Counter-Strike Deathmatch with Large-Scale Behavioural Cloning
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Counter-Strike Deathmatch
with Large-Scale Behavioural Cloning
Tim Pearce1,2 ∗, Jun Zhu1
1
Tsinghua University, 2 University of Cambridge
arXiv:2104.04258v1 [cs.AI] 9 Apr 2021
Abstract
This paper describes an AI agent that plays the popular first-person-shooter (FPS)
video game ‘Counter-Strike; Global Offensive’ (CSGO) from pixel input. The
agent, a deep neural network, matches the performance of the medium difficulty
built-in AI on the deathmatch game mode, whilst adopting a humanlike play style.
Unlike much prior work in games, no API is available for CSGO, so algorithms
must train and run in real-time. This limits the quantity of on-policy data that can
be generated, precluding many reinforcement learning algorithms. Our solution
uses behavioural cloning — training on a large noisy dataset scraped from human
play on online servers (4 million frames, comparable in size to ImageNet), and a
smaller dataset of high-quality expert demonstrations. This scale is an order of
magnitude larger than prior work on imitation learning in FPS games.
Gameplay examples: https://youtu.be/p01vWk7uMvM
Figure 1: Screenshot, agent’s vision and map overview for the deathmatch game mode.
1 Introduction
Deep neural networks have matched human performance in a variety of video games; from 1970’s
Atari classics, to 1990’s first-person-shooter (FPS) titles Doom and Quake III, and modern real-time-
strategy games Dota 2 and Starcraft II [Mnih et al., 2015, Lample and Chaplot, 2017, Jaderberg et al.,
2019, Berner et al., 2019, Vinyals et al., 2019].
Something these games have in common is existence of an API allowing researchers both to interface
with the game easily, and to simulate it at speeds far quicker than real time and/or run it cheaply at
∗
Project started while affiliated with University of Cambridge, now based in Tsinghua University.
Preprint.
scale. This is necessary for today’s deep reinforcement learning (RL) algorithms, which require large
amounts of experience in order to learn effectively – a simple game such as Atari’s Breakout required
38 days of playing experience for vanilla Q-learning to master [Mnih et al., 2015], whilst for one
of the most complex games, Dota 2, an actor-critic algorithm accumulated around 45,000 years of
experience [Berner et al., 2019].
Games without APIs, that can’t be run easily at scale, have received less research attention. This
is unfortunate since in many ways these games bring challenges closer to those in the real world –
without access to large-scale simulations, one is forced to explore more efficient algorithms. In this
paper we take on such a challenge; building an agent for Counter-Strike: Global Offensive (CSGO),
with no access to an API, and only modest compute resources (several GPUs and one game terminal).
Released in 2012, CSGO continues to be one of the world’s most popular games in player numbers
(around 20 million unique players per month2 ) and audience viewing figures34 . The complexity
of CSGO is an order of magnitude higher than the FPS games previously studied – the system
requirements for the CSGO engine (Source) are 100× that of Doom and Quake III engines [Kempka
et al., 2016].
CSGO’s constraints preclude mass-scale on-policy rollouts, and demand an algorithm efficient in both
data and compute, which leads us to consider behavioural cloning. Whilst prior work has explored
this for various games, demonstration data is typically limited to what authors provide themselves
through a station set up to capture screenshots and log key presses. Playing repetitive games at low
resolution means these datasets remain small – from one to five hours (section 5) – producing agents
of limited performance.
Our work takes advantage of CSGO’s popularity to record data from other people’s play – by joining
games as a spectator and scraping screenshots and inferring actions. This allows us to collect a dataset
an order of magnitude larger than in previous FPS works, at 4 million frames or 70 hours, comparable
in size to ImageNet. We train a deep neural network on this large dataset, then fine-tune it on smaller
clean high-quality datasets. This leads to an agent capable of playing an aim training mode just below
the level of a strong human (top 10% of CSGO players), and able to play the deathmatch game mode
to the level of the medium-difficulty built-in AI (the rules-based bots available as part of CSGO).
We are careful to point out that our work is not exclusively focused on creating the highest performing
agent – perfect aim can be achieved through some simple geometry and accessing backend information
about enemy locations (built-in AI uses this) [Wydmuch et al., 2019]. Rather, we intend to produce
something that plays in a humanlike fashion, that is challenging to play against without placing
human opponents at an unfair disadvantage.
Contributions: The paper is useful from several perspectives.
• As a case study in building an RL agent in a setting where noisy demonstration data is
plentiful, but clean expert data and on-policy rollouts are expensive.
• As an approach to building AI for modern games without APIs and only modest compute
resources.
• As evidence of the scalability of large-scale behavioural cloning for FPS games.
• As a milestone toward building an AI capable of playing CSGO.
Organisation: The paper is organised as follows. Section 2 introduces the CSGO environment and
behavioural cloning. The key design choices of the agent are given in section 3, and the datasets and
training process is described in section 4. Related work is listed in section 5. The performance is
evaluated and discussed in section 6. Section 7 concludes and considers future work. Appendix A
contains details on the challenge of interfacing with game, appendix B provides game settings used.
2 Background
This section introduces the CSGO environment, and briefly outlines technical details of behavioural
cloning.
2
https://www.statista.com/statistics/808922/csgo-users-number/
3
https://www.statista.com/statistics/1125460/leading-esports-games-hours-watched/
4
https://twitchtracker.com/games
2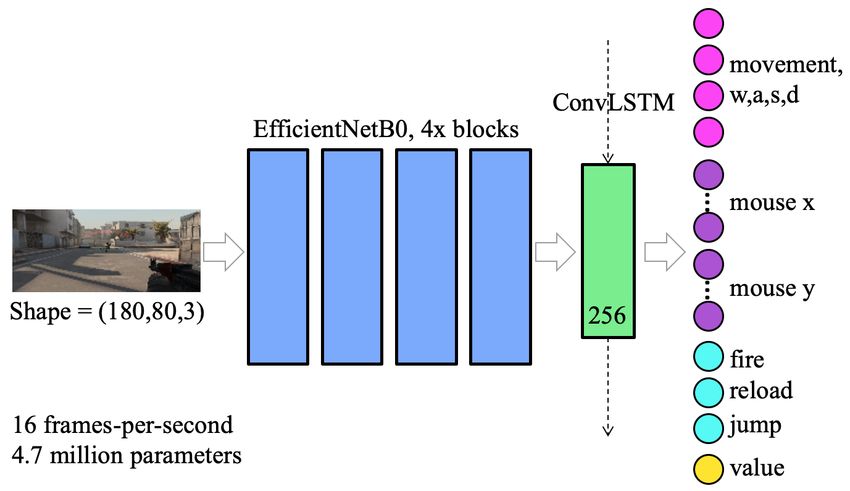
2.1 CSGO Environment
CSGO is played from a first person perspective, with mechanics and controls that are standard across
FPS games – the keyboard is used to move the player left/right/forward/backwards, while mouse
movement turns the player horizontally and vertically, serving both to look around and aim weapons.
