I Can Has Cheezburger? A Nonparanormal Approach to Combining Textual and Visual Information for Predicting and Generating Popular Meme Descriptions
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

I Can Has Cheezburger?
A Nonparanormal Approach to Combining Textual and Visual Information
for Predicting and Generating Popular Meme Descriptions
William Yang Wang and Miaomiao Wen
School of Computer Science
Carnegie Mellon University
Pittsburgh, PA 15213
Abstract
The advent of social media has brought Inter-
net memes, a unique social phenomenon, to
the front stage of the Web. Embodied in the
form of images with text descriptions, little do
we know about the “language of memes”. In
this paper, we statistically study the correla-
tions among popular memes and their word-
ings, and generate meme descriptions from Figure 1: An example of the LOL cat memes.
raw images. To do this, we take a multi-
modal approach—we propose a robust non- include superimposed text with broken grammars
paranormal model to learn the stochastic de- and/or spellings.
pendencies among the image, the candidate
Even though the memes are popular over the In-
descriptions, and the popular votes. In experi-
ments, we show that combining text and vision ternet, the “language of memes” is still not well-
helps identifying popular meme descriptions; understood: there are no systematic studies on pre-
that our nonparanormal model is able to learn dicting and generating popular Internet memes from
dense and continuous vision features jointly the Natural Language Processing (NLP) and Com-
with sparse and discrete text features in a prin- puter Vision (CV) perspectives.
cipled manner, outperforming various com- In this paper, we take a multimodal approach to
petitive baselines; that our system can gener-
predict and generate popular meme descriptions. To
ate meme descriptions using a simple pipeline.
do this, we collect a set of original meme images,
1 Introduction a list of candidate descriptions, and the correspond-
ing votes. We propose a robust nonparanormal ap-
In the past few years, Internet memes become a new, proach (Liu et al., 2009) to model the multimodal
contagious social phenomenon: it all starts with an stochastic dependencies among images, text, and
image with a witty, catchy, or sarcastic sentence, and votes. We then introduce a simple pipeline for gen-
people circulate it from friends to friends, colleagues erating meme descriptions combining reverse im-
to colleagues, and families to families. Eventually, age search and traditional information retrieval ap-
some of them go viral on the Internet. proaches. In empirical experiments, we show that
Meme is not only about the funny picture, the our model outperforms strong discriminative base-
Internet culture, or the emotion that passes along, lines by very large margins in the regression/ranking
but also about the richness and uniqueness of its experiments, and that in the generation experiment,
language: it is often highly structured with special the nonparanormal outperforms the second-best su-
written style, and forms interesting and subtle con- pervised baseline by 4.35 BLEU points, and obtains
notations that resonate among the readers. For ex- a BLEU score improvement of 4.48 over an unsu-
ample, the LOL cat memes (e.g., Figure 1) often pervised recurrent neural network language model
trained on a large meme corpus that is almost 90 and Zitnick, 2014; Donahue et al., 2014; Fang et
times larger. Our contributions are three-fold: al., 2014; Karpathy and Fei-Fei, 2014) using neural
network models. Although the above studies have
• We are the first to study the “language of shown interesting results, our task is arguably more
memes” combining NLP, CV, and machine complex than generating text descriptions: in ad-
learning techniques, and show that combining dition to the visual and textual signals, we have to
the visual and textual signals helps identifying model the popular votes as a third dimension for
popular meme descriptions; learning. For example, we cannot simply train a con-
• Our approach empowers Internet users to select volutional neural network image parser on billions
better wordings and generate new memes auto- of images, and use recurrent neural networks to gen-
matically; erate texts such as “There is a white cat sitting next
• Our proposed robust nonparanormal model to a laptop.” for Figure 1. Additionally, since not
outperforms competitive baselines for predict- all images are suitable as meme images, collecting
ing and generating popular meme descriptions. training images is also more challenging in our task.
In contrast to prior work, we take a very
In the next section, we outline related work. In
different approach: we investigate copula meth-
Section 3, we introduce the theory of copula, and
ods (Schweizer and Sklar, 1983; Nelsen, 1999), in
our nonparanormal approach. In Section 4, we de-
particular, the nonparanormals (Liu et al., 2009), for
scribe the datasets. We show the prediction and gen-
joint modeling of raw images, text descriptions, and
eration results in Section 5 and Section 6. Finally,
popular votes. Copula is a statistical framework for
we conclude in Section 7.
analyzing random variables from Statistics (Liu et
2 Related Work al., 2012), and often used in Economics (Chen and
Fan, 2006). Only until very recently, researchers
Although the language of Internet memes is a rel- from the machine learning and information retrieval
atively new research topic, our work is broadly re- communities (Ghahramani et al., 2012; Han et al.,
lated to studies on predicting popular social media 2012; Eickhoff et al., 2013). start to understand the
messages (Hong et al., 2011; Bakshy et al., 2011; theory and the predictive power of copula models.
