Information Prediction using Knowledge Graphs for Contextual Malware Threat Intelligence
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Information Prediction using Knowledge Graphs for
Contextual Malware Threat Intelligence
Nidhi Rastogi, Sharmishtha Dutta, Ryan Christian, Mohammad Zaki, Alex Gittens
Rensselaer Polytechnic Institute, Troy, NY
Charu Aggarwal
arXiv:2102.05571v2 [cs.CR] 18 Feb 2021
IBM Research, Yorktown, NY
Abstract This information is available in abundance; however, it is
Large amounts of threat intelligence information about mal- typically in non-standard and unstructured formats. Besides,
ware attacks are available in disparate, typically unstructured, information is not always accurate or complete. For exam-
formats. Knowledge graphs can capture this information and ple, threat reports2 about the recent attacks on SolarWinds
its context using RDF triples represented by entities and rela- software captured detailed analysis on the Sunspot malware
tions. Sparse or inaccurate threat information, however, leads that inserted the Sunburst malware into SolarWinds’ Orion
to challenges such as incomplete or erroneous triples. Named software. The timeline has changed in subsequent reports as
entity recognition (NER) and relation extraction (RE) models more information became revealed. However, no information
used to populate the knowledge graph cannot fully guaran- is available about the threat actor, although the Sunburst mal-
tee accurate information retrieval, further exacerbating this ware and a backdoor linked to the Turla advanced persistent
problem. This paper proposes an end-to-end approach to gen- threat (APT) group share similarities. Knowledge graphs can
erate a Malware Knowledge Graph called MalKG, the first enable the identification of this missing information about the
open-source automated knowledge graph for malware threat attack actor.
intelligence. MalKG dataset called MT40K1 , contains approx- A primary goal for security threat researchers is to automate
imately 40,000 triples generated from 27,354 unique entities threat detection and prevention with minimal human involve-
and 34 relations. We demonstrate the application of MalKG ment in the loop. AI-enabled technology, together with big
in predicting missing malware threat intelligence informa- data about threats, have the potential to deliver on this to a
tion in the knowledge graph. For ground truth, we manually great extent. Increasing sources of threat information on the
curate a knowledge graph called MT3K, with 3,027 triples Internet, such as analysis reports, blogs, common vulnerabili-
generated from 5,741 unique entities and 22 relations. For ties, and exposure databases (CVE, NVD), provide enough
entity prediction via a state-of-the-art entity prediction model data to evaluate the current threat landscape and prepare our
(TuckER), our approach achieves 80.4 for the hits@10 met- defenses against future ones. Structuring this mostly unstruc-
ric (predicts the top 10 options for missing entities in the tured data and converting it into a usable format solves only
knowledge graph), and 0.75 for the MRR (mean reciprocal one problem. It misses out on capturing the context of the
rank). We also propose a framework to automate the extrac- threat information, which can significantly boost threat intel-
tion of thousands of entities and relations into RDF triples, ligence. However, several challenges need addressing before
both manually and automatically, at the sentence level from this step, for instance: (a) lack of standardized data aggrega-
1,100 malware threat intelligence reports and from the com- tion formats that collect both data and context, (b) limitations
mon vulnerabilities and exposures (CVE) database. in data extraction models that lead to incomplete information
gathered about attacks, and (c) inaccurate data extracted from
threat information. In this paper, we address the first two chal-
1 Introduction lenges. The third challenge that addresses the trustworthiness
of source information is left as future work.
Malware threat intelligence informs security analysts and re-
One might argue that data sources such as Common Vulner-
searchers about trending attacks and defense mechanisms.
abilities and Exposures (CVE) [38] and National Vulnerability
They use this intelligence to help them in their increasingly
Database (NVD) [27], and standards like Structured Threat
complex jobs of finding zero-day attacks, protecting intel-
Information Expression (STIX) [3] can effectively aggregate
lectual property, and preventing intrusions from adversaries.
1 Anonymous GitHub link: https://github.com/malkg-researcher/MalKG 2 https://www.cyberscoop.com/turla-solarwinds-kaspersky/
1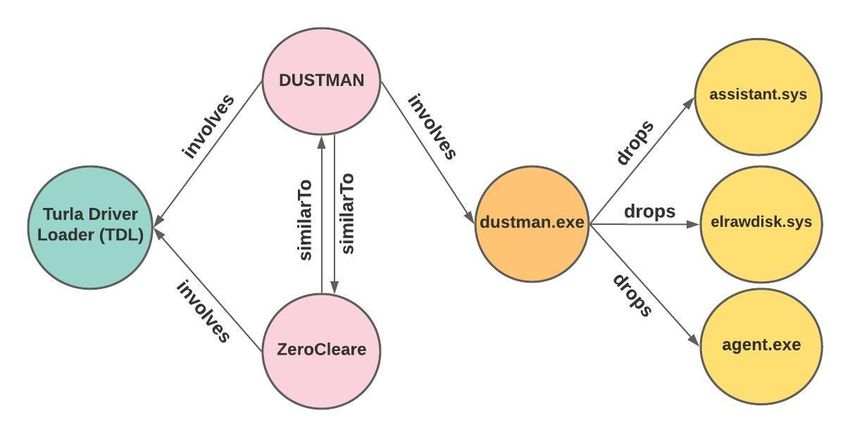
threat and vulnerability data in an automated way. However, space can represent an entity, and a matrix can represent a
these data sources and standards overlook the context’s impor- relation. Therefore, entities and relations can be embedded us-
tance, which can be favorably added via linking and semantic ing various approaches [7] [6] [2] [40] into machine readable
metadata. Text data is not a mere aggregation of words. There forms that are amenable to automated analysis and inference.
is a meaning in the information and linking of concepts to Motivation: In the examples described in the previous sec-
outside sources is crucial to its effective use. For example, a tion, knowledge graph completion would predict the missing
human security analyst can correctly comprehend the mean- head entity, i.e., the author of the “Aurora Botnet” malware.
ing of the term “Aurora” in a threat report. It refers to the series MalKG’s completeness primarily relies on two factors: (1)
of cyber attacks conducted by Advanced Persistent Threats information available in the threat reports and (2) the effi-
(APTs) by China, first detected by Google in 2009. However, cacy of NER and RE models. Entity prediction is the task of
a computer or an AI model collecting this information might predicting the best candidate for a missing entity or inferring
mistake it for the Northern Lights unless the security context new facts based on existing information stored in a knowledge
is provided. graph. The rule-based inference using a malware threat intel-
Knowledge graphs bridge this gap by adding context as ligence ontology governs which head and tail entity classes
well as allowing reasoning over data. The smallest unit of a can form relations. In this paper, we present entity prediction
knowledge graph, referred to as an RDF triple [21], comprises based on the TuckER [2] entity recognition model. We also
data instances using entities and relations. Entities capture compare and contrast the performance of entity prediction
real-world objects, events, abstract concepts, and facts. For ex- models that otherwise perform well for datasets in other do-
ample, entities represent malware, organizations, vulnerability, mains. Translation-based embedding models [6, 20, 40] fare
and malware behavioral characteristics for the cybersecurity especially well, as does tensor-factorization [2, 37, 43]. Other
domain. Relations connect entities using key phrases that models perform adequately on specific datasets but do not
describe the relationship between them. Specifically, adding fully express some properties of MalKG, such as one-to-many
context using knowledge graphs in malware threat intelli- relations among entities, not including inverse relations, and
gence opens up many opportunities: very few instances of symmetric relations.
