Generative Networks for LHC
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Generative
Networks
Tilman Plehn
GAN basics
1- Events
2- Inverting
Generative Networks for LHC
Tilman Plehn
Universität Heidelberg
CMS 1/2021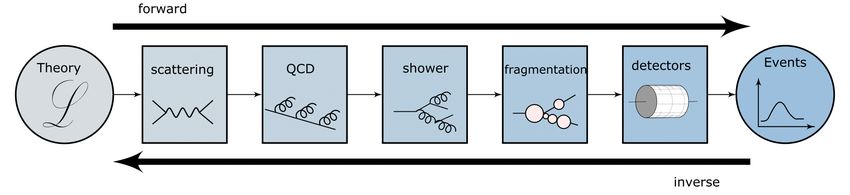
Generative
Networks Simulations for future LHC runs
Tilman Plehn
Unique: fundamental understanding of lots of data
GAN basics
1- Events – precision theory predictions
2- Inverting – precision simulations
– precision measurements
⇒ What’s needed to keep the edge?
ATLAS Preliminary
2020 Computing Model -CPU: 2030: Aggressive R&D
2% 10%
8%
12%
13% Data Proc
7% MC-Full(Sim)
MC-Full(Rec)
MC-Fast(Sim)
MC-Fast(Rec)
EvGen
16% Heavy Ions
18% Data Deriv
MC Deriv
5% Analysis
8%Generative
Networks Simulations for future LHC runs
Tilman Plehn
Unique: fundamental understanding of lots of data
GAN basics
1- Events – precision theory predictions
2- Inverting – precision simulations
– precision measurements
⇒ What’s needed to keep the edge?
Event generation towards HL-LHC
– simulated event numbers scaling with the expected events [factor 25]
– general move to NLO/NNLO as standard [5% error]
– higher relevant final-state multiplicities [jet recoil, extra jets, WBF, etc.]
– additional low-rate high-multiplicity backgrounds
– specific precision predictions not available in standard generators [N3 LO in MC?]
– interpretation of measurements with general signal hypothesis [jets+MET]Generative
Networks Simulations for future LHC runs
Tilman Plehn
Unique: fundamental understanding of lots of data
GAN basics
1- Events – precision theory predictions
2- Inverting – precision simulations
– precision measurements
⇒ What’s needed to keep the edge?
Event generation towards HL-LHC
– simulated event numbers scaling with the expected events [factor 25]
– general move to NLO/NNLO as standard [5% error]
– higher relevant final-state multiplicities [jet recoil, extra jets, WBF, etc.]
– additional low-rate high-multiplicity backgrounds
– specific precision predictions not available in standard generators [N3 LO in MC?]
– interpretation of measurements with general signal hypothesis [jets+MET]
Three ways to use ML
– improve current tools: iSherpa, ML-MadGraph, etc
– new ideas, like fast ML-generator-networks
– conceptual ideas in theory simulations and analysesGenerative
Networks GAN algorithm
Tilman Plehn
Generating events
GAN basics
1- Events – training: true events {xT }
2- Inverting
output: generated events {r } → {xG }
– discriminator constructing D(x) by minimizing [classifier D(x) = 1, 0 true/generator]
LD = − log D(x) xT
+ − log(1 − D(x)) xG
– generator constructing r → xG by minimizing [D needed]
LG = − log D(x) xG
– equilibrium D = 0.5 ⇒ LD = LG = 1
⇒ statistically independent copy of training eventsGenerative
Networks GAN algorithm
Tilman Plehn
Generating events
GAN basics
1- Events – training: true events {xT }
2- Inverting
output: generated events {r } → {xG }
– discriminator constructing D(x) by minimizing [classifier D(x) = 1, 0 true/generator]
– generator constructing r → xG by minimizing [D needed]
⇒ statistically independent copy of training events
Generative network studies [review 2008.08558]
– Jets [de Oliveira (2017), Carrazza-Dreyer (2019)]
– Detector simulations [Paganini (2017), Musella (2018), Erdmann (2018), Ghosh (2018), Buhmann (2020)]
– Events [Otten (2019), Hashemi, DiSipio, Butter (2019), Martinez (2019), Alanazi (2020), Chen (2020), Kansal (2020)]
