A distributed framework for information retrieval, processing and presentation of data
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
2018 22nd International Conference on System Theory, Control and Computing (ICSTCC)
A distributed framework for information retrieval,
processing and presentation of data
Adrian Alexandrescu
Department of Computer Science and Engineering
Faculty of Automatic Control and Computer Engineering, "Gheorghe Asachi" Technical University of Iași
Iași, Romania
aalexandrescu@tuiasi.ro
Abstract—The Internet is ever growing and the information is opposed to extracting product information which requires a
highly unstructured. Finding the best priced product when more complex approach to parsing.
shopping online is a difficult task, but shopping search engines
help the user identify the desired product. Starting from this In [4] the authors present a distributed web crawler that
reality, this paper presents a distributed framework for uses multi-threaded agents to scan the web. There is an
information retrieval, processing and presentation of data, which assignment function that makes it so each agent gets
has three main components: a data server cluster, a distributed approximately the same number of websites and that set of
crawler with a product extraction feature, and a web server for websites changes if an agent activates or deactivates. Our
presenting the processed data. The considered use case consists of proposed solution is better because each crawler gets the next
extracting information about board and card games from URL to process from a centralized database so there is no need
specialized websites and presenting the data in a user-friendly for the reallocation of websites and fault tolerance is achieved
website. Efficiency is determined by means of performance by using the database cluster. Other existing crawler solutions
evaluation metrics that include crawl and extraction times, and a refer to using idle computing resources [5], sitemaps to find the
discussion in terms of scalability. site URLs [6]. Regarding structured data extraction, the authors
The high modularization of the framework allows it to be an from [7] present a survey on existing applications and
effective teaching tool in classrooms; each module can be easily techniques. There, the authors refer to a commercial data
swapped with a custom implementation. The proposed
extraction solution whose implementation is a proprietary
framework offers students and researchers an environment for
secret. In [8] the authors use deep neural network to determine
developing and testing a wide range of algorithms and
programming solutions, e.g., load balancer, crawler, reverse the template. This approach will be considered in future
engineering a web template, product extractor from web pages, improvements of our Template Provider module.
data normalization, notification services, web APIs, custom Building an effective shopping search engine must start
database. with a stable and especially scalable system architecture. This
paper proposes a highly modularized and distributed
Keywords—information retrieval, distributed crawler, shopping
framework for information retrieval, processing and
search engine, data mining, web scraping, micro service
architecture, learning framework
presentation of data. The context and the issues that arise from
tackling the considered problem are discussed in the Problem
Statement section. Afterwards, it is presented the proposed
I. INTRODUCTION framework and all of its components, while the next section
The information available on the Internet grows describes a practical and working use-case scenario, built on
continuously and the number of users that have access to the the proposed framework: a shopping search engine for board
Internet reached more than 50% of the world population in and card games. Lastly, the conclusions are presented with an
2017 [1]. This means that online businesses have now a emphasis on the future work and research that can be done
broader audience to which they can sell their products and using the proposed system.
services. From a user's point of view, when it comes to finding In terms of the novelty of this paper, it consists of the high
a specific product online, the search can sometimes prove modularization and distribution of the framework and the great
difficult, especially if one wants to find the best cost-effective potential for researching and developing new techniques for
product. Shopping search engines, like Google Shopping, the different modules (e.g., increasing the system scalability,
Shopzilla and PriceGrabber [2], help narrow down the search. product extraction, data normalization).
When developing a shopping search engine, the biggest
problem is from where and how to gather the product
information. II. PROBLEM STATEMENT
There is a comprehensive literature when it comes to The considered problem is twofold. Firstly, it is finding an
information retrieval in the general sense; this includes the efficient solution for gathering product information from
required mathematical model, structuring the data, constructing different shopping websites, processing that information and
the index, and computing scores in search systems [3]. Much offering the user a single-access point to finding the products
of the existing related work focuses on having a distributed that are more suitable for the user's needs. And secondly, is to
crawler and on parsing the web pages to extract words; as design a framework that will allow researchers and students to
978-1-5386-4444-7/18/$31.00 ©2018 IEEE 267develop, test and evaluate algorithms for the many problems that is proposed is meant to be a practical solution to the
that the aforementioned considered scenario entails. The ideal shopping search engine problem.
