Data Fabric Its time has come ARB-1316 - Technical Whitepaper August 2022 - IBM
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Technical Whitepaper August 2022 Data Fabric Its time has come ARB-1316 IBM Academy of Technology

IBM Academy of Technology
Authors:
Sonia Mezzetta, Pat O’Sullivan, Jo Ramos,
Elizabeth A Ackerman, Stephen W Jones, Paul
Christensen, Ashok K Iyengar, Pradeep K Kutty,
Bryan Kyle, Nicholas McCrory, Julio Ortega,
Guillaume Subramanyam, Oliver Claude, Mehdi
Charafeddine, Shankara N. Sudarsanam
Academy of Technology Executive Sponsor and
Co-Sponsor: Jo Ramos and Oliver Claude
Initiative Lead and Co-Lead: Sonia Mezzetta and
Pat O’Sullivan
ARB-1316
Table of Contents
PREFACE 2
WHO IS THE AUDIENCE FOR THIS PAPER? 2
ACKNOWLEDGEMENTS 2
INTRODUCTION 3
WHY ORGANIZATIONS NEED A DATA FABRIC TO ACHIEVE BETTER BUSINESS OUTCOMES? 3
DATA FABRIC: KEY TO DATA-DRIVEN TRANSFORMATION 5
DATA FABRIC DEFINED 6
HISTORY AND LINEAGE OF DATA FABRIC 6
HOW DOES IT INTEGRATE WITH DATA AND AI ECOSYSTEM? 7
WHAT IS THE VALUE PROPOSITION? 8
DATA FABRIC VS. DATA MESH 9
ARE DATA FABRIC AND DATA MESH CONCEPTS OR TECHNOLOGIES? 9
CAN A DATA FABRIC AND DATA MESH CO-EXIST, OR DO YOU NEED TO CHOOSE ONE APPROACH OVER THE OTHER? 9
DATA FABRIC REFERENCE ARCHITECTURE 10
WHAT ARE THE CRITICAL CAPABILITIES OF A DATA FABRIC SOLUTION? 10
BIRDS EYE VIEW 11
DETAILED VIEW 16
OPERATIONAL VIEW 18
HOW CAN ORGANIZATIONS EXPLOIT DATA FABRIC? 21
HOW A DATA FABRIC FACILITATES AN ORGANIZATION’S MOVE TO BE MORE DATA DRIVEN 22
A DATA FABRIC ASSISTS IN BRIDGING THE GAP BETWEEN BUSINESS AND IT 23
TYPICAL USE CASES 24
A DATA FABRIC METHODOLOGY TO ENABLE SUCCESSFUL ADOPTION AND IMPLEMENTATION 25
GUIDING PRINCIPLES 25
DETERMINE SCOPE 25
REVIEW CURRENT DATA TOPOLOGY 25
DEVELOP FUTURE-STATE TOPOLOGY 26
DEFINE FUTURE STATE PHYSICAL INSTANTIATION 27
DEFINE IMPLEMENTATION STRATEGY/APPROACH 27
ACCOMMODATING TECHNICAL CONSIDERATIONS 28
FUTURE 31
CONCLUSION 32
REFERENCES 33
IBM Academy of Technology
ARB-1316
IBM Academy of Technology
Preface
What is the purpose of this paper and who is the audience?
This paper is intended to introduce the definition of a Data Fabric solution from a
business perspective, the technical capabilities required to instantiate the solution,
and a reference architecture representative of the solution.
It is anticipated for large to medium sized enterprises.
The target audience includes:
• Executive leadership: Chief Data Officers, Chief Technology Officers and Chief
Information Officers
• Lead technical roles such as Enterprise Architects, and Data Architects
• Data Governance roles: Data Security, Data Privacy roles, and Data Stewards
• Analytical and Development roles: Business/Data Analysts, Data Engineers,
Data Scientists, Business Intelligence developers and other data roles
Acknowledgements
We would like to acknowledge and thank Mohammed Abdul Qadeer Moini for
collaborating on this effort and producing an incredible design. We thank you and your
great talent.
We would like to thank the executive sponsors of this initiative, Jo Ramos and Oliver
Claude who have supported the creation of this white paper and who have also
contributed to its writing.
Finally, we would like to thank the IBM Academy of Technology which is an innovative
program within IBM that fosters collaboration, technology innovation and growth. It
offers a unique opportunity for a talented set of professionals to come together on
their own time and work on technical topics they are extremely passionate about.
ARB-1316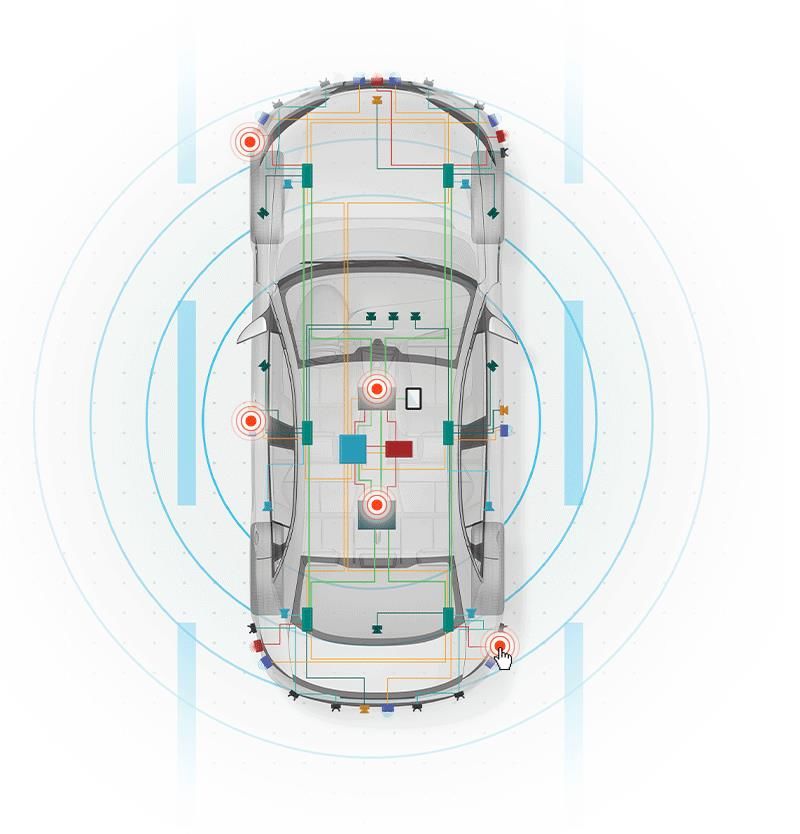
Introduction
Why organizations need a Data Fabric to achieve
better business outcomes?
