Establishing Human-Robot Trust through Music-Driven Robotic Emotion Prosody and Gesture
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Establishing Human-Robot Trust through Music-Driven Robotic
Emotion Prosody and Gesture
Richard Savery, Ryan Rose and Gil Weinberg1
Abstract— As human-robot collaboration opportunities con- [8], implying methods for gaining trust at the start of a
tinue to expand, trust becomes ever more important for full relationship, such as prosody and gesture are crucial.
engagement and utilization of robots. Affective trust, built on
emotional relationship and interpersonal bonds is particularly
critical as it is more resilient to mistakes and increases the
willingness to collaborate. In this paper we present a novel
arXiv:2001.05863v1 [cs.HC] 11 Jan 2020
model built on music-driven emotional prosody and gestures
that encourages the perception of a robotic identity, designed to
avoid uncanny valley. Symbolic musical phrases were generated
and tagged with emotional information by human musicians.
These phrases controlled a synthesis engine playing back pre-
rendered audio samples generated through interpolation of
phonemes and electronic instruments. Gestures were also driven
by the symbolic phrases, encoding the emotion from the musical
phrase to low degree-of-freedom movements. Through a user
study we showed that our system was able to accurately
portray a range of emotions to the user. We also showed with
a significant result that our non-linguistic audio generation
achieved an 8% higher mean of average trust than using a
state-of-the-art text-to-speech system.
I. INTRODUCTION
As co-robots become prevalent at home, work, and in
public environments, a need arises for the development of
trust between humans and robots. A meta-study of human-
robot trust [1] has shown that robot-related attributes are
the main contributors to building trust in Human-Robot-
Interaction, affecting trust more than environmental and
human related factors. Related research on artificial agents Fig. 1. The musical robot companion Shimi
and personality traits [2], [3] indicates conveying emotions
using subtle non-verbal communication channels such as We address two research questions, firstly, can we use
prosody and gesture is an effective approach for building non-verbal prosody through musical phrases combined with
trust with artificial agents. These channels can help convey gestures to accurately convey emotions? We present a novel
intentions as well as expressions such as humor, sarcasm, deep learning based musical voice generation system that
irony, and state-of-mind, which help build social relationship uses the created phrases to generate gesture through musical
and trust. prosody. In this way music is central to all interactions
In this work we developed new modules for Shimi, a presented by Shimi. We evaluate the effectiveness of the
personal robotic platform [4], to study whether emotion- musical audio and generative gesture system for Shimi to
driven non-verbal prosody and body gesture can help es- convey emotion, specified by valence-arousal quadrants. Our
tablish affective-based trust in HRI. Our approach is to second research question is whether emotional conveyance
use music, one of the most emotive human experiences, to through prosody and gestures driven by music analysis can
drive a novel system for emotional prosody [5] and body increase the level of trust in human-robot-interaction. For
gesture [6] generation. We propose that music-driven prosody this we conduct a user study to evaluate prosodic audio
and gesture generation can provide effective low degrees of and gestures created by our new model in comparison to
freedom (DoF) interaction that can convey robotic emotional a baseline text-to-speech system.
content, avoid the uncanny valley [7], and help build human-
robot trust. Furthermore, trust is highly dictated by the first II. BACKGROUND
impression for both human-human and human-robot relations A. Trust in HRI
1 Georgia Tech Center for Music Technology, Atlanta, GA, USA Trust is a key requirement for working with collaborative
rsavery3@gatech.edu robots, as low levels of trust can lead to under-utilization
in work and home environments [9]. A key component of facilitated human-robot interactions [36], [25], [37]. Gesture
the dynamic nature of trust is created in the first phase of has been used to accompany speech in robots to help convey
a relationship [10], [11], while lack of early trust building affective information [38], however, to our knowledge, there
can remove the opportunity for trust to develop later on is no prior work that attempts to integrate physical gestures
[12]. Lack of trust in robotic systems can also lead to and music-driven prosody to convey robotic emotional states.
expert operators bypassing the robot to complete tasks [13].
