Intelligent Architectures for Intelligent Computing Systems - Onur Mutlu February 2021 DATE ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Intelligent Architectures
for
Intelligent Computing Systems
Onur Mutlu
omutlu@gmail.com
https://people.inf.ethz.ch/omutlu
2 February 2021
DATE Special Session Invited Talk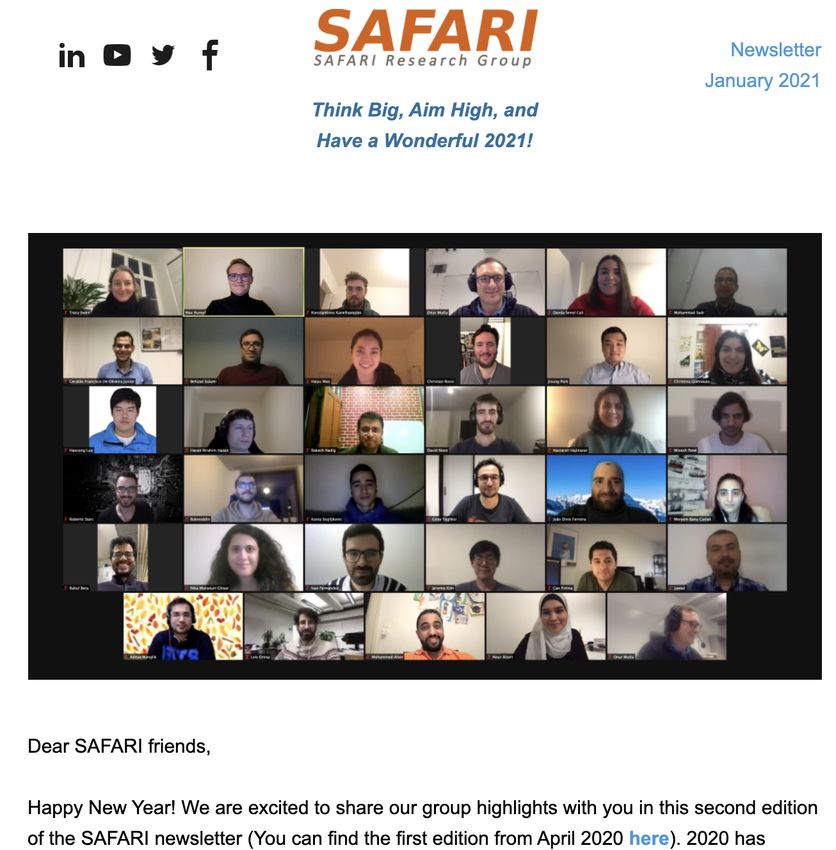
The Problem
Computing
is Bottlenecked by Data
2
Data is Key for Future Workloads In-memory Databases Graph/Tree Processing [Mao+, EuroSys’12; [Xu+, IISWC’12; Umuroglu+, FPL’15] Clapp+ (Intel), IISWC’15] In-Memory Data Analytics Datacenter Workloads [Clapp+ (Intel), IISWC’15; [Kanev+ (Google), ISCA’15] Awan+, BDCloud’15]

Data Overwhelms Modern Machines In-memory Databases Graph/Tree Processing [Mao+, EuroSys’12; [Xu+, IISWC’12; Umuroglu+, FPL’15] Clapp+ (Intel), IISWC’15] Data → performance & energy bottleneck In-Memory Data Analytics Datacenter Workloads [Clapp+ (Intel), IISWC’15; [Kanev+ (Google), ISCA’15] Awan+, BDCloud’15]

Data is Key for Future Workloads
Chrome TensorFlow Mobile
Google’s web browser Google’s machine learning
framework
Video Playback Video Capture
Google’s video codec Google’s video codec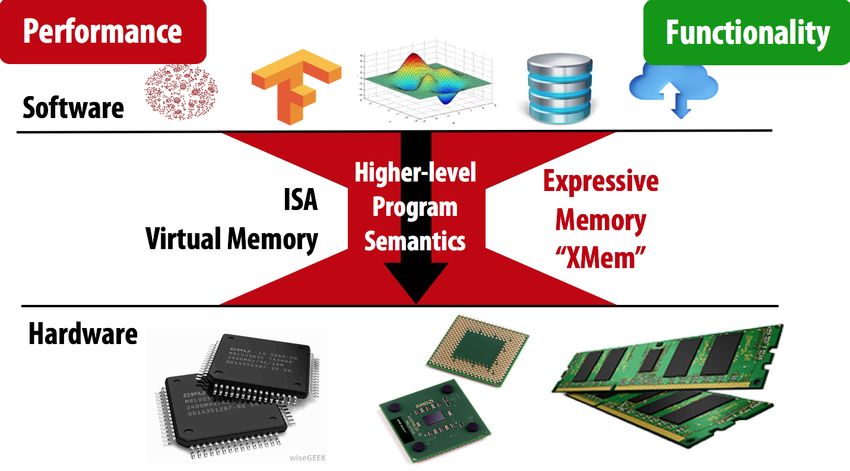
Data Overwhelms Modern Machines
Chrome TensorFlow Mobile
Google’s web browser Google’s machine learning
Data → performance & energy bottleneck
framework
Video Playback Video Capture
Google’s video codec Google’s video codec
Data is Key for Future Workloads
development of high-throughput
sequencing (HTS) technologies
Number of Genomes
Sequenced
http://www.economist.com/news/21631808-so-much-genetic-data-so-many-uses-genes-unzipped 7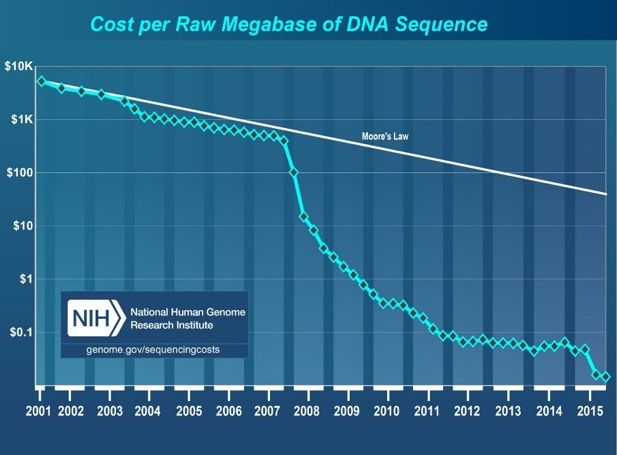
C CA TC AT TT AA AT
G C AC
A C G
T
C 0 1 2
AA 1 0 1 2
CC 2 1 0 1 2
TT 2 1 0 1 2
Billions of Short Reads AA 2 1 2 1 2
CCCCCCT AT AT AT ACGT ACT AGT ACGT TG 2 2 2 1 2
AA 3 2 2 2 2
ACGAC T T TAGT ACGT ACGT TA 3 3 3 2 3
T AT AT AT ACGT ACT AGT ACGT AC 4 3 3 2 3
CT 4 4 3 2
GT 5 4 3
ACGT ACG CCCCT ACGT A Short Read Read
T AT AT AT ACGT ACT AGT ACGT
Alignment
ACGAC T T TAGT ACGT ACGT
T AT AT AT ACGT ACT AAAGT ACGT
T AT AT AT ACGT ACT AGT ACGT
ACG T T T T TAAAACGT A
T AT AT AT ACGT ACT AGT ACGT
ACGAC GGGGAGT ACGT ACGT
... ...
Reference Genome