Data is a critical component for enterprises
looking to achieve better outcomes through data
driven decisions and processes. A data-driven
approach can lead to improved decision-making,
minimization of risk, and competitive advantage.
However, for many organizations leveraging data
in an easily accessible and integrated way
can be challenging. Many organizations have
access to highly skilled resources and state-of-
the-art technologies yet struggle to move the
needle rapidly enough with ever-changing
business needs.
Why is this? What makes it so difficult for
organizations to become data-driven? Outlined
below are the major obstacles typically
experienced by organizations.
1. Complex data architectures
Continuous changing data architecture: The continuous pressure to transform and innovate have led
organizations to embrace new, often disruptive, business models (e.g., digital ecosystems, and anything as a
service). Significant technology investments are being made in support of the evolving business models
including the modernization and expansion of applications and data ecosystems. Examples of newer
technologies being integrated into the modernization effort include blockchain, robotic process
automation, machine learning algorithms, and AI. The speed in which data is generated, the explosion of
types of data collected, and the amount of data collected have forced organizations to continuously attempt
to modernize their data architectures or work around their current data architectures. As a result, many have
increased the complexity of their data architectures with various technologies and a sprawl of data stores.
Lack of integration
Data is stored across multiple repositories (files, data lakes, data warehouses, data marts, cloud data stores,
etc.) and locations like on premises and in multiple clouds. However, meaningful integration and
understanding of the data is often lacking, leading to data silos, time consuming SME and tribal knowledge
required to advance any business efforts, and significant IT efforts (ETL, data movement, etc.) to support the
needs of users and applications.
Lack of scalable and flexible architecture
The amount of data that companies collect has exploded in recent years. It provides great opportunities, but
also poses new challenges. Exponential data growth requires a scalable and flexible architecture, which
many companies still lack.
IBM Academy of Technology 3
ARB-1316
Data store complexity
Data is not “simple.” It comes in different forms
and types. Data is collected in multiple formats
from various sources e.g., ERPs, CRM, core
transactional systems, machine generated
data, external social media, customer
interactions, etc.). There are several types of
data stores (structured and unstructured)
that pose additional challenges to integrate
information in a unified manner.
2. Insufficient data governance
The complexity and variety of data collected,
and the increasing points of data locations
challenge business consumers to take full
advantage of data quickly unless there
are processes and technology to facilitate the
ease of finding and consuming relevant data.
Capabilities such as active metadata, data
lineage, business vocabulary, taxonomies,
ontologies, and data quality insights are
required to understand and use the data with
confidence and accuracy.
Data provides little value if one is unable to
make sense of the data or has trouble finding
the data. Inconsistent, inaccurate, or
misunderstood data has proven to be
detrimental for effective decision-making
situations.
3. Currency with data regulations
In the last few years, there has been a growing
number of regulations around data privacy,
data protection, and data residency. In practice
that means that data privacy and data
protection related to PHI (Protected Health
Information), Personal Sensitive Information
and other state and government regulations
(GDPR, CCPA, etc.), will require a series of data
access controls to be put in place. This
frequently results in data access challenges for
users, as well as significant efforts (time and
cost) to build and implement those data
controls.
4. Insufficient 360 views to enable critical
business uses cases
Every organization aspires to leverage all their
customer data in a way that is fully actionable
across all channels. Many have not succeeded.
Despite other business challenges, data quality
issues are still a major inhibitor. Data silos, data
duplication and lack of entity resolution
capabilities are major factors that prevent
organizations from achieving reliable and
trustworthy views of their customers.
4 IBM Academy of Technology
ARB-1316
Data Fabric
Key to Data-Driven Transformation
A Data Fabric with extensive automated capabilities is key to helping
organizations empower users with easy to find, consumable, and trusted
information. Faster data access drives quicker insights and better business
outcomes, all while keeping data access and usage controls in place.
What is the path forward?
Data Fabric is a concept and framework, which includes an overall
architecture and supporting capabilities, that allows data to be shared easily
across a hybrid cloud landscape, while ensuring data and AI governance (IBM,
2022). The obstacles to data location or data type are minimized, rendering
maximum flexibility to the end users. This means that organizations no longer
need to move all their data to a single location/data store or have a completely
decentralized approach. A Data Fabric implies that there is a balance between
what needs to be logically or physically decentralized and what needs to be
centralized. There is no limitation to the number of data stores (purpose fit
data stores) that can participate in the Data Fabric ecosystem.
Many organizations are now moving to a multi-cloud transformation model
and even to a hybrid, on-premise, and multi-cloud model. In many cases
though, this data remains largely siloed, with minimal data governance which
creates a lack of user trust in the data assets creating a very challenging data
landscape.
From a business perspective many data needs are unchanged, but the needs
may be compounded based on the availability of more types, sources, and
locations of data. The expansion of needs across a broader set of data assets
in multiple locations creates a more complex environment and a potential for
greater uncontrolled costs. But a single view of the customer, enforcement of
regulatory and compliance requirements, and business intelligence remain
table stakes to success.
This brings us to the core principles of a Data Fabric. It is ultimately a
comprehensive, flexible, and extensible means to share, virtualize or
distribute data in a way that enables ease of use while ensuring data
governance and compliance requirements are met. There are capabilities
within a data fabric which accommodate various types of workloads and
workload requirements. For example, will data be processed in place? Does
data need to move into memory? Will copies of data be needed? A data fabric
can provide the best approach based on use cases and workload
characteristics that impact the solution. Performance, cost, compliance, and a
handful of additional nonfunctional requirements will drive how data is
managed. This is not about nothing moves, or everything moves, it's about the
balance on the needs and constraints.
IBM Academy of Technology 5
ARB-1316
Data Fabric Defined
A data fabric is a conceptual framework and architecture
strategy that better aligns with emerging characteristics
in the flow and use of data in enterprises. It is not a
product. A data fabric describes a distributed model of
data management where data may reside, be managed
and made available across a hybrid multi-cloud
infrastructure. This includes a network of on-premise,
cloud and edge sources. The architecture is fluid enough
to recognize that various data operations may occur
anywhere within the fabric and there are appropriate
integration features, security and controls including
governance and stewardship to support it. This is an
enabler for an enterprise to leverage data assets
whenever and wherever it is appropriate including in
near real-time fashion.
