Master Lecture: Competitive Problem Solving with Deep Learning - Introduction Dr. Haojin Yang - Hasso ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Master Lecture: Competitive Problem Solving with Deep Learning Introduction Dr. Haojin Yang Internet Technologies and Systems Hasso Plattner Institute, University of Potsdam

Content Course roadmap Teaching team Multimedia analysis and Deep Learning Important information Competitive Problem Solving with Deep Learning Course Website

Lectures Theoretical Foundation 09.04.2018 Intro (H-2.57) 16.04.2018 Machine learning basics (HS 3) 23.04.2018 Neural Network I (HS 1) 07.05.2018 Neural Network II (HS 3) 28.05.2018 Architecture design and advanced techniques (HS 3) 11.06.2018 Deep learning research (HS 3) Practical use case 30.04.2018 Build your first neural network from scratch (HS 3) 14.05.2018 Advanced techniques in practice (HS 3) 04.06.2018 A computer vision example (HS 3) 18.06.2018 Generative network example (HS 1) 25.06.2018 Written exam (40%) (HS 3) Chart 3

Project Competitive problem solving: An image recognition challenge Chart 4

Project - Roadmap Competitive problem solving: An image recognition challenge 11.06.2018 Challenge open: Release training und validation data, grouping 02.07.2018 Release test set 09.07.2018 Release pre-ranking result 09-10.07.2018 Model submission: Tutors will run the models using a secret test dataset 16.07.2018 Final presentation, release final ranking result, (20%) awards granting Until 31. August Final submission: Implementation + Paper (40%) Weekly individual meeting with your tutors during the project Chart 5

Content Course roadmap Teaching team Multimedia analysis and Deep Learning Important information

7 Dr. Haojin Yang • Dipl.-Ing study at TU-Ilmenau (2002-2007) • Software engineer (2008-2010) • PhD student, internet technology and system HPI (2010-2013) • Senior researcher, Multimedia and Deep Learning research team • Research interest: multimedia analysis, computer vision, machine learning/deep learning Research Group:

Personal Information Dr. Xiaoyin Che Education: ■ 2005~2009 Bachelor Degree in Beijing University of Technology ■ 2009~2012 Master Degree in Beijing University of Technology ■ 2012~2018 PhD Student in Hasso Plattner Institute Research Topics: ■ Document Analysis ■ Deep Learning ■ Natural Language Processing ■ E-Learning 8

Personal Information Christian Bartz, M.sc Research background 2010~2013 Bachelor Degree (Hasso-Plattner-Institute) 2013~2016 Master Degree (Hasso-Plattner-Institute) 2016~ PhD Student at Hasso-Plattner-Institute Research interests Computer vision, deep learning, text recognition 9
Personal Information Joseph Bethge, M.sc Research background 2010~2013 Bachelor Degree (Hasso-Plattner-Institute) 2014~2017 Master Degree (Hasso-Plattner-Institute) 2017~ PhD Student at Hasso-Plattner-Institute Research interests Computer vision, deep learning, binary neural networks 10
Goncalo Mordido B.Sc, Computer Science (2012-2015) Exchange Program, Computer Science (2015-2016) M.Sc, Computer Science (2015-2017) Ph.D. Student, Deep Learning (July 2017-Present) ■ Interests: Generative Adversarial Models Natural Language Processing Chart 11
Personal Information Mina Rezaei, M.sc ■ Research background ■ 2005.10-2008.03 Azad University, Arak, Iran B.S c. Computer Engineering ■ 2010.10-2013.03 Shiraz University, Shiraz, Iran M.Sc. Artificial Intelligence ■ 2015.11-now PhD student at HPI ■ Research interests ■ Deep Learning for Medical Image Analysis 12
Content Course roadmap Teaching team Multimedia analysis and Deep Learning Important information
