HPC, AI Khronos SYCL: an open standard heterogeneous modern C++ Programming model for exascale - Michael Wong
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Khronos SYCL: an open standard heterogeneous
modern C++ Programming model for exascale
HPC, AI
Michael Wong
Codeplay Software Ltd.
Distinguished Engineer
CERN 2021
2 © 2020 Codeplay Software Ltd.
Distinguished Engineer
Michael Wong
● Chair of SYCL Heterogeneous Programming Language
● C++ Directions Group
● Past CEO OpenMP
● ISOCPP.org Director, VP
http://isocpp.org/wiki/faq/wg21#michael-wong
● michael@codeplay.com
● fraggamuffin@gmail.com Ported
Build LLVM-
● Head of Delegation for C++ Standard for Canada TensorFlow to
based
● Chair of Programming Languages for Standards open
compilers for
Council of Canada standards
accelerators
Chair of WG21 SG19 Machine Learning using SYCL
Chair of WG21 SG14 Games Dev/Low
Latency/Financial Trading/Embedded Releasing open-
Implement
source, open- OpenCL and
● Editor: C++ SG5 Transactional Memory Technical standards based AI SYCL for
Specification acceleration tools:
accelerator
SYCL-BLAS, SYCL-ML,
● Editor: C++ SG1 Concurrency Technical Specification VisionCpp processors
● MISRA C++ and AUTOSAR
● Chair of Standards Council Canada TC22/SC32
Electrical and electronic components (SOTIF)
● Chair of UL4600 Object Tracking
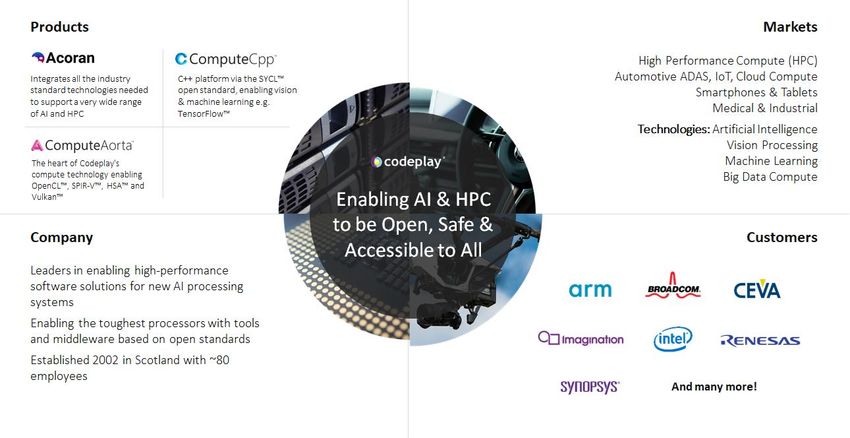
● http://wongmichael.com/about We build GPU compilers for semiconductor companies
● C++11 book in Chinese: Now working to make AI/ML heterogeneous acceleration safe for
https://www.amazon.cn/dp/B00ETOV2OQ autonomous vehicle
3 © 2020 Codeplay Software Ltd.
Acknowledgement and Disclaimer
Numerous people internal and external
to the original C++/Khronos
group/OpenMP, in industry and
academia, have made contributions,
influenced ideas, written part of this
presentations, and offered feedbacks to
form part of this talk. These in clude
Bjarne Stroustrup, Joe Hummel, Botond
Ballo, Simon Mcintosh-Smith, as well as
many others.
But I claim all credit for errors, and stupid mistakes. These
are mine, all mine! You can’t have them.
4 © 2020 Codeplay Software Ltd.
Legal Disclaimer
THIS WORK REPRESENTS THE VIEW OF THE OTHER COMPANY, PRODUCT, AND SERVICE
AUTHOR AND DOES NOT NECESSARILY NAMES MAY BE TRADEMARKS OR SERVICE
REPRESENT THE VIEW OF CODEPLAY. MARKS OF OTHERS.
5 © 2020 Codeplay Software Ltd.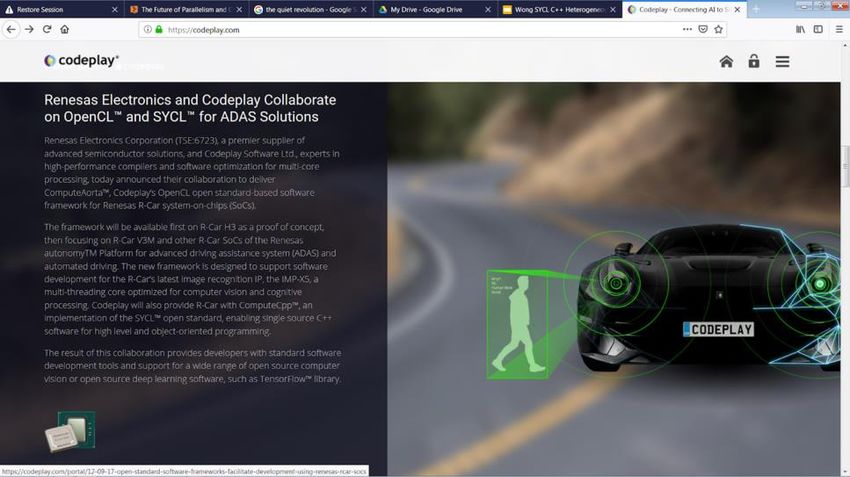
Disclaimers
NVIDIA, the NVIDIA logo and CUDA are trademarks and/or
registered trademarks of NVIDIA Corporation in the U.S.
and/or other countries
Codeplay is not associated with NVIDIA for this work and it is
purely using public documentation and widely available code
6 © 2020 Codeplay Software Ltd.