1 Sequencing Genome Read Mapping 2
Analysis
Data → performance & energy bottleneck
3 Variant Calling Scientific Discovery 4
New Genome Sequencing Technologies
Oxford Nanopore MinION
Senol Cali+, “Nanopore Sequencing Technology and Tools for Genome
Assembly: Computational Analysis of the Current State, Bottlenecks
and Future Directions,” Briefings in Bioinformatics, 2018.
[Open arxiv.org version]
9
New Genome Sequencing Technologies
Oxford Nanopore MinION
Senol Cali+, “Nanopore Sequencing Technology and Tools for Genome
Assembly: Computational Analysis of the Current State, Bottlenecks
Data → performance & energy bottleneck
and Future Directions,” Briefings in Bioinformatics, 2018.
[Preliminary arxiv.org version]
10Accelerating Genome Analysis
n Mohammed Alser, Zulal Bingol, Damla Senol Cali, Jeremie Kim, Saugata Ghose, Can
Alkan, and Onur Mutlu,
"Accelerating Genome Analysis: A Primer on an Ongoing Journey"
IEEE Micro (IEEE MICRO), Vol. 40, No. 5, pages 65-75, September/October 2020.
[Slides (pptx)(pdf)]
[Talk Video (1 hour 2 minutes)]
11GenASM Framework [MICRO 2020]
n Damla Senol Cali, Gurpreet S. Kalsi, Zulal Bingol, Can Firtina, Lavanya Subramanian, Jeremie S.
Kim, Rachata Ausavarungnirun, Mohammed Alser, Juan Gomez-Luna, Amirali Boroumand,
Anant Nori, Allison Scibisz, Sreenivas Subramoney, Can Alkan, Saugata Ghose, and Onur Mutlu,
"GenASM: A High-Performance, Low-Power Approximate String Matching
Acceleration Framework for Genome Sequence Analysis"
Proceedings of the 53rd International Symposium on Microarchitecture (MICRO), Virtual,
October 2020.
[Lighting Talk Video (1.5 minutes)]
[Lightning Talk Slides (pptx) (pdf)]
[Talk Video (18 minutes)]
[Slides (pptx) (pdf)]
12Data Overwhelms Modern Machines …
n Storage/memory capability
n Communication capability
n Computation capability
n Greatly impacts robustness, energy, performance, cost
13Data Movement Overwhelms Modern Machines
n Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul
Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, and Onur Mutlu,
"Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks"
Proceedings of the 23rd International Conference on Architectural Support for Programming
Languages and Operating Systems (ASPLOS), Williamsburg, VA, USA, March 2018.