YouTube: > 400 hours of video uploaded per minute TouTiao: 20 million video clips uploaded per day Facebook: 350 million photo uploaded per day Instagram: 55 million photo upload per day Flickr: 3.5 million photo upload per day Cisco report: video data 2017: >74% of internet traffics, 2020: >90%
Automatic Multimedia Analysis man woman man Event Detection: Getting into or out of a vehicle Event Detection: bungee jumping Overlay Scene Text Text Captioning: Face A group of people are watching TV Audio-Mining Detection
Current State of Visual Recognition and AI: We are really really far… (example from Andrej Karpathy’s blog)
Artificial Intelligence Current Approach: Deep Learning Deep Learning, Deep Neural Networks (since 2006): Achieved many break-record results in research fields like Speech Recognition Computer Vision Reinforcement Learning Nature Language Processing etc. Impacting wide range of academic and industrial products, e.g. Autonomous driving Digital assistant (Image from Welch Labs)
Artificial Intelligence Current Approach: Deep Learning Insights: Subfield of Machine Learning Hierarchically learning features from large scale data Data driving machine learning, and scale driving Deep Learning: Deep Learning progress CNN, RNN Representation Learning Machine Learning Artificial Intelligence Chart 18
Artificial Intelligence Current Approach: Deep Learning Deep learning as human beings (Andrew Ng 2013) (Taigman et al. 2014)
Deep Learning Impact in Research Deep Learning Breakthroughs Achieved human performance in many visual recognition tasks (Image source: Intel)
Success Factors Rapid development of hardware acceleration and massive amounts of computational power ■ Applying GPUs in neural network computation becomes mainstream ■ Training time of a very deep model: 10 years ago: several months Today: within several days ■ Cloud computing, distributed system (Roelof Pieters 2015)
Success Factors Big data available for training deep neural networks, e.g. ■ ImageNet data set for image classification with 14,197k images in 21.841 categories ■ YouTube-8M data set with 7 million videos
Success Factors Working ideas on how to train deep networks Stacked Restricted Boltzman Machines (RBM), Hinton et al. 2006 Stacked Autoencoders (AE), Bengio et al. 2007 Encoder: Decoder: Reconstruction: Minimizing the reconstruction error: (Russ Salakhutdinov 2017)
Before Deep Learning Traditional ML Approach Traditional ML Approach Get a new problem: Data preparation, create labeled dataset (CIFAR ImageNet etc.) Spend hours hand engineering representative features (e.g. HOG, SIFT, LBP, bag-of-words), fed into a ML algorithm Evaluate different ML algorithms (SVM, Random Forest etc.) Repeat feature engineering and evaluation step: pick the best configuration for your application Image source: templecarvings.com
Before Deep Learning Handcrafted Features Example: HOG Machine Learning approach based on learning Representation of data, e.g. HOG – Histogram of Oriented Gradients – feature for face detection
Before Deep Learning Handcrafted Features Example: HOG Machine Learning approach based on learning Representation of data, e.g. HOG – Histogram of Oriented Gradients – feature for face detection
Before Deep Learning Handcrafted Features Example: HOG Machine Learning approach based on learning Representation of data, e.g. HOG – Histogram of Oriented Gradients – feature for face detection
Before Deep Learning Handcrafted Features Example: HOG Machine Learning approach based on learning Representation of data, e.g. HOG – Histogram of Oriented Gradients – feature for face detection „Feature Engineering“ designed by Expert SVM Classifier face? non-face?
