Knowledge-Grounded Dialogue Flow Management for Social Robots and Conversational Agents
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Int J Soc Robot manuscript No.
(will be inserted by the editor)
Knowledge-Grounded Dialogue Flow Management for Social
Robots and Conversational Agents
Lucrezia Grassi · Carmine Tommaso Recchiuto · Antonio Sgorbissa
arXiv:2108.02174v1 [cs.RO] 4 Aug 2021
Received: date / Accepted: date
Abstract The article proposes a system for knowledge- 1 Introduction
based conversation designed for Social Robots and other
conversational agents. The proposed system relies on an Social Robotics is a research field aimed at providing
Ontology for the description of all concepts that may robots with a brand new set of skills, specifically re-
be relevant conversation topics, as well as their mutual lated to social behaviour and natural interaction with
relationships. The article focuses on the algorithm for humans.
Dialogue Management that selects the most appropri- Social robots can be used in many contexts such
ate conversation topic depending on the user’s input. as education [1], welcoming guests in hotels [2], cruise
Moreover, it discusses strategies to ensure a conversa- ships [3], malls [4], and elderly care [5]. A noteworthy
tion flow that captures, as more coherently as possible, application of Socially Assistive Robots (SARs) is in
the user’s intention to drive the conversation in spe- the healthcare field: it has been argued that robots can
cific directions while avoiding purely reactive responses be used to make people feel less lonely and help human
to what the user says. To measure the quality of the caregivers taking care of elders in care homes [6][7]. In
conversation, the article reports the tests performed particular, robots may help to cope with caregiver bur-
with 100 recruited participants, comparing five conver- den, i.e., the stress perceived by formal and informal
sational agents: (i) an agent addressing dialogue flow caregivers, a relevant problem both in care homes and
management based only on the detection of keywords domestic environments. This subjective burden is one of
in the speech, (ii) an agent based both on the detec- the most important predictors for adverse outcomes of
tion of keywords and the Content Classification feature the care situation for the caregivers themselves, as well
of Google Cloud Natural Language, (iii) an agent that as for the one who requires care. Clinicians frequently
picks conversation topics randomly, (iv) a human pre- overlook the caregiver burden problem [8].
tending to be a chatbot, and (v) one of the most famous Recently, social robots have been recognized as a
chatbots worldwide: Replika. The subjective perception very important resource by one of the most recent ed-
of the participants is measured both with the SASSI itorials of Science Robotics [9], which analyzes the po-
(Subjective Assessment of Speech System Interfaces) tential of robots during the COVID-19 pandemic and
tool, as well as with a custom survey for measuring the underlines how Social Robotics is a very challenging
subjective perception of coherence. area: social interactions require the capability of au-
tonomously handling people’s knowledge, beliefs, and
Keywords Social Robotics · Conversational Agents · emotions. In the last year, COVID-19 threatened the
Knowledge-Grounded Conversation life of people with a higher risk for severe illness, i.e.,
older adults or people with certain underlying medi-
L. Grassi (B) · C.T. Recchiuto · A. Sgoribissa cal conditions. To slow down the spread of the virus
University of Genoa, DIBRIS, via all’Opera Pia 13
Tel.: +39 010 3532801
[10], there is the need to reduce social contacts and, as
Fax: +39 010 3532154 a consequence, many older adults have been left even
E-mail: lucrezia.grassi@edu.unige.it more socially isolated than before. However, in many
cases, loneliness can spring adverse psychological effects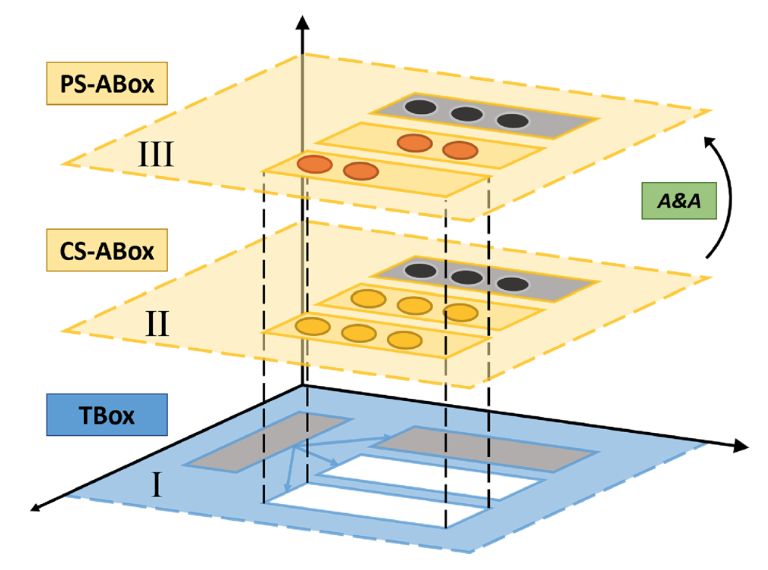
2 Lucrezia Grassi et al.
such as anxiety, psychiatric disorders, depression, and conversation to provide coherent replies, even when it
decline of cognitive functions [11]. In this scenario, So- is not able to fully understand what the user is talking
cial Robotics and Artificial Intelligence, in general, may about (which is likely to happen very often if the user
have a crucial role: conversational robots and virtual is free to raise any topic).
agents can provide social interactions, without spread- To increase the impact of the conversational sys-
ing the virus. tems of Social Robots, [19] argues that they shall be
In many Social Robotics applications, the main fo- designed to overcome a number of limitations. Some
cus is on the conversation. Based on its purpose, the desirable features that are not present in most systems
conversation can be subdivided into: are: (1) Breaking the “simple commands only” bar-
– task-oriented : it is used to give commands to per- rier; (2) Multiple speech acts; (3) Mixed initiative dia-
form a task or retrieve information. Examples of logue;(4) Situated language and the symbol grounding
task-oriented conversations can be found both dur- problem; (5) Affective interaction; (6) Motor correlates
ing the interaction with a robot, i.e., “Go to the and Non-Verbal Communication; (7) Purposeful speech
kitchen”, and during the interaction with a smart and planning; (8) Multi-level learning; (9) Utilization of
assistant, i.e., “Turn off the light”. In this case, the online resources and services.