goal is to have a shopping search engine where the user can
look for any product or service that is sold on the web. A positive by-product to having a highly modular system is
the possibility to have its modules swapped with custom
One of the first problems is to have a list of all the shopping implementations. Therefore, another problem that is treated in
websites. This means, crawling the web and, for each website, this paper is in terms of teaching and researching solutions to
determining if that website sells products. Then, for each common problems that occur in distributed systems. Teaching
shopping website, another problem is how to determine which algorithms to students, while offering little practical context,
pages contain product information and where exactly on the leads to a decrease in the students' interest and in their ability
page is that data. If a website is built from a known shopping to fully understand those algorithms. Having a practical,
platform (e.g., BigCommerce, WIX, Weebly, Zen Cart, distributed and modular system allows students to test their
OpenCart) [9][10], then the problem becomes simpler as long implementations and see the effects of their solutions to the
as the used naming conventions remain the same. For example, overall performance of the system. From a researcher's point of
for the WIX platform, the product names can be found on the view, developing a shopping search engine and having a
product page in the h2 HTML element having the product- working framework provides multiple opportunities to discover
name class. Otherwise, each shopping website has its own better and more efficient solution to the many problems that
product page structure and it has to be determined. such a system presents.
Each product has a list of mandatory attributes (i.e., name,
manufacturer and price) and other optional attributes that III. PROPOSED SOLUTION
depend on the product type (e.g., description, size). In order to
simplify the problem, the considered attributes are product A. System Architecture
name, description, image, price and availability. However, this This paper proposes a novel highly modularized framework
restriction does not affect the efficacy of the desired solution. for information retrieval, processing and presentation of data.
Communication between the modules is done similarly to the
After the product information is extracted from different
pipes and filters architectural pattern [13], i.e., the modules are
shopping websites, another problem is product normalization,
chained so that the output of a module is the input of another
i.e., determining if two products taken from different websites
one. The proposed solution is designed for gathering product
represent in fact the same product. Also, if the product names
information, but it can easily be adapted for other web data
are written slightly differently, which one of them is the proper
extraction by simply swapping a single module.
product name. For example, in [11] the authors propose a
method for normalizing mobile phone names in Internet The system architecture of the proposed framework is
forums. Gathering all this information requires a significant presented in Fig. 1. The overall data flow is as follows:
Internet bandwidth, high performance computing capabilities multiple Site Crawlers coordinated by a Crawler Manager
and a large amount of storage. Cloud solutions [12] such as gather product information from the web and store that data to
Google Cloud Platform or Amazon EC2 provide turn-key a Data Server and to a Product Web Server by means of micro
platforms for deploying multiple crawlers, parser, extractors, web services. There are three main components: the distributed
and other modules the such a complex system requires. In crawler, the persistent storage (i.e., Data Server) and the
order for the system to be efficiently deployed in a cloud product web server used for presentation. Therefore, the
environment, one of the most important aspect is scalability. If framework can be seen as a three-tier application where the
the system is highly modular and the modules have a high communication between tiers is achieved via micro web
degree of independency then there can be as many instances of services and where each component is highly modularized.
each module as it is required to achieve maximum efficiency.
Each of the modules is discussed in terms of its current
In terms of presenting the data to the user, a shopping implementation and on how each one can be improved. In a
search engine must be developed and this engine must provide teaching environment, the students can use their own
the user product information quickly and accurately. The main implementations for each module.
problems here are how to index the data and how to decide
which product is higher and which one is lower in the search Initializer. The crawl process is initialized with a seed file,
results. This process is similar to what normal search engines which contains the list of sites that are about to be crawled, and
use for page ranking. But this also can be refined and fine a config file, which contains general crawl parameters.
tuned to the user's needs based on the product characteristics Scheduler. Product prices can change often due to
(e.g., color, weight, size, shape) and the user's shopping temporary promotions or permanent increases or decreases in
behavior (i.e., the previous purchases). the product cost. Therefore, the crawler must extract
As aforementioned, there are many aspects in terms of information at least daily to offer accurate information to the
designing and implementing an efficient shopping search clients. The role of the Scheduler module is to trigger the
engine. The novel solution presented in this paper focuses on recrawl of the product websites. Currently it is set to recrawl
the overall architecture of such a system, the modularization of daily at 8 o'clock, but another approach could be to use an
the problem and the relationship between the different system artificial intelligence approach and recrawl each site with a
modules. Some of the modules have trivial functionality and different periodicity based on the product types that are being
are not the scope of this paper, but the overall system design sold and based on that website’s history of fluctuating prices.
