SP-DARTS: Synchronous Progressive Differentiable Neural Architecture Search for Image Classification
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
IEICE TRANS. INF. & SYST., VOL.E104–D, NO.8 AUGUST 2021
1232
PAPER Special Section on Computational Intelligence and Big Data for Scientific and Technological Resources and Services
SP-DARTS: Synchronous Progressive Differentiable Neural
Architecture Search for Image Classification
Zimin ZHAO†a) , Nonmember, Ying KANG† , Student Member, Aiqin HOU†b) , and Daguang GAN†† , Nonmembers
SUMMARY Differentiable neural architecture search (DARTS) is now which is unaffordable for lots of researchers. Many efforts
a widely disseminated weight-sharing neural architecture search method explore ways to reduce search time. DARTS [6] brings NAS
and it consists of two stages: search and evaluation. However, the original
into the second stage: differentiable search, which deviates
DARTS suffers from some well-known shortcomings. Firstly, the width
and depth of the network, as well as the operation of two stages are dis- completely from reinforcement learning and evolutionary
continuous, which causes a performance collapse. Secondly, DARTS has a algorithms. DARTS uses multiple cell stacks, each of which
high computational overhead. In this paper, we propose a synchronous pro- is represented by a directed acyclic graph (DAG) consist-
gressive approach to solve the discontinuity problem for network depth and ing of multiple nodes. A relaxation method is used to train
width and we use the 0-1 loss function to alleviate the discontinuity prob-
lem caused by the discretization of operation. The computational overhead
the mixed operations among nodes by a gradient descent ap-
is reduced by using the partial channel connection. Besides, we also dis- proach, thus reducing the computational overhead to single-
cuss and propose a solution to the aggregation of skip operations during the digit GPU days. NAS aims at searching for the model of the
search process of DARTS. We conduct extensive experiments on CIFAR- highest accuracy with the least search time, and the model
10 and WANFANG datasets, specifically, our approach reduces search time
size should be as small as possible. DARTS overcomes the
significantly (from 1.5 to 0.1 GPU days) and improves the accuracy of im-
age recognition. issue of high computational cost in traditional methods and
key words: NAS, DARTS, skip operation, synchronous progressive, image greatly reduces search time while ensuring model accuracy.
classification It has become a new focus of research in NAS after rein-
forcement learning and evolutionary algorithms. DARTS
1. Introduction can search for a well-performing model automatically by ap-
plying a search strategy, which costs less computation and
Image classification is one of the basic tasks in the field of less time. However, DARTS still suffers from many draw-
computer vision. In 2012, AlexNet [1] improved the accu- backs, such as discontinuous network configuration, skip
racy of image classification tremendously using an eight- operation aggregation, etc., which affect the performance
layer convolutional network and won the ImageNet com- of the search algorithm. Therefore, it is important to in-
petition championship. Since then, the convolutional neu- vestigate and solve these problems to improve accuracy and
ral network has become the mainstream approach for im- performance.
age classification, and various networks have been designed The rest of the paper is organized as follows. We first
to improve the performance [2]–[5]. In the past, most re- review the related work on NAS in Sect. 2. Then, we pro-
searchers designed neural networks manually. However, this pose SP-DARTS in Sect. 3. We evaluate the performance of
situation has changed recently due to the development of the proposed approaches through extensive experiments on
neural architecture search (NAS), which achieved great suc- the CIFAR-10 dataset in Sect. 4. We conclude our work in
cess in image classification. For image classification, NAS Sect. 5.
is expected to design the search space, and learn to discover The main contributions of our work are summarized as
neural network architectures with good performance auto- follows:
matically. The development of NAS mainly goes through
two stages according to the search strategy. In the first stage, • We propose an efficient “synchronous progressive
although the search strategy has achieved good performance method” for DARTS to bridge the depth and width gap
by applying reinforcement learning or evolutionary algo- between search and evaluation, and demonstrate its su-
rithms, the computational overhead is still considerably high periority over standard DARTS in terms of accuracy
as it often takes hundreds or even thousands of GPU days, and search time.
Manuscript received November 11, 2020. • We apply partial channel connections (PC) and edge
Manuscript revised January 13, 2021. normalization (EN) to reduce computing overhead
Manuscript publicized April 23, 2021. caused by the synchronous progressive method. The
†
The authors are with School of Information Science and Tech- search stage in DARTS typically costs 1.5 GPU-days,
nology, Northwest University, Xi’an, Shaanxi 710127, China. and we reduce this time to 0.1 GPU-days without per-
††
The author is with Wanfang Data Co., Beijing, 100038,
formance loss.