problem is to understand the semantics of what the The main contribution of the article is to investigate
user is saying, to provide the required service. possible solutions to issue 7, that we aim to achieve by
– chit-chatting: it has the purpose of gratifying the properly managing the conversation flow towards the
user in the medium to long term, keeping him/her execution of tasks or the exploration of relevant top-
engaged and interested. For this kind of conversa- ics, thus ultimately leading to a more engaging interac-
tion, the most relevant problem, rather than per- tion with the user. During the conversation, it typically
fectly grasping the semantics of what the person happens that a robot may provide answers that have
says, is to be able to manage the conversation, show- nothing to do with what the user says: this has a very
ing the knowledge and competence on a huge num- negative impact on the “suspension of disbelief” that is
ber of different topics coherently and entertainingly required to give the user the impression of genuine in-
[12]. telligence, and ultimately it generates frustration. Here,
a key element is the capability to know when to further
In this scenario, the CARESSES project1 is the first
explore the current topic or choose the next conversa-
project having the goal of designing SARs that are cul-
tion topic, coherently with the user’s sentence: if the
turally competent, i.e., able to understand the culture,
algorithm does not pick a topic coherently, the agent’s
customs, and etiquette of the person they are assisting,
reply will not be appropriate, even if the system had
while autonomously reconfiguring their way of acting
the knowledge to interact consistently.
and speaking [13]. CARESSES exploited the humanoid
Specifically, we proceed as follows.
robot Pepper2 as the main robotic platform for inter-
acting with people [6], in particular with older people First, we propose a novel system for knowledge-
in care homes, to make them feel less isolated and re- based conversation and Dialogue Management that re-
duce the caregiver burden. Under these conditions, the lies on an Ontology for the description of all relevant
capability of engaging the user to chit-chat with the sys- concepts that may play a key role in the conversation:
tem becomes of the utmost importance, as it has been the Ontology is designed to take into account the pos-
shown [7] that this may have a positive impact on qual- sible cultural differences between different users in a
ity of life [16], negative attitude towards robots [17], and no-stereotyped way, and it stores chunks of sentences
loneliness [18]. However, for a proper conversation to be that can be composed in run-time, therefore, enabling
possible, the system shall be able to talk about a huge the system to talk about the aforementioned concepts
number of topics that may be more or less relevant for in a culture-aware and engaging way [14][20].
different cultures, by properly managing the flow of the Second, we test the developed solutions by compar-
ing five Artificial Conversational Agents during a con-
1
http://caressesrobot.org/ versation with 100 recruited participants: (i) an agent
2
CARESSES architecture has been recently revised to al-
addressing dialogue flow management based only on the
low for a Cloud-based implementation [14], thus enabling vir-
tually any device equipped with a network interface to per- detection of keywords, (ii) an agent addressing dialogue
form long-term, culture-aware conversation with the user. flow management based both on the detection of key-
Currently, the robots Pepper and NAO, the pill-dispenser words and the Content Classification feature of Google
Pillo, Prof. Einstein, and a virtual character implemented as
Cloud Natural Language, (iii) an agent that picks ran-
an Android application have been provided with the onboard
functionalities to implement the instructions received by the dom topics among those present in the Ontology, (iv) a
CARESSES Cloud [15]. human pretending to be a chatbot, and (v) one of theKnowledge-Grounded Dialogue Flow Management for Social Robots and Conversational Agents 3
most famous chatbots worldwide: Replika. The subjec- as “I see, very interesting” as it has no previous knowl-
tive perception of the participants is measured both edge about Pizza. On the other side, the latter may be
with the SASSI (Subjective Assessment of Speech Sys- more specific, i.e., “Oh, pizza is a very delicious Italian
tem Interfaces) tool [21][22] and a custom survey for food”, if it had the chance to recall internal or exter-
measuring the subjective perception of coherence in the nal knowledge about pizza, e.g., using resources on the
conversation. web.
The remainder of this article is organized as follows. Building a knowledge-grounded conversational sys-
Section 2 presents an overview of previous works related tem raises many challenges. For instance, the internal
to Knowledge-Grounded Conversation, the most popu- knowledge may be static or “expandable”, i.e., updated
lar validated tools to evaluate the User Experience, and in run-time with new external information retrieved
introduces the concept of “coherence” in Dialogue Man- from the user utterances, which will be considered as
agement. Eventually, it presents a typical classification internal knowledge in the next interactions. The exter-
for Artificial Conversational Agents and describes the nal knowledge in most cases will come from websites:
up-to-date most famous chatbots. An overview of the however, even if the system can find some documents
CARESSES knowledge-based conversational system is associated with the current conversation topic by using
given in Section 3. Section 4 describes the experiment a state-of-the-art information retrieval system, it may
carried on to evaluate the user satisfaction when inter- be difficult to extract knowledge from the search results
acting with the agents, along with the statistical tools because this would typically require complex Natural
used to analyse the collected data. Section 5 presents Language Processing techniques to select the appropri-
the results obtained, discussed in detail in Section 6. ate knowledge.
Eventually, Section 7 draws the conclusions. This is done in [23] using a Generative Transformer
Memory Network and in [24] using an SVM classifier,
to name a few. Another complex task is to generate
2 State of the Art appropriate responses that reflect the acquired knowl-
edge as a consequence of the conversation history. The
This section addresses Knowledge-Grounded Conversa- problems of knowledge extraction and response gener-
tion, presenting a brief analysis of the related Litera- ation, among the others, are addressed in [25], where a
ture. Moreover, it gives an overview of the most used knowledge-grounded multi-turn chatbot model is pro-
tools to evaluate the User Experience during the in- posed (see also 2.3 for popular chatbots based on this
teraction with conversational agents and introduces a principle).
new metric exploited in our experiment. Eventually, A data-driven and knowledge-grounded conversa-
it presents a classification for Artificial Conversational tion model, where both conversation history and rel-
Agents and describes the up-to-date most famous chat- evant facts are fed into a neural architecture that fea-
bots. tures distinct encoders for the two entries, is proposed
in [26]. Such model aims to produce more appropriate
responses: the article shows that the outputs generated
2.1 Knowledge-Grounded Conversation by a model trained with sentences and facts related
to the conversation history were evaluated by human
A knowledge-grounded conversational system is a dia- judges as remarkably more informative (i.e., knowledge-
logue system that can communicate by recalling inter- able, helpful, specific) with respect to those of a model
nal and external knowledge, similarly to how humans trained with no facts.