62.7% of the total system energy
is spent on data movement
14Axiom
An Intelligent Architecture
Handles Data Well
15How to Handle Data Well
n Ensure data does not overwhelm the components
q via intelligent algorithms
q via intelligent architectures
q via whole system designs: algorithm-architecture-devices
n Take advantage of vast amounts of data and metadata
q to improve architectural & system-level decisions
n Understand and exploit properties of (different) data
q to improve algorithms & architectures in various metrics
16Corollaries: Architectures Today …
n Architectures are terrible at dealing with data
q Designed to mainly store and move data vs. to compute
q They are processor-centric as opposed to data-centric
n Architectures are terrible at taking advantage of vast
amounts of data (and metadata) available to them
q Designed to make simple decisions, ignoring lots of data
q They make human-driven decisions vs. data-driven decisions
n Architectures are terrible at knowing and exploiting
different properties of application data
q Designed to treat all data as the same
q They make component-aware decisions vs. data-aware
17Architectures for Intelligent Machines
Data-centric
Data-driven
Data-aware
18Data-Centric (Memory-Centric)
Architectures
19Data-Centric Architectures: Properties
n Process data where it resides (where it makes sense)
q Processing in and near memory structures
n Low-latency and low-energy data access
q Low latency memory
q Low energy memory
n Low-cost data storage and processing
q High capacity memory at low cost: hybrid memory, compression
n Intelligent data management
q Intelligent controllers handling robustness, security, cost
20Processing Data
Where It Makes Sense
21Goal: Processing Inside Memory
Memory
Processor Database
Core
Graphs
Cache
Media
Query
Interconnect
Results Problem
Algorithm
n Many questions … How do we design the: Program/Language
q compute-capable memory & controllers? System Software
q processor chip and in-memory units? SW/HW Interface
q software and hardware interfaces? Micro-architecture
Logic
q system software, compilers, languages?
Devices
q algorithms and theoretical foundations?
ElectronsMemory as an Accelerator
mini-CPU
CPU CPU core GPU GPU
(throughput) (throughput)
core core core core
video
core
GPU GPU
CPU CPU imaging
(throughput) (throughput)
Memory
core core core core
core
LLC
Specialized
Memory Controller compute-capability
in memory
Memory Bus
Memory similar to a “conventional” acceleratorProcessing in Memory:
Two Approaches
1. Minimally changing memory chips
2. Exploiting 3D-stacked memory
24Approach 1: Minimally Changing Memory
n DRAM has great capability to perform bulk data movement and
computation internally with small changes
q Can exploit internal connectivity to move data
q Can exploit analog computation capability
q …
n Examples: RowClone, In-DRAM AND/OR, Gather/Scatter DRAM
q RowClone: Fast and Efficient In-DRAM Copy and Initialization of Bulk Data
(Seshadri et al., MICRO 2013)
q Fast Bulk Bitwise AND and OR in DRAM (Seshadri et al., IEEE CAL 2015)
q Gather-Scatter DRAM: In-DRAM Address Translation to Improve the Spatial
Locality of Non-unit Strided Accesses (Seshadri et al., MICRO 2015)
q "Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity
DRAM Technology” (Seshadri et al., MICRO 2017)
25In-Memory Bulk Bitwise Operations
n We can support in-DRAM COPY, ZERO, AND, OR, NOT, MAJ
n At low cost
n Using analog computation capability of DRAM
q Idea: activating multiple rows performs computation
n 30-60X performance and energy improvement
q Seshadri+, “Ambit: In-Memory Accelerator for Bulk Bitwise Operations
Using Commodity DRAM Technology,” MICRO 2017.
n New memory technologies enable even more opportunities
q Memristors, resistive RAM, phase change mem, STT-MRAM, …
q Can operate on data with minimal movement
26RowClone: In-DRAM Data Copy and Init.
n Vivek Seshadri, Yoongu Kim, Chris Fallin, Donghyuk Lee, Rachata
Ausavarungnirun, Gennady Pekhimenko, Yixin Luo, Onur Mutlu, Michael A.
Kozuch, Phillip B. Gibbons, and Todd C. Mowry,
"RowClone: Fast and Energy-Efficient In-DRAM Bulk Data Copy and
Initialization"
Proceedings of the 46th International Symposium on Microarchitecture
(MICRO), Davis, CA, December 2013. [Slides (pptx) (pdf)] [Lightning Session
Slides (pptx) (pdf)] [Poster (pptx) (pdf)]
27LISA: Increasing Connectivity in DRAM
n Kevin K. Chang, Prashant J. Nair, Saugata Ghose, Donghyuk Lee,
Moinuddin K. Qureshi, and Onur Mutlu,
"Low-Cost Inter-Linked Subarrays (LISA): Enabling Fast
Inter-Subarray Data Movement in DRAM"
Proceedings of the 22nd International Symposium on High-
Performance Computer Architecture (HPCA), Barcelona, Spain,
March 2016.