China.
a) E-mail: zhaozimin@stumail.nwu.edu.cn • We explore the impact of channels of the network and
b) E-mail: houaiqin@nwu.edu.cn (Corresponding author) the sampling rate K of the PC method on skip aggre-
DOI: 10.1587/transinf.2020BDP0009 gation phenomenon and provide justifications for such
Copyright ⃝
c 2021 The Institute of Electronics, Information and Communication Engineers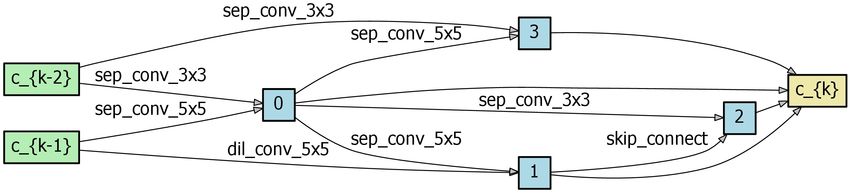
ZHAO et al.: SP-DARTS: SYNCHRONOUS PROGRESSIVE DIFFERENTIABLE NEURAL ARCHITECTURE SEARCH FOR IMAGE CLASSIFICATION
1233
impact. gation, and utilized edge regularization to solve the problem
• We conduct experiments to show the skip operation ag- of search instability [15]. Chu et al. pointed out the reason
gregation phenomenon caused by DARTS and employ for skip operation aggregation is that the softmax relaxation
the Sigmoid activation function to eliminate this phe- method of discrete operations causes unfair competition in
nomenon. the processing of gradient descent of weight [16]. There-
fore, they used a sigmoid relaxation function to solve this
problem, and proposed a one-zero loss function to acceler-
2. Related Work ate the convergence speed of mixed operation weights.
Some early studies proposed pioneering search architectures 3. The Proposed Approach
based on reinforcement learning (RL) [7]–[9]. NASNet can
generate strings that represent the structure of neural net- This section introduces a DARTS-based framework of neu-
works through RNN [7], and continuously update the gradi- ral architecture search to address the drawbacks of the orig-
ent of strategy to generate a network architecture with bet- inal DARTS.
ter performance. However, the procedure is computationally
very intensive and can only process small data sets. NASNet 3.1 Preliminary: Differentiable Architecture Search
is among the first that proposed a cell-based search space, (DARTS)
where a cell is a DAG consisting of an orderly sequence of
nodes. NASNet searches for operation types and topological Our proposed algorithm is based on DARTS [6], which has
connections in the cell and repeats the cell to form the entire two stages for search and evaluation. During the search
network architecture. The depth, width, and sampling oper- stage, a model stacked with L cells is used to search, and the
ation of the architecture are all set manually, which greatly input of each cell is two previous cells. A cell is defined as
improves the search efficiency of the algorithm compared a directed acyclic graph (DAG) consisting of a sequence of
with the work in [7]. The approaches based on evolution- N nodes denoted as {x0 , x1 , · · · , xN−1 }. The number of input
ary algorithms (EA) [10]–[12] have also achieved great per- and output channels for each cell except for input node and
formance. Some research efforts applied EA to the search output node is denoted as C. There are 8 operations defined
field to initialize a neural network model population, from in search space (O), including the operations of 3×3 and 5×5
which each individual model is evaluated for its adaptability separable convolutions, 3×3 and 5×5 dilated separable con-
on the validation set. The algorithm proceeds to reproduce volutions, 3 × 3 max pooling, 3 × 3 average pooling, identity,
and mutate the superior architectures while eliminating the and zero. Each operation represents some function o(·), and
inferior ones. RL- and EA-based methods generally incur each edge E(i, j) represents the mixed weighted operation
very high computational overhead. DARTS is the first work from node(i) to node( j) , where the weights are parameter-
that applies a gradient-based method to the field of NAS and ized by vector α(i, j) . We make the search space continuous
reduces the search time to 1.5 GPU days. Liu et al. initial- using softmax over all operations as follows:
ized all operations between nodes in each cell and gener- ∑ exp(α(i, j)
o )
ated weights using multi-cell stacking. They also relaxed the o(i, j) (x) = ∑ o(x). (1)
search space to be continuous, so that the architecture can be oϵO o′ ϵO exp(α(i,
o′
j)
)
optimized by gradient descent and reduce the computational The output of each intermediate node is expressed as:
