Improving Gradient Flow with Unrolled Highway Expectation Maximization
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

PRELIMINARY VERSION: DO NOT CITE
The AAAI Digital Library will contain the published
version some time after the conference
Improving Gradient Flow with Unrolled Highway Expectation Maximization
Chonghyuk Song, Eunseok Kim, Inwook Shim∗
Ground Technology Research Institute, Agency for Defense Development
Abstract Jointly training this combined architecture discriminatively
allows one to leverage the expressive power of deep neural
Integrating model-based machine learning methods into deep
neural architectures allows one to leverage both the expres-
networks and the ability of model-based methods to incorpo-
sive power of deep neural nets and the ability of model-based rate prior knowledge of the task at hand, resulting in poten-
methods to incorporate domain-specific knowledge. In par- tially many benefits (Hershey, Roux, and Weninger 2014).
ticular, many works have employed the expectation maxi- First, unrolled EM iterations are analogous to an atten-
mization (EM) algorithm in the form of an unrolled layer- tion mechanism when the underlying latent variable model
wise structure that is jointly trained with a backbone neu- is a Gaussian Mixture Model (GMM) (Hinton, Sabour, and
ral network. However, it is difficult to discriminatively train Frosst 2018; Li et al. 2019). The Gaussian mean estimates
the backbone network by backpropagating through the EM capture long-range interactions among the inputs, just like
iterations as they are prone to the vanishing gradient prob-
lem. To address this issue, we propose Highway Expecta-
in the self-attention mechanism (Vaswani et al. 2017; Wang
tion Maximization Networks (HEMNet), which is comprised et al. 2018; Zhao et al. 2018). Furthermore, EM attention
of unrolled iterations of the generalized EM (GEM) algo- (Li et al. 2019) is computationally more efficient than the
rithm based on the Newton-Rahpson method. HEMNet fea- original self-attention mechanism, which computes repre-
tures scaled skip connections, or highways, along the depths sentations as a weighted sum of every point in the input,
of the unrolled architecture, resulting in improved gradient whereas EM attention computes them as a weighted sum of a
flow during backpropagation while incurring negligible addi- smaller number of Gaussian means. The EM algorithm itera-
tional computation and memory costs compared to standard tively refines these Gaussian means such that they monoton-
unrolled EM. Furthermore, HEMNet preserves the underly- ically increase the log likelihood of the input, increasingly
ing EM procedure, thereby fully retaining the convergence enabling them to reconstruct and compute useful represen-
properties of the original EM algorithm. We achieve signif-
icant improvement in performance on several semantic seg-
tations of the original input.
mentation benchmarks and empirically show that HEMNet Despite the beneficial effects EM has on the forward pass,
effectively alleviates gradient decay. jointly training a backbone neural network with EM lay-
ers is challenging as they are prone to the vanishing gra-
dient problem (Li et al. 2019). This phenomenon, which
1 Introduction was first introduced in (Vaswani et al. 2017), is a problem
The Expectation Maximization (EM) algorithm (Dempster, shared by all attention mechanisms that employ the dot-
Laird, and Rubin 1977) is a well-established algorithm in product softmax operation in the computation of attention
the field of statistical learning used to iteratively find the maps. Skip connections have shown to be remarkably effec-
maximum likelihood solution for latent variable models. It tive at resolving vanishing gradients for a variety of deep
has traditionally been used for a variety of problems, rang- network architectures (Srivastava, Greff, and Schmidhuber
ing from unsupervised clustering to missing data imputa- 2015; He et al. 2016b; Huang et al. 2017; Gers, Schmidhu-
tion. With the dramatic rise in adoption of deep learning in ber, and Cummins 1999; Hochreiter and Schmidhuber 1997;
the past few years, recent works (Jampani et al. 2018; Hin- Cho et al. 2014), including attention-based models (Vaswani
ton, Sabour, and Frosst 2018; Li et al. 2019; Wang et al. et al. 2017; Bapna et al. 2018; Wang et al. 2019). However,
2020; Greff, Van Steenkiste, and Schmidhuber 2017) have the question remains as to how to incorporate skip connec-
aimed to combine the model-based approach of EM with tions in way that maintains the underlying EM procedure of
deep neural networks. These two approaches are typically monotonically converging to a (local) optimum of the data
combined by unrolling the iterative steps of the EM as layers log-likelihood.
in a deep network, which takes as input the features gener- In this paper, we aim to address the vanishing gradient
ated by a backbone network that learns the representations. problem of unrolled EM iterations while preserving the EM
∗
Inwook Shim is the corresponding author. algorithm, thereby retaining its efficiency and convergence
Copyright c 2021, Association for the Advancement of Artificial properties and the benefits of end-to-end learning. Instead of
Intelligence (www.aaai.org). All rights reserved. unrolling EM iterations, we unroll generalized EM (GEM)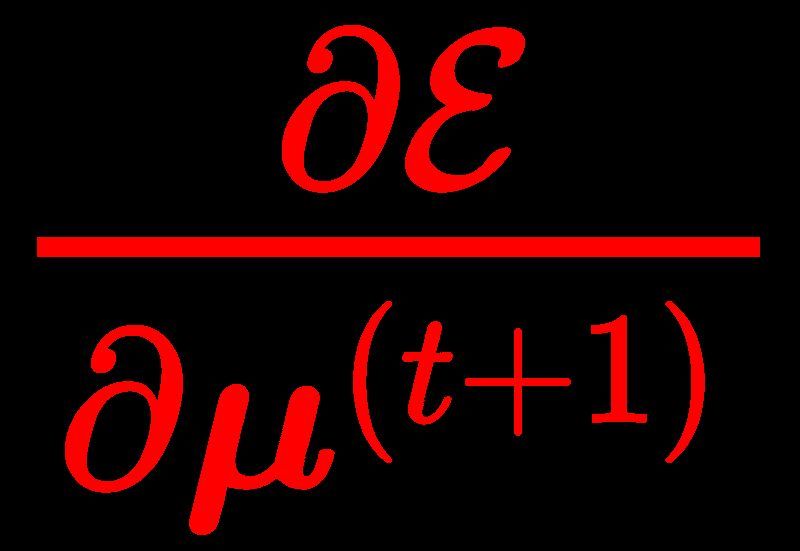
iterations, where the M-step is replaced by one step of the Our approach is motivated by the success of the above
Newton-Rahpson method (Lange 1995). This is motivated works in combating vanishing gradients and in fact struc-
by the key insight that unrolling GEM iterations introduces turally resembles Highway Networks (Srivastava, Greff, and
weighted skip connections, or highways (Srivastava, Greff, Schmidhuber 2015) and Gated Recurrent Units (Cho et al.
