ASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding - arXiv
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
ASR-GLUE: A New Multi-task Benchmark for
ASR-Robust Natural Language Understanding
Lingyun Feng Jianwei Yu
Tsinghua University Tencent AI Lab
Tencent AI Lab Shen Zhen, China
arXiv:2108.13048v1 [cs.CL] 30 Aug 2021
Shen Zhen, China tomasyu@tencent.com
fly19@mail.tsinghua.edu.cn
Deng Cai Songxiang Liu
The Chinese University of Hong Kong Tencent AI Lab
Hong Kong, China Shen Zhen, China
thisisjcykcd@gmail.com shaunxliu@tencent.com
Haitao Zheng Yan Wang
Tsinghua University Tencent AI Lab
Shen Zhen, China Shen Zhen, China
zheng.haitao@sz.tsinghua.edu.cn brandenwang@tencent.com
Abstract
Language understanding in speech-based systems have attracted much attention in
recent years with the growing demand for voice interface applications. However, the
robustness of natural language understanding (NLU) systems to errors introduced
by automatic speech recognition (ASR) is under-examined. In this paper, we
propose ASR-GLUE benchmark, a new collection of 6 different NLU tasks for
evaluating the performance of models under ASR error across 3 different levels
of background noise and 6 speakers with various voice characteristics. Based on
the proposed benchmark, we systematically investigate the effect of ASR error on
NLU tasks in terms of noise intensity, error type and speaker variants. We further
purpose two ways, correction-based method and data augmentation-based method
to improve robustness of the NLU systems. Extensive experimental results and
analysises show that the proposed methods are effective to some extent, but still far
from human performance, demonstrating that NLU under ASR error is still very
challenging and requires further research.1
1 Introduction
Language understanding in speech-based systems have attracted much attention in recent years
with the growing demand for voice interface applications and devices such as Alexa [1], Siri [2],
and Cortana [3]. These speech-based intelligent systems usually comprise an automatic speech
recognition (ASR) component which converts audio signals to readable natural language text, and
a natural language understanding (NLU) component which takes the output of ASR component
as input and fulfill downstream tasks such as sentiment analysis, natural language inference, and
1
The dataset is available at
https://drive.google.com/drive/folders/1slqI6pUiab470vCxQBZemQZN-a_ssv1Q
Submitted to the 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets
and Benchmarks. Do not distribute.
response selection. The upstream ASR error may propagate to the downstream NLU component and
degrade the overall performance [4, 5]. In real-world scenarios, ASR error can be ubiquitous due to
poor articulation and acoustic variability caused by environment noise and reverberation [6]. The
persistence of ASR error indicates a need for ASR-robust natural language understanding.
Previous work in this area is limited to task-oriented language understanding such as hotel reservation
and meeting scheduling through human-machine interactions [7, 8, 9, 10]. However, ASR error
can affect many other NLU tasks, such as sentiment analysis in voice assistants. A benchmark that
enables the comprehensive evaluation of NLU under ASR error on a diverse range of tasks is still
missing.
In this paper, to quantitatively investigate how ASR error affect NLU capability, we propose the
ASR-robust General Language Understanding Evaluation (ASR-GLUE) benchmark: a collection
of 6 NLU tasks including sentiment analysis, similarity and paraphrase tasks and natural language
inference (NLI) tasks. We hire 6 native speakers to convert the test data into audio recordings with 3
different levels of environment noise. Each speaker is requested to record all test data to study the
variance between individuals. Finally we get 18 different types of audio recordings (3 levels of noise
* 6 different speakers) for each of the 6 NLU tasks, varying in noise intensity, error type and speaker
variants. In addition, we also test the human performance under different noise levels. We hope it
would benefit the research of ASR-robust NLU in the future.
With the annotated dataset above, we observe that recent state-of-the-art (SOTA) NLU models are
sensitive to ASR error. To alleviate this problem , a straightforward approach is to make error
correction for the mistranscriptions as a post-processing step. Another approach is data augmentation
which uses text with potential ASR error as additional training data to simulate the real-world scenario
in training. We propose two different augmentation methods: 1) Audio-level augmentation. We adopt
a Text-to-Speech system (TTS) - then - ASR pipeline to first transforms the training corpus to audio
and then convert them back to text (with errors). 2) Text-level augmentation. Due to the high cost
of TTS and ASR system, we further attempt to injects the ASR error to the training corpus through
text generation models [11, 12] or some manually predefined rules [13, 14]. Experimental results
demonstrate that while these approaches improve the model robustness against ASR error to some
extent, they are still far from human understanding capability.
Our contributions are as follows: 1) A new benchmark dataset, ASR-GLUE, is proposed to enable
a comprehensive evaluation of the robustness of NLU model to ASR error, covering 6 diversified
tasks under 6 different speakers and 3 different levels of environment noise. 2) We systematically
and quantitatively investigate the sensitivity of state-of-the-art NLU models to ASR error in terms of
noise intensity, error type and speaker variants. 3) We provide two types of approaches to alleviate the
effect of ASR error. Experimental results demonstrate their effectiveness, and they can be considered
as baseline methods in future studies.
2 ASR-GLUE
2.1 Selected NLU Tasks
The proposed ASR-GLUE is constructed on the basis of GLUE [15], a popular NLU evaluation
benchmark consists of diverse NLU tasks. We select 5 typical NLU tasks from it, namely: Sentiment
classification (SST-2 [16]), Semantic Textual Similarity (STS-B [17]), paraphrase (QQP 2 ), Question-
answering NLI (QNLI [18]), Recognizing Textual Entailment (RTE [19, 20, 21, 22].) and incorporate
with a Science NLI task (SciTail [23]), resulting in 6 tasks in total. Detailed descriptions of the
the chosen tasks are presented in Appendix. They are common and typical tasks of language
understanding in speech-based scenarios, making them suitable for ASR-GLUE.