Artzi et al., 2012). Most recently, Tan et al. (2014) Wang and Hua (2014) are the first to introduce semi-
study the effect on wordings for Tweets. However, parametric Gaussian copula (a.k.a. nonparanormals)
none of the above studies have investigated multi- for text prediction. However, their approach may
modal approaches that combine text and vision. be prone to overfitting. In this work, we generalize
Recently, there has been growing interests in Wang and Hua’s method to jointly model text and
inter-disciplinary research on generating image de- vision features with popular votes, while scaling up
scriptions. Gupta el al. (2009) have studied the prob- the model using effective dropout regularization.
lem of constructing plots from video understand-
ing. The work by Farhadi et al. (2010) is among 3 Our Approach
the first to generate sentences from images. Kulka-
rni et al. (2011) use linguistic constraints and a con- A key challenge for joint modeling of text and vision
ditional random field model for the task, whereas is that, because textual features are often relatively
Mitchell et al. (2012) leverage syntactic information sparse and discrete, while visual features are typi-
and co-occurrence statistics and Dodge et al. (2012) cally dense and continuous, it is difficult to model
use a large text corpus and CV algorithms for detect- them jointly in a principled way.
ing visual text. With the surge of interests in deep To avoid comparing “apple and oranges” in the
learning techniques in NLP (Socher et al., 2013; De- same probabilistic space, we propose the non-
vlin et al., 2014) and CV (Krizhevsky et al., 2012; paranormal approach, which extends the Gaussian
Oquab et al., 2013), there have been several unref- graphical model by transforming its variables by
ereed manuscripts on parsing images and generating smooth functions. More specifically, for each di-
text descriptions lately (Vinyals et al., 2014; Chen mension of textual and visual features, instead of
Figure 2: Our nonparanormal method extends Gaussian
by transforming each dimension with a smooth function, Figure 3: An example of the standard SIFT keypoints de-
and jointly models the stochastic dependencies among tected on the “doge” meme.
textual and visual features, as well as the popular votes
memes, we have also extracted typed depen-
by the crowd.
dency triples (e.g., subj(I,are)) using the Malt-
using raw counts or histograms, we first use prob- Parser (Nivre et al., 2007).
ability integral transform to generate empirical cu- • Named Entity Features: after browsing the
mulative density functions (ECDF): now instead of dataset, we notice that certain names are of-
the probability density function (PDF) space, we are ten mentioned in memes (e.g. “Drake”, “Kenye
working in the ECDF space where the value of each West”, and “Justin Bieber”), so we utilize the
feature is based on the rank, and is strictly restricted Stanford named entity recognizer (Finkel et al.,
between 0 and 1. Then, we use kernel density esti- 2005) to extract lexicalized named entities.
mation to smooth out the zeroing features1 . Finally,
• Frame-Semantics Features: SEMAFOR (Das
now textual and visual features are compatible, and
et al., 2010) is a state-of-the-art frame-
we then build a parametric Gaussian copula model
semantics parser that produces FrameNet-style
to estimate the pair-wise correlations among the co-
semantic annotation. We use SEMAFOR to ex-
variate and the dependent variable.
tract frame-level semantic features.
In this section, we first explain the visual and tex-
tual features used in this study. Then, we introduce Visual Features A key insight on viral memes is
the theory of copula, and describe the robust non- that the images producing a shared social signal are
paranormal. Finally, we show a simple pipeline for typically inter-related in style. For example, LOL-
generating meme descriptions. cats are an early series of memes involving funny cat
photos. Similarly, “Bieber memes” involve modified
3.1 Features pictures of Bieber.
Textual Features To model the meme descriptions, Therefore, we hypothesize that, by extracting vi-
we take a broad range of textual features into con- sual features, it is of crucial importance to capture
siderations: the entities, objects, and styles as visual words in
• Lexical Features: we extract unigrams and bi- these inter-related meme images. The popular vi-
grams from meme descriptions as surface-level sual bag-of-words representation (Sivic and Zisser-
lexical features. man, 2003) is used to describe images:
• Part-of-Speech Features: to model shallow 1. PHOW Features Extraction: unlike text fea-
syntactic cues, we extract lexicalized part-of- tures, SIFT first detects the Harris keypoints
speech features using the Stanford part-of- from an image, and then describes each key-
speech tagger (Toutanova et al., 2003). point with a vector. An example of the SIFT
frames are shown in Figure 3. PHOW (Bosch
• Dependency Triples: to better understand the et al., 2007) is a dense and multi-scale vari-
deeper syntactic dependencies of keywords in ant of the Scale Invariant Feature Transform
1
This is necessary for the normal inversion of the ECDFs, (SIFT) descriptors. Using PHOW, we obtain
which we will describe in Section 3.2. about 20K keypoints for each image.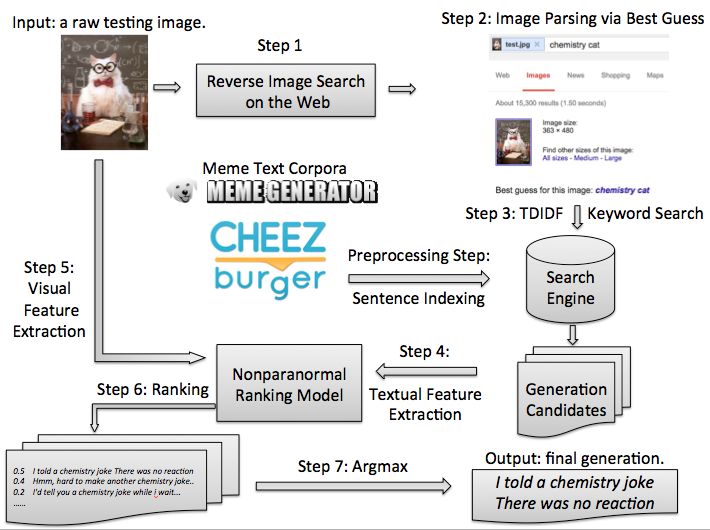
2. Elkan K-means Clustering is the clustering C[F1 (x1 ), ..., Fn (xn )] defines a multivariate
method (Elkan, 2003) that we use to obtain cumulative distribution function.