268Crawler Manager. Once a crawl is scheduled, the Crawler Manager and starts processing it. This component has
Instance Manager module of the Crawler Manager decides multiple modules which are discussed next. The framework
how many crawler instances are required to finish crawling in a has support for using a third-party crawler, but an adapter has
timely manner whilst abiding to the crawl best practices (i.e., to be made in order for the other crawler to be properly used by
following the robots.txt file and not making too many requests the Crawler Manager.
so that the crawler gets banned). When the required instances
are determined, the Load Balancer assigns sites to each Starter. Firstly, it checks if all the pages from that web site
crawler. Currently, the Load Balancer is based on the Thread have finished being processed from the previous crawl and sets
each page state to waiting. This check is required in order to
Pool design pattern: a fixed number of crawlers are available
and each crawler processes a single website; after a site is allow multiple crawlers to process the same website; in this
processed that crawler processes the next website and so on. case, only the first crawler resets the page status. It makes
sense to have multiple crawlers on the same website especially
Site Crawler. The largest component of the framework is if each crawler has a different real IP address.
the Site Crawler, which receives a web site name from the
Config file
Seed file
Crawler Manager
Instance Manager Load Balancer
Initializer Scheduler (cron)
Site Crawler Data Server
1. Resets the page status (if needed) WebAPI Server:
Starter
- SiteDAO
Call API
Update -PageDAO
2. Determine template Template template Crawler WebAPI - ProductDAO
Provider Manager -NotificationDAO
3. Fetch with template
Update URLs
3.2. Extract 3.2.1. Get URLs Link
Fetcher Extractor
Extractor
3.1. Fetch web page 3.2.2. Get products Notify of wrong template
Database
Cluster
Product Extractor
Web
Product Data Field Data Notification
Page Filter Extractor Normalizer Service Update
product info
Store products
Product WebAPI WebAPI
Manager Manager
Call API to update the extracted product data
Product Web Server
WebAPI Server: Web Site Web Site
- SiteDAO Business Presentation
Web Database
- ProductDAO Logic Logic
User
Fig. 1. System architecture for the proposed distributed framework for information retrieval, processing and presentation of data
269Crawler WebAPI Manager. All the communication with for the user to be notified of changes in price based on different
the persistent storage is done by means of micro web services criteria.
which are discussed in the section describing the Data Server.
Template Provider. The module with the biggest research B. WebAPI Server
potential is the Template Provider. As the name suggests, this Micro web services employing the REST standard are used
module provides the html template of the product pages. in order to keep separately the three main components. There
Ideally, this template is determined by analyzing the structure are two WebAPI Servers: one at the Data Server and the other
of the pages and determining which pages contain product at the Product Web Server. There are some differences
information and where it is on the page (e.g., what is the regarding the HTTP methods used by each of the two servers
hierarchy of html tags to get to the product name). At this stage as shown in Table I.
of the framework, the template for each site is given in the seed For sake of brevity, the web service methods that deal with
file in the form of a json file. price history (/products/id/priceHistory), the crawl reports
Fetcher. A critical module is the Fetcher, which retrieves (/reports) and the system notifications (/notifications) are
each page from the web and passes that data along with the omitted from the table.
template to the Extractor. TABLE I. MICRO WEB SERVICES FOR THE FRAMEWORK RESOURCES
HTTP
Extractor. The Extractor module allows different modules URL
method
Description
to extract information from the web page. A mandatory
implementation for a crawler is the Link Extractor, which /sites GET Returns the list of web sites
extracts the URLs from the page and stores them in the /sites POSTa Adds a new web site
database. Because the goal is to have a shopping search engine,
Returns the site with the specified
having a Product Extractor module is also mandatory. This /sites/sid GET
id
coordinates four modules: Product Page Filter, who
determines if the page contains product information, Data /sites/sid/template PUTa Updates the template for the site id
Field Extractor, who finds a specific product attribute (e.g., /sites/sid/pages Returns the next waiting to be
GETa
product name, price) and extracts its value, Data Normalizer, ?state=waiting&limit=1 processed page
who removes unnecessary characters from the product attribute /sites/sid/pages POSTa Adds a new page
values; this module has a research potential for finding a
solution to link products from different websites which have Updates one or more pages (e.g.,
/sites/sid/pages/[pid] PATCHa
page status, retrieved date)
different product names but are in fact the same product, and
Notification Service, who sends a notification when it detects /products?search=terms GET Performs a product search by name
that the existing template cannot be applied to a product page; /products POST a
Adds a new product
this is usually because of an update on the site structure.