cost in the procedure of search [6]. A significant number of ∑
research efforts are based on [13] to improve differentiable xj = o(i, j) (x(i) ). (2)
search. Xin et al. [14] pointed out that the depth discontinu- i< j
ity of the search stage and evaluation stage in [6] causes the The output node of a cell is calculated as:
low accuracy of the search model. They also proposed to
divide the search process into multiple stages, increase the xN−1 = concat(x2 , x3 , . . . , xN−2 ). (3)
network depth continuously to address the discontinuity of The training and valid loss are determined by the ar-
depth, and discard some of the operations when switching chitecture α and weights w of network, denoted by Ltrain
the search stage to adapt GPU memory. Their result shows and Lval . The optimization approach is as follows:
that the accuracy is improved and the search time is reduced
to 0.3 GPU days. GDSA [7] is proposed with a partial op- min Lval (w∗ (α), α)
α
timization subgraph method and a new loss function, which (4)
s.t. w∗ (α) = argminw Ltrain (w, α),
reduced the search time to 0.21 GPU days. In addition, the
work in [7] also mentioned that many architecture search where the weights w∗ is obtained by minimizing the training
techniques of reduction cell are very similar, and designed loss Ltrain . In the search stage, the network depth L = 8, and
reduction cell manually, which can reduce search time and the initial number of channels C = 16. There are N = 7
improve search accuracy in the search stage. Xu et al. pro- nodes in each cell, including two input nodes, four interme-
posed PC-DARTS to reduce the search time by partial chan- diate nodes, and one output node. In the evaluation stage,
nel sampling, solved the problem of skip operation aggre- the structure of each cell remains the same as the search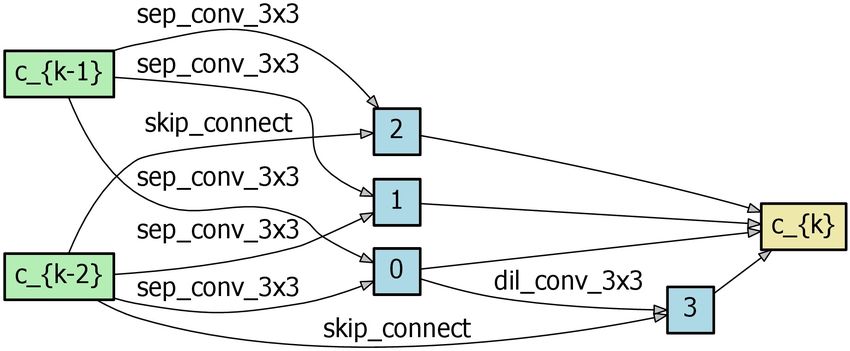
IEICE TRANS. INF. & SYST., VOL.E104–D, NO.8 AUGUST 2021
1234
stage, but the depth L is increased from 8 to 20 and the Algorithm 1 SP-DARTS
number of channels C is increased from 16 to 36. The opti- Input: Number of search stages T ; The network depth, channels for stage
mal model selected from the search stage is determined after t: Layert , Channelt ;
The proportion of PC selected channels for stage t: Kt ;
training on the training dataset and evaluation on the valid
Initial architecture α, model weights ω, edge normalization coefficient
dataset. β;
Number of saved operations for stage t: Ot ;
3.2 Synchronous Progressive DARTS for t = 1 to T do
Update network configuration to Layert , Channelt , Kt ,
Ot ;
The network depth and width are not continuous between Reinitialize architecture α, model weights ω, and EN
the search and evaluation stages of DARTS: the depth is coefficient β based on Ot ;
from 8 cells to 20 cells, and the width (i.e., the initial number while not converged do
of channels) is from 16 to 36. It is well known in the neu- Sample a batch of training data Xtrain and a batch of
validation data Xval ;
ral architecture search algorithm that if the model performs Update α and β by descending ∇α (Lval (ω, α, β)+
well in the search stage, it also performs well in the evalua- ω0−1 L0−1 ), ∇β (Lval (ω, α, β) + ω0−1 L0−1 );
tion stage. In other words, the model with good performance Update ω by descending ∇ω Ltrain (ω, α, β);
in the search stage performs well with probability P in the end while
end for
evaluation stage. Therefore, the higher the probability P is,
Derive the final architecture based on the learned α and β;
the better performance of the search algorithm has. How-
ever, the discontinuity of depth and width may reduce the
probability P, as the continuity worsens, and the difference
of performances between the search and evaluation stages is
greater. To address this drawback, we propose an approach
based on DARTS to change the depth and width in a syn-
chronous progressive way during the search stage, referred
to as SP-DARTS (Synchronous Progressive DARTS), which
divides the search process into three stages. The steps of SP- Fig. 1 Difference between DARTS and SP-DARTS.
DARTS are shown in Algorithm 1. The search process in the
original DARTS and our SP-DARTS are shown in Fig. 1 (a)
and (b), respectively, for comparison.