2.2 Data Construction
Since the original datasets are presented in clean text form, we manually select instances from their
test sets for human audio recording to evaluate the NLU capability in the presence of ASR error.
Samples with non-standard words (e.g., abbreviations, currency expressions, strange names and
addresses) or sentences that are too long (more than 100 words) are excluded from these selected test
2
data.quora.com/First-Quora-Dataset-Release-Question-Pairs
2
Figure 1: An illustration of the data collection and recording process.
sets. Considering the cost and quality of annotation, we keep the original training set and randomly
select a subset of samples from the test set for human audio recording on each task3 . The statistics of
the data is shown in Table 1. In human recording process , 6 native speakers are hired to record all
test samples. Different levels of environment noise is provided and the audio signals are sent into an
ASR system to get the final ASR hypothesis. The overall process is depicted in Figure 1.
Table 1: Statistics of ASR-GLUE. The reported hours are the sum of recording time under different
levels of noise. We also report Word Error Rates (WER) for test sets under each noise level.
WER (test) Hours
Corpus #Train #Dev #Test
Low Noise Medium Noise High Noise Test+Dev
SST-2 67349 2772 2790 18.35% 30.76% 34.86% 8.05
STS-B 5749 3042 3222 12.49% 24.70% 28.53% 10.82
QQP 363846 1476 3996 13.78% 24.34% 27.45% 11.56
QNLI 104743 2718 2718 22.51% 33.61% 37.90% 18.00
RTE 2490 2070 2088 24.54% 39.47% 47.03% 26.19
SciTail 23596 2718 2736 17.55% 30.09 % 34.04% 16.81
Human Audio Recording We hire six native speakers to record the test sets for each task. The
speakers are 3 male and 3 female with different ages ranging from 18 to 40 from the U.S. In the
recording process, each speaker is required to record all text samples independently so that we can
study the impact of speaker variation. They are instructed to imagine they are communicating with
someone when speaking the sentences of the six tasks. Note that they are allowed to make minor
changes to the original text for natural and smooth expression such as change cannot to can’t. To
collect high-quality audio, all the original speech signals are recorded in a low-noise environment.
Environment Noise In real-world scenario, human audio often recorded with environment noise
and reverberation [24]. The presence of the background interference will lead to substantial perfor-
mance degradation of current ASR systems [25] and further effect the downstream NLU systems
[26]. Therefore, to better evaluate the robustness of NLU models in the noisy acoustic environment,
speech data with different levels of noise is further provided in the ASR-GLUE corpus.
In ASR-GLUE, the widely-adopted simulation approach [27] is used to introduce different levels of
noise and reverberation into the low-noise audio signals. Specifically, the background noise caused
by such as phone ring, alarm clock and incoming vehicles are randomly sampled and added into the
original recordings with the signal-to-noise-ratio (SNR) from 10dB to 15dB. Here SNR is defined as:
||s ||2
SNR := 10 log ||starget
noise || 2 , where starget and snoise denote the acoustic signal of the clean speech
and the noise respectively. ||s||2 = sT s denotes the signal power. In addition, the room reverberation
is also introduced by involving the recorded audio signals with the Room Impulse Responses (RIRs)
4
generated by the image-source method [28]. The simulation process totally covers 843 kinds of
different background noise and 417 types of different RIRs.
Finally, for each recorded human audio signal we get three versions: (1) Low-level noise, same as
the original audio. (2) Medium-level noise which introduces reverberation and 15dB SNR level
background noise into the original audio. (3) High-level noise , which introduces reverberation and
3
If there is no public test set, we use their dev set instead.
4
The noise and RIR files can be found via link: http://www.openslr.org/resources/28/rirs_noises.zip
3
$FFXUDF\
$FFXUDF\
667 41/, 6FL7DLO 676% 443 57( %(57 ;/1HW 5R%(57D $/%(57
+XPDQ &OHDQ /RZ 0HGLXP +LJK
(a) (b)
Figure 2: (a) The performance of BERT on different tasks under different levels of noise. The shaded
area represents human performance. (b) Accuracy results for different model architecture on SST-2
task. Here “Human” indicates human performance under various noise settings. “Clean” stands for
test on clean text data. “Low/Medium/High” stands for test in low-level/medium-level/high-level
noise respectively.
10dB SNR level background noise into the original audio. Then we build an 6000h trained ASR
system based on the widely-used open source Kaldi toolkit5 [29, 30] to transcribe these audio files
into text.
3 Analysis of ASR-GLUE
In this section we give extensive analyses on the proposed ASR-GLUE dataset. In Section 3.1, we
obtain human performance to measure the ceiling performance on the test set, Then we analyse the
performance of recent SOTA NLU models across different levels of environment noise in Section 3.2.
Furthermore, in Section 3.3 we categorize ASR errors into four types, and systematically investigate
the impact of different error types on NLU performance. Finally, we analyse the effect of voice
variation from different speakers in Section 3.4.
3.1 Human Performance
To obtain the human performance under environment noise, we hire native annotators to predict labels
of each test sample in audio form. The annotators is hired from a third-party company. To guarantee
the annotators fully understand these tasks, we first give the annotators a brief training on each task
in ASR-GLUE. Then we ask them to take an exam before starting annotation, only annotators who
pass the exam will be hired. Finally we have 3 annotators to measure the ceiling performance for
each task in ASR-GLUE. Details about the exam and annotation process are presented in Appendix.
