Hate Classifier for Social Media Platform Using Tree LSTM
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
ITM Web of Conferences 44, 03034 (2022) https://doi.org/10.1051/itmconf/20224403034
ICACC-2022
Hate Classifier for Social Media Platform Using Tree LSTM
Sahil Raut1, Nikhil Mhatre1, Sanskar Jha1 and Aditi Chhabria1
1Department of Computer Engineering, Ramrao Adik Institute of Technology, DY Patil Deemed to be University, Nerul(E), Navi Mumbai,
India
Abstract. Social-media without a doubt is one of the most noteworthy developments ever. From associating with individuals across
the globe for sharing of data and information in an infinitesimal of a second, online media stages have enormously altered the method
of our lives. This is joined by a steadily expanding utilization of social media, less expensive cell phones, and the simplicity of web
access which have additionally prepared for the huge development of social media. To place this into numbers, according to an ongoing
report, billions of individuals all over the planet presently utilize web-based media every month, and a normal amount of almost 2
million people new clients are going along with them consistently. While web-based media stages have permitted us to interface with
others and fortify connections in manners that were not conceivable previously. Unfortunately, they have additionally turned into the
default gatherings for can’t stand discourse. Online hate is a wild issue, with the adverse result of disallowing client support in web-
based conversations and causing mental mischief to people. Since hate is pervasive across friendly, media stages, our objective was to
foster a classifier that is feasible to train classifiers that can identify hateful remarks with strong execution and with the portion of
misleading up-sides and negatives staying inside sensible limits.
Keywords. Hate-speech, Twitter, Feature-extraction, Cyberbullying, Personal attacks.
1. Introduction
2. Literature Survey
Cyberbullying and forceful language on friendly stages are
a portion of the maladies of our cutting-edge time. The right Web-based media organizations can straightforwardly
to speak freely of discourse online can without much of a report occurrences to the police, yet most badgering is
stretch wreck into hostile, outlandish and non-productive passed on to the casualty to report. Twitter will give a
analysis towards sexual, political, and strict convictions. AI rundown email of connections to messages that can be sent
classifiers and the abundance of information accessible on to the police, while Facebook has no such framework set
friendly stages offer a legitimate arrangement to alleviate up.[5] Online media stages can be utilized by individuals
this issue.[1] Disdain discourse’s definition as taken from secretly or with counterfeit profiles, with minimal in
Cambridge Dictionary: public discourse that communicates method of confirmation. Despite the fact that they regularly
disdain or energizes viciousness towards an individual or give approaches to hailing hostile and scornful substance,
gathering dependent on something like race, religion, sex, as per different studies it is observed that main 17% of all
or sexual direction. [2] Notwithstanding this definition, it is grown-ups have hailed hassling discussion, though just
likewise generally realized that disdain discourse is more 12% of grown-ups have revealed somebody for such
ruinous when it spreads through the media and underlines demonstrations.[6] We experience disdain discourse in each
that disdain discourse is an extreme danger to majority part of life, sadly. It is much more testing to manage its
rules system, multiculturalism, and pluralism. The primary damaging impacts in the advanced world. Individuals
objective of this task is to assemble a model equipped for might act all the more forcefully via web-based media since
recognizing disdain discourse.[3] In this task, a progression they can be mysterious, their messages can arrive at a huge
of classifiers, for example, Logistic Regression, SVM, and openness, and for some different reasons. At the point when
BERT was prepared on 25000 thousand tweets human- we incorporate the messages posted by bots and phony
named as hostile or not hostile. The 25000 tweets were records, disdain discourse turns out to be too normal to ever
gathered by consolidating two unique datasets. A vital test be distinguished and directed physically.[7] Meanings of
for programmed disdain discourse discovery via online online disdain: Instead of one single common meaning, the
media is the partition of disdain discourse from different writing is contained with numerous definitions with
occurrences of hostile language.[4] We use public support particular ways to deal with online disdain.
to present a reference of these tweets into three classes:
ones containing disdain discourse, just hostile language,
and the other ones with neither or them. Then we build a
multiclass classifier in order to understand the various
classifications. Close investigation of the expectations and
the mistakes depicts when we can isolate disdain discourse
from different hostile languages and when this separation
is more problematic. Then we track the bigot and
homophobic tweets which are bound to be delegated
disdain discourse.