[Slides (pptx) (pdf)]
[Source Code]
28FIGARO: Fine-Grained In-DRAM Copy
n Yaohua Wang, Lois Orosa, Xiangjun Peng, Yang Guo, Saugata Ghose,
Minesh Patel, Jeremie S. Kim, Juan Gómez Luna, Mohammad
Sadrosadati, Nika Mansouri Ghiasi, and Onur Mutlu,
"FIGARO: Improving System Performance via Fine-Grained In-
DRAM Data Relocation and Caching"
Proceedings of the 53rd International Symposium on
Microarchitecture (MICRO), Virtual, October 2020.
29Network-On-Memory: Fast Inter-Bank Copy
n Seyyed Hossein SeyyedAghaei Rezaei, Mehdi Modarressi, Rachata
Ausavarungnirun, Mohammad Sadrosadati, Onur Mutlu, and Masoud
Daneshtalab,
"NoM: Network-on-Memory for Inter-Bank Data Transfer in
Highly-Banked Memories"
IEEE Computer Architecture Letters (CAL), to appear in 2020.
30In-DRAM AND/OR: Triple Row Activation
½V
VDD +δ
A
Final State
B
AB + BC + AC
C
C(A + B) +
dis
en ~C(AB)
½V0DD
Seshadri+, “Fast Bulk Bitwise AND and OR in DRAM”, IEEE CAL 2015. 31In-DRAM NOT: Dual Contact Cell
Idea:
Feed the
negated value
in the sense amplifier
into a special row
Seshadri+, “Ambit: In-Memory Accelerator for Bulk Bitwise Operations using Commodity DRAM Technology,” MICRO 2017.
32Ambit vs. DDR3: Performance and
Energy
Performance Improvement
Energy Reduction
70
60 32X 35X
50
40
30
20
10
0 or
r
or
n
t
no
/o
ea
xn
/n
d
m
nd
an
r/
xo
na
33
Seshadri+, “Ambit: In-Memory Accelerator for Bulk Bitwise Operations using Commodity DRAM Technology,” MICRO 2017.Bulk Bitwise Operations in Workloads
[1] Li and Patel, BitWeaving, SIGMOD 2013
[2] Goodwin+, BitFunnel, SIGIR 2017Performance: Bitmap Index on Ambit
>5.4-6.6X Performance Improvement
Seshadri+, “Ambit: In-Memory Accelerator for Bulk Bitwise Operations using Commodity DRAM Technology,” MICRO 2017
35Performance: BitWeaving on Ambit
>4-12X Performance Improvement
Seshadri+, “Ambit: In-Memory Accelerator for Bulk Bitwise Operations using Commodity DRAM Technology,” MICRO 2017.
36More on In-DRAM Bulk AND/OR
n Vivek Seshadri, Kevin Hsieh, Amirali Boroumand, Donghyuk
Lee, Michael A. Kozuch, Onur Mutlu, Phillip B. Gibbons, and
Todd C. Mowry,
"Fast Bulk Bitwise AND and OR in DRAM"
IEEE Computer Architecture Letters (CAL), April 2015.
37More on Ambit
n Vivek Seshadri et al., “Ambit: In-Memory Accelerator
for Bulk Bitwise Operations Using Commodity DRAM
Technology,” MICRO 2017.
38In-DRAM Bulk Bitwise Execution
n Vivek Seshadri and Onur Mutlu,
"In-DRAM Bulk Bitwise Execution Engine"
Invited Book Chapter in Advances in Computers, to appear
in 2020.
[Preliminary arXiv version]
39Coming Up in ASPLOS 2021…
https://arxiv.org/pdf/2012.11890.pdf
40RowClone & Bitwise Ops in Real DRAM Chips
https://parallel.princeton.edu/papers/micro19-gao.pdf 41Pinatubo: RowClone and Bitwise Ops in PCM
42
https://cseweb.ucsd.edu/~jzhao/files/Pinatubo-dac2016.pdfProcessing in Memory:
Two Approaches
1. Minimally changing memory chips
2. Exploiting 3D-stacked memory
43Opportunity: 3D-Stacked Logic+Memory
Memory
Logic
Other “True 3D” technologies
under development
44Tesseract System for Graph Processing
Interconnected set of 3D-stacked memory+logic chips with simple cores
Host Processor Memory
Memory-Mapped Logic
Accelerator Interface
(Noncacheable, Physically Addressed)
In-Order Core
DRAM Controller
…
…
LP PF Buffer
Crossbar Network
… MTP
…
Message Queue NI
Ahn+, “A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing” ISCA 2015.Evaluated Systems
DDR3-OoO HMC-OoO HMC-MC Tesseract
32
Tesseract
Cores
128 128
8 OoO 8 OoO 8 OoO 8 OoO
In-Order In-Order
4GHz 4GHz 4GHz 4GHz 2GHz 2GHz
128 128
8 OoO 8 OoO 8 OoO 8 OoO
In-Order In-Order
4GHz 4GHz 4GHz 4GHz 2GHz 2GHz
102.4GB/s 640GB/s 640GB/s 8TB/s
Ahn+, “A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing” ISCA 2015.Tesseract Graph Processing Performance
>13X Performance Improvement
16
14
On five graph processing algorithms 13.8x
12 11.6x
10 9.0x
Speedup
8
6
4
2 +56% +25%
0
DDR3-OoO HMC-OoO HMC-MC Tesseract Tesseract- Tesseract-
LP LP-MTP
Ahn+, “A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing” ISCA 2015.Tesseract Graph Processing System Energy
Memory Layers Logic Layers Cores
1.2
1
0.8
0.6
0.4
0.2 > 8X Energy Reduction
0
HMC-OoO Tesseract with Prefetching
Ahn+, “A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing” ISCA 2015.More on Tesseract
n Junwhan Ahn, Sungpack Hong, Sungjoo Yoo, Onur Mutlu,
and Kiyoung Choi,
"A Scalable Processing-in-Memory Accelerator for
Parallel Graph Processing"
Proceedings of the 42nd International Symposium on
Computer Architecture (ISCA), Portland, OR, June 2015.