/products PATCHb Batch-updates product details
WebAPI Manager. Whenever a product is extracted, the a.
Method available only at the Data Server, and not at the Product Web Server.
WebAPI Manager modules call micro web services to store the b.
Method called only from the WebAPI Manager(s), and not from the Web Site Business Logic.
product information. Besides updating the Data Server, the
manager updates the Product Web Server. This is done so there
C. Scalability
is a clear separation between the database used by the crawler
and the database used by the shopping search engine, in order System scalability is achieved mainly by allowing multiple
to increase security and performance. The Product WebAPI crawler instances to process the web sites. The Instance
Manager does not send the entire product data if that product is Manager and Load Balancer modules ensure that the system
already in the database, but rather it sends only the product handles any load as long as there are computational resources
attributes that were updated from the previous crawl. Also, it available. When using a Cloud solution, the system scales
has the possibility to send batch updates so fewer calls are seamlessly. The Crawler Manager can be improved by using
made to the WebAPI Server. neural network regression [14] to dynamically scale up and
down depending on the load at a specific point in time.
Data Server. The site, web page and product information
are stored in a database cluster by means of a WebAPI Server In order to increase even more the scalability of the system,
that uses access tokens for an extra layer of security. The exact each module of the Site Crawler component can be a separate
type and implementation for the database cluster is beyond the process on a different computer. The main issue is the time it
scope of this paper, but a practical and simple approach is takes to transmit data between the processes, but in certain
presented in the Use-Case Scenario section. instances it makes sense to perform this separation. For
example, the Template Provider can be easily decoupled to
Product Web Server. The user interface consists of a web perform the computing intensive task of determining the
server that permits product searches by querying a database by template. Another example is to separate the Fetcher from the
means of web services. At this point, the user can only search Extractor, especially if extracting the information takes much
by name thanks to the indexing of every word in the product longer than getting the web page content. In this case it is
names. Another important feature is the price history for each better for the Fetcher to store the pages in the database and
product. This allows for the implementation of the possibility then multiple Extractors to process those pages.
270The current framework design uses two databases with each page retrieval from a specific site, so not to result in the
somewhat duplicate site and product information for security site banning the crawler IP.
reasons. Instead, a single database cluster can be used with
different authentication tokens for each module that interacts Pages Sites Products
with the database by means of the micro web services. PK id PK id PK id
FK siteId name FK siteId
IV. USE-CASE SCENARIO, RESULTS AND DISCUSSION urlPath urlBase url
The considered use-case scenario implies having a list of addedDate logoUrl name
known product websites that sell board and card games and retrievedDate seedList description
extracting that information so the user can search for the best
state pageRegEx imageUrl
priced products. The websites that are crawled are:
www.lexshop.ro, www.pionul.ro, www.redgoblin.ro and FK templateId price
www.regatuljocurilor.ro. All the crawling is done on the same Template addedDate
computer in order to accurately measure performance. PK id retrievedDate
Regarding the implementation, the framework is written in base PriceHistoryItem
availability
Java, the Data Server is an Apache Tomcat server with a name inCurrentRun
PK id
MongoDB database, while the Product Web Server is an App description
Engine server [15] deployed on the Google Cloud Platform imageUrl
FK productId
with Google Datastore [16] for the database. The reasoning for price
productUrl
using the Google Cloud Platform is that it is free as long as the retrievedDate
daily quotas are not exceeded. Optimizations are made using price
availability
special indexes and memory caches in order to prevent those availability
quotas to be exceeded too quickly. For the web services, the
Jersey library was used on all three servers. The website for the Fig. 3. Entity-relation diagram showing the main entities of the proposed
framework's database
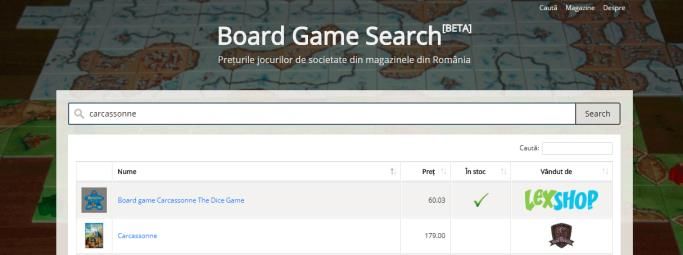
board game search engine described in this section is shown in
Fig. 2 and in can be accessed at: After a crawler sets all the page states for that site to
http://boardgamesearch.h23.ro. waiting, the Template Provider module simply returns a json
file containing the selectors (i.e., the template), which were
determined by manually analyzing the pages. Then the Fetcher
retrieves the first page in waiting state returned by the WebAPI
Server. Once the content of the page is received, the Link
Extractor finds all the URLs in the page and updates them in
the database via the micro web services. In parallel, the
Product Extractor uses the template to get the product
information, which gets stored on the Data Server and the
Product Web Server.
