Domain Specific Languages to Tame Heterogeneous and Emerging Computing Systems
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Domain Specific Languages to Tame Heterogeneous and Emerging Computing Systems Jeronimo Castrillon Chair for Compiler Construction (CCC) TU Dresden, Germany The Platform for Advanced Scientific Computing (PASC) Conference Geneva (virtual), Switzerland July 9, 2021

Evolution of computing Transistors (thousands) single-core Use multi-core architectures architectures Dark Si: Post specialize ~2005 Single-threadCMOS? Performance J. Castrillon, et al. "A Hardware/Software Stack for Heterogeneous Systems", In IEEE Transactions on Multi-Scale Computing Systems, vol. 4, no. 3, pp. 243-259, Jul 2018. Frequency (MHz) Typical power q Massive parallel and heterogeneous systems (W) q Specialization: TPUs, AI engines, PCM, … Core count q Interconnected & distributed computing M. Horowitz, F. Labonte, et al. Dotted-line by C. Moore, q Emerging non-volatile memories “Data processing in exascale-class computer systems,” The Salishan Conference on High Speed Computing, 2011 2 © Prof. J. Castrillon. PASC'21. Geneva, 2021

Evolution of computing: Programming Transistors (thousands) single-core Use multi-core architectures architectures Dark Si: Post specialize ~2005 Single-threadCMOS? Performance Frequency (MHz) Typical power (W) The golden era in computer architecture requires Core count major changes in programming methods to democratize heterogeneous and M. Horowitz, F. Labonte, et al. Dotted-line by C. Moore, emerging high-performance computing “Data processing in exascale-class computer systems,” The CIMA Foundation Weather www.eso.org Astronomy Fluid dynamics Salishan Conference on High Speed Computing, 2011 3 © Prof. J. Castrillon. PASC'21. Geneva, 2021

What’s wrong with good old sequential languages? What we want What we (naively) code How many more times should we optimize this manually? What compilers see 4 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Polyhedral compilation: Hope for regular loops q Recognize high-level patterns like matrix multiply-and-add operation (MMA) Peak Intel MKL “Our method attained the performance Open BLAS of vendor optimized BLAS libraries” Polly-opt icc Complex and sensitive pattern recognition to help close the Polly-orig. performance gap clang R. Gareev, T. Grosser, M. Kruse. "High-performance generalized tensor operations: A compiler-oriented approach." ACM Transactions on Architecture and Code Optimization (TACO) 15.3 (2018): 34. 5 © Prof. J. Castrillon. PASC'21. Geneva, 2021
