the actions of the Public Health Agency in addressing the public health emergency. When the 23
coronavirus pandemic began, Sweden had a social democratic minority government. Making prompt decisions and implementing active measures in response to the rapidly evolving situation would not have been possible without oppositional support, which is possibly why politics became a central topic. The keywords with highest weights in this topic had roots like Swed-, crisis, government, country, need, coronavirus, leading, politics, measure, economic, state. This proxy was named POLIT. Economic Policy. Many companies suffered rapid declines in their revenues due to the coronavirus outbreak. This crisis was completely unpredictable and in no way caused by the businesses themselves, which is why nobody was prepared to handle it. The Swedish government had to act decisively and quickly to avoid widespread bankruptcy. Economic support packages were introduced, one after another, but businesses continued to ask for more help. Unemployment rates increased heavily, although much of the support was addressing employment issues. The keywords with highest weights in this topic had roots like company, percent, crowns, state, econom-, billions, employed, Swed-, government, support. This proxy was named ECON. Sport. The coronavirus pandemic caused almost all organised sporting events around the world to be suspended, cancelled, delayed or moved. Delaying the Olympic Games in Tokyo and the UEFA European Football Championship were unprecedented measures taken in light of the coronavirus crisis. Because sport affects so many people, and we know from earlier studies that it also affects stock prices, it is not surprising sport became an important topic. The keywords with highest weights in this topic had roots like game, sport, match, Olympics, cancel, coronavirus, club, move. This proxy was named SPORT. Coronavirus Contemplations. For many individuals, an important part of the debate around the coronavirus outbreak has centred upon “the new normal”, i.e. how to adapt and carry on living meaningful and fulfilling lives in an unusual and confronting situation characterised by social distancing, isolation and loneliness. The spread of the virus has impacted every aspect of our lives and in turn prompted widespread debate in the media. The keywords with highest weights in this topic had roots like world, death, person, time, self, life, live, years. This proxy was named FEEL. Culture. Culture also had a central place in public discourse, as many cultural events were also cancelled completely or moved to unknown dates in the future. The arts, exactly like sport, depend on people gathering in large groups, and many culturally based industries rapidly fell into a deep crisis within a week. The keywords with highest weights in this topic had roots like culture, film, public, music, cancel, media, concert. This proxy was named CULTURE. 24
Instructions to Swedish People. The Swedish government and authorities repeatedly called on the public to follow existing instructions and advice to help slow the spread of the virus and protect the health care system from collapse. Their guidelines included working from home where possible, maintaining distance between one another where practicable, limiting social contact to members of one’s own household, and avoiding crowded places. People above the age of 70 were repeatedly instructed to be careful and follow these recommendations very carefully. This topic was different from the aforementioned Swedish Strategy in that it did not deal with restrictions and limitations enforced on the public, but mostly with calls on personal responsibility and solidarity. The keywords with highest weights in this topic had roots like at home, keep distance, job, think, help, public, time, try, people. This proxy was named INSTR. Swedish Healthcare System. Most countries in the world are simply not prepared to respond to a pandemic with overwhelming numbers of sick people at a time. The state of the healthcare system became crucial as it was associated with the potential outcome for both COVID-19 patients and medical staff. Due to the characteristics of the virus and its transmissibility, elderly care received a lot of attention in the media due to the high occurrence of deaths in nursing homes. A lack of protective equipment in hospitals and nursing homes, limited intensive care places and shortages of medical staff sparked intense debate in the Swedish media. The words with highest weights in this topic had roots like region, patient, medical care, Stockholm, staff, hospital, protective equipment, intensive care, commune, nursing home, Karolinska (a Swedish university and hospital institution). This proxy was named MED. Coronavirus-Related Events in The World. Delivering information on the spread of coronavirus around the world has been a main goal of the media during the unfolding crisis. In the modern, globalised world, countries are dependent on each other's production and trade and it is reasonable to assume Swedish investors have meticulously followed not only local coronavirus-related news but also sought information from other countries. This is particularly true of Italy and the United States. The words with highest weights in this topic had roots like Chin-, coronavirus, Trump, USA, Ital-, country, president, infect-, close, quarantine. This proxy was named WORLD. Coronavirus Spread. A lot of news articles published during our research period were dedicated to the virus and its spread. First there was news about a new virus outbreak in Wuhan, then about deaths associated with this new disease in China. After the virus had spread to other parts of the world and the WHO announced that coronavirus could be characterised as a pandemic, news articles began to centre upon statistical comparisons between countries, and the ways in which governments were 25