the vocabulary for visual words. Compar-
ing to other variants of K-means, this method 3.3 The Nonparanormal
quickly constructs the codebook from PHOW To model multivariate text and vision variables,
keypoints. we choose the nonparanormal (NPN) as the copula
3. Bag-of-Words Histograms are used to repre- function in this study, which can be explained in the
sent each image. We match the PHOW key- following two parts.
points of each image with the vocabulary that
The Nonparametric Estimation
we extract from the previous step, and generate
a 1 × 200 sized visual bag-of-words vector. Assume we have n random variables of vision and
3.2 The Theory of Copula text features X1 , X2 , ..., Xn . The problem is that
text features are sparse, so we need to perform non-
In the Statistics literature, copula is widely known parametric kernel density estimation to smooth out
as a family of distribution function. The idea be- the distribution of each variable. Let f1 , f2 , ..., fn
hind copula theory is that the cumulative distribu- be the unknown density, we are interested in deriv-
tion function (CDF) of a random vector can be rep- ing the shape of these functions. Assume we have m
resented in the form of uniform marginal cumula- samples, the kernel density estimator can be defined
tive distribution functions, and a copula that con- as:
nects these marginal CDFs, which describes the cor-
m
relations among the input random variables. How- 1 X
ever, in order to have a valid multivariate distribution fˆh (x) = Kh (x − xi ) (2)
m
i=1
function regardless of n-dimensional covariates, not
m
!
every function can be used as a copula function. The 1 X x − xi
= K (3)
central idea behind copula, therefore, can be sum- mh h
i=1
marize by the Sklar’s theorem and the corollary.
Theorem 1 (Sklar’s Theorem (1959)) Let F be Here, K(·) is the kernel function, where in our case,
the joint cumulative distribution function of n ran- we use the Box kernel2 K(z):
dom variables X1 , X2 , ..., Xn . Let the correspond-
1
ing marginal cumulative distribution functions of K(z) = , |z| ≤ 1, (4)
2
the random variable be F1 (x1 ), F2 (x2 ), ..., Fn (xn ).
= 0, |z| > 1. (5)
Then, if the marginal functions are continuous, there
exists a unique copula C, such that
Comparing to the Gaussian kernel and other kernels,
F (x1 , ..., xn ) = C[F1 (x1 ), ..., Fn (xn )]. (1) the Box kernel is simple, and computationally in-
expensive. The parameter h is the bandwidth for
Furthermore, if the distributions are continuous, the
smoothing3 .
multivariate dependency structure and the marginals
Now, we can derive the empirical cumulative dis-
might be separated, and the copula can be consid-
tribution functions
ered independent of the marginals (Joe, 1997; Parsa
and Klugman, 2011). Therefore, the copula does not F̂X1 (fˆ1 (X1 )), F̂X2 (fˆ2 (X2 )), ..., F̂Xn (fˆn (Xn ))
have requirements on the marginal distributions, and
any arbitrary marginals can be combined and their of the smoothed covariates, as well as the dependent
dependency structure can be modeled using the cop- variable y (which is the reciprocal rank of the pop-
ula. The inverse of Sklar’s Theorem is also true in ular votes of a meme) and its CDF F̂y (fˆ(y)). The
the following:
2
It is also known as the original Parzen windows (Parzen,
Corollary 1 If there exists a copula C : (0, 1)n 1962).
and marginal cumulative distribution func- 3
In our implementation, we use the default h of the Box
tions F1 (x1 ), F2 (x2 ), ..., Fn (xn ), then kernel in the ksdensity function in Matlab.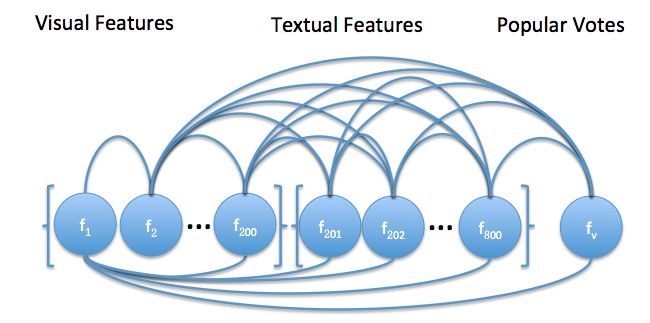
empirical cumulative distribution functions are de- shirani, 1996). While Lasso is widely used, the non-
fined as: differentiable nature of the L1 norm often make the
m objective function difficult to optimize. In this work,
1 X we propose dropout training (Hinton et al., 2012)
F̂ (ν) = I{xi ≤ ν} (6)
m as copula regularization. Dropout was proposed by
i=1
Hinton et al. as a method to prevent feature co-
where I{·} is the indicator function, and ν indicates adaptation in the deep learning framework, but re-
the current value that we are evaluating. Note that cently studies (Wager et al., 2013) also show that its
the above step is also known as probability integral behaviour is similar to L2 regularization, and can be
transform (Diebold et al., 1997), which allows us to approximated efficiently (Wang and Manning, 2013)
convert any given continuous distribution to random in many other machine learning tasks. Another ad-
variables having a uniform distribution. This is cru- vantage of dropout training is that, unlike Lasso, it
cial for text: instead of using the raw counts, we are does not require all the features for training, and
now working with uniform marginal CDFs, which training is “embarrassingly” parallelizable.