Cybersecurity intelligence is a broad domain, and it is a
1. Entity prediction: Predict the missing entities from a massive undertaking to represent this domain in one knowl-
knowledge graph. Given a malware knowledge graph, edge graph. Therefore, in this research we concentrate on
complete missing information such as malware author malware threat intelligence and study malware examples to
and vulnerabilities. For an incomplete triple h multi- illustrate the work. Nonetheless, the challenges and approach
homed windows systems, hasVulnerability, ? i, entity are broad enough to be applied to other areas in the security
prediction would return an ordered set of entities e.g., domain. Our malware threat intelligence knowledge graph,
{spoofed route pointer, multiple eval injection vulnera- MalKG, is instantiated from malware threat intelligence re-
bility, heap overflow}. In this case, spoofed route pointer ports collected from the Internet. We tokenize approximately
is a correct tail entity for the incomplete triple. 1100 threat reports in PDF format and from the CVE vul-
2. Entity classification: Determine if the class label nerability description database to extract entities covering
of an entity is accurate. For example, correctly de- malware threat intelligence. The instantiating process is de-
termining spoofed route pointer is an instance of scribed in the sections below and includes algorithms for
class:Vulnerability. named entity extraction (NER) and relation extraction (RE).
Together, both NER and RE algorithms are deployed and au-
3. Entity resolution: Determine whether two entities refer to tomated to generate thousands of RDF triples that capture
the same object. For example, Operation AppleJeus and malware threat information into units of a knowledge graph.
Operation AppleJeus Sequel might have similar proper- We also discuss the challenges encountered in this process.
ties. However, they are different malware campaigns and Specifically, the main contributions of this paper are:
should not be resolved to the same entity.
1. We present an end-to-end, automated, ontology-defined
4. Triple classification: Verify if an RDF triple in the mal- knowledge graph generation framework for malware
ware threat intelligence knowledge graph is accurately threat intelligence. 40,000 triples are extracted from
classified. For example, h ZeroCleare, targets, Energy 1,100 threat reports and CVE vulnerability descriptions
Sector In The Middle-East i should be classified as a cor- written in unstructured text format. These triples cre-
rect triple whereas h ZeroCleare, targets, Energy Sector ate the first open-source knowledge graph for extracting
In Russia i should be classified as an incorrect triple. structural and contextual malware threat intelligence for
almost one thousand malware since 1999.
Knowledge Graphs like the MalKG are rich in information
that can be leveraged by statistical learning systems [7]. For 2. The triples are encoded into vector embeddings using
instance, in the MalKG, a low-dimensional embedding vector tensor-factorization based models that can extract latent
2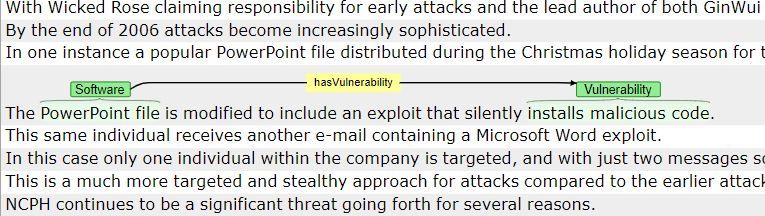
information from graphs and find hidden information.
Table 1: Notations and Descriptions
This is a crucial goal for cybersecurity analysts because
Notation Description
running machine learning models on vector embeddings
E the set of all entities
can produce more accurate and contextual predictions
for autonomous intrusion detection systems. R the set of all relations
T the set of all triples
3. We provide a ground truth dataset, MT3K, which com- hehead , r, etail i head entity, relation and tail entity
prises 5,741 hand-labeled entities and their classes, 22 hh, r, ti embedding of a h, r and a t
relations, and 3,027 triples extracted from 81 unstruc- de , dr embedding dimension of entities, relations
tured threat reports written between 2006-2019. Security ne , nr , nt number of h+t, r, triples
experts validated this data and are extremely valuable fφ scoring function
in training the automation process for larger knowledge
graphs for malware threat intelligence.
graphs such as Freebase [5], Google’s Knowledge Graph3 ,
4. We adopt a state of the art entity and relation extraction
and WordNet [10] have emerged in the past decade. They
models to the cybersecurity domain and map the default
enhance “big-data” results with semantically structured infor-
semantic classification to the malware ontology. We also
mation that is interpretable by computers, a property deemed
ensure that the models scale up to the threat corpus’s
indispensable to build more intelligent machines. No open-
size without compromising on the precision.
source malware knowledge graph exists, and therefore, in
5. Given the MalKG with missing information (or entities) this research, we propose the first of its kind automatically
from the knowledge graph, we demonstrate the effec- generated knowledge graph for malware threat intelligence.
tiveness of entity completion using embedding models The MalKG generation process uses a combination of cu-
that learned accurately and predicted the missing infor- rated and automated unstructured data [21] to populate the
mation from MalKG by finding semantic and syntactic KG. This has helped us in achieving the high-accuracy of a
similarities in other triples of MalKG. curated approach and the efficiency of an automated approach.
MalKG was constructed using existing ontologies [28, 34] as
6. MalKG is open source, and along with the text corpus, they provide a structure to MalKG generation with achievable
triples, and entities, it provides a new benchmark frame- end goals in mind. Ontologies are constructed using compe-
work for novel contextual security research problems. tency questions that pave way for systematic identification
of semantic categories (called classes) and properties (also
2 Background called relations) [28]. An ontology also avoids generation of
redundant triples and accelerates the triple generation process.