do, typically to increase the engagement of the user dur- In [27], a large corpus of status-response pairs found
ing chit-chatting. The internal knowledge is composed on Twitter has been employed to develop a system
of things that the system already knows, while exter- based on phrase-based Statistical Machine Translation,
nal knowledge refers to the knowledge acquired in run- able to respond to Twitter status posts. As stated in the
time. To this end, knowledge-grounded systems must article, data-driven response generation will provide an
not only understand what the user says but also store important breakthrough in the conversational capabil-
external knowledge during the conversations, and their ities of a system. Authors claim that when this kind of
responses should be based on the stored knowledge. approach is used inside a broad dialogue system and is
There are many differences between the replies of a combined with the dialogue state, it can generate lo-
normal conversational system and those of a knowledge- cally coherent, purposeful, and more natural dialogue.
grounded system. For example, if the user says “I love Finally, the problem of knowledge representation
pizza”, the former might provide a general answer such and knowledge-based chit-chatting, keeping into account4 Lucrezia Grassi et al.
the cultural identity of the person, is addressed in [20] utterance, and then act appropriately. However, accord-
and [14] using an Ontology designed by cultural experts ing to the aforementioned definition, what the System
coupled with a Bayesian network, to avoid rigid rep- Response Accuracy scale aims to measure is not equiv-
resentations of cultures that may lead to stereotypes. alent to the broader concept of coherence that has been
Such an approach allows the system to have more con- given: it measures the quality of the system’s reply to
trol over what the robot says during the conversation: the user’s input in a purely reactive fashion, without re-
the idea of having a knowledge base designed by experts lying on the concept of “current topic of conversation”.
is particularly suitable for sensitive situations, i.e. when For this reason, a coherence measure in the spirit of
dealing with the more fragile population such as older [31] and [32] has been used to supplement the SASSI
adults or children. Approaches that automatically ac- questionnaire, which requires users to rate individual
quire knowledge from the Internet may not be optimal sentences pronounced by the robot at the light of the
in these scenarios. context (details are given in Section 4.2.1). Notice that
[32] and [33] propose also methods to automatically
evaluate the coherence, as this is considered an impor-
2.2 User Experience
tant metrics to evaluate multi-turn conversation in open
domains: however, in this work we are only interested
In the Literature, tools exist that can be used to eval-
in evaluating the subjective perception of users, which
uate the User Experience (UX) and the overall qual-
makes a simple rating mechanism perfectly fitting our
ity of the conversation. The work carried on in [28] re-
purposes.
views the six main questionnaires for evaluating conver-
sational systems: AttrakDiff, SASSI, SUISQ, MOS-X,
PARADISE, and SUS. Moreover, it assesses the poten- 2.3 Artificial Conversational Agents
tial suitability of these questionnaires to measure vari-
ous UX dimensions. Depending on the emphasis they put on a task-oriented
As a measure of the quality of the flow of conversa- conversation or chit-chatting, a typical classification for
tion, we aim to evaluate how “coherent” the system is: artificial conversational agents is based on their scope:
this shall be done not only taking into account the last
user’s utterance but also the current conversation topic – Question answering bots: knowledge-based conver-
(i.e., what is referred to as context in [29][30]). To clar- sational systems that answer to users’ queries by
ify what this means, suppose a conversational system analysing the underlying information collected from
that replies very accurately to everything the user says: various sources like Wikipedia, DailyMail, Allen AI
if the user talks about football, the system will reply science and Quiz Bowl [34];
talking about football, if the user talks about apples, – Task-oriented bots: conversational systems that as-
the system will reply talking about apples. But what if sist in achieving a particular task or attempt to solve
the person and the system are talking about football, a specific problem such as a flight booking or hotel
and the person says something that is not recognized as reservation [35];
related to anything specific, such as “I will think about – Social bots: conversational systems that communi-
that”, “I think so”, “It’s so nice to talk with you”, and cate with users as companions, and possibly en-
so on? A coherent Dialogue Management system shall tertain or give recommendations to them [36]: re-
be able to understand when it is more appropriate to cent notable examples are Microsoft Xiaoice [37] and
further explore the current conversation topic (in this Replika3 .
example, by taking the initiative to ask the person a
question about his/her preferred team or players) or In the following, we discuss more in detail the agents
lead the dialogue to another topic, coherently with what belonging to the third class pointing out differences and
the user said. similarities with out solution, without making a dis-
Unfortunately, the aforementioned UX tools are not tinction between robots and chatbots, unless strictly
meant to evaluate a medium-term mixed-initiative dia- required.
logue, as in our case. The most similar measure to what For many decades, the development of social bots,
we want to evaluate is the System Response Accuracy or intelligent dialogue systems that can engage in em-
scale of the SASSI questionnaire: such a questionnaire, pathetic conversations with humans, is one of the main
described more in detail in Section 4.2.2, has been used goals of Artificial Intelligence. As stated in [38], early
during our experiments. The System Response Accuracy conversational systems such as Eliza [39], Parry [40],
is defined as the system’s ability to correctly recognise 3
https://help.replika.ai/hc/en-us/articles/
the speech input, correctly interpret the meaning of the 115001070951-What-is-Replika-Knowledge-Grounded Dialogue Flow Management for Social Robots and Conversational Agents 5
and Alice [41] were designed to mimic human behaviour conversation. Unfortunately, we could not try XiaoIce
in a text-based conversation, hence to pass the Tur- as it is not available in Italy.
ing Test [42] within a controlled scope. Despite their Replika is presented as a messaging app where users
impressive successes, these systems, which were pre- answer questions to build a digital library of informa-
cursors to today’s social chatbots, worked well only in tion about themselves. Its creator, a San Francisco-
constrained environments. In more recent times, among based startup called Luka, sees see a whole bunch of
the most successful conversational agents for general possible uses for it: a digital twin to serve as a compan-
use that can act as digital friends and entertainers, Xi- ion for the lonely, a living memorial of the dead, created
aoice, Replika, Mitsuku, and Insomnobot-3000 are the for those left behind, or even, one day, a version of our-
most frequently mentioned [43]. selves that can carry out all the mundane tasks that we
XiaoIce (“Little Ice” in Chinese) is one of the most humans have to do, but never want to.