helps coping with the overfitting issue due to noise In Gaussian copula estimation context, we can in-
and data sparsity. We also use the same procedure to troduce another dimension `: the number of dropout
transform the vision features into CDF space to be learners, to extend the Σ into a dropout tensor. Es-
compatible with text features. sentially, the task becomes the estimation of
The Robust Estimation of Copula Σ1 , Σ2 , ..., Σ`
Now that we have obtained the marginals, and where the input feature space for each dropout com-
then the joint distribution can be constructed by ap- ponent is randomly corrupted by (1 − δ) percent of
plying the copula function that models the stochastic the original dimension. In the inference time, we
dependencies among marginal CDFs: use geometric mean to average the predictions from
each dropout learner, and generate the final predic-
F̂ (fˆ1 (X1 ), ..., fˆ1 (Xn ), fˆ(y)) tion. Note that the final Σ matrix has to be symmet-
= C[F̂X1 fˆ1 (X1 ) , ..., F̂Xn fˆn (Xn ) , F̂y fˆy (y) ] ric and positive definite, so we apply tiny random
(7) Gaussian noise to maintain the property.
In this work, we apply the parametric Gaussian cop- Computational Complexity
ula to model the correlations among the text features One important question regarding the proposed
and the label. Assume xi is the smoothed version of nonparanormal model is the corresponding compu-
random variable Xi , and y is the smoothed label, we tational complexity. This boils down to the es-
have: timation of the Σ̂ matrix (Liu et al., 2012): one
F (x1 , ..., xn , y) only needs to calculate the correlation coefficients
of n(n − 1)/2 pairs of random variables. Chris-
= ΦΣ Φ−1 [Fx1 (x1 )], ..., , Φ−1 [Fxn (xn )], Φ−1 [Fy (y)]
(8) tensen (2005) shows that sorting and balanced bi-
where ΦΣ is the joint cumulative distribution func- nary trees can be used to calculate the correlation
tion of a multivariate Gaussian with zero mean and coefficients with complexity of O(n log n). There-
Σ variance. Φ−1 is the inverse CDF of a standard fore, the computational complexity of MLE for the
Gaussian. In this parametric part of the model, the proposed model is O(n log n).
parameter estimation boils down to the problem of Efficient Approximate Inference
learning the covariance matrix Σ of this Gaussian In this prediction task, in order to perform
copula. In this work, we perform standard maxi- the exact inference of the conditional probabil-
mum likelihood estimation (MLE) for the Σ matrix, ity distribution p(Fy (y)|Fx1 (x1 ), ..., Fxn (xn )),
where we follow the details from prior work (Wang one needs to solve the mean response
and Hua, 2014). Ê(Fy (y)|Fx1 (x1 ), ..., Fx1 (x1 )) from a joint
To avoid overfitting, traditionally, one resorts to distribution of high-dimensional Gaussian cop-
classic regularization techniques such as Lasso (Tib- ula. Unfortunately, the exact inference can bequery image with all possible images with their cap-
tions in Google’s database, a “Best Guess” of the
keywords in the image is then revealed.
Using the extracted image keywords, we further
query a TF-IDF based Lucene5 meme search en-
gine, which we indexed with a large number of Web-
crawled meme descriptions. After we obtain the
candidate generations, we then extract all the text
and vision features that we described in Section 3.1.
Finally, our nonparanormal model ranks all possible
candidates, and selects the final generation with the
highest posterior.
Figure 4: Our pipeline for generating memes from raw 4 Datasets
images. We collected meme images and text descriptions6
intractable in the multivariate case, and approximate from two popular meme websites7 . In the predic-
inference, such as Markov Chain Monte Carlo tion experiment, we use 3,008 image-description
sampling (Gelfand and Smith, 1990; Pitt et al., pairs for training, and 526 image-description pairs
2006) is often used for posterior inference. In this for testing. In the generation experiment, we use
work, we propose an efficient sampling method 269,473 meme descriptions to index the meme
to derive y given the text features — we sample search engine, and 50 randomly selected images for
Fyˆ(y) s.t. it maximizes the joint high-dimensional testing. During training, we convert the raw counts
Gaussian copula density: of popular votes into reciprocal ranks (e.g., the most
1 1
popular text descriptions will all have a reciprocal
exp − ∆T · Σ−1 − I · ∆
arg max √ rank of 1, and n-th popular one will have a score of
Fyˆ(y)∈(0,1) det Σ 2
1/n).
(9)
where 5 Prediction Experiments
Φ−1 (F
x1 (x1 )) In the first experiment, we compare the proposed
.. NPN with various baselines in a prediction task,
∆=
.
