Binary Ensemble Neural Network: More Bits per Network or More Networks per Bit? - Sioni Summers - CERN Indico
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Binary Ensemble Neural Network: More Bits per
Network or More Networks per Bit?
mPP Journal Club
August 6 2020
Sioni Summers
Introduction & Context
●
We recently published a paper on Binary & Ternary Neural Networks (BNNs,
TNNs) in hls4ml [1]
●
BNNs & TNNs can be very efficiently computed → multiplication becomes
boolean ‘xnor’ & accumulation involves summing ‘1s’
– Multipliers are the critical FPGA resource for NNs with more than a few
bits weights & activations
●
However, with the same architecture (numbers of neurons, layers) as a
float-precision reference, performance can drop a lot
– Common approach → increase network size
– Balance between accepted performance loss vs. compute efficiency
●
This paper [2] introduces ‘BENN’ : Binary Ensemble Neural Networks
– Instead of increasing network size, use several smaller ones with
ensemble methods
●
[1] https://iopscience.iop.org/article/10.1088/2632-2153/aba042/meta
●
[2] https://ieeexplore.ieee.org/document/8954129
6/8/2020 mPP Journal Club – Sioni Summers
Introduction & Context
●
“In this paper, we investigate BNNs systematically in terms of representation
power, speed, bias, variance, stability, and their robustness. We find that
BNNs suffer from severe intrinsic instability and non-robustness
regardless of network parameter values. What implied by this observation is
that the performance degradation of BNNs are not likely to be resolved by
solely improving the optimization techniques; instead, it is mandatory to
cure the BNN function, particularly to reduce the prediction variance and
improve its robustness to noise”
6/8/2020 mPP Journal Club – Sioni Summers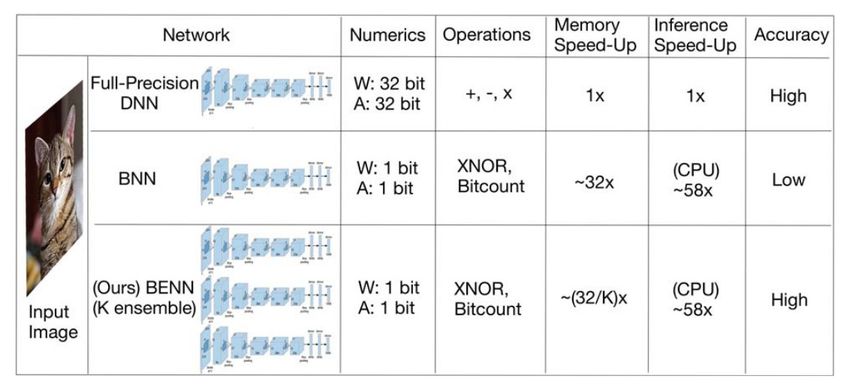
Ensemble Methods
●
Combine multiple weak learners into a strong one
– Bagging & Boosting most common methods
●
Paraphrasing the paper: ensemble techniques not normally useful for NNs, NNs
are not ‘weak classifiers’, but BNNs are :D
●
Bagging: (Bootstrap aggregating)
– Train different learners (BNNs) independently
– Boostrapping → randomly draw samples from the dataset for each learner
– Train each learner on its sample, aggregate predictions (hard-voting, soft-
voting)
https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
6/8/2020 mPP Journal Club – Sioni Summers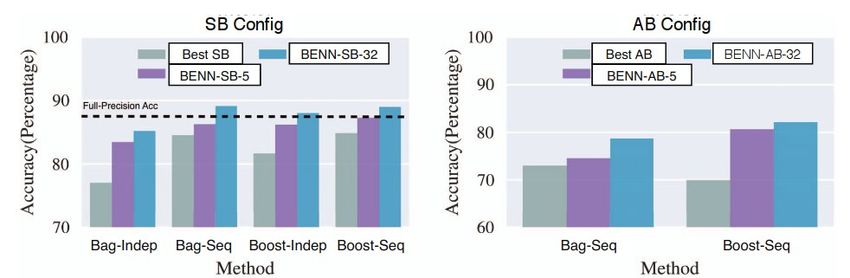
Ensemble Methods
●
Boosting is a sequential fitting of the weak learners
– Samples which are badly predicted in a round are given more weight in