In CSGO’s full ‘competitive mode’, two teams of five players win either by eliminating the opposing
team, or completing an assigned objective. Success requires mastery of behaviour at three time
horizons; In the short term an agent must control its aim and movement, reacting to enemies. Over
medium term horizons the agent must navigate through map regions, manage its ammunition and
react to its health level. In the long term an agent should manage its economy, plan strategies, adapt
to opponents’ strengths and weaknesses and cooperate with teammates.
As one of the first attempts to play CSGO from pixel input, we do not consider the full competitive
mode. Instead we focus on two simpler modes, summarised in table 1 (full settings in appendix B).
Screenshots for each mode can be found in figures 1 (deathmatch) & 2 (aim training).
‘Aim training mode’5 provides a controlled environment for human players to improve their reactions,
aim and recoil control. The player stands fixed in the centre of a visually uncluttered map, while
unarmed enemies run toward them. It is not possible to die, and ammunition is unlimited. This
constitutes the simplest environment we consider.
‘Deathmatch mode’ rewards players for killing any enemy on the opposing team (two teams,
‘terrorists’ and ‘counter-terrorists’). After dying a player regenerates at a random location. Whilst it
does not require the long-term strategies of competitive mode, most other elements are intact. It is
played on the same maps, with the full variety of weapons available, ammunition must be managed,
and the agent should distinguish between teammates and enemies.
We further consider three settings of deathmatch mode, all on the ‘de_dust2’ map, with the agent on
the terrorist team, with the ‘AK-47’ equipped. 1) Easy – with built-in AI bots, on easy mode, with
pistols, reloading not required, 12 vs 12. 2) Medium – with built-in AI bots, on medium difficulty,
all weapons, reloading required, 12 vs 12. 3) Human – with human players, all weapons, reloading
required, 10 vs 10.
Table 1: CSGO game modes and the behaviour horizon required for success in each.
Short-term Medium-term Long-term
Game mode Reactive & control Navigation & ammo Strategy & cooperation
Aim training 3 7 7
Deathmatch 3 3 7
Competitive 3 3 3
2.2 Behavioural Cloning
In behavioural cloning (also ‘imitation learning’) an agent aims to mimic the action a demonstrator
(typically an ‘expert’) would take given some observed state. Learning is based on a dataset of the
expert’s logged behaviour, consisting of observations, o ∈ O, paired with the actions taken, a ∈ A.
For N such pairs the dataset is, D = {{o1 , a1 } . . . {oN , aN }}.
An agent is represented by a policy that takes as input an observation and outputs a probability
distribution over actions. For a policy parameterised by θ the action is typically selected either via,
â ∼ πθ (a|o), or, â = argmaxa πθ (a|o).
Behavioural cloning reduces learning a sequential decision making process to a supervised learning
problem. Given some loss function, l : A × A → R, that measures the distance between predicted
and demonstrated actions, a model is asked to optimise,
N
X
θ = argminθ l (ai , âi ) ,
i
5
Fast aim / reflex training workshop map: https://steamcommunity.com/sharedfiles/
filedetails/?id=368026786
3where, l, might typically be cross-entropy or mean squared error.
Behavioural cloning can be a highly efficient method for learning [Bakker and Kuniyoshi, 1993],
since an agent is told exactly how to behave, removing the challenge of exploration – in reward-based
learning an agent should experiment via trial-and-error to learn effective strategies by itself.
One drawback is that the learnt policy can only perform as well as the demonstrator (and in practise
may be worse since it is only an approximation of it). A second is that often only a small portion of
the state space will have been visited in the demonstration dataset, but due to compounding errors,
the agent may find itself far outside of this – i.e. there is a distribution mismatch during test time,
pD (o) 6= pπθ (o).
3 Agent Design
This section provides details and justification of the major design decisions for the agent.
3.1 Observation Space
CSGO is typically run at a resolution of around 1920×1080, which is far larger than most GPUs
can process at a reasonable frame rate, meaning downsampling was required. The gives rise to
a difficult trade-off between image fidelity, size of neural network, frames-per-second, GPU spec
requirements, training dataset size and training time. Additionally, rather than using the whole screen,
a central portion can be cropped, which provides higher resolution for the important region around
the crosshair but at the cost of narrowing the field of view.
For this work, following some experimentation and domain knowledge, the game is run at a resolution
of 1024×768 resolution, and the agent crops a central region of 584×488, then downsamples it to
180×80 – see figure 2. This allows state-of-the-art network architectures to be run at 16 frames-per-
second on an average gaming GPU. Whilst the cropping reduces the agent’s field-of-view and the
downsampling compromises its ability in longer-range firefights, these choices allows us to collect
and train on a larger demonstration dataset than would otherwise be possible (noting a 2× increase in
pixel resolution in both dimensions leads to a 4× increase in dataset size).
Figure 2: Screen processing involves cropping and downsampling. Aim training map shown.
Auxillary Information
The cropped pixel region excludes the radar map, kill feed, and also information about health, ammo,
and time remaining. It usefully excludes several visual artefacts which appear in spectator mode (but
not when actively playing).
We experimented with providing some of this auxiliary information in vector form later in the
network, but recurrent connections appeared able to capture some of this anyway. We leave further
experimentation to future work.
4Table 2: CSGO action space, and the agent’s output space.
Action Meaning Output by agent? Output activation
w,a,s,d forward, backward, left, right 3 sigmoid
space jump 3 sigmoid
r reload 3 sigmoid
ctrl crouch 7 –
shift walk 7 –
1,2,3,4 weapon switch 7 –
left click fire 3 sigmoid
right click zoom 7 –
mouse x & y aim 3 2×softmax
value value estimate 3 linear
3.2 Action Space
Table 2 summarises the action space in CSGO, and what the agent outputs – only those actions
we deemed essential for playing to a reasonable level were included. Success in CSGO’s firefights
depends on fast and precise mouse movement (aiming) as well as coordination with the player
movement (weapon accuracy reduces when moving). This creates two main challenges; 1) CSGO’s
output space mixes discrete (e.g. movement keys) and continuous (mouse movement) actions, with
mouse control being of high importance. 2) The actions are not mutually exclusive (e.g. one might
reload, jump and move left simultaneously).