3 Act Play
1. Landscape of
Programming models
2. Khronos SYCL
3. SYCL 2020 as an HPC
heterogeneous modern
C++ programming model
7 © 2020 Codeplay Software Ltd.
Act 1
Landscape of programming models
8 © 2020 Codeplay Software Ltd.
Which one to choose?
19 © 2020 Codeplay Software Ltd.
20 © 2020 Codeplay Software Ltd.
Heterogeneous Devices
Accelerator CPU GPU
DSP APU FPGA
21 © 2020 Codeplay Software Ltd.Hot Chips
22 © 2020 Codeplay Software Ltd.Fundamental Parallel Architecture Types
• Uniprocessor • Shared Memory
• Multiprocessor (SMP)
Scalar processor
• Shared memory address
processor
space
• Bus-based memory system
memory
• Single Instruction processor … processor
Multiple Data (SIMD) bus
memory
processor
… • Interconnection network
memory
processor … processor
• Single Instruction network
Multiple Thread (SIMT) …
memory
23
23 © 2020 Codeplay Software Ltd.SIMD vs SIMT
24 © 2020 Codeplay Software Ltd.Distributed and network Parallel Architecture Types
• Distributed Memory • Cluster of SMPs
Multiprocessor • Shared memory
• Message passing addressing within SMP
node
between nodes • Message passing between
memory memory SMP nodes
… M M
processor processor …
P … P P … P
interconnection network network
interface
interconnection network
processor processor
…
P … P P … P
memory memory …
• Massively Parallel Processor
M M
(MPP) • Can also be regarded as
Introduction to Parallel • Many, many processors MPP if processor number
Computing, University of is large
Oregon, IPCC 25
25 © 2020 Codeplay Software Ltd.Modern Parallel Architecture
Multicore Manycore • Heterogeneous: CPU+Manycore CPU
M M
Manycore vs Multicore CPU …
cores can be P P P P
C C C C C C C C C C C C … …
m m m m m m m m m m m m hardware network
multithreaded interface
C C C C C C C C (hyperthread) interconnection network
m m m m m m m m memory
P … P P … P
Heterogeneous: CPU + GPU
memory … M
M
processor
PCI
• Heterogeneous: Multicore SMP+GPU Cluster
M M
…
memory
P P P P
Heterogeneous: “Fused” CPU + GPU … …
processor
interconnection network
memory P … P P … P
…
26
26 M M © 2020 Codeplay Software Ltd.Modern Parallel Programming model
Multicore Manycore
• Heterogeneous: CPU+Manycore CPU: OpenCL, OpenMP, SYCL,
C++11/14/17/20, TBB, Cilk, pthread
M M
Manycore vs Multicore CPU: OpenCL, OpenMP, SYCL,
…
C++11/14/17/20, TBB, Cilk, pthread
cores can be P P P P
C C C C C C C C C C C C … …
m m m m m m m m m m m m hardware network
multithreaded interface
C C C C C C C C (hyperthread) interconnection network
m m m m m m m m memory
P … P P … P
Heterogeneous: CPU + GPU: OpenCL, OpenMP, SYCL, C++17/20,
memory OpenACC, CUDA, hip, RocM, C++ AMP, Intrinsics, OpenGL, Vulkan, … M
CUDA, DirectX M
processor
PCI • Heterogeneous: Multicore SMP+GPU Cluster: OpenCL, OpenMP, SYCL, C++17/20
M M
…
memory
Heterogeneous: “Fused” CPU + GPU: OpenCL, OpenMP, SYCL, C++17/20, hip, P P P P
… …
RocM, Intrinsics, OpenGL, Vulkan, DirectX
processor
interconnection network
memory P … P P … P
…
27
27 M M © 2020 Codeplay Software Ltd.Which Programming model works on all the Architectures?Is there a pattern?
Multicore Manycore
• Heterogeneous: CPU+Manycore CPU: OpenCL, OpenMP, SYCL,
C++11/14/17/20, TBB, Cilk, pthread
M M
Manycore vs Multicore CPU: OpenCL, OpenMP, SYCL,
…
C++11/14/17/20, TBB, Cilk, pthread
cores can be P P P P
C C C C C C C C C C C C … …
m m m m m m m m m m m m hardware network
multithreaded interface
C C C C C C C C (hyperthread) interconnection network
m m m m m m m m memory
P … P P … P
Heterogeneous: CPU + GPU: OpenCL, OpenMP, SYCL, C++17/20,
memory OpenACC, CUDA, hip, RocM, C++ AMP, Intrinsics, OpenGL, Vulkan, … M
CUDA, DirectX M
processor
PCI • Heterogeneous: Multicore SMP+GPU Cluster: OpenCL, OpenMP, SYCL, C++17/20
M M
…
memory
Heterogeneous: “Fused” CPU + GPU: OpenCL, OpenMP, SYCL, C++17/20, hip, P P P P
… …
RocM, Intrinsics, OpenGL, Vulkan, DirectX
processor
interconnection network
memory P … P P … P
…
28
28 M M © 2020 Codeplay Software Ltd.To support all the different parallel architectures
• With a single source • You really only have a
code base few choices
• And if you also want it
to be an International
Open Specification
• And if you want it to be
growing with the
architectures
29 © 2020 Codeplay Software Ltd.Act 2
Khronos SYCL
43 © 2020 Codeplay Software Ltd.Khronos is an open, non-profit,
member-driven industry
consortium developing royalty-free
standards, and vibrant ecosystems,
to harness the power of silicon
acceleration for demanding
graphics rendering and
computationally intensive