There is only su much we can do/reconstruct… q Lots of progress: polyhderal compilers, trace- driven dynamic parallelization, patterns/ idiom extraction DSLs start here! Bridge gap: Domain experts à C++/fortran DSLs for performance: Halide, Spiral, TVM, TensorFlow, Firedrake… L. Chelini, et al. "Progressive S. Manilov, C. Vasiladiotis, B. Franke. "Generalized profile- Raising in Multi-level guided iterator recognition." CC 2018. IR." CGO 2021 6 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Examples (1): Tensors expressions (CFD, ML) q Expression-language for tensor operations and optimizations q Originally for spectral element methods in computational fluid dynamics source = ... var input A : matrix & var input u : tensorIN & Interpolation kernel var input output v : tensorOUT & var input alpha : [] & var input beta : [] & v = alpha * (A # A # A # u . Fortran and C++ integration [[5 8] [3 7] [1 6]]) + beta * v CC0 public domain N. A. Rink, et al. “CFDlang: High-level code generation for high- order methods in fluid dynamics”. RWDSL’18. N.A. Rink, N. A. and J. Castrillon. “TeIL: a type-safe imperative Tensor Intermediate Language”, ARRAY’19, pp. 57-68 7 © Prof. J. Castrillon. PASC'21. Geneva, 2021

Semantic gap è performance gap source = ... var input A : matrix & var input u : tensorIN & var input output v : tensorOUT & var input alpha : [] & var input beta : [] & 100X v = alpha * (A # A # A # u . [[5 8] [3 7] [1 6]]) + beta * v What we (naively) code What performance experts code 8 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Closing the performance gap q Not really optimization magic q Leverage expert knowledge q Algebraic identities Easy to generate, hard to transform N. A. Rink, et al. “CFDlang: High-level code generation for high-order methods in fluid dynamics”. RWDSL’18. A. Susungi, et al., "Towards Compositional and Generative 9 Tensor Optimizations", GPCE’17 pp. 169–175. Actual code variants © Prof. J. Castrillon. PASC'21. Geneva, 2021

Closing the performance gap q Not really optimization magic Interpolation q Leverage expert knowledge q Algebraic identities 20 Inverse Helmholtz 15 GFLOPs 10 N. A. Rink, et al. “CFDlang: High-level code generation for 5 high-order methods in fluid dynamics”. RWDSL’18. A. Susungi, et al., "Towards Compositional and Generative Tensor Optimizations", GPCE’17 pp. 169–175. 0 10 © Prof. J. Castrillon. PASC'21. Geneva, 2021 2 4 6 8 10 12 p+1