Trust is generally categorized into either cognitive trust or III. S HIMI AND E MOTION
affective trust [14]. Affective trust involves emotional bonds A. Prosody
and personal relationships, while cognitive trust focuses on The goal of this project was to create a new voice for
considerations around dependability and competence. Per- Shimi, using musical audio phrases tagged with an emotion.
ceiving emotion is crucial for the development of affective We aimed to develop a new voice that could generate
trust in human-to-human interaction [15], as it increases phrases in real-time. This was achieved through a multi-layer
the willingness to collaborate and expand resources bought system, combining symbolic phrase generation using MIDI
to the interactions [16]. Importantly, relationships based controlling a synthesis playback system.
on affective trust are more resilient to mistakes by either
party [15], and perceiving an emotional identity has been
shown to be an important contributor for creating believable
and trustworthy interaction [2], [3]. In group interactions,
emotional contagion - where emotion is spread between a
group - has been shown to improve cooperation and trust in
team exercises [17].
B. Emotion, Music and Prosody
Emotion conveyance is one of the key elements for cre-
ating believable agents [2], and prosody has been proven
to be an effective communication channel to convey such
emotions for humans [18] and robots [19]. On a related front,
music which shares many of the underlying building blocks
of prosody such as pitch, timing, loudness, intonation, and
Fig. 2. Angry Speech Pitch and Intensity
timbre [20], has also been shown to be a powerful medium to
convey emotions [21]. In both music and prosody, emotions
can be classified in a discrete categorical manner (happiness,
sadness, fear, etc.) [22], and through continuous dimensions
such as valence, arousal, and less commonly, dominance,
and stance [23], [24]. While some recent efforts to generate
and manipulate robotic emotions through prosody focused on
linguistic robotic communication [19], [25] no known efforts
have been made to use models from music analysis to inform
real-time robotic non linguistic prosody for collaboration, as
we propose here.
C. Emotion, Music and Gesture
Human bodily movements are embedded with emotional
expression [26], [27], which can be processed by human
“affective channels” [28]. Researchers in the field of af-
fective computing, have been working on designing ma- Fig. 3. Calm Speech Pitch and Intensity
chines that can process and communicate emotions through
such channels [29]. Non-conscious affective channels have 1) Dataset and Phrase Generation: To control Shimi’s
been demonstrated to communicate compassion, awareness, vocalizations we generate MIDI phrases that drive the syn-
accuracy, and competency, making them vital components thesis and audio generation described below and lead the
of social interaction with robots [30]. Studies have shown gesture generation. MIDI is a standard music protocol, where
clear correlations between musical features and movement notes are stored by pitch value with a note on velocity,
features, suggesting that a single model can be used to followed by a note off to mark the end of the note. With
express emotion through both music and movement [31], the absence of appropriate datasets we chose to create our
[32], [33]. Certain characteristics of robotic motion have own set of MIDI files tagged with valence and arousal by
been shown to influence human emotional response [34], quadrant. MIDI files were collected from eleven different
[35]. Additionally, emotional intelligence in robots leads to improvisers around the United States, each of whom tagged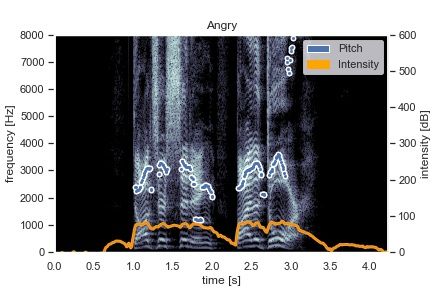
their recorded files with an emotion corresponding to a features are used to create mappings between Shimi’s voice
quadrant of the valence/arousal model. Phrases were required and movement: for example, pitch contour is used to gov-
to be between 100ms and 6 seconds and each improviser ern Shimi’s torso forward and backward movement. Other
recorded between 50 to 200 samples for each quadrant. To mappings include beat synchronization across multiple sub-
validate this data we created a separate process whereby divisions of the beat in Shimi’s foot, and note onset-based
the pitch range, velocities and contour were compared to movements in Shimi’s up-and-down neck movement.