popular chatbots in the world. It is available in 5 coun- To the best of the authors’ knowledge, there is no
tries (i.e., China, Japan, US, India, and Indonesia) un- detailed explanation of the implementation of Replika,
der different names (e.g., Rinna in Japan) on more hence we can only make assumptions on how issues re-
than 40 platforms, including WeChat, QQ, Weibo, and lated to Dialogue Management are faced. After having
Meipai in China, Facebook Messenger in the United intensively tried Replika, it seems that the conversation
States and India, and LINE in Japan and Indonesia. is partitioned into “sessions” in which it has specific
Its primary goal is to be an AI companion with which competencies, somehow playing a similar role as top-
users form long-term emotional connections: this dis- ics in XiaoIce and our system. Concerning issue 7 in
tinguishes XiaoIce not only from early chatbots but Section 1, the chatbot uses a Neural Network to hold
also from other recently developed conversational AI an ongoing, one-on-one conversation with its users, and
personal assistants such as Apple Siri, Amazon Alexa, over time, learn how to talk back [44]. The agent is
Google Assistant, and Microsoft Cortana. trained on texts from more than 8 million web pages,
As stated in [37], the topic database of XiaoIce is from Twitter posts to Reddit forums, and it can re-
periodically updated by collecting popular topics and spond in a thoughtful and human-like way. From time
related comments and discussions from high-quality In- to time, it will push the user to have a “session” to-
ternet forums, such as Instagram in the US and the gether: in this session, it will ask questions regarding
website douban.com in China. To generate responses, what the user did during the day, what was the best
XiaoIce has a paired database that consists of query- part of the day, what is the person looking forward to
response pairs collected from two data sources: human tomorrow, and eventually, the user has to rate his/her
conversational data from the Internet, (e.g., social net- mood on a scale of 1 to 10. During this session, Rep-
works, public forums, news comments, etc.), and human- lika takes control of the conversation and insists that
machine conversations generated by XiaoIce and her the user answers its questions about a specific matter,
users. Even if the data collected from the Internet are something that may be annoying and frustrating, and
subjected to quality control to remove personally iden- we avoid by letting the user free to easily switch to an-
tifiable information (PII), messy code, inappropriate other topic at any time. Replika’s responses are backed
content, spelling mistakes, etc., the knowledge acqui- by Open AI’s GPT-24 text-generating AI system [45].
sition process is automated and it is not supervised Mitsuku 5 , or Kuki as her close friends call her, is a
by humans: differently from our system, this solution chatbot created by Pandorabots6 : an open-source chat-
may not be suitable in sensitive situations, e.g., when bot framework that allows people to build and publish
dealing with the more fragile population such as older AI-powered chatbots on the web, mobile applications,
people or children. Regarding issue 7 in Section 1 (i.e., and messaging apps like LINE, Slack, WhatsApp, and
the lack of flow in the conversation), the implementa- Telegram.
tion of XiaoIce addressed this problem by using a Topic The Pandorabots chatbot framework is based on the
Manager that mimics human behavior of changing top- Artificial Intelligence Markup Language (AIML) script-
ics during a conversation. It consists of a classifier for ing language, which developers can use to create con-
deciding at each dialogue turn whether or not to switch versational bots. The downside is that Pandorabots do
topics and a topic recommendation engine for suggest- not include machine learning tools that are common
ing a new topic. Topic switching is triggered if XiaoIce on other chatbot building platforms. A specific AIML
does not have sufficient knowledge about the topic to file allows users to teach Mitsuku new facts: the user
engage in a meaningful conversation, an approach that 4
https://en.wikipedia.org/wiki/GPT-2
our system adopts as well by relying on an Ontology 5
https://www.pandorabots.com/mitsuku/
6
for representing relationships among different topics of https://home.pandorabots.com/home.html6 Lucrezia Grassi et al.
should say “Learn” followed by the fact (i.e., “Learn time, more specific to the context. Authors report also
the sun is hot”). The taught information is emailed to that issues related to inappropriate and biased language
its creator Steve Worswick, which will personally su- have still to be solved: to the best of our knowledge, a
pervise the learning process. To address issue 7 in Sec- publicly available version of this chatbot has not been
tion 1, specific areas of competence of the chatbot are released yet.
managed by different AIML files, which are responsible BlenderBot [30] is a very recent open-domain chat-
for maintaining coherence in the responses: AIML files, bot developed at Facebook AI Research. As like as we
therefore, play a similar role as topics/concepts in the do, the authors put a stronger emphasis on aspects that
Ontology that are the core elements of our system, but are not only related to sentence generation: they argue
without the benefit of having a hierarchical structure that good conversation requires a number of skills to
as a key element for Dialogue Management. Mitsuku is be blended in a seamless way, including providing en-
a five-time Loebner Prize winner (in 2013, 2016, 2017, gaging topics of conversation as well as listening and
2018, 2019), and it is available in a web version7 , Face- showing interest to what the user says, among the oth-
book Messenger, Kik Messenger, and Telegram. ers. Current generative models, they argue, tend to pro-
Insomnobot-3000 8 is the world’s first bot that is duce dull and repetitive responses (and, we would add,
only available to chat, exclusively via SMS, between they do not take cultural appropriateness into account),
11pm and 5am regardless of the time zone. The bot was whereas retrieval models may produce human written
built by the mattress company Casper and, according utterances that tend to include more vibrant (and cul-
to its creators, it was programmed to sound like a real turally appropriate) language. To overcome the limita-
person and talk about almost anything. Insomnobot- tions of purely generative models, BlenderBot includes
3000 cannot learn new things and expand its knowl- a retrieval step before generation according to a retrieve
edge base: however, it can generate over 2,000 different and refine model [46], which retrieves initial dialogue
responses, depending on which category and emotion utterances and/or knowledge from a large knowledge
the keyword falls under. Concerning issue 7 in Section base. As like Meena, the system is trained to choose
1, when the bot receives a text, it chooses an appro- the next dialogue utterance given the recent dialogue
priate response by identifying keywords: however, dif- history, referred to as context: training is performed us-
ferently from the aforementioned systems and our solu- ing a number of datasets that are key to exhibit differ-
tion, it lacks a more sophisticated mechanism for Dia- ent skills (i.e., engaging personality, emotional talking,
logue Management to switch in-between different areas knowledge-grounded conversation), as well as a Blended
of competence or topics to provide contextual replies. Skill Talk dataset that merges utterances taken from
In addition to the aforementioned chatbot avail- the three. Authors claim that their model outperforms
able to the large public, recent research on data-driven Meena in human evaluations, however, they acknowl-
knowledge-grounded conversation based on sophisticated edge that the system still suffers from a lack of in-
generative models is worth being mentioned. depth knowledge if sufficiently interrogated, a tendency
Meena [29] is a generative chatbot model trained to stick to simpler language, and a tendency to repeat
end-to-end on 40B words mined from public domain often used phrases.