History and lineage of Data Fabric
Enterprise data management grew out of a desire to
consolidate and centralize large volumes of data into
data warehouses, then later into data lakes to make data
more accessible for analytical processes. However,
several factors made these structures obsolete and
inefficient (IDG, 2021, September 7; The rise of the Data
Fabric). First, the sheer velocity and volume of data that
enterprises capture quickly made storage and transfers
costly. Second, increasing demand and expectations
from technical and business executive stakeholders
drove the demand for an increased level of automation
and self-service to reduce time to value.
Centralized Structured Centralized Structured & Network of Structured and
Governed Data Unstructured Data Governed Data Unstructured Governed Data
Figure 1 – From Data Warehouse to Data Lakehouse to Data Fabric
Data Warehouse
For almost two decades, the single focus for organizations was the creation of data warehouse
architectures. Underpinning all of these, irrespective of the data warehouse approach chosen was the need
to consolidate and reconcile data coming from many sources. The process itself was extremely code
intensive and time consuming.
Data Lake
The advent of big data and NoSQL technologies meant that organizations saw this as an opportunity to avoid
expensive data movement and duplication. To enable faster sharing of data and accommodate data in
additional formats such as unstructured, semi-structured, streaming data etc. resulted in a data lake. It
enables data to be onboarded at speed via an Extract Load then Transform approach. It has been key in
fulfilling data science use cases. This led to the realization that data was only useful to the business if it
could be found and understood. The emergence of the Data Catalog made its way, as the means to achieve
a conformance of the business meaning of data.
6 IBM Academy of Technology ARB-1316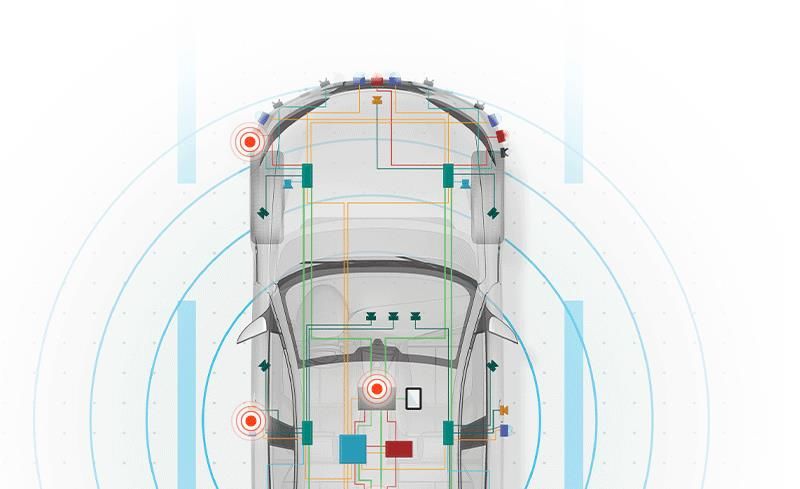
Data Lakehouse
A Data lakehouse was born from the motivation to integrate a cataloged data lake with a traditional data
Warehouse. There was realization that each platform has their strengths and weaknesses, and both
complement each other. Traditionally, data warehouses were used to support transactional and operational
use cases based on structured data. Data Lakes were used to support use cases requiring unstructured or
semi structured data typically found in in data science, IOT or other use cases.
Data Fabric
This leads us to where we are today. Organizations are looking to evolve the data ecosystem to improve and
rationalize how to best manage and bring this polyglot of data to different business users in a consumable
fashion. A data fabric focuses on intelligent data integration through technologies such as data
virtualization, batch, real-time, and event driven architectures. Automation of federated metadata catalogs
and the notion of active metadata (knowledge catalog) which connects data across distributed systems are
key in enabling a self-service experience.
How does it integrate with Data and AI ecosystem?
A data fabric doesn't require all data to be moved to a central repository. It leaves data to reside in
repositories throughout the organization while allowing the data to be used by a data consumer anywhere in
the organization. In a data fabric each data repository is a node, and the nodes are connected (networked
into a constellation) together with governance and security policies applied to a granular (cellular) level.
Silos inherent in large organizations dissolve, while allowing the owners of data to maintain control over,
responsibly for, and stewardship of their data.
A data fabric adds a layer of governance and cataloguing that connects data lakes, data warehouses, and
various other data repositories throughout an organization to each other and to a diverse set of end
consumers such as an analyst, data scientist or developers who need to use data. Each data repository
becomes a node in the data fabric. Data can be on premise, at a hyper scaler, or on any network in a multi-
cloud environment. It can be on any platform such as DB2, Oracle, BigQuery, Snowflake, Teradata, Hadoop,
MS SQL, IMS, VSAM, or any other platform that accepts JDBC or API calls.
A data fabric takes its place within an overall data operations ecosystem in an organization. A data fabric
needs to span and be referenced by some, or all the main steps in a typical end-to-end data pipeline.
Figure 2 – Data & AI Ecosystems integrated with a Data Fabric
ARB-1316 IBM Academy of Technology 7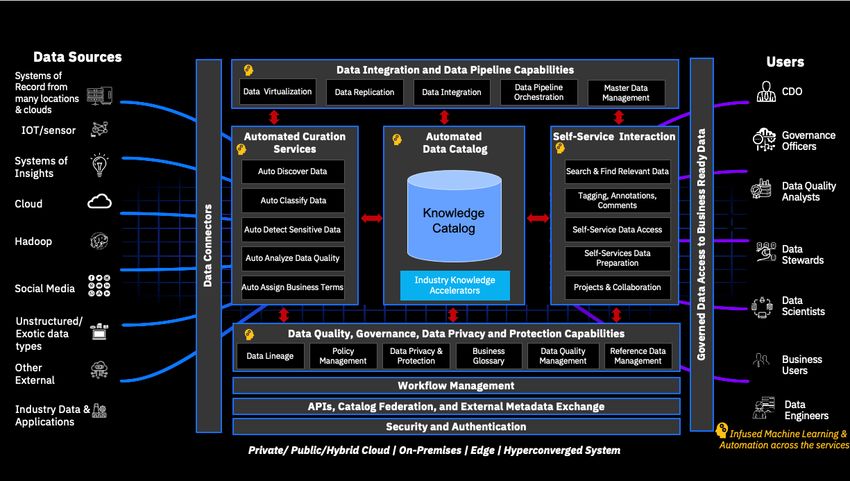
What is the value proposition?