TeML: Meta-programming for tensor optimizations q Generalize for cross-domain tensor expressions q Formal semantics and composition of transformations Formally defined Higher-level transformations transformation primitives via composition A. Susungi, et al. "Meta-programming for cross- domain tensor optimizations" GPCE’18, 79-92 11 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Meta-programming for optimizations: Results Performance of Pluto could be reproduced Higher abstraction à more optimization potential A. Susungi, et al. "Meta-programming for cross-domain tensor optimizations”, GPCE’18, 79-92 12 © Prof. J. Castrillon. PASC'21. Geneva, 2021
TeIL: Formal language – added value A = placeholder((m,h), name='A') q Core common to multiple tensor languages & B = placeholder((n,h), name='B') q Index-free notation and strong type system !" = # h), k = reduce_axis((0, #! #" name='k') q Provably no out-of-bound accesses C = compute((m,#$% n), lambda i, j: sum(A[k, i] * B[k, j], axis=k)) N.A. Rink, N. A. and J. Castrillon. “TeIL: a type-safe imperative Tensor Intermediate Language”, ARRAY’19, pp. 57-68 13 © Prof. J. Castrillon. PASC'21. Geneva, 2021
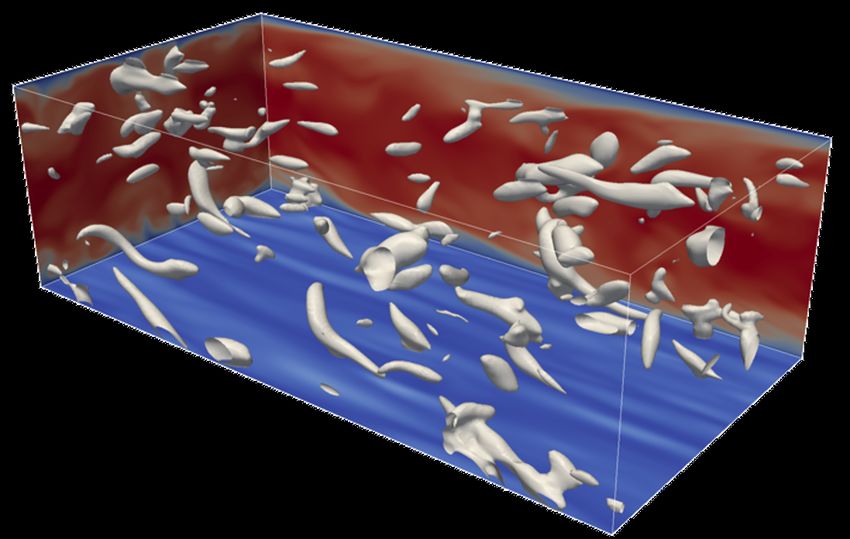
Examples (2): Particle-mesh simulations Vortex ring q Particle-mesh simulations in computational biology P. Incardona, et al “OpenFPM: A scalable open framework for particle and particle-mesh codes on parallel q Discrete/continuous computers”, Computer Physics q Deterministic/stochastic Communications, 2019 Syntax for interact, evolve, automatic insertion of interpolation, … S. Karol, et al. "A Domain-Specific Language and Editor for Parallel Particle Methods", In ACM TOMS’18, vol. 44, no. 3, pp. 32, Mar 2018. N Khouzami, et al., "The OpenPME Problem Solving Environment for Numerical Simulations”, In ICCS’21 pp. 614–627, Jun 2021. 14 © Prof. J. Castrillon. PASC'21. Geneva, 2021
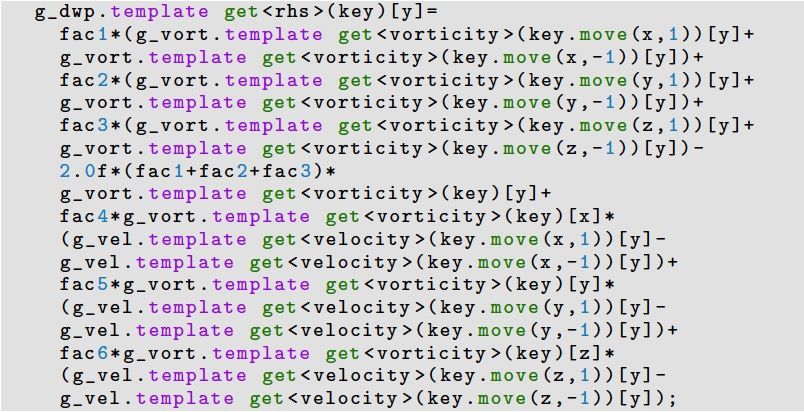
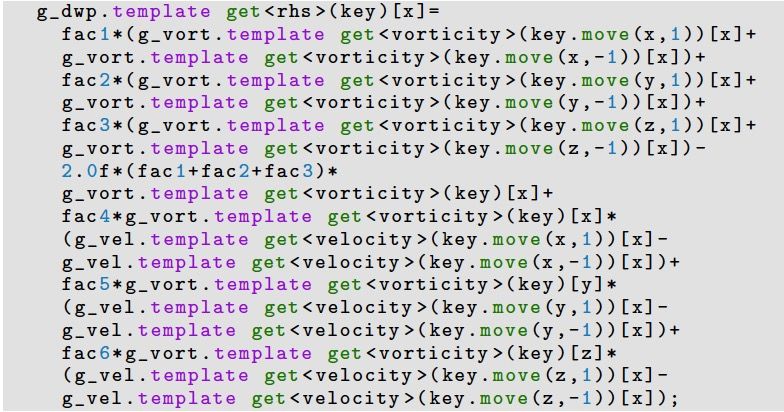
Semantic gap è Debugging gap P. Incardona, et al “OpenFPM: A scalable open framework for particle and particle-mesh codes on q OpenFPM library parallel computers”, Computer Physics Communications, 2019 q Modern C++ template library (for CPUs and GPUs) q Support for dynamic load-balancing, checkpointing and communication abstractions q Template meta-programming = ω . ∇ u + νΔ What we want What we code 3D (already quite abstracted!) 15 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Model-to-model code generation
OpenPME DSL
Intermediate ...