– Unfolding [Datta (2018), Omnifold (2019), Bellagente (2019), Bellagente (2020)]
– Templates for QCD factorization [Lin (2019)]
– EFT models [Erbin (2018)]
– Event subtraction [Butter (2019)]
– Sherpa [Bothmann (2020), Gao (2020)]
– Basics [GANplification (2020), DCTR (2020)]
– Unweighting [Verheyen (2020), Backes (2020)]
– Superresolution [DiBello (2020), Blecher (2020)]Generative
Networks GANplification
Tilman Plehn
Gain beyond training data [Butter, Diefenbacher, Kasieczka, Nachman, TP]
GAN basics
1- Events – true function known 0.18
compare GAN vs sampling vs fit 10 quantiles truth
2- Inverting 0.16 GAN trained on 100 data points fit
Sample
– quantiles with χ2 -values 0.14 GAN
0.12
0.10
p(x)
0.08
0.06
0.04
0.02
0.00 8 6 4 2 0 2 4 6 8
xGenerative
Networks GANplification
Tilman Plehn
Gain beyond training data [Butter, Diefenbacher, Kasieczka, Nachman, TP]
GAN basics
1- Events – true function known 0.18
compare GAN vs sampling vs fit 10 quantiles truth
2- Inverting 0.16 GAN trained on 100 data points fit
Sample
– quantiles with χ2 -values 0.14 GAN
0.12
– fit like 500-1000 sampled points
0.10
GAN like 500 sampled points [amplifictation factor 5]
p(x)
0.08
requiring 10,000 GANned events
0.06
0.04
0.02
0.00 8 6 4 2 0 2 4 6 8
x
50 quantiles
GAN 100 data points
quantile MSE
sample
10 2 200
300
fit
101 102 103 104 105 106
number GANedGenerative
Networks GANplification
Tilman Plehn
Gain beyond training data [Butter, Diefenbacher, Kasieczka, Nachman, TP]
GAN basics
1- Events – true function known 0.18
compare GAN vs sampling vs fit 10 quantiles truth
2- Inverting 0.16 GAN trained on 100 data points fit
Sample
– quantiles with χ2 -values 0.14 GAN
0.12
– fit like 500-1000 sampled points
0.10
GAN like 500 sampled points [amplifictation factor 5]
p(x)
0.08
requiring 10,000 GANned events
0.06
– 5-dimensional Gaussian shell 0.04
sparsely populated 0.02
amplification vs quantiles 0.00 8 6 4 2 0 2 4 6 8
x
– fit-like additional information
– interpolation and resolution the key [NNPDF]
200
⇒ GANs enhance training data
GAN amplification factor
150
100
50
0
3 4 5 6 7 8 9 10
quantiles per dimensionGenerative
Networks How to GAN LHC events
Tilman Plehn
Idea: replace ME for hard process [Butter, TP, Winterhalder]
GAN basics
1- Events – medium-complex final state t t̄ → 6 jets
2- Inverting t/t̄ and W ± on-shell with BW 6 × 4 = 18 dof
on-shell external states → 12 dof [constants hard to learn]
– flat observables flat [phase space coverage okay]
– direct observables with tails [statistical error indicated]
– constructed observables similar
3
⇥10
6.0 True
[GeV 1]
GAN
4.0
dpT,t
2.0
1 d
0.0
1.2
GAN
True
1.0
0.8
1.0 pT,t [GeV]
Ntail
20%
p1
0.1
0 50 100 150 200 250 300 350 400
pT,t [GeV]Generative
Networks How to GAN LHC events
Tilman Plehn
Idea: replace ME for hard process [Butter, TP, Winterhalder]
GAN basics
1- Events – medium-complex final state t t̄ → 6 jets
2- Inverting t/t̄ and W ± on-shell with BW 6 × 4 = 18 dof
on-shell external states → 12 dof [constants hard to learn]
– flat observables flat [phase space coverage okay]
– direct observables with tails [statistical error indicated]
– constructed observables similar 1M true events ×101
3
– improved resolution [1M training events]
5.0
2
4.0
1
φ j2
0 3.0
−1 2.0
−2
1.0
−3
−3 −2 −1 0 1 2 3
φ j1Generative
Networks How to GAN LHC events
Tilman Plehn
Idea: replace ME for hard process [Butter, TP, Winterhalder]
GAN basics
1- Events – medium-complex final state t t̄ → 6 jets