3.2 Performance of Existing NLU Models
To demonstrate the significance of the ASR error issue, we leverage typical NLU models such
as BERT to test their robustness to different levels of ASR error on different tasks. As shown in
Figure 2(a), While BERT yields promising results on error-free text, its performance degrades in
presence of ASR error on six tasks. As the noise increases, the performance of the model drops more
severely. In contrast, human is less affected by the environment noise, which indicates that there still
remains a gap between the robustness of models and humans to ASR error.
We also investigate the effect of ASR error with different noise levels on different NLU models. We
adopt base version of BERT [31], RoBERTa [32], ALBERT [33], XLNet [34] as the NLU model. As
shown in Fig. 2(b) we can observe that all these pretrained language models are sensitive to ASR
error and the performance degrades with the increase of the noise level.
3.3 Breakdown Analysis by ASR Error Type
We conclude that the ASR error types can be categorized into four folds, namely similar sounds,
liaison, insertion and deletion. Specifically, (i) Similar sounds happen when ASR system sometimes
5
https://github.com/kaldi-asr/kaldi
4Table 2: Examples of speech recognition perturbation in ASR-GLUE.
Error Type Ground Truth Recognition Result
The man couldn’t lift his son. The man couldn’t lived his son.
Similar sounds
Tommy dropped his ice cream. Tommy jumped his ice cream.
Does Quora stand for question or answer. Does Quora Stanford question or answer.
Liaison
The drain is clogged with hair. The drains clogged with hair.
This afternoon. This after afternoon.
Insertion
A warm funny ∗ engaging film A warm funny and engaging film.
A black and white photo of an old train station. A black ∗ white ∗ of ∗ train station
Deletion
Old style bicycle parked on floor Old style bicycle ∗ ∗ floor
3HUFHQWDJH
$FFXUDF\
/RZ1RLVH 0HGLXP1RLVH +LJK1RLVH
/RZ1RLVH 0HGLXP1RLVH +LJK1RLVH
6LPLODUVRXQGV /LDLVRQ ,QVHUWLRQ 'HOHWLRQ
Figure 3: Left: The percentage of each error type under different noise setting in SST-2 dataset. Right:
The accuracy of BERT on four subsets under different noise level. Each subset only contains test
samples with one specific error type. For example, the red block represents the accuracy of BERT
on test samples which contain similar sounds errors. The shaded area represents the performance
degradation against clean text caused by a specific error type.
wrongly identifies one word as another with similar pronunciation. (ii) Liaison constantly occurs
between successive words which has sound fusion across word boundaries. (iii) Insertion happens
when ASR system makes word redundancies. (iv) Deletion happens when there are word omissions
in the ASR hypothesis. Examples of each error type are presented in Table 2.
We report the percentage of each aforementioned error type in Figure 3(a). We choose SST-2 task
as an example and observe that similar sounds most commonly happened. As the noise increases,
the percentage of similar sounds and deletion made by ASR system gradually increase while the
percentage of liaison and insertion error type remain relatively stable. Note that the sum percentages
of the four error type is over 100%, since different error types may simultaneously exist in one
hypothesis.
We also investigate the impact of each error type on NLU model on SST-2 task. We group data
according to error types and compare the model performance with the same grouped raw data without
errors respectively. As shown in Figure 3 (b), we can observe that BERT can better handle Liaison
error for the performance degradation is minimal under varied noise settings. As noise increases, the
accuracy of the model decreases more severely for each different type of error.
3.4 Effect of Individual Difference
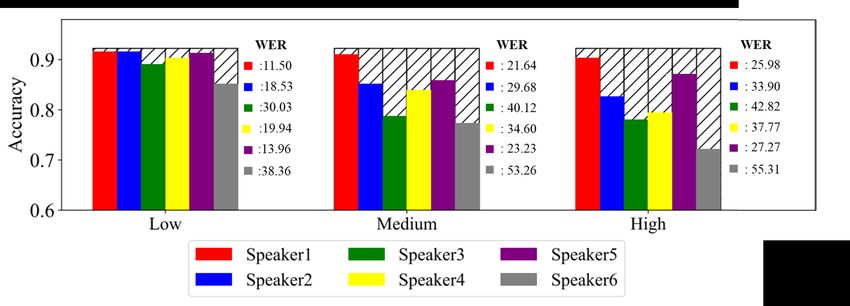
We test the effect of voice variation of the six hired speakers on the test set of SST-2. As shown in
Fig. 4 we can observe that the recognition quality and classification accuracy varies greatly across
speakers. For example, the accuracy of BERT on S1 (corresponds to Speaker 1) are consistently
higher than S6 (corresponding to Speaker 6) with a very large margin (27% ∼ 32%). Meanwhile, we
can also observe that the drop of classification accuracy is due to the increase of WER. The higher
WER means more ASR errors in the test samples, resulting in more misclassification.
4 ASR-Robust NLU
To alleviate the effect of ASR error to NLU models, we propose two strategies: correction-based
methods and augmentation-based methods. As shown in Fig 5, the first strategy (Section 4.1) is
to recover the clean text from erroneous text while the second aims to train NLU models on data
5Figure 4: NLU performance under voice variation from different speakers.
(a) ASR Error Correction
(b) Data Augmentation
Figure 5: An illustration of the proposed two strategy: ASR error correction and data augmentation.