2.1 Definitions The MalKG comprises hierarchical entities. For example,
a Malware class can have sub-classes such as TrojanHorse and
The malware knowledge graph, MalKG, expresses hetero- Virus. A hierarchy captures the categories of malware based
geneous multi-modal data as a directed graph, MalKG = on how they spread and infect computers. The relations in
{E, R, T}, where E, R and T indicate the sets of entities, rela- MalKG, on the other hand, are not hierarchical. For instance,
tions and triples (also called facts), respectively. Each triple a Virus (sub-class of Malware) known as WickedRose exploits
hehead , r, etail i ∈ T indicates that there is a relation r ∈ R be- a Microsoft PowerPoint vulnerability and installs malicious
tween ehead ∈ E and etail ∈ E. For the entities and relation code. Here “exploits” is the relation between the entities Virus
ehead , etail , r we use the bold face h, t, r to indicate their low- (a subclass) and Software, and therefore does not require a sub-
dimensional embedding vectors, respectively. We use de and relation to describe a different category of exploit. MalKG
dr to denote the embedding dimensions of entities and re- stores facts like these in the form of a triple.
lations, respectively. The symbols ne , nr , and nt denote the
number of entities, relations, and triples the KG, respectively.
We use the fφ notation for the scoring function of each triple 2.3 Information Prediction
hh, r, ti. The scoring function measures the plausibility of a Consider an incomplete triple from MalKG, h Adobe Flash
fact in T, based on translational distance or semantic similar- Player, hasVulnerability, ? i. Knowledge graph completion
ity [19]. A summary of the notation appears in Table 1. would predict its missing tail t, i.e., a vulnerability of the
software titled “Adobe Flash Player.” MalKG can predict
2.2 Malware Knowledge Graph (MalKG) missing entities from an incomplete triple, which forms the
smallest malware threat intelligence unit. During knowledge
Knowledge graphs store large amount of domain specific
graphs construction, triples can have a missing head or tail.
information in the form of triples using entities, and rela-
tionships between them [21]. General purpose knowledge 3 https://developers.google.com/knowledge-graph
3Knowledge graph completion, sometimes also known as entity (a) Malware threat reports cover technical and social aspects
prediction, is the task of predicting the best candidate for a of a malware attack in the form of unstructured text.
missing entity. It also predicts an entity by inferring new facts There is no standardized format for these reports used
based on existing information represented by the knowledge to describe the malware threat intelligence. Therefore,
graph. Formally, the task of entity-prediction is to predict extracted information from raw text contains noise and
the value for h given h?, r, ti or t given hh, r, ?i, where “?" other complex information such as code snippets, images,
indicates a missing entity. and tables.
(b) Threat reports contain both generic and domain-specific
2.4 MalKG Vector Embedding information. Using named entity extraction (NER) mod-
els trained on generic datasets or specific domains such
Triples of MalKG are represented by a relatively low (e.g., as health cannot be used for cybersecurity threat reports.
50) dimensional vector space embeddings [2, 36, 39, 42, 43], Besides, domain-specific concepts sometimes have titles
without losing information about the structure and preserving that can mislead NER models into categorizing them as
key features. We construct embeddings for all the triples in generic concepts. For example, when a CVE description
MalKG where each triple has three vectors, e1 , r, e2 ∈ Rd and mentions “Yosemite backup 8.7,” it refers to Yosemite
the entities are hierarchical. Therefore, to narrow down the server backup software, not the national park in Califor-
choice of embedding models, we ensured that the embedding nia.
model meets the following requirements:
(c) Entity extraction can sometimes lead to multiple classifi-
1. An embedding model has to be expressive enough cation of the same concept. For example, SetExpan [29]
to handle different kinds of relations (as opposed to may classify annotated entities similar to an input seed
general graphs where all edges are equivalent). It semantic class. For instance, the entity “Linux” was clas-
should create separate embeddings for triples shar- sified as both as a software and as a vulnerability.
ing the same relation. To elaborate, the embed-
ding of a triple he1 , hasVulnerability, e3 i where e1 ∈ (d) The relation extraction method like DocRED [44] are
class:ExploitTarget should be different from the em- trained on medical dataset and are sparsely documented.
bedding of a triple he2 , hasVulnerability, e3 i where e2 ∈ Hard coded variables in the source code that specifically
class:Software. works for the sample data make it challenging for re-
use. However, we generalized it to target malware threat
2. An embedding model should also be able to create dif- intelligence entities. Another crucially important aspect
ferent embeddings for an entity when it is involved in in [44] is the exponential growth in memory requirement
different kinds of relations [40]. This requirement en- with the number of entities in a given document.
sures creating embedding of triples with 1-to-n, n-to-1,
and n-to-n relations. For example, a straightforward and (e) The semantic classifiers defined by entity extraction mod-
expressive model TransE [6] has flaws in dealing with 1- els [1, 5, 29] are distinct from the ones required by the
to-n, n-to-1, and n-to-n relations [20, 40]. It would create malware threat intelligence domain, and therefore, can-
very similar embeddings of DUSTMAN and ZeroCleare not be applied directly.
malswares because they both involve TDL file, although
these are two separate entities and should have separate 3 MalKG: System Architecture
embeddings.
The input to our proposed framework for malware KG con-
3. Entities that belong to the same class should be projected struction, as shown in Figure 1, consists of a training corpus
in the same neighborhood in the embedding space [11]. and an existing ontology (e.g., [28]) that has classes and re-
This requirement allows using an embedding’s neighbor- lations to provide structure to MalKG. The training corpus
hood information when predicting the class label of an contains malware threat intelligence reports gathered from
unlabeled entity (this task is called entity classification). the Internet, manual annotations of the entities and relations
in those reports using the ontology, and the CVE vulnerability
2.5 Challenges in MalKG Construction database. The training corpus and the ontology classes are fed
into entity extractors such as SetExpan [29] to provide entity
Generating triples from the vast number of threat reports is instances from the unstructured malware reports. A relation
not a trivial task, and unlike for a small cureated benchmark extraction model [44] uses these entity instances and ontology
dataset, the manual annotation process is not replicable and relations as input and predicts relations among the entity pairs.
scalable for a large amount of data. Some of the challenges Entity pairs and the corresponding relations are called triples
that need to be addressed are: and they form an initial knowledge graph. We use a tensor
4factorization-based approach, TuckER [2], to create vector
Table 2: Triples corresponding to the threat report.
embeddings to predict the missing entities and obtaining the
Head Relation Tail
final version of MalKG with the completed RDF triples.
hDUSTMAN, similarTo, ZeroClearei
hDUSTMAN, involves, Turla Driver Loader(TDL)i
3.1 Generating Contextual and Structured In- hZeroCleare, involves, Turla Driver Loader(TDL)i
formation hDUSTMAN, involves, dustman.exei
hdustman.exe, drops, assistant.sysi
This section describes the process of generating contextual
hdustman.exe, drops, elrawdisk.sysi
and structured malware threat information from unstructured
hdustman.exe, drops, agent.exei
data.