© The Authors, published by EDP Sciences. This is an open access article distributed under the terms of the Creative Commons Attribution
License 4.0 (http://creativecommons.org/licenses/by/4.0/).ITM Web of Conferences 44, 03034 (2022) https://doi.org/10.1051/itmconf/20224403034
ICACC-2022
order model Waseem et al. given an informational index of
16,000 tweets and they additionally examined which
elements give the best presentation with regards to the
arrangement of disdain talks. Likewise, there are a lot of
works done where scientists take open-source information
and attempt to foster models which are utilized to recognize
scornful messages on interpersonal interaction locales.[13]
Additionally, the shortfall of comprehensive classifiers
suggests that the results across studies and online
entertainment stages are not successfully same. Despite the
fact that disdain has been seen as an issue in different
internet-based web-based entertainment stages, including
Reddit, Twitter, YouTube, etc., aside from a couple of
exploratory investigations, there is an absence of
improvement and testing of models utilizing information
from numerous web-based entertainment stages. In
aggregate, the fracture of models and component portrayals
unnecessarily confounds disdain location across various
stages and settings. Additionally, attempting to seem OK of
the information with catchphrase-based look doesn't give
right outcomes because of the language's design and types
of articulation, like incongruity. In a climate where even the
greatest news sources on the planet are at times compelled
to cripple remarks on delicate recordings they distribute on
YouTube, it is beyond difficult to physically battle disdain
discourse for organizations and different associations with
Table 1: Definition of Online Hate [8] more restricted assets. Hence, it is unavoidable to depend
on strategies that naturally detect disdain discourse.
The issue of distinguishing disdain discourse has been
tended to by different analysts in various ways. As a rule, 3. Proposed Methodology
the issue can be tended to in various ways. One of the
potential ways is to foster an unadulterated Natural
Language Processing model, which is for the most part a
solo model. Thus, the identification turns out to be similarly
simpler as there is no requirement for a marked
informational index.[9] In this methodology, an NLP model
can be planned which orders whether or not a sentence
contains disdain discourse. In writing, there are less works
that were completed completely dependent on
unadulterated NLP-based ideas. One of the likely reasons
is the models are relatively slower than the models
fabricated utilizing Machine Learning or Deep Learning
Models. The AI and profound learning models for the
identification of disdain discourse need a named
informational collection that is utilized to prepare the
model.[10]
A lot of explores have been completed in this space
where the analysts made their own dataset. The overall
technique is to gather the information from a person-to-
person communication site clean the information and
afterward get them explained by a group of specialists who
physically comment on if a message contains a derisive
message or not. Khan et al. led a thorough review of AI
models utilized broadly in NLP.[11] Ahmed et al. fostered a
dataset that comprises of English and Bengali blended texts
and commented on the tweets as disdain discourse or non-
disdain discourse. Sahi et al. fostered an administered
learning model to distinguish disdain discourse against Fig 1: Architecture of Hate Classification Model
ladies in the Turkish language. They gathered tweets
referencing the apparel selections of ladies and utilized this The proposed methodology is to examine methods utilized
information to prepare the AI models.[12] Waseem in disdain discourse checking and select the best
inspected the impact of annotators’ information on the appropriate procedure for making an altered disdain
2ITM Web of Conferences 44, 03034 (2022) https://doi.org/10.1051/itmconf/20224403034
ICACC-2022
discourse discovery model to foster an application that will BERT has boundlessly beaten past models, for instance, the
consolidate disdain discourse watchwords for order, allow GPT and ELMo which stands for Generative Pretrained
the client to prepare his decision of dataset on the model Transformer and Embeddings from Language Models
and afterward breeze through on the assessment respectively.
information to actually take a look Sat its level of
repulsiveness. To exhibit and test the application while 3.2.4 Long Short-Term Memory (LSTM)
giving investigation on the disdain discourse results from
the dataset transferred. These are exceptional kinds of neural organizations which
are intended to function admirably when one has
3.1 Word Embeddings arrangement informational index and there exists a drawn-
out reliance. These organizations can be helpful when one
Word embeddings are numerical depictions of words that necessity an organization to recall data for a more extended
work with language and understands it by mathematical enough said. This element makes LSTM appropriate for
computations. They rely upon a vector space model that handling printed information. [17] A LSTM is an assortment
gets the general similarity among person word vectors, in of comparable cells, though every cell processes the info in
this way giving information on the essential significance a particular methodology. Aside from the contribution from
of words. Subsequently, word embeddings are by and outside sources, every cell likewise gets inputs from its
large used for text portrayal and online hatred previous cell in the chain.