and Schmidhuber 2015), along the depths of the unrolled ar- 2014). The key difference is that our method introduces skip
chitecture, thereby improving its gradient flow during back- connections into the network in a way that preserves the
propgation. The use of Newton’s method is non-trivial. Not underlying EM procedure and by extension its convergence
only do GEM iterations based on Newton’s method require properties and computational efficiency.
minimal additional computation and memory costs com-
pared to the original EM, but they are also guaranteed to 3 Preliminaries
improve the data log-likelihood. To demonstrate the effec- 3.1 EM Algorithm for Gaussian Mixture Models
tiveness of our approach, we formulate the proposed GEM
iterations as an attention module, which we refer to as High- The EM algorithm is an iterative procedure that finds the
way Expectation Maximization Network (HEMNet), for ex- maximum likelihood solution for latent variable models. A
isting backbone networks and evaluate its performance on latent variable model is described by the joint distribution
challenging semantic segmentation benchmarks. p(X, Z|θ), where X and Z denote the dataset of N observed
samples xn and the corresponding set of latent variables zn ,
2 Related Works respectively, and θ denotes the model parameters. The Gaus-
sian mixture model (GMM) (Richardson and Green 1997) is
Unrolled Expectation Maximization. With the recent rise
a widely used latent variable model that models the distribu-
in adoption of deep learning, many works have incorpo-
tion of observed data point xn as a linear superposition of
rated modern neural networks with the well-studied EM al-
K Gaussians:
gorithm to leverage its clustering and filtering capabilities.
K
SSN (Jampani et al. 2018) combine unrolled EM iterations X
with a neural network to learn task-specific superpixels. p(xn ) = π k N (xn |µk , Σk ), (1)
CapsNet (Hinton, Sabour, and Frosst 2018) use unrolled EM k=1
iterations as an attentional routing mechanism between adja- N
X
( K
X
)
cent layers of the network. EMANet (Li et al. 2019) designs ln p(X|θ) = ln N (xn |µk , Σk ) , (2)
an EM-based attention module that boosts the performance n=1 k=1
of a backbone network on semantic segmentation. A similar
module is used in (Wang et al. 2020) as a denoising filter for where the mixing coefficient π k , mean µk , and covariance
fine-grained image classification. On the other hand, NEM Σk constitute the parameters for the k th Gaussian. We use
(Greff, Van Steenkiste, and Schmidhuber 2017) incorporates a fixed isotropic covariance matrix Σk = σ 2 I and drop the
the generalized EM (GEM) algorithm (Wu 1983) to learn mixing coefficients as done in many real applications. The
representations for unsupervised clustering, where the M- EM algorithm aims to maximize the resulting log-likelihood
step of the original EM algorithm is replaced with one gra- function in Eq. (2) by performing coordinate ascent on its
dient ascent step towards improving the data log-likelihood. evidence lower bound L (ELBO) (Neal and Hinton 1999):
Unlike our proposed method and original EM, NEM does X X
not guarantee an improvement of the data log-likelihood. ln p(X|θ) ≥ q(Z) ln p(X, Z|θ) + −q(Z) ln q(Z)
Skip Connections. Skip connections are direct connections Z Z
| {z } | {z }
between nodes of different layers of a neural network that Q(θ,q(Z)) H(q(Z))
bypass, or skip, the intermediate layers. They help overcome K
N X
the vanishing gradient problem associated with training very
X
= γnk ln N (xn |µk , Σk ) − γnk ln γnk ,
deep neural architectures (Bengio, Simard, and Frasconi n=1 k=1
1994) by allowing gradient signals to be directly backprop- | {z }
agated between adjacent layers (He et al. 2016a; Srivastava, L(µ,γ)
Greff, and Schmidhuber 2015; Huang et al. 2017; Hochreiter (3)
and Schmidhuber 1997; Cho et al. 2014). In particular, skip which is the sum of the expected complete log-likelihood
connections are crucial for training attention-based models, Q(θ, q) and entropy P term H(q), for any arbitrary distribu-
which are also prone to vanishing gradients (Bapna et al. tion q(Z) defined by k γnk = 1. By alternately maximiz-
2018; Wang et al. 2019; Zhang, Titov, and Sennrich 2019). ing the ELBO with respect to q and θ via the E- and M-step,
The Transformer (Vaswani et al. 2017) employs an identity respectively, the log-likelihood is monotonically increased
skip connection around each of the sub-layers of the net- in the process and converges to a (local) optimum:
work, without which the training procedure collapses, result-
ing in significantly worse performance (Bapna et al. 2018). N (xn |µold
k , Σk )
Subsequent works (Bapna et al. 2018; Wang et al. 2019) E-step: γnk = PK (4)
old
were able to train deeper Transformer models by creating j=1 N (xn |µj , Σj )
weighted skip connections along the depth of the encoder of N
1 X
the Transformer, providing multiple backpropagation paths M-step: µnew
k = γnk xn (5)
Nk n=1
and improving gradient flow.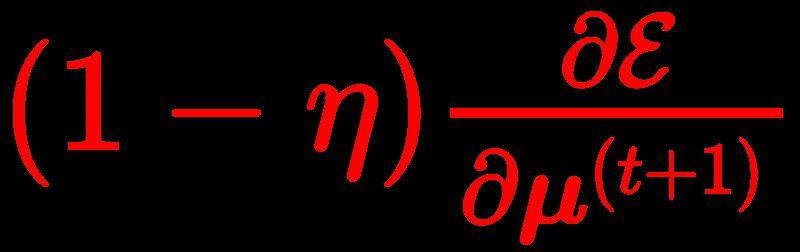
HEMNet
... E-step N-step ... E-step N-step
1×1 Conv
R-step BatchNorm
CNN 1×1
Conv
Figure 1: High-level structure of the proposed HEMNet
In the E-step, the optimal q is p(Z|X, θ old ), the posterior The M-step then updates the Gaussian bases according to
distribution of Z. Eq. (4) shows the posterior for GMMs, Eq. (5), which is implemented by a matrix multiplication
which is described by γnk , the responsibility that the k th between normalized responsibilities γ̄ and features X:
Gaussian basis µk takes for explaining observation xn . In
the M-step, the optimal θ new = argmaxθ Q(θ, q(θ old )) M-step: µ(t+1) = γ̄ (t+1) X, (9)
since the entropy term of the ELBO isn’t dependent on θ. After unrolling T iterations of EM, the input xn , whose
For GMMs, this argmax is tractable, resulting in the closed- distribution was modeled as a mixture of Gaussians, is re-