In SP-DARTS, we adopt a staged strategy that splits the
search process into three stages where the depth and width
are gradually increased from 5 to 20, and from 16 to 36, re-
spectively. At the end of each stage, the depth and width
of the model are increased for the next stage. The proce-
dure is provided in Fig. 2. The algorithm divides the search
process into three stages, each of which performs the same
process with different network settings. In the first stage, 3
normal cells and 2 reduction cells are stacked, so the depth
of the network is 5. The number of input and output chan- Fig. 2 Search space approximation.
nels of each cell is set to 16, so the width of the network is
16. The second stage initializes the network to a depth of 11 1, 2 and 3 are four intermediate nodes in the cell, the lines
and a width of 24. The third stage initializes the network to of different colors represent different operations. After the
a depth of 17 and a width of 32. The same process is carried first stage, four operations with the maximum weight are re-
out in each search stage: the model parameters and archi- tained according to the operation weight, while other oper-
tecture parameters of the network are optimized by gradient ations are discarded. After the second stage, two operations
descent according to Eq. (8). After search, the evaluation are retained in the same way, and one operation is retained
stage initializes the network to a depth of 20 and a width after the third stage.
of 36. This way, the network’s depth and width are gradu- The progressive method in SP-DARTS can learn more
ally increased, and the discontinuity between the search and complex representations with the increasing depth of the
evaluation stages is addressed. However, the computational network, whereas each layer becomes simpler [17], [18].
cost during the process increases linearly with respect to the Similarly, the network can learn more abundant features
depth of the model, and increases by power of two with re- with an increasing width [19]. Because the network depth
spect to the width. Therefore, SP-DARTS cannot run on a and width are different, we propose a synchronous progres-
single GPU directly. In order to address this problem, we sive method in the search stage to make the depth and width
use the ”search space approximation” method proposed in approximate to the corresponding values in the evaluation
[14], which progressively reduces the operations in differ- stage. Therefore, the operations of the final network archi-
ent stages to fit into a GPU. As shown in Fig. 2, while 0, tecture are different with a high probability.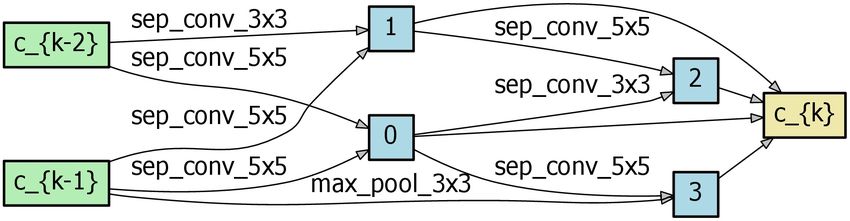
ZHAO et al.: SP-DARTS: SYNCHRONOUS PROGRESSIVE DIFFERENTIABLE NEURAL ARCHITECTURE SEARCH FOR IMAGE CLASSIFICATION
1235
3.3 Problems of Memory Inefficiency and Skip Operations
Aggregation
A drawback of DARTS lies in memory inefficiency [15].
In the search stage, the network width is large so that the
storage of convolution template parameters of intermediate
Fig. 3 The number of skip connections when searching with DARTS.
nodes and the storage of output results take up a large pro-
portion. The batch size of training needs to be limited to to the aggregation of weak parameter operations. In addi-
complete the search on a single GPU, which reduces the tion, such unfairness affects the operation competition of all
search speed and accuracy. Besides, the full channel con- precursor nodes of each node, which greatly inhibits the in-
nections restrict the network’s depth and width from setting crease of operation weight, as it might be better in the future
a large number potentially in the search stage, which also during the search stage, and affects the performance of the
affects the search’s accuracy. Following the partial channel search model. If sigmoid activation function is applied ac-
connections method proposed in [15], we propose the in- cording to Eq. (5), the relation between operations is free,
formation flow between nodes in the cell as the following and fair competition is thus established. Even if the activa-
expression: tion value of weight reaches the upper limit of 1, weights
∑ of other operations can continue to update well, so as to
fi, j (xi , si, j ) = σ(αoi, j ) · o(S i, j ∗ xi ) + (1 − S i, j ∗ xi ), (5) mitigate the weak parameter operation aggregation. Also,
oϵO
it is proved in [15] that the edge normalization method can
where σ() represents the sigmoid activation on σoi, j , and solve the search instability problem caused by partial chan-
S i, j ∗ xi and (1 − S i, j ∗ xi ) denote the selected and masked nel sampling and improves the search quality. Therefore,
channels, respectively. The hyper-parameter K is set to ex- the intermediate node is calculated as:
press the proportion of selected channels by 1/K. The par- ∑ exp(βi, j )
tial channel connections also mitigate the skip operation ag- xj = ∑ · fi, j (xi ), (6)
i< j k< j exp(βk, j )
gregation problems in DARTS. In the early studies, archi-
tecture search algorithms generally preferred no parameter where βi, j denotes the weight from node(i) to node( j), and
or weak parameter operations because they had few param- fi, j (xi ) denotes the value of forward propagation. The rule
eters to train, and thus the output was more continuous. By that the input weights of precursor nodes of each intermedi-
contrast, for those operations with more parameters, each ate node are equal is broken by using edge normalization.
epoch’s update transmits discontinuous information before
all parameters are well optimized. As a result, weak pa- 3.4 Problem of Mixed Operation Discretization
rameter operations tend to accumulate an enormous weight.