Φ−1 (Fxn (xn ))
since prior literature (Hodosh et al., 2013) also sug-
Φ−1 (Fy (y)) gests using ranking based evaluation for associating
images with text descriptions. Throughout the ex-
This approximate inference scheme using max- periment sections, we set ` = 10, and δ = 80 as the
imum density sampling from the Gaussian copula dropout hyperparameters.
significantly relaxes the complexity of inference. Fi-
nally, to derive ŷ, the last step is to compute the Baselines:
inverse CDF of Fyˆ(y). A detailed description of The baselines are standard squared-loss lin-
the inference algorithm can be found in our prior ear regression, linear kernel SVM, and non-linear
work (Wang and Hua, 2014). (Gaussian) kernel SVM. In a recent empirical
study (Fernández-Delgado et al., 2014) that evalu-
3.4 A Simple Meme Generation Pipeline
ates 179 classifiers from 17 families on 121 UCI
Now after we train a nonparanormal model for rank- datasets, the authors find that Gaussian SVM is one
ing meme descriptions, we show the simple meme of the top performing classifiers. We use the Sta-
generation pipeline in Figure 4. tistical Toolbox’s linear regression implementation
Given a test image, we disguise as the Internet in Matlab, and LibSVM (Chang and Lin, 2011) for
Explorer, and query Google’s “Search By Image” 5
http://lucene.apache.org/
inverse image search service4 . By comparing the 6
http://www.cs.cmu.edu/˜yww/data/meme dataset.zip.
4 7
http://www.google.com/imghp/ memegenerator.net and cheezburger.comtraining and testing the SVM models. The hyperpa- Feature Sets LR LSVM GSVM NPN
rameter C in linear SVM, and the γ and C hyperpa- Unigrams 0.152 0.158 0.176 0.241*
rameters in Gaussian SVM are tuned on the training + Bigrams 0.163 0.248 0.279 0.318*
+ Named Entities 0.188 0.296 0.312 0.339*
set using 10-fold cross-validation.
+ Part-of-Speech 0.184 0.318 0.337 0.343
Evaluation Metrics: + Dependency 0.191 0.322 0.348 0.350
+ Semantics 0.183 0.368 0.388 0.367
Spearman’s correlation (Hogg and Craig, 1994) All Text + Vision 0.413 0.415 0.451 0.754*
and Kendall’s tau (Kendall, 1938) have been widely
used in many real-valued prediction (regression) Unigrams 0.102 0.105 0.118 0.181*
problems in NLP (Albrecht and Hwa, 2007; Yo- + Bigrams 0.115 0.164 0.187 0.237*
gatama et al., 2011), and here we use them to mea- + Named Entities 0.127 0.202 0.213 0.248*
sure the quality of predicted values ŷ by comparing + Part-of-Speech 0.125 0.218 0.232 0.239
+ Dependency 0.130 0.223 0.242 0.255
to the vector of ground truth y. Kendall’s tau is a
+ Semantics 0.124 0.257 0.270 0.270
nonparametric statistical metric that have shown to All Text + Vision 0.284 0.288 0.314 0.580*
be inexpensive, robust, and representation indepen-
dent (Lapata, 2006). We use paired two-tailed t-test Table 1: The Spearman correlation (top table) and
to measure the statistical significance. Kendall’s τ (bottom table) for comparing various text fea-
tures and combining with vision features. The best results
5.1 Comparison with Various Baselines of each row are highlighted in bold. * indicates p < .001
The first two figures in Figure 5 show the learn- comparing to the second best result.
ing curve of our system, comparing other baselines.
We see that when increasing the amount of training mance for associating popular votes, meme images,
data, our approach clearly dominates all other meth- and text descriptions.
ods by a large margin. Linear and Gaussian SVMs
5.3 The Effects of Dropout Training for
perform similarly, and have good performances with
Nonparanormals
only 25% of the training data, but the improvements
are not large when increasing the amount of training As we mentioned before, because NPNs model the
data. complex network of random variables, a key issue
In the last two figures in Figure 5, we increase for training NPN is to prevent the model from over-
the amount of features, and compare various mod- fitting to the training data. So far, none of the prior
els. We see that the linear regression model overfits work have investigated dropout training for regular-
with 600 features, and Gaussian SVM outperforms izing the nonparanormals or even copula in general.
the linear SVM. We see that our NPN model clearly To empirical test the effects of dropout training for
outperforms all baselines by a big gap, and does not nonparanormals, in addition to our datasets, we also
overfit. compare with the unregularized copula from Wang
and Hua (2014) on predicting financial risks from
5.2 Combination of Text and Vision earnings calls. Table 2 clearly suggests that dropout
In Table 1, we systematically compare the contribu- training for NPNs significant improves the perfor-
tions of each feature set. First, we see that bigram mances on various datasets.
features clearly improve the performance on top of
unigram features. Second, named entities are crucial 5.4 Qualitative Analysis
for further boosting the performance. Third, adding Table 3 shows the top ranked text features that are
the shallow part-of-speech features does not benefit highly correlated with popular votes. We see that the
all models, but the dependency triples are shown to named entity features are useful: Paul Walker, UPS,
be useful for all methods. Finally, we see that using Bruce Willis, Pencil Guy, Amy Winehouse are rec-
semantic features helps increasing the performances ognized as entities in the meme dataset. Dependency
for most of the cases, and combining text and vision triples, as a less-understood feature set, also perform
features in our NPN framework doubles the perfor- well in this task. For example, xcomp(tell,mean)Figure 5: Two figures on the left: varying the amount of training data. L(1): Spearman. L(2): Kendall. Two figures on
the right: varying the amount of features. R(1): Spearman. R(2): Kendall.