PN
form of Eq. (5), where Nk = n=1 γnk . constructed as a weighted sum of the converged Gaussian
When the M-step is not tractable however, we resort to bases, with weights given by the converged responsibilities
the generalized EM (GEM) algorithm, whereby instead of (Li et al. 2019; Wang et al. 2020). As a result, reconstructing
maximizing Q(θ, q) with respect to θ the aim is to at least e ∈ RN ×C , which we call the R-step, is
the input features X
increase it, typically by taking a step of a nonlinear optimiza- also implemented by matrix multiplication:
tion method such as gradient ascent or the Newton-Raphson
method. In this paper, we use the GEM algorithm based e = γ (T ) µ(T )
R-step: X (10)
on the Newton-Raphson method for its favorable properties,
which are described in section 4.2: Unrolling T iterations of E- and M-steps followed by one
−1 R-step incurs O(N KT ) complexity (Li et al. 2019). How-
" #
new old ∂2Q ∂Q
θ =θ −η (6) ever, T can be treated as a small constant for the values used
∂θ∂θ ∂θ old in our experiments, resulting in a complexity of O(N K).
θ=θ
3.2 Unrolled Expectation Maximization 4 Highway Expectation Maximization
In this section, we no longer consider EM iterations as an Networks
algorithm, but rather as a sequence of layers in a neural
network-like architecture. This structure, which we refer to 4.1 Vanishing Gradient Problem of EM
as “unrolled EM”, is comprised of a pre-defined T number Vanishing gradients in unrolled EM layers stem from the
of alternating E- and M-steps, both of which are consid- E-step’s scaled dot-product softmax operation, shown in
ered as network layers that take as input the output of its Eq. (8). This also happens to be the key operation of the
previous step and the feature map X generated by a back- self-attention mechanism in the Transformer (Vaswani et al.
bone CNN. For simplicity, we consider the feature map X 2017), which was first proposed to address vanishing gradi-
of shape C × H × W from a single sample, which we re- ents associated with softmax saturation; without scaling, the
shape into N × C, where N = H × W . magnitude of the dot-product logits grows larger with in-
Given the CNN features X ∈ RN ×C and Gaussian bases creasing number of channels C, resulting in a saturated soft-
from the t-th iteration µ(t) ∈ RK×C , the E-step com- max with extremely small local gradients. Therefore, gradi-
putes the responsibilities γ (t+1) ∈ RN ×K according to ents won’t be backpropagated to layers below a saturated
Eq. (4), which can be rewritten in terms of the RBF kernel softmax. The Transformer counteracts this issue in self-
exp(−||xn − µk ||22 /σ 2 ): attention layers by setting the softmax temperature σ 2 =
√
(t)
exp(−||xn − µk ||22 /σ 2 ) C, thereby curbing the magnitude of the logits.
(t+1)
γnk = PK (t) 2
(7) However, even with this dot-product scaling operation the
2
j=1 exp(−||xn − µj ||2 /σ ) Transformer is still prone to gradient vanishing, making it
extremely difficult to train very deep models (Bapna et al.
Xµ(t)>
E-step: γ (t+1) = softmax (8) 2018; Wang et al. 2019). In fact, the training procedure has
σ2 shown to even collapse when residual connections are re-
As shown in Eq. (8), the RBF kernel can be replaced by moved from the Transformer (Bapna et al. 2018). To make
the exponential inner dot product exp(x> 2
n µk /σ ), which
matters worse, an EM layer only has a single gradient path
brings little difference to the overall results (Wang et al. through µ(t) that reach lower EM layers, as opposed to the
2018; Li et al. 2019) and can be efficiently implemented by a self-attention layer, which backpropagates gradients through
softmax applied to a matrix multiplication operation scaled multiple paths and therefore has shown to prevent more se-
by the temperature σ 2 . vere gradient vanishing (Zhang, Titov, and Sennrich 2019).N-step its (shared) input, by first recursively applying Eq. (13):
* (T ) (t)
E-step M-step µk =(1 − η)(T −t) µk
(T −1 )
Scale Softmax Norm * X
(T −i−1) EM (i) (14)
1×1
+ η(1 − η) F µk , X ,
Conv
i=t
Figure 2: Architecture of single HEM layer, which is com- and then applying the chain rule to Eq. (14), where E, T ,
(i) (i)
F̂k = η(1 − η)(T −i−1) F EM µk , X are the loss func-
prised of one E-step and N-step operation
tion, number of HEM layers, and shorthand that absorbs the
scalars, respectively:
(T )
4.2 Unrolled Highway Expectation Maximization ∂E ∂E ∂µk
(t)
= (T ) (t)
In order to resolve the vanishing gradient problem in un- ∂µk ∂µk
∂µk
rolled EM layers, we propose Highway Expectation Max- T −1 (15)
∂E (T −t) ∂ X (i)
imization Networks (HEMNet), which is comprised of = (T ) (1 − η) + (t)
F̂k
unrolled GEM iterations based on the Newton-Raphson ∂µk ∂µk i=t
method, as shown in Fig. 1. The key difference between It can be seen that the upstream gradients to µk is the
HEMNet and unrolled EM is that the original M-step is re- sum of two gradient terms: a term (1 − η)(T −t) ∂E(T )
placed by one Newton-Raphson step, or N-step: ∂µk
directly propagated through the skip connections and a
N-step: PT −1 (i)
term ∂E(T ) ∂(t) i=t F̂k propagated through the E-step,
∂µk ∂µk
−1
∂2Q which is negligible due to the E-step’s vanishing gradient
(t+1) (t) ∂Q
µk = −η
µk (11) problem and hence can be ignored. This means that as we
∂µk ∂µk ∂µk
( N (t+1) ) increase the scalar (1 − η)(T −t) (by reducing η), the propor-
(t) −σ 2 Xγ
nk (t) tion of upstream gradients backpropagated to earlier HEM
= µk − η (t+1) xn −µk )
Nk σ 2 layers increases as well. Furthermore, it can be seen that
n=1
when η = 1 (the original EM case) the skip connection
(12)
! term in Eq. (15) vanishes and leaves only gradients prop-
N
(t) 1 X (t+1) agated through the gradient-attenuating E-step, highlighting
= (1 − η)µk +η (t+1)
γnk xn , (13) the vanishing gradient problem of unrolled EM.