the next → focus on the difficult examples
●
Adaboost (adaptive boosting), as used in the BENN paper, aggregates the
weak learners (BNNs)
●
Using NN, you need to choose random init of each learner, or ‘warm start’
from previous round (paper tries both)
https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
6/8/2020 mPP Journal Club – Sioni Summers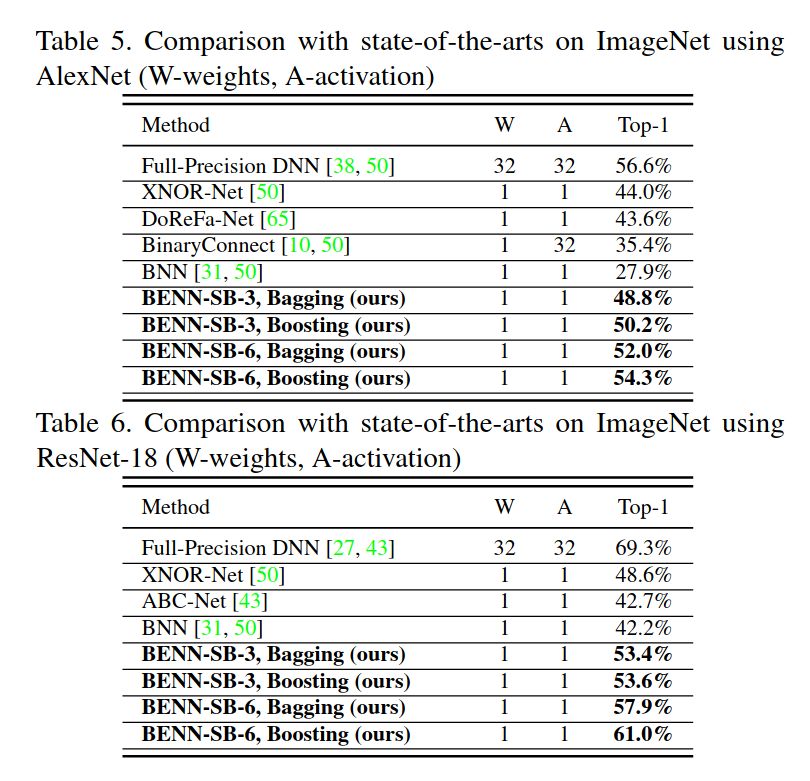
Training BNNs, TNNs
●
Binary Neural Networks use 1-bit for the weights: {+1, -1}. TNNs
additionally allow ‘0’
●
The {+1, -1} are encoded as {+1, 0} → use 1 bit, ‘*’ = ‘xnor’
●
We use the ‘Straight Through Estimator’ (STE) to train:
– Weights are actually continuous floating point values
– Clip & round during forward pass
– Compute gradient with respect to floating point weight, update FP
weight
●
Activations can also be 1- or 2- bits, but we see better performance with
ReLU using a few (>~4 bits)
●
In our paper, used a Bayesian Optimization of hyperparameters to find best
model size → 7x more neurons per hidden layer (7² more ‘*’)
●
(The paper only uses BNNs, but the technique should apply to TNNs too)
6/8/2020 mPP Journal Club – Sioni Summers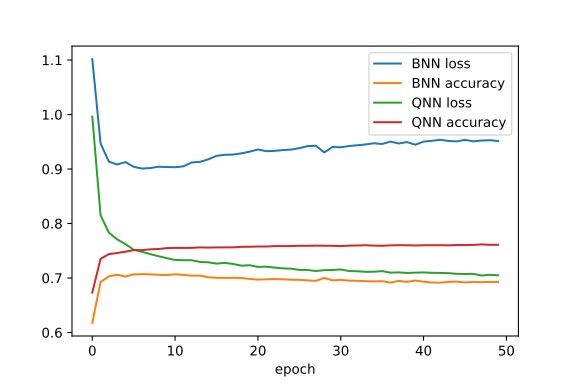
Training BNNs, TNNs
●
From our paper
●
Experiments with MNIST
●
Experiments with jets high level features
6/8/2020 mPP Journal Club – Sioni Summers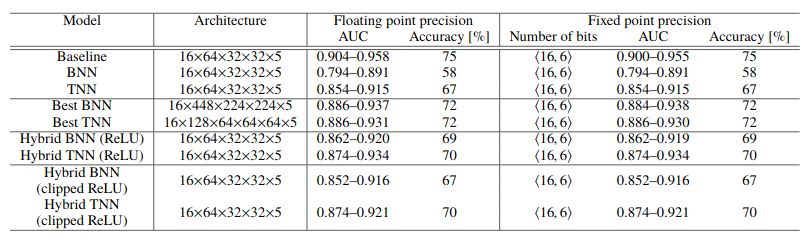
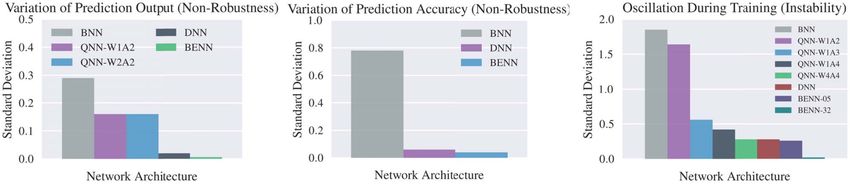
BNN Training problems
●
Non-robustness (overfitting)
●
BNNs have huge variation in loss, accuracy while training
●
(I think) this has a lot to do with 1) the extreme quantization, 2) the STE
●
In literature ‘Gradient mismatch’
●
(Stochastic rounding as in QKeras is supposed to help with this)
6/8/2020 mPP Journal Club – Sioni Summers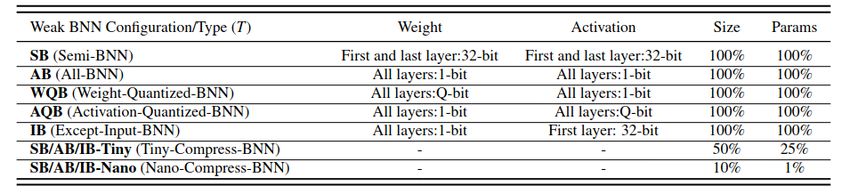
BNN Training problems
●
Non-robustness (overfitting)
●
BNNs have huge variation in loss, accuracy while training
●
(I think) this has a lot to do with 1) the extreme quantization, 2) the STE
●
In literature ‘Gradient mismatch’
●
(Stochastic rounding as in QKeras is supposed to help with this)
6/8/2020 mPP Journal Club – Sioni SummersExperiments
●
Datasets: CIFAR-10, Imagenet
●
Many different flavours of BNN tested
●
Generally keeping some layers (in particular 1st and last) has been seen to
help a lot, while keeping most of the compute savings
●
In the hls4ml BNN+TNN paper, we used something like ‘AB’ (= “BNN”) and
‘AQB’ (= “Hybrid BNN”)
6/8/2020 mPP Journal Club – Sioni SummersResults
‘-Indep’ = independent trainings, vs. ‘-Seq’ = warm start
●
‘BENN-SB-5’ = 5 learners of type SB, x-axis shows boosting method
●
‘SB’ better than ‘AB’ (no surprise)