So, what are the implications of such a framework to some
of the key personas.
To the business user:
• Faster and more accurate insights due to easy access
to high quality data
• Ability to focus time on analyzing data rather
than finding, and preparing data
• Frustration-free self-service data shopping experience
• Avoidance of biased or incomplete analysis due to
data restrictions
• Increased compliance and security despite full
analytics utilization
• Accelerated time to value resulting from frictionless
access to data across the hybrid landscape
To the technical community
• Decreased effort to maintain data quality standards
due to fewer data versions and the ability to detect
and remediate data quality issues
• Reduced infrastructure and storage cost (consolidated
data management tools and reduction in data copies)
• Faster and simplified data delivery processes due to
flexibility and advance optimization of data flows
• Reduction in efforts for data access management with
automated global policy enforcement
• Improved regulatory compliance across the
hybrid landscape with automated global enforcement
To the CDO
• Increased compliance and security despite full
analytics utilization
• Reduction in time and effort to address and implement
requirements for new regulatory compliance needs
• Increased time to value and improved productivity of
uses by enabling self-service data access at scale
while ensure data is fully managed and governed.
• Increased ability to provide value from existing data in
support of new business initiatives and
implementation of new uses cases
A data fabric provides the capabilities that support each of
these crucial benefits thus enabling users to leverage data
with greater trust and confidence.
A data fabric provides a simple and integrated approach
irrespective of what that data is or where it resides (whether
in a traditional datacenter or a hybrid cloud environment, in a
conventional database or unstructured data).
8 IBM Academy of Technology
ARB-1316Data Fabric vs. Data Mesh
The concept of a data mesh has come to prominence roughly at the same time as a data fabric. So, what are
they? How do they relate? How to position these concepts?
Are data fabric and data mesh concepts or technologies?
Both are architecture concepts, and both have people, process, and technology implications. Both data
fabric and data mesh follow use-case driven design, and both seek to solve the challenges of data sprawl,
data governance and data availability. Ongoing data discovery and self-service data knowledge catalogs are
key aspects of both approaches.
Data mesh architectures are technology-agnostic, designed for analytic use cases with decentralized data
and data governance. Data ownership relies on localized data products with a focus on reusability.
Data fabric architectures are designed for both analytic and operational use cases. While data fabric
provides a unified view of all data assets, actual data storage may be decentralized, centralized, or a mixture
of both. Likewise, data fabric architectures support multiple organizational structures from federated to
distributed. Finally, data fabric architectures leverage artificial intelligence (“AI”) and machine learning
(“ML”) technologies to automate data discovery, data classification, and policy enforcement.
Can a data fabric and data mesh co-exist, or do you need to choose one approach over the other?
You can implement a data mesh architecture leveraging the data discovery and analysis capabilities of a
data fabric. A data fabric brings capabilities including active metadata, AI/ML automation, multi-modal data
governance and compliance to a data mesh. In the real world these concepts need to co-exist, and any
technology solution needs to support both concepts (Beyer, 2021, November 24 Are Data Fabric and Data
Mesh the Same or Different?).
Figure 3 depicts the high-level implementation of both approaches.
Data Mesh Data Fabric
Analytic Use Cases Analytic and Operational Use Cases
Use-Case-Driven Design Use-Case-Driven and Reusable Design
Ongoing Data Discovery Automated Data Discovery and Classification
Smart Integration and Unified Lifecycle
Intelligent 360 Match
Distributed Policies Centralized Policy Enforcement
Distributed Data Governance Federated Data Governance
Data Catalog Active Knowledge Catalog (AI/ML)
Common Data (Master, Reference, Hierarchy)
Distributed Data Distributed and Centralized Data
Enables automated data management
and cross-platform orchestration
Figure 3 - Data Fabric + Data Mesh in a hybrid multi-cloud architecture
ARB-1316 IBM Academy of Technology 9Data Fabric
Reference Architecture
A data fabric calls for a reference architecture that is applicable across
all environments including hybrid cloud, multi-cloud, on-premises, and
Edge because data is either stored, in-transit or in-use across these
environments.
What are the critical capabilities of a Data Fabric solution?
We allude to the six broad areas in a data fabric. These are depicted in
figure 4 and are typically bookended by data sources and data
consumers. These areas address capabilities that need to operate in a
flexible, interoperable manner, thus enabling the architecture to
support heterogeneous environments in any enterprise.
We show you how each component plays a critical part in a data fabric
architecture. Three levels of a data fabric reference architectures are
presented:
1. Bird’s eye view
2. Detailed view
3. Operational view
10 IBM Academy of Technology
ARB-1316In the paper How and Why to DataOps (Mezzetta, et al., 2022), DataOps is described using a car
manufacturing assembly line that produces high quality cars (data) with speed, reduced costs, and
efficiencies. DataOps plays a key role in operationalizing a data fabric architecture. Building on the car
analogy, a Data Fabric can be thought of as a self-driving smart car. It can drive independently on its own
or have a human driver. Its smart enough to know when it needs to accelerate and when it just needs to lay
back, observe, and learn. It analyzes what it learns and provides recommendations to improve operations.
If we bring this back to a Data Fabric and DataOps, both approaches are complementary to each other and
related. Key components of a data fabric architecture will be discussed leveraging definitions from the How
and Why to DataOps white paper.
Birds eye view
Data Consumers
5 2 4 6
Augmented
Self Service |
Knowledge
APIs
Graph
Find,
Unified
Collaborate,
metadata view
use data
/ Insights to
Knowledge automate /
assets / data Data
Catalog products Governance
meaning to
data fabric
Management Security
1 3
Sharing Compliance
Data Prep | Data
Delivery | Orchestration |
Integration DataOps
Data made Continuous &
available to timely flow of
users / Policy data across
driven the data fabric
Integration
Data Sources
Figure 4 – Core Data Fabric architecture layers (Smart Car Analogy)
ARB-1316
IBM Academy of Technology 111. Data Prep | Delivery | Integration
A data fabric needs to support different modes of data delivery (ETL/ELT, data
virtualization, streaming, replication, messaging, etc.) Data preparation needs to deliver
high quality data for data consumers based on a diverse set of delivery methods. Data
preparation tasks are performed by data producers.