| {z } Nk n=1 One consequence of Eq. (15) is that as η decreases, the
skip connection | {z }
(t)
F EM µk , X
backbone network parameters will be increasingly influ-
enced by earlier HEM layers, as shown in the following
derivation of the upstream gradients to input point xn , which
where η is a hyperparameter that denotes the step size. For
is generated by the backbone network:
GMMs, the N-step update is given by Eq. (11), which re-
T
arranged becomes Eq. (13), a weighted sum of the current ∂E X ∂E
(t) (t) = (16)
µk and the output of one EM iteration F EM µk , X . In- ∂xn (t)
t=1 ∂xn
terestingly, the original M-step is recovered when η = 1,
T X K (t) (t) (t)
implying that the N-step generalizes the EM algorithm. X ∂E ∂µk ∂E ∂µk ∂γnk
= + (17)
Eq. (13) is significant as the first term introduces a skip (t) ∂x (t) (t) ∂x
t=1 k=1 ∂µk n ∂µ ∂γ n
connection that allows gradients to be directly backpropa- | {z } | k {znk }
gated to earlier EM layers, thereby alleviating vanishing gra- grad. from N-step grad. from E-step
dients. Furthermore, the weighted-sum update of the N-step T X
K
( ) (t)
!
X
(T −t) ∂E γnk
endows HEMNet with two more crucial properties: improv- ≈ (1 − η) η (t) (18)
(T )
ing the ELBO in the forward pass and incurring negligible t=1 k=1 ∂µk Nk
additional space-time complexity compared to unrolled EM. Eq. (17) shows that, ignoring the gradients from the E-step,
(t)
∂E ∂µk ∂E
Backward-pass properties: alleviating vanishing gradi- ∂xn becomes a weighted sum of ∂xn weighted by (t) ,
∂µk
ents The update equation of Eq. (13) resembles that of which is substituted with Eq. (15). As η is reduced, the up-
the Highway Network (Srivastava, Greff, and Schmidhuber stream gradients to earlier HEM layers grow relatively larger
2015), which contain scaled skip connections, or highways, in magnitude, meaning that the loss gradients with respect
that facilitate information flow between neighboring layers. to xn become increasingly dominated by earlier HEM lay-
HEMNet also contains highways in between its unrolled it- ers. Therefore, the backbone network can potentially learn
erations, or HEM layers, that bypass the gradient-attenuating better representations as it takes into account the effect of its
E-step and allow gradients to be directly sent back to earlier parameters on not only the final HEM layers, but also on ear-
HEM layers, as shown in Fig. 2. To show this, we derive ex- lier HEM layers, where most of the convergence of the EM
pressions for the upstream gradients to each HEM layer and procedure occurs. A full derivation is given in Appendix A.Table 1: Ablation study on training iteration number Ttrain Table 2: Ablation study on evaluation iteration number Teval .
and step size ηtrain on PASCAL VOC. The rightmost column For each ηtrain , we perform ablations on the best Ttrain (un-
denotes EMANet (Li et al. 2019), where ηtrain = 1.0. derlined). The best Teval is highlighted in bold.
XXXηtrain XXXηtrain
XXX XXX
0.1 0.2 0.4 0.8 EMANet (1.0) 0.1 0.2 0.4 0.8 EMANet (1.0)
Ttrain XXX Teval XXX
1 77.17 77.50 77.92 77.26 77.31 1 64.52 70.30 73.20 77.16 76.26
2 77.16 77.80 77.50 78.10 77.55 2 70.72 75.50 76.94 78.10 77.55
3 77.05 77.82 77.81 77.94 76.51 3 73.72 77.33 77.85 78.34 77.73
4 77.64 77.73 78.11 77.10 76.63 4 75.34 77.96 78.11 78.42 77.70
6 77.46 78.22 77.83 77.40 76.26 6 76.88 78.22 78.24 78.37 77.50
8 77.48 78.14 77.60 78.04 76.48 8 77.47 78.13 78.24 78.30 77.37
12 77.74 78.11 77.73 77.84 76.17 12 77.74 77.98 78.19 78.26 77.21
16 77.64 77.65 77.81 77.06 76.29 16 77.84 77.90 78.17 78.23 77.16
ELBO (iter. 0) Gradient to X from N-step (iter. 0) Gradient to X from E-step (iter. 0) Total gradient to X
1×101 Mean absolute grad. 3×105
= 0.1
1.2×101 = 0.2
2×10 5 = 0.4
ELBO
1.4×101 = 0.8
= 1.0
1.6×101 10 5
1.8×101 0
1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 0 10000 20000 30000
HEM layer HEM layer HEM layer iteration
(a) (b) (c) (d)
Figure 3: The effects of changing ηtrain on (a) the ELBO, (b) the gradient to input X from N-step and (c) from E-step at the
beginning of training, and (d) the total gradient to X during training. The E-step gradients in (c) are on the order of 10−7 and
is therefore not displayed. The mean absolute gradients were computed by backpropagating with respect to the same set of 100
randomly chosen training samples, every 2000 training iterations.