Fig. 2. The search page with results for the board game search engine Table II presents a few experimental results from crawling
website: http://boardgamesearch.h23.ro
the four aforementioned websites. The values shown represent
Next is presented the implementation of each framework the average results obtained by running the crawlers five times
module and a discussion on the decisions that were made in at different times of day. For this use-case scenario, some
order to have a simple yet effective working example. The optimizations were made on the proposed framework in order
emphasis is on the behavioral differences of each module to speed up the crawling. Only specific web pages are
compared to the descriptions from the previous section. processed because the Product Page Filter allows extraction of
products only from multi-product pages. Also, only multi-
Regarding the framework's database, the main entities are product page links are added to the database by the Link
shown in Fig. 3. For security and performance reasons, the Extractor (which uses the same filter). This way, fewer pages
Product Web Server database uses only the Sites table (only the are processed: an average of 1792 products/site were extracted
id, name, urlBase and logoUrl attributes), the Products and the with a rate of 161 pages/site.
PriceHistoryItem tables. Web services make the access to the
databases to be schema-agnostic and either of the two In terms of the extraction times, the link extraction depends
databases can easily be relational or non-relational. significantly on the number of links that pass the filter and are
stored in the database. For example, at the Red Goblin website
The framework uses the config and seed files to run the there are an average of 678 links per page but only 47 relevant
crawler daily at 8 o'clock on the four websites. Each time the links. When it comes to products, the extraction and the upload
recrawl starts, the Crawler Manager creates four crawlers that times depend on the number of products on each page.
run in parallel: one for each web site. In this scenario, there is
no need for multiple crawlers to process the same website The total processing time of each web page is the sum of
because the waiting time is between 1 and 5 seconds between the times it takes to retrieve the page from the web, extract the
links and the products from that page and upload the product
information on the remote presentation server. Each page
271processing takes an average of 2.15 seconds. The time it takes method of uploading the links and products to the database,
to process all the four websites is around 92 minutes, and e.g., by using a local cache and making batch uploads. Also, it
during that time a total of 7167 products are extracted from 642 is important to find a good solution for the Data Normalizer
pages. module. For the presented scenario, the implementation allows
TABLE II. EXPERIMENTAL RESULTS OBTAINED BY USING THE FRAMEWORK
to have multiple copies of the same product in the database as
TO PROCESS FOUR BOARD GAME SHOPPING SITES long as it is from different websites. In terms of the Template
Lex Red Regatul Provider, the deep neural networks approach will be
Pionul
shop goblin jocurilor considered in the future research that will be done to expand
Total number of unique
1420 318 1603 3826
our proposed framework.
products
Total number of
178 35 48 381 REFERENCES
processed pages
Extracted links counta 281 86 678 268
[1] Internetworldstats.com, "Internet growth statistics", 2018. Available:
Extracted links timeab 51 ms 80 ms 47 ms 43 ms https://www.internetworldstats.com/emarketing.htm, [Accessed:
04.04.2018].
Extracted product counta 12 20 51 21
[2] Searchenginewatch.com, " The 10 Best Shopping Engines", 2014.
Extracted product timea 73 ms 66 ms 172 ms 50 ms Available: https://searchenginewatch.com/sew/study/2097413/shopping-
engines, [Accessed: 04.04.2018].
Retrieval timea 662 ms 711 ms 2741 ms 2485 ms [3] R. R. Larson, "Introduction to information retrieval", Journal of the
Product upload timea 330 ms 333 ms 409 ms 346 ms American Society for Information Science and Technology, vol 61, no.
