INSIDE THE NVIDIA AMPERE A100 GPU IN THETAGPU AND PERLMUTTER JULY 28, 2021
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
INSIDE THE NVIDIA AMPERE A100 GPU IN THETAGPU AND PERLMUTTER JULY 28, 2021

EXPLODING DATA AND MODEL SIZE
175
Zettabytes GPT-3
175 Bn
# Parameters (Log scale)
Turing-NLG
393 TB 287 TB/day 17 Bn
COVID-19 Graph Analytics ECMWF
GPT-2 8B
58 8.3 Bn
Zettabytes
BERT
340 M
Transformer
65 M
16 TB/sec 550 TB
2010 2015 2020 2025 2017
2017 2018
2018 2019
2019 2020
2020 2021
SKA NASA Mars Landing Sim.
Big Data Growth Growth In Scientific Data Exploding Model Size
90% of the World’s Data in last 2 Years Fueled by Accurate Sensors & Simulations Driving Accuracy
Source for Big Data Growth chart: IDC – The Digitization of the World (May, 2020) 2
NVIDIA A100 40GB
The World’s Highest Performing AI
Supercomputing GPU
40GB HBM2e 1.5 TB/s +
For large datasets World’s highest memory bandwidth
and models to feed the world’s fastest GPU
3rd Gen Tensor Core Multi-Instance GPU
3rd Gen NVLink
3
UNIFIED AI ACCELERATION
BERT-LARGE TRAINING BERT-LARGE INFERENCE
(FP32) (FP16)
2,400 7,000
2,100 3X 6,000
7X
1,800
5,000
Sequences/s
Sequences/s
1,500
4,000
6X
1,200
3,000
900
600
1X 2,000
300 1,000
1X 0.6X
1X 1X
0 0
V100 A100 V100 A100 T4 V100 1/7th A100 A100
All results are measured (7 MIG)
BERT Large Training (FP32 & FP16) measures Pre-Training phase, uses PyTorch including (2/3) Phase1 with Seq Len 128 and (1/3) Phase 2 with Seq Len 512,
V100 is DGX1 Server with 8xV100, A100 is DGX A100 Server with 8xA100, A100 uses TF32 Tensor Core for FP32 training 4
BERT Large Inference uses TRT 7.1 for T4/V100, with INT8/FP16 at batch size 256. Pre-production TRT for A100, uses batch size 94 and INT8 with sparsity