[Slides (pdf)] [Lightning Session Slides (pdf)]
49Eliminating the Adoption Barriers
How to Enable Adoption
of Processing in Memory
50Barriers to Adoption of PIM
1. Functionality of and applications & software for PIM
2. Ease of programming (interfaces and compiler/HW support)
3. System support: coherence & virtual memory
4. Runtime and compilation systems for adaptive scheduling,
data mapping, access/sharing control
5. Infrastructures to assess benefits and feasibility
All can be solved with change of mindset
51We Need to Revisit the Entire Stack
Problem
Algorithm
Program/Language
System Software
SW/HW Interface
Micro-architecture
Logic
Devices
Electrons
We can get there step by step
52PIM Review and Open Problems
Onur Mutlu, Saugata Ghose, Juan Gomez-Luna, and Rachata Ausavarungnirun,
"A Modern Primer on Processing in Memory"
Invited Book Chapter in Emerging Computing: From Devices to Systems -
Looking Beyond Moore and Von Neumann, Springer, to be published in 2021.
53
https://arxiv.org/pdf/1903.03988.pdfPIM Review and Open Problems (II)
Saugata Ghose, Amirali Boroumand, Jeremie S. Kim, Juan Gomez-Luna, and Onur Mutlu,
"Processing-in-Memory: A Workload-Driven Perspective"
Invited Article in IBM Journal of Research & Development, Special Issue on
Hardware for Artificial Intelligence, to appear in November 2019.
[Preliminary arXiv version]
54
https://arxiv.org/pdf/1907.12947.pdfUPMEM Processing-in-DRAM Engine (2019)
n Processing in DRAM Engine
n Includes standard DIMM modules, with a large
number of DPU processors combined with DRAM chips.
n Replaces standard DIMMs
q DDR4 R-DIMM modules
n 8GB+128 DPUs (16 PIM chips)
n Standard 2x-nm DRAM process
q Large amounts of compute & memory bandwidth
https://www.anandtech.com/show/14750/hot-chips-31-analysis-inmemory-processing-by-upmem
55
https://www.upmem.com/video-upmem-presenting-its-true-processing-in-memory-solution-hot-chips-2019/Challenge and Opportunity for Future
Computing Architectures
with
Minimal Data Movement
56Exploiting Data to Design
Intelligent Architectures
57System Architecture Design Today
n Human-driven
q Humans design the policies (how to do things)
n Many (too) simple, short-sighted policies all over the system
n No automatic data-driven policy learning
n (Almost) no learning: cannot take lessons from past actions
Can we design
fundamentally intelligent architectures?
58An Intelligent Architecture
n Data-driven
q Machine learns the “best” policies (how to do things)
n Sophisticated, workload-driven, changing, far-sighted policies
n Automatic data-driven policy learning
n All controllers are intelligent data-driven agents
How do we start?
59More on Self-Optimizing DRAM Controllers
n Engin Ipek, Onur Mutlu, José F. Martínez, and Rich Caruana,
"Self Optimizing Memory Controllers: A Reinforcement Learning
Approach"
Proceedings of the 35th International Symposium on Computer Architecture
(ISCA), pages 39-50, Beijing, China, June 2008.
60Challenge and Opportunity for Future
Self-Optimizing
(Data-Driven)
Computing Architectures
61Data-Aware Architectures
n A data-aware architecture understands what it can do with
and to each piece of data
n It makes use of different properties of data to improve
performance, efficiency and other metrics
q Compressibility
q Approximability
q Locality
q Sparsity
q Criticality for Computation X
q Access Semantics
q …
62One Problem: Limited Expressiveness
63A Solution: More Expressive Interfaces
64Expressive (Memory) Interfaces
n Nandita Vijaykumar, Abhilasha Jain, Diptesh Majumdar, Kevin Hsieh, Gennady
Pekhimenko, Eiman Ebrahimi, Nastaran Hajinazar, Phillip B. Gibbons and Onur Mutlu,
"A Case for Richer Cross-layer Abstractions: Bridging the Semantic Gap
with Expressive Memory"
Proceedings of the 45th International Symposium on Computer Architecture (ISCA),
Los Angeles, CA, USA, June 2018.