(a) is an example of ASR correction which corrects the source erroneous input “hello word” to target
correct output “hello world”. (b) is an example for data augmentation. The source input is clean text
data (e.g., “hello world”) and the target output is noisy data with ASR error (e.g., “hello word”). We
simulate ASR error in audio or text level and train the NLU models with the augmented data.
augmented with ASR error. In the second strategy, there are two types of augmentation method:
1) audio-level augmentation (Section 4.2), we adopt a TTS-ASR pipeline which first transform the
training corpus into audio files then convert them into text containing ASR error. 2) Text-level
augmentation (Section 4.3): due to the high cost and latency time of TTS and ASR system, we
propose to use generation models [11, 12] or some manually predefined rules [13, 14] as a substitution
of the TTS-ASR pipeline to direct generate text with ASR error from clean text.
4.1 ASR Correction
ASR error correction is a ASR post-processing process that recover the clean text from erroneous
text. We adopt two most typical technical paradigms: GETToR [35] and BART [12] (referred to as
BART-C) to transform the output of the ASR systems into clean text.
In training, the model takes the ASR hypothesis as input and its corresponding clean transcript as
output. In this way model learns to correct the errors in the hypothesis and recover it to a clean
sentence. During inference time, the input of NLU models will be the output of ASR error correction
model other than the original ASR hypothesis.
4.2 Audio-Level Augmentation
We also attempt to train the NLU models with ASR error so that they can learn to understand those
text containing ASR error during inference time. One straightforward way is to hire human speakers
to record all training data to audio files. However it is unpractical due to high labor cost. Thus, as
shown in the upper part of Figure 5(b), in audio-level augmentation we adopt a TTS system to convert
the text-form training data in into audio files. Then we add random environment noise into the audio
6and adopt ASR systems to convert the audio files into ASR hypotheses. Specifically, the TTS system
we adopted is DurIAN [36]. The noise simulation and speech recognition follows the same process
as described in section 2.2. In training we use these augmented data as additional training data,
along with the original training set to train the NLU model. Note that the original training data set is
important and cannot be discarded in training to make the model maintain its original performance
on clean text.
4.3 Text-Level Augmentation
In audio-level augmentation, the audio from TTS system is still quite different from human voice,
which may cause a different error distribution. Besides, the TTS-then-ASR pipeline is time-consuming
and expensive, since it takes one week to generate the synthesized audio signals using four 32-core
Intel E5 CPU servers and another week to transcribe them with three 2-card Tesla P4 GPU servers
using the kaldi-based ASR system. So we propose text-level augmentation which uses text generation
models as a substitution of the TTS-ASR pipeline and directly generate the ASR hypothesis from the
original textual training data. These generation models take the ASR transcript as the model input
and train model to generate the corresponding hypothesis as output.
Concretely, we adopt three different models to generate the text with ASR error. Two pretrained
language models, GPT-2 [11] and BART [12] (referred to as BART-S) are used as the generation
models to generate ASR hypotheses. We also adopt a rule-based method based on Confusion-matrix
(abbreviated as CM) [14]). In CM, each ASR hypothesis and its reference text are aligned at the
word level by minimizing the Levenshtein distance between them. Then we conduct the confusion
matrix based on the aligned n-grams and add ASR error according to the frequencies of confusions.
Further comparisons about the aforementioned methods are presented in experiments.
5 Experiment
5.1 Experimental Settings
The clean transcriptions and their corresponding ASR hypotheses which are used to train the correction
model and augmentation models are collected from the public dataset LibriSpeech [37]. LibriSpeech
is an ASR corpus based on public domain audio books which contains 1000 hours of speech and their
according transcriptions. We use the Kaldi-based ASR system to convert audio recordings into ASR
hypothesis. For correction-based methods, the input is hypothesis and the output is its corresponding
clean transcript. For text-level augmentation methods, the input is the clean transcript while the output
is its corresponding hypothesis which contains ASR error. In text-level and audio-level augmentation,
the proportion between the augmented data and original data is 1:1 and we combine them together as
the training set.
The NLU model we used in our experiment is BERTbase 6 . We use Adam [38] with an initial learning
rate of 5e-5. For GPT-27 and BART8 used in text-level augmentation (BART-S) and ASR correction
(BART-C), sentences are tokenized with byte-pair encoding (BPE) [39]. Both of them use beam
search [40] as their decoding strategy. For GETToR, the sequence tagging model is an encoder made
up of RoBERTa [32] stacked with two linear layers with softmax layers on the top. BPE is used for
tokenization. Early stopping was used, stopping criteria was 3 epochs of 10K updates each without
improvement.
5.2 Results
The main result of proposed methods are shown in Table 3, we can observe that the NLU models
are sensitive to ASR error and the performance of NLU degrade severely across various task. The
proposed methods can effectively improve the robustness of the model to a certain extent in most
scenarios, but are still far from human performance. For example, the accuracy on SciTail task under
high environment noise decline by 32.35% and is restored from 62.39% to 78.62% by audio-level
augmentation method. In contrast, human are almost unaffected by the ASR error and still maintain
6
https://huggingface.co/bert-base-uncased
7
https://huggingface.co/gpt2
8
https://huggingface.co/facebook/bart-large/tree/main
7Table 3: Baseline performance on the ASR-GLUE test sets. Here “Clean” stands for test on clean
text data. “Low/Medium/High” stand for test on low-level/medium-level/high-level noise version
respectively. Spearman correlations are reported for STS-B, and accuracy scores are reported for the
other tasks. All values are scaled by 100.