social media conversations, that addresses the problem DialoGPT [47] is a neural conversational response
of multi-turn conversation in open domains. Accord- generation model trained on 147M conversation-like ex-
ing to its authors, this chatbot can conduct conversa- changes extracted from Reddit comment chains over a
tions that are more sensible and specific than existing period spanning from 2005 through 2017 and it extends
state-of-the-art chatbots. Such improvements are mea- GPT-2. Authors claim that conversational systems that
sured by a new human evaluation metric, called Sensi- leverage DialoGPT generate more relevant, contentful,
bleness and Specificity Average (SSA), which captures and context-consistent responses than strong baseline
important attributes for human conversation. Meena is systems. As it is fully open-sourced and easy to deploy,
based on the concept of multi-turn contexts to evaluate users can extend the pre-trained conversational system
the quality of a response: not only the last sentences to bootstrap training using various datasets. Authors
but the recent conversation history in terms of (con- claim that the detection and control of toxic output
text, response) pairs is used to train and evaluate the will be a major focus of future investigation.
network. Experiments show significant improvements in
All generative models based on human-human data
SSA with respect to competitors, providing replies that
offers many advantages in producing human-like utter-
are coherent with what the user said and, at the same
ances fitting the context, but have the major drawback
7
https://chat.kuki.ai that they can learn undesirable features leading to toxic
8
https://insomnobot3000.com or biased language. Classifiers to filter out inappropri-Knowledge-Grounded Dialogue Flow Management for Social Robots and Conversational Agents 7
ate language exist [48], but they still have limitations: whichever the cultural identity of the user is, to avoid
this issue is particularly important when dealing with stereotypes (an example related to different kind of bev-
the more frail populations, especially by considering erages is shown in Figure 2). The system will initially
that classifying language as inappropriate or offensive guess the user’s beliefs, values, habits, customs, pref-
typically depends on cultural factors, and the devel- erences based on the culture he/she declared to self-
opment of classifiers working properly in multiple cul- identify with, but it will then be open to considering
tures may be very challenging. Since we claim that a choices that may be less likely in a given culture, as the
proper flow of conversation deserves higher attention user explicitly declares his/her attitude towards them.
than the automatic generation of sentences, we address According to this principle, the system may initially in-
these problems through an Ontology of conversation fer that an English person may be more interested to
topics and topic-related chunks of sentences generated talk about Tea rather than Coffee, and the opposite
by cultural experts, that are then composed in run-time may be initially inferred for an Italian user. However,
using the hierarchical structure of the knowledge-base during the conversation, initial assumptions may be re-
to produce a huge variety of sentences. Finally, even if vised, thus finally leading to a fully personalized repre-
this is not the main objective of this article, it is worth sentation of the user’s attitude towards all concepts in
reminding that our system may take cultural aspects the TBox, to be used for conversation.
into account in Dialogue Management, an element that
is completely ignored by all state-of-the-art systems.
3 System Architecture
Even if the focus of this article is on knowledge-based
chit-chatting and dialogue flow management, and not
on cultural adaptation, it is necessary to briefly in-
troduce the structure of the cultural knowledge base
used by the CARESSES conversational system since it
strongly influences the algorithms we implemented.
3.1 Knowledge Representation
In CARESSES, the ability of the companion robot to
Fig. 1 Knowledge representation architecture for a cultur-
naturally converse with the user has been achieved by ally competent robot.
creating a framework for cultural knowledge represen-
tation that relies on an Ontology [49] implemented in
OWL2 [50]. According to the Description Logics formal- To implement this mechanism, the Culture-Specific
ism, concepts (i.e., topics of conversation the system is ABox layer comprises instances of concepts (with prefix
capable of talking about) and their mutual relations are EN for “English” in Figure 2) encoding culturally ap-
stored in the terminological box (TBox) of the Ontol- propriate chunks of sentences to be automatically com-
ogy. Instead, instances of concepts and their associated posed (Data Property hasSentence) and the probabil-
data (e.g., chunks of sentences automatically composed ity that the user would have a positive attitude toward
to enable the system to talk about the corresponding that concept, given that he/she belongs to that cultural
topics) are stored in the assertional box (ABox). group (Data Property hasLikeliness).
To deal with representations of the world that may Eventually, the Person-Specific ABox comprises in-
vary across different cultures [51], the Ontology is or- stances of concepts (with prefix DS for a user called
ganized into three layers, as shown in Figure 1. The “Dorothy Smith” in Figure 2) encoding the actual user’s
TBox (layer I) encodes concepts at a generic, culture- attitude towards a concept (Mrs Dorothy Smith may be
agnostic level, which can be inherited from existing more familiar with having tea than the average English
upper and domain-specific Ontologies (grey boxes) or person, hasLikeliness=Very High), sentences to talk
explicitly defined to enable culture-aware conversation about a topic explicitly taught by the user to the sys-
with the user (white boxes). An important point to be tem (hasSentence=“You can never get a cup of tea
highlighted is that the TBox should include concepts large enough or a book long enough to suit me”) or
that are typical of the union all cultures considered, other knowledge explicitly added during setup (e.g., the8 Lucrezia Grassi et al.
user’s name and the town of residence). At the first en-
counter between the robot and a user, many instances
of the Ontology will not contain Person-Specific knowl-
edge: the robot will acquire this awareness at run-time
either from its perceptual system or during the interac-
tion with the user, e.g., asking questions. Figure 1 also
shows that some instances of existing Ontologies that
are not culture- or person-dependent (dark circles) may
not change between the two ABox layers: this may re-
fer, for instance, to technical data such as the serial
number of the robot or physical quantities, if they need
to be encoded in the Ontology. For a detailed descrip-
tion of the terminological box (TBox) and assertional
box (ABox) of the Ontology, as well as the algorithms
for cultural adaptation, see [14][20].
The Dialogue Tree (DT) (Figure 2), used by the
chit-chatting system (Section 3.2), is built starting from
the Ontology structure: each concept of the TBox and
the corresponding instances of the ABox are mapped
into a conversation topic, i.e., a node of the tree. The re-
lation between topics is borrowed from the structure of
the Ontology: specifically, the Object Property hasTopic
and the hierarchical relationships among concepts and
instances are analyzed to define the branches of the
DT. In the example of Figure 2, the instance of Tea
for the English culture is connected in the DT to its
child node GreenTea (which is a subclass of Tea in the
Ontology), and its sibling MilkTea (since EN MILK is a
filler of EN TEA for the Object Property hasTopic).