...
representation (IR) ...
while (mloop_iterator_h5a0.isNext())
{
N Khouzami, et al., "The OpenPME Problem
Solving Environment for Numerical Simulations",
OpenFPM }
16 In ICCS’21 pp. 614–627, Jun 2021 © Prof. J. Castrillon. PASC'21. Geneva, 2021Closing the performance gap Lennard Jones Gray-Scott Vortex in Cell (particles, discrete) (mesh, continuous) (hybrid, continuous) 57 LOC vs 40 LOC vs 73 LOC vs 151 LOC 100 LOC 580 LOC Missing loop fusion (to merge mesh processing) N Khouzami, et al., "The OpenPME Problem Solving Environment for Numerical Simulations", In ICCS’21 pp. 614–627, Jun 2021 17 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Higher-level optimizations q Insertion of ghost-gets, based on high-level dataflow Gray-Scott q Model-based auto-tunning for discretization q Theoretical convergence 1x, 8x, 16x more exploration time to steer with various degrees of success search With comparable exploration time, oblivious auto-tuners orders of magnitude worse 18 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Formal language – added value q Mathematical expressions: Possible to explore performance-accuracy trade-offs q Type system: High-level semantics checks (e.g., units) S. Karol, et al. "A Domain-Specific Language and Editor for Parallel Particle Methods", In ACM TOMS’18, vol. 44, no. 3, pp. 32, Mar 2018. 19 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Examples (3): Big data (only briefly) q Dataflow IR from a seqentual syntax (Rust or Java-like) Sequential code (implicit parallelism) Monolithic Microservices Program manual: high e↵ort hard: develop easy: develop Program test test debug debug update hard: easy: Collaboration with update update 20 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Examples (3): Big data (only briefly) q Dataflow IR from a seqentual syntax (Rust or Java-like) q IR to abstract from “cloud ISAs” Sequential code (implicit parallelism) Monolithic Microservices Program Programming Cloud Compiler Model easy: develop automatic: translate test Program optimize debug update Collaboration with S. Ertel, A. Goens, J. Adam, J. Castrillon, "Compiling for Concise Code and Efficient I/O", Proceedings of the 27th International Conference on Compiler Construction (CC 2018), ACM, pp. 104–115, 21 © Prof. J. Castrillon. PASC'21. Geneva, 2021
EVEREST: Efficient large-scale heterogeneous computing q Current work on large-scale EU H2020 project Everest q Stencil and Tensor Operations in Weather Modelling (WRF) q Interplay orchestration (dataflow) and kernels https://everest-h2020.eu q MLIR framework for reusable abstractions CIMA Foundation C. Pilato, et al. "EVEREST: A design environment for extreme-scale big data analytics on heterogeneous platforms”, DATE 2021 22 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Challenges ahead: Emerging memories q Example: Hybrid STT-/DRAM q Placement and layout optimization q Hints for memory controllers F. Hameed, J. Castrillon, TVLSI’19 q Racetrack memories q Extreme density q Sequential bit access per cell Bläsing et al, IEEE Proc.’20 q Memristive accelerators A. Siemieniuk, TCAD’21 q In-memory computing q Compiler abstractions 23 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Architecture and data layout optimization q Underlying idea: Zig-zag through data to reduce number of shifts q Exploit explicit patterns in high-level DSLs q Recognize patterns with polyhedral compilers compulsory shifts compulsory shifts A. A. Khan, et al, "Optimizing Tensor Contractions for A00 A01 A0n-1 