Corpus - Threat reports, blogs, threat advisories, tweets,
and reverse engineered code can be investigated to gather de-
MalKG, this provenance information contains a unique iden-
tails about malware characteristics. Our work relies on threat
tifier of the threat reports from which it was extracted or the
reports to capture information on the detailed account of mal-
unique CVE IDs.
ware attacks and CVE vulnerability descriptions. Security
Information Extraction - Following the ontology for mal-
organizations publish in-depth information on how cyber-
ware threat intelligence, we created ground truth triples by
criminals abuse various software and hardware platforms and
manually annotating threat reports. We generated MT3K, a
security tools. See Figure 2 for an excerpt of a threat report on
knowledge graph for malware threat intelligence using hand
the Backdoor.Winnti malware family. Information collected
annotated triples. While this was an essential step for creat-
from a corpus of threat reports includes vulnerabilities, plat-
ing ground truth, the hand-annotated approach had several
forms impacted, modus operandi, attackers, the first sighting
limitations, but is invaluable for testing large-scale models.
of the attack, and facts such as indicators of compromise.
Inference Engine - We used the classes and relations de-
These reports serve as research material for other security
fined in MALOnt [28] and Malware ontology [34] to extract
analysts who acquire essential information to study and an-
triples from unstructured text. While using an ontology is not
alyze malware samples, adversary techniques, learn about
the only approach to instantiate MalKG, it can map disparate
zero-day vulnerabilities exploited, and much more. However,
data from multiple sources into a shared structure and main-
not all reports are consistent, accurate, or comprehensive. Ag-
tains a logic in that structure using rules. An ontology uses a
gregating valuable data from these threat reports to incor-
common vocabulary that can facilitate the collection, aggre-
porate all knowledge about a given malware and obtain this
gation, and analysis of that data [24]. For example, there are
information during threat incident research (e.g., investigating
classes named Malware and Location in MALOnt. According
false-positive events) is an important research goal.
to the relations specified in MALOnt, an entity of Malware
Contextualization - MalKG captures threat information
class can have a relation “similarTo” with another Malware
in a triple, which is the smallest unit of information in the
class entity. But due to the rule engine, Malware class can
knowledge graph [21]. For instance, consider the following
never be related to an entity of Location class.
snippet from a threat report:4
A knowledge graph contains 1-to-1, 1-to-n, n-to-1, and n-
“... DUSTMAN can be considered as a new variant of to-n relations among entities. An entity-level 1-to-n relation
ZeroCleare malware ... both DUSTMAN and ZeroCleare means there are multiple correct tails in a knowledge graph
utilized a skeleton of the modified “Turla Driver Loader for a particular pair of head and relation. In Figure 3, the
(TDL)” ... The malware executable file “dustman.exe” is not entity “dustman.exe” is an instance of a Malware File. It drops
the actual wiper, however, it contains all the needed three different files. Entities DUSTMAN and ZeroCleare both
resources and drops three other files [assistant.sys, *involve* the Turla Driver Loader (TDL) file, and elaborate
elrawdisk.sys, agent.exe] upon execution...” how n-to-1 relations exist in a knowledge graph; n-to-n works
similarly.
Table 2 shows a set of triples generated from this text. To-
gether, many such triples form the malware knowledge graph
where the entities and relations model nodes and directed 3.2 Predicting Missing Information
edges, respectively. Figure 3 shows the sample knowledge
Knowledge graph completion enables inferring missing facts
graph from the text.
based on existing triples in MalKG when information (entities
Instantiating Ontology - Each entity in MalKG has a
and relations) about a malware threat is sparse. For MalKG,
unique identifier, which captures the provenance informa-
we demonstrate entity prediction through TuckER [2] and
tion comprising references to the triples’ threat sources. For
TransH [40]. Standard datasets such as FB15K [6], FB15k-
4 https://www.lastwatchdog.com/wp/wp-content/uploads/ 237 [35], WN18 [6] , and WN18RR [9] were used to com-
Saudi-Arabia-Dustman-report.pdf pare with other models and create baselines for other more
5Figure 1: System Architecture for MalKG construction and showing entity prediction.
2. Dissimilarity scores fφ (h, r,t) are calculated for each true
test triple and its corresponding corrupted triples. The
scores are sorted in ascending order to identify the rank
of the true test triple in the ordered set. This rank as-
sesses the model’s performance in predicting head given
h ?, relation, tail i. A higher rank indicates the model’s
efficiency in learning embeddings for the entities and
relations.
Figure 2: An excerpt of a threat report on Backdoor.Winnti 3. The previous two steps are repeated for the tail entity t,
malware family. and true test triples ranks are stored. This rank assesses
the model’s performance in predicting the missing t
given hh, r, ti.
4. Mean Rank, Mean Reciprocal Rank (MRR), and Hits@n
are conventional metrics used in literature, calculated
from the ranks of all true test triples. Mean rank signifies
the average rank of all true test triples. Mean rank is
significantly affected when a single test triple has a bad
rank. Recent works [2, 17] report mean reciprocal rank
(MRR) for more robust estimation. It is the average of
the inverse of the ranks of all the true test triples. Hits@n
denotes the ratio of true test triples in the top n positions
Figure 3: Sample MalKG. Nodes and edges represent entities of the ranking. When comparing embedding models,
and relations, respectively. The edge labels denote relation smaller values of Mean Rank and larger values of MRR
type. and Hits@n indicate a better model. We report the results
of MRR and Hits@n for various tensor-factorization and
translation-based models.
elaborate models. However, the datasets that were used for
comparison differed starkly form our MT3KG and MT40K
triple dataset. The following protocol describes the prediction 4 Experimental Evaluation
for missing entities in the malware knowledge graph:
This section describes our experimental setup, results, and
1. The head entity h is replaced with all other entities in implementation details for knowledge graph completion.
the knowledge graph for each triple in the test set. This
generates a set of candidate triples to compare with each 4.1 Datasets
true test triple. This step is known as corrupting the
head of a test triple, and the resultant triple is called a The malware threat intelligence corpus comprises of threat
corrupted triple. reports and CVE vulnerability descriptions. The threat reports
6have been used to evaluate the performance of generic knowl-
Table 3: Description of Datasets
edge graphs and their applications, such as link-prediction,
Dataset ne nr nt docs avgDeg density and knowledge graph completion. However, there is no open-
MT3K 5,741 22 3,027 81 0.5273 0.00009 source knowledge graph for malware threat intelligence, and
MT40K 27,354 34 40,000 1,100 1.46 5.34 × therefore there do no exist triples for malware KG evaluation.
10−5 We hope that MT3K and MT40K will serve as benchmark
FB15K 14,951 1345 592213 - 39.61 0.00265 datasets for future security research.
