LIFTS: Lidar and Monocular Image Fusion for Multi-Object Tracking and Segmentation - MOT Challenge
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

LIFTS: Lidar and Monocular Image Fusion for Multi-Object Tracking and
Segmentation
Haotian Zhang, Yizhou Wang, Jiarui Cai, Hung-Min Hsu, Haorui Ji, Jenq-Neng Hwang
Department of Electrical and Computer Engineering
University of Washington, Seattle, WA, USA
{haotiz, ywang26, jrcai, hmhsu, hji2, hwang}@uw.edu
Abstract
In recent years, the computer vision society has made
significant progress in multi-object tracking (MOT) and
video object segmentation (VOS) respectively. Further
progress can be achieved by effectively combining the fol-
lowing tasks together – detection, segmentation and track-
ing. In this work, we propose a multi-stage framework
called “Lidar and monocular Image Fusion based multi-
object Tracking and Segmentation (LIFTS)” for multi-
object tracking and segmentation (MOTS). In the first stage,
we use a 3D Part-Aware and Aggregation Network detector
on the point cloud data to get 3D object locations. Then a Figure 1. The framework of the proposed LIFTS, which consists
graph-based 3D TrackletNet Tracker (3D TNT), which takes of a three-stage pipeline: 3D object detection and tracking, pre-
computed proposals and masks generation, and post-processing.
both CNN appearance features and object spatial informa-
tion of detections, is applied to robustly associate objects
along time. The second stage involves a Cascade Mask
R-CNN based network with PointRend head for obtaining able approaches can successfully track objects when they
instance segmentation results from monocular images. Its are consistently visible, but fail in the long-term through
input pre-computed region proposals are generated from either disappearances or occlusions, which are caused by
projecting 3D detections in the first stage onto a 2D im- heterogeneous objects, interacting objects, edge ambiguous
age plane. Moreover, two post-processing techniques are and shape complexity. Jointly solving the two problems of
further applied in the last stage: (1) generated mask results multi-object tracking and segmentation (MOTS) can over-
are refined by an optical-flow guided instance segmentation come respective difficulties and improve both of their per-
network; (2) object re-identification (ReID) is applied to formances.
recover ID switches caused by long-term occlusion; Over- To tackle the MOTS problems, we propose a multi-stage
all, our proposed framework is evaluated on BMTT Chal- framework named “Lidar and monocular Image Fusion for
lenge 2020 Track2: KITTI-MOTS dataset and achieves a multi-object Tracking and Segmentation (LIFTS)”. The
79.6 sMOTSA for Car and 64.9 for Pedestrian, with the 2nd LIFTS consists of a three-stage pipeline, which is shown in
place ranking in the competition. Figure 1. First, given the LiDAR point cloud, a 3D Part-
Aware and Aggregation Network is adopted to get accu-
rate 3D object locations. A graph-based TrackletNet, which
1. Introduction takes both CNN appearance and object spatial information,
is then applied to robustly associate objects to form track-
Multi-Object Tracking (MOT) is the task of associat- lets along time. We additionally interpolate and recover
ing objects in a video and assigning consistent IDs for the the unreliable/missing detections in each tracklet to form
same identities. On the other hand, Video Object Seg- longer trajectories. In the second stage, we project each
mentation (VOS) task is aimed to generate the object seg- frame of these trajectories onto 2D image plane using the
mentation masks in video frames. However, many avail- camera intrinsics and treat them as the pre-computed region
1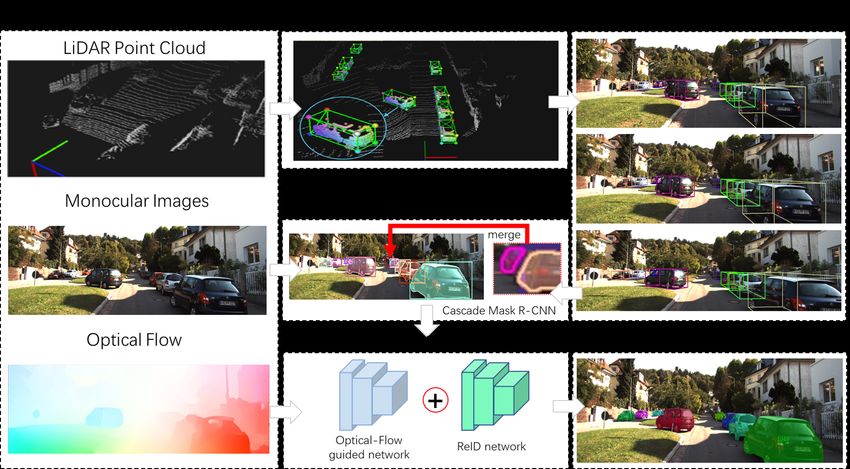
proposals for a Cascade Mask R-CNN [2] based network Tracker (3D TNT) takes both discriminative CNN appear-
with a PointRend [4] segmentation branch. For those ob- ance features and accurate object spatial information from
jects that are not detected by the 3D detector from LiDAR each frame to ensure tracking robustness. The 3D TNT
point cloud data but detected by the 2D detector from im- is extended from the 2D TNT [10], which builds a graph-
ages, we use Hungarian algorithm to merge these detections based model that takes 2D tracklets as the vertices and use
with existing trajectories. This is able to bridge 3D world a multi-scale CNN network to measure the connectivity be-