●
BENN-SB-5, BENN-SB-32 can do as well as full float model
6/8/2020 mPP Journal Club – Sioni SummersResults - ImageNet
●
On ImageNet dataset,
AlexNet model, the
‘BENN-SB-6, Boosting’
model does nearly as
well as the Full-Precision
●
On ImageNet, with
ResNet-18 the gap
between Full-Precision
and BENN is wider
6/8/2020 mPP Journal Club – Sioni SummersBENN is hardware friendly
●
“BENN is hardware friendly: Using BENN with K ensembles is
better than using one K-bit classifier”
●
I don’t think they can really conclude this from their study
– The only ‘K-bit’ classifier is the ‘full-precision’, which uses float and is
not really a fair comparison
– They didn’t include results for low-bitwidth QNN to compare with e.g.
the 3, 5, 6 ensemble BENNs
– Would be interesting to compare to something like QKeras ~few bit
models
●
That said, an ensemble of N neural networks involves fewer operations
(MACCs) than one NN with neurons increased N-times
●
So the method could be very useful for cases which must use BNNs, but
model size/architecture is free
6/8/2020 mPP Journal Club – Sioni SummersPaper Conclusion
●
“In this paper, we proposed BENN, a novel neural network
architecture which marries BNN with ensemble methods. The
experiments showed a large performance gain in terms of
accuracy, robustness, and stability. Our experiments also reveal
some insights about trade-offs on bit width, network size,
number of ensembles, etc. We believe that by leveraging
specialized hardware such as FPGA and more advanced modern
ensemble techniques with less overfitting, BENN can be a new
dawn for deploying large deep neural networks into mobile and
embedded systems.”
6/8/2020 mPP Journal Club – Sioni SummersMy Conclusion
●
It’s a cool idea to increase performance and robustness of BNNs, which are
known to be difficult to train, and lossy compared to full-precision
●
For me, it’s still not clear in the 1 to ~8 range whether a k-ensemble BENN
or a k-bit QNN is better
●
But, in a case which must use BNNs, certainly seems BENN can ‘boost’
performance ;)
●
I tried to run my own tests with QKeras and scikit-learn boosting methods
– TF Keras has ‘KerasClassifier’ wrapper for scikit-learn
– It doesn’t suport ‘sample_weight’, so I had to add another wrapper of
my own…
– sklearn BaggingClassifier worked, performance slightly worse than QNN,
4 bits
– sklearn AdaBoost didn’t train → random performance, not sure why
– Need to fiddle with parameters and try again!
– Here’s what I tried
https://gist.github.com/thesps/b0c3d1636d5f3d7d8c35391e0155d592
6/8/2020 mPP Journal Club – Sioni SummersYou can also read