Data preparation includes data transformation and data cleansing based on data quality
checks. It is essential that high-quality data passes the quality control checks in a
pipeline. Data observability occurs in parallel with data preparation. When data fails data
quality checks, errors need to be addressed immediately in a DataOps pipeline. Live
notifications should be sent to stakeholders to drive remediation.
The ingestion components of a data pipeline are the processes that read data from data
sources
• Batch ingestion is a pattern used to extract and operate on groups of data. Batch
processes are sequential: the ingestion mechanism reads, processes, and outputs
groups of data according to defined criteria. The process runs on a schedule or
based on triggers.
• Streaming is an alternative data ingestion pattern where data sources transport
along each unit of information. Streaming ingestion is used when there is a need for
real-time data for use with analytics that require minimum possible latency.
Once data is ingested from source systems, or virtualized from the source systems,
the structure or format may need to be adjusted. Transformation processes include
mapping with descriptive data, filtering, aggregating and integrating multiple sources,
tables, columns, and records. The timing of transformation depends on data replication
process i.e., ETL or ELT in the data pipeline. Data integration capabilities to extract,
ingest, stream, virtualize, and transform data, are driven by data policies. These policies
may include maximizing performance while at the same time minimizing storage and
egress costs. The polices may also dictate the ability to train AI/ML models without
copying or moving the data. With data virtualization data can be refreshed from the
source in near real time to provide near real time insights.
Data delivery serves a diverse set of data consumers. To support a scalable data delivery
approach there needs to be a seamless data delivery method that is integrated across its
platform services. It needs to follow data standards in the handling of data to support
data delivery across a diverse set of data users, data types, systems,
or virtualized within source systems.
ARB-1316
12 IBM Academy of Technology2. Augmented Knowledge Graph
This is where a unified metadata view provides meaning to a data fabric. The knowledge graph
leverages metadata in the knowledge catalog to provide semantic search and leverage NLP to
improve the users view to quickly find assets and artifacts as well as visualize relationships
across the assets of interest.
Active Metadata
Active metadata is the foundation for a Data Fabric architecture. It creates an intelligent layer
by executing analysis and recommendations from the metadata collected. Metadata can be
passive or active. Passive metadata is technical metadata - schemas, data types, models, etc.
It can include business metadata and operational metadata. It represents collected metadata
although does not generate action. Active metadata on the other hand, collects, analyses,
derives insights and recommends action to be taken based on the enriched metadata.
Enriched metadata includes descriptive statistics and insights derived from the application of
machine learning.
Machine Learning and AI
Machine Learning and AI are the enablers of active metadata. Metadata is collected over time
based on data integration activities where it is monitored. ML/AI learn and identify patterns
and relationships leading to potential predictions and/or recommendations to effectively
improve data management.
Semantic Data Layer on Knowledge Graph
A semantic data layer focuses on enriching data with semantic understanding. An example of
this is mapping business language to technical metadata such as Table, Column or File names
to facilitate data discovery and intuitive understanding of the data. A semantic data layer is
built via a knowledge graph also known as a semantic network. This represents a network of
real-world entities (e.g., objects, events, situations, or concepts). It also illustrates the
relationships between them. This information is usually stored in a graph database and
visualized as a graph structure. A knowledge graph is made up of three main components:
nodes, edges, and labels. Any object, place, or person can be a node. An edge defines the
relationship between the nodes. A node can be a client, and an agency. An edge would be
categorizing the relationship as a customer relationship between the client and agency.
Now if we marry these two concepts, active metadata, and knowledge graph, it creates what
we call an Augmented Knowledge graph. This provides a powerful understanding of enterprise
data, its definition, and its relationships to other data. As well as undiscovered relationships
through inferencing.
ARB-1316
IBM Academy of Technology 133. Data Orchestration | DataOps
The timely and continuous flow of data is key to any data fabric. DataOps adheres to data governance, data
privacy, regulatory policies, and data quality to ensure there is consistent data across environments.
DataOps is a discipline focused on the delivery of data faster and cheaper to derive business value quickly.
It focuses on modernizing data management via automation, quality control, reusability, and self-service.
It follows the best practices of DevOps and Agile. Although, the implementation of DataOps to data, is
nothing like DevOps to code. Data is unique in many respects, such as data quality which is key in enabling
trust in data. DataOps is an accelerator to a Data Fabric architecture. It provides an operational layer
for managing data as a product. It focuses on automation of data pipelines, data orchestration, quality
monitoring of distributed data storage and drills down on efficiencies to deliver high quality data to data
consumers.
Data orchestration is a process enabled with a tool to help data professionals create data pipelines and
workflows. The orchestrator tool helps automate and re-use data pipelines or workflows based on the
premise of distributed data sources. It breaks the data pipeline components into smaller (reusable) steps.
It then connects these smaller steps to build a seamless integrated end-to-end data workflow. Data
orchestration encompasses the processes of data governance, data preparation, data storage and can
integrate with several pipelines for a diverse set of use cases such as a machine learning pipeline for a data
science or business intelligence.
4. Self Service | APIs, Services and Tools
A data marketplace is where users can easily find, understand, use, collaborate and get access to data
(query data anywhere). Managing data as a product is key in this capability. Various data products drive the
discovery of data assets, their use and collaboration with various consumers. The notion of self-service is
to enable the ability to share data and data derived assets such as dashboards, machine learning models,
or queries in a scalable manner. This represents the ability for data owners to manage the lifecycle of their
data to freely create, publish, govern, and share data. Self-service capabilities are needed by data
consumers to search, discover, request access, and consume data without relying on IT.
5. Knowledge Catalog | Management | Sharing
A Knowledge Catalog is a collection of metadata, combined with data
management and search tools, assisting analysts and other data users in
finding the data that they need, by serving as an inventory of available
data assets, while providing information to evaluate the data’s fitness for
use. It serves as a single source of truth and a logical single point to
enable data access. Once such a catalog is created, it is then possible to
add various data assets, whether these are connected assets,
connections, or relevant local files. A data steward can pull together, in
one central place, the various data assets to be processed with their
corresponding data location. Access to this catalog can be opened to the
enterprise to expose available data for use. A Knowledge Catalog also
enables Federation while maintaining a centralized view of enterprise
metadata.