Datasets No Dropout With Dropout Top 1-10 Top 11-20 Top 21-30
Meme 0.625 0.754* paul/PER FE party you new
Finance (pre2009) 0.416 0.482* xcomp(tell,mean) dep(when,but) FE Entity it
Finance (2009) 0.412 0.445* possessive(’s,it) ... : bruce/PER
Finance (post2009) 0.377 0.409* yo daw FE Theme i FE party we
Meme 0.491 0.580* pobj(vegas,in) on a FE Food fat
Finance (pre2009) 0.307 0.349* ups/ORG FE Exp. they make
Finance (2009) 0.302 0.318* into FE Entity you so you
Finance (post2009) 0.282 0.297* so you’re how penci/PER
FE Cognizer i of the y
Table 2: The effects of dropout training for NPNs on yo . pobj(life,of) winehouse/PER
meme and other datasets. The best results of each row
are highlighted in bold. * indicates p < .001 comparing Table 3: Top-30 linguistic features that are highly corre-
to the no dropout setting. lated with the popular votes.
captures the dependency relation of the popular of memes, and Web dialect such as “y” (why) also
meme series “You mean to tell me...”. Interestingly, exhibits high correlation with the popular votes.
the transitional dependency feature dep(when,but) 6 Generation Experiments
plays an important role in the language of memes.
In this section, we investigate the performance of
The object of a preposition, such as pobj(vegas,in)
our meme generation system using 50 test meme
and pobj(life,of), also made the list.
images. To quantitatively evaluate our system, we
Bigrams are shown to be important features as
compare with both unsupervised and supervised
usual. For example, “Yo daw” is a popular meme
baselines. For the unsupervised baselines, we com-
based on rapper Xzibit’s famous reality car show
pare with a compact recurrent neural network lan-
“Pimp My Ride”, where the rapper customizes peo-
guage model (RNNLM) (Mikolov, 2012) trained on
ple’s car according to personal preferences. This vi-
the 3,008 text descriptions of our meme training set,
ral meme follows the pattern8 of “Yo daw(g), I herd
as well as a full model of RNNLM trained on a large
you like X (noun), so I put an X in your Y (noun)
meme corpus of 269K sentences9 . For the super-
so you can W (verb) while you Z (verb).”
vised baselines, all models are trained on the 3,008
The use of pronouns, captured by frame semantics training image-description pairs with labels. All
features, is associated with popular memes. We hy- these models can be viewed as different re-ranking
pothesize that by using pronouns such as “i”, “you”, methods for the retrieved candidate descriptions. We
“we”, and “they”, the meme recalls personal expe- use BLEU score (Papineni et al., 2002) as the evalu-
riences and emotions, thus connects better with the ation metric, since the generation task can be viewed
audience. Finally, we see that the punctuation bi- as translating raw images into sentences, and it is
gram “... :” is an important feature in the language
9
Note that there are no image features feeding to the unsu-
8
http://knowyourmeme.com/memes/xzibit-yo-dawg pervised RNN models.BLEU points over the full RNNLM, which is trained
on a corpus that is ∼90 times larger, in an unsuper-
vised fashion. When breaking down the results, we
see that our NPN’s advantage is on generating longer
phrases, typically trigrams and four-grams, compar-
ing to the other models. This is very interesting, be-
cause generating high-quality long phrases is diffi-
cult, since the memes are often short.
We show some generation examples in Figure 6.
We see that on the left column, the reference memes
are the ones with top votes by the crowd. The first
chemistry cat meme includes puns, the second for-
ever alone meme includes reference to the life sim-
ulation video game, while the last Batman meme
has interesting conversations. In the second col-
umn, we see that the memes generated by the full
RNNLM model are short, which corresponds to the
quantitative results in Table 4. In the third col-
umn, our NPN meme generator was able to gen-
Figure 6: Examples from the meme generation exper-
erate longer descriptions. Interestingly, it also cre-
iment. First row: the chemistry cat meme. Second
row: the forever alone meme. Third row: the Batman ates a pun for the chemistry cat meme. Our genera-
slaps Robin meme. Left column: human generated top- tion on the forever alone meme is also accurate. In
voted meme descriptions on memegenerator.net at the the Batman example, we show that the NPN model
time of writing. Middle column: generated output from makes a sentence-image-mismatch type of error: al-
RNNLM. Right column: generated output from NPNs. though the generated sentence includes the entities
Batman and Robin, as well as their slapping activ-
used in many caption generation studies (Vinyals ity, it was originally created for the “overly attached
et al., 2014; Chen and Zitnick, 2014; Donahue et girlfriend” meme10 .
al., 2014; Fang et al., 2014; Karpathy and Fei-Fei,
7 Conclusions
2014).
The generation result is shown in Table 4. Note In this paper, we study the language of memes
that when combining B-1 to B-4 scores, BLEU in- by jointly learning the image, the description, and
cludes a brevity penalty as described in the original the popular votes. In particular, we propose a ro-
BLEU paper. We see that our NPN model outper- bust nonparanormal approach to transform all vi-
forms the best supervised baseline by 4.35 BLEU sion and text features into the cumulative density
points, while also obtaining an advantage of 4.48 function space. By learning the stochastic depen-
dencies, we show that our model significantly out-
performs various competitive baselines in the pre-
Systems BLEU B-1 B-2 B-3 B-4
diction experiments. In addition, we also propose
RNN-C 19.52 62.2 21.2 12.1 9.0
a simple pipeline for generating memes from raw
RNN-F 23.76 72.2 31.4* 16.2 8.7
LR 23.89 72.3 28.3 15.0 10.6 images, drawing the wisdom from reverse image
LSVM 21.06 65.0 24.8 13.1 9.3 search and traditional information retrieval perspec-
GSVM 20.63 66.2 22.8 12.8 9.3 tives. Finally, we show that our model obtains sig-
NPN 28.24* 66.9 29.0 19.7* 16.6* nificant BLEU point improvements over an unsuper-
vised RNNLM baseline trained on a larger corpus,
Table 4: The BLEU scores for generating memes from as well as other strong supervised baselines.