the RAVDESS [39] data set, with files removed when the After mapping musical features to low-level movements,
variation was over a manually set threshold. RAVDESS Shimi’s emotional state is used to condition the actuation of
contains speech files tagged with emotion, Figure 2 and the movements. Continuous values for valence and arousal
Figure 3 clearly demonstrate the variety of prosody details are used to influence the range, speed, and amount of motion
apparent in the RAVDESS dataset (created using [40], [41]) Shimi exhibits. Some conditioning examples include limiting
and the variation between a calm and angry utterance of the or expanding the range of motion according to the arousal
same phrase. value, and governing how smooth motor direction changes
We chose to use a Recurrent Neural Network, Long Short are through Shimi’s current valence level. In some cases, the
Term Memory (RNN-LSTM) as described in [42] to generate gestures generated for one degree of freedom are dependent
musical phrases using this data. RNN-LSTM’s have been on another degree of freedom. For example, when Shimi’s
used effectively to generate short melodies, as they are torso leans forward, Shimi’s attached head will be affected
sequential and consider the input as the output is generated. as well. As such, to control where Shimi is looking, any neck
Other network structures were considered however we found gestures need to know the position of the torso. To accom-
RNN-LSTM’s very effective for this task when compared modate these inter-dependencies, when the gesture system is
to alternate approaches developed by the authors [43], [44], given input, each degree of freedom’s movements are gener-
[45], [46], more detail is provided in [47]. While using ated sequentially and in full, before being actuated together
samples directly from the data was possible, using a neu- in time with Shimi’s voice. Video examples of gesture and
ral network allowed infinite variation but also allowed for audio are available at www.richardsavery.com/shimitrust.
generated phrases utilizing all the musical features created
by the improvisers, not just one improviser per sample. IV. M ETHODOLOGY
2) Audio Creation and Synthesis: The generated MIDI
phrases contain symbolic information only without audio. We designed an experiment to identify how well partic-
To create audio we developed a synthesis system to playback ipants could recognize the emotions shown by our music-
the MIDI phrase. As we desired to create a system devoid of driven prosodic and gestural emotion generator. This part of
semantic meaning a new vocabulary was constructed. This the experiment aimed to answer our first research question,
was built upon phonemes from the Australian Aboriginal can non-verbal prosody combined with gestures accurately
language Yuwaalaraay a dialect of the Gamilaraay language. portray emotion. After watching a collection of stimuli,
Sounds were created by interpolating four different synthe- participants completed a survey measuring the trust rating
sizer sounds with 28 phonemes. Interpolation was done using from each participant. This part of the experiment was
a modified version of WaveNet. These samples are then time designed to answer the second question, can emotion driven,
stretched and pitch shifted to match the incoming MIDI file. non-semantic audio generate trust in a robot.
For a more detailed technical overview of audio processing We hypothesized that through non-semantic prosodic vo-
read [47]. calizations accompanied with low-DoF robotic gesture hu-
mans will be able to correctly classify Shimi’s portrayed
B. Gestures emotion as either happy, calm, sad, or angry, with an
In human communication gestures are tightly coupled with accuracy consistent with that of text-to-speech. Our second
speech [48]. Thus, Shimi’s body language is implemented hypothesis was that we will see higher levels of trust from
in the same way, derived from its musical prosody and the Shimi using non-speech.
leveraging the musical encoding of emotion to express that
emotion physically. Music and movement are correlated, A. Stimuli