4, pp. 852-853, 2010.
1191
Total processing timea 1116 ms 3370 ms 2924 ms [4] P. Boldi, B. Codenotti, M. Santini and S. Vigna. "Ubicrawler: A scalable
ms
a. fully distributed web crawler". Software: Practice and Experience, vol.
Average values per page.
b. 34, no. 8, pp.711-726, 2004.
Includes the time it takes to store the link in the database.
[5] M. Thelwall. "A Web crawler design for data mining". Journal of
The scope of having the board game search engine scenario Information Science, vol. 27, pp. 319-325, 2001
is to show the usefulness of the framework and to emphasize [6] S.B. Brawer, I.B.E.L. Max, R.M. Keller, and N. Shivakumar. "Web
its ease of use. Further research will be conducted to find new crawler scheduler that utilizes sitemaps from websites". Google Inc.
U.S. Patent 9,355,177. 2016.
and better solutions for each of the modules and to have a fully
functional shopping search engine. [7] E. Ferrara, P. De Meo, G. Fiumara, and R. Baumgartner. "Web data
extraction, applications and techniques: A survey. Knowledge-based
systems", vol. 70, pp.301-323, 2014.
V. CONCLUSION AND FUTURE WORK [8] T. Gogar, O. Hubacek, and J. Sedivy. "Deep neural networks for web
page information extraction". In IFIP International Conference on
The scope of the research presented this paper was to Artificial Intelligence Applications and Innovations, pp. 154-163.
design and implement a novel modularized distributed Springer, Cham. 2016
framework for information retrieval, processing and [9] Top10ecommercesitebuilders.com, "Best Ecommerce Site Builders of
presentation, and to use that framework as a stepping point for 2018", 2018. Available:
researching the different aspects that the considered https://www.top10ecommercesitebuilders.com/, [Accessed: 11.05.2018].
environment presents. Besides the highly emphasized [10] Ecommerce-platforms.com, "11 Best Open Source and Free Ecommerce
advantage of high modularization, the proposed framework is Platforms for 2018", 2018. Available: https://ecommerce-
an effective solution for developing a complex shopping search platforms.com/articles/open-source-ecommerce-platforms, [Accessed:
11.05.2018].
engine. The final goal is to have a fully autonomous system
[11] Y. Yao and A. Sun, "Product name recognition and normalization in
that detects product websites, correctly extracts products and internet forums". SIGIR Symposium on IR in Practice (SIGIR Industry
links same products on different websites so to provide an Track), 2014.
excellent user purchase experience in determining the most [12] Q. Zhang, L. Cheng, and R. Boutaba, "Cloud computing: state-of-the-art
cost-effective products. and research challenges". Journal of internet services and applications,
vol. 1, no. 1, pp.7-18, 2010.
In its current form, the framework is a straightforward
[13] C. Wulf, N.C. Ehmke and W. Hasselbring, "Toward a generic and
shopping search engine solution. On the other hand, the concurrency-aware pipes & filters framework". Symposium on Software
potential of the proposed framework is great as it can provide a Performance 2014: Joint Descartes/Kieker/Palladio Days (SOSP 2014),
developing environment (for researchers and students alike) for 2014.
problems specific to distributed systems (load balancing, fault [14] J. Snoek, O. Rippel, K. Swersky, R. Kiros, N. Satish, N. Sundaram, M.
tolerance, replication, scalability), product detection and Patwary, M. Prabhat and R. Adams. "Scalable bayesian optimization
extraction from websites, distributed relational and non- using deep neural networks". In International conference on machine
learning, pp. 2171-2180, 2015.
relational database systems, indexing techniques, notification
[15] Cloud.google.com, "Google App Engine", 2018. Available:
services, and recommendation systems. https://cloud.google.com/appengine/, [Accessed: 30.03.2018].
Improvements can be made to speed up the extraction [16] I. Shabani, A. Kovaçi and A. Dika. "Possibilities offered by Google App
because now the framework implementation of the Extractor Engine for developing distributed applications using datastore". 2014
Sixth International Conference on Computational Intelligence,
uses the Jsoup selector-syntax to find the information on the Communication Systems and Networks (CICSyN), pp. 113-118. IEEE,
page. A sequential parsing approach would have probably 2014.
yielded better results. Another optimization can be made on the
272You can also read