WN18 40943 18 151,442 - 3.70 0.00009
FB15K- 14,541 237 310,116 - 21.32 0.00147
237
4.3 Automated Dataset: MT40K
WN18RR 40,943 11 93,003 - 2.27 0.00005 The MT40K dataset is a collection of 40,000 triples generated
from 27,354 unique entities and 34 relations. The corpus
consists of approximately 1,100 de-identified plain text threat
were written between 2006-2021 and all CVE vulnerability reports written between 2006-2021 and all CVE vulnerability
descriptions created between 1990 to 2021. We perform sev- descriptions created between 1990 to 2021. The annotated
eral pre-processing steps on the raw corpus data. We provide keyphrases were classified into entities derived from semantic
a unique identifier to every individual document and the CVE categories defined in malware threat ontologies [28, 34]. The
description. Individual sentences were extracted from each inference rule engine was applied when forming relations
document and assigned a sentence ID. Identification of doc- between entities to produce triples used to build the MalKG.
uments and sentences also provides provenance for future Our information extraction framework comprises entity
work in trustworthiness, contextual entity classification, and and relation extraction and is grounded in the cybersecurity
relation extraction. We tokenize and parse the plain text sen- domain requirements. The framework takes as input the plain
tences into words with start and end positions using the spaCy text of threat reports and raw CVE vulnerability descriptions.
default tokenizer5 library and saves them in sequential order It locates and classifies atomic elements (mentions) in the
for each document. text belonging to pre-defined categories such as Attacker, Vul-
nerability, and so on. We split the tasks of entity extraction
and recognition. The entity extraction (EE) step combines an
4.2 Manually Curated Triples: MT3K ensemble of state-of-the-art entity extraction techniques. The
The MT3K dataset is a collection of 5741 triples manually entity classification (EC) step addresses the disambiguation
annotated by our research team and validated by security ex- of an entity classified into more than one semantic category,
perts. 81 threat reports were annotated (see Figure 4) using and assigns only one category based on an empirically learned
the Brat annotation tool [32]. In Figure 4, “PowerPoint file” algorithm. Results obtained from both EE and EC are com-
and “installs malicious code” are labeled as classes Software bined to give the final extraction results. Details are provided
and Vulnerability respectively. The arrow from Software to in the next section.
Vulnerability denotes the semantic relationship hasVulnerabil-
ity between them. The annotation followed rules defined in 4.3.1 Entity Extraction (EE)
malware threat ontologies [28, 34]. 22 other relation types
(nr ) are defined in malware threat intelligence ontology [28]. We segregate the extraction of tokenized words into two cate-
gories: domain-specific key-phrase extraction and generic
key-phrase extraction (class:Location). The cybersecurity
domain-specific EE task was further subdivided into factual
key-phrase extraction (class:Malware) and contextual key-
phrase extraction (class:Vulnerability). We use precision and
recall measures as evaluation criteria to narrow down the
EE models for different classes. Specifically, the Flair frame-
work [1] gave high precision scores (0.88-0.98) for classi-
Figure 4: Annotation using Brat annotation tool. fication of generic and factual domain-specific key-phrases
such as - Person, Date, Geo-Political Entity, Product (Software,
The MT3K dataset serves as the benchmark dataset for Hardware). The diversity in writing style for the threat reports
evaluating malware threat intelligence using our automated and the noise introduced during reports conversion to text led
approach for triples generation. Other triple datasets such as to different precision scores for classes but within the range
the FB15K [6], FB15k-237 [35], WN18 [6] , and WN18RR [9] of 0.9-0.99. For contextual entity extraction, we expanded the
SetExpan [29] model to generate all entities in the text corpus.
5 https://spacy.io/api/tokenizer The feedback loop that input seed values of entities based on
7confidence score allowed for better training dataset. Some 4.4 Predicting Missing Information
of the semantic classes used in this approach are Malware,
Knowledge graph completion (or entity prediction) predicts
Malware Campaign, Attacker Organization, Vulnerability.
missing information in MalKG. It also evaluates the entity pre-
diction accuracy of a given triple and recommends a ranking
4.3.2 Entity Classification (EC) of predicted entities. For the missing entities in the MalKG
triples, a tensor factorization-based approach TuckER [2]
A shortcoming of using multiple EE models is that some en- meets the requirements (see Section 2.4) of MalKG struc-
tities can get classified multiple times, which might even be ture and can predict the missing entities. However, before
inaccurate in some cases. We observed empirically that this narrowing down on the entity prediction model, we evaluated
phenomenon was not limited to any specific class. An expla- its performance against other state-of-the-art models.
nation for this phenomenon is the variation and grammatical
inconsistency in different threat reports and their writing style.
4.4.1 Benchmark Dataset
For example, the entity “linux” was classified as Software
and Organization for the same position in a document. Since Due to the lack of a benchmark dataset in the cybersecurity
the entity extraction models are running independently of domain, we rely on other datasets to observe and compare
each other, it was likely for close class types to have over- existing embedding models’ performances. The most com-
laps. We followed a three step approach for resolving the monly used benchmark datasets are FB15K, WN18, FB15K-
disambiguation in entity classification: 237, WN18RR. Collected from the freebase knowledge graph,
FB15K and FB15K-237 are collaborative knowledge bases
1. We compared the confidence score of entities occurring containing general facts such as famous people, locations,
at the same position in the same document and between events. WN18 and WN18RR are datasets from Wordnet, a
classes. lexical database of the English language. Simpler models per-
form better on these datasets where a test triple’s correspond-
2. For the same confidence scores, we marked those classes ing inverse relation exists in the training set. Such instances
as ambiguous. We retained these instances until the rela- are eliminated from FB15K and WN18 to generate FB15K-
tion extraction phase. At that time, we relied on the rule 237 and WNRR. Experimental results by OpenKE6 for entity
engine from the ontology to determine the correct class prediction (or knowledge graph completion) are summarized
of the head and tail entity for a given relation (described in Table 4.
in the next section). The comparison between the structure of the graphs we
generated - MalKG and hand-annotated, their properties, and
3. For entities that passed the first two steps, we classified corpus details are described in Table 3. For example, it com-
them using the broader semantic class. pares the number of entities, relations, and triples (facts), the
average degree of entities, and graph density of our datasets
4.3.3 Relation Extraction (MT3K, MT40K) and benchmark datasets. Note, the average
degree across all relations and graph density are defined as
We base relation extraction for MalKG on the DocRED; a nt /ne and nt /n2e , respectively [25]. A lower score of these two
distantly supervised artificial neural network model [44] pre- metrics indicates a sparser graph.
trained on the Wiki data and Wikipedia with three features.