with research finding commonalities in features between both
modes [31]. Additionally, humans demonstrate patterns in Name Audio Stochastic Experimental
movement that is induced from music [49]. Particular music- Audio Only X
Stochastic Gesture, audio X X
induced movement features are also correlated to perceived Stochastic Gesture, no audio X
emotion in music [50]. After a musical phrase is generated Experimental Gesture, audio X X
for Shimi’s voice to sing, the MIDI representation of that Experimental Gesture, X X
phrase is provided as input to a gesture generation system. no audio
Musical features such as tempo, range, note contour, key, TABLE I
and rhythmic density are obtained from the MIDI through E XPERIMENT S TIMULI
Python libraries pretty_midi [51] and music211 . These
1 https://github.com/cuthbertLab/music21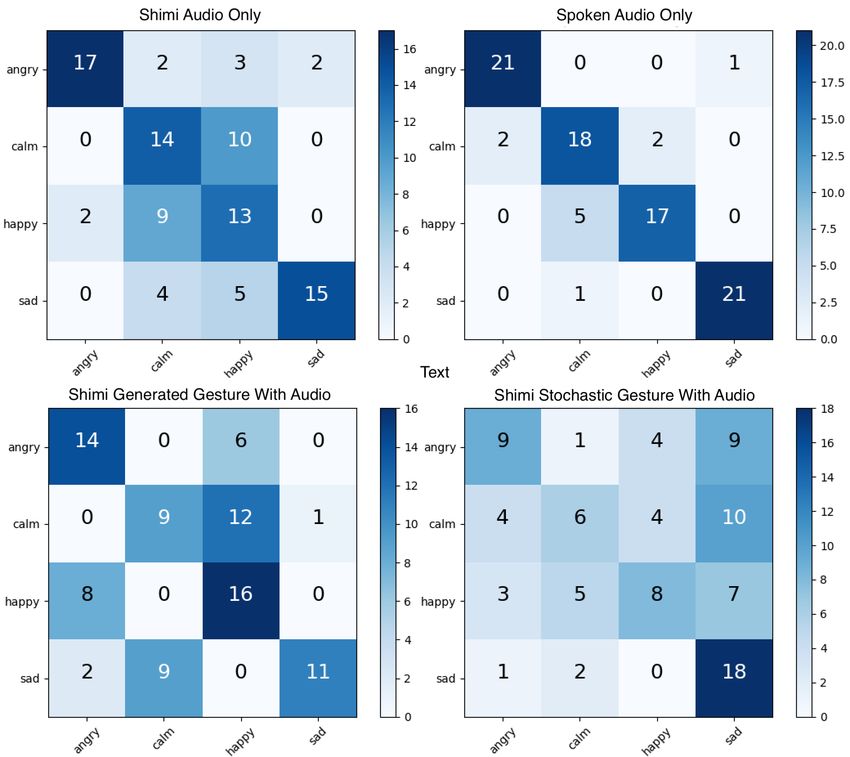
Fig. 4. Confusion Matrix
The experiment was designed as a between-subjects study, Subjects participated independently, with the group alter-
where one group would hear the audio with the Shimi voice, nating for each participant, culminating with 12 in each
while the other would hear pre-rendered text-to-speech. Both group. The session began with an introduction to the task
groups saw the same gesture and answered the same prompts. of identifying the emotion displayed by Shimi. Participants
The text-to-speech examples were synchronized in length responded through a web interface that controlled Shimi
and emotion to Shimi’s voice. The stimuli for the Speech through the experiment and then allowed the user to select
Audio experiment used CereProc’s Meghan voice2 . CereProc the emotion they thought Shimi was expressing. Stimuli were
is a state of the art text to speech engine. The text spoken by randomly ordered for each participant. Table I shows the
Meghan was chosen from the EmoInt Dataset [52], which is order of stimuli used, each category contained 8 stimuli, 2 for
a collection of manually tagged tweets. each valence arousal quadrant. After identifying all stimuli
participants were directed to a Qualtrics survey to gather
B. Emotion
their trust rating.
The generated gestures were either deterministic gestures To measure trust, we used the Trust Perception Scale-
created using the previously described system, or determinis- HRI [12]. This scale uses 40 questions, each one using a
tic stochastic gestures. Stochastic gestures were implemented rating scale between 0-100%, to give an average trust rating
by considering each DoF separately, restricting their ranges per participant. The questions take between 5-10 minutes
to those implemented in the generative system, and speci- to complete and include questions such as how often the
fying random individual movement durations up to half of robot will be reliable or pleasant. After completing the trust
the length of the full gesture. The random number generator rating, participants had several open text boxes to discuss
used in these gestures were seeded with an identifier unique any observations in regards to emotion recognition, trust or
to the stimuli such that they were deterministic between the general experiment. This was the first time trust was
participants. Gesture stimuli were presented both with and mentioned in the experiment.
without audio.
V. R ESULTS
C. Procedure
A. Gestures and Emotion
Participants were gathered from the undergraduate student
population at the Georgia Institute of Technology (N=24). After data was collected, two participant’s emotion predic-
tion data was found to be corrupted due to a problem with
2 https://www.cereproc.com/ the testing interface, reducing the number of participants inFig. 5. Questions with P less than 0.1
this portion of the study to 22. First, we considered classifi-
cation statistics for the isolated predictions of Shimi’s voice
and text-to-speech (TTS) voice. While TTS outperformed
Shimi’s voice (F1 score T T S = 0.87 vs. Shimi = 0.63),
the confusion matrices show errant predictions in similar
scenarios (see figure 4). For example, both audio classes
struggle to disambiguate happy and calm emotions.