ACCELERATING HPC WITH UP TO 2X PERF OVER V100
Molecular Dynamics Physics Engineering Geoscience
2.0x 2.1X
A100 2.0X
1.9X 1.9X
1.8X
1.7X
1.5x 1.6X 1.5X 1.5X
Speedup
1.0x V100
0.5x
0.0x
AMBER GROMACS LAMMPS NAMD Chroma BerkeleyGW FUN3D RTM SPECFEM3D
All results are measured
Except BerkeleyGW, V100 used is single V100 SXM2. A100 used is single A100 SXM4
More apps detail: AMBER based on PME-Cellulose, GROMACS with STMV (h-bond),
LAMMPS with Atomic Fluid LJ-2.5, NAMD with v3.0a1 STMV_NVE
Chroma with szscl21_24_128, FUN3D with dpw, RTM with Isotropic Radius 4 1024^3,
SPECFEM3D with Cartesian four material model 5
BerkeleyGW based on Chi Sum and uses 8xV100 in DGX-1, vs 8xA100 in DGX A100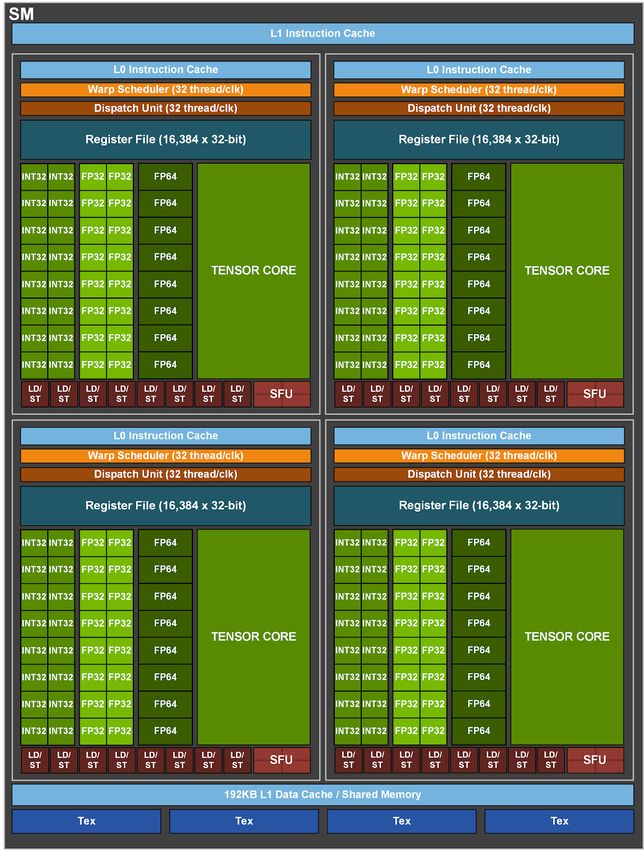
NVIDIA A100: SPECS
V100 A100
SMs 80 108
Tensor Core Precision FP16 FP64, TF32, BF16, FP16, I8, I4, B1
Maximum Shared Memory
96 kB 160 kB
per Block
Unified L1/SMEM per SM 128 kB 192 kB
L2 Cache Size 6144 kB 40960 kB
Memory Bandwidth 900 GB/sec 1555 GB/sec
NVLink Interconnect 300 GB/sec 600 GB/sec
FP64 Throughput 7.8 TFLOPS 9.7 (FMA) | 19.5 TFLOPS (MMA)
FP32 Throughput 15.7 TFLOPS 19.5 TFLOPS
TF32 Tensor Core Throughput N/A 156 (Dense) | 312 TFLOPS (Sparse)
6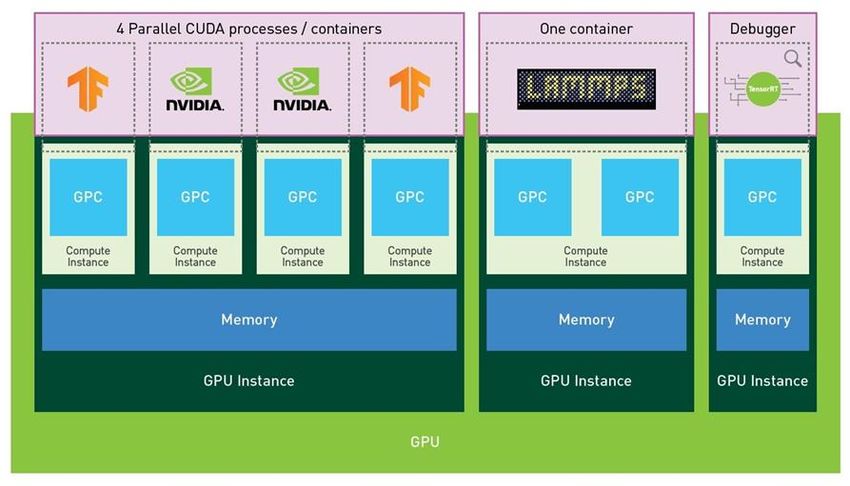
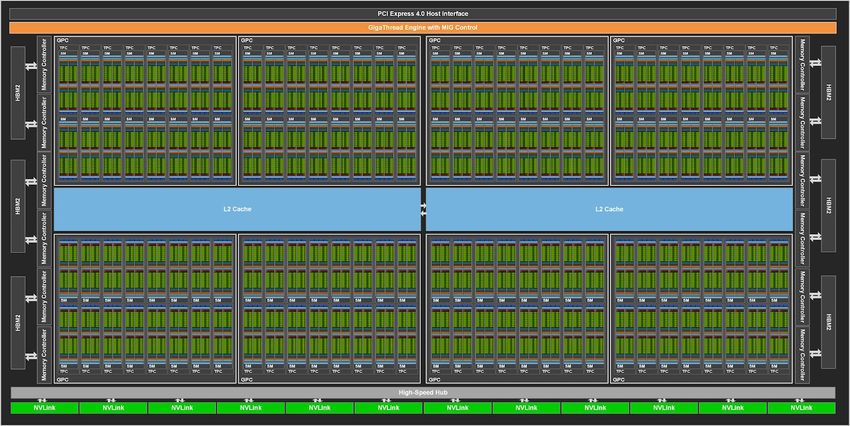
A100 BLOCK DIAGRAM 7x
54 billion transistors in 7nm
GigaThread Engine with MIG Control
HBM2
HBM2
Multi-Instance GPU
HBM2
HBM2
L2 Cache L2 Cache
HBM2
HBM2
2x BW
NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink
108 SMs 40MB L2 1.56 TB/s HBM2
6912 CUDA Cores 6.7x capacity 1.7x bandwidth
7
A100 SM
Third-generation Tensor Core
Faster and more efficient
3rd Gen.