As mentioned, each conversation topic has chunks
of culturally appropriate sentences associated with it
that are automatically composed and used during the
conversation. Such sentences can be of different types
(i.e., positive assertions, negative assertions, different
kinds of questions, or proposals for activities) and are
selected in subsequent iterations, also depending on in-
put received from the user. Typically, when exploring a
topic, the system may first ask a question to understand
if the user is familiar with that topic: if so, this may be
followed by general considerations, proposals for activ-
ities, or open questions, until the system moves to the
next topic if the conditions hold. Multiple sentences of
the same type are present, randomly chosen to reduce
the chance of repetitions. At any time, the user is free to
take the initiative to express his/her considerations or
lead the conversation somewhere else. Sentences may
contain variables that are instantiated when creating
the DT. For instance, a hypothetical sentence “Do you
like $hasName?” encoded in the concept Coffee might
Fig. 2 The three layers of the Ontology: TBox, CS-ABox (for
be used to automatically produce both “Do you like
the English culture), PS-ABox (for the user Dorothy Smith),
and the Dialogue Tree generated from the Ontology structure. Coffee?” and “Do you like Espresso?” (being Espresso
a subclass of Coffee). As further example, the sentence
“I love $hasName with $hasTopic*hasName” encodedKnowledge-Grounded Dialogue Flow Management for Social Robots and Conversational Agents 9
in the concept Movie can be used to produce both “I BreakfastHabits) to more specific (e.g., the topic
love movies with great actors” and “You know... I love HavingTeaForBreakfast) or related ones (e.g., the
Bollywood movies with Amitabh Bachchan”, depend- topic TakingCareOfOneself). This is achieved by
ing on the taxonomy of the knowledge base and ad- selecting the branches to maximise the probability
ditional rules for sentence composition. In the current that the user will be interested in the next topic
version used for testing, exploiting the taxonomy of the (also based on cultural factors). When in a topic,
Ontology allowed us to easily produce a DT with 2,470 the system asks questions, reply with positive or
topics of conversation and 24,033 sentences, with ran- negative assertions, propose activities or simply en-
dom variations made in run-time. courage the user to freely express his/her view, by
A few additional words are worth spending to clar- composing chunks of sentences encoded in the on-
ify this concept. Currently, as in the aforementioned ex- tology, until the topic has been sufficiently explored.
ample, one sentence may contain two variables whose Probabilities associated with topics have been ini-
value depends on (i) the specific concept that inherited tially assigned with the help of Transcultural Nurs-
that Data Property from superconcepts in the Ontol- ing experts as well as looking for information on the
ogy, and (ii) related concepts connected to it through an Internet about habits, foods, sports, religions, etc. in
Object Property. Then, when manually adding a sen- different cultures. Please, notice however that these
tence as a Data Property of a given concept, a num- are only initial guesses, as the system will update
ber of sentences will be inherited and added automat- probabilities during the conversation depending on
ically depending on the number of (i) its subconcepts the user’s preferences and attitudes to avoid stereo-
and (ii) their role-fillers. By considering a DT gener- typed representations.
ated from the Ontology and having a branching factor 2. The second mechanism enables the Dialogue Man-
B = Bs + Bp , where Bs is the branching factor due agement algorithm to jump to a different topic of
to subconcepts and Bp is the branching factor due to the DT depending on what the user says (e.g., when
role-fillers, adding a sentence in a concept at a height talking about BreakfastHabits the person may start
H from DT leaves produces a number of sentence in talking about a Restaurant he/she loves). After do-
the order of O(H B ); by considering that all sentences ing so, the system reverts to the first mechanism
are randomly associated in run-time with a prefix (e.g., but starting from the new topic: it asks questions,
“You know...”, “I heard that...”) and may be appended makes positive and negative comments, proposes ac-
to each other, this increases the number of variations tivities, or allows the person to freely express his/her
even more. For instance, in the current configuration view about the new topic, and then re-start follow-
with 2,470 concepts, adding a sentence at the root of ing branches as previously.
the DT will produce a maximum of 2,470 inherited sen-
With reference to Figure 2, a possible dialogue pat-
tences in the whole Ontology (which however, may lack
tern between the robot and Mrs Dorothy Smith, using
specificity, as it is unlikely that the same pattern may
the aforementioned mechanisms, would be the follow-
be easily adapted to talk about everything in the ontol-
ing (labels 1 and 2 identify the mechanism currently
ogy: i.e., “I love talking about $hasTopic with you” may
adopted by the system to navigate the DT):
work for all subconcepts, but “I like eating $hasTopic”
R. (1): Do you usually drink something with your
will not).
meals?
Mrs S.: Always! At least I try...
R. (1): Drinking water is very important for health!
3.2 Chit-Chatting
Please, tell me more about your drinking preferences.
When the user pronounces a sentence that triggers the Mrs S.: Well, I mostly drink water during lunch.
start of a conversation, the system switches to the chit- R. (1): I know that many English persons love tea.
chatting state. In this case, the Dialogue Management Do you?
algorithm operates to keep the conversation as engaging Mrs S.: Yes, of course! But mostly in the afternoon.
and natural as possible by implementing two different, R. (1): You can never get a cup of tea large enough
intertwined methods to navigate the DT based on what or a book long enough to suit me. Do you usually have
the user says: milk with your tea?
Mrs S.: Yes, and scones, too! But they are not very
1. The first mechanism implemented by the Dialogue healthy.
Management algorithm simply chooses the topic based R. (2): I love scones with jam and whipped cream!
on the DT, following the branches from more general Figure 3 depicts a detailed flow-chart that clarifies
conversation topics close to the root (e.g., the topic what happens during the interaction with the user.10 Lucrezia Grassi et al.
The diagram shows that, as soon as the person says
something, the Dialogue Management algorithm first
checks if the user’s sentence contains some command
that is aimed to trigger an activity (box Perform the
required activity). This task-oriented part of the di-
alogue has been implemented in our experiments with
caring robots during the CARESSES project, but not
in the tests described in this article, and it may rely on
a third-party system for NLP9 or a pre-existing com-
mand interface that is already implemented onboard
the robot (e.g., verbal commands to clean the room in
case of a robotic vacuum cleaner, or to deliver medicines
in case of a robotic pill dispenser).