Forward-pass properties: improvement of ELBO In the 5 Experiments
forward pass, the N-step increases the ELBO for fractional
5.1 Implementation Details
step sizes, as shown in the following proposition:
We use ResNet (He et al. 2016a) pretrained on Ima-
Proposition 1. For step size η ∈ (0, 1], the N-step of a HEM geNet (Russakovsky et al. 2015) with multi-grid (Chen et al.
iteration given by Eq. (13) updates µ such that 2017) as the backbone network. We use ResNet-50 with an
L(µ(t+1) , γ (t+1) ) > L(µ(t) , γ (t+1) ), (19) output stride (OS) of 16 for all ablation studies and Resnet-
101 with OS = 8 for comparisons with other state-of-the-
√
unless µ(t+1) = µ(t) , where L(µ, γ) is the ELBO defined art approaches. We set the temperature σ 2 = C follow-
for GMMs in Eq. (3), γ (t+1) are the responsibilities com- ing (Vaswani et al. 2017), where C is the number of in-
puted in the E-step using µ(t) , and t is the iteration number. put channels to HEMNet, which is set to 512 by default.
The step size is set to η = 0.5 for PASCAL VOC (Ever-
The proof is given in Appendix B. Since HEMNet is com- ingham et al. 2010) and PASCAL Context (Mottaghi et al.
prised of alternating E-steps and N-steps, it monotonically 2014), and η = 0.6 for COCO Stuff (Caesar, Uijlings,
increases the ELBO, just as does the original unrolled EM. and Ferrari 2018). We set the training iteration number to
This is a non-trivial property of HEMNet. Monotonically in- Ttrain = 3 for all datasets. We use the moving average
creasing the ELBO converges the unrolled HEM iterations mechanism (Ioffe and Szegedy 2015; Li et al. 2019) to up-
to a (local) maximum of the data-log likelihood. In other date the initial Gaussian bases µ(0) . We adopt the mean
words, with every successive HEM iteration, the updated Intersection-over-Union (mIoU) as the performance metric
Gaussian bases µk and attention weights γnk can better re- for all experiments across all datasets. Further details, in-
construct the original input points, as important semantics of cluding the training regime, are outlined in Appendix C.
the inputs are increasingly distilled into the GMM parame-
ters (Li et al. 2019). 5.2 Ablation Studies
Computational Complexity Eq. (13) shows that comput- Ablation study on step size In Fig. 3, we analyze the ef-
ing the N-step update requires one additional operation to fects of the step size ηtrain on the ELBO in the forward pass
the original M-step: a convex summation of the M-step out- and the gradient flow in the backward pass. It can be seen
put F EM µ(t) , X and the current µ(t) estimate. This op- that as ηtrain is reduced, the convergence of the ELBO slows
eration incurs minimal additional computation and memory down, requiring more unrolled HEM layers than would oth-
costs compared to the matrix multiplications in the E- and erwise (Fig. 3a) . On the other hand, the gradients backprop-
M-step, which dominates unrolled EM. Therefore, HEMNet agated to input X from each HEM layer, which is dominated
has O(N K) space-time complexity, as does unrolled EM. by the N-step, become more evenly distributed as a greaterTable 3: Comparisons on PASCAL VOC val set in mIoU Table 5: Comparisons on the PASCAL Context test set. ‘+’
(%). All results are computed for a ResNet-101 backbone, means pretraining on COCO.
where OS = 8 for training and evaluation. FLOPs and mem-
ory are computed for input size of 513 × 513. SS: Single- Method Backbone mIoU (%)
scale input testing. MS: Multi-scale input testing. Flip: PSPNet (Zhao et al. 2017) ResNet-101 47.8
Adding left-right flipped input. (256), (512) denote the no. MSCI (Lin et al. 2018) ResNet-152 50.3
of input channels to EMANet and HEMNet. SGR (Liang et al. 2018) ResNet-101 50.8
CCL (Ding et al. 2018) ResNet-101 51.6
EncNet (Zhang et al. 2018a) ResNet-101 51.7
Method SS MS+Flip FLOPs Memory Params SGR+ (Liang et al. 2018) ResNet-101 52.5
ResNet-101 - - 370.1G 6.874G 40.7M DANet (Fu et al. 2019) ResNet-101 52.6
DeeplabV3+ (Chen et al. 2018) 77.62 78.72 +142.6G +318M +16.0M EMANet (Li et al. 2019) ResNet-101 53.1
PSANet (Zhao et al. 2018) 78.51 79.77 +185.7G +528M +26.4M CFNet (Zhang et al. 2019) ResNet-101 54.0
EMANet (256) (Li et al. 2019) 79.73 80.94 +45.2G +236M +5.15M HEMNet ResNet-101 54.3
HEMNet (256) 80.93 81.44 +45.2G +236M +5.15M
EMANet (512) (Li et al. 2019) 80.05 81.32 +92.3G +329M +10.6M
HEMNet (512) 81.33 82.23 +92.3G +331M +10.6M
Table 6: Comparisons on COCO Stuff test set.
Table 4: Comparisons on the PASCAL VOC test set. Method Backbone mIoU (%)
RefineNet (Lin et al. 2017) ResNet-101 33.6
Method Backbone mIoU (%) CCL (Ding et al. 2018) ResNet-101 35.7
PSPNet (Zhao et al. 2017) ResNet-101 85.4 DSSPN (Liang, Zhou, and Xing 2018) ResNet-101 37.3
DeeplabV3 (Chen et al. 2017) ResNet-101 85.7 SGR (Liang et al. 2018) ResNet-101 39.1
PSANet (Zhao et al. 2018) ResNet-101 85.7 DANet (Fu et al. 2019) ResNet-101 39.7
EncNet (Zhang et al. 2018a) ResNet-101 85.9 EMANet (Li et al. 2019) ResNet-101 39.9
DFN (Yu et al. 2018) ResNet-101 86.2 HEMNet ResNet-101 40.1
Exfuse (Zhang et al. 2018b) ResNet-101 86.2
SDN (Fu et al. 2019) ResNet-101 86.6
DIS (Luo et al. 2017) ResNet-101 86.8
CFNet (Zhang et al. 2019) ResNet-101 87.2
EMANet (Li et al. 2019) ResNet-101 87.7 ber Ttrain up to a certain point, after which it decreases.