images. B-1 to B-4: BLEU unigram to four-grams. The
10
best BLEU results are highlighted in bold. * indicates http://www.overlyattachedgirlfriend.com
p < .001 comparing to the second best system.References Hao Fang, Saurabh Gupta, Forrest Iandola, Rupesh Sri-
vastava, Li Deng, Piotr Dollár, Jianfeng Gao, Xi-
Joshua Albrecht and Rebecca Hwa. 2007. Regression for aodong He, Margaret Mitchell, John Platt, et al. 2014.
sentence-level mt evaluation with pseudo references. From captions to visual concepts and back. arXiv
In Proceedings of ACL. preprint arXiv:1411.4952.
Yoav Artzi, Patrick Pantel, and Michael Gamon. 2012. Ali Farhadi, Mohsen Hejrati, Mohammad Amin Sadeghi,
Predicting responses to microblog posts. In Proceed- Peter Young, Cyrus Rashtchian, Julia Hockenmaier,
ings of NAACL-HLT. and David Forsyth. 2010. Every picture tells a
Eytan Bakshy, Jake M Hofman, Winter A Mason, and story: Generating sentences from images. In Com-
Duncan J Watts. 2011. Everyone’s an influencer: puter Vision–ECCV 2010, pages 15–29. Springer.
quantifying influence on twitter. In Proceedings of Manuel Fernández-Delgado, Eva Cernadas, Senén Barro,
WSDM, pages 65–74. ACM. and Dinani Amorim. 2014. Do we need hun-
Anna Bosch, Andrew Zisserman, and Xavier Munoz. dreds of classifiers to solve real world classification
2007. Image classification using random forests and problems? Journal of Machine Learning Research,
ferns. 15:3133–3181.
Chih-Chung Chang and Chih-Jen Lin. 2011. Libsvm: a Jenny Rose Finkel, Trond Grenager, and Christopher
library for support vector machines. ACM TIST. Manning. 2005. Incorporating non-local information
Xiaohong Chen and Yanqin Fan. 2006. Estimation into information extraction systems by gibbs sampling.
of copula-based semiparametric time series models. In Proceedings of the 43rd Annual Meeting on Associ-
Journal of Econometrics. ation for Computational Linguistics, pages 363–370.
Association for Computational Linguistics.
Xinlei Chen and C Lawrence Zitnick. 2014. Learning a
recurrent visual representation for image caption gen- Alan Gelfand and Adrian Smith. 1990. Sampling-based
eration. arXiv preprint arXiv:1411.5654. approaches to calculating marginal densities. Journal
of the American statistical association.
David Christensen. 2005. Fast algorithms for the calcu-
Zoubin Ghahramani, Barnabás Póczos, and Jeff Schnei-
lation of kendalls τ . Computational Statistics.
der. 2012. Copula-based kernel dependency mea-
Dipanjan Das, Nathan Schneider, Desai Chen, and sures. In Proceedings of the 29th International Con-
Noah A Smith. 2010. Probabilistic frame-semantic ference on Machine Learning.
parsing. In Proceedings of NAACL-HLT.
Abhinav Gupta, Praveen Srinivasan, Jianbo Shi, and
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, Thomas Larry S Davis. 2009. Understanding videos, con-
Lamar, Richard Schwartz, and John Makhoul. 2014. structing plots learning a visually grounded storyline
Fast and robust neural network joint models for statis- model from annotated videos. In Computer Vision and
tical machine translation. In Proceedings of ACL. Pattern Recognition, 2009. CVPR 2009. IEEE Confer-
Francis X Diebold, Todd A Gunther, and Anthony S Tay. ence on, pages 2012–2019. IEEE.
1997. Evaluating density forecasts. Fang Han, Tuo Zhao, and Han Liu. 2012. Coda: High
Jesse Dodge, Amit Goyal, Xufeng Han, Alyssa Men- dimensional copula discriminant analysis. Journal of
sch, Margaret Mitchell, Karl Stratos, Kota Yamaguchi, Machine Learning Research.
Yejin Choi, Hal Daumé III, Alexander C Berg, et al. Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky,
2012. Detecting visual text. In Proceedings of the Ilya Sutskever, and Ruslan R Salakhutdinov. 2012.
NAACL-HLT. Improving neural networks by preventing co-
Jeff Donahue, Lisa Anne Hendricks, Sergio Guadar- adaptation of feature detectors. arXiv preprint
rama, Marcus Rohrbach, Subhashini Venugopalan, arXiv:1207.0580.
Kate Saenko, and Trevor Darrell. 2014. Long-term re- Micah Hodosh, Peter Young, and Julia Hockenmaier.
current convolutional networks for visual recognition 2013. Framing image description as a ranking task:
and description. arXiv preprint arXiv:1411.4389. Data, models and evaluation metrics. J. Artif. Intell.
Carsten Eickhoff, Arjen P. de Vries, and Kevyn Collins- Res.(JAIR), 47:853–899.
Thompson. 2013. Copulas for information retrieval. Robert V Hogg and Allen Craig. 1994. Introduction to
In Proceedings of the 36th International ACM SIGIR mathematical statistics.