If a command is not found, the user’s input is pro-
cessed (box Process user sentence with Dialogue
Management mechanism 1 or 2) by using the two mech-
anisms described so far: as a first step the user’s utter-
ance is analysed to check if something relevant is de-
tected, and possibly used to jump to another topic us-
ing mechanism 2; if no information is found to jump
to another topic, mechanism 1 checks if the current
topic shall be further explored or it is time to follow the
branches of the DT from a parent node to a children
node that is semantically related in the Ontology. Even-
tually, it should be mentioned that activities (e.g., vac-
uum cleaning or pill delivery) may even be proposed by
the Dialogue Management System itself when related Fig. 3 Flow chart of the basic chit-chatting framework.
to the current topic of discussion (i.e., if the person is
talking about cleaning and the robot has this capabil-
ity). The interaction continues in this way until the user at evaluating the quality of the conversation: the anal-
explicitly asks to stop it. ysis performed was rather aimed to measure improve-
This approach to Dialogue Management, despite its ment in health-related quality of life (SF-36 [16]), neg-
simplicity, reveals to be very effective for chit-chatting. ative attitude towards robots (NARS [17]), loneliness
It should be reminded that here Dialogue Management (ULS-8 [18]). Indeed, additional analysis with a wider
is not meant to understand all the nuances of human population is needed to evaluate the quality of the con-
language when giving a specific command to be ex- versation produced by our system in terms of issue 7 in
ecuted (i.e., “Put the red ball on the green table”), Section 1, and motivates the present study. When nav-
but rather it aims at engaging the user in rewarding igating in the knowledge base following the branches
conversations: an objective that we try to achieve by of the DT (aforementioned mechanism 1), coherence in
enabling the system to coherently talk about a huge the flow of conversation is straightforwardly preserved
number of different topics while properly managing the by the fact that two nodes of the DT are semantically
conversation flow. Please notice that the approach has close to each other by construction. However, to pre-
been already tested in the CARESSES project with serve coherence when deciding if it is needed to jump
more than 20 older people of different nationalities, from one node to another (mechanism 2), proper strate-
for about 18 hours of conversation split into 6 ses- gies should be implemented to avoid the feeling that
sions: both the quantitative and qualitative analysis the system is “going off-topic” with respect to what
performed revealed very positive feedback from the par- the person says: on the one side, the system needs to be
ticipants [6][7]. However, the quantitative analysis per- enough responsive to promptly move to another topic if
formed with care home residents was not explicitly aimed the person wants to; on the other side, the system needs
9
to avoid jumping from one topic to another, overesti-
For instance, https://dialogflow.cloud.google.com/,
mating the desire of the person to talk about something
that in the current implementation also manages small-talk
requests triggered by sentences such as “Hello”, “How are else when he/she would be happier to further explore
you”, or similar). the current topic of conversation.Knowledge-Grounded Dialogue Flow Management for Social Robots and Conversational Agents 11
3.3 Jumping to a different discussion topic
When using the two mechanisms described in the pre-
vious section to navigate the DT, to preserve coher-
ence in the conversation flow the system uses one of
the two following methods: keyword-based topic match-
ing and keyword- and category-based topic matching.
These methods differ in terms of complexity and in
terms of the need to rely on third-party services to an-
alyze the semantic content of sentences.
3.3.1 Keyword-Based Topic Matching
The first, and the simpler, method is exclusively based
on the detection of keywords in the user sentence (key-
words are manually encoded in the Ontology in a corre-
sponding Data Property). To match a topic, at least two
keywords associated with that topic should be detected
in the sentence pronounced by the user, using wildcards
to enable more versatility in keyword matching. The
use of multiple keywords allows the system to differen-
tiate between semantically close topics (i.e., Green Tea
rather than the more general concept of Tea).
Figure 4 shows a possible implementation of the box
Process user sentence with Dialogue Management Fig. 4 Flow chart of the keyword-based topic matching
mechanism 1 or 2 in Figure 3 when using the keyword- method.
based topic matching method:
– If the user’s sentence contains keywords correspond- the keyword-based method, to find the most appropri-
ing to a topic in the Ontology (left part of the di- ate topic to continue the conversation. The algorithm
agram), the algorithm returns a topic of the DT finds the word “interest” matching with the keyword 1
that matches the keywords. In case more matches of the topic HOBBY. Then it should ideally check if the
are found, the algorithm randomly chooses one of sentence contains a word matching with keyword 2 as-
the matching topics. sociated with the same topic: however, in this case, it
– Otherwise: it turns out that no second keyword is needed since a
– If there are still relevant questions to be asked wildcard is used in the topic HOBBY to guarantee that
or assertions to be made about that topic, the one keyword is sufficient. As a result, the algorithm will
system stays on the same topic. return the only matching node of the DT: the system
– Otherwise: will start asking the user about his/her hobbies (which
• If not at the bottom of the DT, the Dialogue does not look very appropriate). The second limitation
Management System keeps on exploring the related to the behaviour of this algorithm arises when
DT along its branches; no keywords are found and we are at the bottom of the
• Otherwise the algorithm returns a random DT: in this case, as already mentioned, the algorithm
topic immediately below the root. has no information to continue the conversation and
This basic approach, despite its simplicity, has been jumps to a random topic close to the root.
successfully exploited during the experimental trial in
care homes, and its capability to provide (almost al- 3.3.2 Keyword- and Category-Based Topic Matching
ways) coherent, knowledge-grounded replies, was con-
firmed in public exhibitions. However, when focusing on The second algorithm is meant to solve the issues of the
coherence, the approach has obvious limitations. Let’s previous algorithm, or at least reduce their frequency,
suppose that the user is having a conversation with the by enabling a more complex understanding of the se-
system and at some point, for some reason, the user mantic content of the sentence. For this purpose, this
says “My bank account has a high interest”. This sen- algorithm not only exploits the keywords, but it also
tence, like any other sentence, is provided as input to takes into account the “category” of the user’s sentence:12 Lucrezia Grassi et al.
rent Ontology, only 122 topics have not been associated
with a category, as none was found to be appropriate.
Hence, the topics mapped to at least a CNL Category11
are 2,348.