HEMNet ResNet-101 88.0 This is likely attributed to the vanishing gradient problem
as an exponentially less proportion of the upstream gradi-
ents reach earlier HEM layers as Ttrain increases, meaning
proportion of upstream gradients are sent to earlier HEM that the backbone network parameters are increasingly in-
layers (Fig. 3b) . The subtlety here is that reducing ηtrain fluenced by the later HEM layers, which amounts to a mere
does not seem to necessarily increase the magnitude of the identity mapping of the GMM parameter estimates for high
total upstream gradients to X (Fig. 3d), since the gradients values of Ttrain . This is corroborated by the observation that
sent back to X from the tth HEM layer is proportional to the performance peaks at larger Ttrain for smaller η, which
can be explained by the fact that smaller η slows down the
η(1 − η)(T −t) , as shown in Eq. (18). This suggests that the
exponential decay of the upstream gradients to earlier HEM
change in performance from changing η is likely due to the
layers, allowing us to unroll more HEM layers. In the case
resulting change in relative weighting among the different
of EMANet (Li et al. 2019) the performance peaks at a low
HEM layers when computing the gradients with respect to
value of Ttrain = 2, most likely because gradients aren’t
xn , not the absolute magnitude of those gradients.
backpropagated through the unrolled EM iterations, prevent-
In other words, there is a trade-off, controlled by ηtrain , ing the rest of the network from learning representations op-
between the improvement of the ELBO in the forward pass timized for the EM procedure.
and how evenly the early and later HEM layers contribute Table 2 shows the effect of changing the evaluation iter-
to backpropagating gradients to X in the backward pass. Ta- ation number, after training. It can be seen that for all val-
ble 1 shows this trade-off, where the best performance for ues of ηtrain except 0.2, increasing T beyond Ttrain during
each value of Ttrain is achieved by intermediate values of evaluation, where vanishing gradients is no longer an issue,
ηtrain , suggesting that they best manage this trade-off. Fur- can further improve performance. The observation can be at-
thermore, the best ηtrain decreases for larger Ttrain , as later tributed to the improvement in the ELBO with more HEM
HEM layers become increasingly redundant as they con- layers, which is consistent with previous findings (Jampani
verge to an identity mapping of the GMM parameter esti- et al. 2018; Li et al. 2019). We suspect that the reason for the
mates as the underyling EM procedure converges as well. performance deterioration at high values of Teval is that the
Reducing the step size reduces the relative weighting on Gaussian bases have not fully converged at the chosen values
these redundant layers by increasing proportion of upstream of Ttrain and that there is still room for the Gaussian bases’
gradients sent to earlier HEM layers, resulting in potentially norms to change, making it difficult for HEMNet to gener-
better learned representations. alize beyond its training horizon (David Krueger 2016).
Ablation study on iteration number We further inves-
tigate the effect of changing the training iteration number. 5.3 Comparisons with State-of-the-arts
It can be seen in Table 1 that for all step sizes ηtrain the We first compare our approach to EMANet (Li et al. 2019)
mIoU generally increases with the training iteration num- and other baselines on the PASCAL VOC validation set. Ta-Image Label Prediction Input Feature Maps X
Attention Maps γ (t) e (t)
Reconstructed Inputs X
t=1
t=2
t=3
γ ·i γ ·j γ ·k X
e ·a X
e ·b X
e ·c
Figure 4: Visualization of the attention maps γ, input feature maps X from the backbone CNN, and reconstructed inputs
Xe = γµ for a sample image from the PASCAL VOC 2012 val set. The images in the top-left corner contain the original image,
label, and the prediction made by HEMNet with a ResNet-101 backbone. The three rows below show the attention maps (left)
and reconstructed inputs (right) at each HEM iteration. γ ·k denotes the attention map w.r.t. the kth Gaussian basis µk and X
e ·c
denotes the cth channel of the reconstructed input, where 1 ≤ i, j, k ≤ K and 1 ≤ a, b, c ≤ C.
ble 3 shows that HEMNet outperforms all baselines by a structed from the updated γ and µ increasingly recovers its
large margin. Most notably, HEMNet outperforms EMANet fundamental semantics from the noisy input X, while pro-
while incurring virtually the same computation and memory gressively suppressing irrelevant concepts and details. This
costs and using the same number of parameters. Further- stems from the fact that every HEM iteration monotonically
more, HEMNet with 256 input channels exceeds EMANet increases the ELBO, and hence the log-likelihood with re-
with 512 input channels, and HEMNet’s single-scale (SS) spect to the input features, thereby removing unnecessary
performance is on par with EMANet’s multi-scale (MS) per- noise and distilling the important semantics from X into
formance, which is a robust method for improving semantic Gaussian bases µ.
segmentation accuracy (Zhao et al. 2017; Chen et al. 2018;
Fu et al. 2019; Li et al. 2019). We also display significant 6 Conclusion
improvement in performance over EMANet on the PASCAL
VOC, PASCAL Context and COCO Stuff test set, as shown In this work, we proposed Highway Expectation Maximiza-
in Table 4, Table 5, and Table 6. tion Networks (HEMNet) in order to address the vanishing
gradient problem present in expectation maximization (EM)
5.4 Visualizations iterations. The proposed HEMNet is comprised of unrolled
iterations of the generalized EM algorithm based on the
In Fig. 4, we demonstrate the effect of improving the ELBO
Newton-Rahpson method, which introduces skip connec-
in HEMNet by visualizing the responsibilities γ, which act
tions that ameliorate gradient flow while preserving the un-
as attention weights, and the feature map X e reconstructed
derlying EM procedure and incurring minimal additional
from those attention weights. It can be seen that the attention computation and memory costs. We performed extensive ab-
map with respect to each Gaussian basis attends to a spe- lation studies and experiments on several semantic segmen-
cific aspect of the input image, suggesting that each Gaus- tation benchmarks to demonstrate that our approach effec-
sian basis corresponds to a particular semantic concept. For tively alleviates vanishing gradients and enables better per-
instance, the attention maps with respect to bases i, j, and k formance.
appear to highlight the background, person and motorbike,
respectively.