Mouse movement can be summarised by changes in x & y coordinates. We trialled treating these
as continuous targets, optimised via mean squared error, but this led to undesirable behaviour (e.g.
given the choice of two enemies or pathways, the agent would output a point midway between the
two, which minimised mean squared error!). A naive approach of discretising the mouse space and
treating it as a classification problem was more successful. The discretisation itself required tuning
and experimentation, since a larger output space allows a higher level of control but requires more
data to train. Since it’s more important for a player to be able to make fine adjusments when aiming,
but if turning large angle, the exact values mattered less, we used an unevenly discretised grid, finer
in the middle, and coarser at the edges, for a total of 19 options on both x and y axes, i.e. mouse x,
mouse y ∈ {−300, −200, −100, −60, −30, −20, −10, −5, −3, −1, 0, 1, 3..., 300}.
To address the mutually exclusive nature of the action space, we used independent (binary) cross
entropy losses for keys and clicks, and two further (multinomial) cross entropy losses for each mouse
axis.
We further trained an estimate of the value function with the view to improving the agent via rewards
in future work,
vt = rt + γvt+1 ,
rt = 1.0Kt − 0.5Dt − 0.02Ft ,
where, Kt , Dt , Ft ∈ {0, 1}, are all binary variable representing if there was a kill Kt , death Dt , or a
shot fired Ft , and discount rate γ = 0.995.
3.3 Network Architecture
The agent’s architecture is summarised in figure 3. Many popular neural network architectures
designed for image classification make heavy use of average or max pooling, which causes loss of
spatial information. For our application, the location of objects within an image is of high importance
– knowing that an enemy exists somewhere in the input is not enough, the agent must also know
its location to take action. Our agent used an EfficientNetB0 at its core, initialised with weights
pre-trained on ImageNet, but with only the first four residual blocks – for an input of 180×80, this
outputs a dimension of 12×5.
An agent receiving a single frame as input would be unable to estimate the movement of itself and
other players. We initially used a stacked input approach to overcome this, where the previous n
frames are jointly fed into the NN. Whilst successful in the simpler aim training mode, this approach
5failed in deathmatch mode, with the agent often getting stuck in doors or corners, and forgetting
about enemies midway through firefights. The final agent used a convolutional LSTM layer [Shi et al.,
2015] after the EfficientNetB0, which seemed to fix both these problems. A linear layer connects the
convolutional LSTM to the output layer.
Figure 3: Overview of the NN architecture.
3.4 Running at Test Time
There are several decisions to be made in how to run the agent at test time. The agent parametrises a
probability distribution for key presses, mouse clicks, and mouse movements. Actions can either be
selected probabilisitically â ∼ πθ (a|o), or according to the highest probability, â = argmaxa πθ (a|o).
Following experimentation, we found that predictions for certain actions – reload, jump, fire – rarely
exceeded the 0.5 threshold so were seldom selected the by the argmax policy, so the agent selects
these probabilistically. Meanwhile, selecting movement keys and mouse movement probabilisitically
produced jerky, unnatural movement, so these are selected via argmax. (Though if the agent is
immobile for more than three seconds, it reverts to probabilistic selection for all actions.)
Since the agent only outputs actions 16 times a second, mouse movement can appear very jerky, and
we artificially increase this to 32 times a second by halving the mouse input magnitude and applying
twice with a short delay. We automate ‘resetting of decals’ (e.g. remove bullet holes) every five
seconds to reduce visual clutter, as was also done during data collection.
4 Demonstration Data & Training
This section describes collection and processing of the demonstration datasets, summarised in table 3,
as well as details of the training process.
Table 3: Summary of the three datasets used in agent training.
Dataset Frames Hours GB Source
Large-scale deathmatch 4,000,000 70 200 Scraped from online servers
HQ aim train 40,000 0.67 6 Purposefully created expert demonstrations
HQ deathmatch 180,000 3 10 Purposefully created expert demonstrations
64.1 Large-Scale Scraped Demonstrations
One of the challenges of using behavioural cloning in video games is that it’s impractical to manually
record a large demonstration dataset – playing at low resolution on repetitive game modes for more
than a few hours is as much as most researchers’ patience allows. This results in small datasets and
limited performance for many systems (section 5).
Prior work in Starcraft II showed that reasonable performance can be achieved through behavioural
cloning, provided one has access to a dataset of sufficient size [Vinyals et al., 2019]. Whilst Vinyals
et al. worked alongside the game developer Blizzard, being granted access to a large dataset of logged
gameplay, for many games and related real-world problems such access is not possible. We did not
have such privileges – our solution instead scraped data from online servers by joining in spectator
mode, and running a script both to capture screenshots and metadata at a rate of 16 frames-per-second
(see appendix A for interfacing details).
4.1.1 Action Inference
Whilst the screen processing was relatively straightforward (figure 2), the metadata we were able to
scrape (appendix A) does not explicitly contain the actions that were applied by the player. Instead,
it contains information about the player state (e.g. weapon selected, available ammunition, health,
number of kills and deaths), position on map (x, y, z coordinates) and orientation (roll and yaw).
This produces a challenging inverse problem; starting from this metadata, infer the actions taken. For
this we wrote a rules-based algorithm. Some actions were straightforward to infer, such as firing
(detected if ammunition decreased). Others were fundamentally ill-posed and required much testing
and tuning. Most challenging was inferring presses of the movement keys (w, s, a, d) moving a
player forward/backwards/left/right – there can be many reasons for a change in velocity aside from
key pushes, such as weapon switching (heavy weapons makes players move slowly), crouching or
walking, bumping into objects, or taking damage. Further complicating matters, we observed subtle
and inconsistent time lags between an action’s application, its manifestation in the metadata, and
observing the change on screen.
We tuned the rules-based algorithm until it was able to infer actions in most scenarios we tested. We
proceeded aware that it would not cover all edge cases and the dataset would contain noisy labels.
This was one reason for using an action space containing only essential actions (table 2).