2- Inverting t/t̄ and W ± on-shell with BW 6 × 4 = 18 dof
on-shell external states → 12 dof [constants hard to learn]
– flat observables flat [phase space coverage okay]
– direct observables with tails [statistical error indicated]
– constructed observables similar 10M generated events ×102
3
– improved resolution [10M generated events]
3.5
2
1 3.0
φ j2
0 2.5
−1 2.0
−2
1.5
−3
−3 −2 −1 0 1 2 3
φ j1Generative
Networks How to GAN LHC events
Tilman Plehn
Idea: replace ME for hard process [Butter, TP, Winterhalder]
GAN basics
1- Events – medium-complex final state t t̄ → 6 jets
2- Inverting t/t̄ and W ± on-shell with BW 6 × 4 = 18 dof
on-shell external states → 12 dof [constants hard to learn]
– flat observables flat [phase space coverage okay]
– direct observables with tails [statistical error indicated]
– constructed observables similar 50M generated events ×103
3 1.8
– improved resolution [50M generated events]
– Proof of concept 2 1.6
1 1.4
φ j2
0
1.2
−1
1.0
−2
0.8
−3
−3 −2 −1 0 1 2 3
φ j1Generative
Networks Chemistry of loss functions
Tilman Plehn
GAN version of adaptive sampling
GAN basics
1- Events – generally 1D features
2- Inverting phase space boundaries
kinematic cuts
invariant masses [top, W ]
– batch-wise comparison of distributions, MMD loss with kernel k
2 0 0
MMD = k(x, x ) xT ,x 0
+ k(y, y ) yG ,y 0
− 2 k(x, y) xT ,yG
T G
2
LG → LG + λG MMD ,Generative
Networks Chemistry of loss functions
Tilman Plehn
GAN version of adaptive sampling
GAN basics
1- Events – generally 1D features
2- Inverting phase space boundaries
kinematic cuts
invariant masses [top, W ]
– batch-wise comparison of distributions, MMD loss with kernel k
2 0 0
MMD = k(x, x ) xT ,x 0
+ k(y, y ) yG ,y 0
− 2 k(x, y) xT ,yG
T G
2
LG → LG + λG MMD ,
×10−1 ×10−1
True True
4.0 Breit-Wigner 4.0 ΓSM
1
Gauss 4 ΓSM
3.0 No MMD 3.0 4ΓSM
[GeV−1]
[GeV−1]
2.0 2.0
σ dmt
σ dmt
1 dσ
1 dσ
1.0 1.0
0.0 0.0
160 165 170 175 180 185 160 165 170 175 180 185
mt [GeV] mt [GeV]Generative
Networks Unweighting
Tilman Plehn
Gaining beyond GANpliflication [Butter, TP, Winterhalder; Clausius’ talk]
GAN basics
1- Events – phase space sampling: weighted events [PS weight ×|M|2 ]
2- Inverting events: constant weights
– probabilistic unweighting weak spot of standard MC
– learn phase space patterns [density estimation]
generate unweighted events [through loss function]
– compare training, GAN, classic unweighting
Train
10−1
Unweighted
−2 uwGAN
10
σ dEµ−
10−3
1 dσ
10−4
10−5
10−6
2.0
1.5
Truth
X
1.0
0.5
0 1000 2000 3000 4000 5000 6000
Eµ− [GeV]Generative
Networks How to GAN away detector effects
Tilman Plehn
Goal: invert Markov processes [Bellagente, Butter, Kasiczka, TP, Winterhalder]
GAN basics
1- Events – detector simulation typical Markov process
2- Inverting – inversion possible, in principle [entangled convolutions]
– GAN task
DELPHES GAN
partons −→ detector −→ partons
⇒ Full phase space unfolded
Conditional GAN
– map random numbers to parton level
hadron level as condition [matched event pairs]Generative
Networks Detector unfolding
Tilman Plehn
Reference process pp → ZW → (``) (jj)
GAN basics
1- Events – broad jj mass peak
2- Inverting
narrow `` mass peak
modified 2 → 2 kinematics
fun phase space boundaries
– GAN same as event generation [with MMD]
Simple application
2 1
⇥10 ⇥10
2.5 Truth 3.0 Truth
FCGAN FCGAN
2.0 2.5
[GeV 1]
[GeV 1]
Delphes Delphes
2.0
1.5
1.5
dpT,j1
dmjj
1.0
1 d
1 d
1.0
0.5 0.5
0.0 0.0
1.2 1.2
FCGAN
FCGAN