Furthermore, after every HEM iteration the attention Broader Impact
maps grow sharper and converges to the underlying seman- Our research can be broadly described as an attempt to lever-
tics of each basis. As a result, every feature map recon- age what has been two very successful approaches to ma-chine learning: model-based methods and deep neural net- for Statistical Machine Translation. In Proceedings of the
works. Deep learning methods have shown state-of-the-art 2014 Conference on Empirical Methods in Natural Lan-
performance in a variety of applications due to their excel- guage Processing (EMNLP), 1724–1734.
lent ability for representation learning, but they are consid- David Krueger, R. M. 2016. Regularizing RNNs by Stabiliz-
ered as black box methods, making it extremely difficult to ing Activations. In 4th International Conference on Learn-
interpret their inner workings or incorporate domain knowl- ing Representations, ICLR 2016, San Juan, Puerto Rico,
edge of the problem at hand. Combining deep neural net- May 2-4, 2016, Conference Track Proceedings.
works with well-studied, classical model-based approaches
provide a straightforward way to incorporate problem spe- Dempster, A. P.; Laird, N. M.; and Rubin, D. B. 1977. Maxi-
cific assumptions, such as those from the physical world mum likelihood from incomplete data via the EM algorithm.
like three-dimensional geometry or visual occlusion. Fur- Journal of the Royal Statistical Society, Series B 39(1): 1–
thermore, this combined approach also provides a level of 38.
interpretability to the inner workings of the system, through Ding, H.; Jiang, X.; Shuai, B.; Liu, A. Q.; and Wang, G.
the lens of well-studied classical methods. In our paper we 2018. Context Contrasted Feature and Gated Multi-scale
consider a semantic segmentation task, which has become Aggregation for Scene Segmentation. IEEE Conference on
a key component of the vision stack in autonomous driv- Computer Vision and Pattern Recognition (CVPR) 2393–
ing technology. Combining deep neural networks with the 2402.
model-based approaches can be crucial for designing and
analyzing the potential failure modes of such safety-critical Everingham, M.; Gool, L.; Williams, C. K.; Winn, J.; and
applications of deep-learning based systems. For instance Zisserman, A. 2010. The Pascal Visual Object Classes
in our approach, the Gaussian bases converge to specific (VOC) Challenge. Int. J. Comput. Vision 88(2): 303–338.
semantics with every passing EM iteration, and the corre- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; and Lu, H.
sponding attention maps give an indication of the underlying 2019. Dual Attention Network for Scene Segmentation. In
semantics of a given input image. This can help researchers IEEE Conference on Computer Vision and Pattern Recogni-
better understand what the system is actually learning, which tion (CVPR), 3146–3154.
can be invaluable, for example, when trying to narrow down
the reason for an accident induced by a self-driving vehicle. Fu, J.; Liu, J.; Wang, Y.; Zhou, J.; Wang, C.; and Lu, H.
We hope that our work encourages researchers to incorpo- 2019. Stacked Deconvolutional Network for Semantic Seg-
rate components inspired by classical model-based machine mentation. IEEE Transactions on Image Processing 1–1.
learning into existing deep learning architectures, enabling Gers, F. A.; Schmidhuber, J.; and Cummins, F. 1999. Learn-
them to embed their domain knowledge into the design of ing to forget: continual prediction with LSTM. In 1999
the network, which in turn may provide another means to Ninth International Conference on Artificial Neural Net-
better interpret its inner mechanism. works ICANN 99. (Conf. Publ. No. 470), volume 2, 850–855
vol.2.
References Greff, K.; Van Steenkiste, S.; and Schmidhuber, J. 2017.
Bapna, A.; Chen, M.; Firat, O.; Cao, Y.; and Wu, Y. 2018. Neural expectation maximization. In Advances in Neural
Training Deeper Neural Machine Translation Models with Information Processing Systems (NIPS), 6691–6701.
Transparent Attention. In Proceedings of the 2018 Confer-
ence on Empirical Methods in Natural Language Process- He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016a. Deep resid-
ing, 3028–3033. ual learning for image recognition. In IEEE Conference
on Computer Vision and Pattern Recognition (CVPR), 770–
Bengio, Y.; Simard, P.; and Frasconi, P. 1994. Learning long- 778.
term dependencies with gradient descent is difficult. IEEE
Transactions on Neural Networks 5(2): 157–166. He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016b. Identity Map-
pings in Deep Residual Networks. In European Conference
Caesar, H.; Uijlings, J.; and Ferrari, V. 2018. COCO-Stuff: on Computer Vision (ECCV), 630–645.
Thing and Stuff Classes in Context. In IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), 1209– Hershey, J. R.; Roux, J. L.; and Weninger, F. 2014. Deep
1218. Unfolding: Model-Based Inspiration of Novel Deep Archi-
tectures. arXiv preprint arXiv:1409.2574 .
Chen, L.-C.; Papandreou, G.; Schroff, F.; and Adam, H.
2017. Rethinking atrous convolution for semantic image Hinton, G. E.; Sabour, S.; and Frosst, N. 2018. Matrix
segmentation. arXiv preprint arXiv:1706.05587 . capsules with EM routing. In International Conference on
Learning Representations.
Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; and
Adam, H. 2018. Encoder-Decoder with Atrous Separable Hochreiter, S.; and Schmidhuber, J. 1997. Long short-term
Convolution for Semantic Image Segmentation. In Euro- memory. Neural computation 9(8): 1735–1780.
pean Conference on Computer Vision (ECCV), 801–818. Huang, G.; Liu, Z.; Van Der Maaten, L.; and Weinberger,
Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; K. Q. 2017. Densely connected convolutional networks. In
Bougares, F.; Schwenk, H.; and Bengio, Y. 2014. Learn- IEEE Conference on Computer Vision and Pattern Recogni-
ing Phrase Representations using RNN Encoder–Decoder tion (CVPR), 4700–4708.Ioffe, S.; and Szegedy, C. 2015. Batch Normalization: Ac- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones,
celerating Deep Network Training by Reducing Internal Co- L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. At-
variate Shift. In Proceedings of the 32nd International Con- tention is all you need. In Advances in Neural Information
ference on Machine Learning, 448–456. Processing Systems (NIPS), 5998–6008.
Jampani, V.; Sun, D.; Liu, M.-Y.; Yang, M.-H.; and Kautz, Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D. F.; and
J. 2018. Superpixel sampling networks. In European Con- Chao, L. S. 2019. Learning deep transformer models for
ference on Computer Vision (ECCV), 352–368. machine translation. arXiv preprint arXiv:1906.01787 .
Lange, K. 1995. A gradient algorithm locally equivalent to Wang, X.; Girshick, R.; Gupta, A.; and He, K. 2018. Non-
the EM algorithm. Journal of the Royal Statistical Society: local Neural Networks. In IEEE Conference on Computer
Series B (Methodological) 57(2): 425–437. Vision and Pattern Recognition (CVPR), 7794–7803.
Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; and Liu, H. Wang, Z.; Wang, S.; Yang, S.; Li, H.; Li, J.; and Li, Z. 2020.
2019. Expectation-Maximization Attention Networks for Weakly Supervised Fine-Grained Image Classification via
Semantic Segmentation. In IEEE International Conference Guassian Mixture Model Oriented Discriminative Learning.
on Computer Vision (ICCV), 9167–9176. In Proceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR).
Liang, X.; Hu, Z.; Zhang, H.; Lin, L.; and Xing, E. P. 2018.
Symbolic graph reasoning meets convolutions. In Advances Wu, C. J. 1983. On the Convergence Properties of the EM
in Neural Information Processing Systems (NIPS), 1853– Algorithm. The Annals of statistics 95–103.
1863. Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; and Sang, N.
Liang, X.; Zhou, H.; and Xing, E. 2018. Dynamic- 2018. Learning a Discriminative Feature Network for Se-
Structured Semantic Propagation Network. IEEE Confer- mantic Segmentation. In The IEEE Conference on Computer
ence on Computer Vision and Pattern Recognition (CVPR) Vision and Pattern Recognition (CVPR).
752–761. Zhang, B.; Titov, I.; and Sennrich, R. 2019. Improving Deep
Lin, D.; Ji, Y.; Lischinski, D.; Cohen-Or, D.; and Huang, Transformer with Depth-Scaled Initialization and Merged
H. 2018. Multi-scale context intertwining for semantic seg- Attention. In Proceedings of the 2019 Conference on Empir-
mentation. In European Conference on Computer Vision ical Methods in Natural Language Processing and the 9th
(ECCV), 603–619. International Joint Conference on Natural Language Pro-
cessing (EMNLP-IJCNLP), 898–909.
Lin, G.; Milan, A.; Shen, C.; and Reid, I. 2017. RefineNet:
Multi-Path Refinement Networks for High-Resolution Se- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi,
mantic Segmentation. In IEEE Conference on Computer Vi- A.; and Agrawal, A. 2018a. Context encoding for semantic
sion and Pattern Recognition (CVPR), 1925–1934. segmentation. In IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), 7151–7160.
Luo, P.; Wang, G.; Lin, L.; and Wang, X. 2017. Deep
Dual Learning for Semantic Image Segmentation. In 2017 Zhang, H.; Zhang, H.; Wang, C.; and Xie, J. 2019. Co-
IEEE International Conference on Computer Vision (ICCV), Occurrent Features in Semantic Segmentation. In IEEE
2737–2745. Conference on Computer Vision and Pattern Recognition
(CVPR), 548–557.
Mottaghi, R.; Chen, X.; Liu, X.; Cho, N.-G.; Lee, S.-W.; Fi-
dler, S.; Urtasun, R.; and Yuille, A. 2014. The Role of Con- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; and Sun, J. 2018b.
text for Object Detection and Semantic Segmentation in the ExFuse: Enhancing Feature Fusion for Semantic Segmenta-
Wild. In IEEE Conference on Computer Vision and Pattern tion. In Proceedings of the European Conference on Com-
Recognition (CVPR), 891–898. puter Vision (ECCV).
Neal, R. M.; and Hinton, G. E. 1999. A View of the EM Algo- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; and Jia, J. 2017. Pyramid
rithm That Justifies Incremental, Sparse, and Other Variants, scene parsing network. In IEEE Conference on Computer
355–368. Cambridge, MA, USA: MIT Press. Vision and Pattern Recognition (CVPR), 2881–2890.
Richardson, S.; and Green, P. J. 1997. On Bayesian analysis Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C. C.; Lin, D.; and
of mixtures with an unknown number of components (with Jia, J. 2018. PSANet: Point-wise Spatial Attention Network
discussion). Journal of the Royal Statistical Society: series for Scene Parsing. In European Conference on Computer
B (statistical methodology) 59(4): 731–792. Vision (ECCV), 267–283.
Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.;
Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.;
Berg, A. C.; and Fei-Fei, L. 2015. ImageNet Large Scale Vi-
sual Recognition Challenge. International Journal of Com-
puter Vision (IJCV) 115(3): 211–252.
Srivastava, R. K.; Greff, K.; and Schmidhuber, J. 2015.
Training very deep networks. In Advances in Neural Infor-
mation Processing Systems (NIPS), 2377–2385.You can also read

















