TENSOR
3rd Gen.
TENSOR
Comprehensive data types
CORE CORE Sparsity acceleration
Asynchronous data movement
and synchronization
3rd Gen. 3rd Gen.
TENSOR
CORE
TENSOR
CORE
Increased L1/SMEM capacity
192 KB L1 Data Cache / Shared Memory
8
NEW TF32 TENSOR CORES
Sign Range Precision
FP32 8 BITS 23 BITS
TF32 Range
TENSOR FLOAT 32 (TF32) 8 BITS 10 BITS
TF32 Precision
➢ Range of FP32 and Precision of FP16
FP16 5 BITS 10 BITS
➢ Input in FP32 and Accumulation in FP32
➢ No Code Change Speed-up for Training
BFLOAT16 8 BITS 7 BITS
9
MATRIX MULTIPLY THROUGHPUT WITH CUBLAS
10STRUCTURAL SPARSITY BRINGS ADDITIONAL SPEEDUPS
BERT Large Inference
1.5x
2X
Faster Execution
1x
A100 A100
Sparsity
Dense Sparse ➢ Structured sparsity: Half the values are
A100 Tensor zero
Matrix Matrix Core
➢ Skip half of the compute and mem fetches
➢ Compute up to 2x rate vs non-sparse
11
BERT Large Inference | precision = INT8 with and without sparsity | Batch sizes - no sparsity: bs256, with sparsity: bs49, A100 with 7 MIGSA100 STRONG SCALING INNOVATIONS
Math Improve speeds & feeds
and efficiency across all
RF SM levels of compute and
memory hierarchy
SMEM/L1
L2
GPU memory system
DRAM
NVLINK Multi-GPU systems
12A100 TENSOR CORE
2x throughput vs. V100, >2x efficiency
A100 TC Instruction
(2048 MACs, 8 cycles)
V100 TC Instruction A100 TC (1
32-Thread 16x8 cycle)
Math
(1024 MACs, 8 cycles)
Operand
FFMA 8-Thread 8-Thread 8-Thread 8-Thread Sharing
(32 MACs, 2 cycles) 8x4
4x8
8x8 16x16 16x8
RF
Registers
SMEM/L1
32 Threads (Warp)
L2 A100 vs. A100 vs.
V100 FFMA
16x16x16 matrix multiply FFMA V100 TC A100 TC (improvement) (improvement)
DRAM
Thread sharing 1 8 32 4x 32x
Hardware instructions 128 16 2 8x 64x
Register reads+writes (warp) 512 80 28 2.9x 18x
NVLINK
Cycles 256 32 16 2x 16x
13
Tensor Cores assume FP16 inputs with FP32 accumulator, V100 Tensor Core instruction uses 4 hardware instructionsA100 SM DATA MOVEMENT EFFICIENCY
3x SMEM/L1 bandwidth, 2x in-flight capacity
V100 A100
Math
warp0
warp1
warp0
warp1
RF
warp2
warp3
warp2
warp3
SMEM/L1 Tensor Cores Tensor Cores
RF RF
5 reads Load-Shared 2 reads
Load-Shared
1 write (4x) (2x)
L2 SMEM SMEM
Store-Shared
Reserved for in-
Reserved for in-
RF flight data Load-Global-
DRAM flight data Store-Shared
L1 Load-Global (Async-Copy)
L2 L2
NVLINK
DRAM DRAM 14A100 L2 BANDWIDTH
Parallelize
across GPU
Output
Activations Split L2 with
Math
hierarchical crossbar –
V100 V100++
(hypothetical)
A100
2.3x increase in
Tile: work
RF
for 1 SM
80 SMs
V100 TC
108 SMs
A100 TC
108 SMs
A100 TC bandwidth over V100,
lower latency
64 L2 slices 64 L2 slices 80 L2 slices
128 32 B/clk/slice 32 B/clk/slice 64 B/clk/slice
SMEM/L1
256
12 B/clk/SM 24 B/clk/SM 24 B/clk/SM
47% 127% 51%
L2
128
16 B/clk/SM 32 B/clk/SM 32 B/clk/SM
128 63% 169% 68%
DRAM
64
24 B/clk/SM 48 B/clk/SM 48 B/clk/SM
128
NVLINK 94% 253% 101%
15A100 DRAM BANDWIDTH
Faster HBM2 Larger and smarter L2
25% more pins, 38% faster clocks 40MB L2, 6.7x vs. V100
Math
→ 1.6 TB/s, 1.7x vs. V100 L2 residency controls
RF
kernel kernel kernel kernel kernel
SMEM/L1
buffer A buffer B buffer A buffer B buffer C
L2