applications such as inferencing
and vision processing
>150 Members ~ 40% US, 30% Europe, 30% Asia
Some Khronos Standards Relevant to Embedded Vision and Inferencing
Vision and Neural Network Heterogeneous Parallel C++ Parallel GPU
Inferencing Runtime Exchange Format Parallel Compute IR Compute Acceleration
Compute
44 © 2020 Codeplay Software Ltd.Khronos Active Initiatives and where does SYCL fit
3D Graphics 3D Assets Portable XR Parallel Computation
Desktop, Mobile, Web Authoring Augmented and Vision, Inferencing,
Embedded and Safety Critical and Delivery Virtual Reality Machine Learning
Guidelines for creating APIs to streamline system safety certification
46 © 2020 Codeplay Software Ltd.SYCL Single Source C++ Parallel Programming
Complex ML frameworks
Standard C++ can be directly compiled
SYCL-BLAS, SYCL-DNN,
C++ ML and accelerated
Eigen, Application
oneAPI libraries Libraries Frameworks
Code
C++ Template C++ Template C++ Template C++ templates and lambda
functions separate host &
Libraries Libraries Libraries
accelerated device code
SYCL Compiler CPU
C++ Kernel Fusion can for OpenCL Compiler
give better performance
on complex apps and libs
than hand-coding CPU
Accelerated code
passed into device CPU
CPU GPU
SYCL is ideal for accelerating larger
CPU GPU
OpenCL compilers C++-based engines and applications
FPGA DSP
with performance portability
AI/Tensor HW
Custom
Hardware
47 © 2020 Codeplay Software Ltd.SYCL aims to make data locality and movement efficient
➢ SYCL separates data storage from data access
➢ SYCL has separate structures for accessing data in different address spaces
➢ SYCL allows you to create data dependency graphs
48 © 2020 Codeplay Software Ltd.Separating Data & Access
Buffers allow type safe
access across host and
device
Accessor CPU
Buffer
Accessor GPU
Accessors are used to
detect dependencies
49 © 2020 Codeplay Software Ltd.Copying/Allocating Memory in Address Spaces
Memory stored in global
Global memory
Accessor
Buffer
Constant Memory stored in read-
Kernel only memory
Accessor
Local Memory stored in group
memory
Accessor
50 © 2020 Codeplay Software Ltd.Data Dependency Task Graphs
Read
Buffer A
Accessor Kernel A
Write
Accessor Kernel A Kernel B
Buffer B Read
Accessor Kernel B
Write
Accessor
Buffer C
Read
Accessor Kernel C
Read
Kernel C
Buffer D Accessor
Write
Accessor
51 © 2020 Codeplay Software Ltd.Benefits of Data Dependency Graphs
•Allows you to describe your problems in terms of
relationships
•Don’t need to en-queue explicit copies
•Synchronisation can be performed using RAII
•Automatically copy data back to the host if necessary
•Removes the need for complex event handling
•Dependencies between kernels are automatically constructed
•Allows the runtime to make data movement optimizations
•Pre-emptively copy data to a device before kernels
•Avoid unnecessary copying data back to the host after kernels
52 © 2020 Codeplay Software Ltd.So what does SYCL look like?
➢ Here is a simple example SYCL application; a vector add
53 © 2020 Codeplay Software Ltd.Example: Vector Add
54 © 2020 Codeplay Software Ltd.Example: Vector Add
#include
Include sycl.hpp for
the whole SYCL
template runtime
void parallel_add(T *inputA, T *inputB, T *output, size_t size) {
}
55 © 2020 Codeplay Software Ltd.Example: Vector Add
#include
template
void parallel_add(T *inputA, T *inputB, T *output, size_t size) {
cl::sycl::buffer inputABuf(inputA, size);
cl::sycl::buffer inputBBuf(inputB, size);
cl::sycl::buffer outputBuf(output, size);
Create buffers to maintain
the data across host and
device
The buffers
synchronise upon
destruction
}
56 © 2020 Codeplay Software Ltd.Example: Vector Add
#include
template
void parallel_add(T *inputA, T *inputB, T *output, size_t size) {
cl::sycl::buffer inputABuf(inputA, size);
cl::sycl::buffer inputBBuf(inputB, size);
cl::sycl::buffer outputBuf(output, size);
cl::sycl::queue defaultQueue;
Create a queue to
en-queue work
}
57 © 2020 Codeplay Software Ltd.Example: Vector Add
#include
template
void parallel_add(T *inputA, T *inputB, T *output, size_t size) {
cl::sycl::buffer inputABuf(inputA, size);
cl::sycl::buffer inputBBuf(inputB, size);
cl::sycl::buffer outputBuf(output, size);
cl::sycl::queue defaultQueue;
defaultQueue.submit([&] (cl::sycl::handler &cgh) { Create a command group to define
an asynchronous task
The scope of the
command group is
}); defined by a lambda
}
58 © 2020 Codeplay Software Ltd.Example: Vector Add
#include
template
void parallel_add(T *inputA, T *inputB, T *output, size_t size) {