B00 B10 Bn-10 Embedded Devices with Racetrack Memory Scratch-Pads”, LCTES’19, pp. 5-18, 2019 overhead shifts overhead shifts à (Bank-0) ~ C (Bank-2) B (Bank-1) DBC:2n DBC:2n+1 DBC:3n-1 DBC:0 DBC:1 R0 A00 A01 A0n-1 B00 B01 R0 C00 C01 B10 B11 R1 R1 A10 A1n-1 An-1n-1 DBC:n-1 Bn-10 Bn-11 Rn-1 Rn-1 n C0 C1 Cn-1 n DBC:n DBC:n+1 DBC:2n-1 24 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Latency comparison vs SRAM q Un-optimized and naïve mapping: Even worse latency than SRAM q 24% average improvement (even with very conservative circuit simulation) 3 SRAM RTM-naïve RTM-opt RTM-opt-ps 2.5 Normalized latency 2 1.5 1 0.5 0 4 8 16 32 64 128 256 512 1024 2048 Avg Tensor size A. A. Khan, et al, "Optimizing Tensor Contractions for Embedded Devices with Racetrack Memory Scratch-Pads”, LCTES’19, pp. 5-18, 2019 A. A. Khan, et al. “Optimizing Tensor Contractions for Embedded Devices with Racetrack and DRAM Memories”. ACM TECS 2020 25 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Energy comparison vs SRAM q Higher savings due to less leakage power q 74% average improvement (in addition to savings due to DRAM placement) 1.2 Leakage Energy Read/Write Energy Shift Energy 1 0.8 0.6 Normalized energy 0.4 0.2 0 SRAM SRAM SRAM SRAM SRAM SRAM SRAM RTM-opt SRAM SRAM SRAM RTM-opt-ps RTM-opt-ps RTM-opt RTM-opt RTM-opt-ps RTM-opt RTM-opt-ps RTM-opt RTM-opt-ps RTM-opt RTM-opt-ps RTM-opt RTM-opt-ps RTM-opt-ps RTM-opt RTM-opt-ps RTM-opt RTM-opt-ps RTM-opt RTM-naïve RTM-naïve RTM-naïve RTM-naïve RTM-naïve RTM-naïve RTM-naïve RTM-naïve RTM-naïve RTM-naïve 4 8 16 32 64 128 256 512 1024 2048 Tensor size A. A. Khan, et al, "Optimizing Tensor Contractions for Embedded Devices with Racetrack Memory Scratch-Pads”, LCTES’19, pp. 5-18, 2019 A. A. Khan, et al. “Optimizing Tensor Contractions for Embedded Devices with Racetrack and DRAM Memories”. ACM TECS 2020 26 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Generalization to stencils and other kernels q Average improvements in performance (~20%) and energy consumption (~40%) rtmst rtm-slt isl isl-rtmst isl-rtm-slt RTM Shifts (normalized) 120% 90% 60% 30% 0% threemm fastwave fdtd-2d diffusion geo-mean syr2k trmm gemm cholesky symm gemver jacobi-2d twomm Advection lu gramschmidt adi bicg syrk doitgen heat-3d Kernel cosmo A. A. Khan, et al., "Polyhedral Compilation for Racetrack Memories", In IEEE TCAD’20, vol. 39, no. 11, pp. 3968-3980, Oct 2020. 27 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Summary q Tame ever-increasing system complexity q Still highly-relevant optimizing compilers (polyhedral, …) q DSL examples: expose higher semantics (efficiency, productivity) q Higher semantics key for emerging accelerators/systems! q Moving forward q Semantic-preserving transformations q Larger use cases (e.g., WRF in the context of EVEREST) q Common abstraction across novel paradimgs (e.g., as MLIR dialects across in-memory computing architectures) 28 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Thanks! & Acknowledgements CO4RTM (Number 450944241) Hasna Alexander Karl Andrés Fazal Gerald Asif Ali OpenPME (Number 350008342) Bouraoui Brauckmann Friebel Goens Hameed Hempel Khan https://everest-h2020.eu Robert Nesrine Galina Christian Julian Lars Felix This project has received funding from the European Union’s Khasanov Khouzami Kozyreva Menard Robledo Schütze Wittwer Horizon 2020 research and innovation programme under grant agreement No 957269 ..., and previous members of the group (Norman Rink, Sven Karol, Sebastian Ertel), and collaborators (J. Fröhlich, I. Sbalzarini, A. Cohen, T. Grosser, T. Hoefler, H. Härtig, H. Corporaal, C. Pilato, S. Parkin, P. Jääskeläinen) 29 © Prof. J. Castrillon. PASC'21. Geneva, 2021