DocRED [44] requires analyzing multiple sentences in a docu- 4.4.2 Implementation
ment to extract entities and infer their relations by amalgamat-
ing all knowledge of the document, a shift from sentence-level MT3K validation set is used for tuning the hyper-parameters
relation extraction. The MT3K triples and text corpus form for MT40K. For the TuckER experiment on MT3K, we
the training dataset and the entities generated in the previous achieved the best performance with de = 200 and dr = 30,
steps, and the processed text corpus the testing dataset. As learning rate = 0.0005, batch size of 128 and 500 iterations.
described in section 2.5, while training and testing was not a For the TransH experiment, de = dr = 200, learning rate =
straightforward implementation, we generated 40,000 triples 0.001 gave us the best results. For MT3K and MT40K, we
using 34 relations between 27,354 entities. The instantiated split each dataset into 70% train, 15% validation, and 15%
entities, their classification, and position in the threat report test data. However, for the larger MT40K dataset, we relied on
or CVE description formed the RE model’s input. The testing the MT3K dataset for testing. Knowledge graph completion
batch size was 16 documents. Due to scalability issues in for MalKG can be described under two scenarios:
DocRED, the number of entities per document was limited to 1. predict head given h?, relation,taili
less than 80. Text documents with a higher number of entities
were further split into smaller sizes. The training ran for 4-6 2. predict tail given hhead, relation, ?i
hours, for an epoch size of 984, and the threshold set to 0.5. 6 https://github.com/thunlp/OpenKE
85 Results and Discussion 2. We show that TuckER does not store all the latent knowl-
edge into separate entity and relation embeddings. In-
Table 4 displays the results of entity prediction existing em- stead, it enforces parameter sharing using its core tensor
bedding models on the benchmark datasets. An upward ar- so that all entities and relations learn the common knowl-
row (↑) next to an evaluation metric indicates that a larger edge stored in the core tensor. This is called multi-task
value is preferred for that metric and vice versa. For ease learning, which no other model except Complex [37]
of interpretation, we present Hits@n measures as a percent- employs. Therefore, TuckER creates embeddings that
age value instead of a ratio between 0 and 1. TransE has reflect the complex relations (1-n, n-1, n-n) between en-
the largest Hits@10 and MRR scores on the FB15K-237 tities in the MalKG.
dataset, whereas TransR performs better on the rest of the
three datasets. However, TransH is more expressive (capa- 3. Moreover, we almost certainly ensure there are no in-
ble of modeling more relations) than TransE despite hav- verse relations and redundant information in the valida-
ing the simplicity of TransE (time complexity O(de )). The tion and test data sets. It is hard for simple yet expressive
space complexity of TransR (O(ne de + nr de dr )) is more ex- models like TransH to perform well in such datasets
pensive than TransH (O(ne de + nr de )) [39]. Additionally, on compared to bi-linear models like TuckER.
average, it takes six times more time to train TransR7 com-
4. The number of parameters of TransH grows linearly
pared to TransH [20]. Considering these model capabilities
with the number of unique entities (ne ), whereas for
and complexity trade-offs, we choose TransH as a represen-
TuckER, it grows linearly for the embedding dimensions
tational translation-based model. DistMult performs better
(de and dr ). A TuckER low-dimensional embedding can
than TuckER by a small margin of 0.37% in only one case
be learned and reused across various machine learning
(Hits@10 on WN18). TuckER and ComplEx both achieve
models and performs tasks such as classification and
very close results on multiple cases.
anomaly detection. We explore anomaly detection as
Therefore, we look closely at the results of the recently future work in the MalKG to identify trustworthy triples.
refined datasets (FB15K-237 and WN18RR) as our MT3K
dataset shares similar properties with these two datasets Since TuckER performed significantly better than TransH
(MT3K has hierarchical relations as in WN18RR and no on the ground truth dataset, we employ only TuckER on the
redundant triples as in FB15K-237). Since the space com- MT40K dataset. It is noteworthy that all the measures except
plexity is very close (ComplEx: O(ne de + nr de ) and TuckER: mean rank (MR) improved on MT40K compared to MT3K.
O(ne de + nr dr )) we choose TuckER for evaluation on MT3K, It confirms the general intuition that as we provide more data,
as it subsumes ComplEx [2]. the model learns the embeddings more effectively. MR is not
We evaluate the performance of TransH [40] and TuckER a stable measure and fluctuates even when a single entity is
[2] on our datasets. Tables 5 and 6 display the performance ranked poorly. We see that the MRR score improved even
of TransH and TuckER on MT3K and MT40K. TransH’s though MR worsened, which confirms the assumption that
MRR score on MT3K improved when compared to the bench- only a few poor predictions drastically affected the MR on
marks. Tucker’s performance improved in all measures when MT40K. Hits@10 being 80.4 indicates that when the entity
compared to the other benchmark results. Evidently, TuckER prediction model predicted an ordered set of entities, the true
outperforms TransH by a large margin on the MT3K dataset. entity appeared in its top 10 for 80.4% times. Hits@1 measure
Four reasons underlie this result: denotes that 73.9% times, the model ranked the true entity at
position 1, i.e., for 80.4% cases, the model’s best prediction
1. MT3K has only 22 relations in comparison to 5,741 was the corresponding incomplete triple’s missing entity. We
unique entities. This makes the knowledge graph dense can interpret Hits@3 similarly. We translate the overall entity
with a higher entities-to-relation ratio, which implies a prediction result on MT40K to be sufficient such that the
strong correlation among entities. Tensor-factorization trained model can be improved and further used to predict
based approaches use tensors and non-linear transfor- unseen entities.
mations that capture such correlations into embeddings
more accurately than linear models do [40]. For larger
6 Related Work
knowledge graphs, such as MalKG, this property is espe-
cially pertinent because it may be missing entities from Several generic and specific knowledge graphs such as Free-
the KG due to shortcomings of entity extraction models base [5], Google’s Knowledge Graph8 , and WordNet [10] are
or for predicting information for a sparsely populated available as open source. Linked Open data [4] refers to all the
graph. Accurate predictions help in both scenarios, espe- data available on the Web, accessible using standards such as
cially in the field of cybersecurity. Uniform Resource Identifiers (URIs) to identify entities, and
7 On benchmark datasets 8 https://developers.google.com/knowledge-graph
9Table 4: Entity Prediction for different Data sets
FB15K WN18 FB15K-237 WN18-RR
Model Hits@10↑ MRR↑ Hits@10↑ MRR↑ Hits@10↑ MRR↑ Hits@10↑ MRR↑
TransE 44.3 0.227 75.4 0.395 32.2 0.169 47.2 0.176
TransH 45.5 0.177 76.2 0.434 30.9 0.157 46.9 0.178
TransR 48.8 0.236 77.8 0.441 31.4 0.164 48.1 0.184
DistMult 45.1 0.206 80.9 0.531 30.3 0.151 46.2 0.264
ComplEx 43.8 0.205 81.5 0.597 29.9 0.158 46.7 0.276
TuckER 51.3 0.260 80.6 0.576 35.4 0.197 46.8 0.272
The top three rows are models from the translation-based approach, rest are from tensor factorization-based approach
Bold numbers denote the best scores in each category
to learn word-level and character-level features. Lample et
Table 5: Experimental evaluation of MT3K for entity predic-
al. [18] use a layer of conditional random field over LSTM
tion.