cl::sycl::buffer inputABuf(inputA, size);
cl::sycl::buffer inputBBuf(inputB, size);
cl::sycl::buffer outputBuf(output, size);
cl::sycl::queue defaultQueue;
defaultQueue.submit([&] (cl::sycl::handler &cgh) {
auto inputAPtr = inputABuf.get_access(cgh);
auto inputBPtr = inputBBuf.get_access(cgh);
auto outputPtr = outputBuf.get_access(cgh);
Create accessors to give
access to the data on the
device
});
}
59 © 2020 Codeplay Software Ltd.Example: Vector Add
#include
template kernel;
template
void parallel_add(T *inputA, T *inputB, T *output, size_t size) {
cl::sycl::buffer inputABuf(inputA, size);
cl::sycl::buffer inputBBuf(inputB, size);
cl::sycl::buffer outputBuf(output, size);
cl::sycl::queue defaultQueue;
defaultQueue.submit([&] (cl::sycl::handler &cgh) {
auto inputAPtr = inputABuf.get_access(cgh);
auto inputBPtr = inputBBuf.get_access(cgh);
auto outputPtr = outputBuf.get_access(cgh);
cgh.parallel_for(cl::sycl::range(size)),
[=](cl::sycl::id idx) {
Create a parallel_for to
})); define a kernel
});
}
60 © 2020 Codeplay Software Ltd.Example: Vector Add
#include
template kernel;
template
void parallel_add(T *inputA, T *inputB, T *output, size_t size) {
cl::sycl::buffer inputABuf(inputA, size);
cl::sycl::buffer inputBBuf(inputB, size); You must provide a
cl::sycl::buffer outputBuf(output, size); name for the lambda
cl::sycl::queue defaultQueue;
defaultQueue.submit([&] (cl::sycl::handler &cgh) {
auto inputAPtr = inputABuf.get_access(cgh);
auto inputBPtr = inputBBuf.get_access(cgh);
auto outputPtr = outputBuf.get_access(cgh);
cgh.parallel_for(cl::sycl::range(size)),
[=](cl::sycl::id idx) {
outputPtr[idx] = inputAPtr[idx] + inputBPtr[idx]; Access the data via the
accessor’s subscript
}));
operator
});
}
61 © 2020 Codeplay Software Ltd.Example: Vector Add
template
void parallel_add(T *inputA, T *inputB, T *output, size_t size);
int main() {
float inputA[count] = { /* input a */ };
float inputB[count] = { /* input b */ };
float output[count] = { /* output */ };
parallel_add(inputA, inputB, output, count);
}
The result is stored in
output upon returning from
parallel_add
62 © 2020 Codeplay Software Ltd.Act 3 63 © 2020 Codeplay Software Ltd.
SYCL Present and Future Roadmap (May Change)
C++11 C++14 C++17 C++20 C++23
SYCL 1.2 SYCL 1.2.1 SYCL 2020 SYCL 2021-?
C++11 Single source C++11 Single source C++17 Single source C++20 Single source
programming programming programming programming
Many backend options Many backend options
2011 2015 2017 2020 2021-????
OpenCL 1.2 OpenCL 2.1 OpenCL 2.2 OpenCL 3.0
OpenCL C Kernel SPIR-V in Core
Language
64 © 2020 Codeplay Software Ltd.SYCL community is vibrant
2X growth
SYCL-1.2.1
65 © 2020 Codeplay Software Ltd.SYCL Evolution SYCL 2020 compared with SYCL 1.2.1
Easier to integrate with C++17 (CTAD, Deduction Guides...)
Less verbose, smaller code size, simplify patterns
Backend independent
SYCL 2020 Potential Features Multiple object archives aka modules simplify interoperability
Generalization (a.k.a the Backend Model) presented by Gordon Brown Ease porting C++ applications to SYCL
Unified Shared Memory (USM) presented by James Brodman Enable capabilities to improve programmability
Improvement to Program class Modules presented by Gordon Brown Backwards compatible but minor API break based on user feedback
Host Task with Interop presented by Gordon Brown
In order queues, presented by James Brodman
Integration of successful
Converge SYCL with ISO
Extensions plus new Core C++ and continue to
functionality support OpenCL to
deploy on more devices
CPU
GPU
SYCL 2020 Roadmap (WIP, MAY CHANGE)
FPGA
AI processors
Improving Software Ecosystem Target 2020 Custom Processors
2017 Tool, libraries, GitHub Provisional Q3 then Final Q4
SYCL 1.2.1
Expanding Implementation Selected Extension
DPC++
ComputeCpp
Pipeline aiming for SYCL
triSYCL 2020 Provisional Q3
hipSYCL Reduction
Regular Maintenance Updates Subgroups
Spec clarifications, formatting and bug fixes Accessor simplification
https://www.khronos.org/registry/SYCL/ Atomic rework
Extension mechanism
Address spaces
Repeat The Cycle every 1.5-3 years Vector rework
66 Specialization Constants © 2020 Codeplay Software Ltd.SYCL Ecosystem, Research and Benchmarks
Machine Learning
Implementations Research Benchmarks Linear Algebra
Libraries and Parallel
Libraries
Acceleration Frameworks
SYCL-BLAS
oneAPI
Eigen SYCL-ML
SYCL-DNN
oneMKL
SYCL Parallel STL
RSBench
Active Working Group
67 Members © 2020 Codeplay Software Ltd.When I was OpenMP CEO, I learned