Artificial Neural Networks Adaptable Weights W „Feature Learning“ Weights updated with the Back-propagation Algorithm Backward pass
Artificial Neural Networks Theoretically given a neural network with a single hidden layer, any function can be approximated as long as its hidden layer has enough neurons Each layer can apply to the previous layer to produce an output, usually a linear transformation followed by a squashing nonlinearity. The output layer transforms the hidden layer activations into target output e.g. probability of each class The commonly applied components include convolution layer, dense layer, pooling, activation, regularization, loss function etc. Image: www.guitarstudio.be
Deep Learning Impact in Research Image Classification ImageNet Challenge Given an image, classify what is depicted (top 5 accuracy) AlexNet (Image from Nvidia) (Deng, J. et al. 2014)
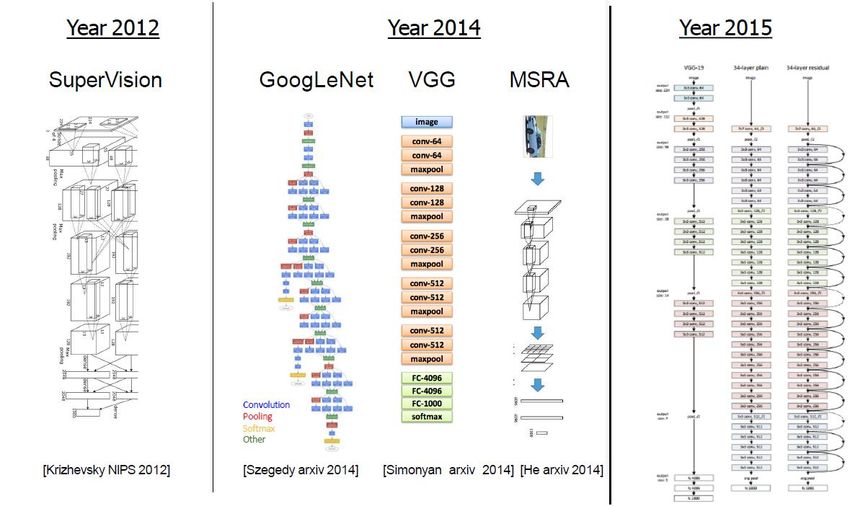
Deep Learning Impact in Research Image Classification ImageNet Challenge (1000 classes, 1,431,167 images): Given an image, classify what is depicted. Recent winners: AlexNet 8 layers Around 20 layers 152 layers ResNet (He et al. arxiv 2015)
Deep Learning Impact in Research Speech Recognition (Roelof Pieters 2015)
Enlightenment: The Mammalian Visual Cortex is Hierarchical The ventral (recognition) pathway in the visual cortex has multiple stage: Retina - LGN - V1 - V2 - V4 - PIT - AIT …., lots of intermediate representations : eyes - ) - nose :-) face : edges ) mouth
Hierarchical Feature Learning Learn higher Abstraction Low-Level Mid-Level High-Level Trainable Features Features Features Classifier (Zeiler and Fergus 2013)
Hierarchical Feature Learning Visual Recognition Example ■ AlexNet model: 8 hidden layers, 650k neurons, 60 million parameters ■ Trained based on ImageNet: 1.4 million training images, 1000 classes ■ Visualization of neurons from specific layers (credit by Zeiler and Fergus 2013)
1. layer Hierarchical Feature Learning (Zeiler and Fergus 2013)
2. layer Hierarchical Feature Learning (Zeiler and Fergus 2013)
3. layer Hierarchical Feature Learning (Zeiler and Fergus 2013)
4. layer Hierarchical Feature Learning (Zeiler and Fergus 2013)
5. layer Hierarchical Feature Learning (Zeiler and Fergus 2013)
Hierarchical Feature Learning Learn higher Abstraction ■ Natural progression from low level to high level structure as seen in natural complexity ■ Easier to monitor what is being learned and to guide the machine to better subspaces ■ A good lower level representation can be used for many distinct tasks (Zeiler and Fergus 2013)
Hierarchical Feature Learning Generalizable Learning ■ Shared lower level representations Multi-task learning Transfer learning Loss 2 + Loss 1 + Loss 3 task 2 task 1 task 3 task 4 Weights transfer Input A Input B
Deep Learning Modern Architecture AlexNet (Google photos 2013), VGG-Net (great impact on research) Google InceptionNet series (tensorflow) ResNet style (AlphaGo Zero) Lightweigt Networks e.g. squeezNet, MobileNet, deepCompression Teacher-Student Network (3D facial recognition of iPhone X) Attention based RNN Network (machine translation) etc.