Audio-level Text-level Augmentation Correction
BERT BEST(∆) Human
Augmentation CM GPT-2 BART-S GECToR BART-C
Clean 92.25 92.90 91.61 90.96 92.90 92.25 92.25 92.90(+0.65) -
Low 88.60 89.35 86.99 87.31 89.78 87.74 87.85 89.78(+1.18) 90.40
SST-2
Medium 83.42 85.68 84.39 82.45 84.71 83.42 82.35 84.71(+1.29) 87.90
High 80.84 81.92 81.59 81.16 81.16 81.70 78.69 81.70(+0.86) 86.18
Clean 91.13 91.54 90.90 90.76 92.22 91.13 91.13 92.22(+1.09) -
Low 85.39 87.21 86.95 86.17 86.58 84.68 83.39 87.21(+1.82) 88.00
STS-B
Medium 69.93 75.49 74.16 73.14 71.38 68.38 69.73 75.49(+5.56) 86.59
High 63.89 70.66 68.70 68.03 65.89 62.83 65.42 70.66(+6.77) 85.44
Clean 87.16 87.75 88.03 88.40 87.75 87.16 87.16 88.40(+1.24) -
Low 76.75 81.98 80.58 81.33 79.18 76.66 73.67 81.98(+5.23) 83.22
QQP
Medium 69.47 76.94 73.76 75.07 70.40 70.59 67.51 76.94(+7.47) 81.02
High 67.77 76.18 72.85 72.21 68.79 69.62 66.67 76.18(+8.41) 77.60
Clean 94.74 90.79 94.74 94.74 91.45 94.74 94.74 94.74(+0.00) -
Low 75.33 85.53 85.31 85.31 77.63 79.61 80.26 85.53(+10.20) 90.82
SciTail
Medium 64.91 81.69 76.54 77.41 71.05 70.07 71.05 81.69(+16.78) 91.08
High 62.39 78.62 74.34 73.90 69.52 67.98 69.08 78.62(+16.23) 90.13
Clean 90.73 87.42 90.07 89.40 88.74 90.73 90.73 90.73(+0.00) -
Low 83.33 84.11 86.09 86.64 85.43 83.77 84.66 86.64(+3.31) 87.23
QNLI
Medium 78.48 82.23 84.11 84.44 83.33 79.80 79.91 84.44(+5.96) 86.29
High 77.15 82.12 82.23 83.44 81.57 76.93 76.71 83.44(+6.29) 83.68
Clean 68.93 63.76 66.37 64.69 66.27 68.93 68.93 68.93(+0.00) -
Low 60.06 62.36 58.91 61.78 59.91 60.78 59.05 62.36(+2.30) 65.43
RTE
Medium 53.87 57.33 54.89 60.78 55.60 56.35 53.59 60.78(+6.91) 64.21
High 52.86 52.73 50.29 56.90 49.86 55.02 51.44 56.90(+4.04) 63.14
high accuracy of 90.13%. Moreover, the human performance is more stable than the NLU model
across all noise-levels for various tasks. We can also observe that although audio-level augmentation
method achieves promising results on most tasks, it is even worse than the original BERT on RTE
task under high environment noise (52.73% vs 52.86%).
We also find that the performance of different method varies across tasks, and it is difficult to find a
universal method for all scenarios. Although the audio-level data augmentation method always gains
the highest accuracy on the data with ASR errors, it can not maintain the original performance on
clean data for certain tasks, e.g., worse than original BERT on clean text data (90.79% vs 94.74 on
SciTail, 87.42% vs 90.73% on QNLI, and 63.76% vs 68.93% on RTE).
Another interesting phenomena is that the ASR error correction is less effective in many cases. On
half of the tasks, such as SST-2, STS-B, QNLI, BERT with correction performs similar or even worse
than the original one. On other tasks, although it performs better than original BERT, but still worse
than augmentation-based methods. One possible reason for its poor performance is that the ASR
system already integrates a strong n-gram language model to guarantee the quality of system output.
So an additional language model is redundant and cannot make further improvement.
By comparison on various tasks, we can observe that the text-level augmentation achieves more
promising results than other methods. It works well in most situations, without degrading the NLU
performance on clean text in general. We further make comparisons between the three text-level
augmentation methods and find that none have absolute advantages. GPT-2 based augmentation
performs better in most situations, but on RTE task with clean text, the accuracy is much lower than
original BERT (64.69% vs 68.93%).
Overall, although the proposed methods can improve the model robustness to some extent, a large
gap still remains between these approaches and human, which indicates much potential for work on
robustness improvement for the NLU model.
5.3 Effect of ASR systems.
To verify this assumption that the ASR error may no longer be a serious problem in NLU for a good
enough ASR system, we conduct a further experiment that replace our kaldi-based ASR system with
a SOTA public ASR system: Google ASR. We replace the ASR system with Google ASR on dev and
test sets (not on training set due to its high price) and test the performance of BERT on these new sets.
8Figure 6: Performance of BERT on STS-B task with Google ASR systems, evaluated by Spearman
correlations.