Federated Catalogs
Federated Catalogs enable the stitching necessary for metadata
management across distributed data storage, locations, and tools. Where
multiple catalogs can exist, reconcilement of the metadata at a global
level may be needed. This would be applicable in larger organizations
perhaps by Lines of Businesses or driven by the complexity of an
organization. An example use case might be, where one catalog serves
line of business A and another services line of business B, but the
corporate enterprise COO’s team required a view across lines of business.
14 IBM Academy of Technology
ARB-13166. Data Governance | Security | Compliance
Unified definition and enforcement of data policies are tied to the other layers. These areas
are key to maintaining data quality, creating policies to control access to data, and provide
data stewardship. Types of capabilities included in this space:
• Data Security & Privacy Policies - Access control to environments, role-based access,
data encryption, obfuscation, virtualization
• Catalog and Business Glossary – Collection of both technical and business metadata
for data assets and other data derived assets (i.e., dashboards or machine learning
models)
• Enterprise Data Standards - Enforce the conformance of data policies,
definition, structure, and management of data
• Master Data Management - Manage / integrate master and reference data
• Regulatory and Compliance controls and policies e.g., data sovereignty and on-soil
This leads into a technology-agonistic reference architecture that is also agnostic to data
environments, processes, use and geography. It helps automate data discovery, data
governance, and data consumption. The reference architecture is based on data sources,
users, use, and flow of data. The goal is to be able to synthesize all this into physical data
architectures that deliver all data needs. A Data fabric architecture can help implement
commonality such as in data access methods, data security and data curation after discovery
and classification to create a data catalog.
Distributed data topology and distributed data methods infused with machine learning are
the new automation paradigm. Automation accelerates the data curation process, enabling
data consumers to obtain data quicker. In this process, a governance catalog is known as a
knowledge catalog. This helps in managing distributed data in a unified way eliminating data
management siloes.
A drill down of the six areas leads to a reference architecture that is applicable across
industries and domains including Private, Public, Hybrid Cloud and Edge locations. This is an
AI-infused composable architecture built for all cloud environments.
ARB-1316
IBM Academy of Technology 15Detailed View
The architecture depicted in Figure 5 represents the components described in the birds eye view 1 to 6.
It shows a range of intelligent integration styles to extract, ingest, stream, virtualize and transform data,
driven by data policies.
One of the key aspects of a data fabric architecture is to provide a unified definition, enforce data
policies, data governance and data stewardship. The layer titled "Data Integration and Data Pipeline
Capabilities" act as the facilitator between data sources and all entities that consume the data.
Figure 5 – Components of a Data Fabric Architecture
16 IBM Academy of Technology ARB-1316Three parts in a Data
Fabric Architecture
1.Data sources
Within an organization or a company, many systems,
both internal and external to the organization can be
considered data producers or data sources as they
collect or generate data that is stored to be later used by
data consumers. A data source is the location where
data originates, and a consumer can access and use it.
2.Data Fabric Solution
Products from a diverse set of vendors can satisfy
different components and processes illustrated in this
reference architecture. Some might specialize in
different facets and require several vendors to compose
an overall data fabric solution. A custom solution, while
complex might also be a consideration. While this paper
has focused on providing a balanced view to what a Data
Fabric is, it’s natural to mention IBM has a data fabric
solution which is part of Cloud Pak for Data. This is a
unified platform that spans hybrid and multi-cloud
environments to support a wide variety of business use
cases. It combines critical core features like data
integration, data virtualization, data governance,
analytics, data quality, and a knowledge catalog with a
semantic data layer for active metadata management.
This is available in a single, cohesive platform, infused
with machine learning and automation.
3.Data consumers
A data consumer is any user, application, or system that
uses data collected by another system or stored in a data
repository. Data consumers can participate in the
definition of business terms to ensure usability within
their business processes. Data consumers can consist of
business analysts, data engineers, data scientists,
architects and developers or can represent several data
systems such as data lakes, data warehouses, data
lakehouses, and business applications (e.g., financial
planning, BI reporting , edge assets with built in
analytics, and intelligent assistants).
IBM Academy of Technology 17
ARB-1316Operational View
Figure 6 provides an operational view of a data fabric architecture. It depicts the fabric interoperating
with a broader ecosystem of catalogs, data marketplace(s), data science components and integrated
into CI/CD pipelines. The components within the operational data fabric architecture are capable of
operating in a hybrid multi-cloud ecosystem.
Figure 6 - Data Fabric Architecture – Operational view
18 IBM Academy of Technology
ARB-1316The following is an outline of the different components of a Data Fabric Architecture – Operational
View:
Data Fabric Automation Framework - This is the capability that essentially creates the “fabric” of
interconnected data assets, business and technical metadata to enable an overall network of
knowledge. The processes that make up this framework are highly automated to ensure the data fabric
is constantly updating and reacting to changes in the underlying physical environment.
Knowledge Catalog – Acts as the central source (library) of information regarding various types of data
assets and their relationships along with data governance and regulatory information relevant to the
data assets. The metadata for the data assets includes the location of data assets, business term
assignment to assets, asset relationships, data lineage, data quality rules, governance policies
(enforcement), as well as data quality results and scores. It also provides the ability to tag, classify, and
include custom attributes for an asset. The knowledge catalog leverages automation and AI to minimize
manual user intervention and to maintain catalog currency. It supports a robust open API library to
readily integrate with other catalogs and the CI/CD pipeline processes within an organization. The
knowledge catalog is the cornerstone required to support a rich ecosystem of data in a “shop for data”
self-service paradigm.
Industry Data & Applications - This is the range of different applications and sources of data that an
enterprise needs to integrate with as part of their data fabric ecosystem. This can consist of data from
internal or external sources, structured or unstructured data, and data from various 3rd party
marketplaces or APIs.
Real-Time, Streaming, & Batch - This component is the set of different capabilities needed to onboard
the data from the various source Industry Data and Applications.
Data Connectors - virtualized processing & direct movement - The set of capabilities to enable the
virtualization and importing of data from the various source Industry Data and Applications.
MDM/Entity Resolution/ RDM/Product Catalog - This is where the various hubs of data such as
Customer, Product and Reference data are managed.
Real-Time Business Events - This is the capability where relevant business events, including Systems
of Engagement (SoE) and Systems of Record (SoR), are integrated into the overall set of assets to be
managed by the data fabric (e.g., the integration of the output of specific business processes).