Our hope was that adding gestures to accompany the
audio would help to disambiguate emotions. To test that our
gestures properly encoded emotion, we compared predictions
for Shimi’s voice accompanied by generated gestures with
predictions accompanied by stochastic gestures, the results
of which can also be seen in figure 4.
While the confusion matrices show a clear prediction
improvement in using generated gestures over stochastic, the
results are not statistically significant. A two-sided T-test
provides a p-value of 0.089, which does not reject the null
hypothesis at α = 0.05. Disambiguities from the audio-only
cases were not mitigated, but the confused emotions changed
slightly, following other gesture and emotion studies [53].
Some experimental error may have accrued through the
mixing of stimuli when presented to participants. Each
stimuli was expected to be independent but some verbal user Fig. 6. Participants Trust Mean
feedback expressed otherwise, such as: “the gestures with no
audio seemed to be frequently followed by the same gesture
with audio, and it was much easier to determine emotion
with the presence of audio.” The presentation of stimuli may
have led participants to choose an emotion based on how
we ordered stimuli, rather than their perceived emotion of showed a significant result (p=0.047), proving the hypothesis.
Shimi. Figure 6 shows the variation in average scores from all
participants. The difference of mean between groups was 8%.
B. Trust Results from the text entries were positive for the prosodic
As per the trust scale, a mean percentage for trust was voice, and generally neutral or often blank for speech. A
calculated on combined answers to 40 questions from each common comment from the participants for the Shimi voice
participant. A t-test was then run on each group mean. The was “Seemed like a trustworthy friend that I would be fine
average score variation between speech and Shimi audio confiding in.”much higher ratings for its perception as being conscious.
While further research is required to confirm the meaning,
we believe that the question on consciousness of Shimi
demonstrating a significant result shows that embodying
a robot with a personal prosody (as opposed to human
speech) creates a more believable agent. Figure 7 shows the
categories with very similar distributions of scores. These
include Lifelike, A Good Teammate, Have Errors, Require
Maintenance and Openly Communicate. While further re-
search is needed, this may imply that these features are not
primarily associated with audio. Further work should be done
to explore if the same impact can be found by adjusting audio
features of a humanoid robot may also lead to interesting
results.
In other future work we plan to develop experiments with
a broader custom musical data-set across multiple robots. We
Fig. 7. Not Significant Trust Results intend to study emotional contagion and trust between larger
groups of robots across distributed networks [54], aiming to
understand collaboration and trust at a higher level between
VI. D ISCUSSION AND F UTURE W ORK multiple robots.
Overall, our trust results were significant and showed
We were able to clearly demonstrate participant recogni- that prosody and gesture can be used to generate higher
tion of the expected emotion from Shimi, confirming our first levels of trust in human-robot interaction. Our belief that
hypothesis. Our model however did not perform completely creating a believable agent that avoided uncanny valley was
as predicted, as audio without gesture lead to the clearest shown to be correct and was validated through participant
display of emotion. With a small sample size and a p-value comments, including the open text response: “Shimi seems
close to being significant, we were encouraged by qualitative very personable and expressive, which helps with trust”.
feedback that provided insight into the shortcomings of the
gestures and gave us ideas for future improvements. For
instance, emotions on the same side of the arousal axis were R EFERENCES
often hard to disambiguate. One participant noted that “it
was generally difficult to distinguish happy and angry if there [1] P. A. Hancock, D. R. Billings, K. E. Schaefer, J. Y. Chen, E. J.
De Visser, and R. Parasuraman, “A meta-analysis of factors affecting
were no sounds (similar situation between sad and calm)”, trust in human-robot interaction,” Human Factors, vol. 53, no. 5, pp.
while another noted “I had some trouble discerning calm 517–527, 2011.
from sad here and there”, and “without speaking, it was [2] M. Mateas, “Artificial intelligence today,” M. J. Wooldridge and
M. Veloso, Eds. Berlin, Heidelberg: Springer-Verlag, 1999, ch.
difficult to decipher between anger and excitement”. The An Oz-centric Review of Interactive Drama and Believable Agents,
general intensity of the emotion was apparent, however.” pp. 297–328. [Online]. Available: http://dl.acm.org/citation.cfm?id=
Certain movement features led to emotional connections 1805750.1805762
[3] J. Bates, “The role of emotion in believable agents,” Commun.