space and 2D image space consistently and produces a high- tween two tracklets. Our 3D TrackletNet Tracker consist of
quality mask for each instance in every frame. Moreover, three key components:
two post-processing stages are further applied in the last (i) Tracklet Generation: Given the refined object local-
stage: (1) the generated masks from the second stage are ization of each frame, generated by 2D box appearance sim-
refined by a proposed optical-flow guided instance segmen- ilarity based on CNN features derived from the FaceNet [7]
tation network; (2) the refined masks are then used for ob- and 3D intersection-over-union (3D IoU) between adjacent
ject re-identification (ReID) to recover ID switches caused frames, is denoted as a node (v ∈ V ) in the graph.
by long-term occlusions. (ii) Connectivity Measurement: Between every two
tracklets, the connectivity (similarity) pe (e ∈ E) is mea-
2. Related Work sured as the edge weight in the graph model. To calculate
the connectivity, a multi-scale TrackletNet is built as a clas-
Multi-Object Tracking. Recent multiple object track-
sifier, which can concatenate both temporal (multi-frame)
ing (MOT) methods have largely employed tracking-by-
and appearance features for the likelihood estimation. For
detection schemes, meaning that tracking is done through
each frame t, a vector consisting of the 7-D detected object
association of detected objects across time. Most works
measurements (x, y, z, h, w, l, θ) from the Part-A2 detector,
[12] on MOT are typically done in 2D image space. How-
concatenated by an 512-D embedding appearance feature
ever, lack of depth information in 2D tracking causes failure
extracted from the FaceNet, is used to represent an individ-
in tracking objects long-term due to disappearances and oc-
ual feature of the input frame.
clusions. Given LiDAR point cloud, [11] uses standard 3D
Kalman filters and Hungarian algorithms to associate detec- (iii) Graph-based Clustering: After the tracklet graph is
tions from LiDAR, which causes fewer ID switches and can built, graph partition and clustering techniques, i.e., assign,
perform long-term tracking. merge, split, switch, and break operations are iteratively
Multi-Object Tracking and Segmentation. MOTS is performed to minimize the total cost on the whole graph.
proposed as a new task to track multiple objects with in- Based on the tracking results from the 3D TNT, we are
stance segmentation. Voigtlaende et al. [9] propose a base- not only able to associate every object across frames, but
line approach Track R-CNN, which can jointly address de- also can deal with errors caused by the occlusions and miss-
tection, tracking, and segmentation via a single convolu- ing detections. For those unreliable/missing detections, we
tional network. While the aforementioned method is able use Lagrangian interpolation to recover/fill-in those frames
to produce tracking outputs with segmentation masks, the to form longer trajectories.
network is trained under multiple task, resulting in increas-
3.2. Pre-Computed Proposals and Masks Genera-
ing the tracking performance while degrading the detection
tion
and segmentation performance.
In Sec. 3.1, accurate locations are obtained by a 3D
3. The Proposed Method object detector and objects are robustly associated across
frames using the proposed 3D TrackletNet Tracker. In order
3.1. 3D Object Detection and Tracking to produce outputs with segmentation masks, we project all
3D Part-Aware and Aggregation Network. We adopt the 3D bounding boxes inside each frame onto the 2D im-
a state-of-the-art point-cloud-based 3D object detector, the age plane by using camera intrinsics, object locations and
part-aware and aggregation neural network (Part-A2 net) orientation angles and treat the projected ROIs as the pre-
[8]. The Part-A2 detector produces 3D bounding boxes pa- computed region proposals to a two-stage image-based ob-
rameterized with (x, y, z, h, w, l, θ), where (x, y, z) are the ject detection framework. For smaller objects that are not
box center coordinates, (h, w, l) are the height, width and detected by Part-A2 network but are detected by the image-
length of each box respectively, and θ is the orientation an- based detector, we use Hungarian algorithm to merge these
gle of each box from the bird’s eye view. detections with existing trajectories.