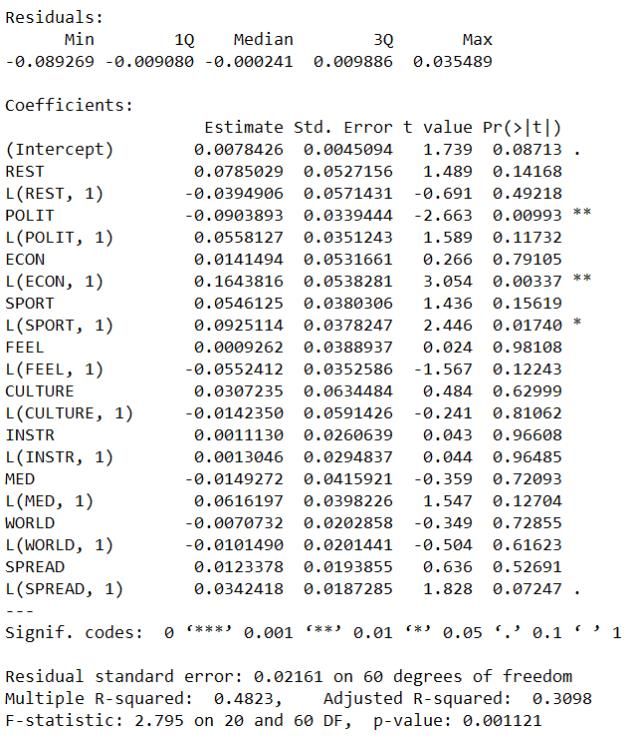
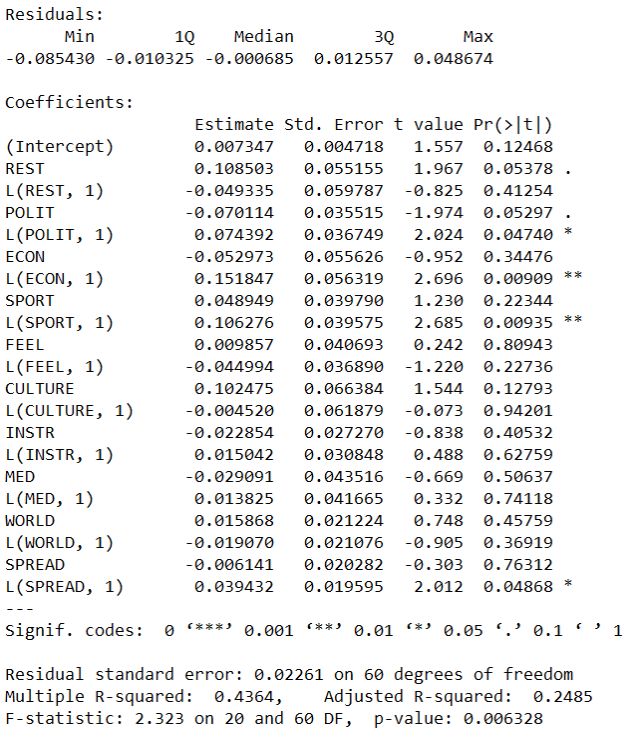
responding to the crisis. The words with highest weights in this topic had roots like infect-, new, coronavirus, virus, disease, China, case. This proxy was named SPREAD. 3.4.5 Sentiment Analysis Sentiment analysis was performed on each article separately in R (R Core Team, 2020), using packages tidyr, tidytext and dplyr. The analysis was performed on the text data translated to English with Microsoft’s translator in Excel and through the use of the bing sentiment lexicon (Hu and Liu, 2004) in R. The translation of text can bring with it some sources of error, but due to the sentiment analysis being done only to get the sentiment orientation of articles, we deemed this error insignificant. Another path would have been to use a Swedish sentiment lexicon (i.e. Dahlgren’s “sentimentlex”, 2019), but due to bing being a built-in lexicon in R and heavily used in literature, we deemed it more reliable and exhaustive than sentiment lexicons found in Github repositories. The bing lexicon contains affective words and their sentiment orientation (positive or negative). The weighted sentiment score allocated to each article was calculated as follows: − = where a denotes the article. The net sentiment of each article was normalised through division with the total amount of words in the article to ensure that the sentiment score was not dependent on the length of the article, but on the relative proportion of sentiment words used. We believe the length of an article is not a primary determining factor in its potential impact on the reader, while its relative sentiment score is of greater importance. Each article’s sentiment score was then combined with the article's topic score using the following formula, yielding the amplitude for each article’s sentiment proxies. , = × , where p denotes each proxy respectively (REST, POLIT, ECON, SPORT, FEEL, CULTURE, INSTR, MED, WORLD and SPREAD) and a denotes the article. 26
3.4.6 Allocation of News to Dates The topic and sentiment scoring was performed on individual news articles. To measure the impact of coronavirus-related news on the stock index, the scores per article were then aggregated to one data point per day. This was done due to the stock index data having a daily frequency. The news occuring on weekends or holidays were aggregated to the following trading day. 3.5 Economic Indicators In literature, the analysis of the effect of sentiment on stock markets has involved the use of explanatory variables encompassing fundamental economic factors, because important economic news most likely causes change in stock returns. Due to the short period of our study and daily frequency of data in use, no suitable economic indicators for the Swedish market can be used at the day of writing. Thus, we used economic news in Dagens Nyheter as proxies for changes in fundamentals. Even though Dagens Nyheter does not publish detailed economic reports on main macro- and microeconomic indicators, it presents the economic news regularly and offers insights into the present state of the economy. 3.6 Multiple Regression Two regression models were set up in this study, one explaining the variations in the Stockholm small cap index, the other the Stockholm large cap index through our coronavirus-related sentiment indicators. The models were specified in accordance with econometric theory (Brooks and Tsolacos, 2010) and regressions run in R (R Core Team, 2020) using dynlm F(Zeileis, 2019). 3.6.1 Model Specification The specification of the empirical regression models is done through statistical tests. First was chosen whether the dependent variables, OMXSSCPI and OMXSLCPI indices, should be in level points or in growth rates. This decision was made based on examination of the autocorrelation of level indices and their returns for different lags. Then, a dynamic model with Distributed Lag variables was chosen, with the dependent variables explained by contemporaneous and lagged sentiment proxies. This was due to two factors: Firstly, it could take time for news to reach the audience and secondly, some news articles were published after the market had closed, meaning news could not possibly impact the indices on the day of publishing. The sentiment proxies allocated to different topics during the modeling process were used as numerical variables in the regression as described by Kaplanski and Levy (2014), creating a multiple 27
You can also read

















