Deep Learning Research Most recent Deep Learning models in research Image models ■ From 2D to multi-dimension convolutional neural networks, e.g. for 3D medical image analysis Image source:Thinkstock
Deep Learning Research Most recent Deep Learning models in research Image models ■ From 2D to multi-dimension convolutional neural networks, e.g. for 3D medical image analysis ■ Binary neural networks for low power devices
BMXNet Open Source BNN Implementation Based On MXNet ▪ Flexible design and fully compatible with standard neural network components ▪ Source code on GitHub (since 27th May 2017): https://github.com/hpi-xnor ▪ Demo: Binary-ResNet-18 for Image Recognition on smart phone ▪ Model size 45MB (full precision) => 1.5MB Chart 47
Deep Learning Research Most recent Deep Learning models in research Image models ■ From 2D to multi-dimension convolutional neural networks, e.g. for 3D medical image analysis ■ Lightweight model for low power devices e.g., BNN Sequence models ■ Recurrent neural networks, attention models … □ Image captioning □ Machine translation e.g., Google translator
Deep Learning Progress in Medicine Esteva et al. “Dermatologist-level classification of skin cancer with deep neural networks”, in Nature, 25 January 2017 Demonstrates capabilities of artificial intelligence in classifying skin cancer with a level of competence comparable to dermatologists (Esteva et al. 2017)
Deep Learning Progress in Medicine Rajpurkar, Ng et al. “Cardiologist-Level Arrhythmia Detection with Convolutional Neural Networks”, arXiv, 7 July 2017 ▪ Exceeds the average cardiologist performance in both recall (sensitivity) and precision (positive predictive value) (Rajpurkar et al. 2017)
Deep Learning Research Generative Model ■ DRAW: a recurrent network for image generation (Karol Gregor et al. 2016) ■ Variational Auto-Encoder (VAE) ■ Apply RNN for both encoder and decoder ■ Dynamic attention mechanism
Deep Learning Research Generative Model ■ GANs (Generative Adversarial Networks) (GoodFellow et al. 2014) is a novel framework for estimating generative models via an adversarial process (Isola et al. 2016) (Gharakhanian) (Nie et al. 2016)
Deep Learning Research Generative Model ■ Classic approaches for speech generation ■ Concatenative TTS (text-to-speech): a large database of short speech fragments ■ Parametric TTS: parameter model ■ WaveNet: directly modelling the raw waveform of the audio ■ Can model any kind of audio (Aaron van den Oord et al. DeepMind 2016)
Major Deep Learning Frameworks
Artificial Neural Network A Short History Lesson Single layer neural network: Perceptron = → Hidden layer ∆ = ƞ ∙ ∙ Frank Rosenblatt (1928-1971) Input Output ∆ : The changes in the i_th synaptic weight Ƞ : Learning rate : Activation value of i_th synapse : Output of j_th synapse Chart 56
Artificial Neural Network 1.0 Perceptron x_1 x_2 Output x_3 Perceptron Research from the 50's & 60's (source: youtube)
Artificial Neural Network 1.0 Perceptron Single layer neural network: Perceptron Not able to learn XOR logic because it is not linearly separable Not able to train multiple layers First AI Winter 1970s, a freeze to funding and publications Chart 58
Artificial Neural Network 2.0 Non-linear Activation Sigmoid function: 1 = 1 + − Chart 59
Artificial Neural Network 2.0 Non-linear Activation Sigmoid function Tanh Function ReLu 1 2 = tanh = −1 ( ) = max(0, ) 1 + − 1 + −2 = 2 2 − 1 Chart 60
Artificial Neural Network 2.0 Backpropagation ~1986 Backpropagation: “Learning representations by back-propagating errors” BP enables training multi-layer artificial neural networks Update weights using Gradient Descent BP is very efficient for calculating Loss ← −1 − Loss Geoffrey Hinton Chart 61
Artificial Neural Network 2.0 Backpropagation BP is biologically difficult to explain. BP not strictly in accordance with bionic neural network We cannot find similar mechanisms in human neural network BP algorithm needs accurate derivation, chain rule, matrix transpose etc. Chart 62
Artificial Neural Network 2.0 Backpropagation BP based on Gradient Descent algorithms non-convex optimization problem Convex optimization methods e.g. dominated by SVM Lacks of data and powerful hardware, cannot train deep network Second AI Winter SGD Objective function: min ( ) Strongly convex Non-convex function (Image source: Issam Laradji)
Artificial Neural Network 3.0 CNN, RNN ReLU + GPU Support + Large dataset Train deep network with BP Supervised learning The most popular algorithms in deep learning research today Convolutional Neural Networks (Lecun et al. “Backpropagation Applied to Handwritten Zip Code” 1989) Recurrent Neural Networks 1980s, e.g. LSTM (Hochreiter&Schmidhuber “Long short-term memory” 1997) Backpropagation (Hinton et al. 1986) Chart 64