kernel kernel kernel
Keep data resident in L2 to
DRAM buffer D buffer E
…
reduce DRAM bandwidth
NVLINK
16A100 NVLINK BANDWIDTH
Third Generation NVLink
50 Gbit/sec per signal pair
Math 12 links, 25 GB/s in/out, 600 GB/s total
2x vs. V100
RF
SMEM/L1
L2
NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink NVLink
DRAM
NVLINK
17A100 ACCELERATES CUDA GRAPHS
…
Grid launches:
• CPU-to-GPU
• GPU grid-to-grid
With strong scaling CPU and grid 32-node graphs of empty grids, DGX1-V, DGX-A100
launch overheads become
increasingly important One-shot CPU-to-GPU Microarchitecture
(Amdahl’s law) graph submission and improvements for grid-
graph reuse to-grid latencies
18A100 STRONG SCALING INNOVATIONS
Delivering unprecedented levels of performance
A100 improvements over V100
Math 2.5x Tensor Core math BW (FP16)
2.9x Effective RF BW with A100 Tensor Core
RF
2.8x Effective RF capacity with Async-Copy bypassing
RF
3.0x Effective SMEM BW with A100 Tensor Core and Async-Copy
SMEM/L1 2.3x SMEM capacity
2.3x L2 BW
L2 6.7x L2 capacity, +Residency Control
1.7x DRAM BW
DRAM 1.3x DRAM capacity
2.0x NVLINK BW
NVLINK
19MULTI-INSTANCE GPU (MIG)
Optimize GPU Utilization, Expand Access to More Users with Guaranteed Quality of Service
Up To 7 GPU Instances In a Single A100:
Dedicated SM, Memory, L2 cache, Bandwidth for
hardware QoS & isolation
Simultaneous Workload Execution With
Guaranteed Quality Of Service:
All MIG instances run in parallel with predictable
throughput & latency
Right Sized GPU Allocation:
Different sized MIG instances based on target
workloads
Diverse Deployment Environments:
Supported with Bare metal, Docker, Kubernetes,
Virtualized Env.
MIG User Guide: https://docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html 20LOGICAL VS. PHYSICAL PARTITIONING
A B C
CUDA MULTI-PROCESS SERVICE CONTROL
TensorFlow PyTorch PyTorch TensorFlow Jarvis + TensorRT TensorRT
GPU MULTI-PROCESS SERVICE
Multi-Process Service Multi-Instance GPU
Dynamic contention for GPU resources Hierarchy of instances with guaranteed resource allocation
Single tenant Multiple tenants
21CUDA CONCURRENCY MECHANISMS
Streams MPS MIG
Partition Type Single process Logical Physical
Max Partitions Unlimited 48 7
Yes (by percentage, not
SM Performance Isolation No Yes
partitioning)
Memory Protection No Yes Yes
Memory Bandwidth QoS No No Yes
Error Isolation No No Yes
Cross-Partition Interop Always IPC Limited IPC
Reconfigure Dynamic Process launch When idle
22GPU METRICS SAMPLING IN NSIGHT SYSTEMS
TensorFlow on 8xGA100 at 20khz
23GPU METRICS SAMPLING IN NSIGHT SYSTEMS
Hardware metrics collected at runtime to answer
▪ Is my GPU full? Sufficient grid size & streams?
▪ Is my instruction rate low (possibly I/O bound)?
▪ Am I using tensor cores?
▪ Can I see GPU Direct RDMA|Storage or other transfers?
System-wide GPU observation
10khz default can be increased depending on GPU
SM utilization metrics I/O throughput metrics
SMs active PCIe
Instructions NVLink
DRAM
Tensor cores
Warp occupancy
TensorFlow on 8xGA100 at 20khz
24You can also read

















