Data Marketplace - This is the range of area that the organization maintains to provide the various
consumers with the data assets that they need to support their self-service use of the data fabric. This
marketplace can consist of specific data assets created by the organization.
Deep Analytics and Data Science - This is the area where the capabilities required by the data science
community to support their analysis are integrated and managed. This area is intended to drive a degree
of consistency and sharing of assets and capabilities across the data scientists to enable them to most
efficiently carry out their tasks.
Data Consumption - This is the wide set of capabilities to enable the different users/consumers to
access and exploit the various assets available within the data fabric ecosystem. This will support users
of a range of different technical skills as well as supporting users across the different areas of the
enterprise.
IBM Academy of Technology 19
ARB-1316Enterprise Analytics - This is the set of different analytics capabilities that are infused throughout the
data fabric ecosystem, for example the various data preparation, data visualization, data storage
capabilities.
Data Quality & Data Governance - This is the layer of capabilities that enforce a consistent and
audited approach to the governance of data and the management of the quality of the data. This layer
will include capabilities such as data lineage, policy management, data catalog, and data quality
management
Security - This is the overall layer of security integrating with the enterprise IAM (Identity Access
Management) to ensure that access to the different components and assets are managed in an
appropriate and efficient manner using RBAC (Role Based Access Control) and/or ABAC (Attribute
Based Access Control).
Additional Data Fabric Accelerators :
There are a range of additional capabilities that may be typically implemented in conjunction with the
overall Data Fabric environment :
• Analyze and create an inventory of objects like
Databases/Views/Tables/Patterns, query-level redundancy, complexity,
Data & Workload workload interdependences, utilization/capacity needs, top resource
Migration Analysis consuming applications/files/users
• Prescribe/right-size workloads and applications to best of breed target
options
• Metadata-driven data ingestion enables the data pipeline to be flexible
enough to adapt to runtime conditions via automated data quality &
Cognitive Mapping governance as required
• ML auto data discovery, classification, quality, and lineage – sensitive
data detection, quality analysis, and auto-assignment of business terms
• The Data Profiling profiles ALL data as it is landed into the environment
and incorporates the ability to integrate complex data quality metrics.
Data Profiling • Source level, Summary and Detail statistics are actively captured and
easily searched and visualized. In addition to profiling, Cross File
Analysis, Propensity, and other services are available
• SQL-based metadata driven ingestion and curation accelerator which
uses metadata to capture the format of the files coming into the
platform and describes how external tables, target tables and views are
Framework
built
• This minimizes the need for custom data ingestion interfaces for each
file / event that could pass through an environment
• Execute dynamic source Change Data Capture (CDC) procedures to
Change Data Capture merge inbound data and events to the platform without having to custom
code for each data source
• Python based data migration testing utilities which create tolerance-
Testing Accelerator based comparisons of datasets hosted in different storage technologies
– used for simplification and automation of data migration components.
20 IBM Academy of Technology
ARB-1316How can organizations exploit Data Fabric?
A data fabric infrastructure exists to support the overarching needs and objectives of the business
and of business-oriented stakeholders and users. If any technical ecosystem is not demonstrably
contributing to the bottom line of the organization, then what use does it serve? The same applies
to a data fabric. Any data fabric initiative needs to have a clear definition of the business
challenges that it will address and the support from key relevant business stakeholders to
succeed.
Organizations should define metrics that are representative of the value in using a Data Fabric.
Here are a few areas that could be measured:
• Making better decisions, or making them faster or cheaper
• Access and use of data that was previously unusable
• Improving the quality of insights provided to the business. Potentially including the associated
data quality rules and KPIs
• Consistent level of data for use across the organization
• Data democratization across the organization - allowing everyone to ask the right questions
from data
• Data literacy across the organization and associated considerations such as training people to
use/leverage data
The underpinning of all of this should be motivation to help an organization and its culture be
more data driven. A key aspect to address is, how to bridge the gap between business and IT
functions to ensure an efficient deployment and ongoing evolution of the data fabric. It would be
useful to get a sense of what type of business challenges can be addressed by having a data fabric
in place.
ARB-1316 IBM Academy of Technology 21How a data fabric facilitates an
organization’s move to be more
Data Driven
There are several aspects for an organization to be truly data driven,
however a data fabric strategy plays a critical role in all of these.
Vision of what it means to be data driven - a company being data
driven does not happen by accident. It must be defined, planned and
directed from the highest level of the organization. There needs to be
an overall business vision on exactly what does data driven mean to
this organization. From the vision, there needs to be a business
strategy defined with goals, objectives, (including benefits and
measurable metrics for success). From there the appropriate
technical strategy and supporting data fabric architecture components
can then be defined and mapped to the business strategy objectives
and goals. What are the benefits, what are the precise and measurable
metrics to gauge the success and what is the necessary infrastructural
and organizational changes to be put in place? Such strategic planning
activities need to include defining which components of the overall
data fabric ecosystem will play a role in this vision.
Infrastructure to enable a data driven approach - a data driven
approach is only feasible if the infrastructure is in place to ensure the
data is Findable, Accessible, Interoperable and Reusable (FAIR). If the
data does not meet these characteristics the employees, suppliers
and customers of the organization will not have the required level of
trust and confidence in that data. Certain components of the data
fabric are critical to this overall infrastructure: data governance, data
virtualization, and network. This infrastructure can include
components in the areas of data quality, data governance, and data
virtualization.
Organization and culture - in the end, it is critical the people and
units within the company have the necessary education, motivation,
and direction to truly make data a core part of their day-to-day
activities and decision-making processes. In this case the interaction
of data fabric components is to ensure the appropriate stakeholders
are involved in the definition of the required data fabric infrastructure.
Then, as the data fabric infrastructure is evolved, it would be critical
that the right users from across the organization are actively involved
in the various discreet prototyping and proof-of-concept activities as
that infrastructure is rolled out to ensure critical user feedback is
incorporated, but also to ensure the required level of ownership and
buy-in is gained from all relevant areas of the business. For the vision,
there needs to be a business strategy defined with goals, objectives,
(including benefits and measurable metrics for success) From there
the appropriate technical strategy and supporting data fabric
architecture components can then be defined and mapped to the
business strategy objectives and goals.
22 IBM Academy of Technology ARB-1316A Data Fabric assists in bridging the gap
between Business and IT.