4.1.2 Scraping via Spectating
The skill level of the demonstration data places an upper limit on the skill level of agent (section
2). As such, it’s desirable to collect data from strong players. Since we were scraping data in an
automated, anonymous manner, this created further challenges. We spectated deathmatches hosted
on official Valve servers, which uses a ranking system to match players to a game of appropriate
skill and ‘trust’ level. By consistently joining in spectator mode, the account we used ended up in
a pool of lower skill rating, and sometimes with a small number of players appearing to cheat. To
overcome these issues, our script tracked the current best performing player in the server, and filtered
out periods of player immobility and suspicious behaviour suggesting cheating. During training we
also oversampled sequences containing successful kill events.
Although developing the scraping script was laborious, the value is in its scalability – once written it
could be left to autonomously scrape gameplay continuously for days at a time, generating a quantity
and variety of data that could not be provided manually. Figure 4 provides some example screenshot
sequences from this data containing kill and death events.
4.2 High-Quality Expert Demonstrations
The second type of dataset used was created with the explicit intention of training the agent, and used
a machine specially set up to precisely log actions and take screenshots. We created two ‘high-quality’
datasets, one for the aim training mode, and one for the deathmatch mode. We used a strong human
player to provide the data (top 10% of CSGO players, DMG rank). The high-quality deathmatch
dataset contained a mixture of gameplay from all three deathmatch settings (easy, medium, human).
There were several advantages to these datasets:
7Figure 4: Example image sequences from the training data.
1. Whilst the large-scale dataset contained noisy labels, directly recording the gameplay allows
clean labelling of the actions implemented.
2. There are several small differences in the visuals rendered by the game when watching
players in spectator mode, compared to actively playing the game, e.g. red damage bar
indicators are not displayed in the former.
3. The large-scale dataset contains gameplay of players using all weapons and on both teams.
By generating our own data we could generate data exclusively for the environment we
tested – terrorist team with AK-47 equipped.
4.3 Training Details
Our agent was initially trained on the full large-scale deathmatch dataset. Beginning from this
checkpoint, two versions of the agent were then created by further training (fine-tuning) on each of
the two high-quality datasets (one for the aim training mode, one for the deathmatch mode).
We found losses on a validation set were unreliable indicators of agent performance. To determine
when to stop training, we evaluated the agent after each epoch, measuring kills-per-minute (easy
setting for the deathmatch agent and aim training map for aim agent).
Since the large-scale dataset contained gameplay of mixed quality, after training for 15 epochs on the
full dataset (≈6 hours wall time per epoch on a single GPU), we filtered for segments that contained
successful kill events, and undersampled all other segments during subsequent training (with 20%
chance of selection), continuing training for a further 12 epochs. The fine-tuning phase proceeded for
828 epochs (deathmatch agent) and 44 epochs (aim training agent). Total combined training time for
all agents was around 8 days.
Since our network used an LSTM, we faced a trade-off between segment length (number of timesteps)
and batch size. During initial training stages, we used a segment length of 16 frames (1 second) and
batchsize of 8, extending this to 64 frames (4 seconds) and batchsize of 2.
We applied data augmentation on the image brightness and contrast, but avoided applying augmenta-
tions affecting spatial properties of the image, since this would invalidate the mouse labels.
5 Related Work
This section details relevant areas of academic work, and points out how our own work is novel in
comparison.
FPS games: FPS games have been proposed as useful environments for RL research, some being
packaged in convenient APIs. Beattie et al. [2016] released DeepMind Lab, built on the Quake 3
engine (originally 1999), and Kempka et al. [2016] introduced VizDoom, packaging several simple
game modes on top of the Doom engine (originally 1993). These environments are rather basic in
comparison to CSGO (originally 2012) – these 1990’s FPS games were designed to be played at low
resolutions, and VizDoom provides a low dimensional mouse action space. As a concrete comparison,
VizDoom allows simulation at 7000 frames-per-second on a single CPU [Wydmuch et al., 2019],
whilst CSGO runs at around 200 frames-per-second on a modern GPU.
The VizDoom and DeepMind Lab environments have inspired much follow up research. Notably, in
the latter environment, Jaderberg et al. [2019] considered a capture the flag mode, and trained agents
able to outperform teams of humans familiar with FPS games – they used an actor-critic algorithm
also trained on auxiliary tasks. The agent received an input of resolution 84x84 pixels, with a mouse
output space of 5x3 (5 options for mouse x and 3 for mouse y), run at 15 frames-per-second, and
learnt over 2 billion frames. Tournament-style contests have been hosted on a deathmatch mode
of VizDoom [Wydmuch et al., 2019], with the strongest agents using either actor-critic methods
or Q-learning, and often using separate modules for movement and firing. Their performance was
below human level. One simple way to improve performance of FPS agents is to add auxiliary tasks
predicting game feature information (e.g. presence and location of enemies) in parallel to learning a
policy [Lample and Chaplot, 2017]. Improvements in decision making at longer time horizons has
been investigated through hierarchical approaches and cleverly compressing the action space [Song
et al., 2019, Huang et al., 2019].
There are two main differences between this prior FPS work and our own; 1) We consider a modern
FPS game bringing several new challenges (no API, better graphics, larger action space). 2) We focus
on a behavioural cloning approach.
Imitation learning for video games: Various authors have experimented building agents for games
using imitation learning. We summarise some of this work in table 4. Typically the datasets are
created by the authors themselves, which results in rather small datasets (1-5 hours), and limited
agent performance. A common approach is to use a policy trained on behavioural cloning as a warm
start for other RL algorithms.
To our knowledge the largest behavioural cloning efforts in games to date are in Go (30 million
frames) [Silver et al., 2016], and Starcraft II (971,000 replays) [Vinyals et al., 2019]. Whilst the
number of frames used in each is larger than in our work, neither of these games operated directly
from pixels, making storage and training far easier than our case, and not directly comparable. As
Berner et al. [2019] observe for Dota 2 (their comments also apply to Starcraft II): "it is infeasible
for us to render each frame to pixels in all training games; this would multiply the computation
resources required for the project many-fold". We also note that Vinyals et al. had convenient access
to demonstration data, while we had to source ours manually.
Several observations made in these papers are of interest. By using only behavioural cloning Vinyals
et al.’s agent acheived a rank in the top 16% of human players, showing behavioural cloning on a large
enough scale can create strong agents. Wang et al. [2020] conducted ablations of this work, finding
similar performance could be achieved using just 5,000-20,000 of the highest quality replays. Adding
a final fine-tuning step on the strongest sub-set of the data could boost performance – something
9Table 4: Comparison of selected prior work using imitation learning in games.