to recognize entities with multiple words. MGNER [41] uses
Model Hits@1↑ Hits@3↑ Hits@10↑ MR↓ MRR↑
a self-attention mechanism to determine how much context
TransH 26.8 50.5 65.2 32.34 0.414 information of a component should be used, and is capable of
TuckER 64.3 70.5 81.21 7.6 0.697 capturing nested entities within a text.
In addition, pre-trained off-the-shelf NER tools such as
StanfordCoreNLP9 , Polyglot10 , NLTK11 , and spaCy12 are
Table 6: Experimental evaluation of MT40K for entity predic- available. These tools can recognize entities representing uni-
tion. versal concepts such as person, organization, and time. These
Model Hits@1↑ Hits@3↑ Hits@10↑ MR↓ MRR↑ tools categorize domain-specific concepts (e.g., malware cam-
TuckER 73.9 75.9 80.4 202 0.75 paign, software vulnerability in threat intelligence domain)
as other or miscellaneous because the models are pre-trained
on corpora created from news articles, Wikipedia articles,
and tweets. While it is possible to train these models on a
Resource Description Framework (RDF) to unify entities into
domain-specific corpus, a large amount of labeled training
a data model. However, it does not contain domain-specific
data is required.
entities that deal with cyber threats and intelligence. Other
existing knowledge graphs are either not open source, too spe- The absence of sufficient training data in a specific domain
cific, or do not cater to the breadth of information our research such as malware threat intelligence poses a challenge to use
intends to gather from intelligence reports. the algorithms mentioned above and tools to extract technical
terms of that domain. Corpus-based semantic class mining
Creating and completing a knowledge graph from raw text
is ideal for identifying domain-specific named entities when
comprises multiple tasks, e.g., entity discovery, relation ex-
there are very few labeled data instances. This approach re-
traction, and designing embedding models. In this section, we
quires two inputs: an unlabeled corpus and a small set of seed
review notable research works to accomplish these tasks. En-
entities appearing in the corpus and belonging to the same
tity discovery refers to categorizing entities in a text according
class. The system then learns patterns from the seed enti-
to a predefined set of semantic categories.
ties and extracts more entities from the corpus with similar
Named Entity Recognition (NER) is a machine learning
patterns. Shi et al. [31], and Pantel et al. [26] prepare a candi-
task for entity discovery. The machine learning model learns
date entity set by calculating the distributional similarity with
features of entities from an annotated training corpus and
seed entities, which often introduces entity intrusion error
aims to identify and classify all named entities in a given text.
(includes entities from a different, often more general, seman-
Deep neural network-based approaches have become a popu-
tic class). Alternatively, Gupta et al. [12], and Shi et al. [30]
lar choice in NER for their ability to identify complex latent
use an iterative approach, which sometimes leads to semantic
features of text corpora without any human intervention for
drift (shifting away from the seed semantic class as undesired
feature design [19]. Long Short Term Memory (LSTM), a re-
entities get included during iterations). SetExpan [29] over-
current neural network architecture, in NER can learn beyond
comes both of these shortcomings by using selective context
the limited context window of a component and can learn long
dependencies among words. Convolutional Neural Network 9 https://stanfordnlp.github.io/CoreNLP/
(CNN) is a class of neural networks that learns character-level 10 https://polyglot.readthedocs.io/en/latest/
features like prefixes, and suffixes when applied to the task 11 https://www.nltk.org/
of NER. Chiu et al. [8] combine LSTM and CNN’s strengths 12 https://spacy.io/api/entityrecognizer
10features of the seeds and resetting the feature pool at the start computational complexity. It uses a separate hyperplane
of each iteration. for each kind of relation, allowing an entity to have dif-
Following the entity discovery phase, extracting relations ferent representations in different hyperplanes when in-
between entity pairs takes place. Deep neural network-based volved in different relations. TransR [20] proposes a
approaches eliminate the need for manual feature engineering. separate space to embed each kind of relation, making it
To extract relations for constructing a large scale knowledge a complex and expensive model. TransD [13] simplifies
graph, manual annotations to generate training data is costly TransR by further decomposing the projection matrix
and time-consuming. Subasic et al. [33] use deep learning into a product of two vectors. TranSparse [14] is another
to extract relations from plain text and later align with Wiki- model that simplifies TransR by enforcing sparseness
data13 to select domain-specific relations. Jones et al. [16] on the projection matrix. These models combined are
propose a semi-supervised algorithm that starts with a seed referred to as TransX models. An important assumption
dataset. The algorithm learns patterns from the context of in these models is that an embedding vector is the same
the seeds and extracts similar relations. A confidence scoring when an entity appears as a triple’s head or tail.
method prevents the model from drifting away from perti-
nent relations and patterns. Ji et al. [15] propose APCNN, a 2. Tensor based approaches: Tensor factorization-based
sentence-level attention module, which gains improvement approaches consider a knowledge graph as a tensor of
on prediction accuracy from using entity descriptions as an order three, where the head and tail entities form the first
input. In applications where labeled data is scarce, distant two modes and relations form the third mode. For each
supervision, a learning approach for automatically generating observed triple hei , rk , e j i, the tensor entry Xi jk is set to
training data using heuristic matching from few labeled data 1; and otherwise 0. The tensor is factorized by param-
instances is favored. Yao et al. [44] use distant supervision eterizing the entities and relations as low dimensional
to extract features beyond the sentence level, and address vectors. For each entry Xi jk = 1, the corresponding triple
document level relation extraction. is reconstructed so that the value returned by the scroing
Vector embeddings address the task of knowledge represen- function on the reconstructed triple is very close to Xi jk ,
tation by enabling computing on a knowledge graph. MalKG i.e., Xi jk ≈ fφ (hei , rk , e j i). The model learns the entity
has highly structured and contextual data and can be lever- and relation embeddings with the objective to minimize
aged statistically for classification, clustering, and ranking. the triple reconstruction error:
However, the implementations of embedding vectors for the
various models are very diverse. We can broadly categorize
L = Σi, j,k (Xi jk − fφ (ei , rk , e j ))2
them into three categories: translation-based, neural-network-
based, or trilinear-product-based [36]. For MalKG, we eval-
uate two embedding approaches that directly relate to our where fφ is a scoring function.