A data fabric is critical to the success of a data driven culture led by the C-Suite. For data to
remain distributed throughout the organization, a culture of data stewardship must be
nurtured. For data to remain where it is created and/or curated, the owners of the data need
to understand their responsibilities for maintaining the security and integrity of that data, and
their responsibility to the enterprise to share their data with other parts of the organization as
needed.
IBM's Institute of Business Value Study - The Intelligent Operations Advantage published in
2020 asked 13,000 C-suite executives "what it takes to lead in a world brimming with bytes"
(IBM, 2022, 2019 COO Study: The intelligent operations advantage). The study identified a
small group of enterprises that stand out from the rest and dubbed them torchbearers. The
primary characteristics of torchbearer companies and all others are COO's that embrace agile
methodology and a data driven culture.
"The Chief Operating Officers (COOs) who help run these organizations have mastered the ability
to transform information into intelligence and operationalize the insights it provides. They
understand how the digital economy is redefining value, and while they recognize that data is an
asset, they realize trust determines what it’s worth. "
"We also found torchbearer COOs excel at leveraging data to assist with decision making. By
using clear, clean, and curated data, along with AI and other technologies, to guide their
operational decisions, these leaders can forestall problems, as well as optimize asset utilization
and energy consumption. Torchbearer COOs are well on the way to building supply chains that
are self-learning and self-correcting. "
These strengths have paid off handsomely, resulting in:
• 64 percent of torchbearer CEOs have presided over superior revenue growth, and 66
percent have delivered outsized profits
• 80 percent intending to invest heavily in artificial intelligence
• 81 percent of torchbearer COOs say data helps their enterprise strengthen the level of
trust that customers place in it
• 87 percent of the CEOs who took part in our study regard data as a strategic asset
• 62 percent of CEOs identify technology as a major factor, with market dynamics trailing
behind at 54 percent
• 79 percent of torchbearer CEOs head organizations with a history of operating at the
leading edge
Other considerations for increasing Business and IT user communications
In a federated data model collation, integrity and security of data is also
distributed. Education in data management and stewardship is vital. Empowering individuals
throughout the organization to manage and responsibly share data with other users within the
organization is a key part of embracing a data driven enterprise. While business controls help
navigate great distinction between what can be shared and what should be shared.
Creating a data driven culture can be difficult, however it is a trust in data that sets these
companies apart. The leaders of Torchbearer organizations recognize that decisions must be
based on data and not assumptions and that data must be trusted.
ARB-1316
IBM Academy of Technology 23Typical use cases It is important a data fabric addresses the various needs and challenges of the business. Looking at some of the typical executive and C-level executive personas, a data fabric should bring a range of overall benefits. • Chief Data Office, VP Business Analytics: time to value from analytics, consistency and integrity in data, leverage in data investments • LOB: analytical insights and decision making, especially for customer, core processes, • VP Customer Experience: customer insights to drive monetization and lifetime value • CIO: Ensure security and governance; Use IT, data and AI to drive transformation • COO: Operational resiliency, regulatory compliance and cost savings • Chief Risk Officer: Improved data accuracy and insights, compliance While a Data Fabric architecture is use case agnostic, here are some examples of how it can provide value across specific industries. • Financial Services/Banking: data fabric brings an opportunity to unify the view of data from across the organization addressing both business areas such single view of customer, to supporting key risk and compliance in a range of areas such as data protection, capital adequacy, anti-money laundering, and financial accounting. • Insurance: Many of the key Insurance business processes such as the building of life insurance policies or analysis of claims require the integration of significant amounts of data from across the enterprise and from 3rd party providers. Data fabric enables the efficient and potentially real-time integration of such data to underpin these insurance business activities. • Autonomous, Connected, Electric, and Shared mobility (ACES): With the emerging software-driven transformation impacting the value chain, data fabric will help to loop UX feedbacks back into innovation and product development in a collaboratively manner by taking into account the challenges of ACES (e.g. Smart city collaboration). • Healthcare: Facilitate the curation of the overwhelming amount of clinical data, genomic data, and social determinants of health data to find the best pathway for prevention/recovery for each patient, member. • Government/Higher Education: Derive insights of all the data collected to align insights to improve policy making. Offer constituents (citizens, businesses, employees, students) a better/insight driven experience for interacting with Government. • Industrial sector: A data fabric has the potential to enable the building of Digital twins to allow the dynamic virtual representation of an asset or process compared to the real-life asset to predict actionable insight using what-if scenarios. 24 IBM Academy of Technology ARB-1316
A Data Fabric Methodology enables the successful
adoption and implementation of a data fabric
A Data Fabric Methodology is a structured, user-centric approach to design and deliver data-centric data
fabric architectures. Driven by guiding principals, the methodology defines the organization, placement,
management and flow of data within a data fabric ecosystem.
1. Guiding Principles
a. A data fabric is iteratively developed within an area of focus based on a given set of objectives or
problems to be solved
b. A data fabric is designed to enable the specialized data needs of users (users, personas, devices, APIs)
and their uses of data
c. Fit-for-purpose data architectures enable the specialized data needs of users
“Single source of the truth” is an objective not an architecture
d. Optimize data persistence and workload placement – unmanaged duplication should be avoided
e. Optimize/reduce data movement (data flows)
I BM Data
f. Design Fabric
to simplify Methodology
data architecture, data management, and data governance (logical to physical)
1 2 3 4 5 6
Guiding Principles Determine the Review current Develop future- Define future Define
scope data topology state topology state physical implementation
instantiation strategy/
approach
Figure 7 – Data Fabric Methodology
© 2022 I BM Corporation 1
2. Determine scope
Determine the scope of your data fabric within your area of focus (business use case). Actual
implementation will start in a focused area and grow over time against a target / evolving future-state
a. Define your area of focus based on a given set of objectives
b. What is the data (subject) within the area of focus?
c. Who are the consumers (users) within the area of focus?
d. What are their uses of data?
3. Review current data topology
If applicable, review/document the current “as-is” data topology. This will provide a baseline to develop an
implementation roadmap against the future-state design.
a. Where is operational and analytic data physically located?
b. What data storage technologies are used for operational data and analytic data?
c. What restrictions or constraints (eg. Data sovereignty, Data Privacy) need to be put in place for these
data stores?
d. What 3rd party data exists and what are the usage constraints?
e. What data processing and data flows exist?
ARB-1316 IBM Academy of Technology 25You can also read

















