• HPC, exascale computing requires programming models
that endures for future workloads, last 20 years
• Must be open and standard, multiple implementations
• C, C++, Fortran
• Or an open consortium with multiple implementations
• OpenMP, SYCL
• That also adapts to parallel, heterogeneous future HW
• OpenMP is great for C and Fortran
• SYCL is great for modern C++, AI, Automotive
68 © 2020 Codeplay Software Ltd.SYCL, Aurora and Exascale computing
SYCL can
run on AMD
ROCM
69 © 2020 Codeplay Software Ltd.What about Europe? EPI, ARM and RISC-V RVV
70 © 2020 Codeplay Software Ltd.Data parallel C++ oneAPI Industry Specification
Standards-based, Cross-architecture Language
Language Libraries
Low Level Hardware Interface
Language to deliver uncompromised parallel programming
productivity and performance across CPUs and accelerators
Direct Programming:
DPC++ = ISO C++ and Khronos SYCL and Extensions Data Parallel C++
Allows code reuse across hardware targets, while permitting
custom tuning for a specific accelerator Community Extensions
Open, cross-industry alternative to single architecture proprietary
language
Khronos SYCL
Based on C++
Delivers C++ productivity benefits, using common and familiar C
and C++ constructs
Incorporates SYCL* from the Khronos Group to support data ISO C++
parallelism and heterogeneous programming
Community Project to drive language enhancements
Extensions to simplify data parallel programming
Open and cooperative development for continued evolution
DPC++ extensions including Unified Shared Memory are being
incorporated into upcoming versions of the Khronos SYCL
standard.
71 © 2020 Codeplay Software Ltd.
Refer to http://software.intel.com/en-us/articles/optimization-notice for more information regarding performance and optimization
choices in Intel software products.oneAPI Industry Specification
Language Libraries
Low Level Hardware Interface
oneAPI Specification
Libraries
Library Name Description Short name
oneAPI DPC++ Library Key algorithms and functions to speed oneDPC
up DPC++ kernel programming
oneAPI Math Kernel Math routines including matrix algebra, oneMKL
Key domain-specific functions to accelerate Library fast Fourier transforms (FFT), and vector
math
compute intensive workloads
oneAPI Data Analytics Machine learning and data analytics oneDAL
Library functions
Custom-coded for supported architectures oneAPI Deep Neural Neural networks functions for deep oneDNN
Network Library learning training and inference (SYCLDNN)
oneAPI Collective Communication patterns for oneCCL
Communications Library distributed deep learning
oneAPI Threading Threading and memory management oneTBB
Building Blocks template library
oneAPI Video Processing Real-time video decoding, encoding, oneVPL
Library transcoding, and processing functions
Refer to http://software.intel.com/en-us/articles/optimization-notice for more information regarding performance © 2020 Codeplay Software Ltd.
and optimization choices in Intel software products 72
7Oct 2020: RISC-V NSITEXE, Kyoto Microcomputer &
Codeplay AI/HPC
73 © 2020 Codeplay Software Ltd.Broad ecosystem of HPC support
SYCL DNN SYCL-BLAS
•Codeplay’s inhouse highly optimised •Codeplay’s inhouse highly optimised
open-source SYCL library open-source SYCL library for BLAS
• Convolution
• Pooling routines
•Purely written in SYCL •Purely written in SYCL
•Support performance portability across •Support performance portability
supported SYCL backend architectures across supported SYCL backend
•Can use any available SYCL Compiler
architectures
tool chain (e.g. ComputeCpp, DPC++,
HipSYCL, TrySYCL) •Can use any available SYCL
Compiler tool chain (e.g.
ComputeCpp, DPC++, HipSYCL,
OneDNN TriSYCL)
•Open Source library
OneMKL
•Part of Intel OneAPI community for DNN
library
• Support all operations required to
build an NN kernel
•Part of Intel OneAPI community for
•Support various backend Math Kernel operations
• Intel CPU via OpenMP (BLAS/LAPACK, etc)
• Intel GPU via OpenCL and SYCL
via OpenCL interoperability mode •Use SYCL interface for BLAS
• Nvidia GPU via SYCL •Support various backend via interoperability
interoperability mode with CUDA mode with vendor specified closed source library
• Intel FPGA via Level zero •Intel CPU
•Intel GPU through SYCL via OpenCL
interoperability mode
•The SYCL backend Works with both •Nvidia GPU via SYCL interoperability mode with
ComputeCPP CUDA
74 © 2020 Codeplay Software Ltd.75 © 2020 Codeplay Software Ltd.
76 © 2020 Codeplay Software Ltd.