It is difficult for other operations to ”defeat” them, even if As mentioned before, in the evaluation stage of DARTS,
they have been trained to a certain extent. According to the there are problems of discontinuities of network depth and
statistics of the number of skip operations through running width, but there still exists a problem: discretization of
DARTS for 3 times, as can be seen from the Fig. 3, with the mixed operations. According to the method proposed in [6],
increase of training epochs, DARTS has a severe skip oper- the operation with the largest weight in mixed operation of
ation aggregation phenomenon. Partial channel connections all precursor nodes for each intermediate node is selected
limit the number of skip operations because the operation first after the search stage, so that there is only one oper-
between nodes only passes through the partial channel. It ation for the edge from each precursor node to this node.
can be more effective by sampling a part of super-net to re- Then two precursor nodes with the maximum weight are se-
duce the redundant space without any performance loss. lected to determine the cell structure. However, we found
In this paper, we not only adopt partial channel connec- that these weights are very close to each other through run-
tions, but also use a sigmoid function to activate the mixed ning DARTS. At the end, it is hard to tell which operations
operation, which addresses unfair competition between op- are good and which ones are bad. It is expected that one-hot
erations in the search stage. It has been pointed out in the architecture will be generated at the end of the search stage
literature that the root cause of the skip operations aggre- of DARTS, where the selected operation has a weight of 1
gation and weak parameter operations is the unfair compe- and the unselected operation has a weight of 0. Therefore,
tition between operations in the search stage [16]. Specif- we use the sigmoid function and set the activation value to
ically, softmax relaxation was used for mixing operations be either 0 or 1. This way, the difference between the model
between nodes within a cell in the DARTS. The nature of after searching and the model after discretization is smaller,
the softmax function determines that an increase of one op- and the performance loss also becomes smaller. The addi-
eration weight results in a decrease of the others, affecting tional loss function [16] is as follows:
competition between operations in mixed operation. The in-
1 ∑
N
crease of weight in the early stage of weak parameter opera- L0−1 = − (σ(αi ) − 0.5)2 , (7)
tion greatly weakens the weight of other operations, leading N i
IEICE TRANS. INF. & SYST., VOL.E104–D, NO.8 AUGUST 2021
1236
Table 1 Comparison of NAS algorithms on CIFAR-10.
where N is the total number of operations in a cell. The
loss of additional function is minimum when σ(αi ) is 0 or
Params Test Error Search Cost
Models Type
(M) (%) (GPU-days)
1, and the loss is maximum when σ(αi ) is 0.5. The weight DenseNet-BC[25] 25.6 3.46 - manual
NASNET-A[2] 3.3 2.65 2000 RL
σ(αi ) converges faster in the direction of 0 or 1 using this BlockQNN[26] 39.8 3.54 96 RL
AmoebaNet-B[23] 2.8 2.55 3150 evolution
additional loss function, and the muti-hot architecture will Hireachical Evolution[12] 15.7 3.75 300 evolution
be formed at the end of search. It also expands the solution PNAS[28] 3.2 3.41 225 SMBO
ENAS[27] 4.6 2.89 0.5 RL
space compared to one-hot. In this paper, the optimization DARTS(first order)[14] 3.3 3.00 1.5 gradient-based
method is as follows: DARTS(second order)[14]
SNAS[29]
3.3
2.8
2.76
2.85
4
1.5
gradient-based
gradient-based
min Lval (w∗ (α)) + w0−1 L0−1
GDAS[18] 3.4 2.93 0.21 gradient-based
Random search baseline 3.2 3.29 4 random
α
(8) SP-DARTS(a) 3.64 2.71 0.11 gradient-based
∗
s.t.w (α) = argminw Ltrain (w, α), SP-DARTS(b) 3.66 2.78 0.11 gradient-based
where w0−1 is the weight of loss function L0−1 , and as in
Eq. (4), W represents model parameters, and α represents
architecture parameters. The search algorithm optimizes
model parameters with training dataset, and optimizes the
architecture parameters with validation dataset. The dis-
cretization method after searching is to multiply the weight
activation value σ(αi, j ) and the edge normalization coeffi-
exp(βi, j )
cient ∑k< j exp(β k, j )
, and then generate the architecture accord-
ing to the discretization method in DARTS. Therefore, the
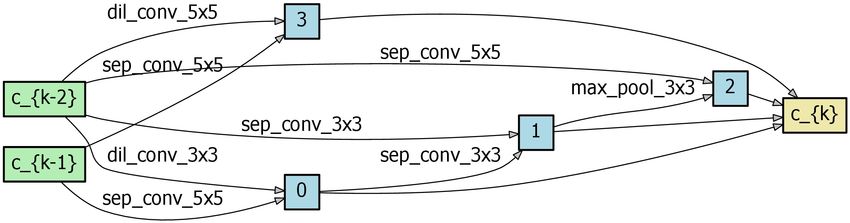
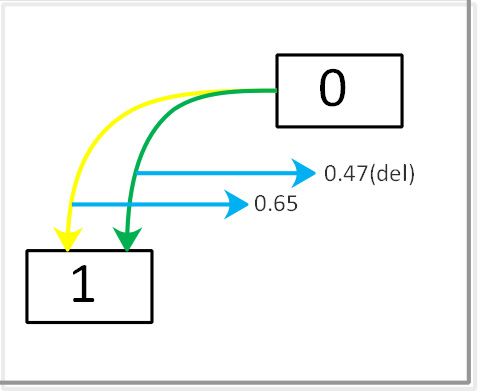
combined flow of Eq. (3), Eq. (5), Eq. (6) and Eq. (8) consti- Fig. 4 Search result
tute our method in this paper; Eq. (5) and Eq. (6) are the cal-
culation methods of intermediate nodes within a cell; Eq. (3) ing 15 epochs. The architecture parameters are optimized
is the calculation method of the output of each cell, and by Adam optimizer, where the learning rate η = 0.0006,
Eq. (8) is the optimization goal of the overall algorithm. The weight decay wd = 0.001 and momentum β = (0.5, 0.999).