acknowledgment. Previous works have shown that
unmistakable pre-arranged word embeddings perform 3.2.5 Tree LSTM
well with respect to hate speech. For this undertaking, we
picked the Word2Vec model to get the word embeddings. Ordinary type of LSTMs can recollect or allude to the data
which it has navigated till now. Be that as it may it doesn't
3.2 Training Models have any proof about the data present after the point crossed
till the point. This turns into a significant disadvantage
3.2.1 Logistic Regression (LR) while managing grouping information, particularly text.
Tree LSTM is one more form of LSTM which can recall
The choice of logistic regression (LR) is upheld by its the data from the two bearings. In Tree LSTM we
straightforwardness and generally expected use for text essentially back proliferation in two different ways. Once
grouping. Contingent upon the highlights, LR can acquire from the front and once from the back. This cycle makes
great outcomes in internet-based disdain identification Tree LSTM a strong apparatus for examining printed
with low model intricacy. Accordingly, including LR information.
when contrasting various models appears to be sane. As of late, Bisht et al., proposed a solitary LSTM layer as a
Ordinary AI classifiers such as direct relapses models basic model for distinguishing hostile language and disdain
have likewise been utilized to actually identify oppressive discourse in twitter information. The review utilized pre-
web-based language. [14] prepared word2vec for contribution to one layer LSTM.
They observed that word2vec+Tree LSTM performed
3.2.2 Support-Vector Machine (SVM) better contrasted with word2vec+LSTM. It likewise
proposed LSTM and Tree LSTM with blend of pre-
Support vector machines (SVM) is one more estimation prepared word vectors as the conveyed word portrayal. In
commonly used in text portrayal. The impulse of SVMs is their work, they call attention to that Tree LSTM has a
to view as a hyperplane that helps the insignificant distance superior F1 score for foreseeing disdain content. [18]
between the classes. The cases portraying this plane are Hence, the justification behind picking Tree LSTM model
known as help vectors. Basically, previous works like Xu is that it functions admirably with successive information,
et al., Nobata et al., have investigated unique roads in where the model requirements to protect the setting of long-
regards to SVM for hatred acknowledgment with great grouping. CNN experiences disappearing and detonating
results. [15] The computational multifaceted nature of slopes issues when the mistake of the angle drop
Support vector machines is lower differentiated with calculation is backpropagated through the organization,
significant learning models, which also gives clearer which creates CNN cannot recall all input history
interpretability. successfully. Be that as it may, rather Tree LSTM saves
long haul conditions in a more powerful manner.
3.2.3 Bidirectional Encoder Representations from
Transformers (BERT) + Convolutional Neural
Network (CNN)
Transformers transform one course of action into one more
by clearing out any rehash and supplanting it with an
extensive part to manage conditions between the data and
yield of the structure. With this plan, a model can be
arranged all the all the more gainfully in view of the finish
of progressive dependence on the past words, extending
sufficiency for showing long stretch circumstances. [16]
3ITM Web of Conferences 44, 03034 (2022) https://doi.org/10.1051/itmconf/20224403034
ICACC-2022
4. Results and Simulation
The overall structure is divided into 6 main parts: Data
Cleaning, Training of Models, Displaying results of each
model with its accuracy. Testing the built model over input
dataset, predicting offensiveness of input statement,
classifying statistically all the hate and non-hate tweets
present in the dataset.
Table 3: Dataset Cleaning
4.3 Data Pre-Processing
Fig 2: System Design
The following are altogether the preprocessing steps:
Lowering of all words in the Tweets, removing of copies,
4.1 Dataset
eliminating re-tweets, removing exceptional characters
what's more estimating tweets' length, reformatting all
This dataset is made accessible for naming and gives a
spaces and hashtags, removing stop words and additionally
definite portrayal of the information assortment standards.
words more limited than 3 characters, dropping
The dictionary, gathered from Hate-base, contains words
unnecessary columns and saving last information outline.
and expressions recognized by web clients as disdain
discourse. This dictionary was additionally utilized by the
4.4 Results
creators as catchphrases to separate the 85.4 M tweets. The
assignment was to comment on the tweet with one of three
classes: disdain discourse, hostile however not disdain
discourse, or neither hostile nor disdain discourse. The
tweets with no larger part class were disposed of, making a
sum of 24,802 tweets with a doled-out mark of which 5
percent was given the contemptuous name. In this way, we
needed to use the Twitter API to remember the dataset. We
had the option to get 24,783 tweets (99.9 percent of the first
dataset), with 19 tweets either erased or in any case
inaccessible.