Eigen
• C++-based template library for linear algebra
• Codeplay provides highly optimised pure SYCL
kernels for Tensor Module in Eigen
• Used as a Tensorflow default backend for linear
algebra operations
• The SYCL backend Can be compiled by any
SYCL compiler toolchain and can target any
supported SYCL backend
77 © 2020 Codeplay Software Ltd.SYCL
Source Code
DPC++ ComputeCpp triSYCL hipSYCL
Uses SYCL 1.2.1 on SYCL 1.2.1 on
Open source
LLVM/clang multiple CUDA &
test bed
Part of oneAPI hardware HIP/ROCm
Experimental
Any CPU CUDA+PTX Any CPU OpenCL+PTX OpenMP OpenMP CUDA
NVIDIA GPUs NVIDIA GPUs Any CPU Any CPU NVIDIA GPUs
OpenCL + OpenCL + OpenCL + ROCm
SPIR-V SPIR(-V) SPIR/LLVM
AMD GPUs
Intel CPUs Intel CPUs XILINX FPGAs
Intel GPUs Intel GPUs POCL
Intel FPGAs Intel FPGAs (open source OpenCL supporting
CPUs and NVIDIA GPUs and more)
AMD GPUs
(depends on driver stack)
Arm Mali
78IMG PowerVR © 2020 Codeplay Software Ltd.
Renesas R-CarFinal words
• SYCL can be a part of a standard programming model for
European HPC
• SYCL is home grown EU, UK company led its development
since 2012, now open standard with multiple
contributions, lots of European projects
• Celerity from Innsbruck, Bologna
• Moves with ISO C++, updates every 1.5-3 years
• Adapts to HPC hardware changes
• Adapted by Exascape Computing Project for first Exascale
computer, other adoptions coming
79 © 2020 Codeplay Software Ltd."Our users will benefit from features in the provisional “At Cineca, based on our experience, we confirm the value
SYCL 2020 specification,” said Hal Finkel, lead for that SYCL is bringing to the development of high
compiler technology and programming languages, performance computing in a hybrid environment. In fact,
Argonne National Laboratory’s Leadership through SYCL, it is possible to build a common and
Computing Facility. “New features, such as support portable environment for the development of computing-
for unified memory and reductions, are important intensive applications to be executed on HPC architectures
capabilities for programming high-performance- configured with floating point accelerators, which allows
computing hardware. In addition, support for C++17 will industries and scientific communities to use the common
allow our users to write better C++ code, with both availability of development tools, libraries of algorithms,
language features (such as deduction guides) and accumulated experience,” said Sanzio Bassini, director
library features (such as std::optional)." of supercomputing, Application Innovation Dept,
Cineca. “Cineca is already running the distributed Celerity
”NSITEXE supports the SYCL 2020 technology, which
runtime on top of several SYCL implementations on the
is gaining attention in embedded applications,” said
new Marconi100 cluster, ranked no. 9 in the Top500 (June
Hideki Sugimoto, CTO, NSITEXE, Inc. “We are
2020), providing users with a unified API for both about
considering adopting this technology in our next
4000 NVIDIA Volta V100 GPUs and IBM Power9 host
generation of IP platforms.”
processors. SYCL 2020 is a big step towards a much
"Xilinx is excited about the progress achieved with SYCL 2020,” said leaner API that unlocks all the potential provided by modern
Ralph Wittig, fellow, Xilinx. “This single-source C++ framework unifies
host and device code for various kinds of accelerators in the same C++
C++ standards for accelerated data-parallel kernels,
program. With host-fallback device execution, developers can emulate making the development of large-scale scientific software
device code on a CPU, exploring hardware-software co-design for easier and more sustainable, either for industrial oriented
adaptable computing devices. SYCL is now extensible via customizable
back-ends, enabling device plug-ins for FPGAs and ACAPs."
domain applications for industries, either for scientific
domain
80
oriented applications.” © 2020 Codeplay Software Ltd.SYCL 2020 Provisional is here
• SYCL 2020 provisional is released and final in Q4
• We need your feedback asap
• https://app.slack.com/client/TDMDFS87M/CE9UX4CHG
• https://community.khronos.org/c/sycl
• https://sycl.tech
• What features are you looking for in SYCL 2020?
• What feature would you like to aim for in future SYCL?
• How do you join SYCL?
81 © 2020 Codeplay Software Ltd.Open to all!
https://community.khronos.org/www.khr.io/slack
Engaging with the Khronos SYCL Ecosystem https://app.slack.com/client/TDMDFS87M/CE9UX4CHG
https://community.khronos.org/c/sycl/
https://stackoverflow.com/questions/tagged/sycl
https://www.reddit.com/r/sycl
$0 https://github.com/codeplaysoftware/syclacademy
https://sycl.tech/ Spec fixes and suggestions made under the Khronos IP
Framework. Open source contributions under repo’s
CLA – typically Apache 2.0
$0 https://github.com/KhronosGroup
Khronos SYCL Forums, Slack https://github.com/KhronosGroup/SYCL-CTS
Channels, stackoverflow, reddit, and https://github.com/KhronosGroup/SYCL-Docs
SYCL.tech https://github.com/KhronosGroup/SYCL-Shared
https://github.com/KhronosGroup/SYCL-Registry
https://github.com/KhronosGroup/SyclParallelSTL
Contribute to SYCL open source $0 Invited Advisors under the Khronos NDA and
IP Framework can comment and contribute
specs, CTS, tools and ecosystem to requirements and draft specifications
https://www.khronos.org/advisors/
SYCL
Advisory $ Khronos members under Khronos NDA and IP
Panels Framework participate and vote in working
group meetings. Starts at $3.5K/yr.
SYCL https://www.khronos.org/members/
Working https://www.khronos.org/registry/SYCL/
Groups Any member or non-
member can propose a
new SYCL feature or fix
82 © 2020 Codeplay Software Ltd.Thank You!