for the participants, as demonstrated here: “generally, when ACM, vol. 37, no. 7, pp. 122–125, Jul. 1994. [Online]. Available:
Shimi put it’s head down, I was inclined to say it looked sad. http://doi.acm.org/10.1145/176789.176803
When it moved more violently, particularly by tapping [sic] [4] M. Bretan, G. Hoffman, and G. Weinberg, “Emotionally expressive dy-
it’s foot, I was inclined to say it was angry or happy”, “more namic physical behaviors in robots,” International Journal of Human-
Computer Studies, vol. 78, pp. 1–16, 2015.
forceful movements tended to suggest anger”, and “When [5] R. Adolphs, D. Tranel, and H. Damasio, “Emotion recognition from
there was more severe motion, I associated that with anger. faces and prosody following temporal lobectomy.” Neuropsychology,
When the motion was slower I associated it with sad or calm. vol. 15, no. 3, p. 396, 2001.
[6] C. Shan, S. Gong, and P. W. McOwan, “Beyond facial expressions:
If the head was down more I associated it with sad. And I Learning human emotion from body gestures.” in BMVC, 2007, pp.
associated it with happy more when there was sound and 1–10.
more motion.” [7] K. F. MacDorman, “Subjective ratings of robot video clips for human
likeness, familiarity, and eeriness: An exploration of the uncanny
The trust perception scale is designed to give an overall valley,” in ICCS/CogSci-2006 long symposium: Toward social mech-
rating, and independent questions should not necessarily anisms of android science, 2006, pp. 26–29.
be used to draw conclusions. However, there were several [8] J. Xu and A. Howard, “The impact of first impressions on human-
robot trust during problem-solving scenarios,” in 2018 27th IEEE
interesting results indicating further areas of research. Fig 5 International Symposium on Robot and Human Interactive Commu-
shows all categories with a p value less than 0.10, for which nication (RO-MAN), Aug 2018, pp. 435–441.
multiple questions showed significant results with a p value [9] J. D. Lee and K. A. See, “Trust in automation: Designing for
under 0.05). Shimi’s voice was crafted to be friendly and appropriate reliance,” Human Factors, vol. 46, no. 1, pp. 50–80, 2004.
[10] P. H. Kim, K. T. Dirks, and C. D. Cooper, “The repair of trust:
inviting and as expected received much higher results for A dynamic bilateral perspective and multilevel conceptualization,”
pleasantness and friendliness. Unexpectedly, it also showed Academy of Management Review, vol. 34, no. 3, pp. 401–422, 2009.[11] R. E. Miles and W. D. Creed, “Organizational forms and managerial robots,” in Human-Robot Interaction (HRI), 2010 5th ACM/IEEE
philosophies-a descriptive and analytical review,” RESEARCH IN International Conference on. IEEE, 2010, pp. 61–68.
ORGANIZATIONAL BEHAVIOR: AN ANNUAL SERIES OF ANALYT- [35] A. Moon, C. A. Parker, E. A. Croft, and H. Van der Loos, “Design and
ICAL ESSAYS AND CRITICAL REVIEWS, VOL 17, 1995, vol. 17, pp. impact of hesitation gestures during human-robot resource conflicts,”
333–372, 1995. Journal of Human-Robot Interaction, vol. 2, no. 3, pp. 18–40, 2013.
[12] K. E. Schaefer, Measuring Trust in Human Robot Interactions: Devel- [36] H. Kozima and H. Yano, “In search of otogenetic prerequisites for
opment of the “Trust Perception Scale-HRI”. Boston, MA: Springer embodied social intelligence,” in Proceedings of the Workshop on
US, 2016, pp. 191–218. Emergence and Development on Embodied Cognition; International
[13] P. M. Satchell, Cockpit monitoring and alerting systems. Routledge, Conference on Cognitive Science, 2001, pp. 30–34.
2016. [37] G. Castellano, I. Leite, A. Pereira, C. Martinho, A. Paiva, and P. W.
[14] A. Freedy, E. DeVisser, G. Weltman, and N. Coeyman, “Measurement McOwan, “Affect recognition for interactive companions: challenges
of trust in human-robot collaboration,” in Collaborative Technologies and design in real world scenarios,” Journal on Multimodal User
and Systems, 2007. CTS 2007. International Symposium on. IEEE, Interfaces, vol. 3, no. 1, pp. 89–98, 2010.