6SHDNHU 6SHDNHU Clean Low Medium High
6SHDUPDQFRUUHODWLRQV
BERT(Google ASR) 91.13 86.97 83.65 82.20
Audio-level Augmentation 91.54 89.66 86.75 85.95
CM 90.90 89.00 85.82 84.63
Text-level
GPT-2 90.76 89.35 85.78 84.44
Augmentation
BART-S 92.22 88.56 84.62 83.38
GECToR 91.13 86.29 83.13 82.04
Correction
/RZ 0HGLXP +LJK BART-C 91.13 86.48 83.80 82.06
As shown in the left part of Figure 6, we report the performance of vanilla BERT on STS-B for two
different speakers (Speaker 1 and Speaker 6). The performance of Speaker 1 seems consistent with
the previous assumption that a good ASR system solves this problem. Nevertheless, for speaker 6, we
observe an opposite phenomena that the model performance still drops a lot (about 15%) in presence
of ASR error. To investigate the reason for these differences, we carefully compared their audio, and
find that although these both of them are native speakers from America, speaker 6 holds a strong
regional accent which can significantly increase the ASR error. Since the accent are widely existed in
audio signals, it is unrealistic to assume the input audio are always clean and standard. So even if we
have a good ASR system, strong and robust NLU models are still necessary.
We also report the result of the proposed methods with Google ASR in the right part of Figure 6.
On STS-B task, the performance of most methods are consistent with the results in Table 3. We can
observe the most data augmentation-based methods still perform well while the correction-based
methods are less effective. Although in training these methods are based on another ASR system,
they can generalize to Google ASR systems as well, which proves the generalization ability of
augmentation-based methods.
6 Related Work
Many benchmark datasets are created to facilitate Spoken Language Understanding (SLU) [41, 42,
5, 43, 26, 44], which evaluate the robustness of the downstream NLU model against the error output
from the upstream acoustic model [7, 8, 9, 10]. However, they are only designed for a particular
domain or a specific task such as intent detection and slot filling. In contrast, the human ability to
understand language is general, flexible, and robust. There is a need to test general-purpose natural
language understanding capability on diverse tasks in different domains.
Large-scale pretrained language models have achieved striking performance on NLU in recent
years [45, 34]. Recently many works test their robustness by human-crafted adversarial examples [46]
or generated examples by adversarial attacks [45, 47, 48, 49]. [50] projects the input data to a latent
space by generative adversarial networks (GANs), and then retrieves adversaries close to the original
instance in the latent space. [51] propose controlled paraphrase networks to generate syntactically
adversarial examples that both fool pre-trained models and improve the robustness of these models to
syntactic variation when used to augment their training data. However, the robustness of pre-trained
model to speech recognition error in real conditions has not been fully explored.
7 Conclusion
We present ASR-GLUE, a new benchmark for evaluating general-purpose language understanding
under ASR error in speech-based applications. We propose two ways to improve robustness of
the NLU system and find that there is still a gap between the NLU capability of the model and
humans. ASR-GLUE offers a rich and challenging testbed for work developing ASR robust model
for general-purpose language understanding. Given the difficulty of ASR-GLUE, we expect that
further progress in multi-task, multi-model learning techniques will be necessary to approach human-
level performance on the benchmark.
9References
[1] Wang, L., M. Fazel-Zarandi, A. Tiwari, et al. Data augmentation for training dialog models
robust to speech recognition errors. arXiv preprint arXiv:2006.05635, 2020.
[2] Williams, J. D., S. Young. Partially observable markov decision processes for spoken dialog
systems. Computer Speech & Language, 21(2):393–422, 2007.
[3] Wang, S., T. Gunter, D. VanDyke. On modelling uncertainty in neural language generation for
policy optimisation in voice-triggered dialog assistants. In 2nd Workshop on Conversational
AI: Today’s Practice and Tomorrow’s Potential, NeurIPS. 2018.
[4] Serdyuk, D., Y. Wang, C. Fuegen, et al. Towards end-to-end spoken language understanding. In
2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),
pages 5754–5758. IEEE, 2018.
[5] Wang, P., L. Wei, Y. Cao, et al. Large-scale unsupervised pre-training for end-to-end spoken
language understanding. In ICASSP 2020-2020 IEEE International Conference on Acoustics,
Speech and Signal Processing (ICASSP), pages 7999–8003. IEEE, 2020.
[6] Errattahi, R., A. El Hannani, H. Ouahmane. Automatic speech recognition errors detection and
correction: A review. Procedia Computer Science, 128:32–37, 2018.
[7] Schumann, R., P. Angkititrakul. Incorporating asr errors with attention-based, jointly trained
rnn for intent detection and slot filling. In 2018 IEEE International Conference on Acoustics,
Speech and Signal Processing (ICASSP), pages 6059–6063. IEEE, 2018.
[8] Weng, Y., S. S. Miryala, C. Khatri, et al. Joint contextual modeling for asr correction and
language understanding. In ICASSP 2020-2020 IEEE International Conference on Acoustics,
Speech and Signal Processing (ICASSP), pages 6349–6353. IEEE, 2020.
[9] Rao, M., A. Raju, P. Dheram, et al. Speech to semantics: Improve asr and nlu jointly via
all-neural interfaces. arXiv preprint arXiv:2008.06173, 2020.
[10] Huang, C.-W., Y.-N. Chen. Learning asr-robust contextualized embeddings for spoken language
understanding. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech
and Signal Processing (ICASSP), pages 8009–8013. IEEE, 2020.
[11] Radford, A., J. Wu, R. Child, et al. Language models are unsupervised multitask learners.
OpenAI blog, 1(8):9, 2019.
[12] Lewis, M., Y. Liu, N. Goyal, et al. Bart: Denoising sequence-to-sequence pre-training for
natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461,
2019.
[13] Fazel-Zarandi, M., L. Wang, A. Tiwari, et al. Investigation of error simulation techniques for
learning dialog policies for conversational error recovery. arXiv preprint arXiv:1911.03378,
2019.