Author Game FPS? Dataset size From pixels? NN architecture
[Harmer et al., 2018] In-house game 3 45 minutes 3 4-layer CNN+LSTM
[Gorman and Humphrys, 2007] Quake 2 3 60 minutes 7 2-layer MLP
[Kanervisto et al., 2020] Various incl. Doom 3 45 minutes 3 2-layer CNN
[Chen and Yi, 2017] Super Mario Smash Bros 7 5 hours 3 5-layer CNN+2-layer MLP
[Hester et al., 2018] Atari 7 60 minutes 3 2-layer CNN+FC
[Bukaty and Kanne, 2020] NecroDancer 7 100 minutes 3 ResNet34
[Vinyals et al., 2019] Starcraft II 7 4,000 hours 7 Mixed incl. ResNet, LSTM
[Silver et al., 2016] Go 7 30 million frames 7 Deep residual CNN
Our work CSGO 3 70 hours 3 EfficientNetB0+ConvLSTM
confirmed in our own work. Kanervisto et al. [2020] found that combining data from different
demonstrators can sometimes perform worse than training on only the strongest demonstrator’s data.
To summarise, our work represents the largest-scale behavioural cloning effort to date in any FPS
game, in any game without an API, and in any work directly learning from pixels.
Counter-Strike specific work: Despite its popularity, relatively little academic research effort has
been applied to the Counter-Strike franchise, likely due to there being no API to conveniently interface
with the game. Relevant machine learning works include predicting enemy player positions using
Markov models [Hladky and Bulitko, 2008], and predicting the winner of match ups [Makarov et al.,
2018]. Other academic fields have studied the game and culture from various societal perspectives,
e.g. [Reer and Krämer, 2014, Hardenstein, 2006]. Ours is the first academic work to build an AI from
pixels for CSGO.
Imitation learning challenges: There has been an increasing awareness that leveraging existing
datasets for tasks typically tackled through pure RL promises improved efficiency and will be valuable
in many real-world situations – a field labelled as offline RL [Levine et al., 2020, Fu et al., 2020], of
which behavioural cloning is one approach.
Behavioural cloning systems can lead to several common issues, and recent research has aimed to
address these – e.g. agents may learn based on correlations rather than causal relationships [de Haan
et al., 2019], and accumulating errors can cause agents to stray from the input space for which expert
data was collected [Ross et al., 2011, Laskey et al., 2017]. One popular solution is to use a cloned
policy as a starting point for other RL algorithms [Bakker and Kuniyoshi, 1993, Schaal, 1996], with
the hope that one benefits from the fast learning of behavioural cloning in the early stages, but without
the performance ceiling or distribution mismatch.
6 Evaluation
This section measures the performance of the agent, and qualitatively discusses its behaviour. Game-
play examples are shared at: https://youtu.be/p01vWk7uMvM. Code to run the agent and its
network weights are provided at: https://github.com/TeaPearce. Appendix B details the game
settings used.
Two metrics are commonly reported for FPS agents. Kill/death ratio (K/D) is the number of times a
player kills an enemy compared to how many times they die. Whilst useful as one measure of an
agent’s performance, more information is needed – avoiding all but the most favourable firefights
would score a high K/D ratio, but may be undesirable. We therefore also report kills-per-minute
(KPM). A strong agent should have both a high KPM and high K/D.
6.1 Agents & Baselines
We test three versions of the agent as described in section 4. 1) Large-scale dm refers to an agent
trained on the scraped large-scale dataset only. 2) Large-scale dm + HQ aim refers to the large-scale
dm agent being further fine-tuned on the high-quality aim train dataset. 3) Large-scale dm + HQ
dm refers to the large-scale dm agent being further fine-tuned on the high-quality deathmatch dataset.
To measure the agent’s performance, for each mode and setting the agent plays three sessions of
20 minutes (vs built-in AI) or 10 minutes (vs humans), and we report mean and one standard error.
10Table 5: Main results. Metrics are kills-per-minute (KPM) and kills/death ratio (K/D). Higher is
better for both. Mean ± 1 standard error over three runs.
————————————— Deathmatch —————————————
Aim Train —– Easy —– —– Medium —– —– Human —–
KPM KPM K/D KPM K/D KPM K/D
Dataset used
Large-scale dm 1.05 ± 0.22 2.89 ± 0.28 1.65 ± 0.15 1.89 ± 0.20 0.75 ± 0.12 0.39 ± 0.08 0.16 ± 0.03
Large-scale dm + HQ aim 26.25 ± 0.7 – – – – – –
Large-scale dm + HQ dm – 3.26 ± 0.12 1.95 ± 0.13 2.67 ± 0.14 1.25 ± 0.09 0.50 ± 0.11 0.26 ± 0.08
Baselines
Built-in AI (easy) – 2.11 1.00 – – – –
Built-in AI (medium) – – – 1.97 1.00 – –
Human (strong) 33.21 14.00 11.67 7.80 4.33 4.27 2.34
For the human matches, opponent skill can vary between servers, so we reconnect to a new server
between each session.
We consider three baselines. 1) Built-in AI (easy) – the bots played against in the deathmatch easy
setting (section 2). 2) Built-in AI (medium) – the bots played against in the deathmatch medium
setting (section 2). 3) Human (Strong) – a player ranked in the top 10% of regular CSGO players
(DMG rank) playing on full 1920×1080 resolution.
For the built-in AI baselines, we report mean KPM from the games the agent was tested in, whilst
K/D is defaulted to 1.00 (since they predominately play against each other). For the human baseline,
we report metrics from 5 minutes (aim train mode) and 10 minutes (deathmatch modes) of play.
Longer periods resulted in fatigue of the human player and decreased performance.
6.2 Results
Table 5 displays results for all agents and baselines, discussed below.
Aim train mode:6 The large-scale dm + HQ aim agent performs only slightly below the strong
human baseline, with the gap much narrower than in the deathmatch game mode. This strong
performance is likely due to aim train mode requiring behaviour over only short time horizons (table
1). Also, in this visually simple environment, the downsampling does not seem to harm the agent’s
ability to detect enemies. The agent shows a good degree of aim accuracy and recoil control. It
prioritises enemy targets in a sensible manner, and is able to anticipate their motion.