Truth
Truth
1.0 1.0
0.8 0.8
0 25 50 75 100 125 150 175 200 70.0 72.5 75.0 77.5 80.0 82.5 85.0 87.5 90.0
pT,j1 [GeV] mjj [GeV]Generative
Networks Detector unfolding
Tilman Plehn
Reference process pp → ZW → (``) (jj)
GAN basics
1- Events
– broad jj mass peak
narrow `` mass peak
2- Inverting
modified 2 → 2 kinematics
fun phase space boundaries
– GAN same as event generation [with MMD]
Simple application
– detector-level cuts [14%, 39% events, no interpolation, MMD not conditional]
pT ,j1 = 30 ... 50 GeV pT ,j2 = 30 ... 40 GeV pT ,`− = 20 ... 50 GeV (12)
pT ,j1 > 60 GeV (13)
2 1
⇥10 ⇥10
4.0
6.0 Truth Truth
FCGAN 3.5 FCGAN
5.0 Eq.(12) 3.0 Eq.(12)
Eq.(13) Eq.(13)
4.0 2.5
dpT,j1
dmjj
2.0
1 d
1 d
3.0
1.5
2.0
1.0
1.0 0.5
0.0 0.0
0 25 50 75 100 125 150 175 200 70.0 72.5 75.0 77.5 80.0 82.5 85.0 87.5 90.0
pT,j1 [GeV] mjj [GeV]Generative
Networks Detector unfolding
Tilman Plehn
Reference process pp → ZW → (``) (jj)
GAN basics
1- Events
– broad jj mass peak
narrow `` mass peak
2- Inverting
modified 2 → 2 kinematics
fun phase space boundaries
– GAN same as event generation [with MMD]
Simple application
– detector-level cuts [14%, 39% events, no interpolation, MMD not conditional]
pT ,j1 = 30 ... 50 GeV pT ,j2 = 30 ... 40 GeV pT ,`− = 20 ... 50 GeV (12)
pT ,j1 > 60 GeV (13)
−3
– model dependence of unfolding ×10
6.0 Truth (W’)
– train: SM events FCGAN
test: 10% events with W 0 in s-channel 5.0 Truth (SM)
[GeV−1]
⇒ Working fine, but ill-defined 4.0
3.0
σ dm``jj
1 dσ 2.0
1.0
0.0
600 800 1000 1200 1400 1600 1800 2000
m``jj [GeV]Generative
Networks Unfolding as inverting
Tilman Plehn
Invertible networks [Bellagente, Butter, Kasieczka, TP, Rousselot, Winterhalder, Ardizzone, Köthe]
GAN basics
1- Events – network as bijective transformation — normalizing flow
2- Inverting Jacobian tractable — normalizing flow
evaluation in both directions — INN [Ardizzone, Rother, Köthe]
– building block: coupling layer
– conditional: parton-level events from {r }Generative
Networks Unfolding as inverting
Tilman Plehn
Invertible networks [Bellagente, Butter, Kasieczka, TP, Rousselot, Winterhalder, Ardizzone, Köthe]
GAN basics
1- Events
– network as bijective transformation — normalizing flow
2- Inverting
Jacobian tractable — normalizing flow
evaluation in both directions — INN [Ardizzone, Rother, Köthe]
– building block: coupling layer
– conditional: parton-level events from {r }
Properly defined unfolding [again pp → ZW → (``) (jj)]
– performance on distributions like FCGAN
– parton-level probability distribution for single detector event
⇒ Proper statistical unfolding
single detector event
3200 unfoldings 1.0
1.4 FCGAN
Parton Truth
1.2 0.8
events normalized
fraction of events
1.0
0.6
0.8
FCGAN
eINN
0.6 0.4
0.4 N
0.2 N
cINN eINN cI
0.2
0.0 0.0
10 15 20 25 30 35 40 45 50 0.0 0.2 0.4 0.6 0.8 1.0
pT,q1 [GeV] quantile pT, q1Generative
Networks Unfolding as inverting
Tilman Plehn
Invertible networks [Bellagente, Butter, Kasieczka, TP, Rousselot, Winterhalder, Ardizzone, Köthe]
GAN basics
1- Events
– network as bijective transformation — normalizing flow
2- Inverting
Jacobian tractable — normalizing flow
evaluation in both directions — INN [Ardizzone, Rother, Köthe]
– building block: coupling layer
– conditional: parton-level events from {r }
Unfolding initial-state radiation
– detector-level process pp → ZW +jets [variable number of objects]
– parton-level hard process chosen 2 → 2 [whatever you want]