rest of the algorithm is the same as DARTS. The model parameter optimizer adopts momentum SGD op-
timization. The initial learning rate η = 0.025, which is
4. Experiments and Results decayed to 0 following the cosine rule, and the momentum
β = 0.9, weight decay wd = 0.0003, the weight of loss
We conduct experiments on image classification datasets function L0−1 w0−1 = 10. The search results of the model
of CIFAR-10, which has 50k/10k training/testing RGB im- are shown in Table 1. SP-DARTS(a) results from using loss
ages with a spatial resolution of 32 × 32. These images function L0−1 , and SP-DARTS(b) is the result without loss
are equally distributed over 10 classes. The training dataset function L0−1 . The experiments are performed on a single
is equally split into two subsets in the architecture search Tesla V100 GPU and cost 0.11 GPU days. Compared with
stage, one for tuning network parameters, the other for tun- DARTS, it is clear that the search time is reduced and the
ing the architecture. In the evaluation stage, the standard model accuracy is improved. Figure 4 shows the searched
training/testing is used. model, where the search depths of (a), (b) and (c) are 5, 11
and 17, respectively, and the initial number of channels is
4.1 Architecture Search 16, 24 and 32, respectively. We observe that the cell be-
comes more hierarchical as the search progresses. (d) is the
The search process consists of 3 stages. The network config- normal cell searched by DARTS v2.
urations are the same as DARTS, except that the zero oper-
ation is dropped. Since zero operation has no gradient, it is 4.2 Architecture Evaluation
useless without a softmax function. In the initial stage (stage
1), the network depth L = 5, the initial channel number The same as DARTS, in the evaluation stage, the model is
C = 16, partial channel sampling K = 4. In the intermediate stacked with 20 cells and 36 initial channels, and model pa-
stage (stage 2), L = 11, C = 24, K = 4. In the final stage rameters are initialized randomly and trained with a batch
(stage 3), L = 17, C = 32, K = 4. Meanwhile, the opera- size of 128 for 600 epochs. We also use the cutout regular-
tion space’s size in three stages is 7, 4, and 2, respectively. ization [20] with the length of 16, Drop-path [21] with a rate
After the final search stage is completed, only one operation of 0.3 and auxiliary towers [5] with a weight of 0.4. The
left to generate the model structure. For each stage, we train standard SGD optimizer and momentum gradient descent
the network using a batch size of 256 for 25 epochs. Since method are adopted, where the weight decay wd = 0.0003,
the partial channel sampling is applied, the larger batch size momentum β = 0.9, and initial learning rate η = 0.025 and
is allowed for acceleration.In the first 10 epochs, only the is decayed to 0 using cosine annealing.
network parameters are tuned at each stage, while the net-
work and architecture parameters are tuned in the remain-
ZHAO et al.: SP-DARTS: SYNCHRONOUS PROGRESSIVE DIFFERENTIABLE NEURAL ARCHITECTURE SEARCH FOR IMAGE CLASSIFICATION
1237
Fig. 5 Weight thermal diagram Fig. 6 Comparative experiment on K.