Conference on Research and Development in Informa- Liangjie Hong, Ovidiu Dan, and Brian D Davison. 2011.
tion Retrieval. Predicting popular messages in twitter. In Proceedings
Charles Elkan. 2003. Using the triangle inequality to of WWW.
accelerate k-means. In ICML, volume 3, pages 147– Harry Joe. 1997. Multivariate models and dependence
153. concepts.Andrej Karpathy and Li Fei-Fei. 2014. Deep visual- Michael Pitt, David Chan, and Robert Kohn. 2006. Effi- semantic alignments for generating image descrip- cient bayesian inference for gaussian copula regression tions. Stanford University Technical Report. models. Biometrika. Maurice Kendall. 1938. A new measure of rank correla- Berthold Schweizer and Abe Sklar. 1983. Probabilistic tion. Biometrika. metric spaces. Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Josef Sivic and Andrew Zisserman. 2003. Video google: 2012. Imagenet classification with deep convolutional A text retrieval approach to object matching in videos. neural networks. In Advances in neural information In Proceedings of ICCV, pages 1470–1477. IEEE. processing systems, pages 1097–1105. Abe Sklar. 1959. Fonctions de répartition à n dimen- Girish Kulkarni, Visruth Premraj, Sagnik Dhar, Siming sions et leurs marges. Université Paris 8. Li, Yejin Choi, Alexander C Berg, and Tamara L Berg. Richard Socher, Alex Perelygin, Jean Y Wu, Jason 2011. Baby talk: Understanding and generating im- Chuang, Christopher D Manning, Andrew Y Ng, and age descriptions. In Proceedings of the 24th CVPR. Christopher Potts. 2013. Recursive deep models for Citeseer. semantic compositionality over a sentiment treebank. Mirella Lapata. 2006. Automatic evaluation of informa- In Proceedings of EMNLP, pages 1631–1642. Cite- tion ordering: Kendall’s tau. Computational Linguis- seer. tics. Chenhao Tan, Lillian Lee, and Bo Pang. 2014. The ef- Han Liu, John Lafferty, and Larry Wasserman. 2009. fect of wording on message propagation: Topic- and The nonparanormal: Semiparametric estimation of author-controlled natural experiments on twitter. In high dimensional undirected graphs. The Journal of Proceedings of ACL. Machine Learning Research, 10:2295–2328. Robert Tibshirani. 1996. Regression shrinkage and se- Han Liu, Fang Han, Ming Yuan, John Lafferty, and Larry lection via the lasso. Journal of the Royal Statistical Wasserman. 2012. High-dimensional semiparamet- Society. Series B (Methodological), pages 267–288. ric gaussian copula graphical models. The Annals of Kristina Toutanova, Dan Klein, Christopher D Manning, Statistics. and Yoram Singer. 2003. Feature-rich part-of-speech Tomáš Mikolov. 2012. Statistical language models tagging with a cyclic dependency network. In Pro- based on neural networks. Ph.D. thesis, Ph. D. the- ceedings of NAACL-HLT. sis, Brno University of Technology. Oriol Vinyals, Alexander Toshev, Samy Bengio, and Du- Margaret Mitchell, Xufeng Han, Jesse Dodge, Alyssa mitru Erhan. 2014. Show and tell: A neural image Mensch, Amit Goyal, Alex Berg, Kota Yamaguchi, caption generator. arXiv preprint arXiv:1411.4555. Tamara Berg, Karl Stratos, and Hal Daumé III. 2012. Stefan Wager, Sida Wang, and Percy Liang. 2013. Midge: Generating image descriptions from computer Dropout training as adaptive regularization. In Ad- vision detections. In Proceedings of EACL. vances in Neural Information Processing Systems, Roger B Nelsen. 1999. An introduction to copulas. pages 351–359. Springer Verlag. William Yang Wang and Zhenhao Hua. 2014. A semi- Joakim Nivre, Johan Hall, Jens Nilsson, Atanas Chanev, parametric gaussian copula regression model for pre- Gülsen Eryigit, Sandra Kübler, Svetoslav Marinov, dicting financial risks from earnings calls. In Proceed- and Erwin Marsi. 2007. Maltparser: A language- ings of ACL. independent system for data-driven dependency pars- Sida Wang and Christopher Manning. 2013. Fast ing. Natural Language Engineering, 13(02):95–135. dropout training. In Proceedings of ICML. Maxime Oquab, Leon Bottou, Ivan Laptev, Josef Sivic, Dani Yogatama, Michael Heilman, Brendan O’Connor, et al. 2013. Learning and transferring mid-level image Chris Dyer, Bryan R Routledge, and Noah A Smith. representations using convolutional neural networks. 2011. Predicting a scientific community’s response to Kishore Papineni, Salim Roukos, Todd Ward, and Wei- an article. In Proceedings of EMNLP. Jing Zhu. 2002. Bleu: a method for automatic evalua- tion of machine translation. In Proceedings of ACL, pages 311–318. Association for Computational Lin- guistics. Rahul A Parsa and Stuart A Klugman. 2011. Copula regression. Variance Advancing and Science of Risk. Emanuel Parzen. 1962. On estimation of a probability density function and mode. The annals of mathemati- cal statistics.
You can also read

















