2007, pp. 106–114. [38] M. W. Alibali, S. Kita, and A. J. Young, “Gesture and the process
[15] D. M. Rousseau, S. B. Sitkin, R. S. Burt, and C. Camerer, “Not of speech production: We think, therefore we gesture,” Language and
so different after all: A cross-discipline view of trust,” Academy of cognitive processes, vol. 15, no. 6, pp. 593–613, 2000.
management review, vol. 23, no. 3, pp. 393–404, 1998. [39] S. R. Livingstone and F. A. Russo, “The Ryerson Audio-Visual
[16] T. Gompei and H. Umemuro, “Factors and development of cognitive Database of Emotional Speech and Song (RAVDESS): A dynamic,
and affective trust on social robots,” in International Conference on multimodal set of facial and vocal expressions in North American
Social Robotics. Springer, 2018, pp. 45–54. English,” PLOS ONE, vol. 13, no. 5, pp. 1–35, 2018. [Online].
[17] S. G. Barsade, “The ripple effect: Emotional contagion and its influ- Available: https://doi.org/10.1371/journal.pone.0196391
ence on group behavior,” Administrative science quarterly, vol. 47, [40] Y. Jadoul, B. Thompson, and B. de Boer, “Introducing parselmouth:
no. 4, pp. 644–675, 2002. A python interface to praat,” Journal of Phonetics, vol. 91, pp. 1–15,
[18] Y. T. Wang, J. Han, X. Q. Jiang, J. Zou, and H. Zhao, “Study of 11 2018.
speech emotion recognition based on prosodic parameters and facial [41] P. Boersma and D. Weenink, “Praat: Doing phonetics by computer
expression features,” in Applied Mechanics and Materials, vol. 241. (version 5.3.51),” 01 2007.
Trans Tech Publ, 2013, pp. 1677–1681. [42] R. Savery and G. Weinberg, “Shimon the robot film composer and
[19] J. Crumpton and C. L. Bethel, “A survey of using vocal prosody deepscore,” Proceedings of Computer Simulation of Musical Creativ-
to convey emotion in robot speech,” International Journal of Social ity, p. 5, 2018.
Robotics, vol. 8, no. 2, pp. 271–285, 2016. [43] M. Bretan, G. Weinberg, and L. Heck, “A unit selection methodology
[20] A. Wennerstrom, The music of everyday speech: Prosody and dis- for music generation using deep neural networks,” arXiv preprint
course analysis. Oxford University Press, 2001. arXiv:1612.03789, 2016.
[21] J. Sloboda, “Music: Where cognition and emotion meet,” in Con- [44] R. J. Savery, “An interactive algorithmic music system for edm,”
ference Proceedings: Opening the Umbrella; an Encompassing View Dancecult: Journal of Electronic Dance Music Culture, vol. 10, no. 1,
of Music Education; Australian Society for Music Education, XII 2018.
National Conference, University of Sydney, NSW, Australia, 09-13 July [45] ——, “Algorithmic improvisers,” in UC Irvine Electronic Theses and
1999. Australian Society for Music Education, 1999, p. 175. Dissertations, 2015.
[22] L. Devillers, L. Vidrascu, and L. Lamel, “Challenges in real-life [46] R. Savery, M. Ayyagari, K. May, and B. N. Walker, “Soccer sonifica-
emotion annotation and machine learning based detection,” Neural tion: Enhancing viewer experience.” Georgia Institute of Technology,
Networks, vol. 18, no. 4, pp. 407–422, 2005. 2019.
[23] J. A. Russell, “Emotion, core affect, and psychological construction,” [47] R. Savery, R. Rose, and G. Weinberg, “Finding Shimi’s voice: fostering
Cognition and Emotion, vol. 23, no. 7, pp. 1259–1283, 2009. human-robot communication with music and a NVIDIA Jetson TX2,”
[24] A. Mehrabian, “Pleasure-arousal-dominance: A general framework Proceedings of the 17th Linux Audio Conference, p. 5, 2019.
for describing and measuring individual differences in temperament,” [48] D. McNeill, How language began: Gesture and speech in human
Current Psychology, vol. 14, no. 4, pp. 261–292, 1996. evolution. Cambridge University Press, 2012.