4.3 Diagnostic Experiments mixed operation. A concatenation operation of other chan-
nels not processed is adopted when reaching the front node,
4.3.1 Utility of Loss Function which is essentially equivalent to skip operation, and more
original information of nodes is retained. Therefore, addi-
In Eqs. (1), the softmax function is adopted in DARTS to tional skip operations are not very necessary in the search
activate the mixed operation between nodes in the cell, and process. However, having no skip operation in the search
the result of weight is in (0,1), which makes the weights of result is also one of our approach’s drawbacks. The removal
mixed operations very similar after searching. In this pa- of the skip operation will affect the capability of the model.
per, comparative experiments on the activation for opera- For the architecture search methods such as DARTS, it is
tion weight and whether to add the loss function L0−1 are essential to find K, the depth L, and initial channel number
conducted additionally. The results are provided in Fig. 5. C to balance if partial channel connection is adopted. If K
The combination of sigmoid activation and L0−1 makes the is too large, the aggregation of weak parameters operation
difference in operations weights larger. It is easier to distin- will be severe. While K is too small, the inhibitory of weak
guish the quality of the operation and the architecture struc- parameter operation will be strong.
ture is more reasonable. We further apply SP-DARTS to the image resource of
WAN FANG datasets to search for a required image. The
4.3.2 Discussion of Skip Operation Aggregation experimental results show that our method performs well on
other datasets and has a good generalization capability.
We conduct comparative experiments on partial channel
sampling proportion K. As shown in Fig. 6, the x-axis is the 5. Conclusion
number of epochs in each training stage. Since the first 10
epochs are only used to tune the model parameters, which This paper proposed a synchronization progressive ap-
do not affect the architecture parameters, we consider the proach based on DARTS for network depth and width and
epochs starting from 10 to 25 in the experiment. The param- adopted several effective optimization methods in the lat-
eters of exp1 in the three stages include the network depth est studies. The experiments are conducted on the CIFAR-
L = 8−8−8, the initial number of channel C = 16−32−64, 10 and WANFANG datasets, and the results show that the
and partial channel sampling proportion K = 4 − 4 − 4. The search time is reduced to 0.1 GPU days with high accuracy.
parameters of exp2 in the three stages are the network depth Meanwhile, we also found some cases in the experi-
L = 8−8−8, the initial number of channel C = 16−32−64, ments where the comparative experiments were designed to
and partial channel sampling proportion K = 4 − 8 − 8. make it clear and provide a preliminary explanation. There
Each experiment is executed twice with a different random are some drawbacks of the proposed method, such as ex-
seed. Two conclusions drawn from these two experiments: cessive inhibition of skip operation. The neural architecture
1) The skip operations aggregation in DARTS is aggravated search (NAS) algorithm still has no unified standard. Var-
with the increase of the initial number of channels; 2) Par- ious training processes and various parameters make it dif-
tial channel connection inhibits skip operation, and the in- ficult to know each step’s exact contribution to the results.
hibitory effect increases with the increase of K. Although the differential scheme greatly reduces the search
The reasons for such conclusions are discussed as fol- time, the training process is still very time-consuming. In
lows: For conclusion 1), with the increasing number of ini- the future, the evaluation stage’s time cost will be greatly
tial channels, the features that can be extracted are richer, so reduced with the development of computing hardware and
the model can achieve the performance with fewer channels the further study of model evaluation. For the improvement
in the case of more skip operations. On the other hand, the of DARTS, a feasible direction is to break the sharing cell
larger the model is, the more discontinuous the output gra- scheme and the fixed structure of the cell, which will enrich
dient of loss for multi-parameter operations will be. There- the search space and be beneficial to searching for a better
fore, the model will prefer the skip operations that make model. In conclusion, it is hoped that deep learning will
the loss function decay rapidly. For conclusion 2), partial develop towards automation with the development of NAS,
channel sampling is adopted to transmit forward through the which can achieve a better model architecture.
IEICE TRANS. INF. & SYST., VOL.E104–D, NO.8 AUGUST 2021
1238
[18] M.D. Zeiler and R. Fergus, “Visualizing and understanding convolu-
Acknowledgments tional networks,” Proc. 13th European Conf. Comput. Vis., (ECCV),
LNCS, vol.8689, 2014, pp.818–833, 2014.
This research is sponsored by National Key Research [19] Z. Lu, H. Pu, F. Wang, Z. Hu, and L. Wang, “The expressive power
of neural networks: a view from the width,” NIPS’17 Proc. 31st Int.
and Development Plan of China under Grant No. Conf. Neural Information Processing Systems, pp.6232–6240, 2017.
2017YFB1400301. Thanks for the collaboration of Dr. [20] T. DeVries and G.W. Taylor, “Improved regularization of
Liqiong Chang. convolutional neural networks with cutout,” arXiv preprint
arXiv:1708.04552, 2017.
References [21] G. Larsson, M. Maire, and G. Shakhnarovich, “Fractalnet: Ultra-
deep neural networks without residuals,” ICLR 2017: Int. Conf.
[1] A. Krizhevsky, I. Sutskever, and G.E. Hinton, “Imagenet classifica- Learning Representations 2017, 2017.
tion with deep convolutional neural networks,” Communications of
The ACM, vol.60, no.6, pp.84–90, June 2017.
[2] K. Simonyan and A. Zisserman, “Very deep convolutional networks
for large-scale image recognition,” ICLR 2015: Int. Conf. Learning
Representations 2015, 2015.