[Slides (pptx) (pdf)] [Lightning Talk Slides (pptx) (pdf)]
[Lightning Talk Video]
65Expressive (Memory) Interfaces for GPUs
n Nandita Vijaykumar, Eiman Ebrahimi, Kevin Hsieh, Phillip B. Gibbons and Onur Mutlu,
"The Locality Descriptor: A Holistic Cross-Layer Abstraction to Express
Data Locality in GPUs"
Proceedings of the 45th International Symposium on Computer Architecture (ISCA),
Los Angeles, CA, USA, June 2018.
[Slides (pptx) (pdf)] [Lightning Talk Slides (pptx) (pdf)]
[Lightning Talk Video]
66EDEN: Data-Aware Efficient DNN Inference
n Skanda Koppula, Lois Orosa, A. Giray Yaglikci, Roknoddin Azizi, Taha
Shahroodi, Konstantinos Kanellopoulos, and Onur Mutlu,
"EDEN: Enabling Energy-Efficient, High-Performance Deep
Neural Network Inference Using Approximate DRAM"
Proceedings of the 52nd International Symposium on
Microarchitecture (MICRO), Columbus, OH, USA, October 2019.
[Lightning Talk Slides (pptx) (pdf)]
[Lightning Talk Video (90 seconds)]
67SMASH: SW/HW Indexing Acceleration
n Konstantinos Kanellopoulos, Nandita Vijaykumar, Christina Giannoula,
Roknoddin Azizi, Skanda Koppula, Nika Mansouri Ghiasi, Taha Shahroodi, Juan
Gomez-Luna, and Onur Mutlu,
"SMASH: Co-designing Software Compression and Hardware-
Accelerated Indexing for Efficient Sparse Matrix Operations"
Proceedings of the 52nd International Symposium on
Microarchitecture (MICRO), Columbus, OH, USA, October 2019.
[Slides (pptx) (pdf)]
[Lightning Talk Slides (pptx) (pdf)]
[Poster (pptx) (pdf)]
[Lightning Talk Video (90 seconds)]
[Full Talk Lecture (30 minutes)]
68Data-Aware Virtual Memory Framework
Nastaran Hajinazar, Pratyush Patel, Minesh Patel, Konstantinos Kanellopoulos, Saugata Ghose, Rachata
Ausavarungnirun, Geraldo Francisco de Oliveira Jr., Jonathan Appavoo, Vivek Seshadri, and Onur Mutlu,
"The Virtual Block Interface: A Flexible Alternative to the Conventional Virtual Memory
Framework"
Proceedings of the 47th International Symposium on Computer Architecture (ISCA), Virtual, June 2020.
[Slides (pptx) (pdf)]
[Lightning Talk Slides (pptx) (pdf)]
[ARM Research Summit Poster (pptx) (pdf)]
[Talk Video (26 minutes)]
[Lightning Talk Video (3 minutes)]
[Lecture Video (43 minutes)]
69Challenge and Opportunity for Future
Data-Aware
(Expressive)
Computing Architectures
70Architectures for Intelligent Machines
Data-centric
Data-driven
Data-aware
71Source: h*p://spectrum.ieee.org/image/MjYzMzAyMg.jpeg 72
We Need to Revisit the Entire Stack
Problem
Algorithm
Program/Language
System Software
SW/HW Interface
Micro-architecture
Logic
Devices
Electrons
We can get there step by step
73PIM Review and Open Problems
Onur Mutlu, Saugata Ghose, Juan Gomez-Luna, and Rachata Ausavarungnirun,
"A Modern Primer on Processing in Memory"
Invited Book Chapter in Emerging Computing: From Devices to Systems -
Looking Beyond Moore and Von Neumann, Springer, to be published in 2021.
https://arxiv.org/pdf/1903.03988.pdf 74PIM Review and Open Problems (II)
Saugata Ghose, Amirali Boroumand, Jeremie S. Kim, Juan Gomez-Luna, and Onur Mutlu,
"Processing-in-Memory: A Workload-Driven Perspective"
Invited Article in IBM Journal of Research & Development, Special Issue on
Hardware for Artificial Intelligence, to appear in November 2019.
[Preliminary arXiv version]
https://arxiv.org/pdf/1907.12947.pdf 75A Longer Version of This Talk
n Onur Mutlu,
"Memory-Centric Computing Systems"
Invited Tutorial at 66th International Electron Devices
Meeting (IEDM), Virtual, 12 December 2020.