Summary q Tame ever-increasing system complexity q Still highly-relevant optimizing compilers (polyhedral, …) q DSL examples: expose higher semantics (efficiency, productivity) q Higher semantics key for emerging accelerators/systems! q Moving forward q Semantic-preserving transformations q Larger use cases (e.g., WRF in the context of EVEREST) q Common abstraction across novel paradimgs (e.g., as MLIR dialects across in-memory computing architectures) 30 © Prof. J. Castrillon. PASC'21. Geneva, 2021
References [IEEE TMSCS’18] J. Castrillon, et al. "A Hardware/Software Stack for [ICCS’21] N Khouzami, et al., "The OpenPME Problem Solving Environment for Heterogeneous Systems", In IEEE Transactions on Multi-Scale Computing Systems, Numerical Simulations", In ICCS’21 pp. 614–627, Jun 2021. pp. 243-259, 2018. [CC’18] S. Ertel, A. Goens, J. Adam, J. Castrillon, "Compiling for Concise Code [Manilov’18] S. Manilov, C. Vasiladiotis, B. Franke. "Generalized profile-guided and Efficient I/O", Proceedings of the 27th International Conference on Compiler iterator recognition." CC 2018. Construction (CC 2018), ACM, pp. 104–115 [Chelini’21] L. Chelini, et al. "Progressive Raising in Multi-level IR." CGO 2021 [DATE’21] C. Pilato, et al. "EVEREST: A design environment for extreme-scale big [Gareev’18] R. Gareev, T. Grosser, M. Kruse. "High-performance generalized data analytics on heterogeneous platforms”, DATE 2021 tensor operations: A compiler-oriented approach." ACM TACO 15.3 (2018): 34. [TCAD’21] A. Siemieniuk, et al. "OCC: An Automated End-to-End Machine [RWDSL’18] N. A. Rink, et al. “CFDlang: High-level code generation for high- Learning Optimizing Compiler for Computing-In-Memory", IEEE TCAD, 2021 order methods in fluid dynamics”. RWDSL’18. [GPCE’17] A. Susungi, et al., "Towards Compositional and Generative Tensor [TVLSI’19] F. Hameed, J. Castrillon, "A Novel Hybrid DRAM/STT-RAM Last-Level- Optimizations", GPCE’17 pp. 169–175. Cache Architecture for Performance, Energy and Endurance Enhancement" , In IEEE TVLSI, 27, pp. 2375-2386, Oct 2019. [GPCE’18] A. Susungi, et al. "Meta-programming for cross-domain tensor optimizations" GPCE’18, 79-92. [IEEE Proc.’20] R. Bläsing, et al. “Magnetic Racetrack Memory: From Physics to the Cusp of Applications within a Decade”. In: Proceedings of the IEEE 2020. [Array’19] N.A. Rink, N. A. and J. Castrillon. “TeIL: a type-safe imperative Tensor Intermediate Language”, ARRAY’19, pp. 57-68 [LCTES’19] A. A. Khan, et al. "Optimizing Tensor Contractions for Embedded Devices with Racetrack Memory Scratch-Pads”, Proceedings of the 20th ACM [Incardona’19] P. Incardona, et al “OpenFPM: A scalable open framework for SIGPLAN/SIGBED LCTES’19, pp. 5-18, Jun 2019 particle and particle-mesh codes on parallel computers”, Computer Physics Communications, 2019 [ACM TECS’20] A. A. Khan, et al. “Optimizing Tensor Contractions for Embedded Devices with Racetrack and DRAM Memories”. ACM TECS 2020 [ACM TOMS’18] S. Karol, et al. "A Domain-Specific Language and Editor for Parallel Particle Methods", In ACM TOMS’18, vol. 44, no. 3, pp. 32, Mar 2018. [TCAD’20] A. A. Khan, et al., "Polyhedral Compilation for Racetrack Memories", In IEEE TCAD’20, vol. 39, no. 11, pp. 3968-3980, Oct 2020. 31 © Prof. J. Castrillon. PASC'21. Geneva, 2021
You can also read

















