[3] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for im-
age recognition,” 2016 IEEE Conf. Comput. Vis. Pattern Recognit.
(CVPR), pp.770–778, 2016. Zimin Zhao received the B.S. degree
[4] A.G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. in Electronic Information Science from North-
Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient con- west University in 2020. His researches focus
volutional neural networks for mobile vision applications,” arXiv on automated machine learning and automated
preprint arXiv:1704.04861, 2017. deep learning.
[5] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov,
D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with
convolutions,” 2015 IEEE Conf. Comput. Vis. Pattern Recognit.
(CVPR), pp.1–9, 2015.
[6] H. Liu, K. Simonyan, and Y. Yang, “Darts: Differentiable architec-
ture search,” ICLR 2019: 7th Int. Conf. Learning Representations,
2019.
[7] B. Zoph and Q.V. Le, “Neural architecture search with reinforce- Ying Kang received the B.S. degree in
ment learning,” CoRR, vol.abs/1611.01578, 2016. School of Software Engineering from North-
[8] B. Zoph, V. Vasudevan, J. Shlens, and Q.V. Le, “Learning west University. Her researches focus on recom-
transferable architectures for scalable image recognition,” CoRR, mendation system and distributed system. She
vol.abs/1707.07012, 2017. is now a graduate student in School of Informa-
[9] Z. Zhong, J. Yan, W. Wu, J. Shao, and C.L. Liu, “Practical block- tion Science and Technology from Northwestern
wise neural network architecture generation,” 2018 IEEE/CVF University.
Conf. Comput. Vis. Pattern Recognit., pp.2423–2432, 2018.
[10] J.D. Dong, A.C. Cheng, D.C. Juan, W. Wei, and M. Sun, “Dpp-
net: Device-aware progressive search for pareto-optimal neural ar-
chitectures,” Proc. European Conf. Comput. Vis. (ECCV), LNCS,
vol.11215, pp.540–555, 2018.
[11] H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu, Aiqin Hou received the Ph.D. degree in
“Hierarchical representations for efficient architecture search,” school of information science and technology
ICLR 2018: Int. Conf. Learning Representations 2018, 2018. from Northwest University in 2018. She is cur-
[12] E. Real, A. Aggarwal, Y. Huang, and Q.V. Le, “Regularized evo- rently an Associate Professor with the School
lution for image classifier architecture search,” Proc. AAAI Conf. of Information Science and Technology, North-
Artifi. Intelli., vol.33, no.1, pp.4780–4789, 2019. west University of China. Her research interests
[13] S. Xie, H. Zheng, C. Liu, and L. Lin, “SNAS: Stochastic neural include big data, high performance network, and
architecture search,” CoRR, vol.abs/1812.09926, 2018. resource scheduling.
[14] X. Chen, L. Xie, J. Wu, and Q. Tian, “Progressive differentiable ar-
chitecture search: Bridging the depth gap between search and eval-
uation,” 2019 IEEE/CVF Int. Conf. Comput. Vis. (ICCV), pp.1294–
1303, 2019.
[15] Y. Xu, L. Xie, X. Zhang, X. Chen, G.J. Qi, Q. Tian, and H. Xiong, Daguang Gan received the M.S. degree
“Pc-darts: Partial channel connections for memory-efficient archi- from the China institute of science and technol-
tecture search,” ICLR 2020: Eighth Int. Conf. Learning Representa- ogy in 2008. He is an assistant to the general
tions, 2020. manager of Beijing wanfang software co., LTD.,
[16] X. Chu, T. Zhou, B. Zhang, and J. Li, “Fair darts: Eliminating un- mainly engaged in knowledge organization, in-
fair advantages in differentiable architecture search,” Proc. European formation retrieval and information analysis.
Conf. Comput. Vis. (ECCV), LNCS, vol.12360, pp.465–480, arXiv
preprint arXiv:1911.12126, 2019.
[17] M. Bianchini and F. Scarselli, “On the complexity of neural network
classifiers: a comparison between shallow and deep architectures,”
IEEE Trans. Neural Netw. Learn. Syst., vol.25, no.8, pp.1553–1565,
Aug. 2014.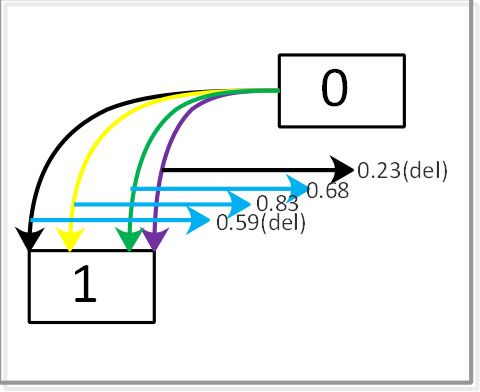
You can also read

















