– ME vs PS jets decided by network [including momentum conservation]
2 jet
2 jet
104 3 jet
3 jet
4 jet
10−2 4 jet
[GeV−1 ]
[GeV−1 ]
103
σ d px / |px|
1 P dσP
σ dpT,q1
1 dσ
10−3
102
10−4 101
20 40 60 80 100 120 140 -2.0 -1.5 -1.0 P
-0.5 P 0.0 0.5 1.0 1.5 2.0
pT,q1 [GeV] px / |px | [GeV]
×10−4Generative
Networks Unfolding as inverting
Tilman Plehn
Invertible networks [Bellagente, Butter, Kasieczka, TP, Rousselot, Winterhalder, Ardizzone, Köthe]
GAN basics
1- Events – network as bijective transformation — normalizing flow
2- Inverting
Jacobian tractable — normalizing flow
evaluation in both directions — INN [Ardizzone, Rother, Köthe]
– building block: coupling layer
– conditional: parton-level events from {r }
Unfolding initial-state radiation
– detector-level process pp → ZW +jets [variable number of objects]
– parton-level hard process chosen 2 → 2 [whatever you want]
– ME vs PS jets decided by network [including momentum conservation]
⇒ How systematically can we invert?Generative
Networks Outlook
Tilman Plehn
Machine learning for LHC theory
GAN basics
1- Events – goal: data-to-data with fundamental physics input
2- Inverting – MC challenges
higher-order precision in bulk
coverage of tails
unfolding to access fundamental QCD
– neural network benefits
best available interpolation
training on MC and/or data, anything goes
lightning speed, once trained
– GANs the cool kid
generator trying to produce best events
discriminator trying to catch generator,
– INNs the theory hope
flow networks to control spaces
invertible network the new tool
Any ideas?Generative
Networks Backup: How to GAN event subtraction
Tilman Plehn
Idea: subtract samples without binning [Butter, TP, Winterhalder]
GAN basics
1- Events – statistical uncertainty q
2- Inverting ∆B−S = ∆2B + ∆2S > max(∆B, ∆S)
– applications in LHC physics
soft-collinar subtraction, multi-jet merging
on-shell subtraction
background/signal subtraction
– GAN setup
1. differential, steep class label
2. sample normalizationGenerative
Networks Subtracted events
Tilman Plehn
How to beat statistics by subtracting
GAN basics
1- Events 1– 1D toy example
2- Inverting
1 1
PB (x) = + 0.1 PS (x) = ⇒ PB−S = 0.1
x x
– statistical fluctuations reduced (sic!)
100 0.13
GAN vs Truth (B − S)GAN
B (B − S)Truth ± 1σ
0.12
S
B−S
10−1 0.11
P (x)
P (x)
0.10
10−2 0.09
0.08
0 25 50 75 100 125 150 175 200 0 25 50 75 100 125 150 175 200
x xGenerative
Networks Subtracted events
Tilman Plehn
How to beat statistics by subtracting
GAN basics
1- Events 1– 1D toy example
2- Inverting
1 1
PB (x) = + 0.1 PS (x) = ⇒ PB−S = 0.1
x x
– statistical fluctuations reduced (sic!)
2– event-based background subtraction [weird notation, sorry]
+ − + − + −
pp → e e (B) pp → γ → e e (S) ⇒ pp → Z → e e (B-S)
⇥101
GAN vs Truth
2.0 B
S
[pb/GeV]
1.5 B S
1.0
dEe
d
0.5
0.0
20 40 60 80 100
Ee [GeV]Generative
Networks Subtracted events
Tilman Plehn
How to beat statistics by subtracting
GAN basics
1- Events 1– 1D toy example
2- Inverting
1 1
PB (x) = + 0.1 PS (x) = ⇒ PB−S = 0.1
x x
– statistical fluctuations reduced (sic!)
2– event-based background subtraction [weird notation, sorry]
+ − + − + −
pp → e e (B) pp → γ → e e (S) ⇒ pp → Z → e e (B-S)
3– collinear subtraction [assumed non-local]
pp → Zg (B: matrix element, S: collinear approximation)
GAN vs Truth
101 B
S
[pb/GeV]
0 B−S
10
10−1
dpT,g
dσ
10−2
0 20 40 60 80 100
pT,g [GeV]
⇒ Applications in theory and analysisYou can also read

















