Artificial Neural Network 3.0 Recent Efforts Recent efforts more based on Gradient Flow Sigmoid saturation, gradient vanishing problem : ReLU If x≤0, ReLU=0 : LeakyReLU, PReLU, ELU etc. Network too “deep”, gradient vanishing : highway (parameterized shortcut connection between layers) Simplified highway : ResNet (shortcut connection without params) Forced stability of the mean and variance of parameters : BatchNorm Adding noises in gradient flow : Dropout RNN with gradient exploding and vanishing : LSTM (by adding more gated controls) Simplified LSTM : GRU (gated recurrent unit) etc. Chart 65
Artificial Neural Network 3.0 Benefits End-to-end optimization possible by using BP Flexible architecture design, e.g. NIN, LSTM, Bi-LSTM, attentions, shortcut connections, deeper, wider etc. Large datasets available, e.g. ImageNet, YouTube 8M High performance computation BP based on tensor computation GPU is perfect for that Computation graph of NN is perfectly suitable for distributed computing A lot of open source deep learning frameworks and supported by both research communities and industries InceptionNet Chart 66
Deep Learning - Current Limitations Architecture Engineering Tuning hyperparameters of DNN is based on expert knowledge Network architecture Learning rate, decay, update method Activation function Regularization function Loss function Initialization method Optimization function etc. Not like SVM, standard grid search doesn't work for 60 million parameters (AlexNet) (Image source: Photographee.eu)
Deep Learning - Current Limitations Architecture Engineering AutoML? Neural architecture search by RL, (ICLR 2017) Evolution search (ICML 2017) Progressive search Transferable architecture Disadvantages E.g. Neural architecture search by RL: 800 GPUs, several months on CIFAR-10 Only available by Google
Deep Learning - Current Limitations Adversarial Samples Adversarial samples is a class of samples that are maliciously designed to attack machine learning models
Deep Learning - Current Limitations Adversarial Samples Adversarial Patch is one of the latest research results from Google [Brown17]
Deep Learning - Current Limitations Adversarial Samples Adversarial samples is a class of samples that are maliciously designed to attack machine learning models “without the dataset the article is useless” “okay google browse to evil dot com” Samples from : https://nicholas.carlini.com/code/audio_adversarial_examples/
Deep Learning - Current Limitations Adversarial Samples Adversarial samples Almost impossible to distinguish the difference between real and adversarial samples with naked eyes Will lead to wrong judgment of the model, but not the human Not specific images Not specific deep neural networks Attacks and defenses of adversarial samples is new research field
Deep Learning - Current Limitations Some Deep Learning‘s limitations mentioned by Gary Marcus [Marcus17] “Deep learning thus far is data hungry” (not only DL, but supervised learning) “Deep learning thus far is not sufficiently transparent” (medical imaging) Highly nonlinear Possible solution: Visualization techniques “Deep learning thus far has not been well integrated with prior knowledge” “Deep learning thus far works well as an approximation, but its answers often cannot be fully trusted” “Deep learning thus far is difficult to engineer with” “Machine learning as yet lacks the incrementality, transparency and debug ability of classical programming, trading off a kind of simplicity for deep challenges in achieving robustness.” --- Google SVP Peter Norvig (2016)
Prior Knowledge Unsupervised learning without label, but how to learn? The reasonable ideas and direction can help us to learn knowledges more efficiently “The reasonable ideas and direction” are Prior Prior knowledge is generally important for machine learning models Why CNN (Convolutional Neural Network) works much better than other DNNs in computer vision problem? CNN has a strong prior: Locality CNN learns local context, then converge to the global context Why Gradient Boosting or Random Forest methods are AlphaGo, Google Deepmind better than CNN in Kaggle challenges for table data? Chart 74 Those data lack of local correlations
Clustering Clustering Prior: Emphasize the spatial correlation, items from the same class should be closer to each other in the data space K-Means 2 =1 − Emphasize uniformity EM (Expectation-Maximization) clustering =1 log( − ) Emphasize density Which one is better?