• Khronos SYCL is creating cutting-edge royalty-free open standard
• For C++ Heterogeneous compute, vision, inferencing acceleration
• Information on Khronos SYCL Standards: https://www.khronos.org/sycl
• Any entity/individual is welcome to join Khronos SYCL: https://www.khronos.org/members
• Join the SYCLCon Tutorial Monday and Wednesday Live panel : Wednesday Apr 29 15:00-18:00 GMT
• Have your questions answered live by a group of SYCL experts
• Michael Wong: michael@codeplay.com | wongmichael.com/about
Gain early insights Influence the design and direction Accelerate your time-to-
into industry trends of key open standards that will market with early access to
and directions drive your business specification drafts
Gather industry Draft Specifications Publicly Release
requirements for future Confidential to Khronos Specifications and
open standards members Conformance Tests
Network with domain experts State-of-the-art IP Framework Enhance your company reputation
from diverse companies in protects your Intellectual as an industry leader through
your industry Property Khronos participation
Benefits of Khronos membership
83 © 2020 Codeplay Software Ltd.Oh, and one more thing
84 © 2020 Codeplay Software Ltd.What can I do with a Parallel For Each?
size_t nElems = 1000u;
10000
elems std::vector nums(nElems);
std::fill_n(std::begin(v1), nElems, 1);
std::for_each(std::begin(v), std::end(v),
[=](float f) { f * f + f });
Traditional for each uses only one core,
rest of the die is unutilized!
Intel Core i7 7th generation
85 © 2020 Codeplay Software Ltd.What can I do with a Parallel For Each?
size_t nElems = 1000u;
2500 2500
elems elems std::vector nums(nElems);
2500 2500 std::fill_n(std::execution_policy::par,
elems elems
std::begin(v1), nElems, 1);
std::for_each(std::execution_policy::par,
std::begin(v), std::end(v),
[=](float f) { f * f + f });
Workload is distributed across cores!
Intel Core i7 7th generation (mileage may vary, implementation-specific behaviour)
86 © 2020 Codeplay Software Ltd.What can I do with a Parallel For Each?
size_t nElems = 1000u;
2500 2500
elems elems std::vector nums(nElems);
2500 2500 std::fill_n(std::execution_policy::par,
elems elems
std::begin(v1), nElems, 1);
std::for_each(std::execution_policy::par,
What about this std::begin(v), std::end(v),
part? [=](float f) { f * f + f });
Workload is distributed across cores!
Intel Core i7 7th generation (mileage may vary, implementation-specific behaviour)
87 © 2020 Codeplay Software Ltd.What can I do with a Parallel For Each?
size_t nElems = 1000u;
std::vector nums(nElems);
std::fill_n(sycl_policy,
std::begin(v1), nElems, 1);
std::for_each(sycl_named_policy
,
10000 elems std::begin(v), std::end(v),
[=](float f) { f * f + f });
Workload is distributed on the GPU cores
Intel Core i7 7th generation (mileage may vary, implementation-specific behaviour)
88 © 2020 Codeplay Software Ltd.What can I do with a Parallel For Each?
size_t nElems = 1000u;
1250 1250
elems elems std::vector nums(nElems);
1250 std::fill_n(sycl_heter_policy(cpu, gpu, 0.5),
1250
elems elems std::begin(v1), nElems, 1);
std::for_each(sycl_heter_policy
(cpu, gpu, 0.5),
5000 elems
std::begin(v), std::end(v),
[=](float f) { f * f + f });
Workload is distributed on all cores!
Intel Core i7 7th generation
Experimental! (mileage may vary, implementation-specific behaviour)
89 © 2020 Codeplay Software Ltd.90 © 2020 Codeplay Software Ltd.
Demo Results - Running std::sort
(Running on Intel i7 6600 CPU & Intel HD Graphics 520)
size 2^16 2^17 2^18 2^19
std::seq 0.27031s 0.620068s 0.669628s 1.48918s
std::par 0.259486s 0.478032s 0.444422s 1.83599s
std::unseq 0.24258s 0.413909s 0.456224s 1.01958s
sycl_execution_policy 0.273724s 0.269804s 0.277747s 0.399634s
91 © 2020 Codeplay Software Ltd.SYCL Ecosystem
● ComputeCpp -
https://codeplay.com/products/computesuite/computecpp
● triSYCL - https://github.com/triSYCL/triSYCL
● SYCL - http://sycl.tech
● SYCL ParallelSTL - https://github.com/KhronosGroup/SyclParallelSTL
● VisionCpp - https://github.com/codeplaysoftware/visioncpp
● SYCL-BLAS - https://github.com/codeplaysoftware/sycl-blas
● TensorFlow-SYCL - https://github.com/codeplaysoftware/tensorflow
● Eigen http://eigen.tuxfamily.org
95 © 2020 Codeplay Software Ltd.Eigen Linear Algebra Library
SYCL backend in mainline
Focused on Tensor support, providing
support for machine learning/CNNs
Equivalent coverage to CUDA
Working on optimization for various
hardware architectures (CPU, desktop and
mobile GPUs)
https://bitbucket.org/eigen/eigen/
96 © 2020 Codeplay Software Ltd.TensorFlow
SYCL backend support for all major CNN
operations
Complete coverage for major image
recognition networks
GoogLeNet, Inception-v2, Inception-v3,
ResNet, ….