work: Another model, RESCAL [23], comprise powerful bi-
linear models, but may suffer from overfitting due to
1. Latent-distance based approach: These models mea-
large number of parameters. DistMult [43] is a spe-
sure the distance between the latent representation of
cial case of RESCAL which fails to create embeddings
entities where relations act as translation vectors. For
for asymmetric relations. ComplEx [37] overcomes the
a triple hh, r, ti, they aim to create embeddings h, r, t
drawback of DistMult by extending the embedding space
such that the distance between h and t is low if hh, r,ti
into complex numbers. HolE [22] combines the expres-
is a correct fact (or triple) and high otherwise. A correct
sive power of RESCAL with the efficiency and sim-
fact is a triple where a relation exists between the head
plicity of DistMult. TuckER [2] is a fully expressive
h and tail t. The simplest application of this idea is:
model based on Tucker decomposition that enables multi-
task learning by storing some learned knowledge in the
fφ (h, t) = −|h + r − t|1/2 core tensor, allowing parameter sharing across relations.
TuckER represents several tensor factorization models
where | · |1/2 means either the l1 or the l2 norm. preceding it as its special case. The model has a linear
TransE [6] creates embeddings such that for a correct growth of parameters as de and dr increases.
triple hh, r,ti, h + r ≈ t. However, it has the limitation of
3. Artificial neural network based models: Neural net-
representing only 1-to-1 relations as it projects all rela-
work based models are expressive and have more com-
tions in the same vector space. Thus, TransE cannot rep-
plexity as they require many parameters. For medium-
resent 1-to-n, n-to-1, and n-to-n relations. TransH [40]
sized datasets, they are not appropriate as they are likely
overcomes the drawback of TransE without increasing
to over fit the data, which leads to below-par perfor-
13 https://www.wikidata.org/wiki/Wikidata:Main_Page mance [39].
117 Conclusion [4] Florian Bauer and Martin Kaltenböck. Linked open data:
The essentials. Edition mono/monochrom, Vienna, 710,
In this research, we propose a framework to generate the first 2011.
malware threat intelligence knowledge graph, MalKG, that
can produce structured and contextual threat intelligence from [5] Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim
unstructured threat reports. We propose an architecture that Sturge, and Jamie Taylor. Freebase: a collaboratively
takes as input an unstructured text corpus, malware threat created graph database for structuring human knowl-
ontology, entity extraction models, and relation extraction edge. In Proceedings of the 2008 ACM SIGMOD in-
models. It creates vector embeddings of the triples that can ternational conference on Management of data, pages
extract latent information from graphs and find hidden infor- 1247–1250, 2008.
mation. The framework outputs a MalKG, which comprises
[6] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran,
27,354 unique entities, 34 relations and approximately 40,000
Jason Weston, and Oksana Yakhnenko. Translating em-
triples in the form of entityhead -relation-entitytail . Since this
beddings for modeling multi-relational data. In Ad-
is a relatively new line of research, we demonstrate how a
vances in neural information processing systems, pages
knowledge graph can accurately predict missing information
2787–2795, 2013.
from the text corpus through the entity prediction application.
We motivate and empirically explore different models for [7] Antoine Bordes, Jason Weston, Ronan Collobert, and
encoding triples and concluded that the tensor factorization Yoshua Bengio. Learning structured embeddings of
based approach resulted in the highest overall performance knowledge bases. In Proceedings of the AAAI Confer-
among our dataset. ence on Artificial Intelligence, volume 25, 2011.
Using MT40K as the baseline dataset, we will explore ro-
bust models for entity and relation extraction for future work [8] Jason PC Chiu and Eric Nichols. Named entity recog-
that can generalize to the cybersecurity domain for disparate nition with bidirectional lstm-cnns. Transactions of the
datasets, including blogs, tweets, and multimedia. Another Association for Computational Linguistics, 4:357–370,
application is to use vector embeddings to identify possi- 2016.
ble cybersecurity attacks from the background knowledge
encoded in MalKG. The current prediction model can gen- [9] Tim Dettmers, Pasquale Minervini, Pontus Stenetorp,
erate a list of top options for missing information. It will be and Sebastian Riedel. Convolutional 2d knowledge
interesting to extend this capability to predicting threat intelli- graph embeddings. In Proceedings of the AAAI Confer-
gence about nascent attack vectors and use that information to ence on Artificial Intelligence, volume 32, 2018.
defend against attacks that are yet to propagate widely. A fun-
damental issue that we want to address through this research [10] Christiane Fellbaum. Wordnet. In Theory and appli-
is inaccurate triples in the knowledge graph. This draws from cations of ontology: computer applications, pages 231–
the limitations of entity and relation extraction models and 243. Springer, 2010.
inaccurate descriptions in the threat reports.
[11] Shu Guo, Quan Wang, Bin Wang, Lihong Wang, and
Li Guo. Semantically smooth knowledge graph em-
bedding. In Proceedings of the 53rd Annual Meeting
References of the Association for Computational Linguistics and
the 7th International Joint Conference on Natural Lan-
[1] Alan Akbik, Tanja Bergmann, Duncan Blythe, Kashif guage Processing (Volume 1: Long Papers), pages 84–
Rasul, Stefan Schweter, and Roland Vollgraf. Flair: An 94, 2015.
easy-to-use framework for state-of-the-art nlp. In Pro-
ceedings of the 2019 Conference of the North American [12] Sonal Gupta and Christopher D Manning. Improved
Chapter of the Association for Computational Linguis- pattern learning for bootstrapped entity extraction. In
tics (Demonstrations), pages 54–59, 2019. Proceedings of the Eighteenth Conference on Computa-
tional Natural Language Learning, pages 98–108, 2014.
[2] Ivana Balažević, Carl Allen, and Timothy M Hospedales. [13] Guoliang Ji, Shizhu He, Liheng Xu, Kang Liu, and Jun
Tucker: Tensor factorization for knowledge graph com- Zhao. Knowledge graph embedding via dynamic map-
pletion. arXiv preprint arXiv:1901.09590, 2019. ping matrix. In Proceedings of the 53rd annual meeting
of the association for computational linguistics and the
[3] Sean Barnum. Standardizing cyber threat intelligence 7th international joint conference on natural language
information with the structured threat information ex- processing (volume 1: Long papers), pages 687–696,
pression (stix). MITRE Corporation, 11:1–22, 2012. 2015.
12You can also read

















