Neural Network 4.0? Hinton proposed Capsule inspired by Neuroanatomy Cognitive Neuroscience Computer Graphics Geoffrey Hinton (2013) Visual cortex is hierarchical, but Large amount of Cortical Minicolumns in cortex Human NN is much more complicated than ANN Mini-column is statistically meaningful, what is the functional meaning? Cortical Minicolumn
Neural Network 4.0? Human vision prior Chart 77
Neural Network 4.0? Chart 78
Neural Network 4.0? Chart 79
Neural Network 4.0? The illusion of human also implies that human and algorithmic models are limited by the "no free lunch theorem", and that human cognition is not particularly different from the algorithm, and perhaps it can be reproduced by algorithms Chart 80
Neural Network 4.0? The illusion of human Human vision has coordinate frame, which influence the perception system. Chart 81
Neural Network 4.0? Real Brief Intro Capsule is a set of (coarse-coded) neurons Invariance e.g., CNN: Represent(X) = Represent(Transform(X)) Equivariance : Transform(Represent(X)) = Represent(Transform(X)) Place-coded (low level): big changes of object location in visual content occurred, use different capsule to represent its content Rate-coded (high level): small changes of object location occurred, use the same capsule to represent it, but change its content Coincidence filtering : low level capsule high level capsule Clustering, calculating cluster scores Dynamic routing based on cluster scores Use multiple linear function (Matrix) to represent the relationships of visual entities The relationship is not affected by the transformation of viewpoint Chart 82
Neural Network 4.0? Real Brief Intro Capsule is a set of (coarse-coded) neurons Equivariance : Transform(Represent(X)) = Represent(Transform(X)) Dynamic routing Matrix manipulation of visual entities (objects) Multi-digit MNIST: CapNet reconstruction result: (Sabour, Hinton et al. 2017)
Content Course roadmap Teaching team Multimedia analysis and Deep Learning Important information
Tools and Hardware ■ Deep learning framework ■ Keras/Tensorflow, MXNet, Caffe/Caffe2, Chainer, PyTorch… ■ GPU Servers from ITS chair 85
Literature ■ Book: "Deep Learning", Ian Goodfellow, Yoshua Bengio and Aaron Courville, online version: www.deeplearningbook.org ■ cs231n: Convolutional Neural Networks for Visual Recognition, course of Standford University ■ Deep Learning courses at Coursera, created by Andrew Ng and deeplearning.ai, MOOC ■ Practical Deep Learning For Coders, created by fast.ai, MOOC ■ “Deep Learning - The Straight Dope” http://gluon.mxnet.io, deep learning tutorials created by MXNet team 86
Grading Policy Lecture Written exam (40%, 25.06.2018) Project Final presentation (20%, 16.07.2018) Codes and paper (40%, until 31.08.2018) 87
Prerequisite Programming in Python Experience with C/C++ as a plus Calculus, Linear Algebra Begeisterung und Phantasie Chart 88
Contact Dr. Haojin Yang Dr. Xiaoyin Che Christian Bartz, M.sc Office: H-1.22 Office: H-1.22 Office: H-1.11 Email: xiaoyin.che@hpi.de Email: chrisitan.bartz@hpi.de Email: haojin.yang@hpi.de Mina Rezaei, M.sc Goncalo Mordido, M.sc Joseph Bethge, M.sc Office: H-1.22 Office: H-1.22 Office: H-1.21 Email: mina.rezaei@hpi.de Email: Goncalo.Mordido@hpi.de Email: joseph.bethge@hpi.de
Thank you for your Attention! Next lecture: Machine learning basics Competitive Problem Solving with Deep Learning Course Website
Reference [Goodfellow15] Ian Goodfellow et al., „Expaining and harnessing adversarial examples“, ICLR 2015 [Brown17] Tom B. Brown et al., „Adversarial Patch“, arXiv preprint arXiv:1712.09665 [Gary17] Gary Marcus, „Deep Learning: A Critical Appraisal” Chart 91
You can also read

















