Ongoing work to reach 100% operator
coverage and optimization for various
hardware architectures (CPU, desktop and
mobile GPUs)
https://github.com/tensorflow/tensorflow
TensorFlow, the TensorFlow logo and any related marks are
trademarks of Google Inc.
97 © 2020 Codeplay Software Ltd.SYCL Ecosystem
• Single-source heterogeneous programming using STANDARD C++
- Use C++ templates and lambda functions for host & device code
- Layered over OpenCL
• Fast and powerful path for bring C++ apps and libraries to OpenCL
- C++ Kernel Fusion - better performance on complex software than hand-coding
- Halide, Eigen, Boost.Compute, SYCLBLAS, SYCL Eigen, SYCL TensorFlow, SYCL GTX
- Clang, triSYCL, ComputeCpp, VisionCpp, ComputeCpp SDK …
• More information at http://sycl.tech
Developer Choice
The development of the two specifications are aligned so
code can be easily shared between the two approaches
C++ Kernel Language Single-source C++
Low Level Control
Programmer Familiarity
‘GPGPU’-style separation of
Approach also taken by
device-side kernel source
C++ AMP and OpenMP
code and host code
98 © 2020 Codeplay Software Ltd.Codeplay
Standards Research Open Presentati Company
bodies source ons
• HSA Foundation: Chair of • Members of EU research • HSA LLDB Debugger • Building an LLVM back-end • Based in Edinburgh, Scotland
software group, spec editor of consortiums: PEPPHER, • SPIR-V tools • Creating an SPMD Vectorizer for • 57 staff, mostly engineering
runtime and debugging LPGPU, LPGPU2, CARP • RenderScript debugger in AOSP OpenCL with LLVM • License and customize
• Khronos: chair & spec editor of • Sponsorship of PhDs and EngDs • LLDB for Qualcomm Hexagon • Challenges of Mixed-Width technologies for semiconductor
SYCL. Contributors to OpenCL, for heterogeneous programming: Vector Code Gen & Scheduling companies
• TensorFlow for OpenCL
Safety Critical, Vulkan HSA, FPGAs, ray-tracing in LLVM • ComputeAorta and
• C++ 17 Parallel STL for SYCL
• ISO C++: Chair of Low Latency, • Collaborations with academics • C++ on Accelerators: Supporting ComputeCpp: implementations
• VisionCpp: C++ performance-
Embedded WG; Editor of SG1 • Members of HiPEAC Single-Source SYCL and HSA of OpenCL, Vulkan and SYCL
Concurrency TS portable programming model for
vision • LLDB Tutorial: Adding debugger • 15+ years of experience in
• EEMBC: members support for your target heterogeneous systems tools
Codeplay build the software platforms that deliver massive performance
99 © 2020 Codeplay Software Ltd.What our ComputeCpp users say about us
Benoit Steiner – Google WIGNER Research Centre
ONERA Hartmut Kaiser - HPX
TensorFlow engineer for Physics
“We at Google have been working “We work with royalty-free SYCL “My team and I are working with It was a great pleasure this week for
closely with Luke and his Codeplay because it is hardware vendor Codeplay's ComputeCpp for almost a us, that Codeplay released the
colleagues on this project for almost agnostic, single-source C++ year now and they have resolved ComputeCpp project for the wider
12 months now. Codeplay's programming model without platform every issue in a timely manner, while audience. We've been waiting for this
contribution to this effort has been specific keywords. This will allow us to demonstrating that this technology can moment and keeping our colleagues
tremendous, so we felt that we should easily work with any heterogeneous work with the most complex C++ and students in constant rally and
let them take the lead when it comes processor solutions using OpenCL to template code. I am happy to say that excitement. We'd like to build on this
down to communicating updates develop our complex algorithms and the combination of Codeplay's SYCL opportunity to increase the awareness
related to OpenCL. … we are ensure future compatibility” implementation with our HPX runtime of this technology by providing sample
planning to merge the work that has system has turned out to be a very codes and talks to potential users.
been done so far… we want to put capable basis for Building a We're going to give a lecture series on
together a comprehensive test Heterogeneous Computing Model for modern scientific programming
infrastructure” the C++ Standard using high-level providing field specific examples.“
abstractions.”
100 © 2020 Codeplay Software Ltd.Further information
• OpenCL https://www.khronos.org/opencl/
• OpenVX
https://www.khronos.org/openvx/
• HSA http://www.hsafoundation.com/
• SYCL http://sycl.tech
• OpenCV http://opencv.org/
• Halide http://halide-lang.org/
• VisionCpp https://github.com/codeplaysoftware/visioncpp
101 © 2020 Codeplay Software Ltd.Community Edition
Available now for free!
Visit:
computecpp.codeplay.com
102 © 2020 Codeplay Software Ltd.• Open source SYCL projects:
• ComputeCpp SDK - Collection of sample code and integration tools
• SYCL ParallelSTL – SYCL based implementation of the parallel algorithms
• VisionCpp – Compile-time embedded DSL for image processing
• Eigen C++ Template Library – Compile-time library for machine learning
All of this and more at: http://sycl.tech
103 © 2020 Codeplay Software Ltd.Thanks
info@codeplay.co
@codeplaysoft codeplay.com
mYou can also read

















