The large-scale dm agent had never seen the aim train map before, and in fact its low KPM is
misleading – this agent had a tendency to get distracted by a ledge close to the floor (bottom of figure
2) and focus its aim on this. For the time it was not doing this, its KPM was around 6. Aside from
this confusion, we were encouraged that the agent showed some generalisation ability in this new
environment, able to track and fire at enemies in a proficient fashion.
Deathmatch mode: The best performing agent, large-scale dm + HQ dm, outperforms the built-in
AI both on easy and medium settings, though falls short of human performance (dying four times for
each successful kill). Fine-tuning on the HQ dm dataset is helpful, though this has less of an impact
than for the aim train mode – this is expected since both datasets are from the deathmatch mode.
In general the agent is able to navigate around the map well, steering through tricky doors layouts,
and only occasionally getting stuck (perhaps once every 3-4 minutes). It reacts to enemies at near
and medium distances well, and is able to distinguish teammates from enemies.
We believe there are two main reasons for the performance gap between agent and strong human.
Firstly, downsampling the image makes enemies difficult to pick out if they are not close – the
agent loses most long-range firefights. Secondly, the agent’s decision making at a medium term time
horizon can be poor – it often enters one area, looks around, goes through a door to a second area,
pauses, then returns to check the first area again, and repeats this several times. A human player
would know that once a room is cleared, it is more likely to find enemies in a new area of the map.
We believe this behaviour arises from training the LSTM over sequences of just four seconds.
6
Note that K/D is not applicable to this mode since the agent is unable to die.
11There are environmental quirks that also contribute to the performance gap – in easy mode, ammuni-
tion is unlimited, and the strong human abused the ability to spray without reloading. However, the
agent is trained on data that always required reloading, so has no notion of infinite ammunition.
6.3 Qualitative Analysis
From a player perspective, just as important as an AI performing competitively, is that it ‘feels
humanlike’ – it is no fun playing against players using cheats giving perfect aim, despite their strong
performance. Measurement of this humanlike quality is less straightforward, and we discuss several
interesting behaviour traits we observed during testing.
Humanlike traits: Mechanically, the agent’s aim and movement are remarkably similar to that of
a human. When a human player turns a large angle in game, there is a pause in motion when the
mouse reaches the end of the mouse pad, and it must be picked up before the turn can continue. When
moving the crosshair toward an enemy, there is a tendency to move quickly to their general location,
then more slowly to aim at their exact location. The agent encodes both these behaviours. It has a
reaction time and shooting accuracy that seem consistent with human players.
Whilst the built-in AI navigates along predictable routes and has predictable reactions to enemies and
teammates, the agent operates in a much more varied manner. The agent runs along ledges and jumps
over obstacles. At times it will jump to get a glimpse of an area it couldn’t otherwise see. Its playing
style contains several other humanlike quirks, such as firing at chickens, or jumping and spinning
when reloading and under fire.
Non-humanlike traits: In addition to the weaknesses previously discussed (poor at long range fights,
repeatedly checking two areas), we found the agent poor at reacting to enemies in unusual positions –
this is more detrimental in the deathmatch human setting, since humans take up more varied positions
than the built-in AI. The agent’s ammunition management is also poor – it only reloads appropriately
following firefights perhaps one in four times. Finally, the agent sometimes begins a fight, then strafes
behind a wall for cover, but then apparently forgets the enemy was ever there and walks off in the
opposite direction.
There are several other more understandable limitations. The agent receives only the image as input,
so receives no audio clues that humans typically use (such as shots being fired, or footsteps of an
enemy around a corner). It also doesn’t often react to red damage bar indicators, since these are not
displayed in spectator mode which forms the majority of its training data. The screen cropping also
means that an enemy can pass by in the edge or top of the screen, but the agent is oblivious to it.
7 Discussion & Conclusion
This paper presented an AI agent that plays the video game CSGO from pixels, outperforming the
game’s rules-based bot on the medium difficulty setting. It is one of the largest scale works in
behavioural cloning for games to date, and one of the first to tackle a modern video game that does
not have an API.
Whilst the AI community has historically focused on real-time-strategy games such as Starcraft
and Dota 2, we see CSGO as an equally worthy test bed, providing its own unique mix of control,
navigation, teamwork, and strategy. Its large and long-lasting player base, as well as similarity to
other FPS titles, means AI progress in CSGO is likely to attract broad interest, and also suggests
tangible value in developing strong, humanlike agents.
Although it is an inconvenience to researchers, CSGO’s lack of API arguably creates a challenge more
representative of those in the real-world, where RL algorithms can’t always be run from a blank state.
As such, CSGO lends itself to offline RL research. This paper has defined several game modes of
varying difficulties, and had a first attempt at solving them with behavioural cloning. We have future
plans to release parts of our code to encourage other researchers to partake in this environment’s
challenges.
There are many directions in which our research might be extended. This paper presents ongoing
work, and we are actively exploring several of these. On the one hand, further scaling up and refining
our current approach is likely to bring improved performance, as is using other methods from offline
RL. On the other hand, there’s the possibility of integration with reward-based learning, or including
12other parts of the environment as input. More ambitiously, there’s the challenge of developing an
agent to take on CSGO’s full competitive mode – we see our paper as a step toward that AI milestone.
References
Paul Bakker and Yasuo Kuniyoshi. Robot See, Robot Do : An Overview of Robot Imitation. AISB
workshop on learning in robots and animals, (May 1996), 1993.
Charles Beattie, Joel Z Leibo, Denis Teplyashin, Tom Ward, Marcus Wainwright, Andrew Lefrancq,
Simon Green, Amir Sadik, Julian Schrittwieser, Keith Anderson, Sarah York, Max Cant, Adam
Cain, Adrian Bolton, Stephen Gaffney, Helen King, Demis Hassabis, Shane Legg, and Stig Petersen.
DeepMind Lab. pages 1–11, 2016.
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Psyho Dȩbiak, Christy
Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, Rafal Józefowicz, Scott Gray,
Catherine Olsson, Jakub Pachocki, Michael Petrov, Henrique Pondé De Oliveira Pinto, Jonathan
Raiman, Tim Salimans, Jeremy Schlatter, Jonas Schneider, Szymon Sidor, Ilya Sutskever, Jie Tang,
Filip Wolski, and Susan Zhang. Dota 2 with large scale deep reinforcement learning. arXiv, 2019.
ISSN 23318422.
Buck Bukaty and Dillon Kanne. Using Human Gameplay to Augment Reinforcement Learning
Models for Crypt of the NecroDancer. ArXiv, 2020.