3D TrackletNet Tracker. To take advantage of the We utilize the Cascade Mask R-CNN framework as our
temporal consistency for improving the localization perfor- basic architecture. Each detector inside the cascade is se-
mance further, we need tracking to associate corresponding quentially more effective in selecting higher quality detec-
detected objects along time. The proposed 3D TrackletNet tions compared with its predecessor. The network can thenFigure 2. Qualitative results of the proposed LIFTS method on KITTI-MOTS datasets. The top two rows are the results for Cars, and the
bottom two rows show the results for Pedestrians.
make itself capable of handling proposals through multiple Re-identification Network. A ReID approach is also
quality levels and generate better detection results. applied to reconnect tracklets due to occlusions or abrupt
In addition to the detection head, we use PointRend [4] motions. We use the trajectory-level of features for ReID
as our mask head for segmentation. Compared with stan- in the tracking refinement process. For frame-level feature
dard mask head, PointRent head, which iteratively renders extraction, we adopt the ResNet50 network pre-trained on
the output mask in a coarse-to-fine fashion, upsamples its ImageNet as our feature extractor. Furthermore, temporal
previously predicted segmentation using bilinear interpo- information is also considered to establish a more repre-
lation and then selects 50 most uncertain points to predict sentative feature by using temporal attention (TA) to con-
their labels using a point-wise feature representation. In vert weighted average of the frame-level features and into
this case it can predict masks with substantially finer details clip-level features. Note that some frames of the object
around object boundaries. might be highly occluded by other objects, and we try to
lower the weights of these frames. Finally, we add a max-
3.3. Post-Processing
pooling layer for these clip-level features to generate the
Optical-Flow Guided Mask Propagation Network. final tracklet-level feature.
Followed the idea by [1], which shows the highly accu-
rate object segmentation in videos can be achieved by using
temporal information, the segmentation mask can be fur-
4. Experiments
ther refined from the previous frame’s ”rough” estimate of a 4.1. Dataset and Evaluation
tracked object. In order to guide the pixel labeling network
to segment the object of interest, we begin by expanding the KITTI-MOTS [9] is a driving scenario dataset for both
network input from RGB to RGB+mask channel. The extra car and pedestrian tracking task. It consists of 21 training
mask channel is meant to provide an estimate of the visible sequences and 29 testing sequences. We evaluate our per-
area of the object in the current frame, its approximate lo- formance based on sMOTSA metrics, which accumulates
cation and shape. Given an initial mask estimate from the the soft number of true positives, false positives, and ID
previous frame t − 1 in Sec. 3.2, we train the network to switches.
provide a refined mask output for the current frame t.
We also consider to employ the optical flow as a source 4.2. KITTI-MOTS Performance
of additional information to guide the segmentation. More
specifically, given a video sequence, we compute the opti- The performance of MOTS for both Car and Pedestrian
cal flow using FlowNet2 [3]. In parallel to the above frame- are evaluated using sMOTA, which measures segmentation
work, we proceed to compute a second output mask using as well as detection and tracking quality. Qualitative per-
the magnitude of the optical flow field as the input image. formance is shown in Fig. 2. In the BMTT Challenge 2020
We then fuse by averaging the output scores given by the Track2 (KITTI-MOTS), our method ranks the second place
two parallel networks. It can be shown in the experimental among the total 16 valid submissions. The performance of
results, optical flow provides complementary information to top-selected algorithms is shown in Table 1 for Car and Ta-
the mask quality, improving the overall performance. ble 2 for Pedestrian.Method sMOTA ↑ MOTSA MOTSP MOTSAL MODSA MODSP MT ML IDS ↓ Frag
PointTrack++ 82.80 92.60 89.70 93.30 93.30 92.10 89.10 1.2 270 584
MCFPA 77.00 87.70 88.30 89.10 89.10 90.80 82.90 0.6 503 724
GMPHD SAF 75.40 86.70 87.50 88.20 88.20 90.10 82.00 0.6 549 874
MOTSFusion [6] 75.00 84.10 89.30 84.70 84.70 91.70 66.10 6.2 201 572
TrackR-CNN [9] 67.00 79.60 85.10 81.50 81.50 88.30 74.90 2.3 692 1058
LIFTS (ours) 79.60 89.60 89.00 89.90 89.90 91.40 79.10 2.9 114 532
Table 1. Competition results for Car of KITTI-MOTS, ours is marked bold.