[Slides (pptx) (pdf)]
[Executive Summary Slides (pptx) (pdf)]
[Tutorial Video (1 hour 51 minutes)]
[Executive Summary Video (2 minutes)]
[Abstract and Bio]
[Related Keynote Paper from VLSI-DAT 2020]
[Related Review Paper on Processing in Memory]
https://www.youtube.com/watch?v=H3sEaINPBOE
https://www.youtube.com/onurmutlulectures 76Detailed Lectures on PIM (I)
n Computer Architecture, Fall 2020, Lecture 6
q Computation in Memory (ETH Zürich, Fall 2020)
q https://www.youtube.com/watch?v=oGcZAGwfEUE&list=PL5Q2soXY2Zi9xidyIgBxUz
7xRPS-wisBN&index=12
n Computer Architecture, Fall 2020, Lecture 7
q Near-Data Processing (ETH Zürich, Fall 2020)
q https://www.youtube.com/watch?v=j2GIigqn1Qw&list=PL5Q2soXY2Zi9xidyIgBxUz7
xRPS-wisBN&index=13
n Computer Architecture, Fall 2020, Lecture 11a
q Memory Controllers (ETH Zürich, Fall 2020)
q https://www.youtube.com/watch?v=TeG773OgiMQ&list=PL5Q2soXY2Zi9xidyIgBxUz
7xRPS-wisBN&index=20
n Computer Architecture, Fall 2020, Lecture 12d
q Real Processing-in-DRAM with UPMEM (ETH Zürich, Fall 2020)
q https://www.youtube.com/watch?v=Sscy1Wrr22A&list=PL5Q2soXY2Zi9xidyIgBxUz7
xRPS-wisBN&index=25
https://www.youtube.com/onurmutlulectures 77Detailed Lectures on PIM (II)
n Computer Architecture, Fall 2020, Lecture 15
q Emerging Memory Technologies (ETH Zürich, Fall 2020)
q https://www.youtube.com/watch?v=AlE1rD9G_YU&list=PL5Q2soXY2Zi9xidyIgBxUz
7xRPS-wisBN&index=28
n Computer Architecture, Fall 2020, Lecture 16a
q Opportunities & Challenges of Emerging Memory Technologies
(ETH Zürich, Fall 2020)
q https://www.youtube.com/watch?v=pmLszWGmMGQ&list=PL5Q2soXY2Zi9xidyIgBx
Uz7xRPS-wisBN&index=29
n Computer Architecture, Fall 2020, Guest Lecture
q In-Memory Computing: Memory Devices & Applications (ETH
Zürich, Fall 2020)
q https://www.youtube.com/watch?v=wNmqQHiEZNk&list=PL5Q2soXY2Zi9xidyIgBxU
z7xRPS-wisBN&index=41
https://www.youtube.com/onurmutlulectures 78Funding Acknowledgments
n Alibaba, AMD, ASML, Google, Facebook, Hi-Silicon, HP
Labs, Huawei, IBM, Intel, Microsoft, Nvidia, Oracle,
Qualcomm, Rambus, Samsung, Seagate, VMware
n NSF
n NIH
n GSRC
n SRC
n CyLab
79Acknowledgments
n My current and past students and postdocs
q Rachata Ausavarungnirun, Abhishek Bhowmick, Amirali
Boroumand, Rui Cai, Yu Cai, Kevin Chang, Saugata Ghose, Kevin
Hsieh, Tyler Huberty, Ben Jaiyen, Samira Khan, Jeremie Kim,
Yoongu Kim, Yang Li, Jamie Liu, Lavanya Subramanian,
Donghyuk Lee, Yixin Luo, Justin Meza, Gennady Pekhimenko,
Vivek Seshadri, Lavanya Subramanian, Nandita Vijaykumar,
HanBin Yoon, Jishen Zhao, …
n My collaborators
q Can Alkan, Chita Das, Phil Gibbons, Sriram Govindan, Norm
Jouppi, Mahmut Kandemir, Mike Kozuch, Konrad Lai, Ken Mai,
Todd Mowry, Yale Patt, Moinuddin Qureshi, Partha Ranganathan,
Bikash Sharma, Kushagra Vaid, Chris Wilkerson, …
80Acknowledgments
https://safari.ethz.chOnur Mutlu’s SAFARI Research Group
Computer architecture, HW/SW, systems, bioinformatics, security, memory
https://safari.ethz.ch/safari-newsletter-january-2021/
38+ Researchers
https://safari.ethz.chSAFARI Newsletter April 2020 Edition
n https://safari.ethz.ch/safari-newsletter-april-2020/
83SAFARI Newsletter January 2021 Edition
n https://safari.ethz.ch/safari-newsletter-january-2021/
84Intelligent Architectures
for
Intelligent Computing Systems
Onur Mutlu
omutlu@gmail.com
https://people.inf.ethz.ch/omutlu
2 February 2021
DATE Special Session Invited TalkBackup Slides for Further Info
Referenced Papers and Talks
n All are available at
https://people.inf.ethz.ch/omutlu/projects.htm
http://scholar.google.com/citations?user=7XyGUGkAAAAJ&hl=en
https://www.youtube.com/onurmutlulectures
87Research & Teaching: Some Overview Talks
https://www.youtube.com/onurmutlulectures
n Future Computing Architectures
q https://www.youtube.com/watch?v=kgiZlSOcGFM&list=PL5Q2soXY2Zi8D_5MGV6EnXEJHnV2YFBJl&index=1
n Enabling In-Memory Computation
q https://www.youtube.com/watch?v=njX_14584Jw&list=PL5Q2soXY2Zi8D_5MGV6EnXEJHnV2YFBJl&index=16
n Accelerating Genome Analysis
q https://www.youtube.com/watch?v=hPnSmfwu2-A&list=PL5Q2soXY2Zi8D_5MGV6EnXEJHnV2YFBJl&index=9
n Rethinking Memory System Design
q https://www.youtube.com/watch?v=F7xZLNMIY1E&list=PL5Q2soXY2Zi8D_5MGV6EnXEJHnV2YFBJl&index=3
n Intelligent Architectures for Intelligent Machines
q https://www.youtube.com/watch?v=n8Aj_A0WSg8&list=PL5Q2soXY2Zi8D_5MGV6EnXEJHnV2YFBJl&index=22
n Revisiting RowHammer
q https://www.youtube.com/watch?v=B58YT9hZM4g&list=PL5Q2soXY2Zi8D_5MGV6EnXEJHnV2YFBJl&index=25
88An Interview on Research and Education
n Computing Research and Education (@ ISCA 2019)
q https://www.youtube.com/watch?v=8ffSEKZhmvo&list=PL5Q2
soXY2Zi_4oP9LdL3cc8G6NIjD2Ydz
n Maurice Wilkes Award Speech (10 minutes)
q https://www.youtube.com/watch?v=tcQ3zZ3JpuA&list=PL5Q2
soXY2Zi8D_5MGV6EnXEJHnV2YFBJl&index=15
89More Thoughts and Suggestions
n Onur Mutlu,
"Some Reflections (on DRAM)"
Award Speech for ACM SIGARCH Maurice Wilkes Award, at the ISCA Awards
Ceremony, Phoenix, AZ, USA, 25 June 2019.