4.2 Data Cleaning
We as a whole understand that prior to applying any
machine learning (ML) model we really want to make our Fig 3: Confusion matrix of Tree LSTM model
dataset prepared for a possible examination. This
progression is especially pertinent when we manage texts. As indicated by confusion matrix, we see that practically
Most words, truth be told, are generally horrible to group 40% of disdain discourse is misclassified: the accuracy and
forceful sentences. recall scores for the disdain class are 0.44 and 0.61
individually. The majority of the misclassification happens
in the upper half of this matrix, proposing that the model is
one-sided towards ordering tweets as less contemptuous or
hostile than the human coders. Far less tweets are named
4ITM Web of Conferences 44, 03034 (2022) https://doi.org/10.1051/itmconf/20224403034
ICACC-2022
more hostile or contemptuous than their actual pragmatic significance since this will be utilized as a
classification; roughly 5% of hostile and 2% of harmless pattern study to think about impending investigates inside
tweets have been incorrectly named can't stand discourse. various programmed text characterization techniques for
programmed disdain discourse identification. There is
still a lot of work to be done in the field of disdain
discourse assessment. It is conceivable that a huge
improvement in execution would be checked whether
word portrayals were utilized rather than character
portrayals; a significant part of the jargon of online
correspondence and talk includes the utilization of
expressions, casual discourse, furthermore allegorical
language, which word-based portrayals could maybe
better catch. Moreover, twofold grouping in itself can be
considered as a restriction. Past examination has shown
that disdain has a scope of translations, and understanding
the setting of the remarks can be vital for disdain location.
Rather than paired order, some specialists have picked
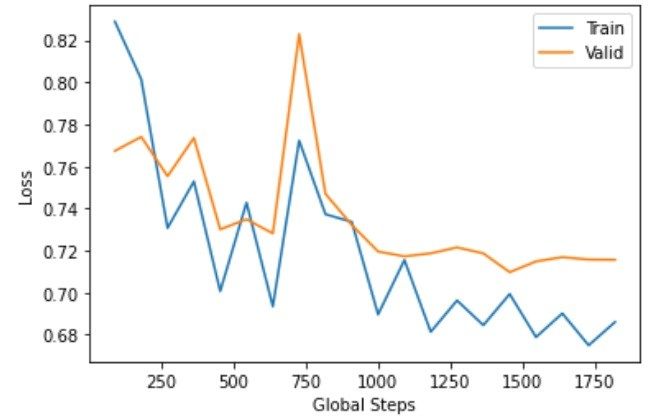
Fig 4: Train and Validation Loss Curve of Tree LSTM distinguishing can't stand targets furthermore more
model on the dataset nuanced classes of online disdain. Future improvement
endeavors incorporate preparation client explicit
information set on the prepared model and afterward
permitting the client to input any type of discourse and
accumulate its level of obnoxiousness.
6. References
[1] Kovács, G., Alonso, P. & Saini, R. “Challenges of
Hate Speech Detection in Social-Media”. SN
COMPUT. SCI. 2, 95 (2021).
https://doi.org/10.1007/s42979-021-00457-3
Table 4: Results of Various Different Models [2] V. Jain, V. Kumar, V. Pal and D. K. Vishwakarma,
“Detection of Cyberbullying on Social Media Using
In all analysis however, the least precision (0.66), recall Machine learning”. (2021).
(0.45), accuracy (45%) and F1 score (0.54) was found in https://ieeexplore.ieee.org/document/9418254
Logistic Regression model utilizing TFIDF highlights
portrayal with bigram highlights. Also, the highest recall [3] Salminen, J., Hopf, M., Chowdhury, S.A. et al.
(0.91), precision (0.92), accuracy (92%) and F1 score “Developing an online hate classifier for multiple
(0.91) were gotten by Tree LSTM utilizing TFIDF social media platforms”. (2020). https://hcis-
highlights portrayal with bigram highlights. In feature journal.springeropen.com/articles/10.1186/s13673-
representation, bigram highlights with TFIDF acquired 019-0205-6
the best execution when contrasted with Word2vec and
Doc2vec. [4] Venkateshwarlu Konduri, Sarada Padathula, Asish
Pamu and Sravani Sigadam, “Hate Speech
5. Conclusion Classification of social media posts using Text
Analysis and Machine Learning”. Paper 5204, (2020).
This study utilized computerized text order procedures to https://www.sas.com/content/dam/SAS/support/en/sas-
distinguish can't stand discourse messages. Additionally, global-forum-proceedings/2020/5204-2020.pdf
this study thought about two include designing methods
and five ML calculations (Logistic Regression, Support [5] Velioglu, Riza & Rose, Jewgeni., “Detecting Hate
Vector Machine, BERT and CNN, LSTM and Tree Speech in Memes” Using Multimodal Deep Learning
LSTM) to characterize disdain discourse messages. The Approaches: Prize-winning solution to Hateful Memes
exploratory results displayed that the bigram highlights, Challenge. (2020).