Method sMOTA ↑ MOTSA MOTSP MOTSAL MODSA MODSP MT ML IDS ↓ Frag
PointTrack++ 68.10 83.60 82.20 84.80 84.80 94.00 66.70 4.80 250 521
MCFPA 67.20 83.00 81.90 84.30 84.30 93.80 67.00 3.00 265 484
GMPHD SAF 62.80 78.20 81.60 80.40 80.50 93.70 59.30 4.80 474 696
MOTSFusion [5] 58.70 72.90 81.50 74.20 74.20 94.10 47.40 15.60 279 534
TrackR-CNN [9] 47.30 66.10 74.60 68.40 68.40 91.80 45.60 13.30 481 861
LIFTS (ours) 64.90 80.90 81.00 81.90 81.90 93.60 61.50 8.90 206 577
Table 2. Competition results for Pedestrian of KITTI-MOTS, ours is marked bold.
5. Conclusion [4] Alexander Kirillov, Yuxin Wu, Kaiming He, and Ross Gir-
shick. Pointrend: Image segmentation as rendering. arXiv
We have presented a framework in which both tracking preprint arXiv:1912.08193, 2019. 2, 3
and segmentation can be performed together and can benefit [5] Jonathon Luiten, Tobias Fischer, and Bastian Leibe. Track
from each other. We first use a Part-Aware and Aggregation to reconstruct and reconstruct to track. IEEE Robotics and
Network given the LiDAR point cloud data to get accurate Automation Letters, 5(2):1803–1810, 2020. 4
3D object locations, then a proposed graph-based 3D Track- [6] Jonathon Luiten, Paul Voigtlaender, and Bastian Leibe. Pre-
letNet Tracker is applied to associate object across frames. mvos: Proposal-generation, refinement and merging for
We treat the projected 2D ROI as the pre-computed region video object segmentation. In Asian Conference on Com-
proposals and send them into a cascade Mask R-CNN net- puter Vision, pages 565–580. Springer, 2018. 4
work with PointRend segmentation. Finally, a proposed [7] Florian Schroff, Dmitry Kalenichenko, and James Philbin.
Facenet: A unified embedding for face recognition and clus-
optical-flow guided instance segmentation network and a
tering. In Proceedings of the IEEE conference on computer
ReID approach is applied to further refine both segmenta- vision and pattern recognition, pages 815–823, 2015. 2
tion and tracking results. Quantitative and qualitative ex- [8] Shaoshuai Shi, Zhe Wang, Xiaogang Wang, and Hongsheng
periments have demonstrated that our system can achieve Li. Part-aˆ 2 net: 3d part-aware and aggregation neural net-
high accuracy in sMOTA for both Cars and Pedestrians and work for object detection from point cloud. arXiv preprint
outperforms other competing methods. arXiv:1907.03670, 2019. 2
[9] Paul Voigtlaender, Michael Krause, Aljosa Osep, Jonathon
References Luiten, Berin Balachandar Gnana Sekar, Andreas Geiger,
and Bastian Leibe. Mots: Multi-object tracking and segmen-
[1] Gedas Bertasius and Lorenzo Torresani. Classifying, seg- tation. In Proceedings of the IEEE Conference on Computer
menting, and tracking object instances in video with mask Vision and Pattern Recognition, pages 7942–7951, 2019. 2,
propagation. In Proceedings of the IEEE/CVF Conference 3, 4
on Computer Vision and Pattern Recognition, pages 9739– [10] Gaoang Wang, Yizhou Wang, Haotian Zhang, Renshu Gu,
9748, 2020. 3 and Jenq-Neng Hwang. Exploit the connectivity: Multi-
[2] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delv- object tracking with trackletnet. In Proceedings of the 27th
ing into high quality object detection. In Proceedings of the ACM International Conference on Multimedia, pages 482–
IEEE conference on computer vision and pattern recogni- 490, 2019. 2
tion, pages 6154–6162, 2018. 2 [11] Xinshuo Weng and Kris Kitani. A baseline for 3d multi-
[3] Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, object tracking. arXiv preprint arXiv:1907.03961, 2019. 2
Alexey Dosovitskiy, and Thomas Brox. Flownet 2.0: Evolu- [12] Zhimeng Zhang, Jianan Wu, Xuan Zhang, and Chi Zhang.
tion of optical flow estimation with deep networks. In Pro- Multi-target, multi-camera tracking by hierarchical cluster-
ceedings of the IEEE conference on computer vision and pat- ing: Recent progress on dukemtmc project. arXiv preprint
tern recognition, pages 2462–2470, 2017. 3 arXiv:1712.09531, 2017. 2You can also read

















