[Slides (pptx) (pdf)]
[Video of Award Acceptance Speech (Youtube; 10 minutes) (Youku; 13 minutes)]
[Video of Interview after Award Acceptance (Youtube; 1 hour 6 minutes) (Youku;
1 hour 6 minutes)]
[News Article on "ACM SIGARCH Maurice Wilkes Award goes to Prof. Onur Mutlu"]
n Onur Mutlu,
"How to Build an Impactful Research Group"
57th Design Automation Conference Early Career Workshop (DAC), Virtual, 19
July 2020.
[Slides (pptx) (pdf)]Reference Overview Paper I
Onur Mutlu, Saugata Ghose, Juan Gomez-Luna, and Rachata Ausavarungnirun,
"Processing Data Where It Makes Sense: Enabling In-Memory
Computation"
Invited paper in Microprocessors and Microsystems (MICPRO), June 2019.
[arXiv version]
91
https://arxiv.org/pdf/1903.03988.pdfReference Overview Paper II
Saugata Ghose, Amirali Boroumand, Jeremie S. Kim, Juan Gomez-Luna, and Onur Mutlu,
"Processing-in-Memory: A Workload-Driven Perspective"
Invited Article in IBM Journal of Research & Development, Special Issue on
Hardware for Artificial Intelligence, to appear in November 2019.
[Preliminary arXiv version]
https://arxiv.org/pdf/1907.12947.pdf 92Reference Overview Paper III
Saugata Ghose, Kevin Hsieh, Amirali Boroumand, Rachata Ausavarungnirun, Onur Mutlu,
"Enabling the Adoption of Processing-in-Memory: Challenges, Mechanisms,
Future Research Directions"
Invited Book Chapter, to appear in 2018.
[Preliminary arxiv.org version]
https://arxiv.org/pdf/1802.00320.pdf 93Reference Overview Paper IV
n Onur Mutlu and Lavanya Subramanian,
"Research Problems and Opportunities in Memory
Systems"
Invited Article in Supercomputing Frontiers and Innovations
(SUPERFRI), 2014/2015.
https://people.inf.ethz.ch/omutlu/pub/memory-systems-research_superfri14.pdfReference Overview Paper V
n Onur Mutlu,
"The RowHammer Problem and Other Issues We May Face as
Memory Becomes Denser"
Invited Paper in Proceedings of the Design, Automation, and Test in
Europe Conference (DATE), Lausanne, Switzerland, March 2017.
[Slides (pptx) (pdf)]
https://people.inf.ethz.ch/omutlu/pub/rowhammer-and-other-memory-issues_date17.pdfReference Overview Paper VI
n Onur Mutlu,
"Memory Scaling: A Systems Architecture
Perspective"
Technical talk at MemCon 2013 (MEMCON), Santa Clara,
CA, August 2013. [Slides (pptx) (pdf)]
[Video] [Coverage on StorageSearch]
https://people.inf.ethz.ch/omutlu/pub/memory-scaling_memcon13.pdfReference Overview Paper VII
Proceedings of the IEEE, Sept. 2017
97
https://arxiv.org/pdf/1706.08642Reference Overview Paper VIII
n Onur Mutlu and Jeremie Kim,
"RowHammer: A Retrospective"
IEEE Transactions on Computer-Aided Design of Integrated
Circuits and Systems (TCAD) Special Issue on Top Picks in
Hardware and Embedded Security, 2019.
[Preliminary arXiv version]
98You can also read

















