[14] Schatzmann, J., B. Thomson, S. Young. Error simulation for training statistical dialogue systems.
In 2007 IEEE Workshop on Automatic Speech Recognition & Understanding (ASRU), pages
526–531. IEEE, 2007.
[15] Wang, A., A. Singh, J. Michael, et al. Glue: A multi-task benchmark and analysis platform for
natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
[16] Socher, R., A. Perelygin, J. Wu, et al. Recursive deep models for semantic compositionality over
a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural
language processing, pages 1631–1642. 2013.
[17] Cer, D., M. Diab, E. Agirre, et al. Semeval-2017 task 1: Semantic textual similarity-multilingual
and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055, 2017.
[18] Rajpurkar, P., J. Zhang, K. Lopyrev, et al. Squad: 100,000+ questions for machine comprehen-
sion of text. arXiv preprint arXiv:1606.05250, 2016.
[19] Dagan, I., O. Glickman, B. Magnini. The pascal recognising textual entailment challenge. In
Machine Learning Challenges Workshop, pages 177–190. Springer, 2005.
[20] Haim, R. B., I. Dagan, B. Dolan, et al. The second pascal recognising textual entailment
challenge. In Proceedings of the Second PASCAL Challenges Workshop on Recognising
Textual Entailment. 2006.
10[21] Giampiccolo, D., B. Magnini, I. Dagan, et al. The third pascal recognizing textual entail-
ment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and
paraphrasing, pages 1–9. 2007.
[22] Bentivogli, L., P. Clark, I. Dagan, et al. The fifth pascal recognizing textual entailment challenge.
In TAC. 2009.
[23] Khot, T., A. Sabharwal, P. Clark. Scitail: A textual entailment dataset from science question
answering. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32. 2018.
[24] Wölfel, M., J. McDonough. Distant speech recognition. John Wiley & Sons, 2009.
[25] Barker, J., S. Watanabe, E. Vincent, et al. The fifth’chime’speech separation and recognition
challenge: dataset, task and baselines. arXiv preprint arXiv:1803.10609, 2018.
[26] Henderson, M., B. Thomson, J. D. Williams. The second dialog state tracking challenge. In
Proceedings of the 15th annual meeting of the special interest group on discourse and dialogue
(SIGDIAL), pages 263–272. 2014.
[27] Ko, T., V. Peddinti, D. Povey, et al. A study on data augmentation of reverberant speech for
robust speech recognition. In 2017 IEEE International Conference on Acoustics, Speech and
Signal Processing (ICASSP), pages 5220–5224. IEEE, 2017.
[28] Habets, E. A. Room impulse response generator. Technische Universiteit Eindhoven, Tech.
Rep, 2(2.4):1, 2006.
[29] Povey, D., A. Ghoshal, G. Boulianne, et al. The kaldi speech recognition toolkit. In IEEE 2011
workshop on automatic speech recognition and understanding, CONF. IEEE Signal Processing
Society, 2011.
[30] Povey, D., V. Peddinti, D. Galvez, et al. Purely sequence-trained neural networks for asr based
on lattice-free mmi. In Interspeech, pages 2751–2755. 2016.
[31] Devlin, J., M.-W. Chang, K. Lee, et al. Bert: Pre-training of deep bidirectional transformers for
language understanding. arXiv preprint arXiv:1810.04805, 2018.
[32] Liu, Y., M. Ott, N. Goyal, et al. Roberta: A robustly optimized bert pretraining approach. arXiv
preprint arXiv:1907.11692, 2019.
[33] Lan, Z., M. Chen, S. Goodman, et al. Albert: A lite bert for self-supervised learning of language
representations. arXiv preprint arXiv:1909.11942, 2019.
[34] Yang, Z., Z. Dai, Y. Yang, et al. Xlnet: Generalized autoregressive pretraining for language
understanding. arXiv preprint arXiv:1906.08237, 2019.
[35] Omelianchuk, K., V. Atrasevych, A. Chernodub, et al. Gector–grammatical error correction:
Tag, not rewrite. arXiv preprint arXiv:2005.12592, 2020.
[36] Yu, C., H. Lu, N. Hu, et al. Durian: Duration informed attention network for speech synthesis.
Proc. Interspeech 2020, pages 2027–2031, 2020.
[37] Panayotov, V., G. Chen, D. Povey, et al. Librispeech: an asr corpus based on public domain
audio books. In 2015 IEEE international conference on acoustics, speech and signal processing
(ICASSP), pages 5206–5210. IEEE, 2015.
[38] Kingma, D. P., J. Ba. Adam: A method for stochastic optimization. arXiv preprint
arXiv:1412.6980, 2014.
[39] Sennrich, R., B. Haddow, A. Birch. Neural machine translation of rare words with subword
units. arXiv preprint arXiv:1508.07909, 2015.
[40] Koehn, P. Pharaoh: a beam search decoder for phrase-based statistical machine translation
models. In Conference of the Association for Machine Translation in the Americas, pages
115–124. Springer, 2004.
[41] Coucke, A., A. Saade, A. Ball, et al. Snips voice platform: an embedded spoken language
understanding system for private-by-design voice interfaces. arXiv preprint arXiv:1805.10190,
2018.
[42] Lugosch, L., M. Ravanelli, P. Ignoto, et al. Speech model pre-training for end-to-end spoken
language understanding. arXiv preprint arXiv:1904.03670, 2019.