when addressed through Word2Vec, showed better https://www.researchgate.net/publication/347880819_
execution when contrasted with TFIDF highlight Detecting_Hate_Speech_in_Memes_Using_Multimod
designing strategies. In addition, SVM and BERT+CNN al_Deep_Learning_Approaches_Prize-
calculations showed better outcomes contrasted with LR. winning_solution_to_Hateful_Memes_Challenge
The most reduced exhibition was seen in LR. Also, the
best execution was found with Tree LSTM as the most [6] Hou, Y., Xiong, D., Jiang, T., Song, L., & Wang, Q.
effective portrayal of derisive web-based media remarks. “Social media addiction: Its impact, mediation, and
The results from this examination concentrate on hold intervention”. Cyberpsychology: Journal of
5ITM Web of Conferences 44, 03034 (2022) https://doi.org/10.1051/itmconf/20224403034
ICACC-2022
Psychosocial Research on Cyberspace, 13(1), Article [16] S. Asur and B. A. Huberman, “Predicting the Future
4. (2019). https://doi.org/10.5817/CP2019-1-4 with Social Media”. IEEE/WIC/ACM International
Conference on Web Intelligence and Intelligent Agent
[7] Kumar, R., Ojha, A.K., Malmasi, S., Zampieri, M, Technology, pp. 492-499, doi: 10.1109/WI-
“Benchmarking aggression identification in social IAT.2010.63. (2010),
media”. In: Proceedings of the First Workshop on https://ieeexplore.ieee.org/document/5616710
Trolling, Aggression and Cyberbullying (TRAC),
(2018) https://aclanthology.org/W18-4401.pdf [17] SongJie Gong. “A collaborative filtering
recommendation system algorithm based on user
[8] Zimmerman, Steven & Fox, Chris & Kruschwitz, Udo. clustering and item clustering”. Journal of Software,
“Improving Hate Speech Detection with Deep vol. 5, (2010).
Learning Ensembles”. (2018). http://www.jsoftware.us/vol5/jsw0507-9.pdf
https://www.researchgate.net/publication/326294340_I
mproving_Hate_Speech_Detection_with_Deep_Learni [18] Kristin P. Bennett and Erin J. Bredensteiner. “Duality
ng_Ensembles and Geometry in SVM Classifiers”. In In Proc. 17th
International Conf. on Machine Learning, pages 57–
[9] Samuel Gibbs. “What can be done about abuse on 64, (2000).
social media?” Guardian News & Media Limited, 12, http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.
(2017) 1.1.36.9635&rep=rep1&type=pdf
https://www.theguardian.com/media/2017/dec/13/what
-can-be-done-about-abuse-on-social-media
[10] Davidson, Thomas & Warmsley, Dana & Macy,
Michael & Weber, Ingmar, “Automated Hate Speech
Detection and the Problem of Offensive Language”.
(2017).
https://www.researchgate.net/publication/314942659_
Automated_Hate_Speech_Detection_and_the_Proble
m_of_Offensive_Language
[11] Gareth James, Daniela Witten, Trevor Hastie, and
Robert Tibshirani. “An Introduction to Statistical
Learning”. With Applications in R. Springer
Publishing Company, Incorporated, ISBN, (2014).
https://www.ime.unicamp.br/~dias/Intoduction%20to
%20Statistical%20Learning.pdf
[12] Bernd Hollerit, Mark Kr¨oll, and Markus Strohmaier.
“Towards linking buyers and sellers: Detecting
commercial intent on twitter”. Published in WWW '13
Companion 2013 Computer Science, (2013).
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.
1.1.402.3220&rep=rep1&type=pdf
[13] Ostrowski, David, “Semantic Filtering in social media
for Trend Modelling”. Proceedings - 2013 IEEE 7th
International Conference on Semantic Computing,
ICSC. 399-404.10.1109/ICSC.2013, 78. (2013)
https://ieeexplore.ieee.org/document/6693553
[14] Cheng Xiang Zhai, Charu C. Aggarwal. “Mining Text
Data”. Science + Business Media. Springer, (2012).
http://digilib.stmikbanjarbaru.ac.id/data.bc/7.%20Data
%20Mining/2012%20Mining%20Text%20Data.pdf
[15] K. Lee, D. Palsetia, R. Narayanan, M.M.A. Patwary,
A. Agrawal, and A. Choudhary. “Twitter trending
topic classification”. In Data Mining Workshops
(ICDMW). (2011)
http://cucis.ece.northwestern.edu/publications/pdf/Lee
Pal11.pdf
6You can also read

















