[25] C. Breazeal and L. Aryananda, “Recognition of affective communica- [49] P. Toiviainen, G. Luck, and M. R. Thompson, “Embodied Meter:
tive intent in robot-directed speech,” Autonomous robots, vol. 12, no. 1, Hierarchical Eigenmodes in Music-Induced Movement,” Music
pp. 83–104, 2002. Perception: An Interdisciplinary Journal, vol. 28, no. 1, pp. 59–70,
[26] M. Inderbitzin, A. Vljame, J. M. B. Calvo, P. F. M. J. Verschure, and sep 2010. [Online]. Available: http://mp.ucpress.edu/content/28/1/59
U. Bernardet, “Expression of emotional states during locomotion based [50] B. Burger, S. Saarikallio, G. Luck, M. R. Thompson, and P. Toiviainen,
on canonical parameters,” in Ninth IEEE International Conference on “Relationships Between Perceived Emotions in Music and Music-
Automatic Face and Gesture Recognition (FG 2011), Santa Barbara, induced Movement,” Music Perception: An Interdisciplinary Journal,
CA, USA, 21-25 March 2011. IEEE, 2011, pp. 809–814. vol. 30, no. 5, pp. 517–533, Jun. 2013. [Online]. Available:
http://mp.ucpress.edu/cgi/doi/10.1525/mp.2013.30.5.517
[27] H. G. Walbott, “Bodily expression of emotion,” European Journal of
[51] C. Raffel and D. P. W. Ellis, “Intuitive analysis, creation and ma-
Social Psychology, vol. 28, no. 6, pp. 879 – 896, 1998.
nipulation of midi data with pretty midi,” in Proceedings of the
[28] B. de Gelder, “Towards the neurobiology of emotional body language,”
15th International Conference on Music Information Retrieval Late
Nature Reviews Neuroscience, vol. 7, pp. 242–249, March 2006.
Breaking and Demo Papers, 2014.
[29] R. W. Picard, “Affective computing,” 1995.
[52] S. M. Mohammad and F. Bravo-Marquez, “WASSA-2017 shared task
[30] M. Scheutz, P. Schermerhorn, and J. Kramer, “The utility of affect ex-
on emotion intensity,” in Proceedings of the Workshop on Computa-
pression in natural language interactions in joint human-robot tasks,” in
tional Approaches to Subjectivity, Sentiment and Social Media Analysis
Proceedings of the 1st ACM SIGCHI/SIGART conference on Human-
(WASSA), Copenhagen, Denmark, 2017.
robot interaction. ACM, 2006, pp. 226–233.
[53] A. Lim, T. Ogata, and H. G. Okuno, “Towards expressive musical
[31] B. Sievers, L. Polansky, M. Casey, and T. Wheatley, “Music robots: a cross-modal framework for emotional gesture, voice
and movement share a dynamic structure that supports universal and music,” EURASIP Journal on Audio, Speech, and Music
expressions of emotion,” Proceedings of the National Academy of Processing, vol. 2012, no. 1, p. 3, Jan. 2012. [Online]. Available:
Sciences, vol. 110, no. 1, pp. 70–75, jan 2013. [Online]. Available: https://doi.org/10.1186/1687-4722-2012-3
http://www.pnas.org/content/110/1/70 [54] G. Weinberg, “Expressive digital musical instruments for children,”
[32] G. Weinberg, A. Beck, and M. Godfrey, “Zoozbeat: a gesture-based Ph.D. dissertation, Massachusetts Institute of Technology, 1999.
mobile music studio.” in NIME, 2009, pp. 312–315.
[33] G. Weinberg, S. Driscoll, and T. Thatcher, “Jamaa: a percussion
ensemble for human and robotic players,” in ACM International
Conference on Computer Graphics and Interactive Techniques (SIG-
GRAPH 2006), ACM Boston, MA, 2006.
[34] L. D. Riek, T.-C. Rabinowitch, P. Bremner, A. G. Pipe, M. Fraser, and
P. Robinson, “Cooperative gestures: Effective signaling for humanoidYou can also read

















