11[43] Price, P. Evaluation of spoken language systems: The atis domain. In Speech and Natural
Language: Proceedings of a Workshop Held at Hidden Valley, Pennsylvania, June 24-27, 1990.
1990.
[44] Peng, B., C. Li, Z. Zhang, et al. Raddle: An evaluation benchmark and analysis platform for
robust task-oriented dialog systems. arXiv preprint arXiv:2012.14666, 2020.
[45] Jin, D., Z. Jin, J. T. Zhou, et al. Is bert really robust? a strong baseline for natural language
attack on text classification and entailment. In Proceedings of the AAAI conference on artificial
intelligence, vol. 34, pages 8018–8025. 2020.
[46] Nie, Y., A. Williams, E. Dinan, et al. Adversarial nli: A new benchmark for natural language
understanding. arXiv preprint arXiv:1910.14599, 2019.
[47] Madry, A., A. Makelov, L. Schmidt, et al. Towards deep learning models resistant to adversarial
attacks. arXiv preprint arXiv:1706.06083, 2017.
[48] Zhu, C., Y. Cheng, Z. Gan, et al. Freelb: Enhanced adversarial training for natural language
understanding. arXiv preprint arXiv:1909.11764, 2019.
[49] Dong, X., A. T. Luu, R. Ji, et al. Towards robustness against natural language word substitutions.
In 9th International Conference on Learning Representations (ICLR). 2021.
[50] Zhao, Z., D. Dua, S. Singh. Generating natural adversarial examples. In 6th International
Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May
3, 2018, Conference Track Proceedings. OpenReview.net, 2018.
[51] Iyyer, M., J. Wieting, K. Gimpel, et al. Adversarial example generation with syntactically
controlled paraphrase networks. arXiv preprint arXiv:1804.06059, 2018.
12A Appendix
A.1 Detailed descriptions for the ASR-GLUE datasets
SST-2 The Stanford Sentiment Treebank [16] is a single-input understanding task for sentiment
classification. The task is to predict the sentiment of a given sentence in movie reviews domain.
Accuracy (ACC) of the binary classification (positive or negative) is used as the metric.
STS-B The Semantic Textual Similarity Benchmark [17] consists of sentence pairs drawn from news
headlines, video and image captions, and natural language inference data. The task is to predict
sentence similarity scores which ranges from 1 to 5. We evaluate using Pearson and Spearman
correlation coefficients.
QQP The Quora Question Pairs 9 dataset consists of question pairs in social QA questions domain.
The task is to determine whether a pair of questions are semantically equivalent. Accuracy (ACC) is
used as the metric.
QNLI Question-answering NLI is modified from the Stanford Question Answering dataset [18]. This
is a sentence pair classification task which determines whether the context sentence contains the
answer to the question. Accuracy (ACC) is used as the metric.
SciTail SciTail [23] is a recently released challenging textual entailment dataset collected from the
science domain. This is a natural language inference task which determines if a natural language
hypothesis can be justifiably inferred from a given premise. Accuracy (ACC) is used as the metric.
RTE The Recognizing Textual Entailment (RTE) datasets come from a series of annual textual
entailment challenges merged from a collection of [19, 20] All datasets are combined and converted
to two-class classification: entailment and not entailment. Accuracy (ACC) is used as the metric.
A.2 Details of kaldi-based ASR word error rate results
Table 4: Detailed kaldi-based ASR WER on ASR-GLUE test set
Corpus Noisy level Speaker1 Speaker2 Speaker3 Speaker4 Speaker5 Speaker6
SST-2 11.50 18.53 30.03 19.94 13.96 38.36
STS-B 6.87 11.89 17.76 12.62 7.67 13.62
QQP 10.44 13.05 25.46 13.10 10.77 25.49
Low
QNLI 13.47 17.43 31.05 19.88 14.55 30.42
RTE 23.04 18.98 34.34 22.05 15.60 37.77
SciTail 8.47 13.98 23.49 16.83 9.18 27.53
SST-2 21.64 29.68 40.12 34.60 23.23 53.26
STS-B 20.06 28.16 31.11 21.79 16.49 29.65
QQP 18.85 22.13 39.01 19.90 18.26 40.39
Medium
QNLI 22.98 31.75 40.09 32.82 20.98 47.32
RTE 37.21 34.39 47.25 35.63 25.54 59.38
SciTail 18.71 26.72 34.75 33.20 15.89 44.13
SST-2 25.98 33.90 42.82 37.77 27.27 55.31
STS-B 24.66 32.61 33.22 25.09 18.83 33.71
QQP 21.64 24.45 41.52 22.11 22.23 43.77
High
QNLI 28.09 36.05 42.96 35.53 24.76 51.73
RTE 44.12 41.20 54.56 50.70 33.33 64.91
SciTail 23.13 29.89 36.60 37.65 19.93 48.55
A.3 Details for the exam and annotation process
In the annotation process, the annotators are required to predict labels of each test sample according
to the corresponding audio signals. Note that for each test sample we have 18 audio signals (3 levels
of noise * 6 speakers), which is a big burden for the annotators. So we randomly select one audio
9
data.quora.com/First-Quora-Dataset-Release-Question-Pairs
13from the six speakers with each noise level and report the averaged performance of the annotators on
all tasks.
The exam is set to guarantee the annotators fully understand each task. In the exam, we randomly
select 50 samples from the original datasets which is in text form for each task. Annotators who
achieve at least 90% accuracy on these samples will be hired.
14You can also read

















