Figure 5 shows a possible implementation of the box
Process user sentence with Dialogue Management
mechanism 1 or 2 in Figure 3 when using both key-
words and categories for topic matching. As a first step,
the algorithm checks whether the sentence contains at
least 20 tokens: the Content Classification feature of
CNL does not work if the input does not satisfy this
requirement. If the sentence is not long enough, it is
replicated until it contains at least 20 words. Then it
proceeds as follows:
– If the user’s sentence contains keywords correspond-
ing to a topic in the Ontology and CNL returns at
least a category associated with the sentence (left
part of the diagram), the algorithm selects the topic(s)
in the Ontology with the greatest number of cate-
gories in common: if there is more than one topic, it
picks the closest to the DT root or, if there are mul-
tiple topics at the same level, it chooses randomly;
Fig. 5 Flow chart of the keyword- and category-based topic
– Otherwise, if no keywords match or the sentence
matching method.
does not have any category:
– If there are still relevant questions to be asked
in the current implementation, it uses the third-party or assertions to be made about that topic, the
services provided by Cloud Natural Language (CNL) system stays on the same topic.
API10 , an advanced tool for Sentiment Analysis, En- – Otherwise:
tity Recognition, and Content Classification, among the • If not at the bottom of the DT, the Dialogue
others. Management System keeps on exploring the
To exploit the information related to the category DT along its branches;
of the sentence, the Content Classification of the topics • Otherwise:
contained in the Ontology is a fundamental operation · If there are keywords or CNL categories
and needs to be performed in a setup phase to create associated with the sentence (we already
a mapping between the topics contained in the Ontol- know there are not both), the algorithm
ogy and the CNL category hierarchy. Off-line, before selects the topic(s) with matching key-
the system starts, the classification procedure is per- words or the greatest number of cate-
formed for all the topics: the algorithm puts together gories in common: if multiple, it picks
all the sentences associated with each topic (inserted the one closer to the root in the DT or
into the Ontology by experts and then automatically randomly if they are at the same level.
composed, or added by the users during the conversa- · Otherwise, the algorithm returns a ran-
tion through a mechanism not described in this article dom topic immediately below the root.
[52]), sends them to CNL, and associates the returned
This second method is more complex and compu-
categories to the corresponding topic in the Ontology
tationally expensive than the previous one (and, in the
and then in the DT (notice that, whilst keywords are
current implementation, it requires third-party services),
manually encoded in the Ontology, categories are auto-
but it provides more stability and consistency when se-
matically assigned). On-line, during the conversation,
lecting the next conversation topic. Also, it diminishes
this mapping will allow the system to find which topics
the chances of performing random changes of conver-
of the Ontology match best (i.e., have more categories
sation topic when at the bottom of the DT and no
in common) with the category (if any) of the sentence
keywords are found: if the sentence has at least one
pronounced by the user according to CNL. In the cur-
11
https://cloud.google.com/natural-language/docs/
10
https://cloud.google.com/natural-language?hl=en categoriesKnowledge-Grounded Dialogue Flow Management for Social Robots and Conversational Agents 13
category associated, recognized by CNL, there is still a 2. The system exploiting the keyword and category-
chance of finding a coherent topic to jump to in order based Dialogue Management algorithm;
to continue the conversation. 3. A system that chooses the next topic randomly (i.e.,
regardless of what the user says);
4. A human pretending to be a chatbot (i.e., in a Turing-
4 Materials and Methods test fashion);
5. Replika.
Experimental tests with recruited participants have been
It shall be reminded that the purpose of the exper-
performed for multiple purposes:
iments is to test the impact of the Dialogue Manage-
– Evaluate the impact of different solutions for Dia- ment solutions we proposed, which emphasize the prob-
logue Management we developed, either keyword- lem of switching in-between different topics: Replika is
based or both keyword- and category-based, to im- expected to perform better than systems 1, 2, and 3
prove the subjective perception of the system in in generating individual sentences, and this is true in
terms of coherence and user satisfaction; the case of a human pretending to be a chatbot. Then,
– Compare our solutions with Replika (one of the most the purpose of the comparison is to show that, even
advanced commercial social chatbots) as well as with in presence of a more advanced approach for produc-
baselines consisting of a system choosing replies ran- ing individual sentences, still our solution for Dialogue
domly, and with a human pretending to be a chat- Management may have a significantly positive impact
bot. on user evaluation.
For reasons due to the Covid-19 pandemic, partic-
Among the most famous chatbots mentioned in Sec- ipants could not take the tests with a robot, but they
tion 2.3 we chose to use Replika for our experiment as had to interact with their assigned conversational sys-
it is available as Android12 and IOS application, and tem (1, 2, 3, 4, or 5) using their computer, by establish-
in a web version. Moreover, as already mentioned, it is ing a connection to a remote server in our laboratory. It
backed by Open AI’s sophisticated GPT-213 : a trans- is crucial to mention that the text-based user interface
former machine learning model that uses deep learning was identical for all the systems: therefore, participants
to generate text output that has been claimed to be assigned group 4 were not aware that they were inter-
indistinguishable from that of humans [45]. acting with a human, writing at a terminal, and par-
ticipants assigned to group 5 were not aware that they
were interacting with Replika (with a human manually
4.1 Participants and Test Groups
copying and pasting sentences from Replika to the ter-
minal and vice-versa).
The participants for this test have been recruited through
In total, each session included 20 exchanges (i.e.,
posts on Social Networks (Facebook and Twitter) as
a pair of utterances) between the participant and the
well as in Robotics and Computer Science classes at the
system.
University of Genoa, for a total of 100 volunteer par-
ticipants aged between 25 and 65. The only inclusion
criteria are that participants shall be able to read and 4.2 Questionnaire
write in English and to use a PC with a network con-
nection from home. Since the test is anonymous and no Immediately after the conversation session, participants
personal data is collected, the whole procedure is fully were asked to fill in a questionnaire, divided into two
compliant with the EU General Data Protection Regu- parts.
lation. Each time a new participant is recruited, he/she The first section of the questionnaire required to
is randomly assigned to a group from 1 to 5 (where each evaluate what we defined as the Coherence of system’s
group corresponds to a different conversation system), replies (Section 4.2.1 below), for a total of 20 replies,
and given the instructions to perform the test. Based individually scored, in a 7-point Likert scale, where 1
on the group they were assigned, participants had to means not Coherent and 7 means Coherent. The sec-
interact with: ond part consisted of the SASSI questionnaire (Section
4.2.2).
1. The system exploiting the keyword-based Dialogue
Management algorithm; 4.2.1 Coherence Measure
12
Replika’s Android application has been downloaded more
than 5,000,000 times from the Google Play Store. The instructions provided to each participant clarified
13
https://en.wikipedia.org/wiki/GPT-2 what is meant by “evaluating the Coherence”. The aimYou can also read

















