Zhao Chen and Darvin Yi. The game imitation: Deep supervised convolutional networks for quick
video game AI. arXiv, 2017. ISSN 23318422.
Pim de Haan, Dinesh Jayaraman, and Sergey Levine. Causal confusion in imitation learning. NeurIPS,
2019. ISSN 23318422.
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. Datasets for Data-Driven
Reinforcement Learning. pages 1–13, 2020. URL http://arxiv.org/abs/2004.07219.
Bernard Gorman and Mark Humphrys. Imitative learning of combat behaviours in first-person
computer games. Proceedings of CGAMES 2007 - 10th International Conference on Computer
Games: AI, Animation, Mobile, Educational and Serious Games, pages 85–90, 2007.
Taylor Stanton Hardenstein. “Skins” in the Game: Counter-Strike, Esports, and the Shady World of
Online Gambling. World, 419(2015):117–137, 2006.
Jack Harmer, Linus Gisslén, Jorge del Val, Henrik Holst, Joakim Bergdahl, Tom Olsson, Kristoffer
Sjöö, and Magnus Nordin. Imitation learning with concurrent actions in 3d games. arXiv, pages
1–8, 2018. ISSN 23318422.
Todd Hester, Tom Schaul, Andrew Sendonaris, Matej Vecerik, Bilal Piot, Ian Osband, Olivier Pietquin,
Dan Horgan, Gabriel Dulac-Arnold, Marc Lanctot, John Quan, John Agapiou, Joel Z. Leibo, and
Audrunas Gruslys. Deep q-learning from demonstrations. 32nd AAAI Conference on Artificial
Intelligence, AAAI 2018, pages 3223–3230, 2018.
Stephen Hladky and Vadim Bulitko. An evaluation of models for predicting opponent positions
in first-person shooter video games. 2008 IEEE Symposium on Computational Intelligence and
Games, CIG 2008, pages 39–46, 2008. doi: 10.1109/CIG.2008.5035619.
Shiyu Huang, Hang Su, Jun Zhu, and Ting Chen. Combo-Action : Training Agent For FPS Game
with Auxiliary Tasks. The Thirty-Third {AAAI} Conference on Artificial Intelligence, {AAAI}
2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, {IAAI} 2019,
The Ninth {AAAI} Symposium on Educational Advances in Artificial Intelligence, {EAAI}, pages
954–961, 2019. doi: 10.1609/aaai.v33i01.3301954. URL https://doi.org/10.1609/aaai.
v33i01.3301954.
Max Jaderberg, Wojciech M Czarnecki, Iain Dunning, Luke Marris, Guy Lever, Antonio Garcia Cas-
tañeda, Charles Beattie, Neil C Rabinowitz, Ari S Morcos, Avraham Ruderman, Nicolas Sonnerat,
Tim Green, Louise Deason, and Joel Z Leibo. Human-level performance in 3D multiplayer games
with population- based reinforcement learning. Science, 2019.
13Anssi Kanervisto, Joonas Pussinen, and Ville Hautamaki. Benchmarking End-to-End Behavioural
Cloning on Video Games. IEEE Conference on Computatonal Intelligence and Games, CIG,
2020-Augus:558–565, 2020. ISSN 23254289. doi: 10.1109/CoG47356.2020.9231600.
Michal Kempka, Marek Wydmuch, Grzegorz Runc, Jakub Toczek, and Wojciech Jaskowski.
ViZDoom: A Doom-based AI research platform for visual reinforcement learning. IEEE
Conference on Computatonal Intelligence and Games, CIG, 2016. ISSN 23254289. doi:
10.1109/CIG.2016.7860433.
Guillaume Lample and Devendra Singh Chaplot. Playing FPS Games with Deep Reinforcement
Learning. AAAI, 2017. doi: arXiv:1609.05521v2. URL http://arxiv.org/abs/1609.05521.
Michael Laskey, Jonathan Lee, Wesley Hsieh, Richard Liaw, Jeffrey Mahler, Roy Fox, and Ken
Goldberg. Iterative Noise Injection for Scalable Imitation Learning. ArXiv preprint, (CoRL):1–14,
2017. URL http://arxiv.org/abs/1703.09327.
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial,
review, and perspectives on open problems. arXiv, 2020. ISSN 23318422.
Ilya Makarov, Dmitry Savostyanov, Boris Litvyakov, and Dmitry I. Ignatov. Predicting winning
team and probabilistic ratings in “Dota 2” and “Counter-strike: Global offensive” video games.
Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence
and Lecture Notes in Bioinformatics), 10716 LNCS(January):183–196, 2018. ISSN 16113349.
doi: 10.1007/978-3-319-73013-4_17.
Volodymyr Mnih, Ioannis Antonoglou, Andreas K. Fidjeland, Daan Wierstra, Helen King, Marc G.
Bellemare, Shane Legg, Stig Petersen, Martin Riedmiller, Charles Beattie, Alex Graves, Amir
Sadik, Koray Kavukcuoglu, Georg Ostrovski, Joel Veness, Andrei A. Rusu, David Silver, Demis
Hassabis, and Dharshan Kumaran. Human-level control through deep reinforcement learning.
Nature, 518(7540):529–533, 2015. ISSN 0028-0836. doi: 10.1038/nature14236. URL http:
//dx.doi.org/10.1038/nature14236.
Felix Reer and Nicole C. Krämer. Underlying factors of social capital acquisition in the context
of online-gaming: Comparing World of Warcraft and Counter-Strike. Computers in Human
Behavior, 36:179–189, 2014. ISSN 07475632. doi: 10.1016/j.chb.2014.03.057. URL http:
//dx.doi.org/10.1016/j.chb.2014.03.057.
Stéphane Ross, Geoffrey J Gordon, and J Andrew Bagnell. A Reduction of Imitation Learning and
Structured Prediction to No-Regret Online Learning. AISTATS, 2011. URL http://www.ri.cmu.
edu/pub{_}files/2011/4/Ross-AISTATS11-NoRegret.pdf.
Stefan Schaal. Learning from demonstration. Advanced Information and Knowledge Processing,
1996. ISSN 21978441. doi: 10.1007/978-3-319-25232-2_13.
Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-kin Wong, and Wang-chun Woo. Con-
volutional LSTM network: A machine learning approach for precipitation nowcasting. Advances
in Neural Information Processing Systems 28, pages 802–810, 2015. ISSN 10495258.
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche,
Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman,
Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine
Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of Go with
deep neural networks and tree search. Nature, 529(7587):484–489, 2016. ISSN 14764687. doi:
10.1038/nature16961. URL http://dx.doi.org/10.1038/nature16961.
Shihong Song, Jiayi Weng, Hang Su, Dong Yan, Haosheng Zou, and Jun Zhu. Playing FPS
games with environment-aware hierarchical reinforcement learning. IJCAI International Joint
Conference on Artificial Intelligence, 2019-Augus:3475–3482, 2019. ISSN 10450823. doi:
10.24963/ijcai.2019/482.
Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung
Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan,
Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P. Agapiou, Max
14Jaderberg, Alexander S. Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David
Budden, Yury Sulsky, James Molloy, Tom L. Paine, Caglar Gulcehre, Ziyu Wang, Tobias Pfaff,
Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith,
Tom Schaul, Timothy Lillicrap, Koray Kavukcuoglu, Demis Hassabis, Chris Apps, and David
Silver. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature,
575(7782):350–354, 2019. ISSN 14764687. doi: 10.1038/s41586-019-1724-z. URL http:
//dx.doi.org/10.1038/s41586-019-1724-z.
Xiangjun Wang, Junxiao Song, Penghui Qi, Peng Peng, Zhenkun Tang, Wei Zhang, Weimin Li,
Xiongjun Pi, Jujie He, Chao Gao, Haitao Long, and Quan Yuan. SCC: An efficient deep reinforce-
ment learning agent mastering the game of StarCraft II. Deep RL Workshop, NeurIPS, 2020. ISSN
23318422.
Marek Wydmuch, Michał Kempka, and Wojciech Jaśkowski. Vizdoom competitions: Playing
doom from pixels. IEEE Transactions on Games, 11(3):248–259, 2019. ISSN 24751510. doi:
10.1109/TG.2018.2877047.
15Appendix to Counter-Strike Deathmatch
with Large-Scale Behavioural Cloning
A Interfacing with the Game
Although not strictly an AI problem, one of the major challenges of this project was solving the
engineering task of reliably interacting with the game. The code base is not open sourced and given a
widespread cheating problem in CSGO, automated control has been restricted as far as possible.
Image capture: There is no direct access to CSGO’s screen buffer, so the game must first be rendered
on a machine and then pixel values copied. We used the Win32 API for this purpose – other options
tested were unable to operate at the required frame rate.
Applying actions: Actions sent by many standard Python packages, such as pynput, were not
recognised by CSGO. Instead, we used the Windows ctypes library to send key presses and mouse
movement and clicks.
Recording local actions: The Win32 API again was used to log local key presses and mouse clicks.
Mouse movement is more complicated – the game logs and resets mouse position at high-frequency
and irregular intervals. Naively logging the mouse position at the required frame rate fails to reliably
determine player orientation. We instead infer mouse movement from game metadata.
Capturing game metadata: CSGO provides a game state integration7 (GSI) API for developers, e.g.
to enable automation of effects during live games. It is carefully designed to not provide information
that would give players an unfair advantage (such as location of enemy players). We use GSI to
collect high-level information about the game, such as kills and deaths. Although it provides data
about a player’s state, we found this was not reliable enough to accurately infer mouse movements.
For lack of alternatives, we parsed the local RAM to obtain precise information about a player’s
location, orientation and velocity. Whilst this approach is typically associated with hacking in CSGO,
we only extract information about the player we are currently spectating, and never to provide the
agent or its training data with information a human player would not have.
7
https://developer.valvesoftware.com/wiki/Counter-Strike:_Global_Offensive_Game_
State_Integration
16B CSGO Game Settings
This section details the game settings we used to evaluate the agent (see https://github.com/
TeaPearce for full list). It’s possible performance may drop if these are not matched, or if future
CSGO updates materially affect gameplay (we have so far found it robust over versions 1.37.7.0 to
1.37.8.6).
• CSGO version: 1.37.8.6
• Game resolution: 1024×768 (windowed mode)
• Mouse sensitivity: 2.50
• Mouse raw input: Off
• Crosshair: Static, green (black outline) with centre dot
• All graphics options: Lowest quality setting
• Clear decals is bound to ‘n’ key
B.1 Game Modes Set-up
The aim train mode uses the ‘Fast Aim / Reflex Training’ map: https://steamcommunity.com/
sharedfiles/filedetails/?id=368026786, with the below console commands. Join counter-
terrorist team, ensure that ‘God’ mode is on, and AK-47 is selected.
sv_cheats 1;
sv_infinite_ammo 1;
mp_free_armor 1;
mp_roundtime 6000;
sv_pausable 1;
sv_auto_adjust_bot_difficulty 0;
Easy and medium deathmatch mode can be initialised from the main menu (play offline with bots
→ dust_2 → easy/medium bots). Then run below commands (some have to be run in two batches).
Manually join terrorist team, and select AK-47.
Deathmatch mode, easy setting
mp_roundtime 6000;
mp_teammates_are_enemies 0;
mp_limitteams 30;
mp_autoteambalance 0;
sv_infinite_ammo 1;
bot_kick ;
bot_pistols_only 1;
b o t _ d i f f i c u l t y 0;
sv_auto_adjust_bot_difficulty 0;
c o n t r i b u t i o n s c o r e _ a s s i s t 0;
c o n t r i b u t i o n s c o r e _ k i l l 0;
mp_restartgame 1;
b o t _ a d d _ t ; ( r u n 11 t i m e s )
b o t _ a d d _ c t ; ( r u n 12 t i m e s )
Deathmatch mode, medium setting
mp_roundtime 6000;
mp_teammates_are_enemies 0;
mp_limitteams 30;
mp_autoteambalance 0;
sv_infinite_ammo 2;
bot_kick ;
17b o t _ d i f f i c u l t y 1;
sv_auto_adjust_bot_difficulty 0;
c o n t r i b u t i o n s c o r e _ a s s i s t 0;
c o n t r i b u t i o n s c o r e _ k i l l 0;
mp_restartgame 1;
b o t _ a d d _ t ; ( r u n 11 t i m e s )
b o t _ a d d _ c t ; ( r u n 12 t i m e s )
Deathmatch mode, human setting is initialised form the main menu (play online deathmatch →
dust_2). Manually join terrorist team, and select AK-47.
18You can also read

















































